






这是一篇探究预训练模型是否真的理解否定的文章。
靠着new bing略读了一遍,感觉挺有意思的,记录一下。
1 摘要
In linguistics, there are two main perspectives on negation: a semantic and a pragmatic view. So far, research in NLP on negation has almost exclusively adhered to the semantic view. In this article, we adopt the pragmatic paradigm to conduct a study of negation understanding focusing on transformer-based PLMs. Our results differ from previous, semantics-based studies and therefore help to contribute a more comprehensive – and, given the results, much more optimistic – picture of the PLMs’ negation understanding.
在语言学中,否定观主要有两种观点:语义观和语用观。迄今为止,NLP对否定的研究几乎完全遵循语义观。在本文中,我们采用语用学研究范式,以基于Transformer的PLMs为研究对象,对否定理解进行研究。我们的结果不同于以往基于语义学的研究,因此有助于对PLMs的否定理解做出更全面- -以及更乐观的描述。
2 问题&动机
预训练模型通过大量的语料进行训练,我们认为它学习了其中某些知识。(文中特别探究的是“否定”,但其实其它知识也可以按这个思路探究一下。)
这就带来了一个问题,预训练模型在处理任务时,是真的理解了文本的上下文,然后做出预测,还是通过预训练得到的知识进行推理?
文中有个例子:
(1) Birds cannot fly.
(2) Birds can fly.
如果预训练一直学的是(2) Birds can fly. 那么当给你的上下文是(1) Birds cannot fly. 时,你这个模型能不能理解?
于是,作者设计了实验,看一下预训练模型们是不是真的都理解否定。
3 设计数据集
定制一些列模板,比如:
(3) FNAME{Petra} is PROF{an architect} who doesn’t like to ACT{sail}.
However, she does like to MASK.
意思是: xxx是xxx,他不喜欢xxx。然而,她喜欢< mask >. 其中几个xxx是作者随机填充的人名、职业、动作。接下来就用模板生成一系列句子。
比如,要测试roberta,
1、先确定人名和职业,这里假设是Jessica和printer。于是生成一个句子(5) Jessica is a printer and she likes to [MASK].
2、扔进roberta,预测一下mask是哪个单词。得到N个预测mask的概率,假设draw这个词概率最高。好了现在我们知道了,在这个语境下,roberta预测概率最高的就是draw。
3、把draw丢进模板(4)得到句子(6) Jessica is a printer who doesn’t like to draw. However, Jessica does like to [MASK].
4、句子(6)丢进roberta,如果它能正确处理否定,就不会输出draw。输出draw,就说明不能正确处理否定。
测试的原理很简单,上下文中说了jessica不喜欢draw了,你还tm说jessica喜欢draw的话,那就是你这个模型完全不懂“否定”是个啥。
总之,作者搞了43个这样的模板,生成了几十万条数据进行了实验。

4 实验
把43个模板分为3类,设计了三个实验。
1、测试一下是否能理解否定

2、作者蔫坏的在上下文里加点噪声,错误引导,看你是不是能理解否定

3、第三个实验致力于评估模型是否对指称对象的变化敏感。就是第一句和第二句说的不是同一个对象。

5 结果
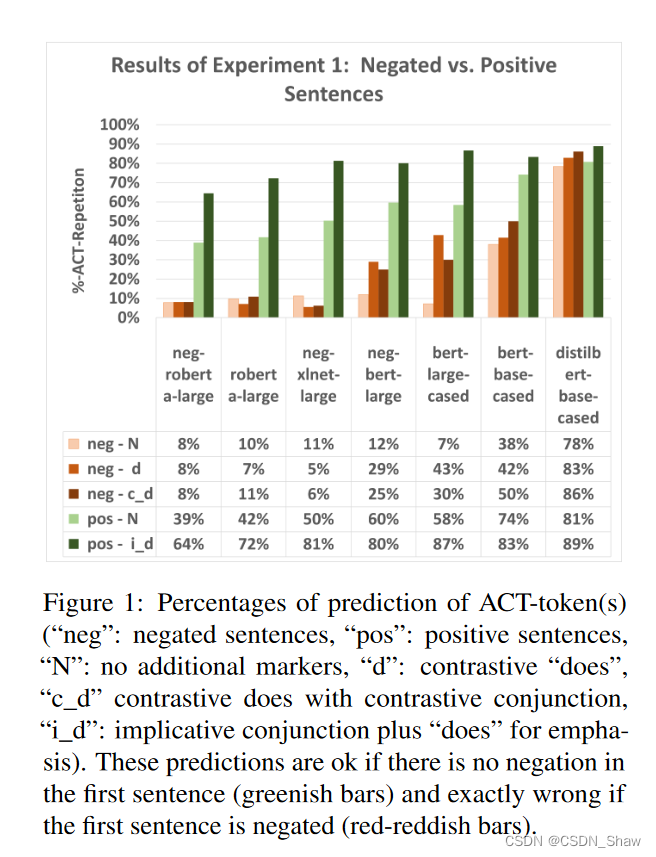
评价指标是重复率,就是第二句< MASK >和第一句ACT的重复百分比。
实验一
用到的模板可以分为两类:
第一句是否定的:marry is a doctor, she doesn’t like draw. she likes < mask >.
第一句是肯定的:marry is a doctor who tries to draw as often as possible. she likes < mask >.
如果第一句是肯定句,那重复率自然越高越好。(图1 绿色系的那些)
如果是否定句,那重复率越高说明模型越差,对于否定的理解越弱。(图1 红色系的那些)
文中提到了红和绿的差值,代表了对否定的敏感程度。
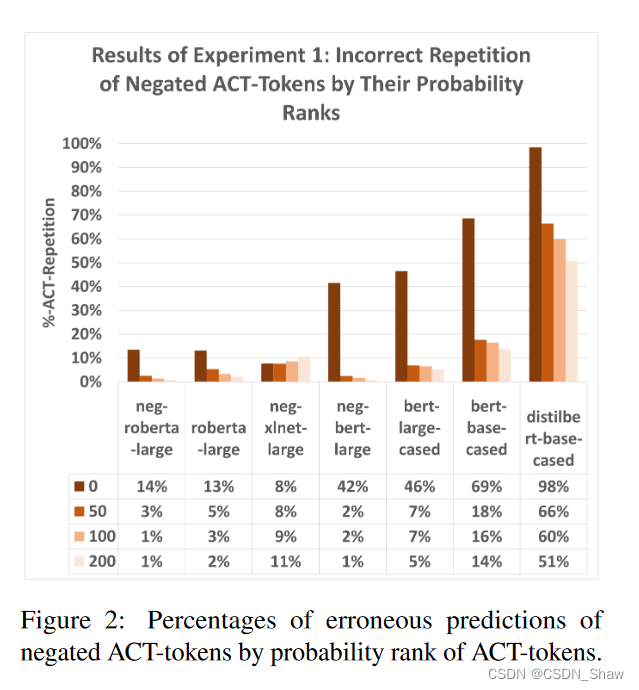
看一下图2,图2要理解很简单啊,那个0 50 100 200,指的是预测mask时的rank。比如:
roberta预测这个句子(5) Jessica is a printer and she likes to [MASK].
mask的可选值有:draw (prob. 0.21), write (prob. 0.16), and travel (prob. 0.15) 等等,之前举例子都是直接取概率最高的那个单词draw,现在放宽条件了,取第50 100 200个单词填到模板中的ACT中。
可以看到,确实是随着概率降低,重复率也降低了。符合我们的直觉。
实验二和三就不讲了。建议大家看看原文。
6 结论
文中讲了4点启示,简单说来:
1、除了distilbert-base-cased,所有模型都显示出对否定的敏感性。
2、预测mask的单词rank,取第几个影响很大。
3、neg-roberta-large不怎么受错误引导,表现最好。其它的都影响较大。
4、对指称对象敏感。
下面是new bing的总结,肥肠抽象……
明确对否定的敏感性
实验一的第一个基本见解是非常积极的:除了distilbert-base-cased,所有模型都显示出对否定的敏感性(参见图1):即使ACT标记具有很高的概率,考虑到模型、性别、名字和职业,即使与正面(未否定)模板相比,子序列重叠要小得多,它们也不太倾向于ACT重复,如果标记已被否定。因此,几乎所有模型都显示出对否定的敏感性,尽管几种浅层启发式对其产生了相反的拉力。另请注意,模型通常不过分敏感于否定句子中的对比突出元素,但非常敏感于正面句子中的蕴涵指示元素,这在考虑诸如(8)之类的例子时似乎在语用上是合理的:在没有这样一个元素的情况下,人们可能会认为这些模板中的第一个和第二个句子除了共同的指称对象外几乎没有任何联系。此外,请注意BERT模型在包含对比突出元素的模式中表现明显较差。这令人惊讶,因为人们会期望这样的元素会使模型更容易意识到预测ACT标记替换MASK是不准确的。
这些结果将Ettinger(2020)、Kassner和Schütze(2020)、Warstadt等人(2020)和Ribeiro等人(2020)的开创性发现置于透视之中:我们的研究清楚地表明,预先训练的基于变压器的语言模型确实显示出对否定的敏感性。在图1中,neg-roberta-large重复替换ACT占位符的动词的倾向在某些情况下下降了约44%,如果这些替换位于否定范围内。显然,这个模型并不简单地忽略否定。这种与早期研究结果之间的差异有两种解释。第一个解释仅仅是提醒这些早期研究并未测试基于RoBERTa或XLNET架构的模型。此外,Ribeiro等人(2020)仅使用了他们测试的模型的基础大小。尽管如此,即使是bert-large-cased和bert-base-cased,以前的发现与我们的结果之间也存在鲜明差异。这意味着需要第二种解释。我们认为最好的候选解释正是我们假设,在这些早期研究中,模型并不是在与否定作斗争,而是在与任务上下文化作斗争:它们并不能表示否定;相反,它们无法确定排除某些预测ab initio
的默认上下文。推理到最佳解释总是容易出错(有关演绎推理的标准研究,请参见Lipton 2004):我们可能没有考虑到另一种解释,它解释了性能差异。然而,鉴于我们使用高度控制、合成和相对简单的句子,我们广泛改变了句法结构、性别、职业和名字,并测试了许多错误提示,所有这些都导致了相同的基本结果,即对否定的敏感性,我们有信心排除其他解释,只要这在当前BERTology方法下是可能的。因此,我们确实将我们的结果视为对我们主要假设的有力支持。
概率等级的影响
此外,实验一还表明,模型和上下文特定的概率等级(在本实验中通过一种新方法控制)对预测具有高度相关性(参见图2)。这种效应对于BERT模型尤为明显,而对于RoBERTas和XLNET则要小得多。概率等级影响的另一个有趣方面是微调似乎减少了高概率令牌的错误率。最后,数字还显示错误率在概率等级0和50之间大幅下降。在50和200之间,几乎没有进一步减少。
对错误提示和随机插入的稳健性
在实验2中,我们测试了模型对插入两种不同错误提示以及一个随机句子的稳健性。有关结果,请参见图3。这些结果显示出非常细致的画面。首先,neg-roberta-large几乎不受错误提示的干扰,除了随机句子:其错误率不超过12%。与之形成鲜明对比的是,neg-xlnet-large的错误率随着所有错误提示插入而飙升:它将错误率从8%提高到43%,甚至更高。其他模型介于两者之间;值得注意的是,BERT模型最多与随机句子挣扎。由于对错误提示的稳健性表明依赖于真正理解而非浅层启发式,这些结果进一步证实了实验1中最佳表现模型(特别是neg-roberta-large)理解否定。
指称对象变化
当考虑RoBERTas和微调后的XLNET时,这项实验的结果令人惊讶。所有三个模型都以超过85%的概率重复ACT标记,如果很清楚第一个句子中不喜欢ACT的人与第二个句子中喜欢MASK的人明显不同。这些结果表明模型显然对这种指称对象变化敏感。
PS1:叠个甲,如果我讲的有问题,可以在评论区讲一下,探讨一下。
PS2:我真的很爱这个作者,他举了好多例子,方便理解了很多……















 2830
2830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









