







java 加密结果不一致的各个坑
1.String的public byte[] getBytes()
2.转Base64字符串
3.jdk的版本,jvm运行环境的配置
4.是否使用第三方加密类
5.操作系统版本
1、String的public byte[] getBytes()方法
此方法作用:使用平台(程序的运行环境)的默认字符集将此String 编码为字节序列,并将结果存储到新的字节数组中
此方法常用重载方法:public byte[] getBytes(Charset charset),即使用指定的字符集,将String编码为字节序列,并将结果存储到新的字节数组中
加密中的坑点:在加密中,String.getBytes()是常用方法,如果不指定字符集,此方法将使用平台默认的字符集来进行编码,这样在接口对接中,很可能因为平台默认编码字符集不一致而加密得到不一致的结果,特别是String中带有中文时
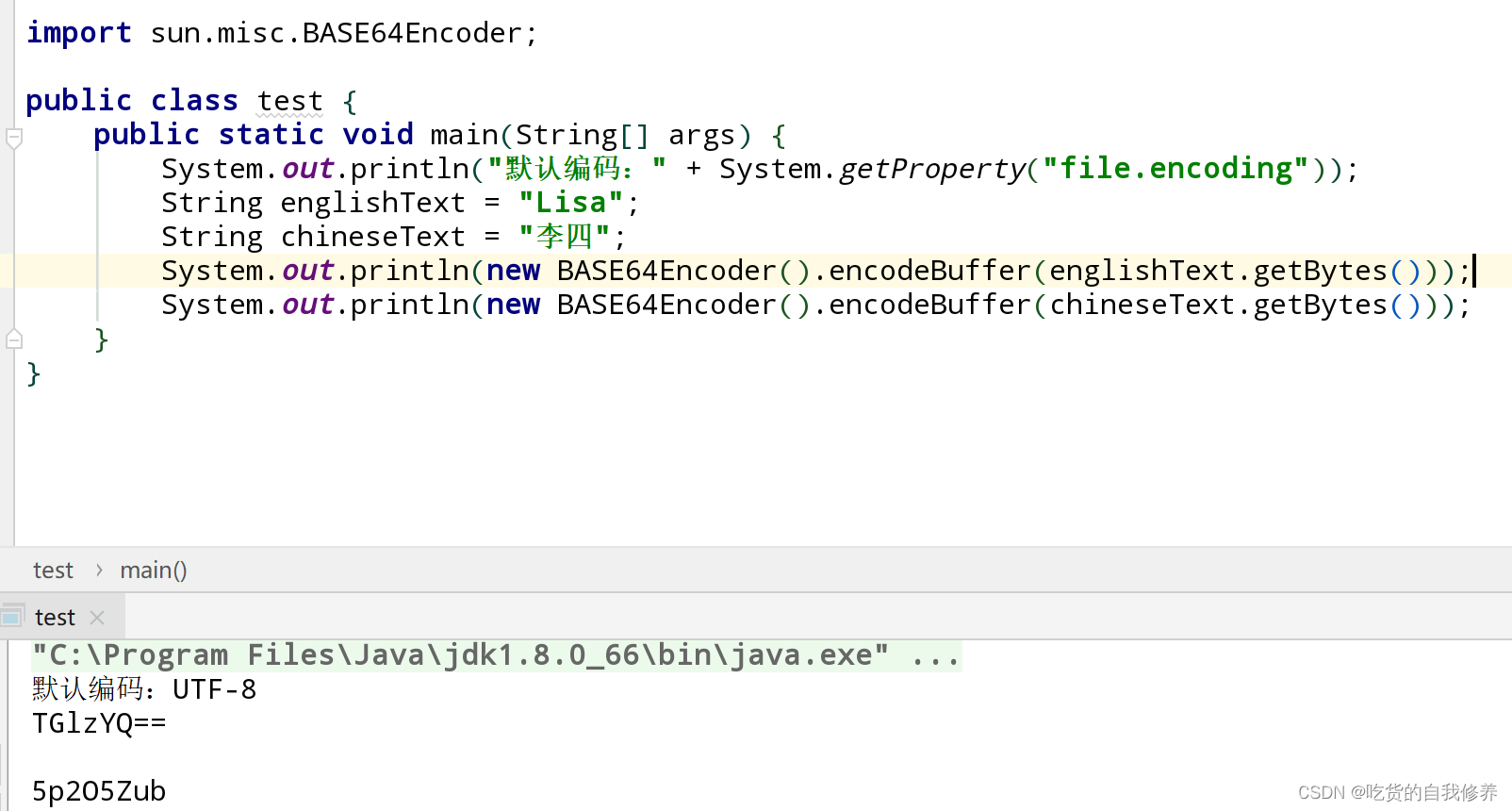
查看平台默认编码集
System.out.println("默认编码:" + System.getProperty("file.encoding"));
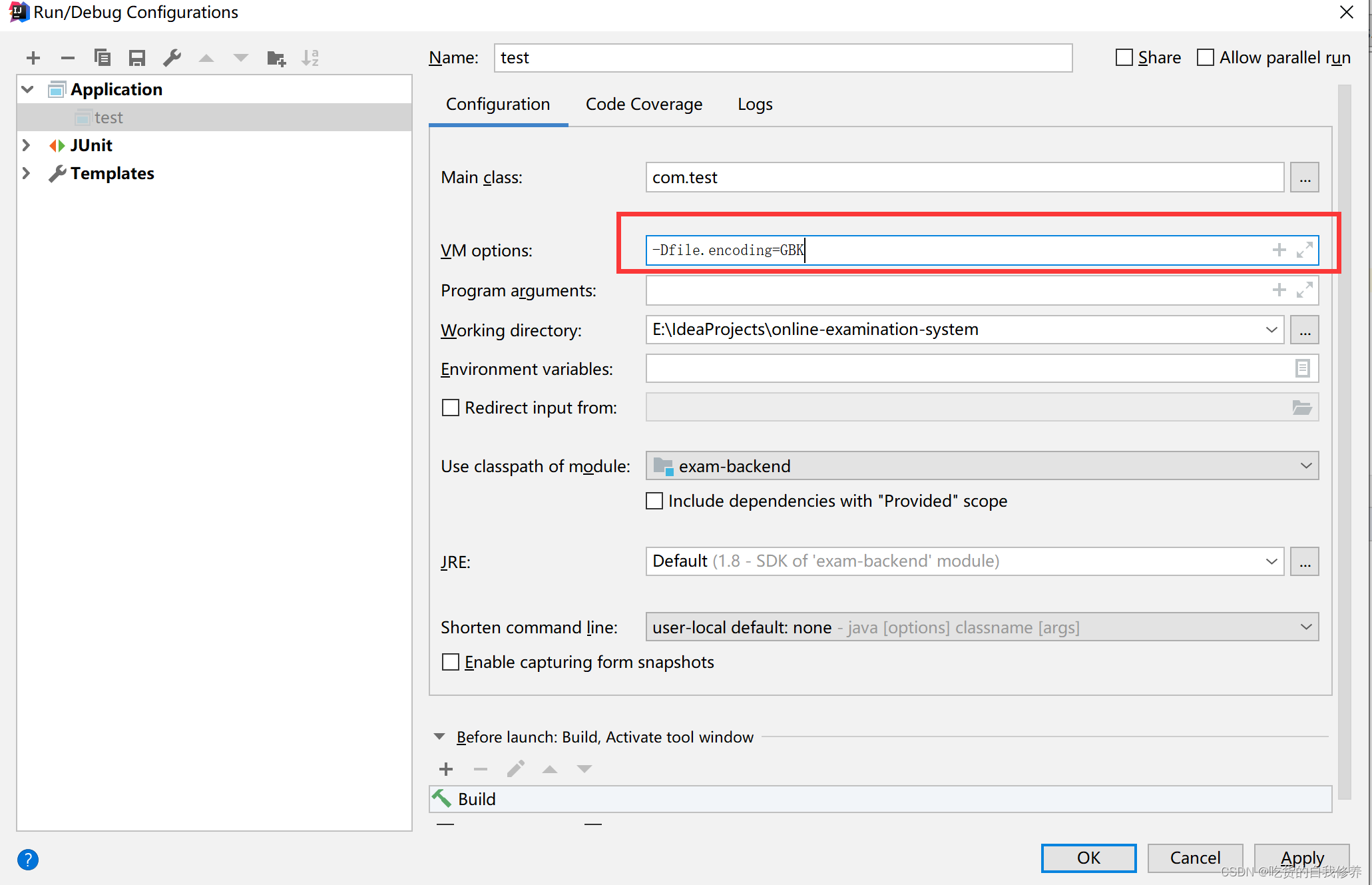
可通过IDEA配置JVM编码集
-Dfile.encoding=GBK
验证效果如图(当前默认编码集为UTF-8)
配置idea默认编码集
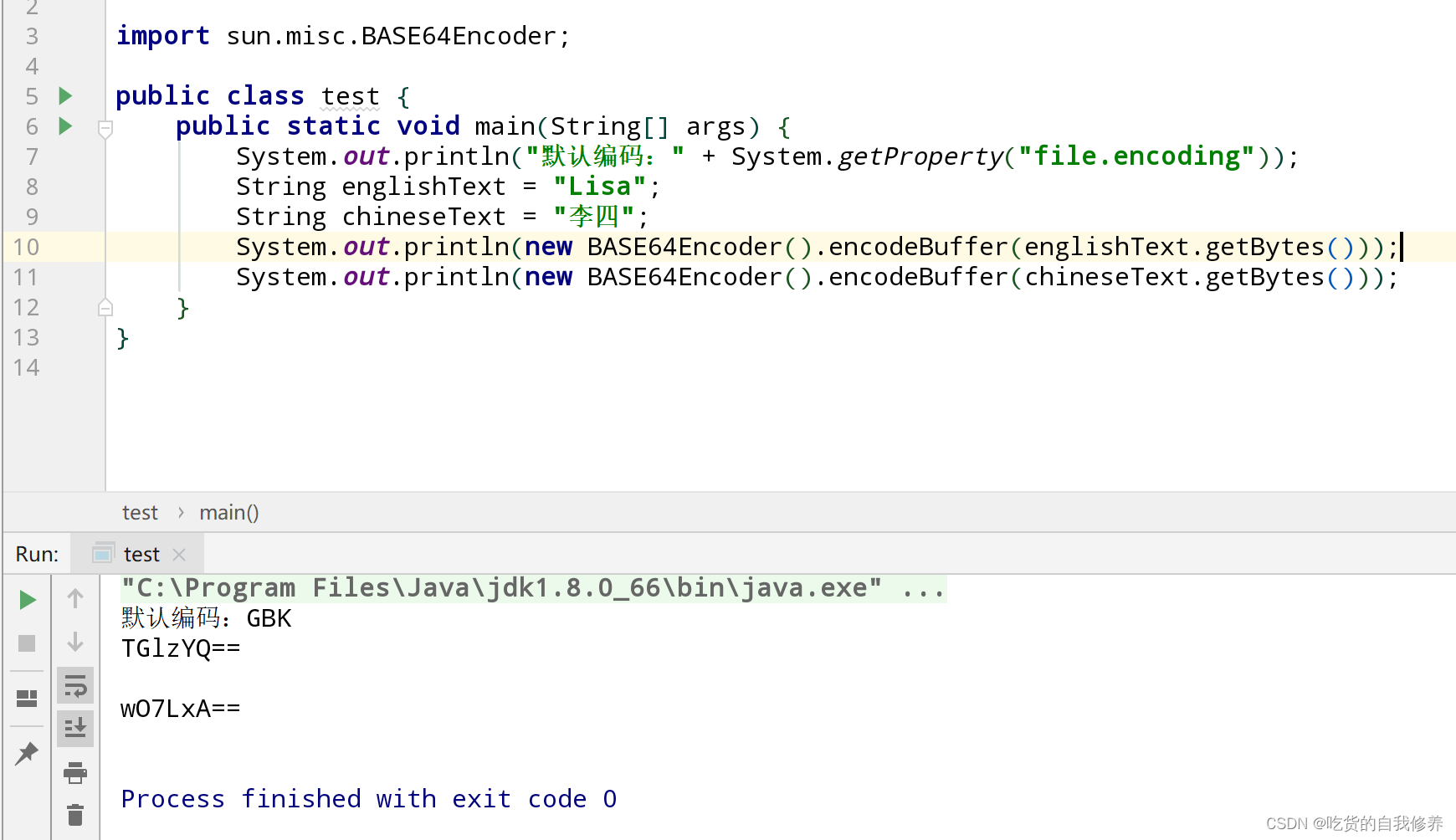
由以上运行结果可以发现,对于英文来说GBK,UTF-8编码结果是一致的,但是中文编码结果不一致
2、Base64编码
参考资料:
1.什么是Base64?
2.Base64编码出现换行符
3.Base64百度百科
Base64是一种字符串编码格式,能将任意Binary资料用64种(可打印字符)字元组合(A-Z、a-z、0-9、+、/(还有补位符=)。
Base64的编码规则(RFC822规定):
1.把每三个8Bit的字节转换为四个6Bit的字节,原字节数非3倍数,先转6bit,剩余用=补齐(可参照百度百科)
2.每76个字符需要加上一个回车换行
3.最后的结束符也要处理
加密中的坑点:坑点其实就是编码规则中的第二条,每76个字符需要加上一个回车换行,但是不是所有的编码包都遵循这个规范
import sun.misc.BASE64Decoder;
import sun.misc.BASE64Encoder;
import java.io.IOException;
import java.util.Base64;
public class test {
public static void main(String[] args) throws IOException {
System.out.println("默认编码:" + System.getProperty("file.encoding"));
String englishText = "LisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisaLisa";
String chineseText = "李四";
//1.jdk rt.jar自带的sun.misc.BASE64Encoder
String s = new BASE64Encoder().encodeBuffer(englishText.getBytes());
String r = new String(new BASE64Decoder().decodeBuffer(s));
//2.jdk rt.jar自带的java.util.Base64
String s1 = Base64.getEncoder().encodeToString(englishText.getBytes());
String r1 = new String(Base64.getDecoder().decode(s1));
//3.Apache Commons Codec
String s2 = org.apache.commons.codec.binary.Base64.encodeBase64String(englishText.getBytes());
String r2 = new String(org.apache.commons.codec.binary.Base64.decodeBase64(s2));
System.out.println("------------------------------------");
System.out.println("sun.misc.BASE64Encoder加密:\n"+s);
System.out.println("sun.misc.BASE64Decoder解密:\n"+r);
System.out.println("------------------------------------");
System.out.println("java.util.Base64加密:\n"+s1);
System.out.println("java.util.Base64解密:\n"+r1);
System.out.println("------------------------------------");
System.out.println("org.apache.commons.codec.binary.Base64加密:\n"+s2);
System.out.println("org.apache.commons.codec.binary.Base64解密:\n"+r2);
System.out.println("------------------------------------");
}
}
运行结果如下:

由以上运行结果可以发现,
- sun.misc.BASE64Encoder加密,每76个字符会加上回车换行,末尾也会加上回车换行
- java.util.Base64和org.apache.commons.codec.binary.Base64运行结果是一致的,不包含回车换行
经过测试 java.util.Base64解析sun.misc.BASE64Encoder会解析失败,所以使用org.apache.commons.codec.binary.Base64来转Base64为佳,不用担心效率问题以及编码包之间的差异
3、URLEncoder编码
各中间件url传输的默认编码可能不一致
tomcat默认的在url传输时是用iso-8859-1编码。
解决方案一:
在使用get传输参数时,将参数中的中文转换成url格式,也就是使用urlEncode和urlDecode来传输,使用这种方式就是把中文转换成以%开头的编码在url中传输。
使用这种方法时,要注意两点。
1.前台使用urlencode,在后台相应的使用urldecode(浏览器在后台会自动执行一次 UrlDecode)。
2.使用urlencode的内容是参数内空。千万要注意,他是会把等于号等符号也给转换了。所以,最好是先把参数传换后再进行拼接。而不是把url拼接好再去转换。
解决方案二:
配置tomcat,使用其在url传输过程中使用相应的支持中文的编码。一般国内的喜欢用gbk或gb2312。我个人建议使用utf-8
在tomcat的/conf/server.xml文件中,找到以下这一行。
这行的意思也就是使用8080端口来接收html的请求。在这里可以加几个参数来配置不同的效果。
URIEncoding=“UTF-8” 设置url传输时对url内容的编码格式















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









