






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
论文作者 | Zhiqi Zhao
编辑 | 3D视觉之心
传统方法和深度学习强强联手
在 VSLAM 系统中,前端视觉里程计(VO)系统通过处理相机图像信息并获取相机运动关系来确定机器人的当前位置和方向。手工特征是 VO 中使用的主要方法。通过从多幅图像中提取特征并匹配其描述符,可以获得相机位姿估计信息。然而,当遇到一些具有挑战性的场景(例如,低光、光照剧烈变化和低纹理场景)时,基于手工特征的传统方法可能无法识别和关联当前环境中的特征信息。
传统基于特征的视觉 SLAM 方法在小规模场景中表现较好,但在复杂和变化的场景中性能不稳定,甚至可能出现跟踪丢失。基于深度学习的方法在特定场景中展示了极大潜力,但在面对未知环境时表现不佳:
当面对未知环境的场景时,大多数深度学习方法由于对用于训练的特定数据集的高度依赖而表现不佳
大多数提出的方法必须在不同场景下(包括具有挑战性的场景)全面评估系统的鲁棒性
存在计算效率方面的严重挑战。这种设计严重限制了系统的性能,往往无法满足 SLAM 系统的稳定性和实时性要求
本文介绍的Light-SLAM[1]是基于 LightGlue[2] 深度学习网络的视觉 SLAM 混合方法:
利用深度局部特征描述符替代传统的手工特征,并通过更准确高效的深度网络实现快速精确的特征匹配,增强了系统在适应低光等具有挑战性环境时的鲁棒性。
提出了一种使用图像金字塔模型进行特征提取的优化算法。该算法将每个图像层的特征提取任务分配给不同的处理单元并行处理,旨在提高图像特征跟踪的效率和系统的实时性能。
提出了一种使用深度神经网络的精确匹配方法用于立体图像帧,以替代传统的粗略匹配方法。该方法旨在通过提高图像像素点与空间地图点之间的数据关联精度,实现更准确的立体视觉重建和深度估计。
在四种公共数据集(KITTI、EuRoC、TUM 和 4Season)以及实际校园场景序列上测试表明,Light-SLAM 在适应不同时间段的光照变化环境方面表现优越,显著提高了系统的鲁棒性和准确性,同时能够在 GPU 上实时运行。
LIGHT-SLAM
系统框架
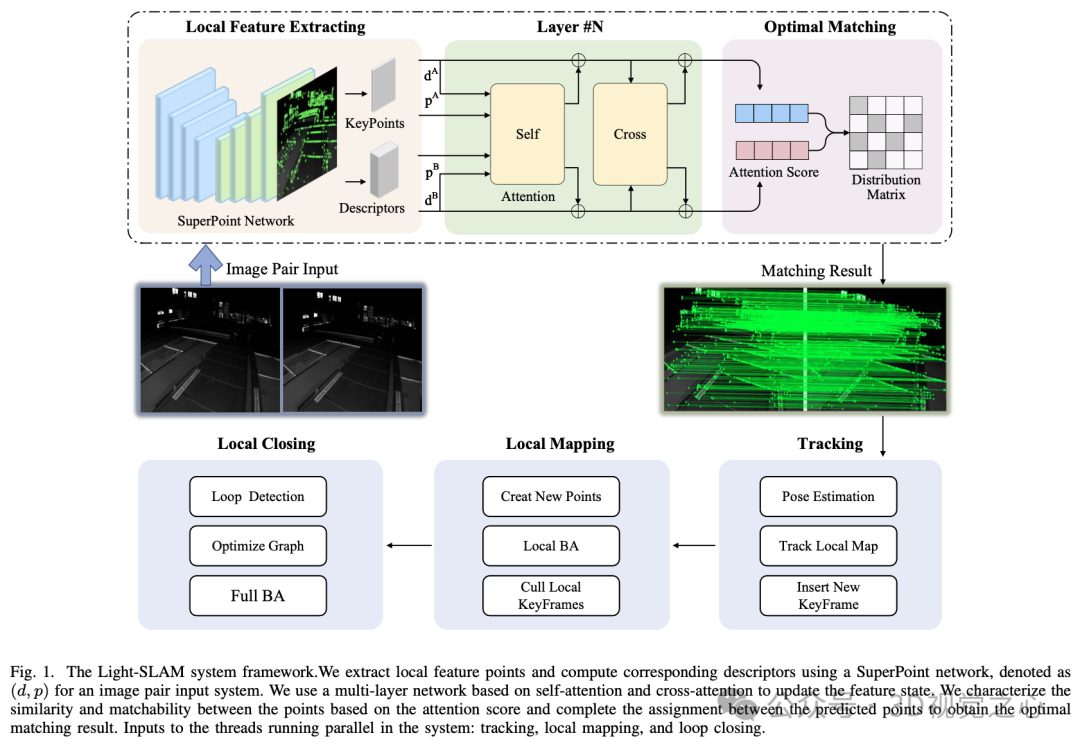
如图 1 所示:类似于 ORB-SLAM2 框架,系统主要包含三个并行运行的线程:跟踪、局部建图和回环检测:
在跟踪线程中,对于输入到系统的每一帧图像,使用深度学习网络提取局部特征描述符以替代传统的手工设计特征。然后,利用基于注意力机制的网络实现快速准确的匹配。接着,使用恒速运动模型估计初始相机位姿。同时,跟踪局部地图并执行重投影搜索以匹配局部地图点。最终,根据线程状态判断是否将新关键帧插入地图中。
在局部建图线程中,当接收到新关键帧时,首先通过三角测量创建与共同视野中的关键帧相关联的新地图点。然后,执行局部 BA(束调整)优化相机位置。随着关键帧数量的增加,通过消除冗余的局部关键帧来降低系统的复杂性。
在回环检测线程中,首先检测上一个线程处理的最后一个关键帧以满足回环条件。如果检测到回环,立即计算当前关键帧与回环关键帧的相似变换,以获得回环中的累计误差,并优化位图以实现全局一致性。最后结合全局 BA 优化以达到最优解。
深度局部特征描述符提取与匹配
在特征提取阶段,使用全卷积神经网络架构,通过对全尺寸图像进行一次前向传递来提取具有固定长度描述符的 SuperPoint 特征点,如图 2 所示。
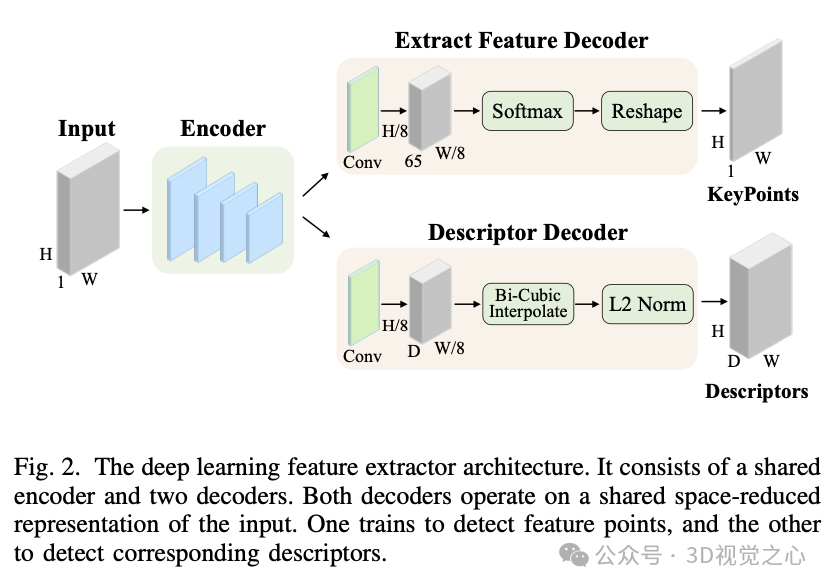
首先,对于大小为 的图像,特征检测器计算 并输出大小为 的张量。这 65 个通道包含一个局部化的、非重叠的 像素网格区域和一个额外的“非特征”箱。使用通道 softmax 去除这个箱维度,并应用重塑函数输出大小为 的张量。描述符解码器使用半密集而非密集设计以减少训练参数并保持运行时的可处理性。然后,它对描述符进行双三次插值和 L2 归一化,最终输出描述符。
SuperPoint 在适应不同具有挑战性的场景时表现出其鲁棒性。用这种深度特征替代传统的手工设计特征可以实现更高的识别和匹配率,克服了一些基于传统特征的视觉 SLAM 方法在具有挑战性场景中表现不佳的问题。更重要的是,SuperPoint 在适应各种复杂场景时表现出色。
将图像 中的每个局部特征 与状态 关联。状态初始化为对应的视觉描述符 ,并随后由每层更新。我们将一层定义为自注意力和交叉注意力单元的序列。在每个注意力单元中,多层感知器(MLP)并行计算两个图像中所有特征点的特征状态,基于从源图像 聚合的信息 更新特征状态。
然后,计算注意力分数,并基于任何层的更新状态进行预测分配。首先计算两图像特征点之间的相似矩阵 :
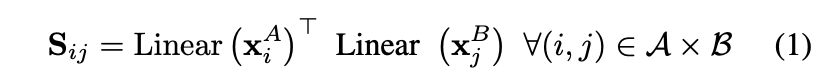
其中 是具有偏差的学习线性变换。然后计算每个特征点 的匹配分数的对应点的可能性:
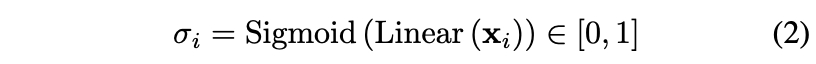
如果匹配失败,则 σ。
将相似性和匹配分数结合在一个分配矩阵 中:
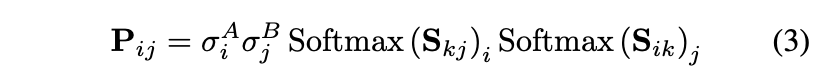
当我们预测一对点 是可匹配的,并且它们的相似性高于其他任何点时,我们将这两个点最佳匹配。
优化的并行图像金字塔模型
为了提高系统跟踪的鲁棒性和效率,采用流行的 SLAM 系统通过构建图像金字塔来实现尺度不变性。执行多尺度特征点提取和匹配,以增强算法对对象尺度变化的鲁棒性。然而,这些附加操作会产生大量计算开销,尤其是在处理大尺寸图像时,会影响系统效率。
因此,我们提出了基于图像金字塔模型的特征提取优化算法。通过并行完成多个图像层的特征提取来提高整体处理速度和系统的实时性能。通过将每层图像的提取任务分配给不同的处理单元,充分利用计算资源,避免串行处理的瓶颈,从而有效加快特征点的提取,提高系统跟踪的效率,解决基于深度学习方法的 SLAM 系统难以满足实时要求的问题。
在图 3 中展示了金字塔构建过程。从底层到顶层是一个下采样过程;底层图像是系统输入的原始图像,宽度为 ,高度为 ,分辨率为 。图像金字塔的缩放因子为 λλ,层数为 。将λ设置为 1.2, 设置为 8。然后,依次按 λ 的幂次减少每一层的宽度和高度,直到达到 层,完成金字塔的构建。
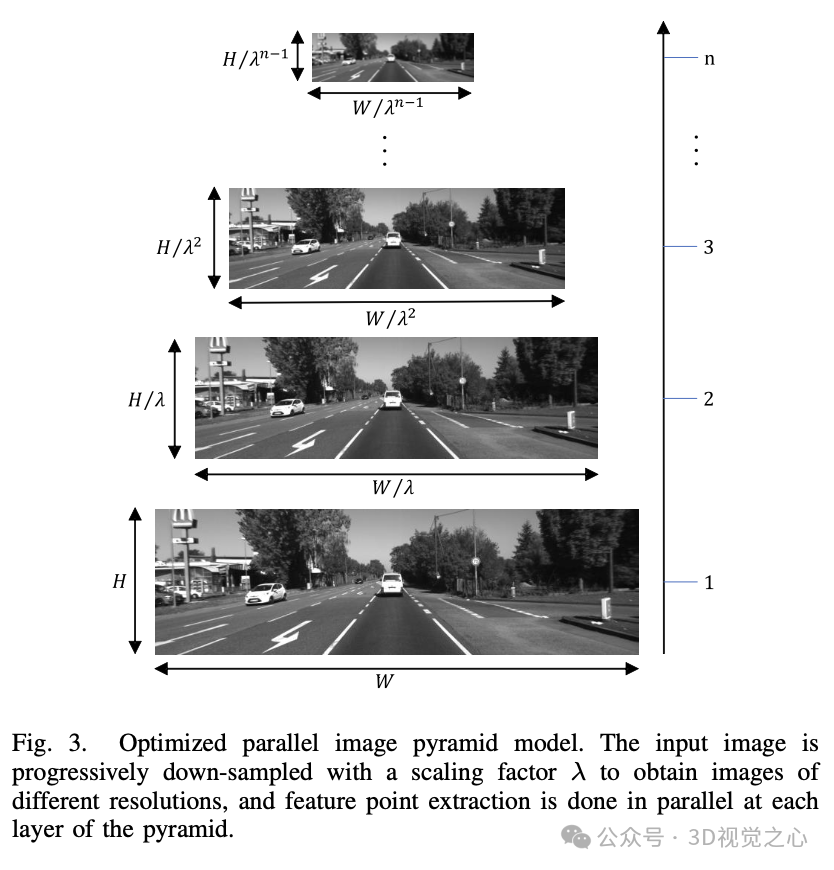
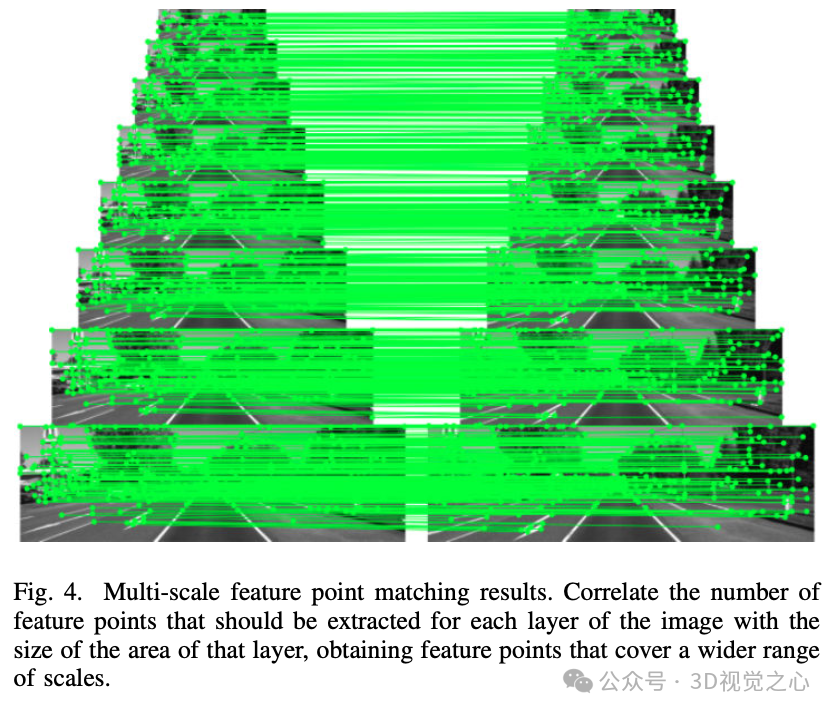
图 4 显示了特征提取和匹配的图像金字塔。图像金字塔中的层数越高,图像分辨率越低,提取的特征点数量越少。因此可以将每层图像提取的特征点数量与该层图像区域的大小相关联,以生成覆盖更多尺度的特征点。
将整个图像金字塔的总面积记为 ,其公式如下:
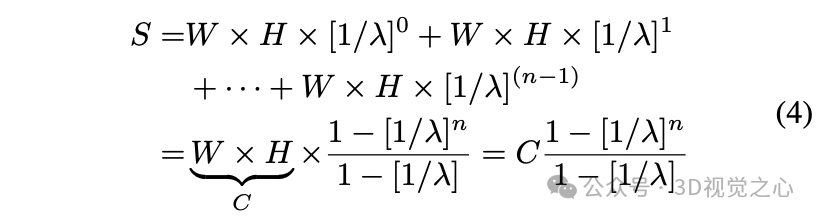
然后,单位面积内应提取的特征点数量为:
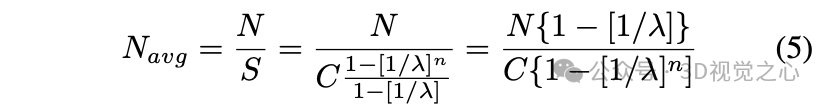
其中, 是从图像金字塔中提取的特征点总数。然后可以计算图像金字塔第 α 层应提取的特征点数量:
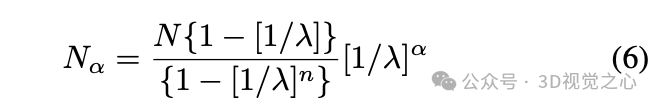
具体来说,特征提取和匹配过程如算法 1 所示。不同层级的图像金字塔包含相似但略有不同的图像信息,这意味着在不同级别的金字塔中可能会重复检测到某些特征点,从而引入冗余特征点。因此进行非极大值抑制剔除以避免输出重复的特征点。

选择图像金字塔的底层作为基准,在每层金字塔中选择特征点 , 作为现有特征点。然后计算候选特征点(包括重复特征点), 和它们所在网格区域内 坐标之间的距离。然后筛选出小于关键阈值 的候选特征点 ε,ε 为响应阈值。根据 ε 的大小对特征点进行排序,并根据非极大值抑制算法搜索局部最大值 ε,以获得特征点所在位置的最佳位置的邻近特征点。排除响应阈值低的邻近候选特征点,以避免输出重复的特征点。
立体深度估计模块
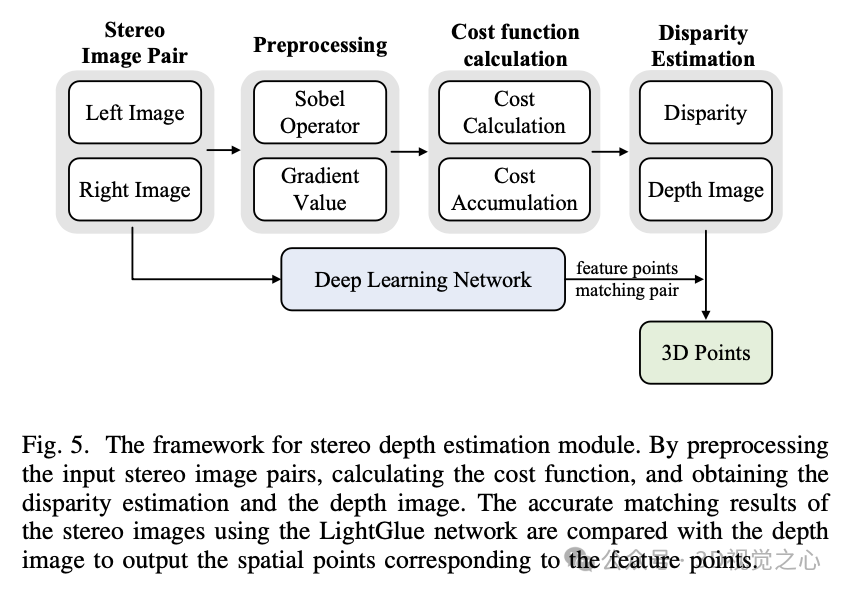
立体深度估计模块框架如图 5 所示。系统首先预处理输入的立体图像对并计算像素点的梯度幅度。然后,估计匹配代价的累积函数,以获得每个像素位置的最佳匹配替代值,并获得视差预测值并将其转换为深度图。利用深度学习网络精确匹配立体图像,将结果与深度图进行比较,并输出对应特征点的空间点。通过提高图像特征点与空间地图点之间的数据关联精度,实现更准确的立体视觉重建和深度估计。
假设左图像的灰度值为 ,则水平方向和垂直方向的梯度幅度计算如下:

其中, 和 分别是水平和垂直卷积核。然后,图像像素点的灰度值幅度为:
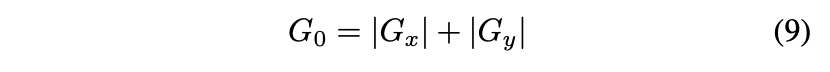
对于每个像素点 ,其在右图像中对应的像素坐标为 ,其中 为视差值。可以定义两者之间的代价函数 为:
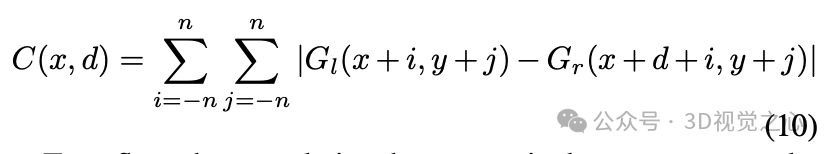
为了更准确地反映像素之间的关联,通过沿各个方向(水平、垂直和对角线)累积匹配代价来选择全局最小代价路径,从而为每个像素位置获得最佳匹配替代值。代价函数的表达式为:
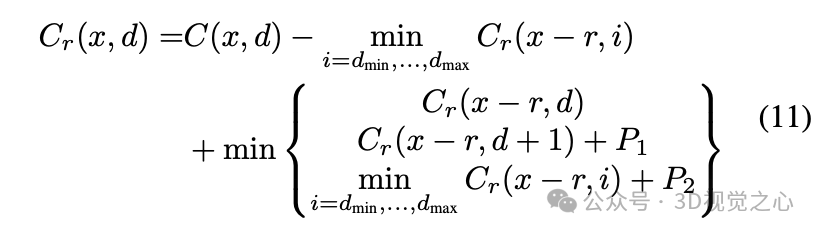
其中, 和 是平滑惩罚项,方程的第二项用于消除由不同方向上的路径长度引起的影响。通过将所有 方向上的匹配代价求和获得总匹配代价,然后找到最小匹配代价的位置,从而得到当前像素点的视差值 :
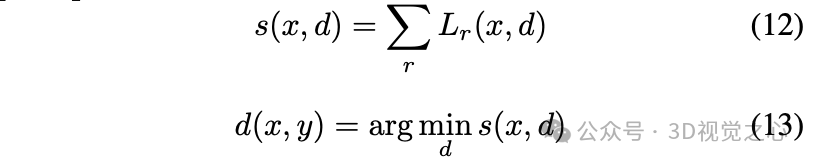
其中, 表示找到使 取得最小值时的 。根据双目视觉的几何关系,可以通过视差值转换为深度值:
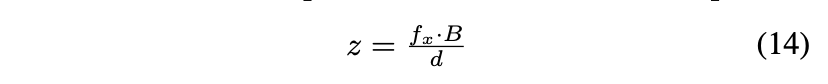
其中, 为归一化焦距, 为两个相机光心之间的距离,称为基线距离。
实验效果

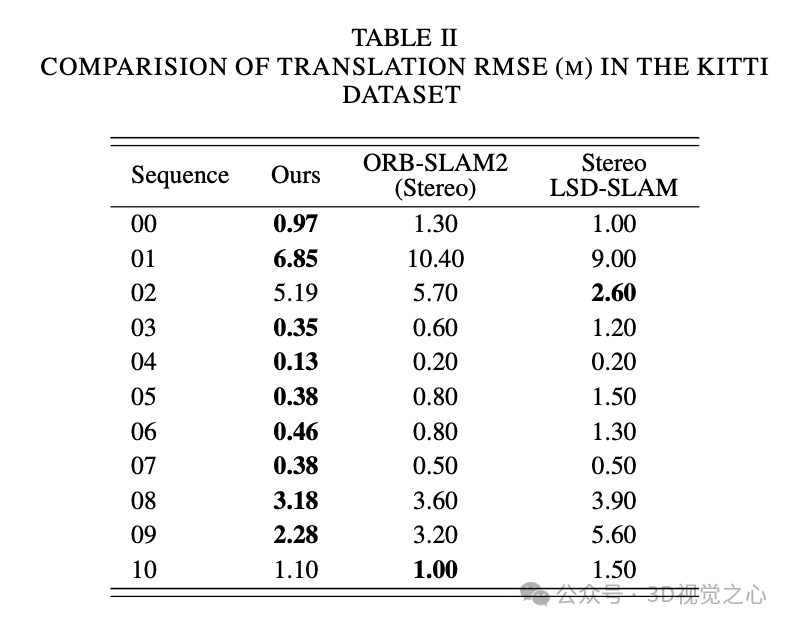

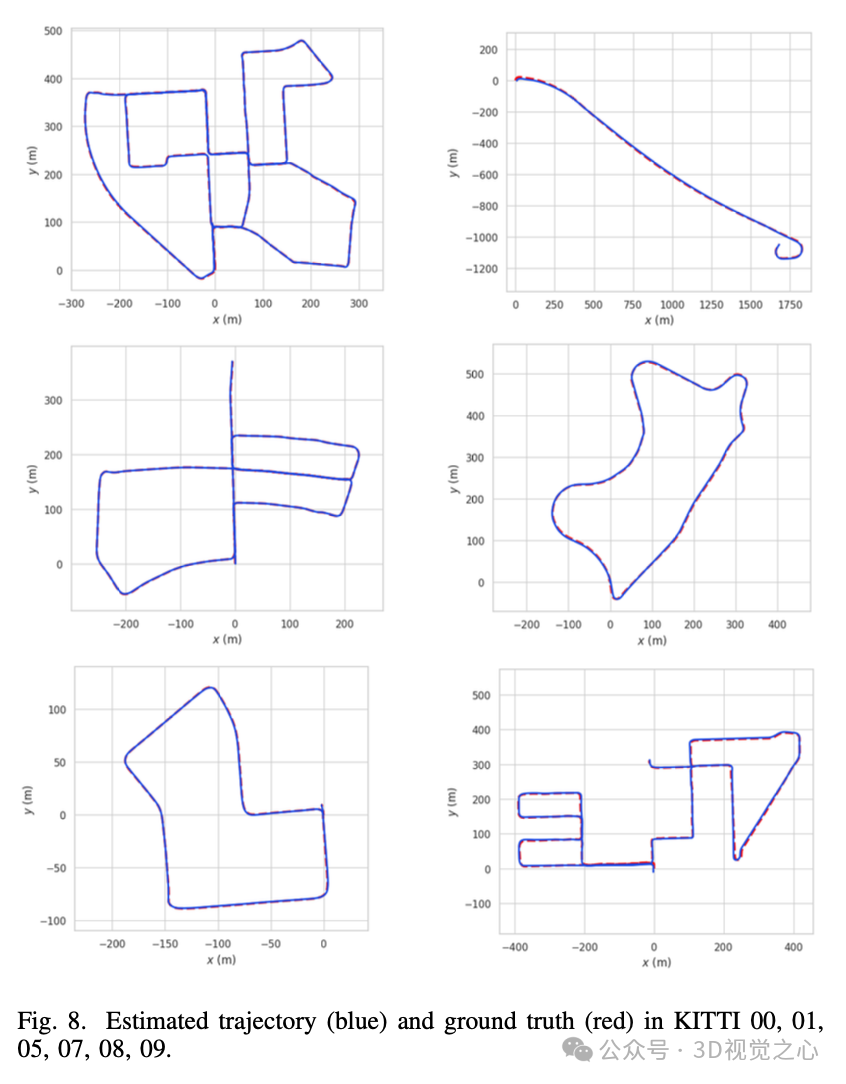
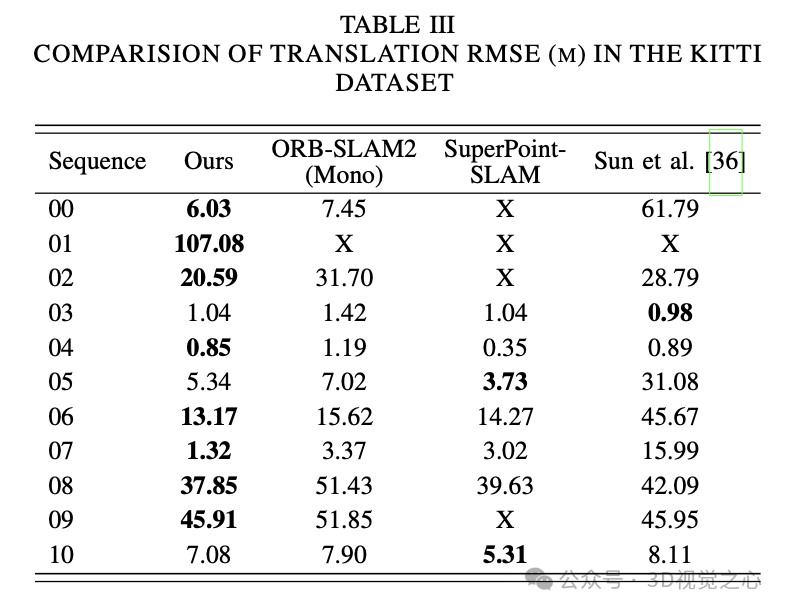

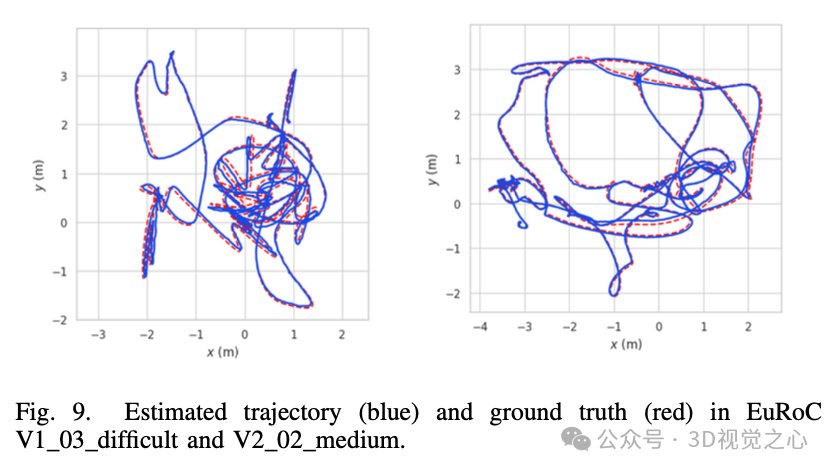
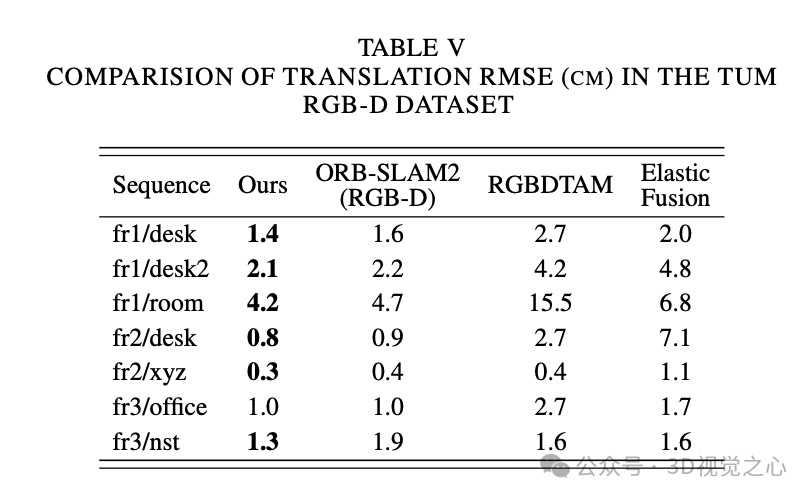

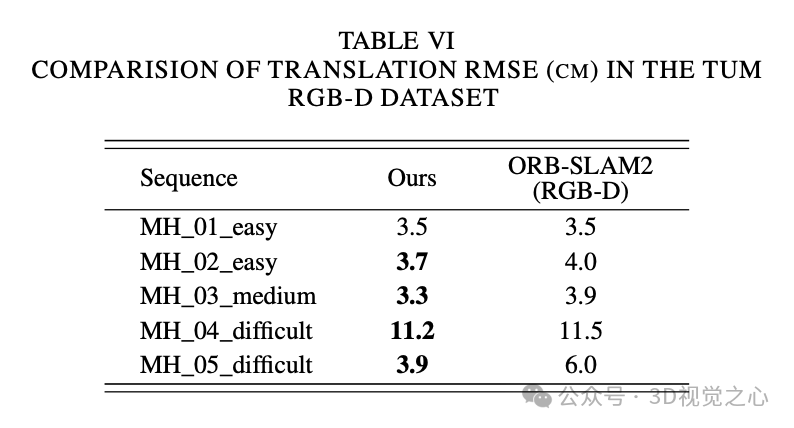
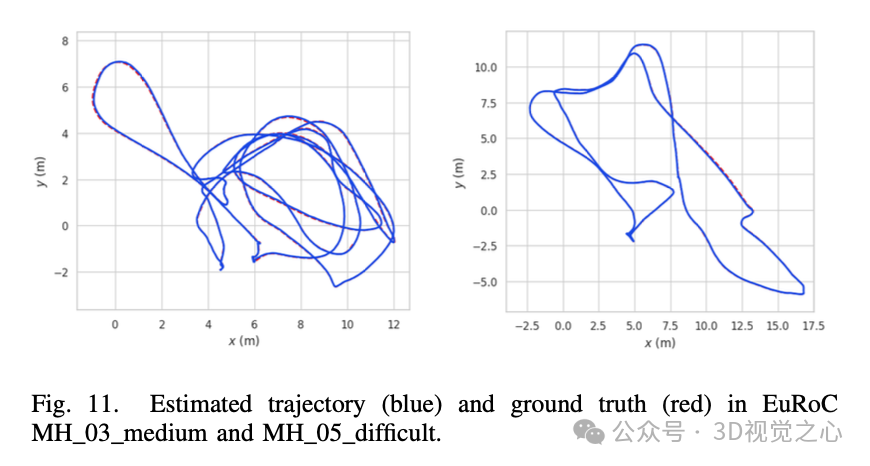
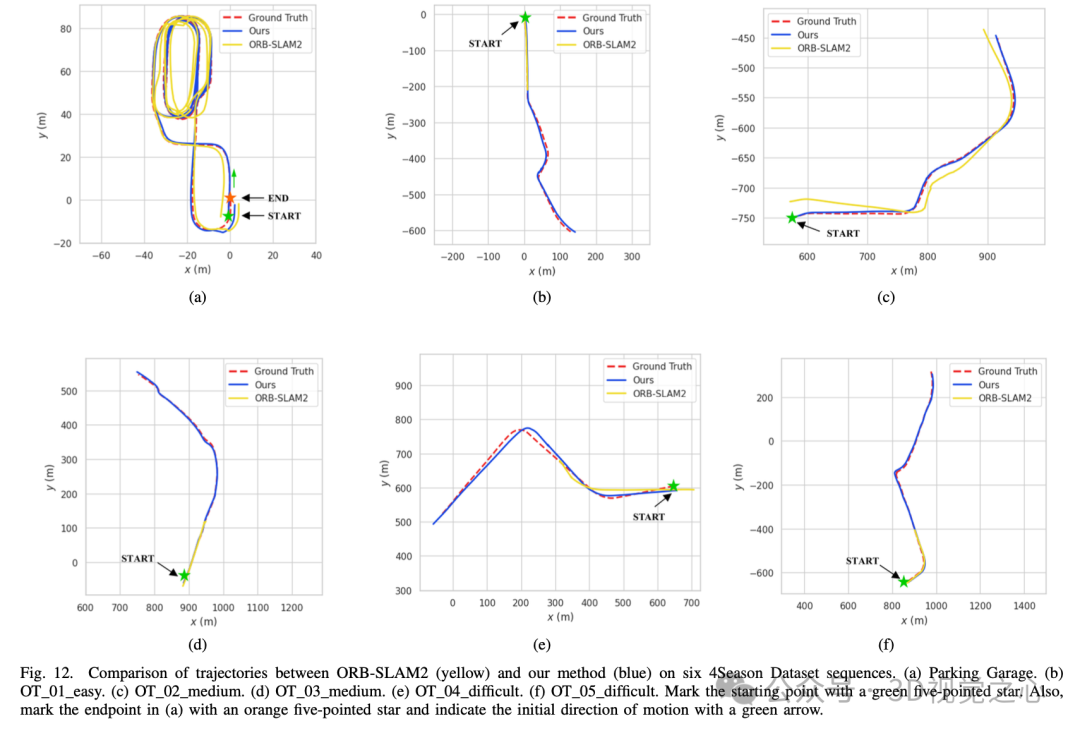
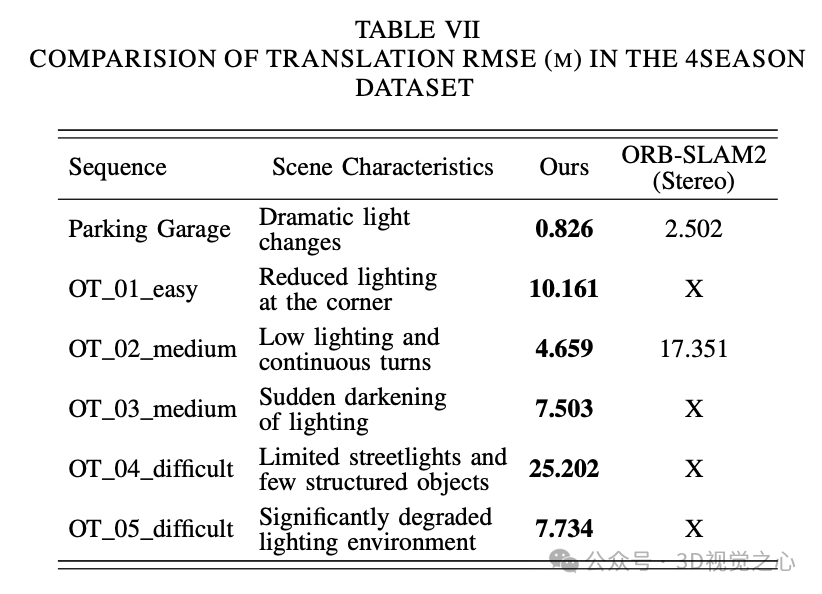
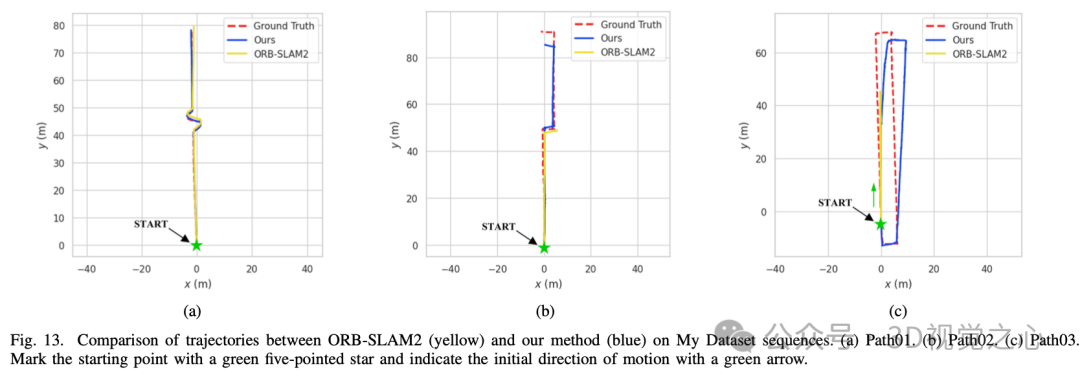
总结一下
Light-SLAM系统成功地将深度学习网络应用于传统视觉SLAM技术,从而实现了在不同时间和具有挑战性光照条件下的鲁棒且高度准确的实时定位。Light-SLAM充分利用了深度学习的优势,使用深度局部特征描述符取代了传统的手工设计特征,通过更准确高效的深度网络快速实现特征之间的精确匹配。
Light-SLAM在大多数数据集序列上的准确性和鲁棒性方面都优于传统的手工特征和基于深度学习的方法。即使在具有挑战性的低光场景中,它也能克服流行算法如ORB-SLAM2可能无法稳定运行的困难。
参考
[1] Light-SLAM: A Robust Deep-Learning Visual SLAM System Based on LightGlue under Challenging Lighting Conditions
[2] Lightglue: Local feature matching at light speed
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 1732
1732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









