






Deepseek-R1最近要多火有多火。我们除了看热闹,也别浪费了R1炸裂的推理能力,辜负deepseek开源的良苦用心。大家跟我动起手来,亲自微调它!
我们选择微调的预训练模型是“DeepSeek-R1-Distill-Qwen-1.5B”。为什么?因为它尺寸最小,我们可以调得动它。目前看来,1.5B只是个玩具模型,不能指望它能涌现出来神奇能力,但麻雀虽小五脏俱全,一通百通,一顺百顺。调通了1.5B,32B还远吗?
不多废话,开始干货。
以下出于教学目的,各类设定就保持简单,跑通代码为第一要务。另外,各项设定未必是最佳训练参数,需要反复实践去精细调整。
我们的任务是股指预测,既根据一段股指价格序列,预测下一个时间步的股指价格涨跌幅。为了教学方便,暂且设定这样简单但不实用的任务。读者可以根据自己的任务去修改。
我们的数据是上证指数(000001.SH),数据量是1万条,仅包含收盘价。
DeepSeek-R1-Distill-Qwen-1.5B能够支持的上下文窗口为32K,我们训练输入设定为2000。
训练环境依旧是使用我们熟悉的modelscope免费GPU资源。白嫖的就是香。
来到我们的主页,记得模型文件到notebook中再下载,速度飞起。
进入notebook,选择GPU环境:
加载必要的python包。
import pandas as pd``import numpy as np``from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer, DataCollatorWithPadding``import torch``import torch.nn as nn``from datasets import Dataset``from peft import LoraConfig, get_peft_model``from sklearn.model_selection import train_test_split
上下文长度最大可以支持32000.
MAX_LENGTH = 5000
预处理输入。我们将价格一字排开,顺序罗列,并将下一根K线的涨跌幅作为标签。但这样未必是最好的处理方式,此处权且暂时如此。有更多的优化方式,比如多周期,多特征输入。
def generate_sequences(prices, window_size):` `sequences = []` `labels = []` `for i in range(len(prices) - window_size - 1):` `window = prices[i:i + window_size]` `next_price = prices[i + window_size]` `last_price = window[-1]` `score = (next_price - last_price) / last_price # 相对变化率` `# 将价格序列转换为文本(示例:"1.2,3.4,5.6,...")` `sequence_text = ",".join([f"{x:.4f}" for x in window])` `sequences.append(sequence_text)` `labels.append(float(score))` `return sequences, labels
加载训练数据源。此处的输入窗口我们设定为2000,即根据2000根K线去预测下一根。相信大力出奇迹。
# 使用示例``df = pd.read_csv("上证1小时0126.csv")``prices = df["close"].values``sequences, labels = generate_sequences(prices, window_size=2000)`` ``# 按时间顺序分割(避免未来数据泄漏)``train_sequences, test_sequences, train_labels, test_labels = train_test_split(` `sequences, labels, test_size=0.2, shuffle=False``)
指定训练设备。
# 明确指定设备``device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
加载分词器。model_name是我们下载的预训练模型的文件夹。
model_name = "./deepseek-qwen-1.5b/"``tokenizer = AutoTokenizer.from_pretrained(` `model_name,` `pad_token="[PAD]", # 显式定义填充标记` `padding_side="right" # 对齐填充方向``)`` ``# 检查 tokenizer 是否已有 pad_token``if tokenizer.pad_token is None:` `tokenizer.add_special_tokens({'pad_token': '[PAD]'})
加载模型,添加回归层。另外一个优化思路,使用时间序列transformer作为模型结构。
# 修改模型为回归任务(输出维度=1)``model = AutoModelForSequenceClassification.from_pretrained(` `model_name,` `num_labels=1, # 回归任务` `problem_type="regression"``).to(device)`` ``# 同步pad_token_id``model.config.pad_token_id = tokenizer.pad_token_id`` ``# 扩展模型词嵌入以适配新 token``model.resize_token_embeddings(len(tokenizer))
创建数据集,训练测试8:2配比。
# 创建数据集并仅转换标签类型``train_dataset = Dataset.from_dict({` `"text": train_sequences,` `"label": train_labels``})``test_dataset = Dataset.from_dict({` `"text": test_sequences,` `"label": test_labels``})`` ``# Tokenization并保持input_ids为Long``def tokenize_function(examples):` `tokenized = tokenizer(` `examples["text"],` `padding="max_length",` `truncation=True,` `max_length=MAX_LENGTH,` `return_tensors="pt"` `)` `return {` `"input_ids": tokenized["input_ids"].squeeze().long(),` `"attention_mask": tokenized["attention_mask"].squeeze().long(),` `"labels": torch.tensor(examples["label"], dtype=torch.float32)` `}`` ``tokenized_train = train_dataset.map(tokenize_function, batched=True, remove_columns=["text"])``tokenized_test = test_dataset.map(tokenize_function, batched=True, remove_columns=["text"])`` ``# 设置数据集格式``tokenized_train.set_format(` `type="torch",` `columns=["input_ids", "attention_mask", "labels"]``)
训练采用lora微调。
# LoRA 配置``lora_config = LoraConfig(` `r=16,` `lora_alpha=32,` `target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # 覆盖全部注意力层` `layers_to_transform=list(range(8,16)), # 微调深层网络` `fan_in_fan_out=True, # 关键参数:改善梯度流` `bias="all",` `task_type="SEQ_CLS"``)`` ``# 应用 LoRA``model = get_peft_model(model, lora_config)``model.print_trainable_parameters() # 应显示少量可训练参数(约0.1%)
设定模型评估指标。
`# 评估指标(适配归一化后的标签)``def compute_metrics(eval_pred):` `predictions, labels = eval_pred` `predictions = np.squeeze(predictions) # 确保形状匹配 (batch_size,)`` ` `# 基础指标` `mae = np.mean(np.abs(predictions - labels))`` ` `# 方向准确率(预测涨跌方向的正确率)` `correct_direction = (predictions * labels) >= 0 # 同号则为正确` `direction_acc = np.mean(correct_direction)`` ` `# 极端值检测(假设标签已归一化到[-0.2, 0.2])` `out_of_safe = np.mean((predictions < -0.2) | (predictions > 0.2))`` ` `return {` `"mae": mae, # 原始MAE(如0.05表示5%误差)` `"mae_percent": mae * 100, # 百分比形式(5.0)` `"direction_accuracy": direction_acc, # 方向正确率(0.7表示70%正确)` `"risk_alert": out_of_safe # 危险预测比例` `}`
设定loss。
# 修改自定义损失函数``class RobustHuberLoss(nn.Module):` `def __init__(self, delta=0.1):` `super().__init__()` `self.delta = delta`` ` `def forward(self, pred, target):` `error = target - pred.squeeze()` `loss = torch.where(` `torch.abs(error) < self.delta,` `0.5 * error**2,` `self.delta * (torch.abs(error) - 0.5 * self.delta)` `)` `return loss.mean()`` ``# 自定义损失函数(无需额外参数)``def custom_loss(logits, labels):` `return RobustHuberLoss(delta=0.05)(logits, labels)`` `` ``# 2. 定义基础数据整理器``data_collator = DataCollatorWithPadding(` `tokenizer=tokenizer,` `padding="max_length",` `max_length=MAX_LENGTH``)`` ``# 3. 自定义设备分配函数``def collate_fn(batch):` `return data_collator(batch) # 不进行设备转移
设定训练超参数。太复杂不解释。抄就完了。重要的几个指标,学习率,轮次,批大小,评估步数。
# 自定义Trainer类``class CustomTrainer(Trainer):` `def compute_loss(self, model, inputs, return_outputs=False, **kwargs):` `labels = inputs.pop("labels")` `outputs = model(**inputs)` `logits = outputs.logits` `loss = custom_loss(logits, labels)` `return (loss, outputs) if return_outputs else loss`` ``# 初始化Trainer时应使用以下参数``trainer = CustomTrainer(` `model=model,` `args=TrainingArguments(` `output_dir="./results",` `per_device_train_batch_size=16,` `gradient_accumulation_steps=2, # 保持等效batch size` `fp16=True,` `max_grad_norm=0.5, # 防止梯度爆炸` `logging_steps=50,` `num_train_epochs=2, # 完成2个epoch` `evaluation_strategy="steps",` `eval_steps=500,` `save_steps=500,` `learning_rate=1e-6,` `lr_scheduler_type="cosine_with_restarts", # 余弦退火` `warmup_steps=100, # 明确预热步数` `warmup_ratio=0.2,` `weight_decay=0.01, # 添加正则化` `fp16_full_eval=False, # 关闭评估混合精度` `remove_unused_columns=False,` `gradient_clipping=0.5, # 严格梯度裁剪` `gradient_checkpointing=True, # 启用梯度检查点` `optim="adamw_bnb_8bit", # 使用量化优化器` `report_to="none"` `),` `train_dataset=tokenized_train,` `eval_dataset=tokenized_test,` `data_collator=collate_fn,` `compute_metrics=compute_metrics``)
可以看到,实际可训练的参数量。

开始训练。
trainer.train()
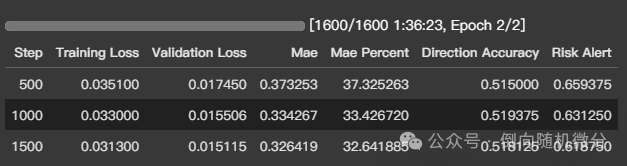
训练跑起来还是挺慢的,两个轮次,一个半小时。Direction Accurancy是方向预测正确性,可以看到,比掷硬币猜涨跌稍好。当然,这只是个玩具模型,教学训练。模型尺寸加大,数据量加大,特征加大,训练轮次加大,难保准确率会有多高,毕竟底层模型具有数学博士级别的知识储备和推理水平,涌现能力不可小觑。
模型评估代码就交给deepseek写吧。
训练完毕保存成果。
# 训练完成后执行``model.save_pretrained(` `"./best_model/",` `safe_serialization=True,` `state_dict=model.state_dict() # 确保保存全部参数``)``tokenizer.save_pretrained("./best_model/")
推理代码。
def predict_tokenize(text):` `"""预测专用预处理(不处理label字段)"""` `tokenized = tokenizer(` `text,` `padding="max_length",` `truncation=True,` `max_length=MAX_LENGTH, # 需与训练时一致` `return_tensors="pt"` `)` `return {` `"input_ids": tokenized["input_ids"],` `"attention_mask": tokenized["attention_mask"]` `}`` ``def predict(price_sequence):` `# 使用专用预处理` `inputs = predict_tokenize(price_sequence)` `# 移动数据到设备` `inputs = {k: v.to(device) for k, v in inputs.items()}` `# 推理模式` `model.eval()` `with torch.no_grad():` `outputs = model(**inputs)` `prediction = outputs.logits.item()` `return np.clip(prediction, -1000, 1000)`` ``# 生成测试输入(注意:必须是字符串格式,包含30个价格)``data = pd.read_csv("上证1小时0126.csv")``ps = df["close"].values``test_prices = ps[-2000:]``input_str = ",".join([f"{x:.4f}" for x in test_prices])`` ``# 执行预测``score = predict(input_str)``print(f"预测分数: {score:.2f}")
为了后面推理方面,要把lora参数合并到原模型中。
# 先加载与微调一致的tokenizer``tokenizer = AutoTokenizer.from_pretrained(` `"./best_model/",` `pad_token="[PAD]",` `padding_side="right",` `trust_remote_code=True``)`` ``# 加载基础模型时同步调整词表``base_model = AutoModelForSequenceClassification.from_pretrained(` `"./deepseek-qwen-1.5b/",` `num_labels=1, # 必须与微调设置一致` `problem_type="regression",` `trust_remote_code=True``)``base_model.resize_token_embeddings(len(tokenizer)) # 关键:先调整词表``
# 加载适配器并合并``model = PeftModel.from_pretrained(base_model, "./best_model/")``merged_model = model.merge_and_unload()`` ``# 验证词表一致性``print(f"当前词表大小: {len(tokenizer)}")``print(f"模型词嵌入维度: {merged_model.get_input_embeddings().weight.shape[0]}")``assert merged_model.get_input_embeddings().weight.shape[0] == len(tokenizer)``
# 手动修正分类层维度``with torch.no_grad():` `merged_model.score.weight = torch.nn.Parameter(` `torch.randn(1, merged_model.config.hidden_size) # 回归任务输出维度为1` `)`` ``# 更新模型配置``merged_model.config.num_labels = 1``merged_model.config.problem_type = "regression"``
merged_model.save_pretrained(` `"./deploy_model",` `safe_serialization=True,` `state_dict=merged_model.state_dict()``)`` ``tokenizer.save_pretrained("./deploy_model")``
合并完毕,deploy_model中就是我们的最终模型,后面可以直接加载用于推理啦。
收工。
祝大家新年快乐!!!
完整训练代码如下:
import pandas as pd``import numpy as np``from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer, DataCollatorWithPadding``import torch``import torch.nn as nn``from datasets import Dataset``from peft import LoraConfig, get_peft_model``from sklearn.model_selection import train_test_split`` ``MAX_LENGTH = 5000`` ``def generate_sequences(prices, window_size):` `sequences = []` `labels = []` `for i in range(len(prices) - window_size - 1):` `window = prices[i:i + window_size]` `next_price = prices[i + window_size]` `last_price = window[-1]` `score = (next_price - last_price) / last_price # 相对变化率` `# 将价格序列转换为文本(示例:"1.2,3.4,5.6,...")` `sequence_text = ",".join([f"{x:.4f}" for x in window])` `sequences.append(sequence_text)` `labels.append(float(score))` `return sequences, labels`` ``# 使用示例``df = pd.read_csv("上证1小时0126.csv")``prices = df["close"].values``sequences, labels = generate_sequences(prices, window_size=2000)`` ``# 按时间顺序分割(避免未来数据泄漏)``train_sequences, test_sequences, train_labels, test_labels = train_test_split(` `sequences, labels, test_size=0.2, shuffle=False``)`` `` ``model_name = "./deepseek-qwen-1.5b/"``tokenizer = AutoTokenizer.from_pretrained(` `model_name,` `pad_token="[PAD]", # 显式定义填充标记` `padding_side="right" # 对齐填充方向``)`` ``# 检查 tokenizer 是否已有 pad_token``if tokenizer.pad_token is None:` `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`` ``# 明确指定设备``device = torch.device("cuda" if torch.cuda.is_available() else "cpu")``# 修改模型为回归任务(输出维度=1)``model = AutoModelForSequenceClassification.from_pretrained(` `model_name,` `num_labels=1, # 回归任务` `problem_type="regression"``).to(device)`` ``# 同步pad_token_id``model.config.pad_token_id = tokenizer.pad_token_id`` ``# 扩展模型词嵌入以适配新 token``model.resize_token_embeddings(len(tokenizer))`` ``# 创建数据集并仅转换标签类型``train_dataset = Dataset.from_dict({` `"text": train_sequences,` `"label": train_labels``})``test_dataset = Dataset.from_dict({` `"text": test_sequences,` `"label": test_labels``})`` ``# Tokenization并保持input_ids为Long``def tokenize_function(examples):` `tokenized = tokenizer(` `examples["text"],` `padding="max_length",` `truncation=True,` `max_length=MAX_LENGTH,` `return_tensors="pt"` `)` `return {` `"input_ids": tokenized["input_ids"].squeeze().long(),` `"attention_mask": tokenized["attention_mask"].squeeze().long(),` `"labels": torch.tensor(examples["label"], dtype=torch.float32)` `}`` ``tokenized_train = train_dataset.map(tokenize_function, batched=True, remove_columns=["text"])``tokenized_test = test_dataset.map(tokenize_function, batched=True, remove_columns=["text"])`` ``# 设置数据集格式``tokenized_train.set_format(` `type="torch",` `columns=["input_ids", "attention_mask", "labels"]``)`` `` `` ``# LoRA 配置``lora_config = LoraConfig(` `r=16,` `lora_alpha=32,` `target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], # 覆盖全部注意力层` `layers_to_transform=list(range(8,16)), # 微调深层网络` `fan_in_fan_out=True, # 关键参数:改善梯度流` `bias="all",` `task_type="SEQ_CLS"``)`` ``# 应用 LoRA``model = get_peft_model(model, lora_config)``model.print_trainable_parameters() # 应显示少量可训练参数(约0.1%)`` `` ``# 评估指标(适配归一化后的标签)``def compute_metrics(eval_pred):` `predictions, labels = eval_pred` `predictions = np.squeeze(predictions) # 确保形状匹配 (batch_size,)`` ` `# 基础指标` `mae = np.mean(np.abs(predictions - labels))`` ` `# 方向准确率(预测涨跌方向的正确率)` `correct_direction = (predictions * labels) >= 0 # 同号则为正确` `direction_acc = np.mean(correct_direction)`` ` `# 极端值检测(假设标签已归一化到[-0.2, 0.2])` `out_of_safe = np.mean((predictions < -0.2) | (predictions > 0.2))`` ` `return {` `"mae": mae, # 原始MAE(如0.05表示5%误差)` `"mae_percent": mae * 100, # 百分比形式(5.0)` `"direction_accuracy": direction_acc, # 方向正确率(0.7表示70%正确)` `"risk_alert": out_of_safe # 危险预测比例` `}`` ``# 修改自定义损失函数``class RobustHuberLoss(nn.Module):` `def __init__(self, delta=0.1):` `super().__init__()` `self.delta = delta`` ` `def forward(self, pred, target):` `error = target - pred.squeeze()` `loss = torch.where(` `torch.abs(error) < self.delta,` `0.5 * error**2,` `self.delta * (torch.abs(error) - 0.5 * self.delta)` `)` `return loss.mean()`` ``# 自定义损失函数(无需额外参数)``def custom_loss(logits, labels):` `return RobustHuberLoss(delta=0.05)(logits, labels)`` `` ``# 2. 定义基础数据整理器``data_collator = DataCollatorWithPadding(` `tokenizer=tokenizer,` `padding="max_length",` `max_length=MAX_LENGTH``)`` ``# 3. 自定义设备分配函数``def collate_fn(batch):` `return data_collator(batch) # 不进行设备转移`` `` ``# 自定义Trainer类``class CustomTrainer(Trainer):` `def compute_loss(self, model, inputs, return_outputs=False, **kwargs):` `labels = inputs.pop("labels")` `outputs = model(**inputs)` `logits = outputs.logits` `loss = custom_loss(logits, labels)` `return (loss, outputs) if return_outputs else loss`` ``# 初始化Trainer时应使用以下参数``trainer = CustomTrainer(` `model=model,` `args=TrainingArguments(` `output_dir="./results",` `per_device_train_batch_size=16,` `gradient_accumulation_steps=2, # 保持等效batch size` `fp16=True,` `max_grad_norm=0.5, # 防止梯度爆炸` `logging_steps=50,` `num_train_epochs=2, # 完成2个epoch` `evaluation_strategy="steps",` `eval_steps=500,` `save_steps=500,` `learning_rate=1e-6,` `lr_scheduler_type="cosine_with_restarts", # 余弦退火` `warmup_steps=100, # 明确预热步数` `warmup_ratio=0.2,` `weight_decay=0.01, # 添加正则化` `fp16_full_eval=False, # 关闭评估混合精度` `remove_unused_columns=False,` `gradient_clipping=0.5, # 严格梯度裁剪` `gradient_checkpointing=True, # 启用梯度检查点` `optim="adamw_bnb_8bit", # 使用量化优化器` `report_to="none"` `),` `train_dataset=tokenized_train,` `eval_dataset=tokenized_test,` `data_collator=collate_fn,` `compute_metrics=compute_metrics``)
还等什么,快训练自己的大模型吧。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









