






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心很荣幸邀请到寒风解读经典单目3D检测算法MonoDLE,如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→自动驾驶之心【3D目标检测】技术交流群
后台回复【3D检测综述】获取最新基于点云/BEV/图像的3D检测综述!
1简介
MonoDLE是2021年发在CVPR上的一篇单目3D目标检测(以下简称单目检测)方向的文献。
单目检测现在更多的成果还是以模仿激光雷达(DD3D)或者引入激光雷达辅助学习(CMKD,当前SOTA)的流派为主。而MonoDLE则显得更加“老派”,沿袭了SMOKE的纯视觉角度对场景进行分析,并反驳了SMOKE提出的2D检测对3D检测没有帮助的论点。当然了,说完全不靠激光雷达也不准确,毕竟3D标签还是靠人家点云标的。
这篇文章的价值就在于简单,对单目检测这个任务进行了拆解分析,对于刚接触这一领域的工作者十分友好,可以对单目检测建立一个初步的认识。并且,他的加强版模型MonoCon去年也曾拿过一段时间的KITTY榜首,证明了这套方法的有效性。
2场景分析
这篇文章很有意思的地方就在这里,作者设计了一系列诊断实验,来分析每一个子任务对模型整体表现影响的大小。具体方式就是,依次用真值代替每一个子任务的预测结果然后观察模型的最终表现。
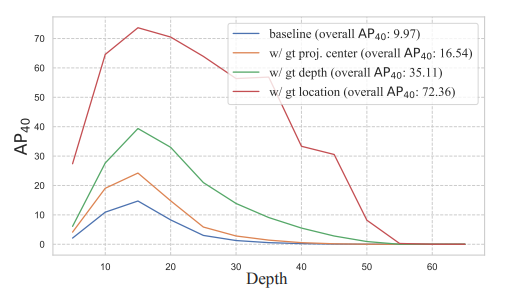
很明显能看出来,当3D框中心点坐标的预测值采用真值代替时,模型的表现几乎赶得上激光雷达了,同时深度估计也是一个很大的影响因素。
基于这个核心观察,作者做了三个方面的主要工作:
重新分析了2D检测框中心点和3D框中心点投影之间的偏移,并且在模型的head上做出了适应性设计。

作者认为现在的技术还不足以支持远距离目标的精确估计,作者在后面的内容中给出了论证,距离越远,单个像素误差对应的实际偏移就会越大。而强行将远距离样本纳入训练集,会对模型造成得不偿失的影响,所以作者干脆删掉了60米以外的训练样本。事实证明学明白了近端的模型,在远距离上表现得还凑合。
作者设计了一个新的针对尺寸估计的损失函数,避免尺寸估计受到定位精度的影响。
作者还专门声明了保留2D检测任务的意义,认为从2D中心点和宽高的学习中获得的共享特征,可以帮助到3D任务。针对这一论点,虽然没有做严格的对照实验,不过这俩模型用的都是DLA-34,其他没有什么重大的设计上的差别,最后的提升也足够明显,还是挺有说服力的。当然任务扩展肯定要带来时间消耗,总体比SMOKE慢了10ms,不过从工程方面讲可以兼容一些原来开发的基于2D检测的任务,也能接受。
3Baseline以及优化方案
作者采用了CenterNet的基础架构作为Baseline,在保留了2D检测任务的基础上添加了一系列3D检测的子任务,最终达到3D检测的目的。这里顺便说一句,CenterNet这个模型虽然知名度不低,但是作为工程工具始终被Yolo落下好远。不过到了3D场景下,因为其简单直接易扩展的特性,经常被拿来魔改,不光是单目3D目标检测,很多多模态融合检测的场景也会拿它来做Baseline,所以还是有一定学习价值的。
模型的backbone还是选用了发挥稳定的DLA-34,比较可惜的是CenterFusion中提出的加了DCN的DLA因为工程化困难一直没有被广泛使用,否则是一个不错的涨点trick。关于DLA的优化大家可以去看一下SMOKE的论文,解读很多就不细说了,还是有很多不错的优化细节的。
在backbone之后,一共有7个检测头,统一规格都是一个3×3卷积层加一个1×1卷积层。7个头分别用来预测
像素坐标系下的粗估中心c的坐标(u,v)
2D框中心ci相对于c的偏移量oi(Δui,Δvi)
2D框宽高w2D、h2D
3D框中心在像素坐标系下的投影cw相对于c的偏移量ow(Δuw,Δvw)
3D框中心点深度z
3D框长宽高l、w、h
航向角γ
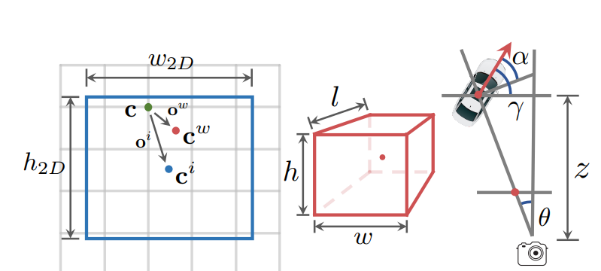
这里针对其中几个任务的细节做一下说明:
1. 粗估中心
粗估中心的监督标签用的是3D中心的投影,也就是cw的真值,毕竟是主要任务嘛,需要一些偏向。文章中说以前的一些文献用的是2D框中心点真值做监督,这个不重要。
2. 3D中心点坐标
从任务分配就可以看出,3D中心点在相机坐标系下的三维坐标(xw,yw,zw)是分两个头实现的,通过预测3D中心在像素坐标系下的投影坐标cw,结合相机内参可以获得中心点在图像物理坐标系下的坐标(x,y,z)。再通过预测深度zw,获得zw/z这个比例系数,就能求出xw,yw。由此可见,深度估计对整体定位精度的影响还是很大的。
3. 深度估计
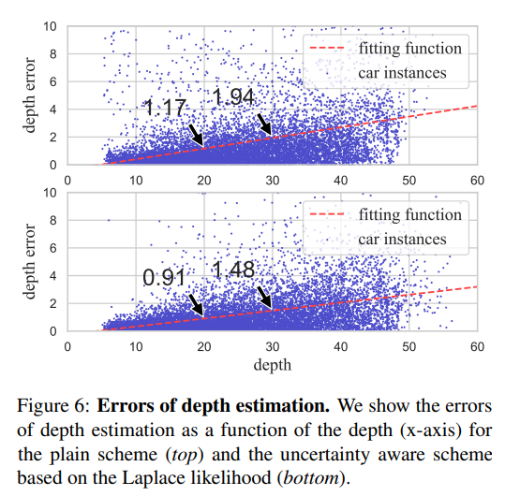
本文对于深度估计的设计,整体还是端到端的思路,不过在输出上做了一个不确定性建模,在预测深度d的基础上同时预测标准差σ。对于σ的分布,文中做了拉普拉斯分布和高斯分布
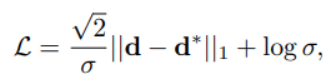
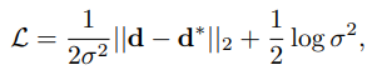
两种假设并进行了实验验证,最终证明拉普拉斯分布下的约束方式效果更好。不过从误差分析的结果上来看,30米外的目标就有1.5米的误差,即便是做了优化,深度估计这块儿仍然是任重道远。
4. 尺寸估计
以往的尺寸估计,应用的损失函数都是通过计算和真值框之间的交并比来约束优化方向。这样带来的问题就是,由于中心点的预测误差导致的损失偏大,会给尺寸估计带来不必要的负担。所以作者单独拎出了尺寸估计并专门设计了损失函数,只针对尺寸的预测误差对这个分支进行优化。并且根据长宽高对于IOU影响的比例不同,对参数优化的权重也按比例进行了设置。这一部分虽然作为一个单独的贡献进行了说明,不过在整个项目中的提升并不算大,就不展开说了。
5. 航向角估计
航向角用的是multi-bin loss,没有什么特殊优化,论文链接在这里https://arxiv.org/abs/1711.08488。
4结语
总体看下来这篇文章还是挺优秀的,确实有新东西,也分析清楚了很多问题。看完之后也能明白为什么深度估计能作为一个单独的方向发展这么久了,其实大部分单目检测方法的主要区别就是针对这个问题做出了不同选择,要么继续尝试从图像角度去优化这个病态问题,要么就干脆去仿激光雷达,或者通过硬件比如深度相机去规避(不过这个好像也不算真正意义上的单目了)。怎么处理深度信息的预测问题也是看大多数单目检测论文的一个不错的切入点。
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









