






数据分析介绍
数据分析是一个广义的概念,在很多工作中都需要用到数据分析,甚至有些公司专门设置了数据分析师的岗位。
数据分析师是大城市中比较热门的岗位,主要通过各类数据分析工具对数据中的信息进行分析挖掘,撰写数据分析报告来为公司提供决策建议。
数据分析是利用数学、统计学理论与实践相结合的科学统计分析方法,对Excel数据、数据库中的数据、收集的大量数据、网页抓取的数据进行分析,从中提取有价值的信息并形成结论进行展示的过程。
广义的数据分析包括狭义数据分析和数据挖掘。
狭义的数据分析通过数据的统计分析发现数据中的信息,分析数据结果背后的原因。
数据挖掘则是通过数学算法和模型挖掘数据潜在规律,还可以预测数据的未来的走向。
数据分析应用场景
客户分析
主要是客户的基本数据信息进行商业行为分析,首先界定目标客户,根据客户的需求,目标客户的性质,所处行业的特征以及客户的经济状况等基本信息使用统计分析方法和预测验证法,分析目标客户,提高销售效率。
其次了解客户的采购过程,根据客户采购类型、采购性质进行分类分析制定不同的营销策略。
最后还可以根据已有的客户特征,进行客户特征分析、客户忠诚分析、客户注意力分析、客户营销分析和客户收益分析。
2.营销分析
囊括了产品分析,价格分析,渠道分析,广告与促销分析这四类分析。
产品分析主要是竞争产品分析,通过对竞争产品的分析制定自身产品策略。
价格分析又可以分为成本分析和售价分析,成本分析的目的是降低不必要成本,售价分析的目的是制定符合市场的价格。
渠道分析目的是指对产品的销售渠道进行分析,
确定最优的渠道配比。
广告与促销分析则能够结合客户分析,实现销量
的提升,利润的增加。
3.社交媒体分析
以不同社交媒体渠道生成的内容为基础,实现不同社交媒体的用户分析,访
问分析,互动分析等。同时,还能为情感和舆情监督提供丰富的资料。
用户分析主要根据用户注册信息,登录平台的时间点和平时发表的内容等
用户数据,分析用户个人画像和行为特征。
访问分析则是通过用户平时访问的内容,分析用户的兴趣爱好,进而分析
潜在的商业价值。
互动分析根据互相关注对象的行为预测该对象未来的某些行为特征。
4.网络安全
新型的病毒防御系统可使用数据分析技术,建立潜在攻击识别分析模型,监测大量网络活动数据和相应的访
问行为,识别可能进行入侵的可疑模式,做到未雨绸缪。
5.设备管理
通过物联网技术能够收集和分析设备上的数据流,包括连续用电、零部件温度、环境湿度和污染物颗粒等无数潜在特征,建立设备管理模型,从而预测设备故障,合理安排预防性的维护,以确保设备正常作业,降低因设备故障带来的安全风险。
6.交通物流分析
物流是物品从供应地向接收地的实体流动。通过业务系统和GPS定位系统获得数据,对于客户使用数据构建交通状况预测分析模型,有效预测实时路况、物流状况、车流量、客流量和货物吞吐量,进而提前补货,制定库存管理策略。
7.欺诈行为检测
身份信息泄露盗用事件逐年增长,随之而来的是欺诈行为和交易的增多。公安机关,各大金融机构,电信部门可利用用户基本信息,用户交易信息,用户通话短信信息等数据,识别可能发生的潜在欺诈交易,做到提前预防未雨绸缪。
series序列对象
获取序列对象方法
从表格对象获取
#导入数据
df =pd.read_excel('超市销售数据.xlsx')
df['城市']用series类来创建
series =pd.Series([1,2,3])
series序列对象的属性
series =pd.Series([1,2,3])
print('原序列:\n',series)
print('值:',series.values)
print('索引:',series.index)
print('元素类型:',series.dtype)
访问序列对象中的元素
series = pd.Series(['a','b','c'])
print(series)
print('_'*20)
print(series[0])#通过索引访问
print('_'*20)
print(series[0:2])#切片访问连续数据
print('_'*20)
print(series[series!='a'])# 条件访问序列对象的运算
series =pd.Series([1,2,3])
series2 =pd.Series([3,2,1])
print(series+10)
print(series*10)
print(series+series2)
print(series.astype(str)+'个')
print(series == 2)序列对象的常用方法
astype
方法实现元素类型转换
series =pd.Series([1,2,3])
print(series)
series2 =series.astype(str)
print(series2)
series3 =series2.astype(float)
print(series3)
value_counta
方法实现元素值出现次数统计
series = pd.Series([1,2,3,3,4,4,4])
print(series.value_counts()) #结果也是序列对象,但是索引和值的含义变了 sort_values
方法实现值的排序
series =pd.Series([1,4,3,2])
print(series)
print(series.sort_values()) # 排序后,索引会乱序round方法
调整序列中的小数点位数
series = pd.Series([1/3,1/6,1/7])
print(series)
print(series.round(2))
string ='hello world'
string.replace('o','0')str类的方法
实现字符串的字符数数据处理
str.replace方法
实现字符替换
df2 =pd.read_csv(
r'新用户表.csv',
encoding='gbk',
#engine='python'不一定需要
)
df2['性别']=df2['性别'].replace('男','man')
df2str.contains方法
实现查询序列各个元素是否包含某个字符串
df2 =pd.read_csv(
r'新用户表.csv',
encoding='gbk')
# 注意:序列.str.xontains()结果是一个布尔值序列
df2[df2['姓名'].str.contains('杨')]agg方法
实现序列对象加工
series =pd.Series(['10岁','20岁','30岁'])
print(series)
# 案例1:提取数字
print(series.agg(lambda x:x.split('岁')[0]))
#案例2:加工得到:成年\未成年的序列
#方法1:用有名函数
#定义一个加工函数
#def is_adult(x):
# if int(x.split('岁')[0])>18:
# return '成年'
# else:
# return '未成年'
#print(series.agg(is_adult))
#方法2:用匿名函数
print(series.agg(lambda x:'成年' if int(x.split('岁')[0])>18 else'未成年'))序列数据统计量计算
series = pd.Series([1,2,3,4,5])
print(series.max())#最大值
print(series.min())#最小值
print(series.sum())#求和
print(series.count())#计数
print(series.mean())#均值
print(series.median())#中位数
print(series.var())#方差数据清洗
1去除重复值
df=pd.DataFrame(
[['甲',80],['乙',90]],
columns=['姓名','分数']
)
df.drop_duplicates(subset=['姓名'],keep='first',inplace=True)
df2 处理缺失值
查看缺失值个数
#查看缺失值个数
df_user =pd.read_csv('D:\yy\新用户表.csv',encoding='gbk')
df_user.isnull().sum()
df_user.info()删除法处理缺失值
#python中缺失值的定义方法
import numpy as np
print(np.nan)
print(float('nan'))
print(None)#python自带的
df_nan =pd.DataFrame(
[['甲',80],[np.nan,np.nan],['乙',np.nan]],
columns=['姓名','分数']
)
df_nan
# 针对一列删除缺失值
df_nan.dropna(subset='姓名')
# 针对两列删除缺失值,任意一个数据缺失就删除
df_nan.dropna(subset=['姓名','分数'],how='any')
#针对两列删除缺失值,同时都缺失,才删除
df_nan.dropna(subset=['姓名','分数'],how='all')2.3 替换法处理缺失值
#案例:处理新用户表的缺失值
df_user = pd.read_csv('D:\yy\新用户表.csv',encoding='gbk')
df_user.isnull().sum()
#查看缺失值所在行数据(条件查询)
df_user[df_user['省份'].isnull()]
# 用特殊值填充性别缺失
df_user['性别'].fillna('?',inplace=True)
#查看缺失值所在行数据(条件查询)
df_user[df_user['省份'].isnull()]
#用特殊填充性别缺失
df_user['性别'].fillna('?',inplace=True)
#用众数填充省份和城市缺失
df_user['省份'].fillna(df_user['省份'].mode()[0],inplace=True)
df_user['城市'].fillna(df_user['城市'].mode()[0],inplace=True)
#用平均值填充年龄缺失
df_user['年龄'].mode()
df_user['年龄'].mean()
df_user['年龄'].fillna(int(df_user['年龄'].mean()),inplace=True)
3处理异常值
案例:处理汽车行驶里程表的异常值
#案例:处理汽车行驶里程表的异常值
df_car =pd.read_excel('D:\yy\新能源汽车行驶里程表.xlsx')
df_car
df_car.describe()#查看各个序列的一些统计量
# 获取序列的Q1\q3
Q1=df_car.describe()['行驶时长']['25%']
Q3=df_car.describe()['行驶时长']['75%']
print(Q1,Q3)
#计算行驶时长的正常值区间
IQR = Q3 - Q1
c=2 # 人为调整IQR系数
normal_low= Q1 - 1.5 * IQR
normal_high=Q3 + 1.5* IQR
print(normal_low,normal_high)
#定位异常值,条件查询
df_car.query('行驶时长>8180')
#删除处理,以查询删除
df_car2=df_car.query('行驶时长>8180').reset_index(drop=True)
df_car2
#如果要修改异常值
#查询数据 =修改后的数据
df_car['行驶时长'][df_car['行驶时长']>8180]=8000
df_car
#查看修改后的数据
df_car['行驶时长'].hist()
matplotlib数据可视化
第一步 导入库
import pandas as pd
import matplotlib.pyplot as plt柱形图
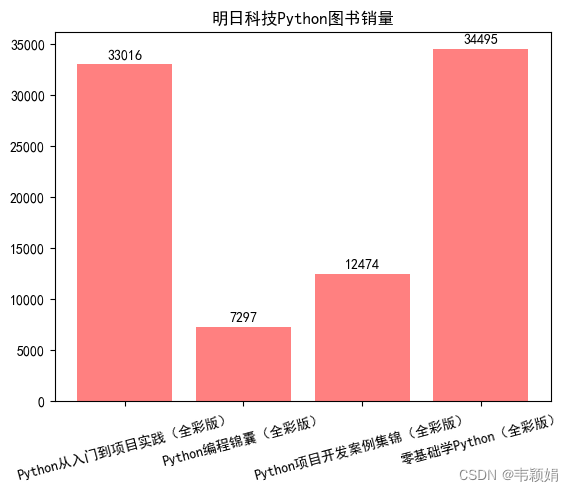
案例:统计明日科技的python类图书总销量,画柱形图
参考代码:
先导入数据
df_bar =pd.read_excel('D:\yy\明日科技图书销量.xlsx')
df_bar
筛选python类图书
df_python =df_bar[df_bar['商品名称'].str.contains('Python')]
df_python汇总所有关于各python书籍的总销量
data_bar =df_python.groupby('商品名称')['成交商品件数'].sum()
data_bar画图
plt.rcParams['font.family'] ='SimHei'
x =data_bar.index
y =data_bar.values
plt.bar(x,
y,
width=0.8,
color ='#ff8080'
)
plt.title('明日科技Python图书销量')在图中显示文本表情
for x0,y0 in zip(x,y):
plt.text(x0,y0+500,f'{y0}',ha='center')
plt.xticks(rotation =15)显示图形
plt.show()显示效果为
饼图
参考代码
df_pie = pd.read_excel('D:\yy\超市销售数据.xlsx')
df_pie
#对性别、支付方式做分组,统计每组的笔数(计数)
data_pie=df_pie.groupby(['性别','支付方式'])['发票编号'].count()
data_pie
# 画图、女性的图
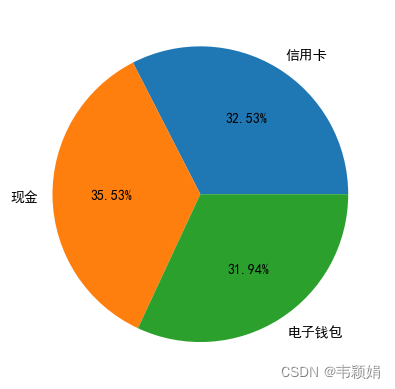
data_woman =data_pie['女']
plt.pie(
data_woman.values,
labels=data_woman.index,
autopct='%1.2f%%',#控制小数点位数
)
plt.show()
# 画图、男性的图
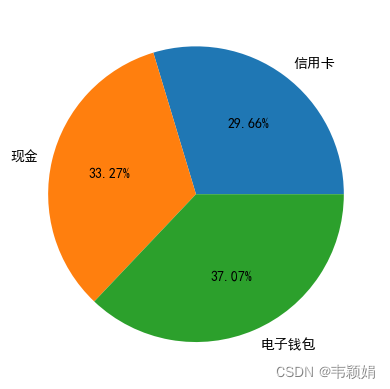
data_man =data_pie['男']
plt.pie(
data_man.values,
labels=data_man.index,
autopct='%1.2f%%',#控制小数点位数
)
plt.show()
显示效果
女性的图
男性的图
折线图
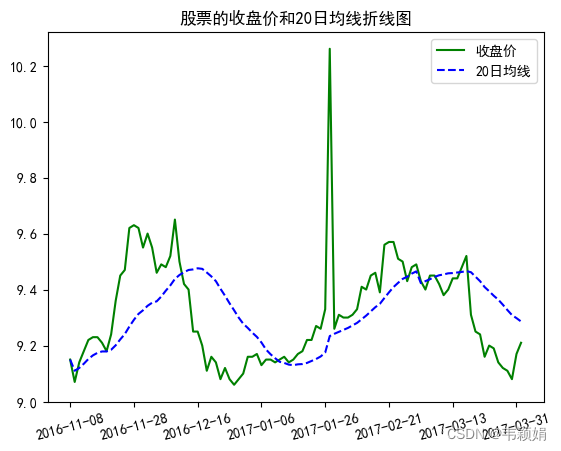
案例:画某只股票的收盘价(close)和20日日均线(ma20)的折线图
df_plot =pd.read_excel('D:\yy\股价数据.xlsx')
df_plot
#对时间做顺序排序
df_plot2=df_plot.sort_values(by='date').reset_index(drop=True)
df_plot2
#画图
n=100 #取前n各数据画图
x_line=df_plot2['date'][:n]
y1 =df_plot2['close'][:n]
y2 = df_plot2['ma20'][:n]
plt.plot(
x_line,
y1, 'g-' , #通过字符串配置线条样式
y2, 'b--'
)
plt.title('股票的收盘价和20日均线折线图')
plt.legend(['收盘价','20日均线'])
plt.xticks([i for i in range(0,n,int(n/7))],rotation=15)#选择7个等距x刻度显示
plt.show()显示效果
散点图
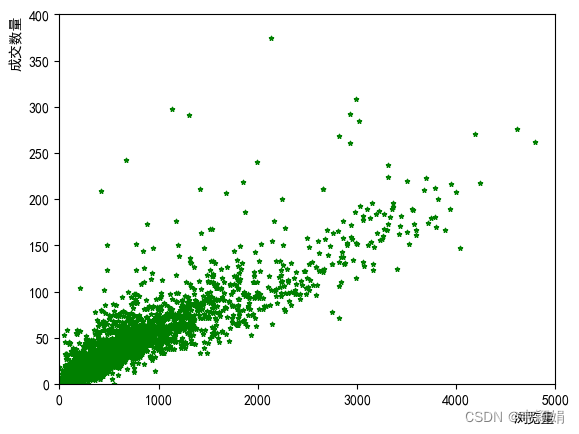
案例:图书浏览量和成交量散点图
导入数据
df_scatter =pd.read_excel('D:\yy\明日科技图书销量.xlsx')
df_scatter画图
plt.scatter(
df_scatter['浏览量'],
df_scatter['成交商品件数'],
s=10, #点的大小
c ='g' ,#颜色
marker='*' #点的样式
)
plt.xlim(0,5000) #x轴的范围
plt.ylim(0,400) #y轴的范围
plt.xlabel('浏览量',loc='right')
plt.ylabel('成交数量',loc='top')
plt.show()显示效果
直方图
案例:航空公司用户的年龄分布直方图
导入数据显示效果
df_hist =pd.read_excel('D:\yy\航空公司数据.xlsx')
df_histplt.hist(
df_hist['年龄'],
bins = [i for i in range(int(df_hist['年龄'].min()),int(df_hist['年龄'].max()),1)]
)
plt.title('航空公司用户年龄分布直方图')
plt.xlabel('年龄区间')
plt.ylabel('人数')
plt.show()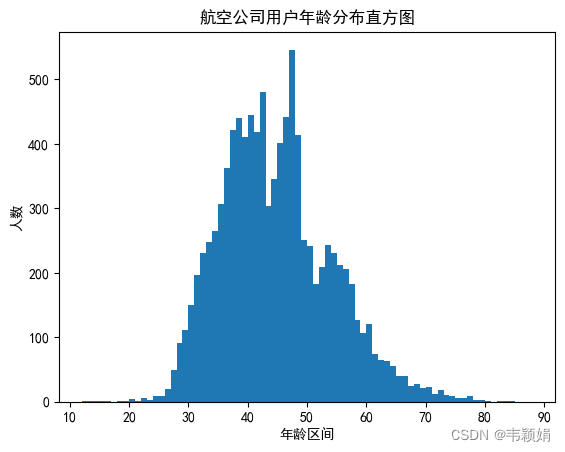
箱形图
案例:航空公司用户的年龄分布箱形图
plt.boxplot(
df_hist['年龄'].dropna(),# 输入序列,但是不能有空值
vert=False,# 横向展示
labels=['年龄']
)
plt.show()多个图放在一个画布里
案例:同时绘制“飞行次数”数据分布的直方图和箱线图,在画布中上下分布。
pf1=pd.read_excel('航空公司数据.xlsx')
plt.figure(figsize = (12,10))
plt.subplot(2,1,1)
plt.hist(
pf1['飞行次数'],
bins =[i for i in range(int(pf1['飞行次数'].min()),int(pf1['飞行次数'].max()),5)]
)
plt.title("用户飞行次数直方图")
plt.xlabel("飞行次数")
plt.ylabel("人数")
plt.subplot(2,1,2)
plt.boxplot(
pf1['飞行次数'].dropna(),
vert=False,
labels=['飞行次数']
)
plt.title("用户飞行次数箱形图")
plt.show()
显示效果
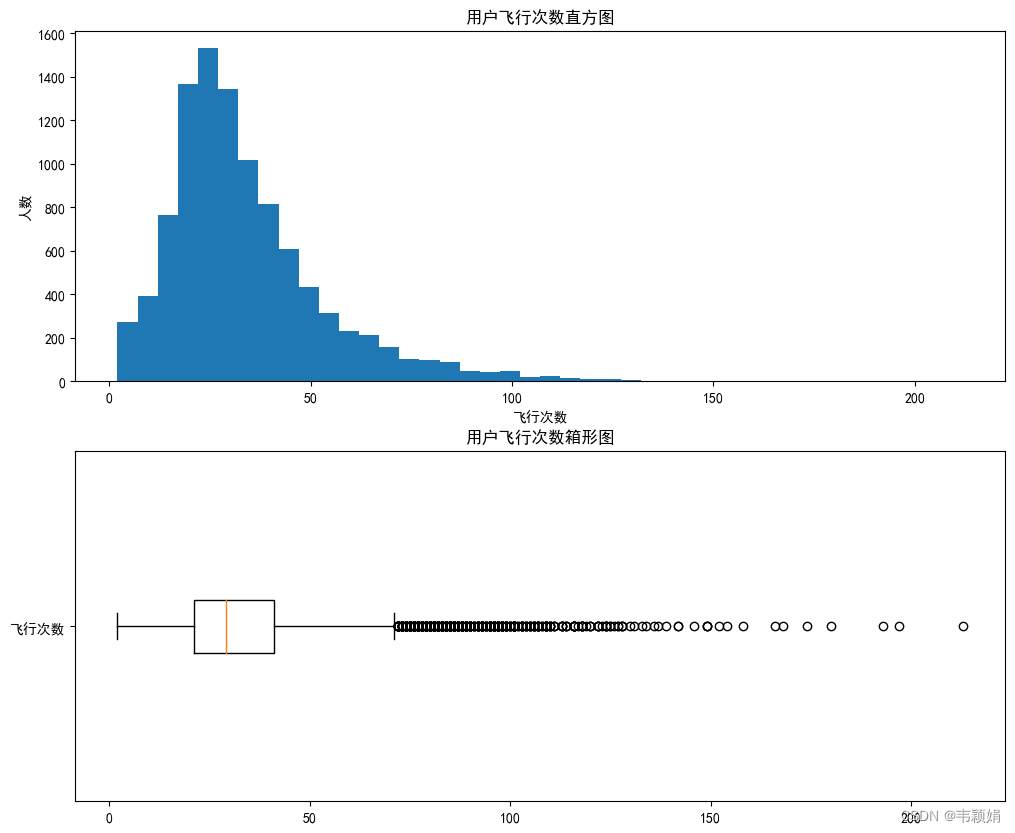















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









