






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家盘点3DGS&NeRF在自动驾驶重建方面的工作!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
编辑 | 自动驾驶之心
近几年,自动驾驶技术的发展日新月异。从ECCV 2020的NeRF问世再到SIGGRAPH 2023的3DGS,三维重建走上了快速发展的道路!再到自动驾驶端到端技术的问世,与之相关的仿真闭环开始频繁出现在大众视野中,新兴的三维重建技术由此在自动驾驶领域也逐渐焕发新机。2023年8月特斯拉发布FSD V12;2024年4月商汤绝影发布面向量产的端到端自动驾驶解决方法UniAD;2024年7月理想夏季发布会宣称端到端正式上车,快系统4D One Model、慢系统VLM,并首次提出『重建+生成』的世界模型测试方案。
可以说,端到端+仿真闭环是当下自动驾驶发展的主流路线。但是仿真闭环提了很多年,到底什么是仿真闭环?仿真闭环的核心又是什么?三维重建又在闭环中起到什么样的作用?业内也一直在讨论,百花齐放。无论如何,闭环的目的是明确的,降低实车测试的成本和风险、有效提高模型的开发效率进而优化系统性能、测试各种corner case并优化整个端到端算法。
今天就和大家盘一盘自动驾驶中新兴的三维重建技术相关算法。
MARS: An Instance-aware, Modular and Realistic Simulator for Autonomous Driving(CICAI 2023)
论文链接:https://arxiv.org/abs/2307.15058v1
代码链接:https://github.com/OPEN-AIR-SUN/mars
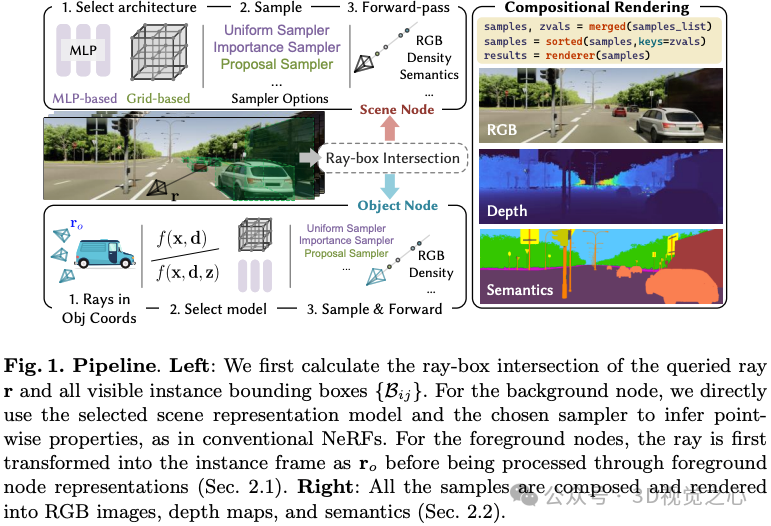
清华AIR提出的首个开源自动驾驶NeRF仿真工具!如今自动驾驶汽车在普通情况下可以平稳行驶,人们普遍认为,逼真的传感器仿真将在通过仿真解决剩余的corner case方面发挥关键作用。为此,我们提出了一种基于神经辐射场(NeRFs)的自动驾驶仿真器。与现有的工作相比,我们有三个显著的特点:
Instance-aware:前景目标和背景,单独建模,因此可以保证可控性
Modular:模块化设计,便于集成各种SOTA的算法进来
Realistic:由于模块化的设计,不同模块可以灵活选择比较好的算法实现,因此效果SOTA。
UniSim: A Neural Closed-Loop Sensor Simulator(CVPR 2023)
论文链接:https://arxiv.org/abs/2308.01898v1
项目主页:https://waabi.ai/unisim/

Waabi和多伦多大学在CVPR 2023上的工作:严格测试自动驾驶系统对于实现安全的自动驾驶汽车(SDV)至关重要。它要求人们生成超出世界上安全收集范围的安全关键场景,因为许多场景很少发生在公共道路上。为了准确评估性能,我们需要在闭环中测试这些场景中的SDV,其中SDV和其他参与者在每个时间步相互作用。以前记录的驾驶日志为构建这些新场景提供了丰富的资源,但对于闭环评估,我们需要根据新的场景配置和SDV的决定修改传感器数据,因为可能会添加或删除参与者,现有参与者和SDV之间的轨迹将与原始轨迹不同。本文介绍了UniSim,这是一种神经传感器模拟器,它将配备传感器的车辆捕获的单个记录日志转换为现实的闭环多传感器模拟。UniSim构建神经特征网格来重建场景中的静态背景和动态参与者,并将它们组合在一起,以在新视角仿真LiDAR和相机数据,添加或删除参与者以及新的位置。为了更好地处理外推视图,我们为动态目标引入了可学习的先验,并利用卷积网络来完成看不见的区域。我们的实验表明,UniSim可以在下游任务中模拟具有较小域间隙的真实传感器数据。通过UniSim,我们演示了在安全关键场景下对自主系统的闭环评估,就像在现实世界中一样。UniSim的主要贡献如下:
高度逼真(high realism): 可以准确地模拟真实世界(图片和LiDAR), 减小鸿沟(domain gap )
闭环测试(closed-loop simulation): 可以生成罕见的危险场景测试无人车, 并允许无人车和环境自由交互
可扩展 (scalable): 可以很容易的扩展到更多的场景, 只需要采集一次数据, 就能重建并仿真测
知乎解读:https://zhuanlan.zhihu.com/p/636695025
一作直播:https://www.bilibili.com/video/BV1nj41197TZ
EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision
论文链接:https://arxiv.org/abs/2311.02077v1
代码链接:https://github.com/NVlabs/EmerNeRF
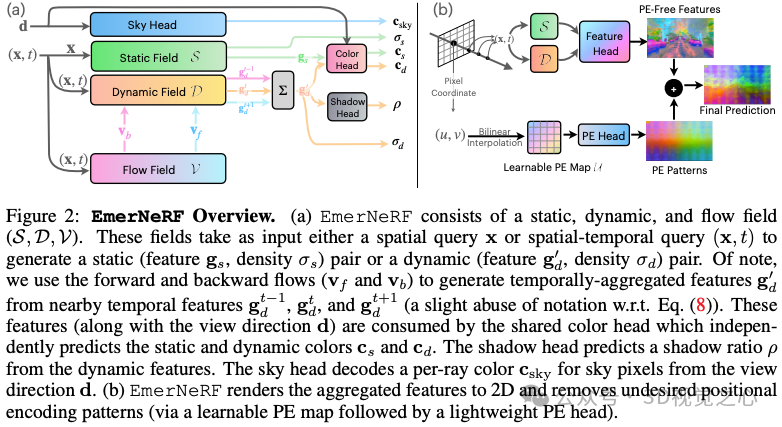
加利福尼亚大学的工作:本文提出了EmerNeRF,这是一种简单而强大的学习动态驾驶场景时空表示的方法。EmerNeRF以神经场为基础,通过自举同时捕获场景几何、外观、运动和语义。EmerNeRF依赖于两个核心组件:首先,它将场景划分为静态和动态场。这种分解纯粹源于自监督,使我们的模型能够从一般的、野外的数据源中学习。其次,EmerNeRF将动态场中的感应流场参数化,并使用该流场进一步聚合多帧特征,从而提高了动态目标的渲染精度。耦合这三个场(静态、动态和流)使EmerNeRF能够自给自足地表示高度动态的场景,而无需依赖GT标注或预先训练的模型进行动态目标分割或光流估计。我们的方法在传感器仿真中实现了最先进的性能,在重建静态(+2.93 PSNR)和动态(+3.70 PSNR)场景时明显优于以前的方法。此外,为了支持EmerNeRF的语义泛化,我们将2D视觉基础模型特征提升到4D时空中,并解决了现代变形金刚中的普遍位置偏差问题,显著提高了3D感知性能(例如,职业预测精度平均相对提高了37.50%)。最后,我们构建了一个多样化且具有挑战性的120序列数据集,用于在极端和高度动态的环境下对神经场进行基准测试。总结来说,本文的主要贡献如下:
EmerNeRF是一种新颖的4D神经场景表示框架,在具有挑战性的自动驾驶场景中表现出色。EmerNeRF通过自监督执行静态动态分解和场景流估计;
一种简化的方法,可以解决ViT中位置嵌入图案的不良影响,该方法可立即应用于其他任务;
我们引入NOTR数据集来评估各种条件下的神经场,并促进该领域的未来发展;
EmerNeRF在场景重建、新视角合成和场景流估计方面实现了最先进的性能。
NeuRAD: Neural Rendering for Autonomous Driving
论文链接:https://arxiv.org/abs/2311.15260v3
代码链接:https://github.com/georghess/neurad-studio
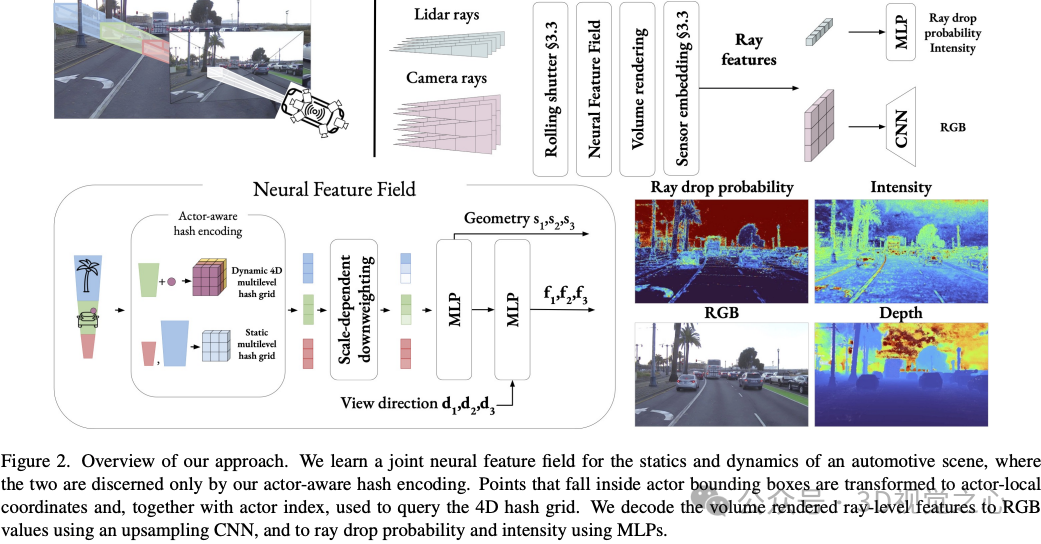
Zenseact的工作:神经辐射场(NeRF)在自动驾驶(AD)领域越来越受欢迎。最近的方法表明,NeRF具有闭环仿真的潜力,能够测试AD系统,并作为一种先进的训练数据增强技术。然而,现有的方法通常需要较长的训练时间、密集的语义监督或缺乏可推广性。这反过来又阻止了NeRFs大规模应用于AD。本文提出了NeuRAD,这是一种针对动态AD数据量身定制的鲁棒新型视图合成方法。我们的方法具有简单的网络设计,对相机和激光雷达进行了广泛的传感器建模,包括滚动快门、光束发散和光线下降,适用于开箱即用的多个数据集。我们在五个流行的AD数据集上验证了它的性能,全面实现了最先进的性能。
DrivingGaussian: Composite Gaussian Splatting for Surrounding Dynamic Autonomous Driving Scenes
论文链接:https://arxiv.org/abs/2312.07920v3
项目主页:https://pkuvdig.github.io/DrivingGaussian/
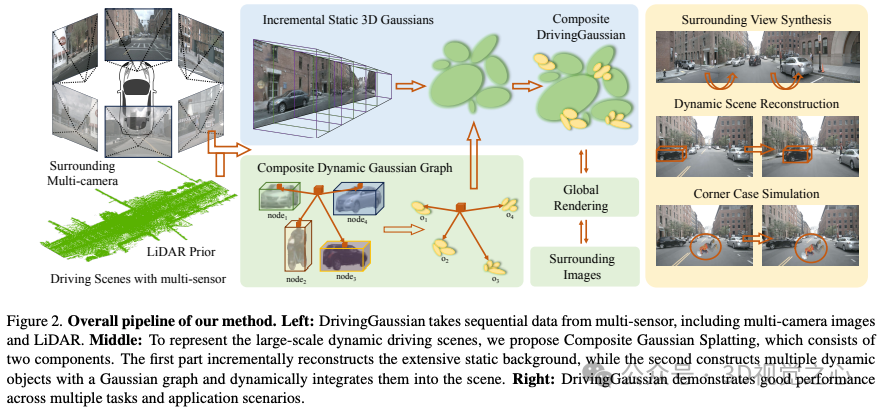
北大&谷歌的工作:本文提出了DrivingGaussian模型,这是一个用于环视动态自动驾驶场景的高效和有效的框架。对于具有运动目标的复杂场景,DrivingGaussian首先使用增量静态3D高斯对整个场景的静态背景进行顺序和渐进的建模。然后利用复合动态高斯图来处理多个运动目标,分别重建每个目标并恢复它们在场景中的准确位置和遮挡关系。我们进一步使用激光雷达先验进行 Gaussian Splatting,以重建具有更多细节的场景并保持全景一致性。DrivingGaussian在动态驱动场景重建方面优于现有方法,能够实现高保真度和多相机一致性的逼真环绕视图合成。总结来说,本文的主要贡献如下:
据我们所知,DrivingGaussian是基于复合Gaussian Splatting的大规模动态驾驶场景的第一个表示和建模框架;
引入了两个新模块,包括增量静态3D高斯图和复合动态高斯图。前者逐步重建静态背景,而后者用高斯图对多个动态目标进行建模。在激光雷达先验的辅助下,所提出的方法有助于在大规模驾驶场景中恢复完整的几何形状;
综合实验表明,Driving Gaussian在挑战自动驾驶基准测试方面优于以前的方法,并能够为各种下游任务进行角情况仿真;
Street Gaussians: Modeling Dynamic Urban Scenes with Gaussian Splatting(ECCV 2024)
论文链接:https://arxiv.org/abs/2401.01339v2
代码链接:https://github.com/zju3dv/street_gaussians
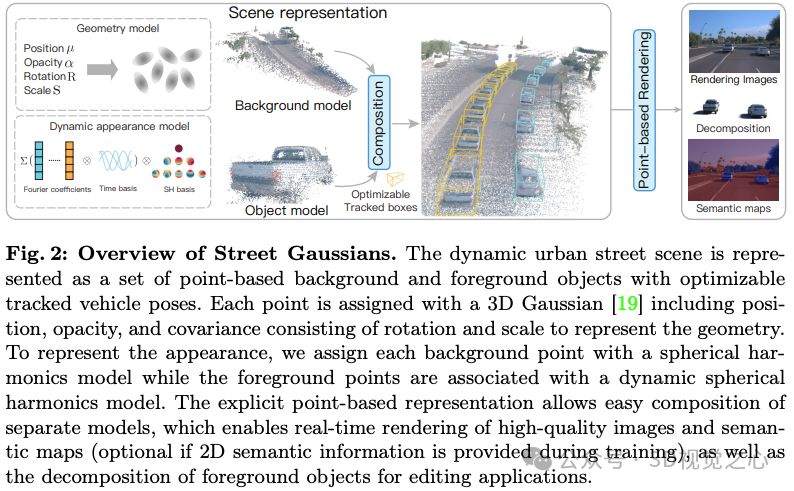
浙大&理想在ECCV 2024上的工作:本文旨在解决自动驾驶场景中动态城市街道的建模问题。最近的方法通过将跟踪的车辆姿态结合到车辆动画中来扩展NeRF,实现了动态城市街道场景的照片级逼真视图合成。然而,它们的训练速度和渲染速度都很慢。为此本文引入了Street Gaussians,这是一种新的显式场景表示,可以解决这些限制。具体来说,动态城市场景被表示为一组配备语义逻辑和3D高斯的点云,每个点云都与前景车辆或背景相关联。为了仿真前景目标车辆的动力学,每个目标点云都使用可优化的跟踪姿态进行优化,并使用4D球谐模型进行动态外观优化。显式表示允许轻松组合目标车辆和背景,这反过来又允许在半小时的训练内以135 FPS(1066×1600分辨率)进行场景编辑操作和渲染。该方法在多个具有挑战性的基准上进行了评估,包括KITTI和Waymo Open数据集。实验表明在所有数据集上,所提出的方法始终优于最先进的方法。
GaussianPro: 3D Gaussian Splatting with Progressive Propagation
论文链接:https://arxiv.org/abs/2402.14650v1
代码链接:https://github.com/kcheng1021/GaussianPro

中科大&港大的工作:3DGS的出现最近在神经渲染领域带来了一场革命,促进了实时速度的高质量渲染。然而,3DGS在很大程度上依赖于运动结构(SfM)技术产生的初始化点云。当处理不可避免地包含无纹理曲面的大规模场景时,SfM技术总是无法在这些曲面上产生足够的点,也无法为3DGS提供良好的初始化。因此,3DGS存在优化困难和渲染质量低的问题。在这篇论文中,受经典多视图立体(MVS)技术的启发,我们提出了GaussianPro,这是一种应用渐进传播策略来指导3D Gaussian致密化的新方法。与3DGS中使用的简单分割和克隆策略相比,我们的方法利用场景现有重建几何的先验和补丁匹配技术来生成具有精确位置和方向的新高斯分布。在大规模和小规模场景上的实验验证了我们方法的有效性,我们的方法在Waymo数据集上显著超过了3DGS,在PSNR方面提高了1.15dB。
LidaRF: Delving into Lidar for Neural Radiance Field on Street Scenes
论文链接:https://arxiv.org/abs/2405.00900v2
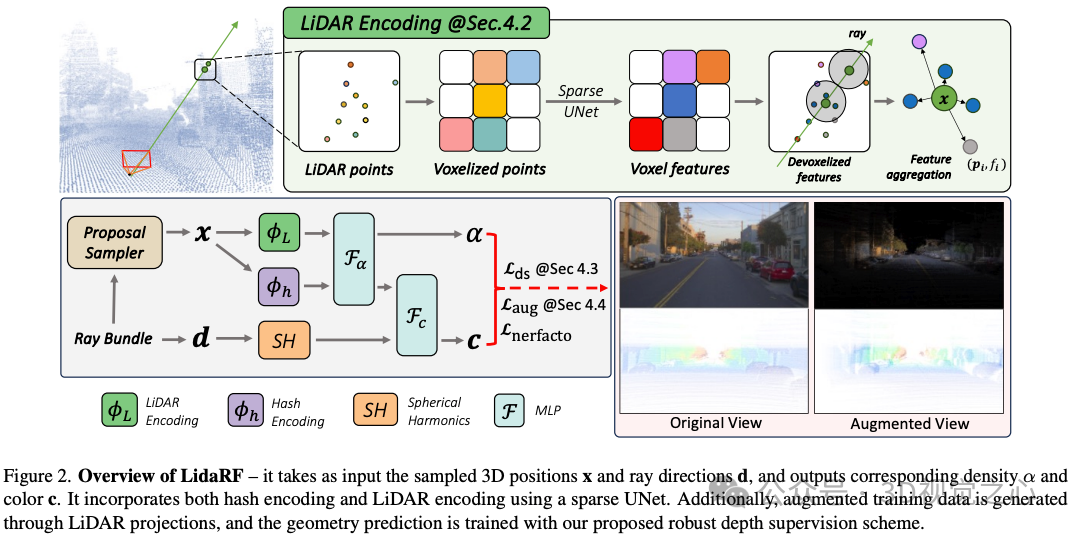
加州大学欧文分校的工作:真实仿真在自动驾驶等应用中起着至关重要的作用,神经辐射场(NeRF)的进步可以通过自动创建数字3D资产来实现更好的可扩展性。然而,由于共线相机的大运动和高速下的稀疏样本,街道场景的重建质量会受到影响。另一方面,实际使用通常要求从偏离输入的相机视图进行渲染,以准确模拟车道变换等行为。在这篇论文中,我们提出了几个见解,可以更好地利用激光雷达数据来提高街道场景的NeRF质量。首先,我们的框架从激光雷达中学习几何场景表示,将其与隐式基于网格的表示融合用于辐射解码,然后提供显式点云提供的更强几何信息。其次提出了一种鲁棒的遮挡感知深度监督方案,该方案允许通过累积来利用密集的激光雷达点。第三本文从激光雷达点生成增强训练视图,以进一步改进。我们的见解转化为在真实驾驶场景下大大改进的新视图合成。
Gaussian: Self-Supervised Street Gaussians for Autonomous Driving
论文链接:https://arxiv.org/abs/2405.20323v1
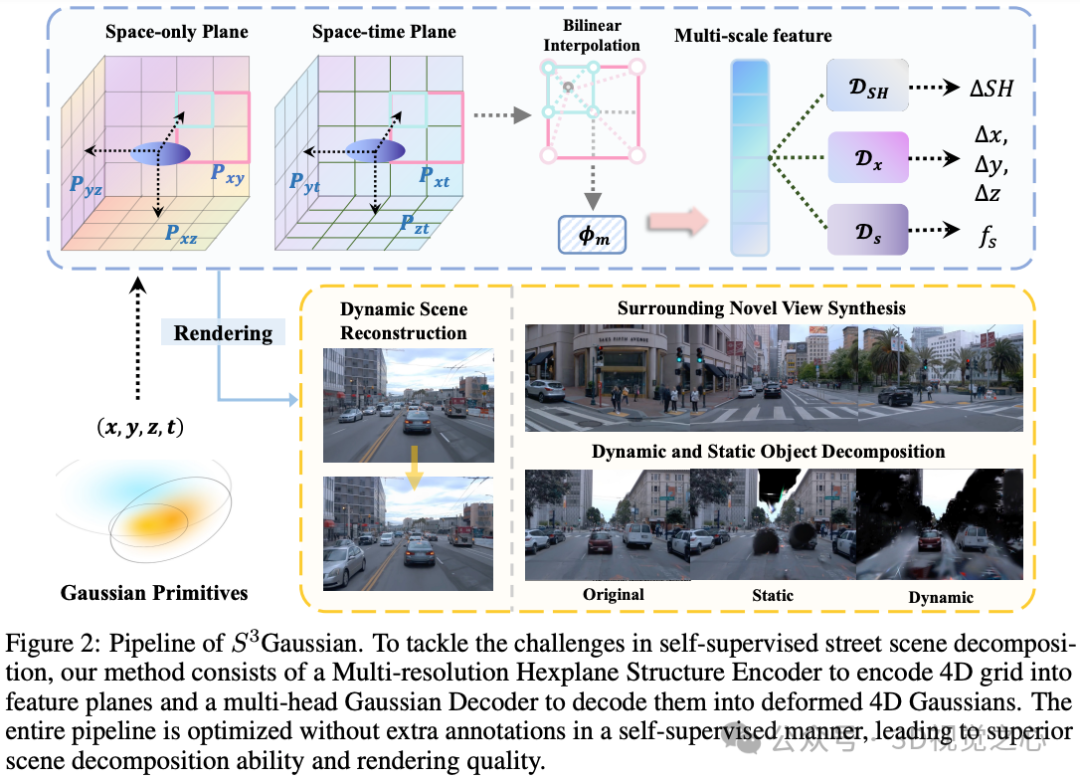
UC Berkeley&北大&清华的工作:街道场景的真实感3D重建是开发自动驾驶仿真的关键技术。尽管神经辐射场(NeRF)在驾驶场景中的效率很高,但3DGS因其更快的速度和更明确的表示而成为一个有前景的方向。然而,大多数现有的街道3DGS方法需要跟踪的3D车辆边界框来分解静态和动态元素以进行有效的重建,这限制了它们在自由场景中的应用。为了在没有标注的情况下实现高效的3D场景重建,我们提出了一种自监督街道高斯(S3Gaussian)方法,用于从4D一致性中分解动态和静态元素。我们用3D高斯分布来表示每个场景,以保持其明确性,并进一步用时空场网络来压缩4D动力学模型。我们在具有挑战性的Waymo Open数据集上进行了广泛的实验,以评估我们方法的有效性。我们的S3Gaussian展示了分解静态和动态场景的能力,并在不使用3D标注的情况下实现了最佳性能。
Dynamic 3D Gaussian Fields for Urban Areas
论文链接:https://arxiv.org/abs/2406.03175v1
代码链接:https://github.com/tobiasfshr/map4d(待开源)
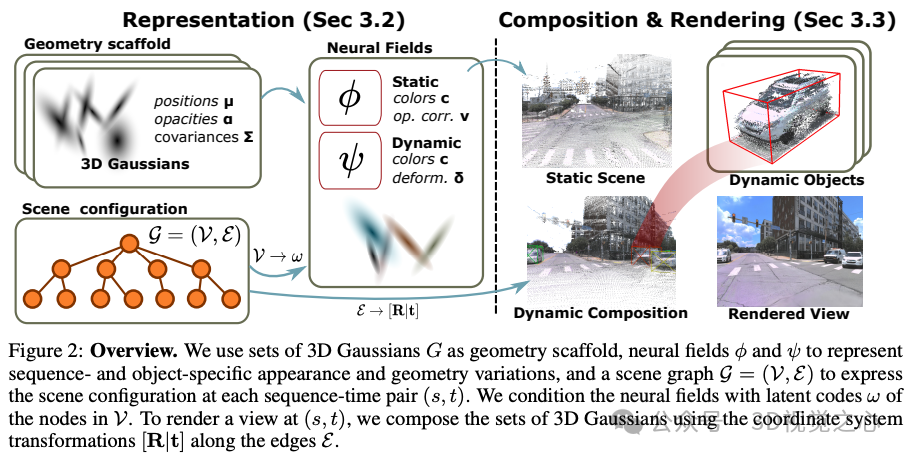
ETH和Meta的工作:本文提出了一种高效的神经3D场景表示方法,用于大规模动态城市地区的新视图合成(NVS)。由于其有限的视觉质量和非交互式渲染速度,现有工作品不太适合混合现实或闭环仿真等应用。最近,基于光栅化的方法以令人印象深刻的速度实现了高质量的NVS。然而,这些方法仅限于小规模、均匀的数据,即它们无法处理由于天气、季节和光照引起的严重外观和几何变化,也无法扩展到具有数千张图像的更大、动态的区域。我们提出了4DGF,这是一种神经场景表示,可扩展到大规模动态城市区域,处理异构输入数据,并大大提高了渲染速度。我们使用3D高斯作为高效的几何支架,同时依赖神经场作为紧凑灵活的外观模型。我们通过全局尺度的场景图集成场景动力学,同时通过变形在局部层面建模关节运动。这种分解方法实现了适用于现实世界应用的灵活场景合成。在实验中,我们绕过了最先进的技术,PSNR超过3dB,渲染速度超过200倍。
StreetSurf: Extending Multi-view Implicit Surface Reconstruction to Street Views
论文链接:https://arxiv.org/abs/2306.04988v1
代码链接:https://github.com/pjlab-ADG/neuralsim
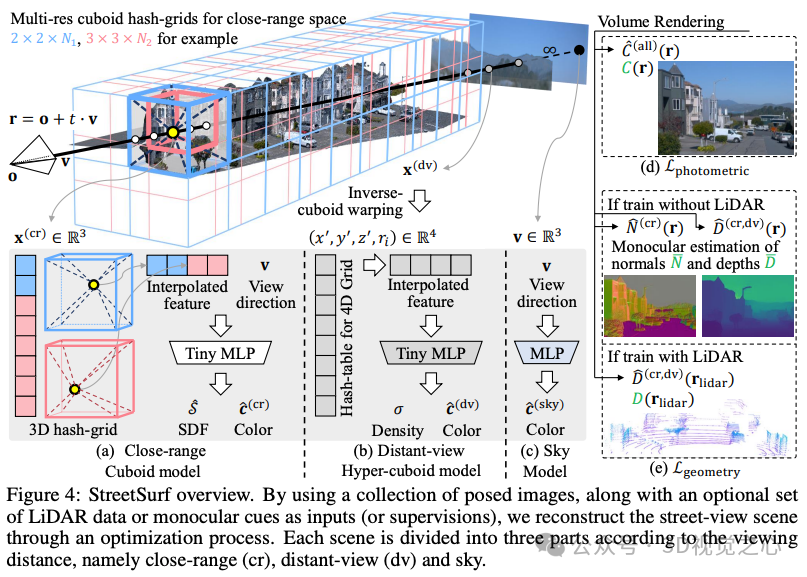
上海AI Lab和商汤的工作:本文提出了一种新的多视图隐式表面重建技术,称为StreetSurf,该技术很容易应用于广泛使用的自动驾驶数据集中的街景图像,如Waymo感知序列,而不一定需要LiDAR数据。随着神经渲染研究的迅速发展,将其整合到街景中开始引起人们的兴趣。现有的街景方法要么主要关注新视图合成,很少探索场景几何,要么在研究重建时严重依赖密集的LiDAR数据。他们都没有研究多视图隐式表面重建,特别是在没有激光雷达数据的情况下。我们的方法扩展了现有的以目标为中心的神经表面重建技术,以解决由非以目标为核心、长而窄的相机轨迹捕获的无约束街景所带来的独特挑战。我们将无约束空间划分为近距离、远景和天空三个部分,具有对齐的长方体边界,并采用长方体/超长方体哈希网格以及路面初始化方案,以实现更精细和更复杂的表示。为了进一步解决无纹理区域和视角不足引起的几何误差,我们采用了使用通用单目模型估计的几何先验。再加上我们实施了高效细粒度的多级光线行进策略,我们使用单个RTX3090 GPU对每个街道视图序列进行训练,仅需一到两个小时的时间,即可在几何和外观方面实现最先进的重建质量。此外,我们证明了重建的隐式曲面在各种下游任务中具有丰富的潜力,包括光线追踪和激光雷达模拟。
AutoSplat: Constrained Gaussian Splatting for Autonomous Driving Scene Reconstruction
论文链接:https://arxiv.org/abs/2407.02598v2
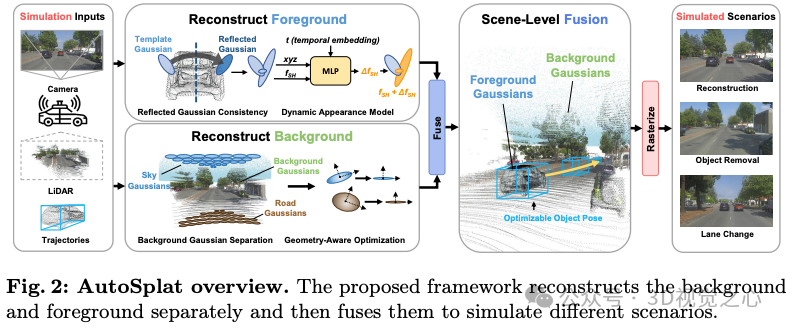
多伦多大学和华为诺亚的工作:逼真的场景重建和视图合成对于通过仿真安全关键场景来推进自动驾驶系统至关重要。3DGS在实时渲染和静态场景重建方面表现出色,但由于复杂的背景、动态对象和稀疏视图,在建模驾驶场景方面遇到了困难。我们提出了AutoPlat,这是一个采用Gaussian Splatting实现自动驾驶场景高度逼真重建的框架。通过对表示道路和天空区域的高斯分布图施加几何约束,我们的方法能够对包括车道变换在内的具有挑战性的场景进行多视图一致的模拟。利用3D模板,我们引入了反射高斯一致性约束来监督前景对象的可见面和不可见面。此外,为了模拟前景对象的动态外观,我们估计了每个前景高斯的残差球面谐波。在Pandaset和KITTI上进行的大量实验表明,AutoPlat在各种驾驶场景中的场景重建和新颖视图合成方面优于最先进的方法。
DHGS: Decoupled Hybrid Gaussian Splatting for Driving Scene
论文链接:https://arxiv.org/abs/2407.16600v3
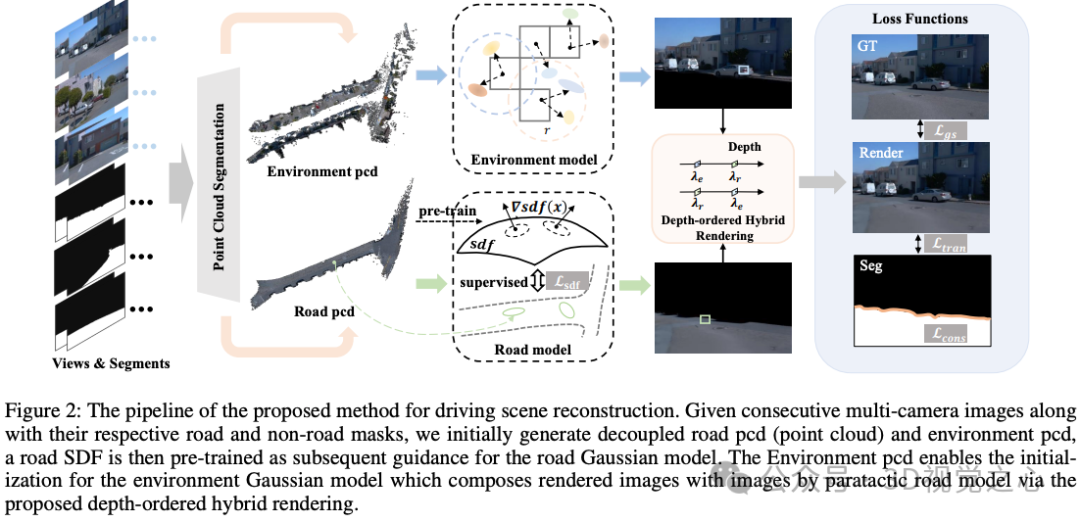
长安汽车的工作:现有的GS方法在实现驾驶场景中令人满意的新视图合成方面往往不足,主要是由于缺乏巧妙的设计和所涉及元素的几何约束。本文介绍了一种新的神经渲染方法,称为解耦混合GS(DHGS),旨在提高静态驾驶场景新型视图合成的渲染质量。这项工作的新颖之处在于,针对道路和非道路层的解耦和混合像素级混合器,没有针对整个场景的传统统一差分渲染逻辑,同时通过提出的深度有序混合渲染策略仍然保持一致和连续的叠加。此外,对由符号距离场(SDF)组成的隐式道路表示进行训练,以监控具有微妙几何属性的路面。伴随着辅助传输损耗和一致性损耗的使用,最终保留了具有不可察觉边界和高保真度的新图像。在Waymo数据集上进行的大量实验证明,DHGS的性能优于最先进的方法。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 2610
2610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









