







一、hadoop集群环境部署:
(服务器已经搭建好java环境)
1、准备材料:
(1)服务器
(2)hadoop-2.6.5.tar.gz
2、修改服务器主机名,并在hosts文件中添加如下内容:
1.9.6.1 dataNode2
1.9.6.2 dataNode1
1.9.6.4 nameNode1
3、设置nameNode到dataNode免密登录
(1)生成SSH免登录秘钥:[escomp@nameNode1 ~]$ ssh-keygen -t rsa;(ssh-keygen -t rsa -P ''一直回车到结束),生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)。
(2)将id_rsa.pub添加至authorized_keys:[escomp@nameNode1 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
(3)将authorized_keys拷贝到dataNode主机上/home/escomp/.ssh文件夹下
(2-2)或者将A主机生成的id_rsa.pub复制到B主机并且改名为authorized_keys:[A]$ scp id_rsa.pub B:~/.ssh/authorized_keys
3、安装hadoop
(1)在服务其中创建hadoop文件夹。
(2)将hadoop-2.6.5.tar.gz粘贴到hadoop中并解压
(3)修改配置文件(hadoop-2.6.5/etc/hadoop下面)
1)修改hadoop-env.sh中jdk地址
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk.x86_64
2)core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://nameNode1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/escompdata/hadoop/temp</value>
<description>Abasefor other temporary directories.</description>
</property>
</configuration>
3)hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>nameNode1:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///escompdata/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///escompdata/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4)mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>nameNode1:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>nameNode1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>nameNode1:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://nameNode1:9001</value>
</property>
</configuration>
5)yarn-env.sh中添加JDK
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk.x86_64
6)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>1.9.6.4:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>1.9.6.4:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>1.9.6.4:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>1.9.6.4:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>1.9.6.4:8088</value>
</property>
</configuration>
7)slaves中添加dataNode主机的主机名
(4)创建下图中的文件夹

(5)对nameNode进行格式化:[escomp@nameNode1 bin]$ hadoop namenode -format
(6)启动hadoop:[escomp@nameNode1 sbin]$ ./start-all.sh
(7)通过jps查看进程
二、运行程序:
1、创建input目录:
[escomp@nameNode1 hadoop-2.6.5]$ mkdir input
2、在input创建f1、f2并写内容:
[escomp@nameNode1 hadoop-2.6.5]$ vi file1
[escomp@nameNode1 hadoop-2.6.5]$ vi file2
3、在hdfs创建/tmp/input目录:
[escomp@nameNode1 hadoop-2.6.5]$ ./bin/hadoop fs -mkdir /tmp
[escomp@nameNode1 hadoop-2.6.5]$ ./bin/hadoop fs -mkdir /tmp/input
4、将file1、file2文件copy到hdfs /tmp/input目录
[escomp@nameNode1 hadoop-2.6.5]$ ./bin/hadoop fs -put /escompdata/hadoop/input /tmp
5、查看hdfs上是否有file1、file2文件
[escomp@nameNode1 hadoop-2.6.5]$ ./bin/hadoop fs -ls /tmp/input/
6、执行wordcount程序
[escomp@nameNode1 hadoop-2.6.5]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /tmp/input /output
7、查看执行结果
[escomp@nameNode1 hadoop]$ hadoop fs -cat /output/part-r-00000 (命令执行在hadoop-2.6.5上一级)
8、hdfs命令:
(1)查看hdfs中的文件:[escomp@nameNode1 hadoop-2.6.5]$ ./bin/hadoop fs -ls 文件夹
三、hadoop文件权限修改
1、查看文件夹tmp下文件权限:
[escomp@nameNode1 hadoop-2.6.5]$ hadoop fs -ls /tmp
2、修改tmp文件夹下的文件权限
[escomp@nameNode1 hadoop-2.6.5]$ hadoop dfs -chmod -R 755 /tmp/
(服务器已经搭建好java环境)
1、准备材料:
(1)服务器
(2)hadoop-2.6.5.tar.gz
2、修改服务器主机名,并在hosts文件中添加如下内容:
1.9.6.1 dataNode2
1.9.6.2 dataNode1
1.9.6.4 nameNode1
3、设置nameNode到dataNode免密登录
(1)生成SSH免登录秘钥:[escomp@nameNode1 ~]$ ssh-keygen -t rsa;(ssh-keygen -t rsa -P ''一直回车到结束),生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)。
(2)将id_rsa.pub添加至authorized_keys:[escomp@nameNode1 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
(3)将authorized_keys拷贝到dataNode主机上/home/escomp/.ssh文件夹下
(2-2)或者将A主机生成的id_rsa.pub复制到B主机并且改名为authorized_keys:[A]$ scp id_rsa.pub B:~/.ssh/authorized_keys
3、安装hadoop
(1)在服务其中创建hadoop文件夹。
(2)将hadoop-2.6.5.tar.gz粘贴到hadoop中并解压
(3)修改配置文件(hadoop-2.6.5/etc/hadoop下面)
1)修改hadoop-env.sh中jdk地址
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk.x86_64
2)core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://nameNode1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/escompdata/hadoop/temp</value>
<description>Abasefor other temporary directories.</description>
</property>
</configuration>
3)hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>nameNode1:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///escompdata/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///escompdata/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4)mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>nameNode1:50030</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>nameNode1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>nameNode1:19888</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://nameNode1:9001</value>
</property>
</configuration>
5)yarn-env.sh中添加JDK
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk.x86_64
6)yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>1.9.6.4:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>1.9.6.4:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>1.9.6.4:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>1.9.6.4:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>1.9.6.4:8088</value>
</property>
</configuration>
7)slaves中添加dataNode主机的主机名
(4)创建下图中的文件夹
(5)对nameNode进行格式化:[escomp@nameNode1 bin]$ hadoop namenode -format
(6)启动hadoop:[escomp@nameNode1 sbin]$ ./start-all.sh
(7)通过jps查看进程
nameNode节点:
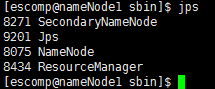
dataNode节点:
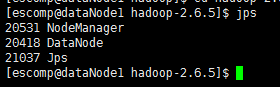
1)http://1.9.6.4:50070/
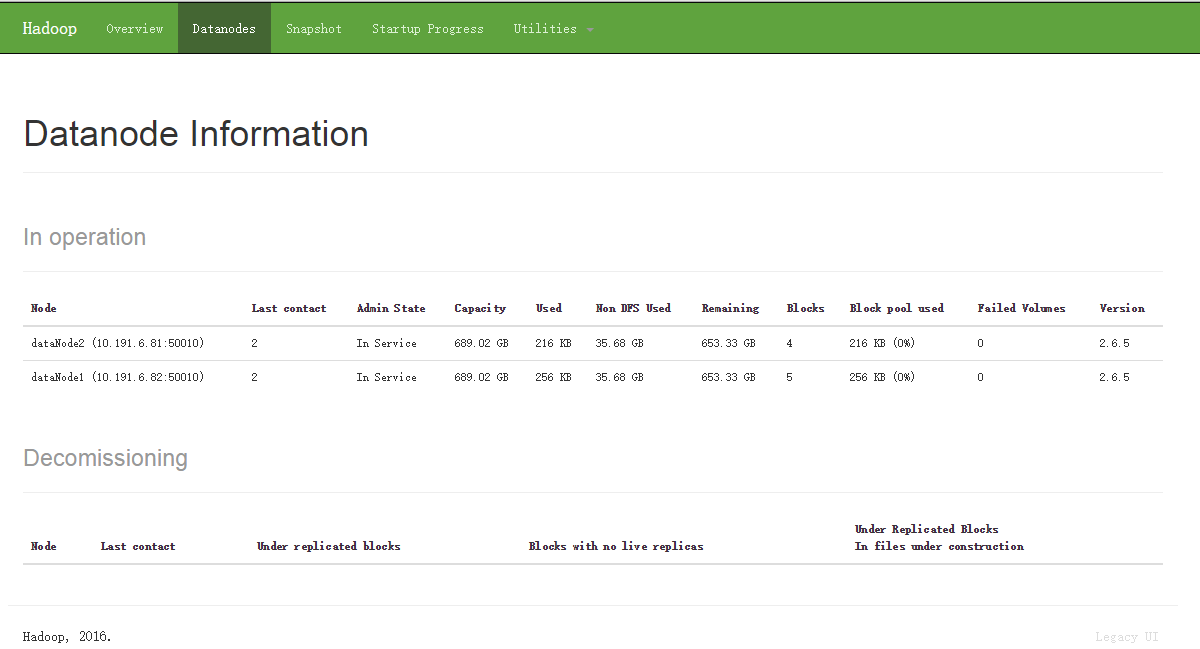

二、运行程序:
1、创建input目录:
[escomp@nameNode1 hadoop-2.6.5]$ mkdir input
2、在input创建f1、f2并写内容:
[escomp@nameNode1 hadoop-2.6.5]$ vi file1
[escomp@nameNode1 hadoop-2.6.5]$ vi file2
3、在hdfs创建/tmp/input目录:
[escomp@nameNode1 hadoop-2.6.5]$ ./bin/hadoop fs -mkdir /tmp
[escomp@nameNode1 hadoop-2.6.5]$ ./bin/hadoop fs -mkdir /tmp/input
4、将file1、file2文件copy到hdfs /tmp/input目录
[escomp@nameNode1 hadoop-2.6.5]$ ./bin/hadoop fs -put /escompdata/hadoop/input /tmp
5、查看hdfs上是否有file1、file2文件
[escomp@nameNode1 hadoop-2.6.5]$ ./bin/hadoop fs -ls /tmp/input/
6、执行wordcount程序
[escomp@nameNode1 hadoop-2.6.5]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar wordcount /tmp/input /output
7、查看执行结果
[escomp@nameNode1 hadoop]$ hadoop fs -cat /output/part-r-00000 (命令执行在hadoop-2.6.5上一级)
8、hdfs命令:
(1)查看hdfs中的文件:[escomp@nameNode1 hadoop-2.6.5]$ ./bin/hadoop fs -ls 文件夹
三、hadoop文件权限修改
1、查看文件夹tmp下文件权限:
[escomp@nameNode1 hadoop-2.6.5]$ hadoop fs -ls /tmp
2、修改tmp文件夹下的文件权限
[escomp@nameNode1 hadoop-2.6.5]$ hadoop dfs -chmod -R 755 /tmp/















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









