






集成方式
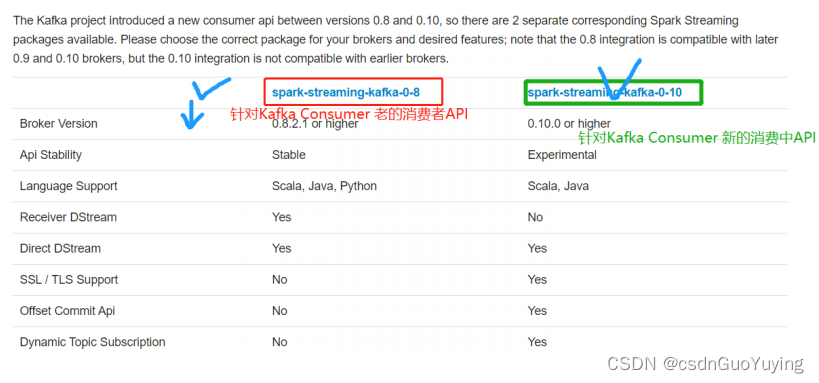
Spark Streaming与Kafka集成,有两套API,原因在于Kafka Consumer API有两套,
文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-integration.html。
方式一:Kafka 0.8.x版本
- 老的Old Kafka Consumer API
- 文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-8-integration.html
- 老的Old消费者API,有两种方式:
- 第一种:高级消费API(Consumer High Level API),Receiver接收器接收数据
- 第二种:简单消费者API(Consumer Simple Level API) ,Direct 直接拉取数据
方式二:Kafka 0.10.x版本
- 新的 New Kafka Consumer API
- 文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-10-integration.html
- 核心API:KafkaConsumer、ConsumerRecorder
两种方式区别
使用Kafka Old Consumer API集成两种方式,虽然实际生产环境使用Direct方式获取数据,但是在面试的时候常常问到两者区别。
文档:http://spark.apache.org/docs/2.4.5/streaming-kafka-0-8-integration.html
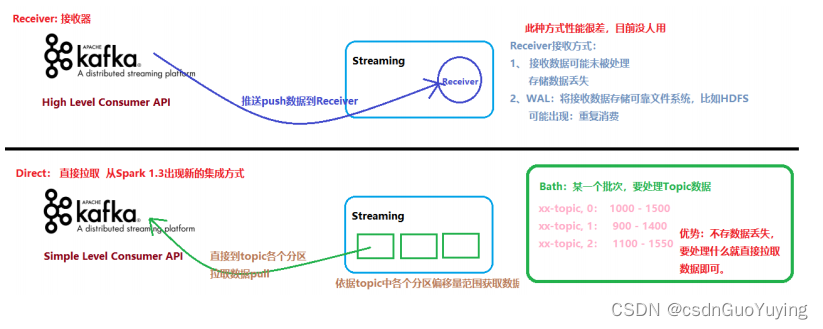
- Receiver-based Approach:
- 基于接收器方式,消费Kafka Topic数据,但是企业中基本上不再使用;
- Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,需要开启多个,再手动合并数据(union),再进行处理,很麻烦;
- Receiver那台机器挂了,可能会丢失数据,所以需要开启WAL(预写日志)保证数据安全,那么效率又会降低;
- Receiver方式是通过zookeeper来连接kafka队列,调用Kafka高阶API,offset存储在zookeeper,由Receiver维护;
- Spark在消费的时候为了保证数据不丢也会在Checkpoint中存一份offset,可能会出现数据不一致;
- Direct Approach (No Receivers):
- 直接方式,Streaming中每批次的每个job直接调用Simple Consumer API获取对应Topic数据,此种方式使用最多,面试时被问的最多;
- Direct方式是直接连接kafka分区来获取数据,从每个分区直接读取数据大大提高并行能力
- Direct方式调用Kafka低阶API(底层API),offset自己存储和维护,默认由Spark维护在checkpoint中,消除了与zk不一致的情况;
- 当然也可以自己手动维护,把offset存在MySQL、Redis和Zookeeper中;
上述两种方式区别,如下图所示:
4.2 Direct 方式集成
使用Kafka Old Consumer API方式集成Streaming,采用Direct方式,调用Old Simple Consumer API,
文档:
http://spark.apache.org/docs/2.4.5/streaming-kafka-0-8-integration.html#approach-2-direct-approach-no-receivers
编码实现
Direct方式会定期地从Kafka的topic下对应的partition中查询最新的偏移量,再根据偏移量范围,在每个batch里面处理数据,Spark通过调用kafka简单的消费者API读取一定范围的数据。

Direct方式没有receiver层,其会周期性的获取Kafka中每个topic的每个partition中的最新offsets,再根据设定的maxRatePerPartition来处理每个batch。较于Receiver方式的优势:
- 其一、简化的并行:Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据;
- 其二、高效:no need for Write Ahead Logs;
- 其三、精确一次:直接使用simple Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录。
添加相关MAVEN依赖:
<!-- Spark Streaming 集成Kafka 0.8.2.1 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.4.5</version>
</dependency>
提供工具类KafkaUtils专门从Kafka消费数据,其中函数【createDirectStream】消费数据:

创建Topic及Console控制台发送数据,命令如下:
# 1. 启动Zookeeper 服务
zookeeper-daemon.sh start
# 2. 启动Kafka 服务
kafka-daemon.sh start
# 3. Create Topic
kafka-topics.sh --create --topic wc-topic \
--partitions 3 --replication-factor 1 --zookeeper node1.itcast.cn:2181/kafka200
# List Topics
kafka-topics.sh --list --zookeeper node1.itcast.cn:2181/kafka200
# Producer
kafka-console-producer.sh --topic wc-topic --broker-list node1.itcast.cn:9092
# Consumer
kafka-console-consumer.sh --topic wc-topic \
--bootstrap-server node1.itcast.cn:9092 --from-beginning
具体演示代码如下:
import java.util.Date
import kafka.serializer.StringDecoder
import org.apache.commons.lang3.time.FastDateFormat
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 集成Kafka,采用Direct式读取数据,对每批次(时间为1秒)数据进行词频统计,将统计结果输出到控制台
*/
object StreamingKafkaDirect {
def main(args: Array[String]): Unit = {
// 1、构建流式上下文实例对象StreamingContext,用于读取流式的数据和调度Batch Job执行
val ssc: StreamingContext = {
// a. 创建SparkConf实例对象,设置Application相关信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
//TODO: 设置每秒钟读取Kafka中Topic最大数据量
.set("spark.streaming.kafka.maxRatePerPartition", "10000")
// b. 创建StreamingContext实例,传递Batch Interval(时间间隔:划分流式数据)
val context: StreamingContext = new StreamingContext(sparkConf, Seconds(5))
// c. 返回上下文对象
context
}
// TODO: 2、从流式数据源读取数据
/*
def createDirectStream[
K: ClassTag, // Topic中Key数据类型
V: ClassTag,
KD <: Decoder[K]: ClassTag, // 表示Topic中Key数据解码(从文件中读取,反序列化)
VD <: Decoder[V]: ClassTag] (
ssc: StreamingContext,
kafkaParams: Map[String, String],
topics: Set[String]
): InputDStream[(K, V)]
*/
// 表示从Kafka Topic读取数据时相关参数设置
val kafkaParams: Map[String, String] = Map(
"bootstrap.servers" -> "node1.itcast.cn:9092",
// 表示从Topic的各个分区的哪个偏移量开始消费数据,设置为最大的偏移量开始消费数据
"auto.offset.reset" -> "largest"
)
// 从哪些Topic中读取数据
val topics: Set[String] = Set("wc-topic")
// 采用Direct方式从Kafka 的Topic中读取数据
val kafkaDStream: DStream[(String, String)] = KafkaUtils
.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, //
kafkaParams, //
topics
)
// 3、对接收每批次流式数据,进行词频统计WordCount
val resultDStream: DStream[(String, Int)] = kafkaDStream.transform(rdd => {
rdd
// 获取从Kafka读取数据的Message
.map(tuple => tuple._2)
// 过滤“脏数据”
.filter(line => null != line && line.trim.length > 0)
// 分割为单词
.flatMap(line => line.trim.split("\\s+"))
// 转换为二元组
.mapPartitions{iter => iter.map(word => (word, 1))}
// 聚合统计
.reduceByKey((a, b) => a + b)
})
// 4、将分析每批次结果数据输出,此处答应控制台
resultDStream.foreachRDD{ (rdd, time) =>
// 使用lang3包下FastDateFormat日期格式类,属于线程安全的
val batchTime = FastDateFormat.getInstance("yyyy/MM/dd HH:mm:ss")
.format(new Date(time.milliseconds))
println("-------------------------------------------")
println(s"Time: $batchTime")
println("-------------------------------------------")
// TODO: 先判断RDD是否有数据,有数据在输出哦
if(!rdd.isEmpty()){
rdd
// 对于结果RDD输出,需要考虑降低分区数目
.coalesce(1)
// 对分区数据操作
.foreachPartition{iter =>iter.foreach(item => println(item))}
}
}
// 5、对于流式应用来说,需要启动应用,正常情况下启动以后一直运行,直到程序异常终止或者人为干涉
ssc.start() // 启动接收器Receivers,作为Long Running Task(线程) 运行在Executor
ssc.awaitTermination()
// 结束Streaming应用执行
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
从WEB UI监控页面可以看出如下信息:

















 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











