






numpy包的应用
import numpy as np
np.min[1,5,2,3]
np.argmax[1,5,2,3]
a=np.array([2,3,-5,6])
import pandas as pd
s = pd.Series([1,2,5,6],index=[‘a’,‘b’,‘f’,‘g’])

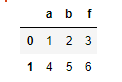
data = pd.DataFrame([[1,2,3],[4,5,6]],columns=[‘a’,‘b’,‘f’])
data=pd.read_excel(‘c:\数据.xlsx’)
import matplotlib.pyplot as plt
x=np.linspace(0,10,10000)
y=np.sin(x)
plt.plot(x,y,label=‘y=sinx’,color=‘red’,linewidth=2)
plt.xlabel(‘Times’)
plt.ylabel(‘Vol’)
plt.title(‘this is line’)
plt.legend(loc=‘center’)
plt.show()
from numpy import size
size([5,6,8,4,2])
json文件解析
import json
with open(‘e:\data\sample1.json’,encoding=‘utf-8’,mode=‘r’)
f_read=f.read()
转换成字典,进行访问
filter起到过滤的作用返回真实值
from numpy import size
size([5,6,8,4,2])
arr2=np.array([-2,4,8,6],dtype=‘str’)
np.arange(0,10,0.5)
np.linspace(1,10,10,endpoint=False)#会扔掉最后一个
np.linspace(1,10,11)等差数列
等比数列:
np.logspace(1,5,base=2,num=10)
2**linspace(1,5,10)
np.zeros(6)
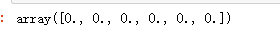
np.zeros([6,8])

np.ones([7,5])

np.eye(6)

np.diag([5,9,6])

np.array([5,6,8])+1
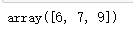
arr2.shape
arr2.ndim
arr2.size
arr2.dtype
arr_change=arr.copy()
arr_change[1:3]=[6,4]

data2=((1,5,2,3,75,6,1),(4,8,5,61,2,12,4),(7,8,9,4,5,6,6),(12,5,7,8,4,5,6))
arr2=np.array(data2)
arr2[2,5]
arr2[2][5]
arr2[1:,2:]
arr2[arr2>3.5]
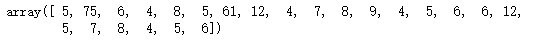
arr2[~(arr2>=3.5)] 取反,取出小于3.5的值
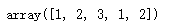
arr2[(arr2>3.5)&(arrarr2[(arr2>3.5)&(arr2<10)]2<10)]
arr2[(arr2>3.5)&(arr2<10)]
arr2[[2,1]] #访问第三行和第二行
arr2[[3,2],[0,2]] #输出(3,0)和(2,2)位置上的数字
arr2[:,[3,1,5]] #输出对行数不做限制,对列数输出第4列,第2列,第6列
arr2[:,1] #取出的数据1维
arr2[:,[1]] #取出的数据是2维的
arr2[[1,-1],[0,1]]
arr2[np.ix_([0,-1],[0,1,3])]
np.ix_([0,-1],[0,1,3])
arr2[[0,-1]][:,[0,1,3]]
arr.reshape(14,2) #展现视图,不会改变原数组的结构
arr.resize(14,2) #改变原数组的结构
arr.shape=(14,2) #改变原数组的结构
arr.ravel() #以横向降为一维
arr.ravel(order=‘F’) #以纵向降为一维
arr.reshape(2,-1) #以横向来排列列表中的数据,2行
arr.reshape(1,-1) #返回一个一行的列表 arr.shape(-1)
arr.flatten()[1]=1000 #将元素做了修改,原函数不会发生改变
arr.ravel()[1]=100 #将元素做了修改,且原函数发生了改变

arr.reshape(-1)[3]=103 #将横排的第四个数字取出来,并进行改变,改变之后原数组发生了变化
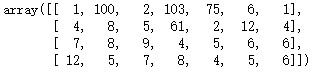
三种方式都不会改变原数组的形状
arr_t[np.newaxis,:] #添加维度数行或者列
arr_t[:,np.newaxis]

arr1=np.arange(28).reshape(7,4) #改变数列的形状
#数组按行合并
np.hstack([arr1,arr2])
np.hstack((arr1,arr2))

np.vstack((arr1,arr2)) #纵向合并

np.concatenate((arr1,arr2),axis=1) #增加列数,不增加行数

np.concatenate((arr1,arr2),axis=0) #增加列数来合并

np.tile(arr4,(4,1)) #沿着行数或者列数进行复制

三维数组:

取出元素:
arr5[0][0][0]
arr5[0,0,0]
数组函数的广播机制
ufun通用函数,能够对array中所有元素进行操作的函数
broadcasting指对不同形状的array之间执行算术运算的方式
不同的形状的数组运算时,Numpy则会执行广播机制
numpy能够运用向量化运算处理整个数组,所以速度比较快
arr1+arr2 #相同形状数组相加
不同形状相加,执行广播机制,行或者列要相等


加法、减法的运算
np.subtract(math,english) #除法

除法运算,乘法运算,幂次运算

s=np.array([1,2,34,5,8,6,78,9,6,2,3,1,2,3])
test=[2,5,6]
np.unique(s) #去重运算
np.inld(s,test) #判断s中的元素是否在test里面
np.intersectld(test,s) #判断两个列表中的相同元素,集合运算
arr1 == arr2 #判断两者是否相等

np.equal(arr1,arr2)

np.greater(arr1,arr2) #比较两个列表元素的大小
另一种写法:arr1 >arr2
np.greater(arr1,arr2).any() 只要有一个为真就返回true
np.greater(arr1,arr2).all() 全部为真就返回true
np.isnan(s) 判断是否为空
列表中元素排序:
np.sort(s)
sorted(s,reverse=True)
np.argsort(s) #返回排完序以后索引值
s.argmax() #返回值最大的元素的下标
s.argmin() #返回值最小的元素的下标
arr.argmax(axis=1) #返回每一行中的最大的元素下标
arr1.argmax(axis=0) #返回每一列中的最大的元素下标

np.where(arr2>3,‘1’,‘0’) #大于3的返回1,否则返回0
np.where(arr2>arr1,arr1,arr2) #返回列表中的元素

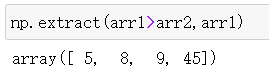
np.extract(arr1>arr2,arr1) #只提取满足条件的元素进行输出
data=np.genfromtxt(r’E:\python\python_practice\aa.txt’,delimiter=’,’)
delimiter 分隔符
data=np.genfromtxt(r’E:\python\python_practice\aa.csv’,delimiter=’,’,skip_header=1)
读取CSV文件,跳过表头
data=np.loadtxt(r’E:\python\python_practice\aa.csv’,delimiter=’,’)
一般不会用numpy来读取数据,会使用pandas来读取
存储数据:
np.savetxt(路径,data,delimiter,fmt)
np.savetxt(r’E:\python\python_practice\array.txt’,data,delimiter=’,’,fmt=’%.3f’)
np.savetxt(r’E:\python\python_practice\array.csv’,data,delimiter=’,’,fmt=’%.3f’)
小写转大写:
np.char.upper(str_list)
做数据处理,用numpy函数效率会高很多
字符串的连接:
np.char.add([‘中国’,‘国庆’],[‘海军’,‘大阅兵’])

重复数组元素:
np.char.multiply([‘中国’,‘你好’],3)

np.char.join([’:’,’-’],[‘hello’,‘world’])

字符串的替换:
np.char.replace(a,‘学习’,‘深入学习’)

np.char.strip([’-电动汽车’,‘海洋科技-’,’-学习python’],’-’)

f=open(r’E:\python\python_practice\array.txt’,encoding=‘utf-8’).readlines()
使用空格进行分割:
arr=f.split(’\t’)’
arr=np.char.rstrip(arr,’\n’) 去除空格
arr=np.char.replace(arr,’"’,’’) 将文件中的符号进行替换
np.char.find(arr,‘学习’) 找到相应的位置。没找到返回-1,找到返回坐标
计数:
np.char.count(arr,‘金融’)
np.random.random() #产生0-1之间的随机数
np.random.random([3,4]) #产生一个3行4列的随机数
给随机数种子后,每次运行产生的随机数就一样了:
np.random.seed(1256)
np.random.random((3,4))
np.random.randint(0,100,size=[100,100]) #产生0到100之间的随机整数,100行100列
np.random.uniform(low=0,high=100,size=100) #产生给定范围的随机数
np.set_printoptions(precision=2) #控制产生的随机数的小数位数

np.random.normal(1,3,size=100) 生成均值为1,标准差为3的正态分布的随机数
np.mean(np.random.normal(1,3,size=100000))
np.std(np.random.normal(1,3,size=100000))

np.random.randn(10,100) 标准正态分布
np.random.randn(10,2)


np.random.shuffle(s) 对数组进行随机排序,直接作用在数组上
np.random.permutation(s) 对数组进行随机排序,不会直接作用在数组上
numpy中的统计函数
data=np.genfromtxt(r’E:\python\python_practice\aa.csv’,delimiter=’,’,skip_header=1)
data.sum(axis=0) # 沿着行的方向作用
data[:,1].mean(axis=1) # 沿着行的方向作用
data.cumsum(axis=0) #累积求和
data.cumprod() 累积求积
data.max(axis=1) 求每一行的最大值是多少
np.percentile(data,50) 计算分位数
np.median(data) 计算中位数
np.percentile(data,[10,20,30,40,50,60])
np.ptp(data) 计算极差 data.max()-data.min()
np.ptp(axis=1)
np.sum(data>0.3) 统计相关数据
vector=np.dot(a,b) 点积

arr5=np.array([5,15,26,45]).reshape(4,1)

矩阵之间的点积:

np.transpose(arr2) 求矩阵的转置
arr2_inv = np.linalg.inv(arr2) 对矩阵进行求逆

np.set_printoptions(precision=2) 解决矩阵格式的问题

控制格式问题

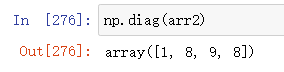
np.diag(arr2) 取出aar2中的对角线上的元素
线性代数的numpy实现:

pandas 包
Series数据结构和DataFrame数据结构
#创建一个Series对象
series1=pd.Series([2.8,3.61,45.34])

创建索引:
series1=pd.Series([2.8,3.61,45.34,2.68,69.4],index=[‘a’,‘b’,‘c’,‘d’,‘e’],name=‘This is Series!’)

另一种创建方式:

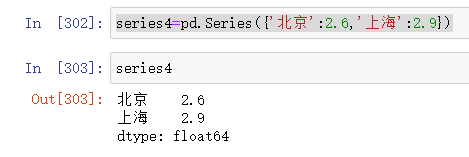
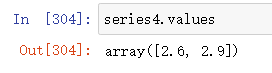
其他创建方法:series4=pd.Series({‘北京’:2.6,‘上海’:2.9})
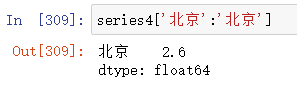
查看索引:

python左开右闭

给标签就不会是左开右闭
series4.append(series5) 将两个序列拼接在一起

对series数据结构进行操作

series6.drop(‘四川’,inplace=True) 修改原表

DataFrame数据结构
df1=pd.DataFrame(list1,columns=[‘姓名’,‘年龄’,‘性别’]) 创建该数据结构

df2=pd.DataFrame({‘姓名’:[‘张三’,‘李四’,‘王二’],‘年龄’:[23,52,45],‘性别’:[‘男’,‘女’,‘男’]}) 创建dataframe数据结构

df3=pd.DataFrame(array1,columns=[‘姓名’,‘年龄’,‘性别’],index=[‘a’,‘b’,‘c’])
创建数据结构

查看数据类型

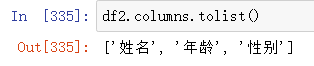
df2.columns.tolist() 得到列的名称
查看数据的维度、索引等

如果要读的文档中有中文,可以加:encoding=‘gbk’

查看前5行,后5行

只读取前10行 nrows=10
定义缺失值 na_values=70

df=pd.read_csv(r’E:\python\python_practice\aa.csv’,encoding=‘gbk’,dtype={‘info_id’:str,‘emp_id’:str},nrows=10,na_values=70,header=0)

读取Excel文件:
df=pd.read_excel(‘E:\python\python_practice\python_exclce.xlsx’,encoding = ‘utf-8’,sheet_name=‘Sheet1’,dtype={‘detail_id’:str})

读取Excel文件中的所有表:
sheet_name=['Sheet' + str(i) for i in range(1,4)]
for i in sheet_name:
data=pd.read_excel('E:\python\python_practice\python_exclce.xlsx',sheet_name=i,dtype={'detail_id':str})
data_all=pd.concat([data_all,data],axis = 0,ignore_index = True)
添加到一个列表中去:
data_all=pd.concat([data_all,data],axis = 0,ignore_index = True)

#保存
data_all.to_csv(‘data_all.csv’,index=False,encoding=‘utf-8’)
data_all.to_excel(‘data_all.xlsx’,index=False,encoding=‘utf-8’)
import pandas as pd
import numpy as np
import os
os.getcwd()
os.chdir(r’E:\python\python_practice’) #修改文件的存储路径,加r防止发生转义。
order.size 数据的尺寸
order.dtypes
order.shape
order[10:] 左开右闭
type(order.dishes_name)
取出某一列的前多少行::
order[[‘dishes_name’,‘logicprn_name’]][:50]
order[‘dishes_name’][:50]
#loc 和 iloc 的用法
order.loc[A,B]
选出列的数据:
order.loc[:,[‘dishes_name’,‘logicprn_name’]]
选择行标签和列标签:
order.loc[[2,5,6],[‘dishes_name’,‘logicprn_name’]]
loc函数可以写条件:
#筛选出order_id为123的列中的数据
order.loc[order[‘order_id’]==123,[‘order_id’,‘dishes_name’,‘logicprn_name’]]
order.iloc[A,B]
order.iloc[:,1:4]
order.iloc[:,[2,3]] #只能是列表的形式,不能是元组
order.iloc[3,[2,3]]
order.iloc[2:7,[2,3]]
取行标,按标签名称来取的
order.loc[0:6]
条件查询和增删改查:
order[order[‘order_id’]==235][[‘order_id’,‘dishes_name’]]
order[[‘order_id’,‘dishes_name’]][(order[‘order_id’]==562) & (order[‘amount’]>3)]
条件与条件之间要用括号括起来
order[[‘order_id’,‘dishes_name’]][(order[‘order_id’]==562) | (order[‘amount’]>3)]
order[[‘dished_id’,‘dished_name’,‘amounts’]][order[‘amounts’].between]
order[‘amounts’].between(10,30,inclusive=True)
isin()函数,判断数据中是否包含某个字段
order[[‘dishes_id’,‘dishes_name’]][order[‘dishes_name’].isin([‘内蒙烤羊腿’])]
例子:
order[‘dishes_name’].isin([‘内蒙烤羊腿’])
order[‘dishes_name’].str.contains(‘烤’) #判断字符串里面是否包含‘烤’字
order[[‘dishes_id’,‘dishes_name’]][order[‘dishes_name’].str.contains(‘烤’)]
order[‘payment’]=order[‘amounts’] * order[‘counts’]
order[‘payway’]=‘现金支付’
order.columns #查看列数
order.drop(‘payway’,axis=1) axis=0是跨行,axis=1是跨列,返回视图,不作用在原数据上
order.drop(‘payway’,axis=1,inplace=True)
del order[‘payment’] 只能一行一行的删除
将某一列放到第一列去
mid=order[‘emp_id’]
order.drop([‘emp_id’],axis=1,inplace=True)
order.insert(0,‘emp_id’,mid) #插入数据
order.drop(labels=[3,4],axis=0,inplace=True)
修改数据:
order.loc[order['order_id']==256,'order_id']=154800 #将order_id=256的修改为154800
修改列名:
order.rename(columns={‘amounts’:‘金额’},inplace=True)
order.describe().loc[‘count’]==0















 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









