









线上环境
JDK1.8 使用默认垃圾收集器:ParallelGC
服务器内存32G(部署了多台服务)
线上启动JVM时,未添加任何参数配置。
所以默认配置为:
Non-default VM flags: -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=null -XX:InitialHeapSize=526385152 -XX:MaxHeapSize=8392802304 -XX:MaxNewSize=2797600768 -XX:MinHeapDeltaBytes=524288 -XX:NewSize=1572864 -XX:OldSize=524812288 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC

初始化内存大小:500M(1/64),最大内存:8G(1/4)。
问题现象
服务器运行一段时间后,可以看出FGC次数频繁且耗时长,104次FGC,耗时达到258秒,平均每次FGC持续时间2秒多。
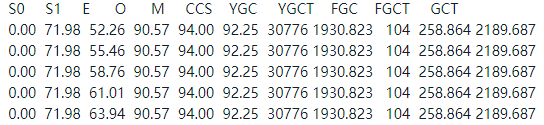
当前内存使用情况
Eden区2G多,老年代5G多,内存被大量消耗,实际上根本不需要如此大的内存,老年代中存在大量的朝生夕死的对象。

内存消耗大
正是因为ParallelGC的自动调节,造成了内存不足的假象,再加上没有控制堆的最大值,导致老年代的内存被无限放大到8G,严重浪费了服务器的内存资源。
目前线上运行状态已经清楚了,分析一下问题吧!
1、首先是关于JVM启动参数问题
JVM启动时,有一些参数是必须要配置的,不然出了问题很难定位
日志类:
从GC日志中,可以看出每次GC前后的内存大小对比,从而帮助分析内存大小设置的合理性,以及是否有内存泄露等问题存在。
-XX:+PrintGCDetails(输出GC的详细日志)
-XX:+PrintGCDateStamps(输出GC的时间戳)
-Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t.log(日志文件的输出路径)
OOM后生成快照:
产生OOM后,需要通过堆的快照分析具体导致OOM的原因。
-XX:+HeapDumpOnOutOfMemoryError (OOM时生成Dump文件)
-XX:HeapDumpPath=/memory.hprof(OOM文件生成地址)
JVM堆内存参数:
合理的堆内存配置,可以帮助减少FGC的次数和时长。
-Xmn(新生代大小)
-Xms (初始分配内存,默认为物理内存的1/64)
-Xmx (最大分配内存大小,默认为物理内存的1/4)
-XX:SurvivorRatio(Eden区和Survivor区比例,默认8:1:1)
默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制。
因此服务器一般设置-Xms、-Xmx相等以避免在每次GC后调整堆的大小。调大导致FGC时间变长,调小又会导致FGC频繁。
2、ParallelGC垃圾收集器问题
现在大多数生产环境中都用的是JDK8,并且使用默认的垃圾收集器ParallelGC。
使用ParallelGC要特别注意AdaptiveSizePolicy参数的问题,还是上面那张图,看看Eden和Survivor区的分配占比,明显不是8:1:1了,这就是因为AdaptiveSizePolicy动态调整的原因。
AdaptiveSizePolicy 有三个目标:
-
Pause goal:应用达到预期的 GC 暂停时间。
-
Throughput goal:应用达到预期的吞吐量,即应用正常运行时间 / (正常运行时间 + GC 耗时)。
-
Minimum footprint:尽可能小的内存占用量。
AdaptiveSizePolicy 为了达到三个预期目标,涉及以下操作:
-
如果 GC 停顿时间超过了预期值,会减小内存大小。理论上,减小内存,可以减少垃圾标记等操作的耗时,以此达到预期停顿时间。
-
如果应用吞吐量小于预期,会增加内存大小。理论上,增大内存,可以降低 GC 的频率,以此达到预期吞吐量。
-
如果应用达到了前两个目标,则尝试减小内存,以减少内存消耗。
所以为了达到期望的目标,Survivor区被调整的很小,导致新生代的对象被大量的移到了老年代了。
又由于每次FGC后老年代空间被动态调整的问题,导致老年代空间越来越大,同时也就意味着一次FGC的时间将会变得越来越长。
解决问题
问题已经分析出来了,那么应该如何解决呢?
-
-XX:SurvivorRatio,指定比例Eden区和Survivor的比例,不要让AdaptiveSizePolicy动态调整。
-
合理控制老年代大小,对于ParallelGC这样的垃圾收集器,老年代空间越大,一次FGC的停顿时间就越长。
-
控制新生代大小,新生代一般可以适当调大一些,让那些朝生夕死的对象能够全部在新生代被回收。
堆内存到底设置多大合适?这个一般要根据线上的实际使用情况来决定,其实如果不存在内存泄露问题,则只需从每次gc的后存活对象的大小,就能大致估算出实际所需要的内存空间(GC日志的重要性)。
比如下面这个,是刚刚经历过一次FGC的服务(频率大概半小时一次),新生代使用159M,老年代使用78M,所以很明显,根据FGC的频率和回收完之后的内存使用大小,可以看出这个项目根本用不到多少内存,为了用来应对系统峰值时的业务量激增导致产生的对象也激增的场景,再做一些适当的冗余,所以新生代500M,老年代1G足矣。

垃圾收集器之所以要分代就是为了能够快速的把一些朝生夕死的对象给处理掉,如果Survivor小到形容虚设,就失去了分代收集的意义,因为每次Eden区的对象只要能熬过一次YGC就会被放到老年代(Survivor区太小不够放),实际上可能在第二次YGC时就可以回收了,对于ParallelGC这样的垃圾收集器,对象一旦进入老年代就只能等待内存100%后触发FGC才会被回收了。
JVM调优的目标之一就是要减少FGC的次数。
最简单的解决方式
其实处理这类问题,需要你对JVM垃圾回收方面有一定的了解,并且随着业务的发展可能需要持续的观察并调整堆空间的大小分配,所以最简单的方式就是直接换G1即可。

















 3230
3230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











