






一、动态规划问题
动态规划的定义
动态规划(Dynamic Programming):简称 DP,是一种求解多阶段决策过程最优化问题的方法。在动态规划中,通过把原问题分解为相对简单的子问题,先求解子问题,再由子问题的解而得到原问题的解。
动态规划最早由理查德·贝尔曼于1957年在其著作「动态规划(Dynamic Programming)」一书中提出。这里的Programming并不是编程的意思,而是指一种「表格处理方法」,即将每一步计算的结果存储在表格中,供随后的计算查询使用。
动态规划的核心思想是把「原问题」分解为「若干个重叠的子问题」,每个子问题的求解过程都构成一个 「阶段」。在完成一个阶段的计算之后,动态规划方法才会执行下一个阶段的计算。
在求解子问题的过程中,按照「自顶向下的记忆化搜索方法」或者「自底向上的递推方法」求解出「子问题的解」,把结果存储在表格中,当需要再次求解此子问题时,直接从表格中查询该子问题的解,从而避免了大量的重复计算。
这看起来很像是分治算法,但动态规划与分治算法的不同点在于:
1.适用于动态规划求解的问题,在分解之后得到的子问题往往是相互联系的,会出现若干个重叠子问题。
2.使用动态规划方法会将这些重叠子问题的解保存到表格里,供随后的计算查询使用,从而避免大量的重复计算
二、POJ1579 Function Run Fun
2.1问题描述
问题截图

图2.1 问题截图
输入
程序的输入将是一系列整数三元组,每行一个,直到文件末尾标志-1 -1 -1。使用上述技术,您将有效地计算w(a,b,c)并打印结果。
输出
打印每个三元组的w(a,b,c)值。
2.2解题思路
题解
记忆化搜索算法上依然是搜索的流程,但是搜索到的一些解用动态规划的那种思想和模式作一些保存。一般说来,动态规划总要遍历所有的状态,而搜索可以排除一些无效状态。更重要的是搜索还可以剪枝,可能剪去大量不必要的状态,因此在空间开销上往往比动态规划要低很多。记忆化算法在求解的时候还是按着自顶向下的顺序,但是每求解一个状态,就将它的解保存下来,以后再次遇到这个状态的时候,就不必重新求解了。
这一题中已经给出了状态方程,因此直接写一个函数去做状态判断,配合记忆化搜索策略,最终在主函数进行函数调用即可。
算法设计路线
定义一个全局的三维数组“arr”用于存储中间结果。如果a≤0或b≤0或c≤0,返回1。如果a>20或b>20或c>20,则将a,b,c限制在20内,使用arr[20][20][20]存储和返回结果。查表:如果arr[a][b][c]已经计算过,直接返回存储的值。随后进行递归计算:如果a<b<c,使用公式w(a,b,c) = w(a,b,c-1) + w(a,b-1,c-1) - w(a,b-1,c)进行递归计算。否则,使用公式w(a,b,c) = w(a-1,b,c) + w(a-1,b-1,c) + w(a-1,b,c-1) - w(a-1,b-1,c-1)进行递归计算。不断读取用户输入的a,b,c三个整数,在每次输入时,初始化arr数组为0。调用sum(a,b,c)计算并存储结果,输出结果,当输入为-1 -1 -1时,终止程序。
2.3 C++源代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 定义三维数组存储中间结果
int arr[22][22][22];
// 函数 sum 计算 w(a, b, c) 的值
int sum(int a, int b, int c) {
if (a <= 0 || b <= 0 || c <= 0) {
return 1;
}
else if (a > 20 || b > 20 || c > 20) {
return arr[20][20][20] = sum(20, 20, 20);
}
else if (arr[a][b][c]) {
return arr[a][b][c];
}
else if (a < b && b < c) {
return arr[a][b][c] = sum(a, b, c - 1) + sum(a, b - 1, c - 1) - sum(a, b - 1, c);
}
else {
return arr[a][b][c] = sum(a - 1, b, c) + sum(a - 1, b - 1, c) + sum(a - 1, b, c - 1) - sum(a - 1, b - 1, c - 1);
}
}
int main() {
int a, b, c, result;
// 不断读取输入,直到遇到终止条件
while (scanf("%d%d%d", &a, &b, &c) != EOF && !(a == -1 && b == -1 && c == -1)) {
// 初始化数组
memset(arr, 0, sizeof(arr));
// 计算 w(a, b, c) 的值
result = sum(a, b, c);
// 输出结果
printf("w(%d, %d, %d) = %d\n", a, b, c, result);
}
return 0;
}
正确解题截图

图2.2 正确解题截图
2.4复杂度分析
时间复杂度
理论上最坏情况下,计算每个a,b,c需要的时间为常数级别(因为有了记忆化存储)。因此总体时间复杂度大约是O(20×20×20)=O(8000)。
空间复杂度
本题通过使用记忆化搜索,算法大大减少了重复计算,提升了效率,适合解决类似的递归问题。这里使用了一个三维数组arr来存储计算结果,空间复杂度为O(21×21×21)=O(9261)。
三、POJ1458 Common Subsequence
3.1问题描述
问题描述

图3.1 问题描述
输入
程序输入来自 std 输入。输入中的每个数据集都包含两个表示给定序列的字符串。序列由任意数量的空格分隔。输入数据正确无误。
输出
对于每组数据,程序在标准输出上打印从单独行开头开始的最大长度公共子序列的长度。
3.2解题思路
题解
这里先说一下子序列和字串的区别。字串是指在一个字串里连续的字符。注意这里是连续的。而子序列是指在不打乱原来字串字符的顺序的情况下,最长的可以间断的字符序列。也就是说子序列可以不连续。
由此我们可以得到这道题的动态方程:
1.a[i] == b[j] => dp[i][j] = dp[i - 1][j - 1] + 1
2.a[i] != b[j] => dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
这也就是说,对于每种a[i]和b[j],其前一组,也就是a[i - 1]和b[j - 1]一定存着前面最大的LCS,所以是这样的话,dp[i][j]就在LCS基础上加一。否则,只有在a[i]或b[j]前面找,也就是dp[i - 1][j]或dp[i][j - 1]。
算法设计路线
使用二维数组dp,其中dp[i][j]表示字符串strA的前i个字符和字符串strB的前j个字符的最长公共子序列长度。如果strA[i-1]==strB[j-1],则dp[i][j]=dp[i-1][j-1]+1。当两个字符匹配时,最长公共子序列长度在dp[i-1][j-1]的基础上增加1。如果strA[i-1]!=strB[j-1],则dp[i][j]=max(dp[i-1][j],dp[i][j-1])。当两个字符不匹配时,最长公共子序列长度取决于去掉strA的最后一个字符或strB的最后一个字符后的最大值。dp数组初始化为全零,因为当任一字符串长度为0时,最长公共子序列长度为0。外层循环遍历字符串strA的每个字符,内层循环遍历字符串strB的每个字符,逐步计算dp值。最终结果存储在dp[strA.size()][strB.size()]中,表示两个字符串strA和strB的最长公共子序列长度。
3.3 C++源代码
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
int main() {
string strA, strB;
// dp数组,用于存储子问题的解
int dp[500][500] = {};
// 不断读取输入的两个字符串
while (cin >> strA >> strB) {
// 遍历strA和strB的每个字符,计算最长公共子序列长度
for (int i = 1; i <= strA.size(); i++) {
for (int j = 1; j <= strB.size(); j++) {
// 如果字符匹配,当前状态等于前一状态加1
if (strA[i - 1] == strB[j - 1])
dp[i][j] = dp[i - 1][j - 1] + 1;
// 如果字符不匹配,当前状态等于去掉一个字符后的最大值
else
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
}
}
// 输出最长公共子序列的长度
cout << dp[strA.size()][strB.size()] << endl;
}
return 0;
}
正确解题截图
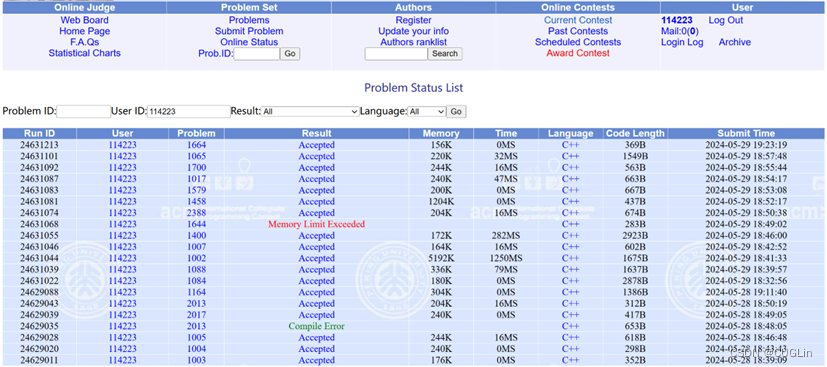
图3.3 正确解题截图
3.4复杂度分析
时间复杂度
该算法的时间复杂度为O(m×n),其中m和n分别是字符串strA和strB的长度。外层和内层循环分别遍历了strA和strB的每个字符。
空间复杂度
空间复杂度为O(m×n),因为需要一个二维数组dp来存储中间结果。具体而言,需要m×n个存储单元来存储从dp[0][0]到dp[m][n]的结果。
四、POJ1088 滑雪
4.1问题描述
问题截图

图4.1 问题截图
输入
输入的第一行表示区域的行数R和列数C(1 <= R,C <= 100)。下面是R行,每行有C个整数,代表高度h,0<=h<=10000。
输出
输出最长区域的长度。
4.2解题思路
题解
在一个矩阵中,每一个点可以往上下左右四个方向中比当前位置小的点移动,求最长路路径。对于矩阵中的每个点,搜索它的上下左右四个点的高度是否小于当前点的高度,如果满足,对该方向递归搜索,递归结束后,返回上下左右四个点的最大值,最后返回的就是从该点开始的最长路径长度,答案就是它们的最大值。直接暴力求解会超时,因此这里需要记忆化搜索,即在每次递归结束后,把改点的最长路径长度保存起来,在下次递归到改点时可以直接调用。
算法设计路线
从地图中的每个点开始,向四个方向(上、下、左、右)进行搜索。对于当前点 (x, y),如果下一个点 (next_x, next_y) 的高度小于当前点的高度,则继续向下一个点搜索。如果下一个点符合条件,则递归调用DFS函数,进入下一层搜索。使用一个记忆化数组 memoization 存储已经计算过的点的最长下降路径长度。在DFS过程中,如果遇到已经计算过的点,则直接返回其记忆化数组中的值,避免重复计算。同时,在每次计算某个点的最长下降路径长度后,将结果存储到记忆化数组中,以备后续使用。对于地图中的每个点 (i, j),都进行一次DFS搜索,求出以该点为起点的最长下降路径长度。在遍历的过程中,更新最长下降路径长度的全局最大值。最终,输出全局最大的最长下降路径长度,即为整个地图的最长下降路径长度。
4.3 C++源代码
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
int grid[105][105]; // 存储地形高度的二维数组
bool visited[105][105]; // 标记当前点是否访问过的二维数组
int directions[4][2] = { {1, 0}, {-1, 0}, {0, -1}, {0, 1} }; // 四个方向:下,上,左,右
int memoization[105][105]; // 记忆化数组,表示从第x行y列开始的最长下降序列的长度
int rows, columns; // 行数和列数
bool isInRange(int x, int y) // 判断点(x, y)是否在地图范围内
{
return (x >= 1 && x <= rows && y >= 1 && y <= columns && !visited[x][y]);
}
int dfs(int x, int y) // 深度优先搜索,计算从点(x, y)开始的最长下降序列的长度
{
if (memoization[x][y]) // 如果当前点已经搜索过,直接返回其值
{
return memoization[x][y];
}
int tmp = 0;
for (int i = 0; i < 4; i++) // 四个方向
{
int next_x = directions[i][0] + x; // 下一个位置的行坐标
int next_y = directions[i][1] + y; // 下一个位置的列坐标
if (isInRange(next_x, next_y) && grid[next_x][next_y] < grid[x][y]) // 下一个位置的高度需小于当前位置的高度
{
visited[next_x][next_y] = true; // 标记当前位置为已访问
tmp = max(tmp, dfs(next_x, next_y)); // 遍历所有分支中的最大值
visited[next_x][next_y] = false; // 取消标记,以便从其他路径继续遍历该点
}
}
memoization[x][y] = tmp + 1; // 当前路径的值为所有分支中的最大值加上当前位置
return tmp + 1; // 返回当前路径的值
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cin >> rows >> columns; // 输入地图的行数和列数
for (int i = 1; i <= rows; i++) // 读入地图高度信息
{
for (int j = 1; j <= columns; j++)
{
cin >> grid[i][j];
}
}
int longestDescent = 0; // 记录最长下降序列的长度
for (int i = 1; i <= rows; i++) // 遍历地图中的每个点,计算最长下降序列的长度
{
for (int j = 1; j <= columns; j++)
{
memset(visited, false, sizeof(visited)); // 在遍历之前,初始化visited数组
visited[i][j] = true; // 标记当前点为已访问
longestDescent = max(longestDescent, dfs(i, j)); // 遍历所有点,求出最长下降序列的长度
}
}
cout << longestDescent << endl; // 输出最长下降序列的长度
return 0;
}
正确结题截图
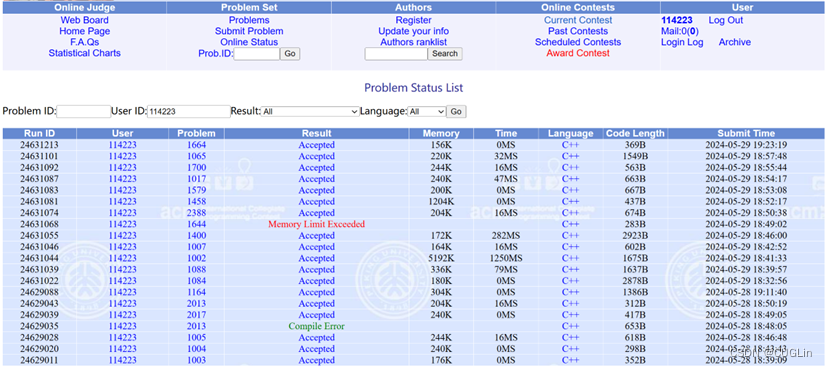
图4.2 正确解题截图
4.4复杂度分析
时间复杂度
算法的时间复杂度主要取决于DFS的遍历过程,在最坏情况下,每个点可能被访问多次,所以时间复杂度为 O(n⋅m),其中 n 是地图的行数,m是地图的列数。
空间复杂度
算法的空间复杂度主要取决于记忆化数组的大小,为 O(n⋅m),同时还有一些额外的变量和常数大小的空间开销。
五、作业小结
在本次上机实习中,我主要学习并使用了动态规划(Dynamic Programming)算法。动态规划是一种在数学、计算机科学和经济学中使用的,通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。它的核心思想是将求解过的子问题的解存储起来,避免重复求解,从而提高算法效率。实习的主要目标是深入理解动态规划的基本思想、掌握其实现方法,并能将其应用于实际问题中。
基本思想:我首先学习了动态规划的基本思想,即利用已知子问题的解来求解当前问题,并存储这些解以避免重复计算。这种“分而治之”和“记忆化”的策略是动态规划的核心。
最优子结构:我了解到,一个问题是否具有最优子结构是能否使用动态规划算法的关键。最优子结构意味着问题的最优解所包含的子问题的解也是最优的。
无后效性:我学习了无后效性原理,即“未来与过去无关”,即“无后效性”是指“某阶段的状态一旦确定,则此后过程的演变不再受此前各种状态及决策的影响”。
0-1背包问题:我通过实现0-1背包问题,深入理解了动态规划算法的基本步骤和实现方式。通过构建状态转移方程,并使用二维数组或滚动数组来存储中间结果,我成功解决了该问题。
最长公共子序列(LCS):我进一步学习了LCS问题,这是另一个典型的动态规划问题。我通过构建状态转移表,并利用动态规划的思想求解了该问题,从而加深了对动态规划算法的理解。
其他应用:除了上述两个经典问题外,我还尝试将动态规划算法应用于其他实际问题中,如最短路径问题、资源分配问题等。这些实践让我更加熟悉动态规划算法的应用场景和技巧。
空间优化:在解决动态规划问题时,我注意到空间复杂度往往是一个需要关注的问题。因此,我尝试使用滚动数组、位运算等技术来优化空间复杂度,减少内存消耗。
时间优化:对于某些问题,我尝试通过改进状态转移方程、使用更高效的数据结构等方式来优化时间复杂度,提高算法效率。
通过本次实习,我深入理解了动态规划算法的基本思想、实现方法以及应用场景。在实践中,我不仅提高了编程能力,还培养了解决问题的逻辑思维和创新能力。未来,我将继续探索动态规划算法在更多领域的应用,并尝试将其与其他算法(如贪心算法、回溯算法等)结合使用,以解决更复杂的问题。同时,我也将关注算法的优化和效率提升,以更好地应对实际项目中的挑战!















 1279
1279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









