







 本文探讨了在SQL join查询中,为何推荐使用小表作为驱动表,通过执行计划分析和时间复杂度解释,揭示了小表驱动带来的效率优势。通过数据准备和实际案例,展示了如何优化查询性能并避免全表扫描。
本文探讨了在SQL join查询中,为何推荐使用小表作为驱动表,通过执行计划分析和时间复杂度解释,揭示了小表驱动带来的效率优势。通过数据准备和实际案例,展示了如何优化查询性能并避免全表扫描。
前言
我相信你一定听说过在做两张表join查询时,要让小表作为驱动表,如果你不知道这是为什么,那么本文就通过分析join的执行过程,来回答这个问题。
一、数据准备
新建了两张表,分别为t1,t2。
t1表结构

t2表结构

其中t1表1W条数据,t2表10W条。t1表中的1W条数据与t2是相同的。
二、join查询
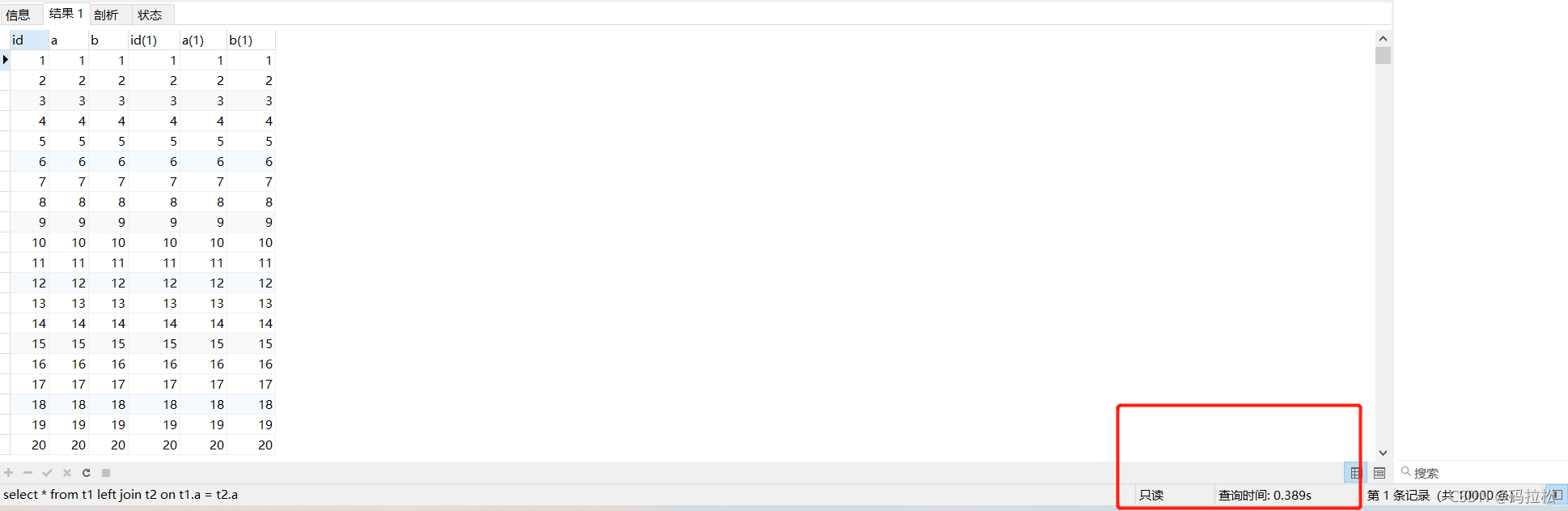
使用小表作为驱动表
select * from t1 left join t2 on t1.a = t2.a;
使用大表作为驱动表
select * from t2 left join t1 on t1.a = t2.a;

通过执行计划分析
小表驱动
EXPLAIN select * from t1 left join t2 on t1.a = t2.a;

大表驱动
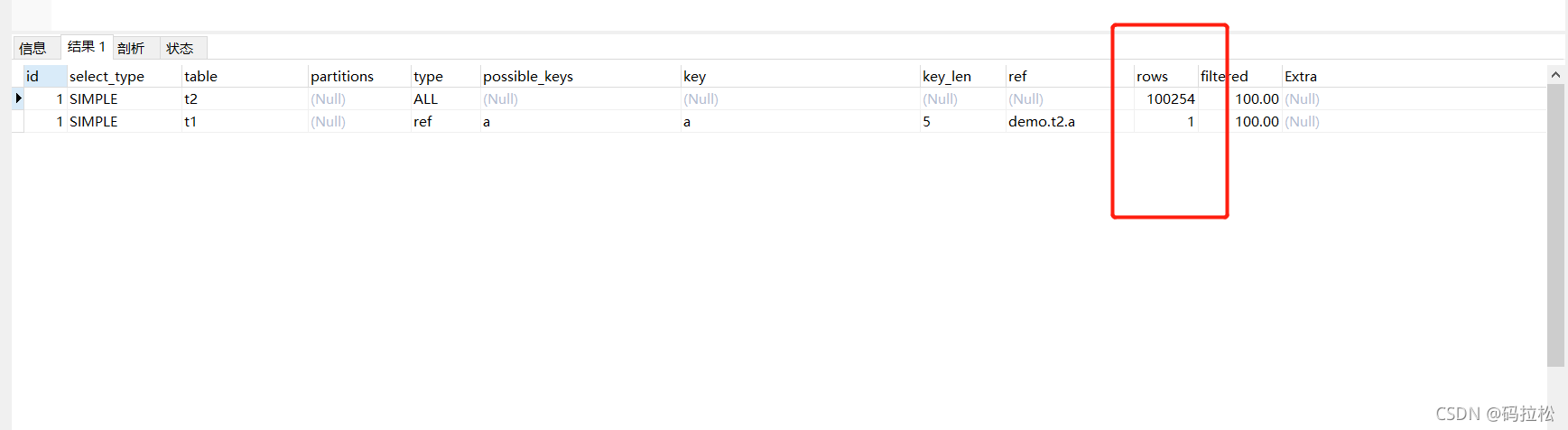
当大表作为驱动表时,查询时间大约比小表作为驱动表时慢了一倍,从执行计划也能分析出,谁是驱动表谁就会进行全表扫描,所以这也是为什么要让小表作为驱动表的原因。
三、join流程分析
从下面这个执行计划中我们可以看出,join的执行流程应该如下:
1、先从t2表中取出一行数据,然后拿到a这个字段
2、用a这个字段与t1表进行匹配,类似如下sql:select * from t1 where t1.a = ?(?就是第一步中从t2里取到的字段a的值)
3、由于t1表的a字段时有索引的,所以可以走索引扫描,如果匹配的上就把结果记录下来
4、继续重复1~3流程,执行扫描完所有t2表中的数据。
四、通过时间复杂度解释为什么要让小表作为驱动表
分析完join流程后,我们可以得到,整个过程的时间复杂度应该是t2表的行数(M)+ t1表走索引的时间复杂度(logN)
所以大致的时间复杂度应该是:M * logN,可以看出M对于整个时间复杂度的影响更大,因此应该尽量让小表作为驱动表。
以上结论是建立在被驱动表可以使用索引的前提下,如果被驱动表不能使用索引,那就会发生Using join buffer (Block Nested Loop),关于这个问题,在之后的文章中我们可以再进行分析。


















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











