







文章目录
- 基础篇
- 提升篇
- 五、常见问题分析
- 六、Kafka为什么能那么快
- 七、生产上使用kafka的一些建议
- 使用原则建议
- 参数建议
- batch.size、linger.ms
- buffer.memory、max.block.ms
- retries、retry.backoff.ms
- acks
- max.poll.records、max.poll.interval.ms
- max.partition.fetch.bytes、fetch.max.bytes、fetch.min.bytes、fetch.max.wait.ms、message.max.bytes
- session.timeout.ms、heartbeat.interval.ms
- enable.auto.commit、auto.commit.interval.ms
- unclean.leader.election.enable、replica.lag.time.max.ms
- num.io.threads、num.network.threads
- auto.offset.reset
- 八、与springboot整合
基础篇
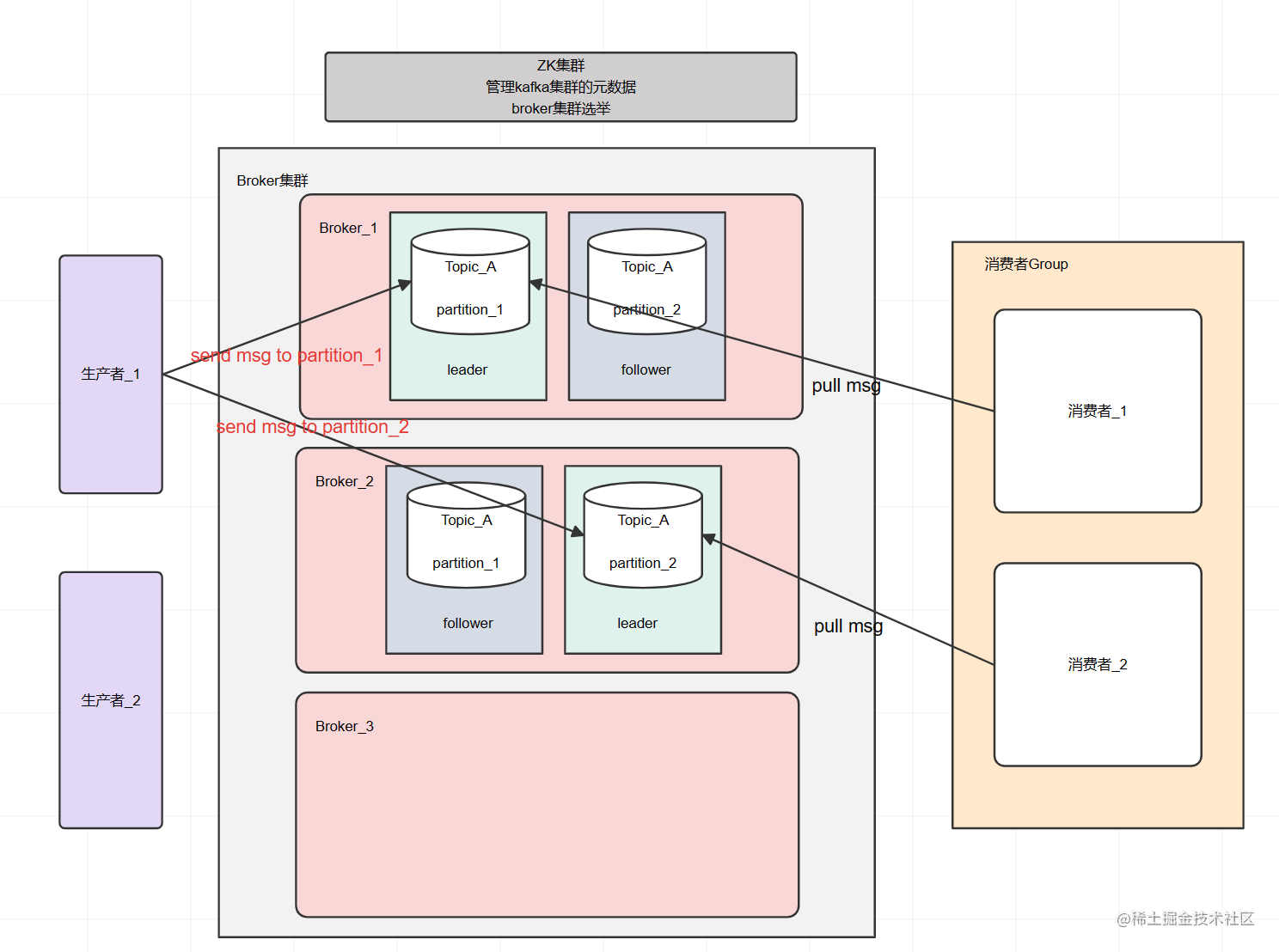
一、概念、名词扫盲
1. 服务节点(broker)
一般提到broker就可以理解为kafka的服务端,多个broker就组成了kafka的集群,broker主要负责消息的接收和处理客户端发来的消息
2. 主题(Topic)
为了方便理解,我用数据库来比较,主题的概念就好像数据表一样,通常可以用来作为一类业务的区分,或者用来定义某种事件也行,比如订单相关的用一个主题,财务相关的用另一个主题,这是按业务划分,比如产生订单交易的事件用一个主题,发生充值行为用一个主题,用户注册用一个主题,这是按事件划分,至于如何选择,这完全取决于你的实际业务场景,我们只要搞清楚利弊关系即可,没有非白即黑的说法。
按业务划分
弊端:很明显当某个业务复杂时,一个Topic必然会成为性能瓶颈,维护起来也麻烦,业务拆分还得考虑Topic,并且资源竞争、互相影响等问题也会变的越来越严重,无法做到良好的隔离性。
优点:当业务不复杂时,按业务划分自然最简单,省事,topic越少也越好运维。
按事件划分
弊端:当业务简单时,有点简单问题复杂化的感觉。
优点:资源独立,易维护、扩展,拥有良好的隔离性。
3. 分区(partition)
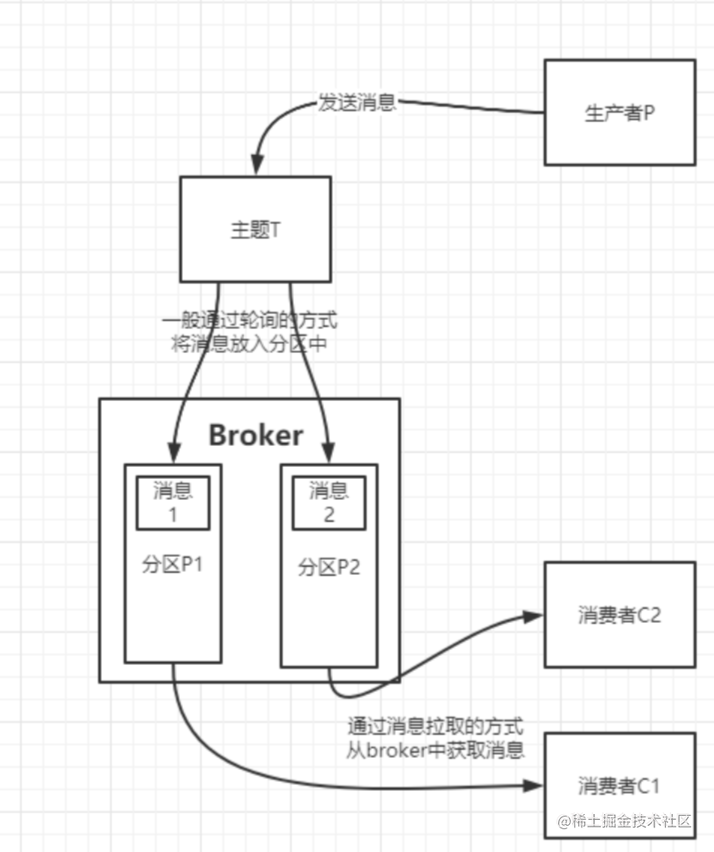
分区是依赖主题存在的,不同主题下的分区互相独立,如果把主题比作数据表,分区就好比对表做了水平拆分一样,通常我们会给一个主题建立多个分区,分区也是提升消费能力的关键。
我们通常所说的写消息,读消息,那这个消息的载体就是分区了,一个分区通常采用队列的方式存储消息,先写进来的消息,自然也会先被消费。
4. 生产者(producer)
这应该很好理解吧,发送消息的一方呗。
5. 消费者(consumer)
有生产者,自然就有消费者。
生产者和消费者都是kafka的客户端,当生产者要发送消息时,根据kafka客户端提供的api会根据一定的规则将消息投递到某个主题下的某个分区中,并由kafka服务端来维护,而当消费者要消费消息时,也是根据kafka客户端提供的api会以定期从kafka服务端拉取消息的方式来消费,消费完之后再告诉kafka服务端。
kafka通过服务端隔离了生产者和消费者之间的直接交互,使得双方读写消息互不影响。
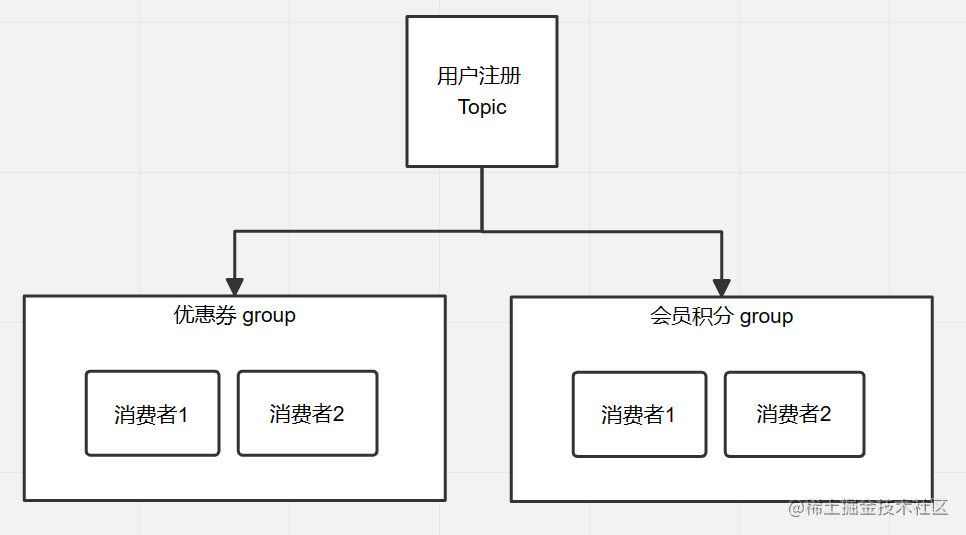
6. 消费者群组(consumer group)
顾名思义,这肯定是定义了多个消费者的存在,消费者群组的存在,提供了消息广播的能力,通常来说,一类事件的产生,可能存在触发多种业务场景处理的情况,比如:用户注册后,可能会触发多种对于新用户营销的活动,比如发券,发红包,送积分等等,那对于生产来说,不可能针对每个业务场景都要生产一条消息,这不科学,并且生产者也不关心到底有多少下游业务会用到,对于生产者来说,发送的就是用户注册这个事件。
消费者群组就是组成这些不同业务的载体,每个主题可以被多个消费者群组订阅,凡是订阅者都可以拉取到主题分区中的消息,当然,订阅者内的多个具体的消费者,就只会有一个能消费消息。
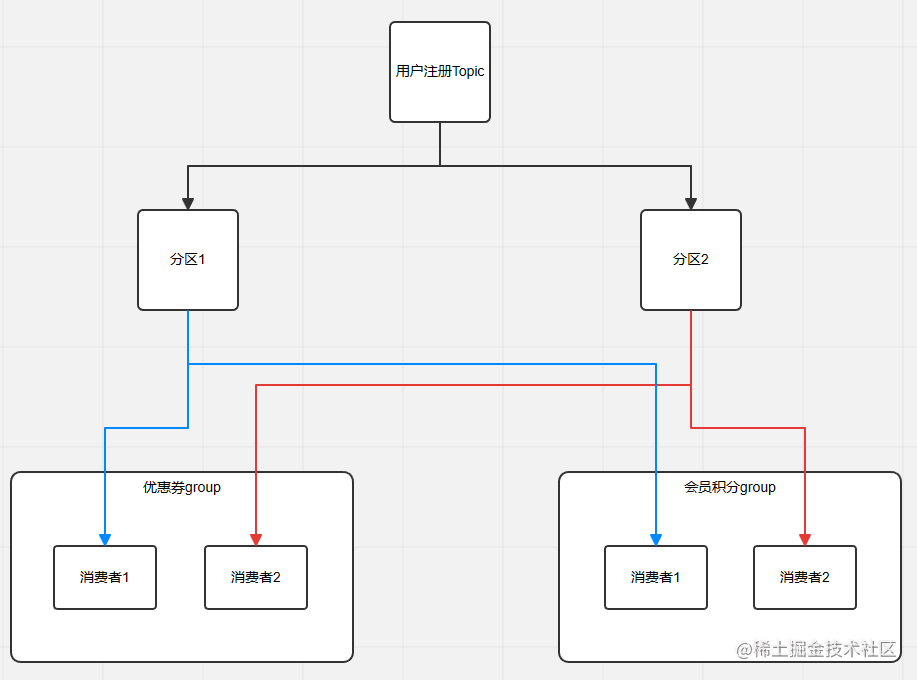
主题、消费者、消费者群组的关系
当产生一条用户注册消息后,优惠券group中的消费者1和消费者2会有一个接收到消息,会员积分group中的消费者1和消费者2也会有一个接收到消息。
加上分区以后的关系
简单的整体关系
二、详解分区
分区是kafka用来提升生产能力和消费能力的关键
1. 分区和主题
正如上面一节介绍的,分区是依赖主题存在的,新建主题时,就会一并建立好分区,分区数量一旦指定后,就只能增加,不能减少。
2. 分区和消费者
消费者实际上就是kafka的客户端,分区与消费者的关系通常在客户端启动时就建立好了,一般也就3种情况:
- 分区数量大于消费者数量
一个消费者会消费多个分区中的消息
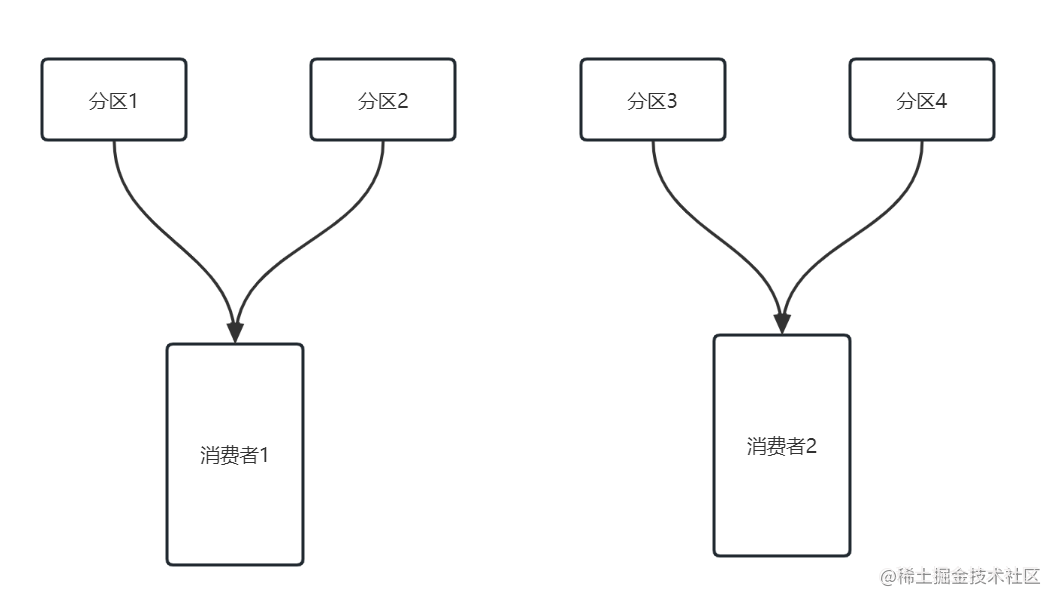
- 分区数量小于消费者数量
有两个消费者是空闲的,资源并没有得到充分的利用
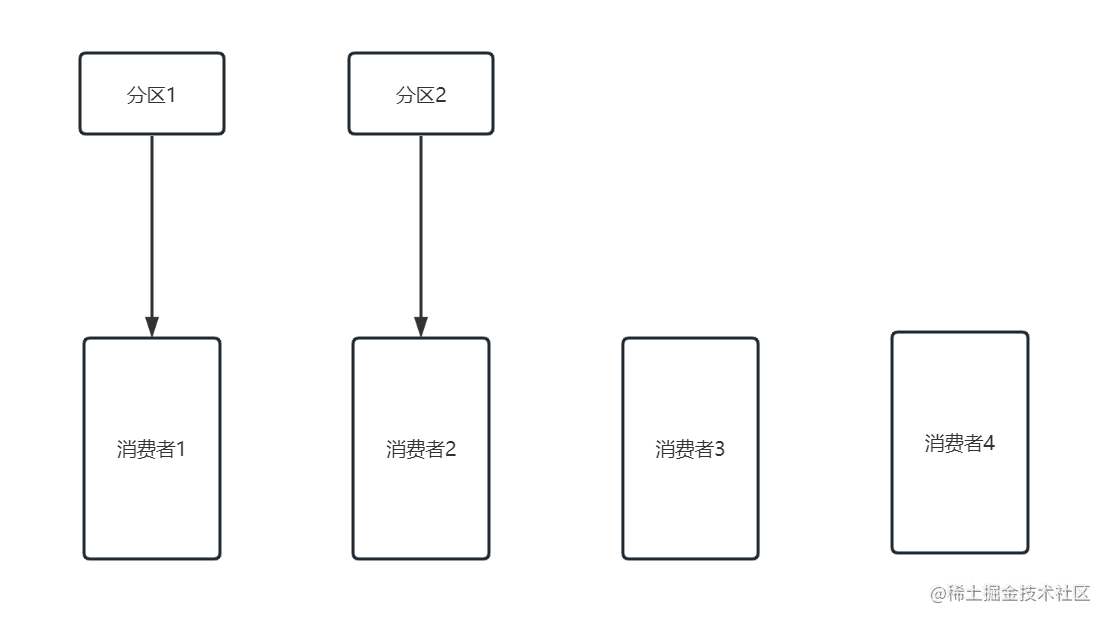
- 分区数量等于消费者数量
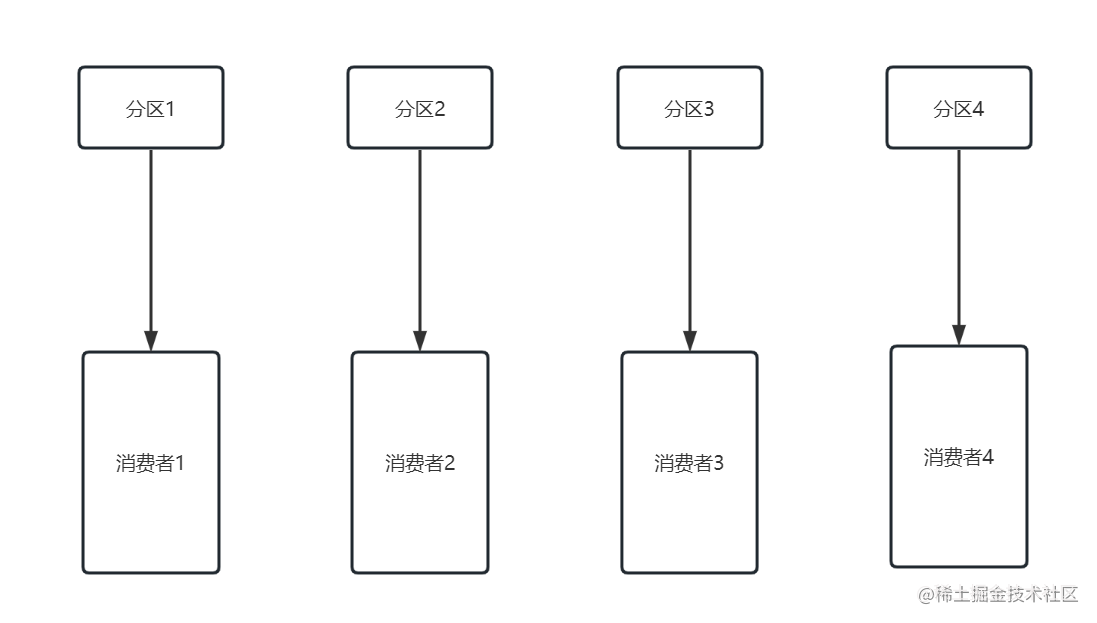
在实际生产环境中,并不一定要求说一定要使用3种情况中的哪一种,对于kafka的使用者来说,只要清楚的理解每种情况的弊端,然后根据实际情况进行调整即可。
3. 分区和消息
这里的消息,主要指的是生产者写入的消息,当生产者要向某个主题发送消息时,生产者会先将消息序列化处理,然后根据主题名称、指定的key、写入的value,计算出当前消息应该发送到哪个分区中,默认情况下如果没有指定key值,则按照类似轮询分区数的方式发送,如果指定了key值,则根据key值进行hash后取模发送,所以通常情况下一定发送消息时指定了key的值,则此类消息会始终被写入到同一个分区中。
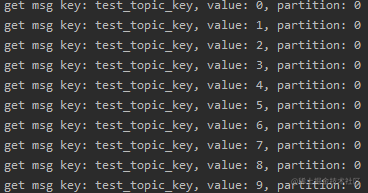
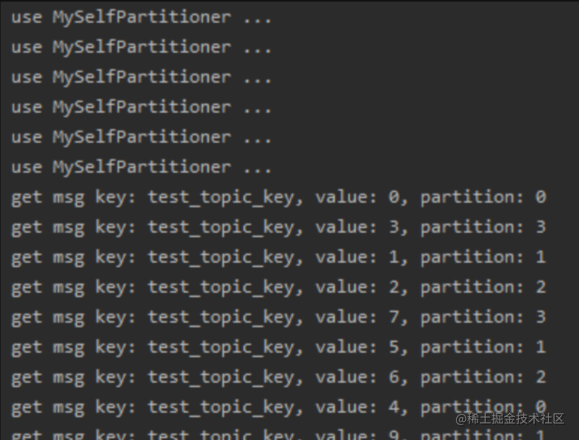
举个例子:假设我们要往有4个分区的topic:test_topic中,发送10条消息,并在发送时指定key为:test_topic_key
for (int i = 0; i < 10; i++) {
kafkaTemplate.send("test_topic", "test_topic_key", String.valueOf(i));
}
可以看到,虽然有4个分区,但消息全部是从分区1中读取的。
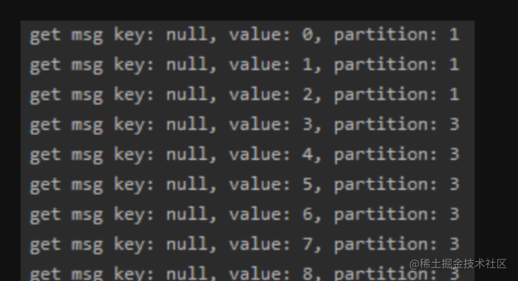
如果不指定key发送时,有的消息在分区1上,有的消息在分区3上。
当然,一般指定key的方式是为了同一个主题中,可以发送多种类型的消息,这样不同的消费端可以根据key的标识来自行选择进行消费,但我们知道指定key会导致消息始终被发送到同一个分区中,从而限制了消费的能力,要解决这个问题,通常我们可以根据消息写入的条件分析出,只要能将原来固定的key值,变的不固定即可,比如我们在原来的key值后面拼接上一串随机数,test_topic_key_?,之后当客户端接收到消息之后,只要截取随机数之前的值,就能得到有意义的key,从而用来进行业务场景的区分。
除此之外,kafka实际上也为我们预留一个扩展点,我们可以通过重写分区器的分区方法来自定义消息分区规则,比如像下面这样:
public class MySelfPartitioner implements Partitioner {
protected final Logger logger = LoggerFactory.getLogger(this.getClass());
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
logger.info("use MySelfPartitioner ...");
//拿到主题中的分区信息
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);
//获取分区数
int num = partitionInfos.size();
//计算value的hashcode,然后取模,获取一个分区
int parId = value.hashCode()%num;
return parId;
}
public void close() {
}
public void configure(Map<String, ?> configs) {
}
}
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.RETRIES_CONFIG, retries);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
props.put(ProducerConfig.LINGER_MS_CONFIG, linger);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//设置自定义分区器
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.wyl.config.MySelfPartitioner");
return props;
}
最终,在制定key的情况下,依旧能够讲消息打散到每个分区中了。
4. 分区再均衡(Rebalance)
4.1 什么是分区再均衡?
在Kafka中每个topic一般都会有多个分区,每个分区会按照一定规则分配给对应的消费者,那么一旦消费者无法接收消息后,就必须对分区进行重新分配,保证消息能够正常的被消费。
比如原来一个主题中有两个分区,分别对应一个消费者组中的两个消费者,此时如果有一个消费者挂了,那么就会触发分区再均衡,此时就会让另一个健康的消费者来消费原来那个消费者对应的分区中的数据。
4.2 触发分区再均衡的场景
4.2.1 消费者成员发生变化
这应该是最常见的触发Rebalance的原因,比如:消费者发布重启,增加或者减少消费者,都会造成消费者成员发生变化。
4.2.2 分区数发生变化
这个场景也很好理解,分区数发生了变化,自然需要重新调整分区与消费者的对应关系,分区一般只能增加不能减少。
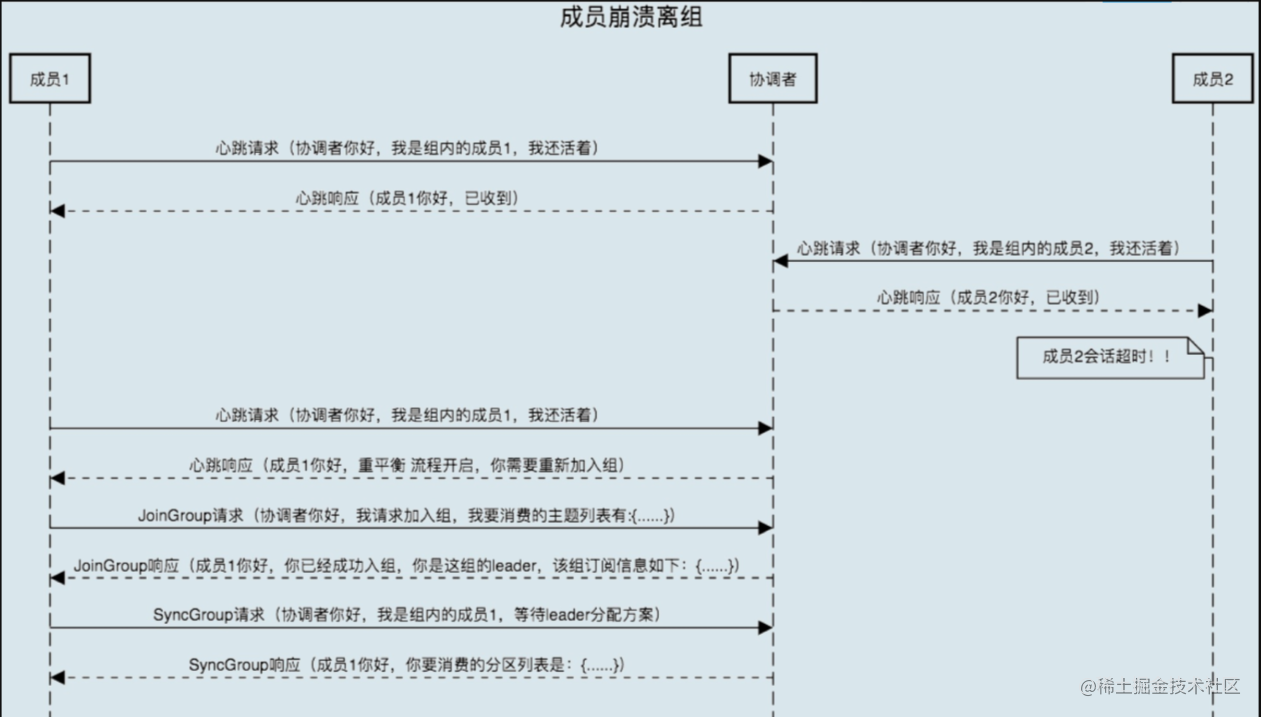
4.2.3 心跳超时
为了保证消费者组的可用性,Kafka中的Coordinator组件会负责监测所有Consumer的存活性,其判定方式是通过每个Consumer定期给它发送心跳来确定的,参数为session.timeout.ms,其默认值是10秒,也就是一旦Consumer超过10秒没有给Coordinator发送心跳,Coordinator就认为Consumer发生故障,此时Coordinator的做法就是将其从消费者组中移除,从而引发Rebalance,当然这本身是一个良好可用性的保障,只不过如果因为其他原因导致Consumer无法发送心跳而引起Rebalance就非其本意了,一般线上环境上最容易导致心跳无法发送的场景就是:长时间的GC暂停、CPU使用过高。
4.2.4 消息拉取超时
除了session.timeout.ms参数超时会引起Rebalance之外,还有一个参数也有类似逻辑,即max.poll.interval.ms,这个参数就规定了,当调用poll()方法之后,如果在max.poll.interval.ms指定的时间内未处理完消息,也就是未再调用poll()方法,则Consumer会主动发起离开组的请求,从而产生Rebalance。
4.3 Rebalance大致过程分析
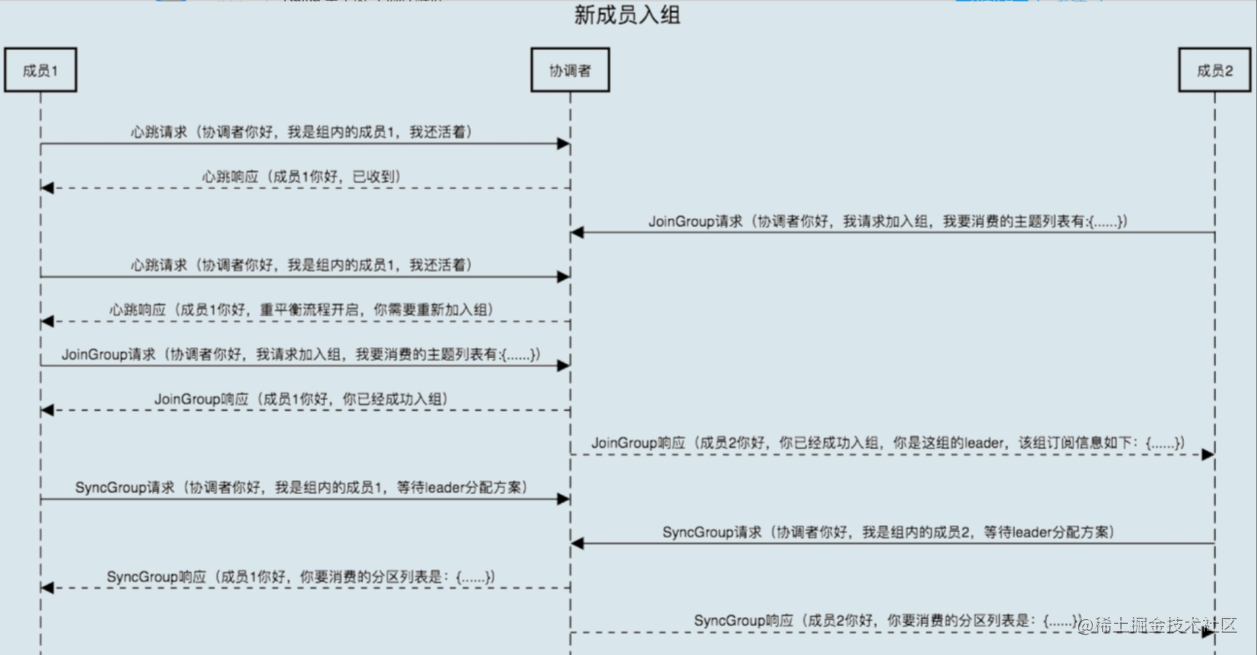
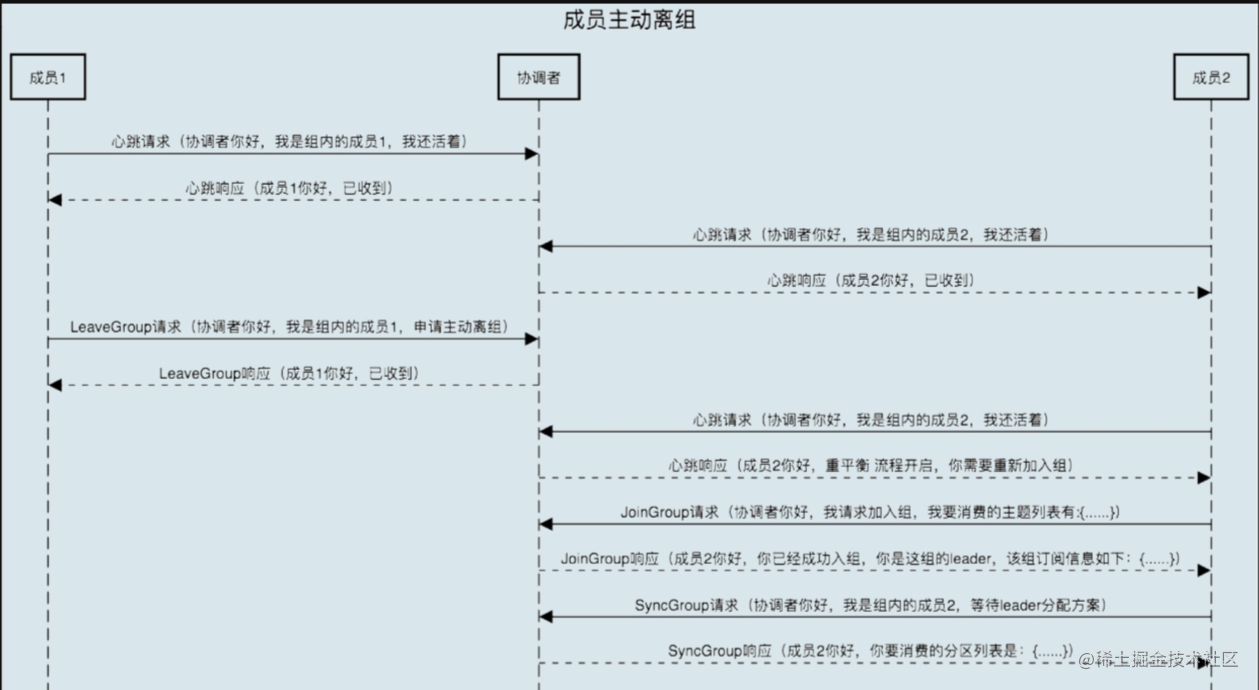
Kafka中Rebalance主要分为两步,第一步是JoinGroup,第二步是SyncGroup,通过Coordinator来协调各消费组的元数据信息以及组成员之间的关系,包括选举group leader、处理JoinGroup、SyncGroup请求等等。
消费组简单理解可以分为两种状态REBALANCING和STABILIZED:
REBALANCING表示消费组元数据发生变化,该状态下消费组中的所有消费者都无法进行正常的业务消费,该触发场景为消费组内有新的消费者加入或有已经建立连接的消费者退出。
STABILIZED表示rebalance完成,消费组处于稳定状态,该状态下消费组中的消费者可以进行正常的业务消费,触发条件是,当前消费组内的所有消费者都同步完成新的消费组元数据,包括之前已经同步过的消费者,也需要重新同步。
而发生Rebalance时,主要在如下4种场景下:
4.3.1 新的消费者加入到消费组中
4.3.2 消费者主动离开消费组
4.3.3 消费者崩溃离开消费组
4.3.4 组成员提交位移时
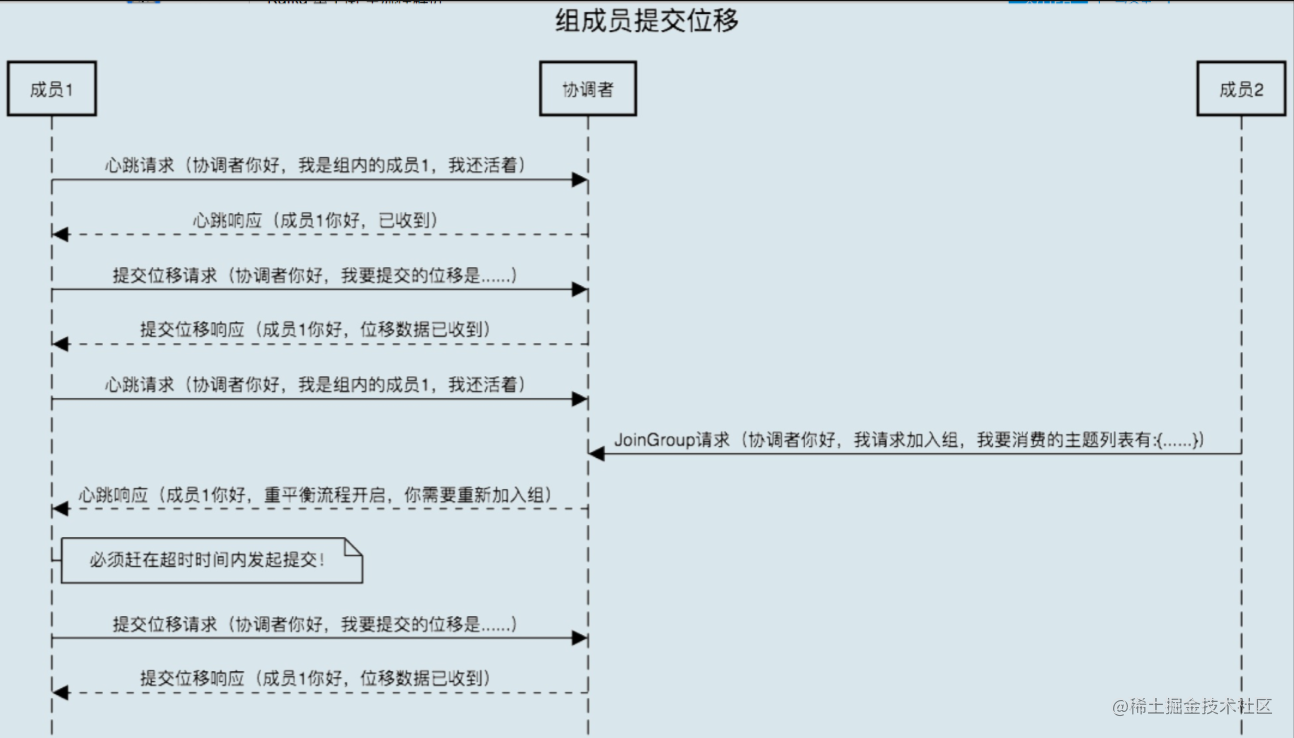
4.4 Rebalance源码浏览
poll方法
public boolean poll(Timer timer) {
maybeUpdateSubscriptionMetadata();
invokeCompletedOffsetCommitCallbacks();
if (subscriptions.partitionsAutoAssigned()) {
// Always update the heartbeat last poll time so that the heartbeat thread does not leave the
// group proactively due to application inactivity even if (say) the coordinator cannot be found.
pollHeartbeat(timer.currentTimeMs());
if (coordinatorUnknown() && !ensureCoordinatorReady(timer)) {
return false;
}
if (rejoinNeededOrPending()) {
// due to a race condition between the initial metadata fetch and the initial rebalance,
// we need to ensure that the metadata is fresh before joining initially. This ensures
// that we have matched the pattern against the cluster's topics at least once before joining.
if (subscriptions.hasPatternSubscription()) {
// For consumer group that uses pattern-based subscription, after a topic is created,
// any consumer that discovers the topic after metadata refresh can trigger rebalance
// across the entire consumer group. Multiple rebalances can be triggered after one topic
// creation if consumers refresh metadata at vastly different times. We can significantly
// reduce the number of rebalances caused by single topic creation by asking consumer to
// refresh metadata before re-joining the group as long as the refresh backoff time has
// passed.
if (this.metadata.timeToAllowUpdate(timer.currentTimeMs()) == 0) {
this.metadata.requestUpdate();
}
if (!client.ensureFreshMetadata(timer)) {
return false;
}
maybeUpdateSubscriptionMetadata();
}
if (!ensureActiveGroup(timer)) {
return false;
}
}
} else {
// For manually assigned partitions, if there are no ready nodes, await metadata.
// If connections to all nodes fail, wakeups triggered while attempting to send fetch
// requests result in polls returning immediately, causing a tight loop of polls. Without
// the wakeup, poll() with no channels would block for the timeout, delaying re-connection.
// awaitMetadataUpdate() initiates new connections with configured backoff and avoids the busy loop.
// When group management is used, metadata wait is already performed for this scenario as
// coordinator is unknown, hence this check is not required.
if (metadata.updateRequested() && !client.hasReadyNodes(timer.currentTimeMs())) {
client.awaitMetadataUpdate(timer);
}
}
maybeAutoCommitOffsetsAsync(timer.currentTimeMs());
return true;
}
boolean ensureActiveGroup(final Timer timer) {
// always ensure that the coordinator is ready because we may have been disconnected
// when sending heartbeats and does not necessarily require us to rejoin the group.
if (!ensureCoordinatorReady(timer)) {
return false;
}
startHeartbeatThreadIfNeeded();
return joinGroupIfNeeded(timer);
}
JoinGroup
boolean joinGroupIfNeeded(final Timer timer) {
while (rejoinNeededOrPending()) {
if (!ensureCoordinatorReady(timer)) {
return false;
}
// call onJoinPrepare if needed. We set a flag to make sure that we do not call it a second
// time if the client is woken up before a pending rebalance completes. This must be called
// on each iteration of the loop because an event requiring a rebalance (such as a metadata
// refresh which changes the matched subscription set) can occur while another rebalance is
// still in progress.
if (needsJoinPrepare) {
// 如果开启了自动提交,再均衡之前会提交offset
// 如果实现了ConsumerRebalanceListener接口,重写了onPartitionsRevoked方法,可以在分区再均衡之前拿到主题分区,处理offset等。。。
onJoinPrepare(generation.generationId, generation.memberId);
needsJoinPrepare = false;
}
// 发送加入group请求
final RequestFuture<ByteBuffer> future = initiateJoinGroup();
client.poll(future, timer);
if (!future.isDone()) {
// we ran out of time
return false;
}
if (future.succeeded()) {
// Duplicate the buffer in case `onJoinComplete` does not complete and needs to be retried.
ByteBuffer memberAssignment = future.value().duplicate();
onJoinComplete(generation.generationId, generation.memberId, generation.protocol, memberAssignment);
// We reset the join group future only after the completion callback returns. This ensures
// that if the callback is woken up, we will retry it on the next joinGroupIfNeeded.
resetJoinGroupFuture();
needsJoinPrepare = true;
} else {
resetJoinGroupFuture();
final RuntimeException exception = future.exception();
if (exception instanceof UnknownMemberIdException ||
exception instanceof RebalanceInProgressException ||
exception instanceof IllegalGenerationException ||
exception instanceof MemberIdRequiredException)
continue;
else if (!future.isRetriable())
throw exception;
timer.sleep(retryBackoffMs);
}
}
return true;
}
protected void onJoinPrepare(int generation, String memberId) {
// commit offsets prior to rebalance if auto-commit enabled
// 如果开启了自动提交,再均衡之前提交offset
maybeAutoCommitOffsetsSync(time.timer(rebalanceTimeoutMs));
// execute the user's callback before rebalance
ConsumerRebalanceListener listener = subscriptions.rebalanceListener();
Set<TopicPartition> revoked = subscriptions.assignedPartitions();
log.info("Revoking previously assigned partitions {}", revoked);
try {
// 可以重写的方法,分区再均衡开始前调用
listener.onPartitionsRevoked(revoked);
} catch (WakeupException | InterruptException e) {
throw e;
} catch (Exception e) {
log.error("User provided listener {} failed on partition revocation", listener.getClass().getName(), e);
}
isLeader = false;
subscriptions.resetGroupSubscription();
}
private synchronized RequestFuture<ByteBuffer> initiateJoinGroup() {
// we store the join future in case we are woken up by the user after beginning the
// rebalance in the call to poll below. This ensures that we do not mistakenly attempt
// to rejoin before the pending rebalance has completed.
if (joinFuture == null) {
// fence off the heartbeat thread explicitly so that it cannot interfere with the join group.
// Note that this must come after the call to onJoinPrepare since we must be able to continue
// sending heartbeats if that callback takes some time.
disableHeartbeatThread();
// 客户端开始分区再均衡了。。。
state = MemberState.REBALANCING;
// 向coordinator发送JoinGroup的请求
joinFuture = sendJoinGroupRequest();
// 处理完成后的回调
joinFuture.addListener(new RequestFutureListener<ByteBuffer>() {
@Override
public void onSuccess(ByteBuffer value) {
// handle join completion in the callback so that the callback will be invoked
// even if the consumer is woken up before finishing the rebalance
synchronized (AbstractCoordinator.this) {
log.info("Successfully joined group with generation {}", generation.generationId);
// 客户端已经加入到Group中,并开始发送心跳
state = MemberState.STABLE;
rejoinNeeded = false;
if (heartbeatThread != null)
heartbeatThread.enable();
}
}
@Override
public void onFailure(RuntimeException e) {
// we handle failures below after the request finishes. if the join completes
// after having been woken up, the exception is ignored and we will rejoin
synchronized (AbstractCoordinator.this) {
state = MemberState.UNJOINED;
}
}
});
}
return joinFuture;
}
RequestFuture<ByteBuffer> sendJoinGroupRequest() {
if (coordinatorUnknown())
return RequestFuture.coordinatorNotAvailable();
// send a join group request to the coordinator
log.info("(Re-)joining group");
JoinGroupRequest.Builder requestBuilder = new JoinGroupRequest.Builder(
new JoinGroupRequestData()
.setGroupId(groupId)
.setSessionTimeoutMs(this.sessionTimeoutMs)
.setMemberId(this.generation.memberId)
.setGroupInstanceId(this.groupInstanceId.orElse(null))
.setProtocolType(protocolType())
.setProtocols(metadata())
.setRebalanceTimeoutMs(this.rebalanceTimeoutMs)
);
log.debug("Sending JoinGroup ({}) to coordinator {}", requestBuilder, this.coordinator);
// Note that we override the request timeout using the rebalance timeout since that is the
// maximum time that it may block on the coordinator. We add an extra 5 seconds for small delays.
int joinGroupTimeoutMs = Math.max(rebalanceTimeoutMs, rebalanceTimeoutMs + 5000);
// 请求完成后,接着由JoinGroupResponseHandler处理
return client.send(coordinator, requestBuilder, joinGroupTimeoutMs)
.compose(new JoinGroupResponseHandler());
}
JoinGroupResponseHandler
private class JoinGroupResponseHandler extends CoordinatorResponseHandler<JoinGroupResponse, ByteBuffer> {
@Override
public void handle(JoinGroupResponse joinResponse, RequestFuture<ByteBuffer> future) {
Errors error = joinResponse.error();
if (error == Errors.NONE) {
log.debug("Received successful JoinGroup response: {}", joinResponse);
sensors.joinLatency.record(response.requestLatencyMs());
synchronized (AbstractCoordinator.this) {
if (state != MemberState.REBALANCING) {
// if the consumer was woken up before a rebalance completes, we may have already left
// the group. In this case, we do not want to continue with the sync group.
future.raise(new UnjoinedGroupException());
} else {
AbstractCoordinator.this.generation = new Generation(joinResponse.data().generationId(),
joinResponse.data().memberId(), joinResponse.data().protocolName());
if (joinResponse.isLeader()) {
// 如果是leader,负责分配方案。leader和follower都会发送SyncGroup请求
onJoinLeader(joinResponse).chain(future);
} else {
onJoinFollower().chain(future);
}
}
}
} else if (error == Errors.COORDINATOR_LOAD_IN_PROGRESS) {
log.debug("Attempt to join group rejected since coordinator {} is loading the group.", coordinator());
// backoff and retry
future.raise(error);
} else if (error == Errors.UNKNOWN_MEMBER_ID) {
// reset the member id and retry immediately
resetGeneration();
log.debug("Attempt to join group failed due to unknown member id.");
future.raise(Errors.UNKNOWN_MEMBER_ID);
} else if (error == Errors.COORDINATOR_NOT_AVAILABLE
|| error == Errors.NOT_COORDINATOR) {
// re-discover the coordinator and retry with backoff
markCoordinatorUnknown();
log.debug("Attempt to join group failed due to obsolete coordinator information: {}", error.message());
future.raise(error);
} else if (error == Errors.FENCED_INSTANCE_ID) {
log.error("Received fatal exception: group.instance.id gets fenced");
future.raise(error);
} else if (error == Errors.INCONSISTENT_GROUP_PROTOCOL
|| error == Errors.INVALID_SESSION_TIMEOUT
|| error == Errors.INVALID_GROUP_ID
|| error == Errors.GROUP_AUTHORIZATION_FAILED
|| error == Errors.GROUP_MAX_SIZE_REACHED) {
// log the error and re-throw the exception
log.error("Attempt to join group failed due to fatal error: {}", error.message());
if (error == Errors.GROUP_MAX_SIZE_REACHED) {
future.raise(new GroupMaxSizeReachedException(groupId));
} else if (error == Errors.GROUP_AUTHORIZATION_FAILED) {
future.raise(new GroupAuthorizationException(groupId));
} else {
future.raise(error);
}
} else if (error == Errors.UNSUPPORTED_VERSION) {
log.error("Attempt to join group failed due to unsupported version error. Please unset field group.instance.id and retry" +
"to see if the problem resolves");
future.raise(error);
} else if (error == Errors.MEMBER_ID_REQUIRED) {
// Broker requires a concrete member id to be allowed to join the group. Update member id
// and send another join group request in next cycle.
synchronized (AbstractCoordinator.this) {
AbstractCoordinator.this.generation = new Generation(OffsetCommitRequest.DEFAULT_GENERATION_ID,
joinResponse.data().memberId(), null);
AbstractCoordinator.this.rejoinNeeded = true;
AbstractCoordinator.this.state = MemberState.UNJOINED;
}
future.raise(Errors.MEMBER_ID_REQUIRED);
} else {
// unexpected error, throw the exception
log.error("Attempt to join group failed due to unexpected error: {}", error.message());
future.raise(new KafkaException("Unexpected error in join group response: " + error.message()));
}
}
}
// onJoinLeader
private RequestFuture<ByteBuffer> onJoinLeader(JoinGroupResponse joinResponse) {
try {
// perform the leader synchronization and send back the assignment for the group
Map<String, ByteBuffer> groupAssignment = performAssignment(joinResponse.data().leader(), joinResponse.data().protocolName(),
joinResponse.data().members());
List<SyncGroupRequestData.SyncGroupRequestAssignment> groupAssignmentList = new ArrayList<>();
for (Map.Entry<String, ByteBuffer> assignment : groupAssignment.entrySet()) {
groupAssignmentList.add(new SyncGroupRequestData.SyncGroupRequestAssignment()
.setMemberId(assignment.getKey())
.setAssignment(Utils.toArray(assignment.getValue()))
);
}
SyncGroupRequest.Builder requestBuilder =
new SyncGroupRequest.Builder(
new SyncGroupRequestData()
.setGroupId(groupId)
.setMemberId(generation.memberId)
.setGroupInstanceId(this.groupInstanceId.orElse(null))
.setGenerationId(generation.generationId)
// 分配的方案
.setAssignments(groupAssignmentList)
);
log.debug("Sending leader SyncGroup to coordinator {}: {}", this.coordinator, requestBuilder);
return sendSyncGroupRequest(requestBuilder);
} catch (RuntimeException e) {
return RequestFuture.failure(e);
}
}
// onJoinFollower
private RequestFuture<ByteBuffer> onJoinFollower() {
// send follower's sync group with an empty assignment
SyncGroupRequest.Builder requestBuilder =
new SyncGroupRequest.Builder(
new SyncGroupRequestData()
.setGroupId(groupId)
.setMemberId(generation.memberId)
.setGroupInstanceId(this.groupInstanceId.orElse(null))
.setGenerationId(generation.generationId)
// follower不负责分配方案
.setAssignments(Collections.emptyList())
);
log.debug("Sending follower SyncGroup to coordinator {}: {}", this.coordinator, requestBuilder);
return sendSyncGroupRequest(requestBuilder);
}
当SyncGroup完成后,执行onJoinComplete方法
protected void onJoinComplete(int generation,
String memberId,
String assignmentStrategy,
ByteBuffer assignmentBuffer) {
// only the leader is responsible for monitoring for metadata changes (i.e. partition changes)
if (!isLeader)
assignmentSnapshot = null;
PartitionAssignor assignor = lookupAssignor(assignmentStrategy);
if (assignor == null)
throw new IllegalStateException("Coordinator selected invalid assignment protocol: " + assignmentStrategy);
Assignment assignment = ConsumerProtocol.deserializeAssignment(assignmentBuffer);
if (!subscriptions.assignFromSubscribed(assignment.partitions())) {
handleAssignmentMismatch(assignment);
return;
}
Set<TopicPartition> assignedPartitions = subscriptions.assignedPartitions();
// The leader may have assigned partitions which match our subscription pattern, but which
// were not explicitly requested, so we update the joined subscription here.
maybeUpdateJoinedSubscription(assignedPartitions);
// give the assignor a chance to update internal state based on the received assignment
assignor.onAssignment(assignment, generation);
// reschedule the auto commit starting from now
if (autoCommitEnabled)
this.nextAutoCommitTimer.updateAndReset(autoCommitIntervalMs);
// execute the user's callback after rebalance
ConsumerRebalanceListener listener = subscriptions.rebalanceListener();
log.info("Setting newly assigned partitions: {}", Utils.join(assignedPartitions, ", "));
try {
// 可以重写的方法,分区再均衡完成后调用。
listener.onPartitionsAssigned(assignedPartitions);
} catch (WakeupException | InterruptException e) {
throw e;
} catch (Exception e) {
log.error("User provided listener {} failed on partition assignment", listener.getClass().getName(), e);
}
}
5. 分区分配策略
分区分配指的是Kafka依据什么样的分配方式将多个主题中的多个分区与多个消费者进行对应。
5.1 Range
按范围分配。对于每个主题,我们按数字顺序排列可用分区,并按字典顺序排列消费者。然后,我们将分区数除以消费者总数,以确定要分配给每个消费者的分区数。如果它不能平均分配,那么前几个消费者将会有一个额外的分区。
比如现在有两个消费者 C0 ,C1
两个主题 t0 ,t1
每个主题有3个分区,结果如下 t0p0, t0p1, t0p2, t1p0, t1p1, t1p2
partition数/consumer数
最终分配结果如下 C0: [t0p0, t0p1, t1p0, t1p1] C1: [t0p2, t1p2]
这种方式的弊端在于如果分区和消费者不能平均分配的话就会造成前几个消费者多分配分区,导致资源负载不均衡。
5.2 RoundRobin
循环分配将列出所有可用分区和所有可用的消费者。然后,它继续执行从分区到消费者的循环分配。如果所有消费者实例的订阅都相同,则分区将被均匀分布。(也就是说,分区所有权计数将在所有消费者中正好为1的增量范围内。)
两个消费者 C0 ,C1
两个主题 t0 ,t1
每个主题有3个分区,结果如下 t0p0, t0p1, t0p2, t1p0, t1p1, t1p2
结果如下: C0: [t0p0, t0p2, t1p1] C1: [t0p1, t1p0, t1p2]
当消费者实例的订阅不同时,指派过程仍会以循环方式考虑每个消费者执行个体,但如果实例没有订阅主题,则会跳过该实例。与订阅相同的情况不同,这可能导致分配不平衡。
比如有3个消费者 C0, C1, C2
3个主题,3个主题分别有1个、2个和3个分区 t0, t1, t2,
那么得到的主题分区关系如下 t0p0, t1p0, t1p1, t2p0, t2p1, t2p2.
假设: C0 订阅 t0; C1 订阅 t0, t1; C2 订阅 t0, t1, t2.
最终分配结果如下: C0: [t0p0] C1: [t1p0] C2: [t1p1, t2p0, t2p1, t2p2]
所以这种分配方式的问题在于,如果消费者之间订阅的主题不相同时,则会造成资源分配不均衡。
5.3 Sticky
我们可以叫他粘粘性分配策略。这种策略主要有两个用途。
首先,它保证分配尽可能平衡,数字分配给消费者的主题分区的数目最多相差一个;或者每个消费者比其他消费者少2个以上的主题分区,则无法将这些主题分区中的任何一个传送给它。
其次,当分区再均衡发生时,它保留了尽可能多的现有赋值。这有助于在主题分区从一个消费者移动到另一个消费者时节省一些开销处理。
上面的第一个目标优先于第二个目标。
第一种场景
3个消费者,每个消费者都订阅了所有主题 C0, C1, C2
4个主题 t0, t1, t2, t3
每个主题有2个分区,得到结果如下 t0p0, t0p1, t1p0, t1p1, t2p0,t2p1, t3p0, t3p1
分配结果如下: C0: [t0p0, t1p1, t3p0] C1: [t0p1, t2p0, t3p1] C2: [t1p0, t2p1]
现在假设C1消费者被删除了,即将发生分区再均衡,如果是RoundRobin策略,则结果为: C0: [t0p0, t1p0, t2p0, t3p0] C2: [t0p1, t1p1, t2p1, t3p1]
而按照Sticky策略,则结果为: C0 [t0p0, t1p1, t3p0, t2p0] C2 [t1p0, t2p1, t0p1, t3p1]
很明显Sticky策略,保留所有以前的分配。
第二种场景
3个消费者 C0, C1, C2
3个主题 t0, t1, t2
3个主题分别有1个、2个和3个分区,得到结果如下 t0p0, t1p0, t1p1, t2p0,t2p1, t2p2.
假设: C0 订阅 t0; C1 订阅 t0, t1; C2 订阅 t0, t1, t2.
上文已经介绍过了按照RoundRobin的分配结果如下: C0: [t0p0] C1: [t1p0] C2: [t1p1, t2p0, t2p1, t2p2]
Sticky的分配结果则如下: C0 [t0p0] C1 [t1p0, t1p1] C2 [t2p0, t2p1, t2p2]
现在假设C0消费者被删除了。
RoundRobin重新分配结果如下: C1 [t0p0, t1p1] C2 [t1p0, t2p0, t2p1, t2p2]
分配结果保留了3个分区未被移动。
Sticky重新分配结果如下: C1 [t1p0, t1p1, t0p0] C2 [t2p0, t2p1, t2p2]
分配结果保留了5个分区未被移动。
使用粘性分配策略还可以为那些在onPartitionsRevoked()回调监听器中有一些分区清理代码的消费者提供一些优化。清理代码放在回调监听器中,因为消费者在使用range或round-robin策略时,不会假设或希望在分区再均衡后留其分配的任何分区。
如上所述,sticky assignor的一个优点是,它可以减少在重新分配期间实际从一个消费者移动到另一个消费者的分区的数量。因此,它可以让消费者更有效地进行清理。当然,它们仍然可以在onPartitionsRevoked()监听器中执行分区清理,但它们可以更高效地在分区再均衡之前和之后记录下自己的分区,并且在分区再均衡之后只对丢失的分区进行清理(这通常不是很多)。
在实际的生产环境中,建议使用黏性分区策略,因为它还可以解决当把消息分散到不同分区后,由于产生过多小batch,导致整体效率降低的问题,黏性分区策略可以尽量保证在一个batch未完成之前所有的消息都分配给这个批次,短期来看,可能会发现消息都打到了一个分区上,但如果拉长整个运行周期来看,消息还是均匀分布到各个分区上的。
三、关于消息
1. 消息的发送
作为生产消息的一方来说,最基本的功能就是如何将消息发送出去,其次就是要不要等待发送响应结果,最后就是怎么才算消息发送成功了,针对这三方面,我们一起来看看kafka是如何做的?
1.1 发送流程
我们直接通过客户端的消息发送doSend方法来分析
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
throwIfProducerClosed();
// first make sure the metadata for the topic is available
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? nowMs : record.timestamp();
if (log.isTraceEnabled()) {
log.trace("Attempting to append record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
}
// producer callback will make sure to call both 'callback' and interceptor callback
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
if (transactionManager != null && transactionManager.isTransactional()) {
transactionManager.failIfNotReadyForSend();
}
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
if (result.abortForNewBatch) {
int prevPartition = partition;
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
if (log.isTraceEnabled()) {
log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);
}
// producer callback will make sure to call both 'callback' and interceptor callback
interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);
}
if (transactionManager != null && transactionManager.isTransactional())
transactionManager.maybeAddPartitionToTransaction(tp);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
} catch (ApiException e) {
log.debug("Exception occurred during message send:", e);
if (callback != null)
callback.onCompletion(null, e);
this.errors.record();
this.interceptors.onSendError(record, tp, e);
return new FutureFailure(e);
} catch (InterruptedException e) {
this.errors.record();
this.interceptors.onSendError(record, tp, e);
throw new InterruptException(e);
} catch (KafkaException e) {
this.errors.record();
this.interceptors.onSendError(record, tp, e);
throw e;
} catch (Exception e) {
// we notify interceptor about all exceptions, since onSend is called before anything else in this method
this.interceptors.onSendError(record, tp, e);
throw e;
}
}
1.1.1 元数据校验
// first make sure the metadata for the topic is available
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
1.1.2 消息序列化
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert key of class " + record.key().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() +
" specified in key.serializer", cce);
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() +
" to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() +
" specified in value.serializer", cce);
}
1.1.3 计算消息应该发送到哪个分区
int partition = partition(record, serializedKey, serializedValue, cluster);
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
如果没有指定分区器,则使用默认的分区器DefaultPartitioner,大概流程:
- 先根据topic获取分区数。
- 如果发送消息时指定了key,则根据key的hash值与分区数取模,获得分区。
- 如果没有指定key,则通过维护一个自增的int值再与分区数取模,获取分区,这就类似轮询的方式了。
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) {
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement();
}
1.1.4 将多条消息打包成一个批次
// 追加消息
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
// 唤醒sender线程
this.sender.wakeup();
}
默认条件一个批次大小是16kb,通过batch.size参数设置,当批次中的消息大小达到16kb时,才会发送到broker中,否则等待,那么等待的时间可以由linger.ms这个参数控制,如果超过等待时间后还未达到16kb,那么还是会发送到broker中,这个参数默认值是0,也就是不等待。
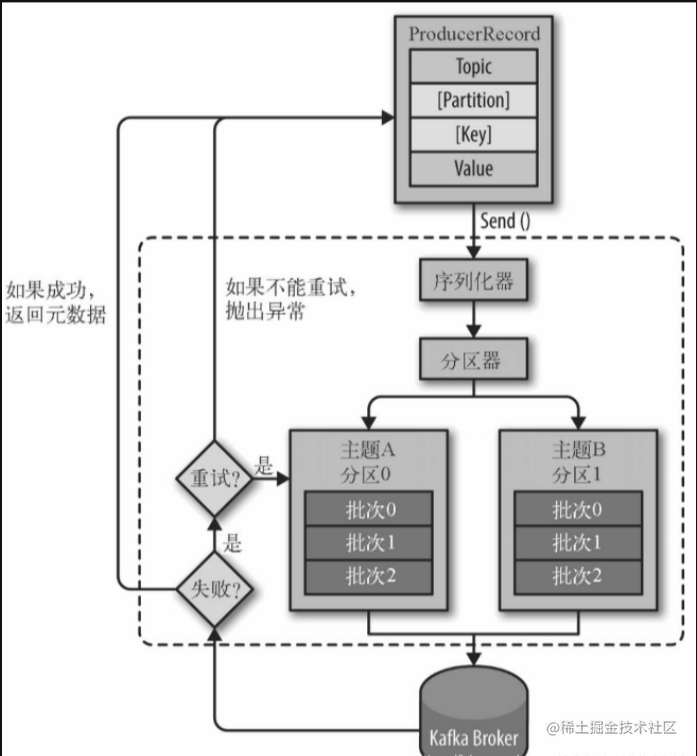
1.2 发送方式
kafka生产者发送消息的方式可以分为:发送并忘记、同步发送、异步发送。
1.2.1 发送并忘记
生产者只要调用send方法就可以了,不需要处理send的返回值,大多数情况下消息都可以正常发送出去,但可能会丢失消息。
public class KafkaProducer {
public static void main(String[] args) {
KafkaProducer<String, String> producer = new KafkaProducer(producerConfigs());
ProducerRecord<String, String> record = new ProducerRecord("test_topic", "hello kafka");
// 调用send方法即完成发送
producer.send(record);
}
public static Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.93.132:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
}
但是当我们获取元数据时出现问题,send的方法依旧会被阻塞。
try {
// 这边会阻塞
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
} catch (KafkaException e) {
if (metadata.isClosed())
throw new KafkaException("Producer closed while send in progress", e);
throw e;
}
比如指定一个不存在的分区发送消息,就会因为元数据获取问题,导致阻塞,默认是等待60s。
Exception in thread "main" java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Topic test_topic not present in metadata after 1000 ms.
at org.apache.kafka.clients.producer.KafkaProducer$FutureFailure.<init>(KafkaProducer.java:1269)
at org.apache.kafka.clients.producer.KafkaProducer.doSend(KafkaProducer.java:933)
at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:856)
at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:743)
at cn.enjoyedu.sendtype.KafkaFutureProducer.main(KafkaFutureProducer.java:26)
Caused by: org.apache.kafka.common.errors.TimeoutException: Topic test_topic not present in metadata after 1000 ms.
1.2.2 同步发送
接收send方法的返回值Future<RecordMetadata>对象,并调用get方法。
public static void main(String[] args) throws ExecutionException, InterruptedException {
KafkaProducer<String, String> producer = new KafkaProducer(producerConfigs());
ProducerRecord<String, String> record = new ProducerRecord("test_topic", "hello kafka");
Future<RecordMetadata> send = producer.send(record);
// get方法会阻塞
RecordMetadata recordMetadata = send.get();
System.out.println("topic: " + recordMetadata.topic() + ", offset: " + recordMetadata.offset() + ", partition: " + recordMetadata.partition());
}
1.2.3 异步发送
使用带Callback的send方法,提供请求完成的异步处理,当发送到服务器的记录已被确认时,将调用此方法。
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
异步发送测试
public static void main(String[] args) {
KafkaProducer<String, String> producer = new KafkaProducer(producerConfigs());
ProducerRecord<String, String> record = new ProducerRecord("test_topic", "hello_key", "hello kafka");
// callback1
producer.send(record,
(metadata, e) -> {
if (e != null) {
e.printStackTrace();
} else {
System.out.println("The offset of the record we just sent is: " + metadata.offset());
}
});
// callback2
producer.send(record,
(metadata, e) -> {
if (e != null) {
e.printStackTrace();
} else {
System.out.println("The offset of the record we just sent is: " + metadata.offset());
}
});
producer.close();
}
结果打印
The offset of the record we just sent is: 98
The offset of the record we just sent is: 99
1.3 ack机制
ACK的定义说明:生产者在确认请求完成之前要求leader副本已收到的确认数,可以定义为这是对消息发送成功的定义。
这个参数一共有3个值,默认为1。
0:生产者只要把消息发送出去即可,不用等待broker的处理结果,消息将立即添加到socket buffer并被视为已发送。在这种情况下,无法保证服务器已收到消息,并且retries配置将不会生效(因为客户端通常不会知道任何故障),每条消息返回的偏移量将始终设置为-1。
1:生成者需要等分区leader将消息写入成功后才认为此消息发送成功,兼顾了吞吐量和消息丢失的问题,但是同样有消息丢失的风险,比如当leader写入成功后突然挂了,其他分区跟随者并未能够将此消息同步,则此消息丢失。
all(等同于-1):生产者会等待所有的副本都写入成功后才认为此消息发送成功,只要至少有一个同步副本保持活跃状态,消息就不会丢失,这是最安全的保障,是吞吐量最低的。
0:吞吐量最高,同样消息的丢失率也最高。
all:吞吐量最低,但也最安全。
1:折中选择。
四、集群副本
1. 什么是副本
简单的理解一下,副本就是对于分区中消息的备份,是kafka中通过数据的冗余保证高可用的一种方式,所以副本又是建立在kafka集群模式的基础上的。
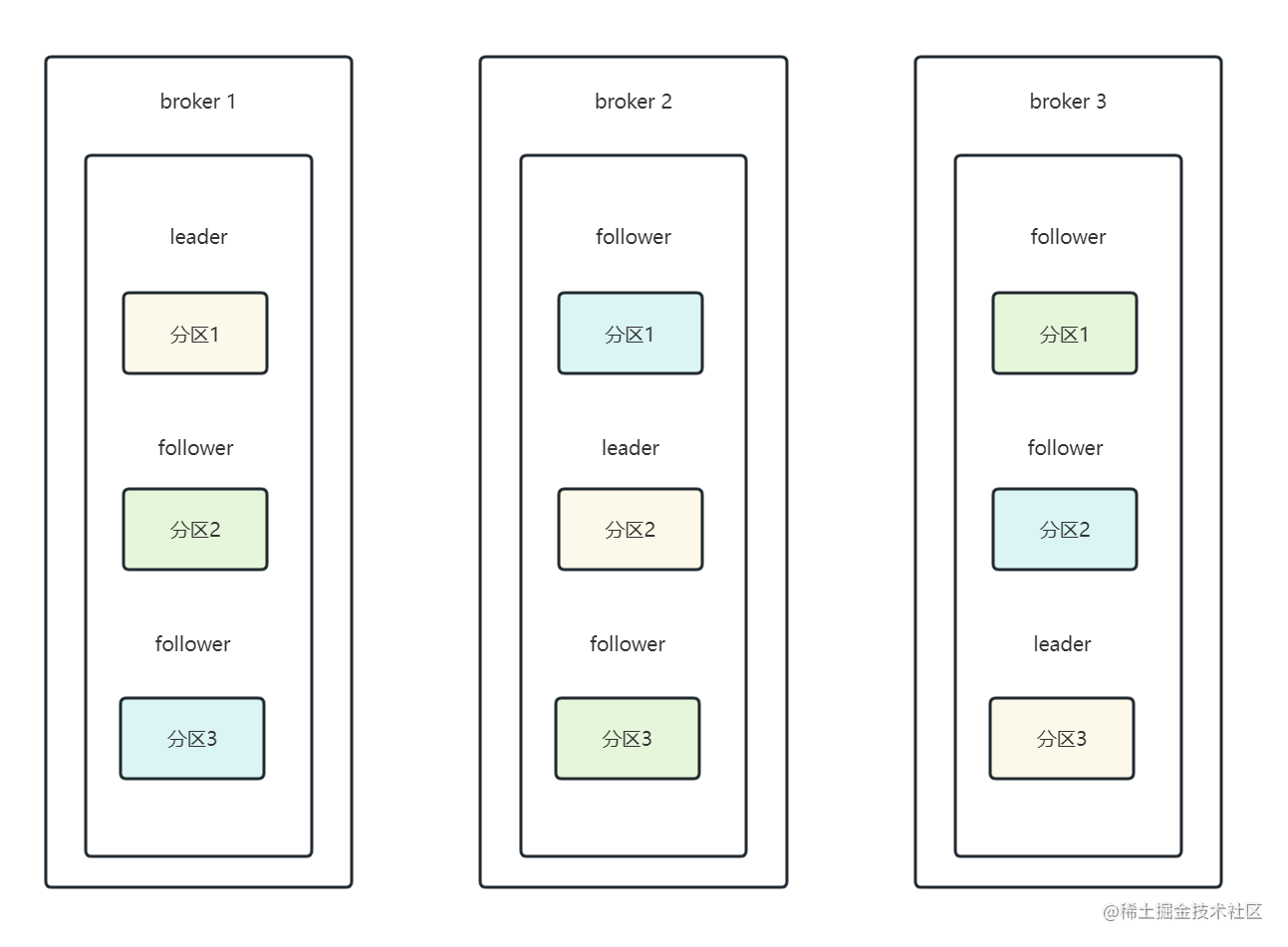
下图中表示的含义为:由3台broker组成的kafka集群,其中某个主题有3个分区,并且每个分区有2个副本。
可以看出,每个分区都由1个leader和2个follower组成,并且位于不同的broker上,当某一个broker实例出现故障时,可将其他分区的follower提升为leader,这样一来就实现了分区的高可用。
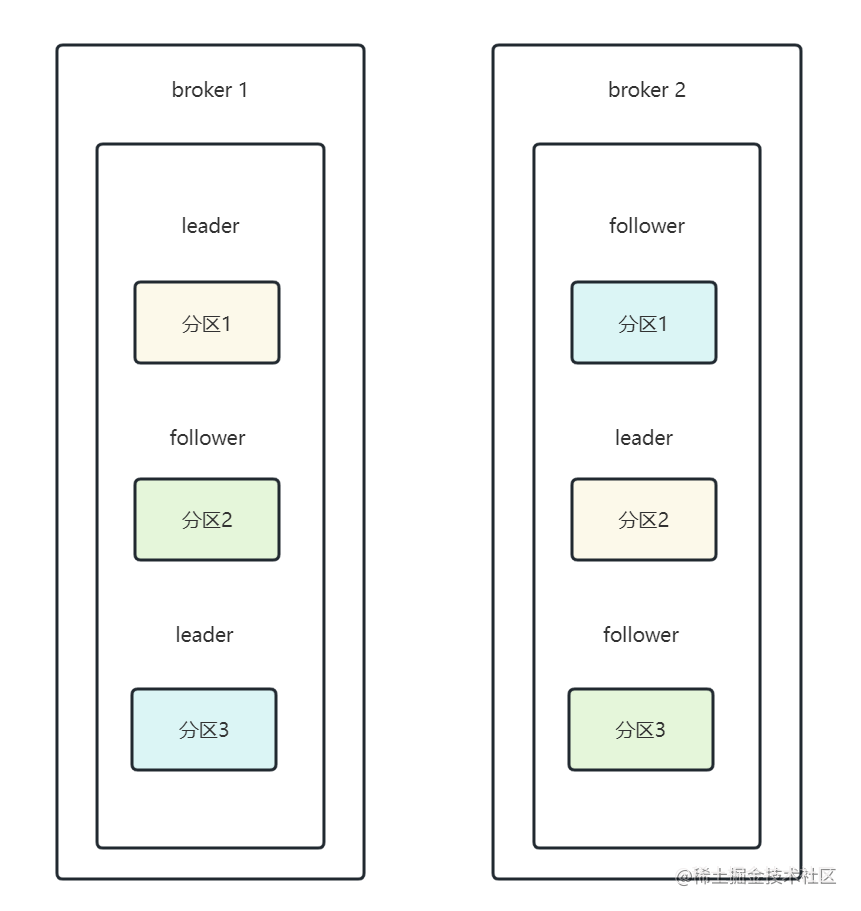
如果分区数量大于副本数量,那就直接在一个broker上放多个leader即可。
但副本的数量是不能超过集群中broker的数量的,创建时就会直接报错。
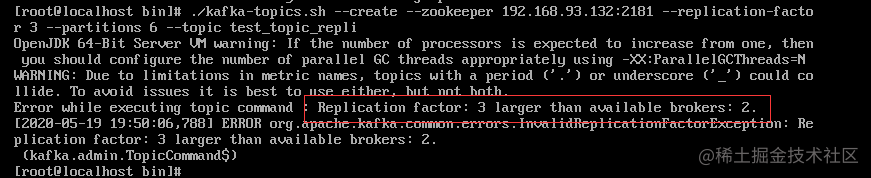
2. leader副本和follower副本
当我们创建topic并指定副本数量时,有且只有一个副本是leader副本,其余的副本都是follower副本。
生产者发送的消息只会由leader副本直接接收到,同样的,消费者拉取消息也只会从leader副本中拉取,follower副本只负责不断的从leader副本中同步数据即可,会尽量的让自己与leader保持一致,follower副本会在leader副本发送故障时,通过选举变为新的leader副本,以此来保证kafka的可用性。
3. ISR机制
ISR(In-Sync Replica),是与leader保持同步的副本集合,在leader宕机时,一般会优先从ISR中选举一个作为新的leader,所以follower副本会不断的从leader副本中拉取并同步消息,以保证自己在ISR集合中。
有一点要能理解,实际上由于网络抖动、通信延迟、突发流量等原因,并不一定要follower与leader保持完全一致才可以放入ISR。
在0.9.0.0版本之前,有一个参数replica.lag.max.messages,意为当副本中的follower与leader最多相差多少条消息时,则会被踢出,这个参数在突发流量的场景下很容易造成follower被频繁的踢出,平稳后又被加入ISR中。
所以之后的版本中衡量一个follower是否能存在ISR中只有一个参数replica.lag.time.max.ms,意为最长多少时间不向leader请求数据,则被判定不同步,被踢出ISR。
思考一个问题如果ISR中只有leader副本,也就是说没有任何一个follower副本满足进入ISR中,此时leader所在的broker发生故障,该如何处理?
此时,通常有两种选择。
- 等待ISR中任意一个副本出现,选举为leader。
- 随便选择一个follower,选举为leader。
第一种方案可能会造成等待时间较长,如果ISR中所有的副本都无法活过来了,则分区会变的永久不可用,侧重于数据的可靠性。
第二种方案虽然可能会丢失消息,但是保证了可用性。
kafka提供了一个参数:unclean.leader.election.enable,它决定了使用哪一种,默认true,表示允许从非ISR中的副本中选择一个follower,选举为leader,false则表示必须从ISR副本中选择leader(注意:在0.11.0.0版本后默认为false)。
最小同步副本
与ISR相关的还有一个参数min.insync.replicas,只有当ISR中的数量大于等于最小同步副本数时,生产者的消息才会被提交,即生产者才会被告知消息发送成功。
注意这个参数必须是生产者设置ack为all时才会生效,如果ack设置为0或者1时,表示的含义明显与最小同步副本冲突
提升篇
五、常见问题分析
1. 如何能按顺序消费
我们知道,消息是以队列的形式存储在分区中,因此在单个分区中的消息本身就是顺序的,所以只要我们能将需要保证顺序的消息固定发送一个分区中,自然就能保证顺序性了。
如何将消息发送到固定的分区中?
主要有两种方式:
- 指定发送分区
- 按key发送(如果发送消息时,指定了key值,那么默认情况下就会根据key的hash值与分区数取模,决定消息应该发送到哪个分区中,所以指定key时也就间接的等于指定了要发送到哪个分区。)
同一个分区中的消息就一定能保证有序吗?
实际上kafka中有一种处理异常重试方案,理论上也会影响消息的顺序性,哪怕你的消息在同一个分区中。
这里主要涉及到两个参数:retries和max.in.flight.requests.per.connection。
retries:生产者在发送消息时,如果遇到理论上重试就能成功的异常,会根据此值进行重试。
max.in.flight.requests.per.connection:在收到服务端消息确认发送之前,可以提前发送的消息数量。
场景分析
假设,第一批消息发送时,由于设置了max.in.flight.requests.per.connection参数,此时第二批消息(max.in.flight.requests.per.connection指定数量的消息)无须等服务端确认收到第一批消息时就可以提前发送,刚好第一批消息又发送异常并且也配置了允许重试,于是在第一批消息重试的过程中,第二批消息无异常正常发送出去了,随后第一批消息经过重试后也成功发送出去了,这样就造成了消息顺序被打乱了。
参数说明

问题解决
所以,要想解决此类打乱消息顺序的场景,只能调整这两个参数:
1. 不允许重试,允许提前发送消息
由于不会重试,也就不会产生乱序问题,带来的问题就是可能会造成消息经常发送失败
2. 允许重试,但是不允许提前发送消息
保证了正常情况下消息都能够被发送,但是不允许提前发送也就等于牺牲了发送消息的吞吐量。
保证顺序所带来的牺牲
kafka之所以能那么快,其中一个很重要的原因就是多分区的架构设计,多个分区与多个消费端相互对应这样的设计能够充分利用消费端的资源,使得消息可以并行消费,并且可以实现水平扩展,而为了让消息实现顺序消费,消息就必须被放入一个分区中,就等于只能被一个消费端线程串行消费,这就大大的降低了消费端的消费能力,所以一定要谨慎评估是否真的有顺序消费的必要。
2. 如何确保消息不丢失
Kafka对于消息的可靠性是可以达到至少一次(at least once)的保证,即消息不会丢失,但有可能重复发送,我们知道一条消息要经过发送、存储、消费三个过程,每一个过程出现问题,就都有可能造成消息的丢失,那么接下来,我们就来看看针对这三个过程kafka分别是如何保证消息不丢失的。
2.1 消息发送
前面提到过,消息发送的方式有三种:发送并忘记、同步发送、异步发送。
在使用发送并忘记的方式下,消息是很有可能丢失的,同步发送可以通过get返回值判断发送是否成功,异步发送则是可以根据回调结果来判断消息是否写入成功,所以这两种方式都可以在发送后得到发送结果,以此确保发送没问题。
ACK机制
前面关于ACK前面已经介绍过了,这不再重复赘述了。
2.2 消息的存储
消息的存储主要还是依靠多副本的机制,为了保证kafka集群的高可用性,集群最少要由3个节点组成,这样每个分区就可以建立3个副本,从而每条消息最终也都会在3个节点上分别存储一份,当然前面在提到ISR机制时,也解释了follower副本和leader副本的关系,unclean.leader.election.enable参数可能会导致消息丢失
2.3 消息的消费
理论上来说,消息一旦被消费者接收到,对于kafka来说就已经不存在丢失的情况下,由客户端自行决定消息是否消费完成,如果你设置为自动提交消息,则很有可能因为处理不当,导致消息还没有被真正的消费,就已经被提交offset,所以最保险的方式是设置为手动提交,这样可以确保自身业务处理完成后才会提交offset。
2.3.1 自动提交offset
通过参数enable.auto.commit=true控制,默认就是true,并通过auto.commit.interval.ms参数指定自动提交的频率,默认为5秒。
kafka会保证每次在调用poll方法时,已经提交了上一批消息的位移,所以kafka层面上设置自动提交消息是不会丢失的,但客户端在使用时就要注意,有时候可能业务逻辑上并没有处理成功,或者发生异常了,但由于设置了自动提交offset而导致消息被消费掉了,虽然严格意思上来说,这并不能算是消息丢失。
2.3.2 手动提交offset
将参数enable.auto.commit设置为false,就表示使用手动提交offset的方式了,之后,只要显示的调用commitSync方法或者commitAsync方法即可。
commitSync
该方法会提交由 KafkaConsumer#poll() 方法返回的最新位移值,它是一个同步操作,会一直阻塞等待直到位移被成功提交才返回,如果提交的过程中出现异常,该方法会将异常抛出。这里我们知道在调用 commitSync() 方法的时机是在处理完 Poll() 方法返回所有消息之后进行提交,如果过早的提交了位移就会出现消费数据丢失的情况。
commitAsync
该方法是异步方式进行提交的,调用 commitAsync() 之后,它会立即返回,并不会阻塞,因此不会影响 Consumer 的 TPS。另外 Kafka 针对它提供了callback,方便我们来实现提交之后的逻辑,比如记录日志或异常处理等等。由于它是一个异步操作, 假如出现问题是不会进行重试的,这时候重试位移值可能已不是最新值,所以重试无意义。
3. 消息积压怎么办
一般情况下,消息积压并不会对kafka集群造成什么影响,削峰填谷本身也是kafka的作用之一。
产生消息积压的原因无非就是消费者消费能力不足,而导致消费能力不足的情况,要么就是产生了突发流量,要么就是消费者本身出现了问题。
解决消费者能力不足的简单方式,就是增加消费者了(包含:consumer实例、消费线程数)。
4. 消息重复怎么处理
kafka默认消息保证机制是at-least-once(至少一次),即保证消息不会丢失,但有可能会重复,因此在日常使用kafka时应当要考虑消息重复出现的场景,一般情况下,我们建议在每条消息中都带上唯一标识,业务上在处理时通过唯一标识来判断此条消息是否重复即可。(kafka的消费端应做好幂等检查)
5. push模式和pull模式
这里讨论的是消息在broker中时,consumer到底是自己去拉取消息,还是由broker进行推送,kafka的选择是由consumer自己来拉取消息。
为什么不让broker直接推消息呢?
首先,无论是生产者还是消费者肯定都是希望消息能尽快的被消费掉,基于这个事实,如果是由broker来推消息,那broker肯定是尽自己最大能力来推送,但如果broker推送的速率远远超过consumer消息的速率,那恐怕整个consumer集群都会被推崩溃,且也很平衡消费速率不同的consumer。
而采用消息拉取模式,则consumer可以自由控制消息消费频率,不至于被因推送了大量的消息而崩溃,当consumer消费能力远远低于消息的生产时,消息可以先由broker来管理,broker可以将消息先写在内存以及磁盘上,这样即可以保证消息的可靠性又可以实现削峰填谷的作用。
当然,拉取模式也并不是完美的,因为对于consumer来说,并不知道生产者到底有没有发送消息,所以必须通过不断的轮询方式来尝试拉取消息,如果消息的生产不是很频繁则会造成一定的资源浪费,除此之外,以什么样的频率来轮询,一次轮询拉取多少消息,如果consumer迟迟未轮询,是不是应该判定consumer挂了呢?等等这些都是采用轮询后需要考虑的地方。
6. 消息位点提交频繁怎么办
如果消息位点提交过于频繁,则会给kafka集群的性能以及稳定性带来一定的影响,建议采用自动提交,或通过其他方式来减少位点提交的频率。
7. 自动提交和手动提交怎么选?
首先要搞清,自动提交实际上是在每次调用poll方法时顺便提交的,因此即使你设置了自动提交,也到了auto.commit.interval.ms设置的时间,但如果没有调用poll方法,则也不会提交位点。
所以,考虑两种情况:
- 如果在
auto.commit.interval.ms之前,或者下一次poll调用之前,kafka异常退出了,则将导致消费位点未提交,从而在之后出现消息重复推送的问题。 - 如果在下一次poll数据时,前一次poll出来的数据还没有消费完毕,但到了
auto.commit.interval.ms设置的时间,则消费位点会被提交,从而出现位点跳跃的情况。
如果设置成手动提交,那就需要注意消息位点提交的频率,如上面第6点的问题,手动提交的情况下,可以选择调用commit(offsets)来控制位点的提交,这样也可以解决频繁提交的问题。
8. 消费失败了怎么办?
一般来说,消费者消费失败以后,不建议通过不断重新尝试消费的方式来处理,因为这样很有可能会造成消费线程的阻塞,导致消息积压,影响后续的任务继续执行。
当发现消费失败以后,建议通过类似告警的方式来进行通知,并且如果需要的话还可以将消息先丢到另一个专门用来存放失败消息的topic中,以便检查和分析失败原因。
9. 频繁Rebalance怎么办?
9.1 版本检查
v0.10.2之前版本的客户端:Consumer没有独立线程维持心跳,而是把心跳维持与poll接口耦合在一起。其结果就是,如果用户消费出现卡顿,就会导致Consumer心跳超时,引发Rebalance。
v0.10.2及之后版本的客户端:如果消费时间过慢,超过一定时间(max.poll.interval.ms设置的值,默认5分钟)未进行poll拉取消息,则会导致客户端主动离开队列,而引发Rebalance。
9.2 未能及时发送心跳请求
session.timeout.ms、heartbeat.interval.ms三个参数都将影响触发rebalance的条件。
9.3 减少Group订阅Topic的数量
一个Group订阅的Topic最好不要超过5个,建议一个Group只订阅一个Topic,以免因一个消费者故障影响其他消费者的一起故障的问题发生。
9.4 消费者消费时间间隔过长
消费者处理一批消息的时间不能超过max.poll.interval.ms的时间,要根据消费能力控制好max.poll.records值。
六、Kafka为什么能那么快
1. 架构设计
分区的设计,可实现消息的并行读写
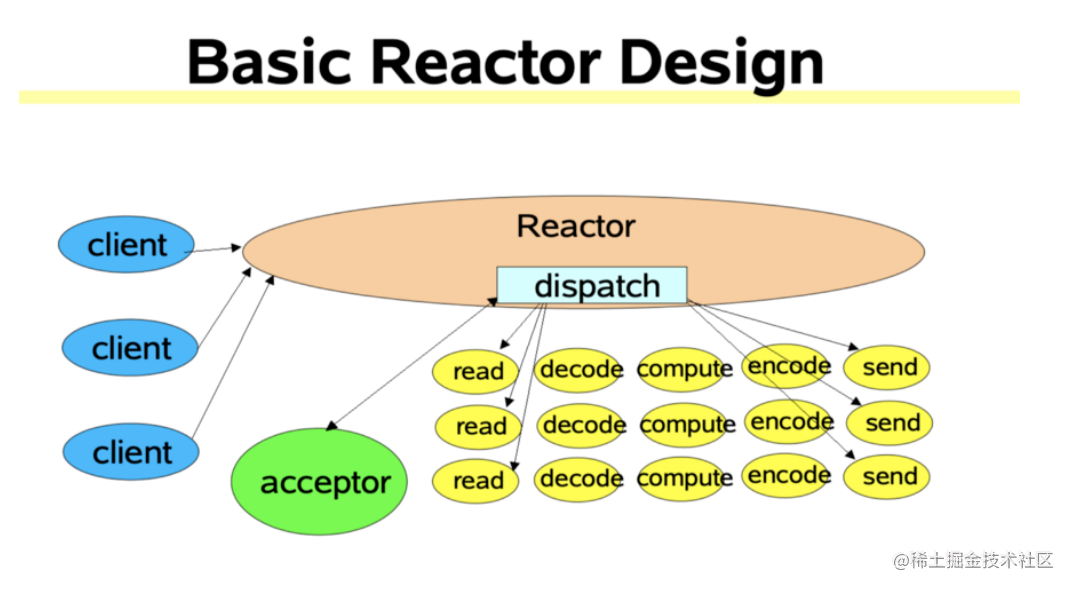
Reactor网络模型
Kafka基于Java NIO的基础上自己实现了一套和Netty一样的Reactor网络模型
发送与拉取的网络模型
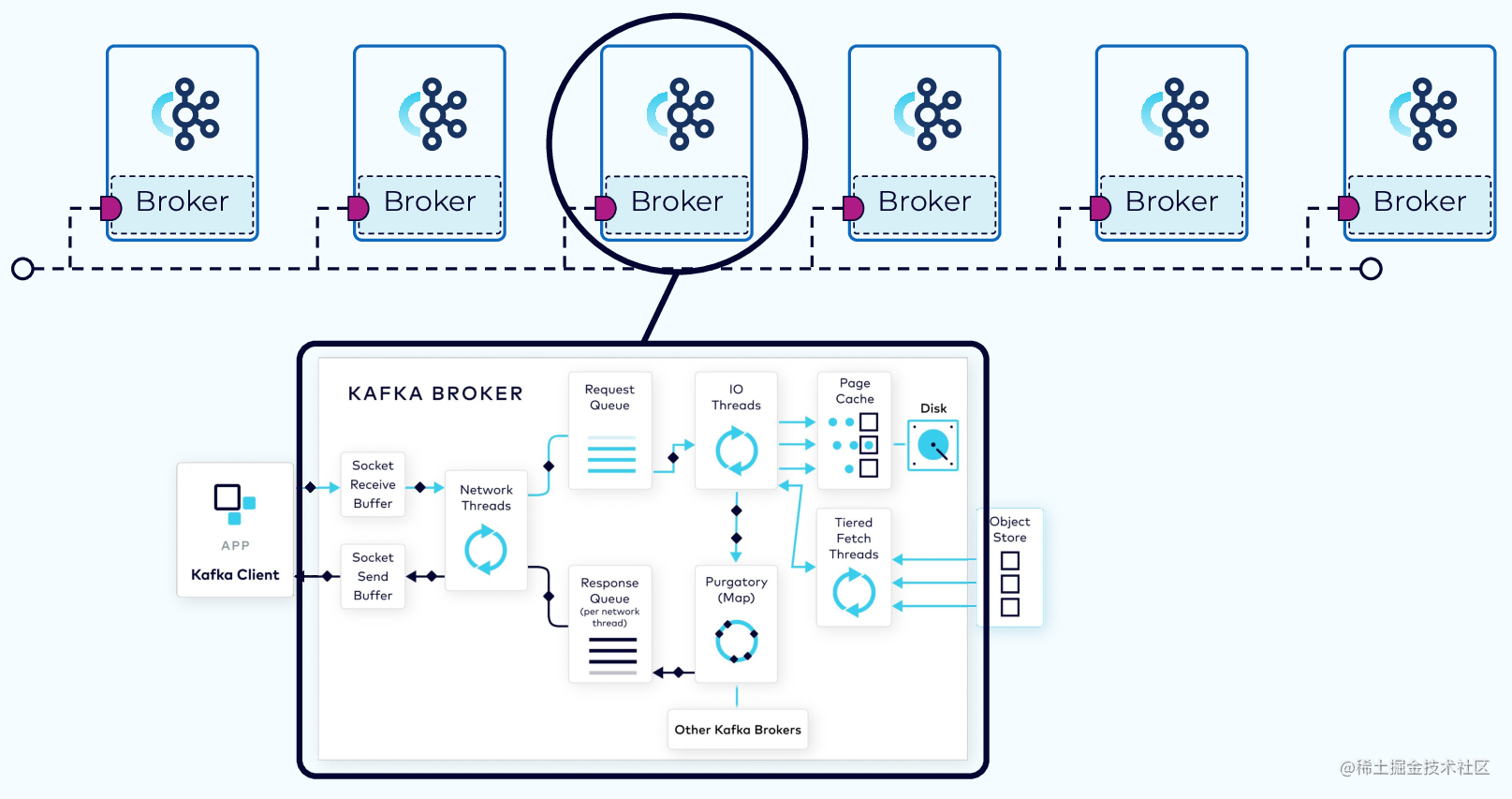
完整的流程
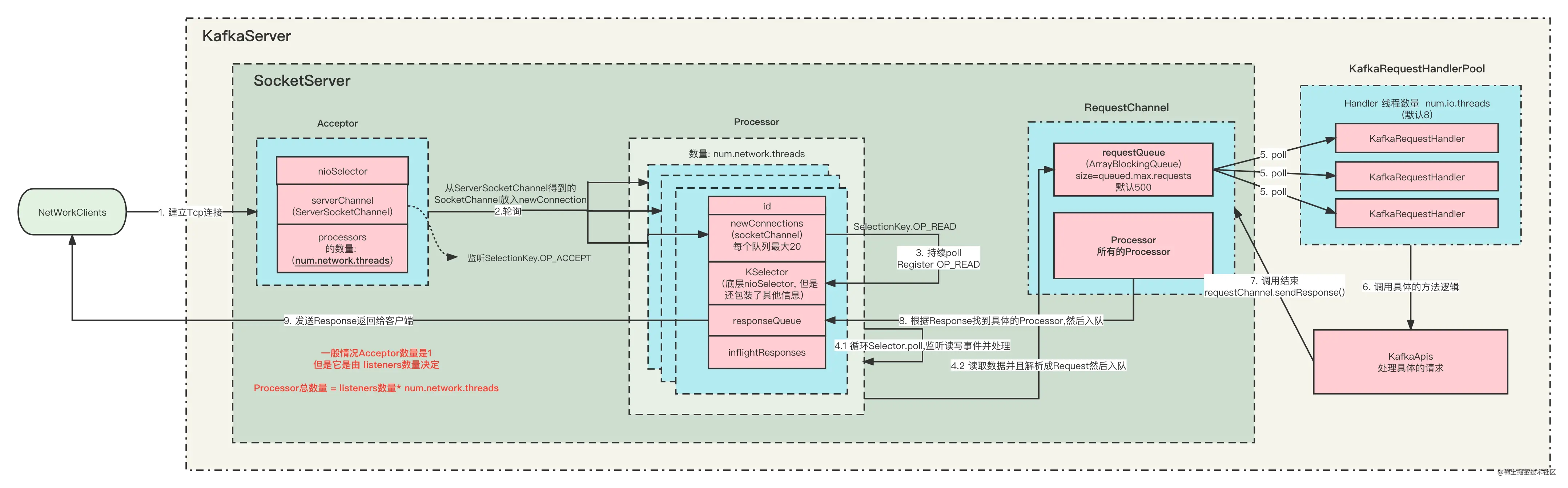
2. 批处理
为了提高发送的吞吐量,kafka的生产者在发送消息时并没有一条一条的发送,而是将多条消息打包成一个批次,其中batch.size和linger.ms就控制了批次的大小和等待的时间。
同时为了存储批次,kafka还自定义CopyOnWriteMap这样的数据结构,key是分区,value是要存储在该分区的批次(多个批次又是用队列来存放)。
CopyOnWriteMap适用于读多写少的场景,而在批处理中,只有当分区不存在时才会put一次,剩下来的全都是查询的场景,特别适用于写时复制的应用场景。
this.batches = new CopyOnWriteMap<>();
写操作
/**
* Get the deque for the given topic-partition, creating it if necessary.
*/
private Deque<ProducerBatch> getOrCreateDeque(TopicPartition tp) {
Deque<ProducerBatch> d = this.batches.get(tp);
if (d != null)
return d;
d = new ArrayDeque<>();
Deque<ProducerBatch> previous = this.batches.putIfAbsent(tp, d);
if (previous == null)
return d;
else
return previous;
}
读操作
private Deque<ProducerBatch> getDeque(TopicPartition tp) {
return batches.get(tp);
}
private List<ProducerBatch> drainBatchesForOneNode(Cluster cluster, Node node, int maxSize, long now) {
int size = 0;
List<PartitionInfo> parts = cluster.partitionsForNode(node.id());
List<ProducerBatch> ready = new ArrayList<>();
/* to make starvation less likely this loop doesn't start at 0 */
int start = drainIndex = drainIndex % parts.size();
do {
PartitionInfo part = parts.get(drainIndex);
TopicPartition tp = new TopicPartition(part.topic(), part.partition());
this.drainIndex = (this.drainIndex + 1) % parts.size();
// Only proceed if the partition has no in-flight batches.
if (isMuted(tp))
continue;
Deque<ProducerBatch> deque = getDeque(tp);
if (deque == null)
continue;
synchronized (deque) {
// invariant: !isMuted(tp,now) && deque != null
ProducerBatch first = deque.peekFirst();
if (first == null)
continue;
// first != null
boolean backoff = first.attempts() > 0 && first.waitedTimeMs(now) < retryBackoffMs;
// Only drain the batch if it is not during backoff period.
if (backoff)
continue;
if (size + first.estimatedSizeInBytes() > maxSize && !ready.isEmpty()) {
// there is a rare case that a single batch size is larger than the request size due to
// compression; in this case we will still eventually send this batch in a single request
break;
} else {
if (shouldStopDrainBatchesForPartition(first, tp))
break;
boolean isTransactional = transactionManager != null && transactionManager.isTransactional();
ProducerIdAndEpoch producerIdAndEpoch =
transactionManager != null ? transactionManager.producerIdAndEpoch() : null;
ProducerBatch batch = deque.pollFirst();
if (producerIdAndEpoch != null && !batch.hasSequence()) {
// If the batch already has an assigned sequence, then we should not change the producer id and
// sequence number, since this may introduce duplicates. In particular, the previous attempt
// may actually have been accepted, and if we change the producer id and sequence here, this
// attempt will also be accepted, causing a duplicate.
//
// Additionally, we update the next sequence number bound for the partition, and also have
// the transaction manager track the batch so as to ensure that sequence ordering is maintained
// even if we receive out of order responses.
batch.setProducerState(producerIdAndEpoch, transactionManager.sequenceNumber(batch.topicPartition), isTransactional);
transactionManager.incrementSequenceNumber(batch.topicPartition, batch.recordCount);
log.debug("Assigned producerId {} and producerEpoch {} to batch with base sequence " +
"{} being sent to partition {}", producerIdAndEpoch.producerId,
producerIdAndEpoch.epoch, batch.baseSequence(), tp);
transactionManager.addInFlightBatch(batch);
}
batch.close();
size += batch.records().sizeInBytes();
ready.add(batch);
batch.drained(now);
}
}
} while (start != drainIndex);
return ready;
}
我们知道批次的大小默认是16KB,如果每次构建都需要申请一块16KB大小的内存,发送完之后再回收,那可能会频繁的触发FGC,因此为了解决这个问题,Kafka也使用了内存池的方式,默认情况下会一次性构建好32M的内存空间,每次批次的构建与回收实际上都是像这个内存池来申请,这样就可以大大的减少FGC发生的频率。
3. 磁盘顺序写
当生产者的消息发送到broker中之后,broker实际上是会写到磁盘上的,我们都说写磁盘慢,远远不如写内存,其中的原因就是因为写磁盘往往需要经过寻道、磁盘旋转、数据传输三个过程,而其中的寻道和磁盘旋转是慢的主要原因,随机读写会造成大量的时间消耗在了机械运动上,磁头被不停的移来移去,如果能省去这两步,那么将大大提升读写磁盘的效率,而顺序读写,则刚好满足这样的场景。
举个例子:外卖小哥给一栋楼的住户送外卖,假如顺序是先10楼,1楼,9楼,2楼,8楼,3楼…就这就是随机,还有一种方式是1,2,3,4,5…这就是顺序。这样大家一看就明白了,如果按照第一种随机方式得累死外卖小哥。
我们常说的kafka分区是逻辑概念,在物理上分区实际上会被分割为多个segmenet,每个segment对应两个物理文件,一个是.log数据文件,一个是.index索引文件,而这两个物理文件就是采用顺序追加的方式来完成数据的写入的,当然读取时也只能从指定位置顺序读取。
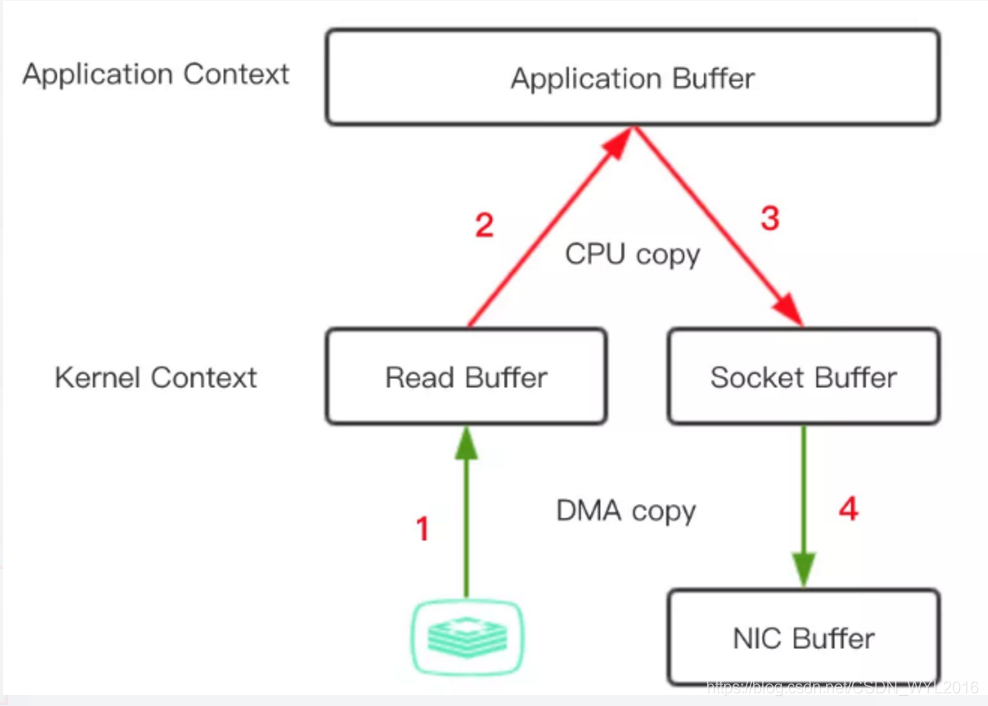
4. 零拷贝
当消费者从broker中拉取消息时,实际上kafka需要将消息从磁盘读取然后再给消费者,我们都知道传统的这一个过程需要经历4次数据copy和4次操作系统上下文切换,但是kafka利用了零拷贝技术,避免了磁盘数据复制到应用程序的过程,kafka读取时先看page cache中是否有数据,如果有直接从page cache拷贝到网卡设备(如果有DMA的支持,可只将描述符拷贝到socket缓冲区。操作系统缓冲区的内存地址和内存偏移量),否则从磁盘拷贝到page cache再拷贝到网卡设备,所以如果性能调优做的优秀,大多数消息就可以通过page cache获取,经历一次copy即可完成数据的传输,相当于在内存中完成了数据的读写。
传统的拷贝方式(4次拷贝和4次上下文切换)
- 执行read,操作系统从用户态切换到内核态,通过DMA将磁盘上的数据拷贝到内核空间的读缓冲区(read buffer)。
- 数据从内核空间的读缓冲区拷贝到用户缓冲区(user buffer),从内核态切换到用户态,此时用户可以操作数据。
- 执行write,从用户态切换到内核态,数据从用户缓冲区拷贝到内核空间的网络缓冲区(socket buffer)。
- 数据再从网络缓冲区拷贝到协议引擎,从内核态切换到用户态。
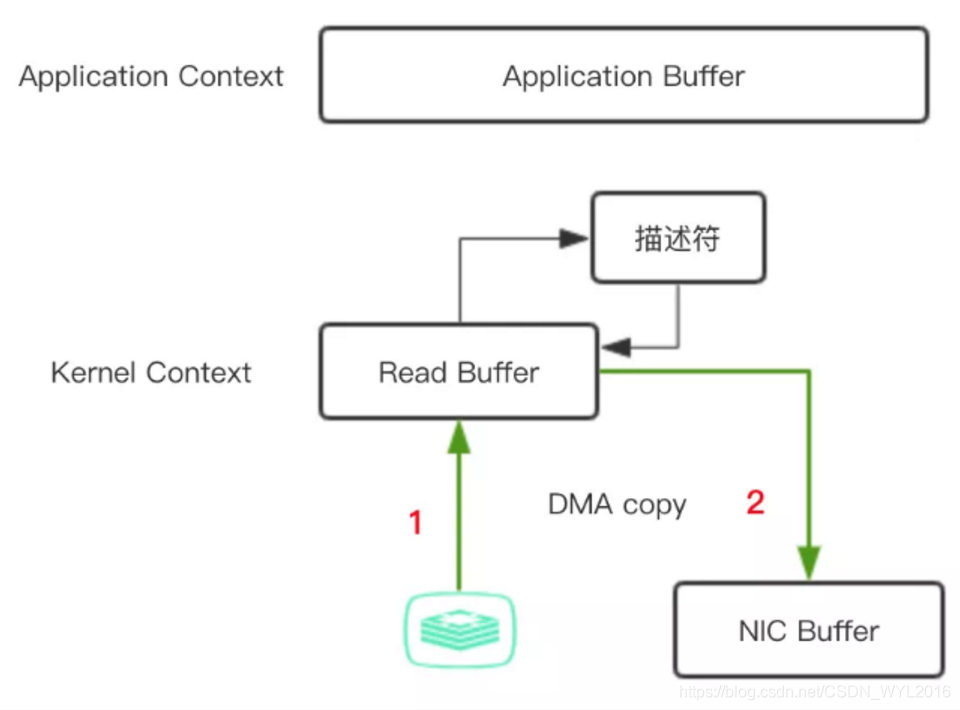
带收集功能的sendFile(2次拷贝和2次上下文切换)
- 执行read,操作系统从用户态切换到内核态,通过DMA将磁盘上的数据拷贝到内核空间的读缓冲区(read buffer)。
- 把数据的地址和偏移量追加到socket buffer。
- DMA直接从把数据从内核空间的读缓冲区拷贝到协议引擎,内核态切换回用户态。
在Java中,FileChannel的transferTo()方法可以实现这个过程。
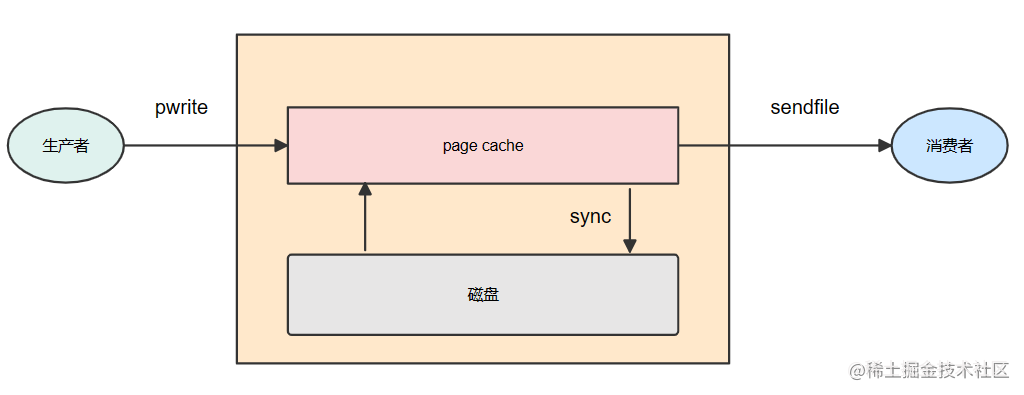
5. page cache
pagecache是操作系统提供的一种加快磁盘读写的方式,数据可以先写到page cache中,然后可通过一定的频率或者调用fsync函数刷到磁盘上,那么对于kafka来说,当生产者将消息发送到broker之后,broker会使用pwrite(对应到Java中就是FileChannel.write函数)系统调用,此时数据会写入page cache,消费者在消费消息时,broker使用的sendfile系统调用(对应到Java中就是FileChannel.transferTo函数),关于零拷贝如果利用page cache,上面讲零拷贝时已经介绍过了。
因此如果kafka生产者的生产速率和消费者的消费速率能保证较平衡的状态,那就相当于只需要通过page cache就能实现消息的读写操作,如此一来将大大的减少磁盘访问,从而提升整体性能。
七、生产上使用kafka的一些建议
使用原则建议
- 一个group不要订阅太多topic,否则很容易因为触发rebalance事件,而影响整个集群的稳定性。
- 生产者在发送消息时,为了保证消息能够打散到不同分区中,建议在发送时不要指定固定的key。
- Kafka以分区为粒度管理消息,分区多导致生产、存储、消费都碎片化,影响性能稳定性,因此在建立topic时不要盲目的创建很多分区。
- 建议对消息进行批量commit,不要每条消息commit一次,这样会导致CPU使用率过高。
- consumer数量如果超过了分区数,则超出的部分不会拉取到消息。
- kafka可以保证消息不丢失,但不能保证消息不重复,因此使用者一定要做好幂等性保护。
- kafka集群最少应由3个broker组成,且同步副本不能等于topic副本数,否则只要宕机1个副本就会导致无法生产消息。
- 单条消息大小不能太大,否则将影响集群吞吐。
- kafka的客户端一定要注意因GC、CPU使用率过高或其他原因导致的不可用,这将则色消息的生产和消费以及rebalance。
- 消费者组应按不同的业务进行区分,不要混在一起使用,以免因某一个消费者阻塞导致整个消费组阻塞,如果按业务分区的话,则可以降低业务影响范围。
参数建议
batch.size、linger.ms
这两个参数一般都是配合一起使用。
batch.size:当多条消息被发送到同一个分区时,生产者会尝试把多条消息变成批量发送。这有助于提高客户端和服务器的性能。此配置以字节为单位设置默认批处理大小。如果消息大于此配置的大小,将直接发送。发送到broker的请求将包含多个批处理,每个分区一个批处理,其中包含可发送的数据。
linger.ms:如果消息的大小一直达不到batch.size设置的值,那么linger.ms设置的时间后则允许直接发送消息,默认是不等待,即消息到来就发送。
当我们发送的消息都比较小的时候,可以通过设置linger.ms来减少请求的次数,批次中累积更多的消息后再发送,提高了吞吐量,减少了I/O请求。
如果设置的太大,则消息会被延迟更长的时间发送。
生产环境中一般建议batch.size保留默认设置:16KB,而linger.ms则设置为100~1000毫秒之间,一个合理的消息发送批次,可以有效降低客户端消息发送的频率,有利于提升kafka的整体消息发送的吞吐量。
buffer.memory、max.block.ms
buffer.memory:生产者可用于缓冲等待发送到服务器的记录的内存总字节数,如果客户端send的速度大于发送到broker的速度,且积压的消息大于这个设置的值,就会造成send阻塞,阻塞时间为max.block.ms设置的值,如果超过时间就抛出异常,buffer.memory默认大小为32m。
max.block.ms:当执行KafkaProducer.send()或者KafkaProducer.partitionsFor()时阻塞等待的时间,之所以会阻塞可能是因为buffer.memory满了或者获取元数据异常,一旦超过这个时间就会抛出异常,该值默认是60秒。
生产环境中一般建议buffer.memory大小为:batch.size * 分区数 * 2。
retries、retry.backoff.ms
retries:生产者发送时如果遇到的是可重试的异常时,则可进行发送的重试,此参数规定了重试的次数,默认值为Integer.MAX_VALUE。
retry.backoff.ms:主要用来控制请求发送异常后retries的请求频率,默认是100ms。
生产环境中由于网络等原因导致消息发送失败是常见的,因此建议开启重试消息发送,可重试3-5次,并保持默认重试的间隔频率,即1秒。
acks
关于acks前面已经介绍过了,生产上一般就建议使用默认为1。
max.poll.records、max.poll.interval.ms
max.poll.records:单次poll()的调用可返回的最大消息总数,默认是500条。
max.poll.interval.ms:这个参数就规定了,当调用poll()之后,如果在max.poll.interval.ms指定的时间内未消费完消息,也就是未再调用poll()方法,则Consumer会主动发起离开组的请求,从而产生Rebalance,默认是5分钟。
生产环境中max.poll.records的大小要根据单条消息的大小来评估单次拉取消息过大是否会对带宽以及内存造成一定影响,以及还要评估消费者的能力,单次拉取的消息能够在max.poll.interval.ms设置的时间内消费完。
对于max.poll.interval.ms参数而言,可能会因为未在规定时间内调用poll方法而产生Rebalance,所以要根据实际消费能力进行调整。
max.partition.fetch.bytes、fetch.max.bytes、fetch.min.bytes、fetch.max.wait.ms、message.max.bytes
max.partition.fetch.bytes:一个消费者一次fetch能拉取到的最大字节数,默认为1M。
fetch.max.bytes:broker能返回的消息(多个批次的集合)总大小的最大数据量,默认50M。
fetch.min.bytes:broker能返回的消息(多个批次的集合)总大小的最小数据量,默认1KB。
fetch.max.wait.ms:如果没有足够的数据立即满足fetch.min.bytes给定的要求,则broker在响应fetch请求之前将阻塞的最长时间,默认为500ms。
message.max.bytes:broker能处理的单条消息的最大大小,默认为1M。
生产环境中fetch.max.bytes、max.partition.fetch.bytes都要比单条消息的最大值稍大一点,同时max.partition.fetch.bytes的设置应大约为fetch.max.bytes的三分之一,fetch.min.bytes和fetch.max.wait.ms在没有确定需要调整的情况下,建议采用默认值。
session.timeout.ms、heartbeat.interval.ms
session.timeout.ms:表示当前consumer如果在指定时间内没有向服务端发送心跳报文则会被认为已经死亡,默认为10s。
heartbeat.interval.ms:这个参数配合session.timeout.ms一起使用,表示consumer向服务端发送心跳报文的频率,默认为3s。
生产环境中为了避免因意外情况,比如网络抖动,consumer端GC等,一般建议不要设置的太小,没有确定需要调整的情况下,建议采用默认值,而heartbeat.interval.ms一般不要大于session.timeout.ms的三分之一,甚至更低,以保证心跳报文发送的及时性。
enable.auto.commit、auto.commit.interval.ms
enable.auto.commit:用于控制consumer的消息offset是否是自动提交还是手动提交,默认为自动提交。
auto.commit.interval.ms:当设置为自动提交时,用于控制自动提交的频率,默认为1s。
关于自动提交和手动提交的设置,前面也介绍过,这里就不再赘述了。
unclean.leader.election.enable、replica.lag.time.max.ms
unclean.leader.election.enable:这个参数表明了什么样的副本才有资格竞争leader,如果设置成false,则表示对于落后太多的副本是没有资格竞选leader的,这样做的后果是可能永远选不出leader来了,如果是true,那么则有可能选出一个差很多数据的副本成为leader,从而造成了数据丢失,此值默认是false。
replica.lag.time.max.ms:这个参数就定义了上面副本落后的标准,其表示follower副本能够落后leader副本的最长时间间隔,默认值为10秒,只要不超过10秒,就不算是落后的副本。
关于这两个参数的设置前面也有过介绍,这里就不再赘述了。
num.io.threads、num.network.threads
num.io.threads:表示每个broker启动后自动创建的I/O线程数量,I/O线程是真正处理请求的线程,默认是8个。
num.network.threads:表示每个broker启动时专门用于从网络接收请求并向网络发送响应的线程数量,默认是3个。
Kafka会通过使用网络线程来专门接收客户端的请求与和发送响应,但是当收到请求之后网络线程并不是真正的由自己来处理,而是丢到一个共享请求队列中,此时就会由另一个线程池中的线程来处理,也就是I/O线程,它会专门负责从共享队列中取出请求,执行真正的处理。
这两个参数也是一样,没有明确的表明需要对其进行调整时,建议使用默认值。
auto.offset.reset
消费位点重置的策略,一共分为三种:
- latest:从最大位点开始消费。
- earliest:从最小位点开始消费。
- none:不做任何操作,即不重置。
默认为latest。
需要进行位点重置的场景一般是当客户端要拉取一个无效偏移量,比如记录的偏移量为10,客户端却要从20开始拉取。又或者是服务端压根就没有记录过之前提交的偏移量,比如客户端第一次上线时。
生成上一般建议设置为latest,这样可以避免因位点非法时从头开始消费,从而造成大量的重复消息。
八、与springboot整合
1. jar包引入
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2. 自定义生产者
@Configuration
@EnableKafka
public class KafkaProducerConfig {
// 从配置文件中读取
@Value("${kafka.producer.servers}")
private String servers;
@Value("${kafka.producer.retries}")
private int retries;
@Value("${kafka.producer.batch.size}")
private int batchSize;
@Value("${kafka.producer.linger}")
private int linger;
@Value("${kafka.producer.buffer.memory}")
private int bufferMemory;
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
props.put(ProducerConfig.RETRIES_CONFIG, retries);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
props.put(ProducerConfig.LINGER_MS_CONFIG, linger);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 自己修改的一些配置
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.wyl.config.MySelfPartitioner");
props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 1000);
props.put(ProducerConfig.LINGER_MS_CONFIG, 1000);
return props;
}
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
KafkaTemplate kafkaTemplate
= new KafkaTemplate(producerFactory()) ;
return kafkaTemplate;
}
}
3. 自定义消费者
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Value("${kafka.consumer.servers}")
private String servers;
@Value("${kafka.consumer.enable.auto.commit}")
private boolean enableAutoCommit;
@Value("${kafka.consumer.session.timeout}")
private String sessionTimeout;
@Value("${kafka.consumer.auto.commit.interval}")
private String autoCommitInterval;
@Value("${kafka.consumer.group.id}")
private String groupId;
@Value("${kafka.consumer.auto.offset.reset}")
private String autoOffsetReset;
@Value("${kafka.consumer.concurrency}")
private int concurrency;
public Map<String, Object> consumerConfigs() {
Map<String, Object> propsMap = new HashMap<>();
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitInterval);
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeout);
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
return propsMap;
}
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
// listener可以使用@Bean,也可以在类上使用@Component。
@Bean
public MyListener listener() {
return new MyListener();
}
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>>
kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory
= new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
}
4. KafkaListener
public class MyListener {
private static final Logger LOGGER = LoggerFactory.getLogger(MyListener.class);
@KafkaListener(id = "test_topic_listener", topics = {"test_topic"})
public void consumer(ConsumerRecord<String, String> consumerRecord, Acknowledgment ack) {
try {
LOGGER.info("接收topic为: {},key为:{},value为:{},offset:{},partition:{}",
consumerRecord.topic(), consumerRecord.key(), consumerRecord.value(), consumerRecord.offset(), consumerRecord.partition());
} catch (Exception e) {
LOGGER.error("kafka 监听异常:{}", e);
} finally {
ack.acknowledge();
}
}
}
5. 大致实现流程分析
5.1. KafkaAutoConfiguration注入
一般直接通过spring.factories方式自动装配KafkaAutoConfiguration,然后又会注入KafkaBootstrapConfiguration,其会构建KafkaListenerAnnotationBeanPostProcessor实例,而KafkaListenerAnnotationBeanPostProcessor实现了BeanPostProcessor,那自然存在postProcessBeforeInitialization和postProcessAfterInitialization两个关键方法。
5.2. 扫描@KafkaListener
KafkaListenerAnnotationBeanPostProcessor会利用postProcessAfterInitialization方法扫描@KafkaListener注解
@Override
public Object postProcessAfterInitialization(final Object bean, final String beanName) throws BeansException {
if (!this.nonAnnotatedClasses.contains(bean.getClass())) {
Class<?> targetClass = AopUtils.getTargetClass(bean);
// 收集注解方法
Collection<KafkaListener> classLevelListeners = findListenerAnnotations(targetClass);
final boolean hasClassLevelListeners = classLevelListeners.size() > 0;
final List<Method> multiMethods = new ArrayList<Method>();
Map<Method, Set<KafkaListener>> annotatedMethods = MethodIntrospector.selectMethods(targetClass,
new MethodIntrospector.MetadataLookup<Set<KafkaListener>>() {
@Override
public Set<KafkaListener> inspect(Method method) {
Set<KafkaListener> listenerMethods = findListenerAnnotations(method);
return (!listenerMethods.isEmpty() ? listenerMethods : null);
}
});
if (hasClassLevelListeners) {
Set<Method> methodsWithHandler = MethodIntrospector.selectMethods(targetClass,
new ReflectionUtils.MethodFilter() {
@Override
public boolean matches(Method method) {
return AnnotationUtils.findAnnotation(method, KafkaHandler.class) != null;
}
});
multiMethods.addAll(methodsWithHandler);
}
if (annotatedMethods.isEmpty()) {
this.nonAnnotatedClasses.add(bean.getClass());
if (this.logger.isTraceEnabled()) {
this.logger.trace("No @KafkaListener annotations found on bean type: " + bean.getClass());
}
}
else {
// Non-empty set of methods
for (Map.Entry<Method, Set<KafkaListener>> entry : annotatedMethods.entrySet()) {
Method method = entry.getKey();
for (KafkaListener listener : entry.getValue()) {
// 遍历处理
processKafkaListener(listener, method, bean, beanName);
}
}
if (this.logger.isDebugEnabled()) {
this.logger.debug(annotatedMethods.size() + " @KafkaListener methods processed on bean '"
+ beanName + "': " + annotatedMethods);
}
}
if (hasClassLevelListeners) {
processMultiMethodListeners(classLevelListeners, multiMethods, bean, beanName);
}
}
return bean;
}
protected void processKafkaListener(KafkaListener kafkaListener, Method method, Object bean, String beanName) {
Method methodToUse = checkProxy(method, bean);
MethodKafkaListenerEndpoint<K, V> endpoint = new MethodKafkaListenerEndpoint<K, V>();
endpoint.setMethod(methodToUse);
endpoint.setBeanFactory(this.beanFactory);
processListener(endpoint, kafkaListener, bean, methodToUse, beanName);
}
protected void processListener(MethodKafkaListenerEndpoint<?, ?> endpoint, KafkaListener kafkaListener, Object bean,
Object adminTarget, String beanName) {
// 把kafkaListener中的属性封装成对象
endpoint.setBean(bean);
endpoint.setMessageHandlerMethodFactory(this.messageHandlerMethodFactory);
endpoint.setId(getEndpointId(kafkaListener));
endpoint.setTopicPartitions(resolveTopicPartitions(kafkaListener));
endpoint.setTopics(resolveTopics(kafkaListener));
endpoint.setTopicPattern(resolvePattern(kafkaListener));
String group = kafkaListener.containerGroup();
if (StringUtils.hasText(group)) {
Object resolvedGroup = resolveExpression(group);
if (resolvedGroup instanceof String) {
endpoint.setGroup((String) resolvedGroup);
}
}
KafkaListenerContainerFactory<?> factory = null;
String containerFactoryBeanName = resolve(kafkaListener.containerFactory());
if (StringUtils.hasText(containerFactoryBeanName)) {
Assert.state(this.beanFactory != null, "BeanFactory must be set to obtain container factory by bean name");
try {
factory = this.beanFactory.getBean(containerFactoryBeanName, KafkaListenerContainerFactory.class);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanInitializationException("Could not register Kafka listener endpoint on [" + adminTarget
+ "] for bean " + beanName + ", no " + KafkaListenerContainerFactory.class.getSimpleName()
+ " with id '" + containerFactoryBeanName + "' was found in the application context", ex);
}
}
// 交给KafkaListenerEndpointRegistry处理
this.registrar.registerEndpoint(endpoint, factory);
}
public void registerEndpoint(KafkaListenerEndpoint endpoint, KafkaListenerContainerFactory<?> factory) {
Assert.notNull(endpoint, "Endpoint must be set");
Assert.hasText(endpoint.getId(), "Endpoint id must be set");
// Factory may be null, we defer the resolution right before actually creating the container
KafkaListenerEndpointDescriptor descriptor = new KafkaListenerEndpointDescriptor(endpoint, factory);
synchronized (this.endpointDescriptors) {
if (this.startImmediately) { // Register and start immediately
this.endpointRegistry.registerListenerContainer(descriptor.endpoint,
resolveContainerFactory(descriptor), true);
}
else {
this.endpointDescriptors.add(descriptor);
}
}
}
5.3. registerListenerContainer注册监听
public void registerListenerContainer(KafkaListenerEndpoint endpoint, KafkaListenerContainerFactory<?> factory,
boolean startImmediately) {
Assert.notNull(endpoint, "Endpoint must not be null");
Assert.notNull(factory, "Factory must not be null");
String id = endpoint.getId();
Assert.hasText(id, "Endpoint id must not be empty");
synchronized (this.listenerContainers) {
Assert.state(!this.listenerContainers.containsKey(id),
"Another endpoint is already registered with id '" + id + "'");
// 创建ConcurrentMessageListenerContainer
MessageListenerContainer container = createListenerContainer(endpoint, factory);
this.listenerContainers.put(id, container);
if (StringUtils.hasText(endpoint.getGroup()) && this.applicationContext != null) {
List<MessageListenerContainer> containerGroup;
if (this.applicationContext.containsBean(endpoint.getGroup())) {
containerGroup = this.applicationContext.getBean(endpoint.getGroup(), List.class);
}
else {
containerGroup = new ArrayList<MessageListenerContainer>();
this.applicationContext.getBeanFactory().registerSingleton(endpoint.getGroup(), containerGroup);
}
containerGroup.add(container);
}
if (startImmediately) {
// 开启监听入口
startIfNecessary(container);
}
}
}
private void startIfNecessary(MessageListenerContainer listenerContainer) {
if (this.contextRefreshed || listenerContainer.isAutoStartup()) {
listenerContainer.start();
}
}
@Override
public final void start() {
synchronized (this.lifecycleMonitor) {
Assert.isTrue(
this.containerProperties.getMessageListener() instanceof KafkaDataListener,
"A " + KafkaDataListener.class.getName() + " implementation must be provided");
doStart();
}
}
5.4. 启动线程处理
@Override
protected void doStart() {
if (!isRunning()) {
ContainerProperties containerProperties = getContainerProperties();
TopicPartitionInitialOffset[] topicPartitions = containerProperties.getTopicPartitions();
if (topicPartitions != null
&& this.concurrency > topicPartitions.length) {
this.logger.warn("When specific partitions are provided, the concurrency must be less than or "
+ "equal to the number of partitions; reduced from " + this.concurrency + " to "
+ topicPartitions.length);
this.concurrency = topicPartitions.length;
}
setRunning(true);
// 根据主题中的分区数和concurrency数计算,决定创建多少KafkaMessageListenerContainer,也就是开启多少线程
for (int i = 0; i < this.concurrency; i++) {
KafkaMessageListenerContainer<K, V> container;
if (topicPartitions == null) {
container = new KafkaMessageListenerContainer<>(this.consumerFactory, containerProperties);
}
else {
container = new KafkaMessageListenerContainer<>(this.consumerFactory, containerProperties,
partitionSubset(containerProperties, i));
}
if (getBeanName() != null) {
container.setBeanName(getBeanName() + "-" + i);
}
if (getApplicationEventPublisher() != null) {
container.setApplicationEventPublisher(getApplicationEventPublisher());
}
container.setClientIdSuffix("-" + i);
//KafkaMessageListenerContainer的doStart()
container.start();
this.containers.add(container);
}
}
}
@Override
protected void doStart() {
if (isRunning()) {
return;
}
ContainerProperties containerProperties = getContainerProperties();
if (!this.consumerFactory.isAutoCommit()) {
AckMode ackMode = containerProperties.getAckMode();
if (ackMode.equals(AckMode.COUNT) || ackMode.equals(AckMode.COUNT_TIME)) {
Assert.state(containerProperties.getAckCount() > 0, "'ackCount' must be > 0");
}
if ((ackMode.equals(AckMode.TIME) || ackMode.equals(AckMode.COUNT_TIME))
&& containerProperties.getAckTime() == 0) {
containerProperties.setAckTime(5000);
}
}
Object messageListener = containerProperties.getMessageListener();
Assert.state(messageListener != null, "A MessageListener is required");
if (messageListener instanceof GenericAcknowledgingMessageListener) {
this.acknowledgingMessageListener = (GenericAcknowledgingMessageListener<?>) messageListener;
}
else if (messageListener instanceof GenericMessageListener) {
this.listener = (GenericMessageListener<?>) messageListener;
}
else {
throw new IllegalStateException("messageListener must be 'MessageListener' "
+ "or 'AcknowledgingMessageListener', not " + messageListener.getClass().getName());
}
if (containerProperties.getConsumerTaskExecutor() == null) {
SimpleAsyncTaskExecutor consumerExecutor = new SimpleAsyncTaskExecutor(
(getBeanName() == null ? "" : getBeanName()) + "-C-");
containerProperties.setConsumerTaskExecutor(consumerExecutor);
}
if (containerProperties.getListenerTaskExecutor() == null) {
SimpleAsyncTaskExecutor listenerExecutor = new SimpleAsyncTaskExecutor(
(getBeanName() == null ? "" : getBeanName()) + "-L-");
containerProperties.setListenerTaskExecutor(listenerExecutor);
}
//创建ListenerConsumer
this.listenerConsumer = new ListenerConsumer(this.listener, this.acknowledgingMessageListener);
setRunning(true);
//开启ListenerConsumer线程
this.listenerConsumerFuture = containerProperties
.getConsumerTaskExecutor()
.submitListenable(this.listenerConsumer);
}
5.5. 循环拉取消息
@Override
public void run() {
if (this.theListener instanceof ConsumerSeekAware) {
((ConsumerSeekAware) this.theListener).registerSeekCallback(this);
}
this.count = 0;
this.last = System.currentTimeMillis();
if (isRunning() && this.definedPartitions != null) {
initPartitionsIfNeeded();
// we start the invoker here as there will be no rebalance calls to
// trigger it, but only if the container is not set to autocommit
// otherwise we will process records on a separate thread
if (!this.autoCommit) {
startInvoker();
}
}
long lastReceive = System.currentTimeMillis();
long lastAlertAt = lastReceive;
while (isRunning()) {
try {
if (!this.autoCommit) {
processCommits();
}
processSeeks();
if (this.logger.isTraceEnabled()) {
this.logger.trace("Polling (paused=" + this.paused + ")...");
}
// 拉取消息
ConsumerRecords<K, V> records = this.consumer.poll(this.containerProperties.getPollTimeout());
if (records != null && this.logger.isDebugEnabled()) {
this.logger.debug("Received: " + records.count() + " records");
}
if (records != null && records.count() > 0) {
if (this.containerProperties.getIdleEventInterval() != null) {
lastReceive = System.currentTimeMillis();
}
// if the container is set to auto-commit, then execute in the
// same thread
// otherwise send to the buffering queue
if (this.autoCommit) {
// 自动提交直接调用@kafkaListener注解的方法
invokeListener(records);
}
else {
// 非自动提交把消息放入队列中
if (sendToListener(records)) {
if (this.assignedPartitions != null) {
// avoid group management rebalance due to a slow
// consumer
this.consumer.pause(this.assignedPartitions);
this.paused = true;
this.unsent = records;
}
}
}
}
else {
if (this.containerProperties.getIdleEventInterval() != null) {
long now = System.currentTimeMillis();
if (now > lastReceive + this.containerProperties.getIdleEventInterval()
&& now > lastAlertAt + this.containerProperties.getIdleEventInterval()) {
publishIdleContainerEvent(now - lastReceive);
lastAlertAt = now;
if (this.theListener instanceof ConsumerSeekAware) {
seekPartitions(getAssignedPartitions(), true);
}
}
}
}
this.unsent = checkPause(this.unsent);
}
catch (WakeupException e) {
this.unsent = checkPause(this.unsent);
}
catch (Exception e) {
if (this.containerProperties.getGenericErrorHandler() != null) {
this.containerProperties.getGenericErrorHandler().handle(e, null);
}
else {
this.logger.error("Container exception", e);
}
}
}
if (this.listenerInvokerFuture != null) {
stopInvoker();
commitManualAcks();
}
try {
this.consumer.unsubscribe();
}
catch (WakeupException e) {
// No-op. Continue process
}
this.consumer.close();
if (this.logger.isInfoEnabled()) {
this.logger.info("Consumer stopped");
}
}
6. 流程总结















 4404
4404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











