







图一**本文内容仅代表个人理解,如有错误,欢迎指正**
1. Problem
本文提出的立足点:主要物体间的相关关系对于框选目标物体而言是十分重要的,而当前一阶段的视觉定位方法对于物体之间的关系模拟比较薄弱,使得模型不能够较好地学到物体之间的相关关系,从而导致模型表现的差强人意。
Q: 那为什么说一阶段的视觉定位方法对于物体之间的关系模拟比较薄弱呢?
A: 如果要对物体之间的关系进行模拟、学习,首先需要有物体。而一阶段的视觉定位方法(相比于两阶段的视觉定位方法)没有利用pre-trained detectors(like Faster R-CNN),意味着一阶段的方法就没有包含了Images中objects的候选框(Proposals),因此就很难在候选框的基础上进行物体间相关关系的modeling。
Q: 为什么说主要物体间的相关关系对于框选目标物体而言是十分重要的?那是不是意味着并不是所有物体间的相关关系都是重要的?
A: 是的。一张图像中可能存在很多Objects,但并非所有Objects之间的关系都是重要的。举个例子,在图一中存在许多Objects,有人物、兰桂坊的牌子、灯牌等等。那么是不是所有物体之间的关系都对我们框选目标有帮助?不是。只有“可能”与我们的Query相关的物体间关系的模拟才能够帮助模型准确框选出目标。那这“可能与Query相关的物体”也被本论文称为“Suspected Objects”,即潜在对象(嫌疑物体/狗头)。

图一
2. Points
论文的创新点如下:
1. 在一阶段视觉定位的框架下探索物体间的相关关系,提出Suspected Object Graph,利用图结构着重学习“Suspected Objects”之间的相关关系,辅助模型进行目标框选。
2. 提出Keyword-aware Node Representation(KNR)和Exploration by Random Connection(ERC)。
3.Main Components
- 此论文主要可以分为三个部分(如图二所示): 1. Multi-modal Encoder 2. Suspected Object Graph 3. Prediction

图二
3.1 Multi-modal Encoder
**** 先给结论,这一块主要是为了得到不同尺度下的Multi-modal features M,并将其作为下一部分SOG的输入。
Multi-modal Encoder的输入有两个,1. Image 2. Query。
1. 利用Darknet-53提取image特征,能够得到三个尺度下的特征图,并分别给每一个特征图拼接一个Coordinate map(因为Darknet53对位置信息不敏感),得到position-aware的visual features X。
2. 利用LSTM或者BERT提取Query的特征,得到sentence representation和word representation。
3. 对position-aware visual features X和sentence represnetation进行FiLM操作,得到Multi-modal features M。(简单来说,就是对不同模态下的特征进行一个融合)
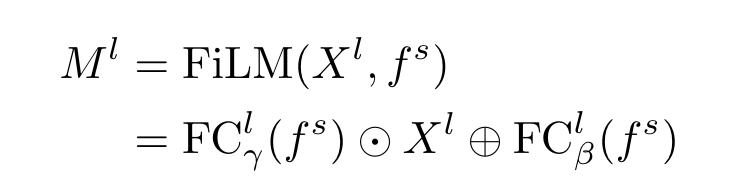
3.2 Suspected Object Graph(SOG)
"SOG is responsible for selecting the suspected objects and updating their feature representations, so as to facilitate the model to rethink and gradually correct its selection." - 简单来说,就是SOG主要负责选出Suspected objects,并且不断更新它们的特征表示,
- 这一部分的内容又可以分为四个模块,分别是 1. Suspected Regions Discovery 2. Keyword-aware Node Representation 3. Exploration by Random Connection 4. Message Passing
3.2.1 Suspected Region Discovery
- 在这一阶段,主要是要找出“Suspected Object”可能存在的位置。
在Multi-modal Encoder中得到的Multi-modal features M显示了每个网格与text query的相关性,为了更方便地利用这一信息(也为了计算方便),该论文利用一个卷积层对multi-modal features M进行dimension reduction得到一个低维的textual activation map C。
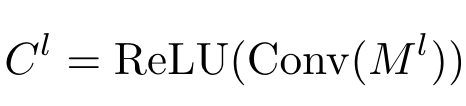
然后,为了能够在不同尺度发现suspected objects,所以将不同尺度的M和C分别进行average operation,得到averaged M和C。(我不理解,我迷惑,感觉不是非常合理诶)

最后,依据averaged C上的相关性在averaged M上找到相对应的部分作为suspected regions(选择K个grid),C上的相关性记作 ,M上的suspected regions的特征记作
。
3.2.2 Keyword-aware Node Representation

- 简单来说,suspected objects往往是比较相似的(或者说可能是属于同一类的?),所以我们需要更多有针对性的信息来辅助甄别目标。
因此,该论文提出一个cross-modal attention module来学习query中每个词的重要性,并利用word representation(weighted by the importance scores)来对suspected regions 进行调整。
- 值得注意的是,在学习query中每个词的重要性时,作者并没有直接将suspected regions的grid feature与word feature进行操作,而是利用空洞卷积(DC)放大感受野,将suspected regions附近的特征作为上下文特征一同进行考虑,得到context-aware suspected region features 。然后将所有对suspected regions计算得到的context-aware suspected region features取平均,再与每一个word representation计算得到每一个词的重要程度
。
![]()
然后,依据每个词的重要程度,计算得到一个keyword-aware textual representation 。再将
与
进行FiLM操作,并将不同扩张率下得到的结果累计在一起作为最终的suspected object feature
,
将作为SOG中的节点。

3.2.3 Exploration by Random Connection
- 简单来说,这一部分主要是为了生成SOG中的边(代表节点之间的相关性)。 边是由节点(suspected regions)的激活分数之间做element-wise multiplication得来的。举个例子,连接节点i与节点j的边,由节点i的激活分数与节点j的激活分数做element-wise multiplication得来。
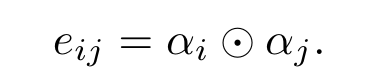
上述边的构成方式使得两个激活分数高的节点之间的相关性会比较高,从而使得这条边在信息传输过程中对后期框选目标物体产生的影响就会比较大。但,如果一开始认定的、有高激活分数的物体实质上是错误的,那模型有很大概率不停地进行错误选择。
因此,受BERT的启发,在计算边的时候以百分之五十的概率替换掉某一节点的激活分数,从而结偶边与节点之间的相关性。这种做法在一定程度上能够平衡两种情况,1. 模型的初始选择 2. 错误累积
3.2.4 Message Passing
- 利用图卷积来更新上述两小节所生成的图的节点表示。
然后类似于做了个跳跃连接(Skip connection),将Multi-modal features M与图卷积更新后的特征相拼接输入grounding module进行目标预测。
3.3 Grounding Module
* 比较常规,不提了。
4. Experimental Results
**这篇论文的实验说明比较简单,不多说了。
4.1 Comparison with the state-of-the-art Methods

4.2 Ablation Study

4.3 Visualization
















 4763
4763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









