






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心为大家分享加利福尼亚大学最新的工作—V2XPnP!论文提出了面向多智能体感知与预测的V2X时空融合新方案。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
论文作者 | Zewei Zhou等
编辑 | 自动驾驶之心
V2XPnP的算法概览
V2X 技术为缓解单一车辆系统在观测能力上的局限性提供了一个有前景的范式。之前的研究主要集中在单帧协同感知上,该方法融合了来自不同空间位置的智能体信息,但忽略了时间线索和时间相关任务(例如,时间感知和预测)。本文聚焦于V2X场景中的时间感知和预测任务,并设计了单步和多步通信策略(即何时传输),同时考察了这两种策略与三种融合策略——早期融合、后期融合和中间融合(即传输什么信息)的结合,并提供了与各种融合模型的综合基准(即如何融合)。此外,本文提出了V2XPnP,一个新的中间融合框架,适用于单步通信中的端到端感知和预测。本文的框架采用统一的基于Transformer的架构,有效建模跨时间帧、空间智能体和高清地图的复杂时空关系。本文还引入了V2XPnP序列数据集,该数据集支持所有V2X协作模式,并解决了现有现实世界数据集的局限性——这些现有数据集仅支持单帧或单模式的协作。大量实验表明,本文的框架在感知和预测任务中均优于现有的最先进方法。
论文链接:https://arxiv.org/pdf/2412.01812

主要贡献
本文提出了V2XPnP,一个V2X时空融合框架,采用了一种新颖的中间融合模型,适用于单步通信。该框架基于统一的Transformer架构,集成了多种注意力融合模块,用于V2X时空信息的融合。
本文引入了首个大规模现实世界V2X序列数据集,涵盖多个智能体和所有V2X协作模式(即VC、IC、V2V、I2I),包括感知数据、物体轨迹和地图数据。
本文对各种时空融合策略进行了广泛分析,并为所有V2X协作模式下的协同感知和预测任务提供了全面的基准,展示了所提模型在协同时间感知和预测任务中的最先进性能。
方法设计:
自动驾驶系统需要准确感知周围的道路用户,并预测其未来轨迹,以确保安全和互动驾驶。尽管在感知和预测方面已有一些进展,但单一车辆系统仍然面临感知范围有限和遮挡问题,这影响了驾驶性能和道路安全。因此,V2X技术作为一种有前景的范式应运而生,能够让联网自动驾驶车辆(CAVs)和基础设施共享互补信息,减少遮挡,从而支持全面的环境理解。
尽管V2X技术具有潜力,现有的研究主要集中在逐帧协同检测,该方法聚合来自不同空间位置的智能体信息。然而,这些研究忽略了跨序列帧的时间线索,而这些线索对于定位之前可见但当前未检测到的物体[44]以及预测物体未来轨迹[29]至关重要。V2X在增强这些时间相关任务,特别是在协同时间感知和预测方面的潜力,仍然很大程度上未得到探索。本文旨在解决多智能体协作中的关键问题:(1)应传输什么信息?(2)何时传输?(3)如何跨空间和时间维度融合信息?为了回答“应传输什么信息”,本文扩展了单帧协同感知中的三种融合策略(即早期融合、后期融合和中间融合),以涵盖时间维度。关于“何时传输”,本文引入了单步和多步通信策略,以捕捉多帧时间信息。至于“如何融合”,本文对各种时空融合策略进行了系统分析,为所有V2X协作模式下的协同感知和预测任务提供了全面的基准。
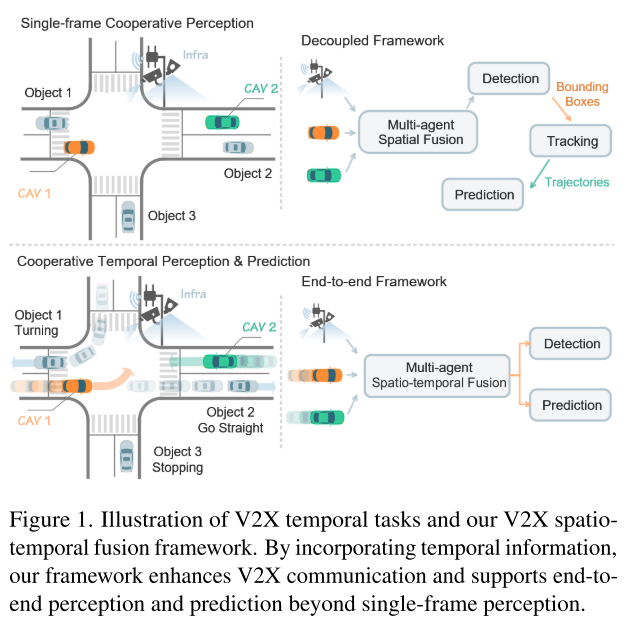
在这些策略中,本文提倡在单步通信中使用中间融合策略,因为它有效地平衡了精度和增加的传输负载之间的权衡。此外,它能够传输中间时空特征,使其非常适合端到端的感知和预测,支持跨多个任务的特征共享,并减少计算需求,如图1所示。基于这一策略,本文提出了V2XPnP,一个V2X时空融合框架,利用统一的Transformer结构进行有效的时空融合,涵盖时间注意力、自空间注意力、多智能体空间注意力和地图注意力。每个智能体首先提取其跨帧和自空间特征,这些特征可以支持单车感知和预测,同时减少通信负载,然后多智能体空间注意力模型将单智能体特征在不同智能体之间进行融合。
另一个挑战是缺乏涵盖多种V2X协作模式的现实世界序列数据集。在V2X场景中,车辆和基础设施作为主要智能体,协作模式包括车对车(V2V)、车对基础设施(V2I)和基础设施对基础设施(I2I)。大多数现有数据集是非序列型的,局限于单一协作模式,且仅关注单帧协同感知,缺乏对时间相关任务的支持。为弥补这一空白,本文引入了首个大规模现实世界V2XPnP序列数据集,该数据集包含四种智能体,并支持所有协作模式。该数据集包括100个以车辆为中心(VC)的场景和63个以基础设施为中心(IC)的场景,具有时间一致的感知和轨迹数据,共计40k帧,并提供来自24个交叉口的点云和矢量地图数据。
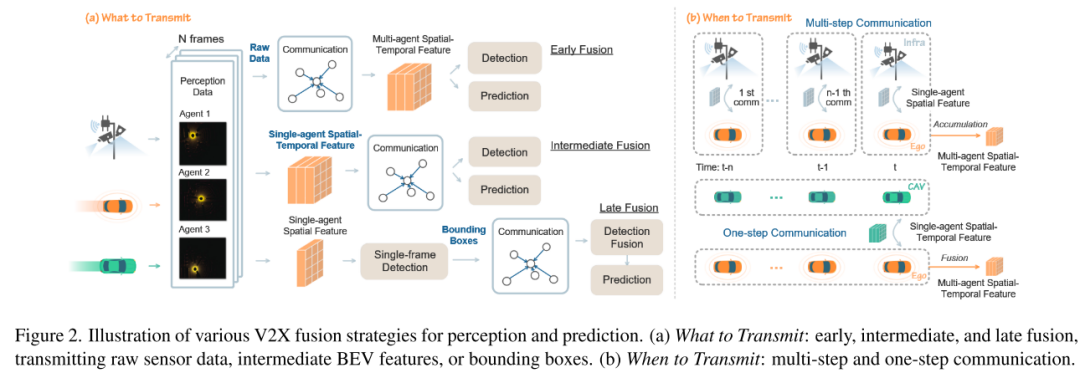
(a) 传输什么信息:早期融合、中间融合和后期融合,分别传输原始传感器数据、中间BEV特征或边界框。
(b) 何时传输:多步通信和单步通信。
中间融合的时空特征使其成为端到端感知和预测的自然选择。因此,本文提出了一个统一的端到端感知和预测框架,用于跨时空维度执行多个任务。整体V2XPnP框架如图3所示,包括六个组件,本文将对其进行详细展开。时空融合模型的详细内容请参见第3.3节。值得注意的是,V2XPnP中的每个模块都是模块化的,便于替换。
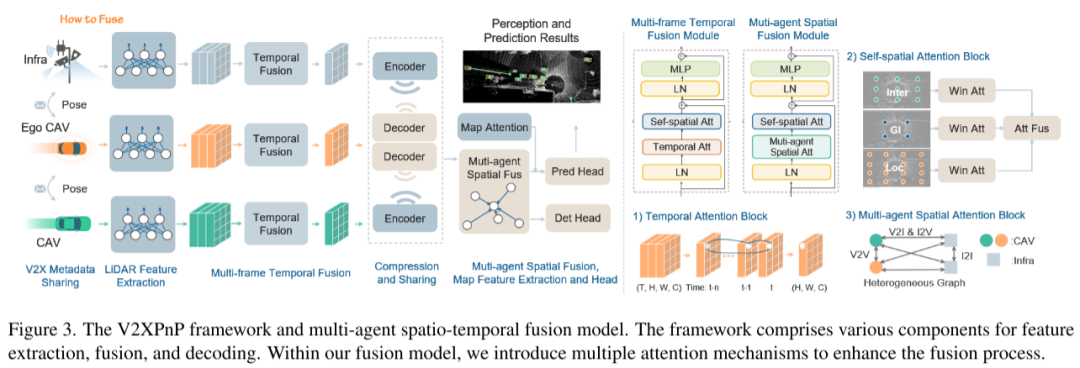
本文提出了基于统一Transformer架构的时空融合。所提模型由三个模块组成:时间注意力、自空间注意力和多智能体空间注意力,如图3所示,以及两个核心融合模块。
(1) 多帧时间融合:每个智能体首先通过迭代的时间注意力和自空间注意力提取其时空特征。
(2) 多智能体空间融合:通过V2X获取来自多个智能体的丰富BEV特征,然后通过迭代的多智能体空间注意力和自空间注意力进行融合。
本文提出了V2XPnP-Sequential数据集,这是首个大规模、现实世界的V2X序列数据集,涵盖多个智能体和所有协作模式。该数据集包含100个场景,每个场景跨越95到283帧,采样频率为10 Hz。数据集包括来自CAV感知的两种数据序列(点云和相机图像)和来自基础设施感知的两种数据序列,如图4(b)所示。本文还为所有采集区域提供了相应的矢量地图和点云地图,如图4(c)所示。数据集包含十个物体类别,每个类别的平均轨迹长度和频率如图4(d)所示。关于数据标注、轨迹和地图生成的更多细节,请参见补充材料。
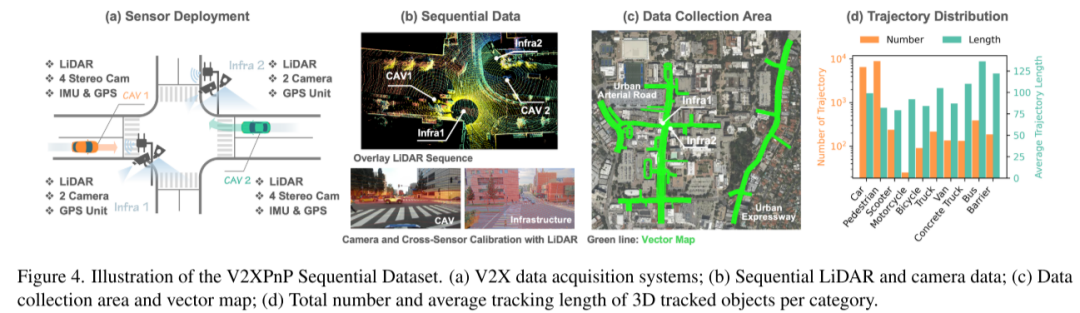
(a) V2X数据采集系统;
(b) 序列LiDAR和相机数据;
(c) 数据采集区域和矢量地图;
(d) 每类3D跟踪物体的总数量和平均跟踪长度。
实验结果:

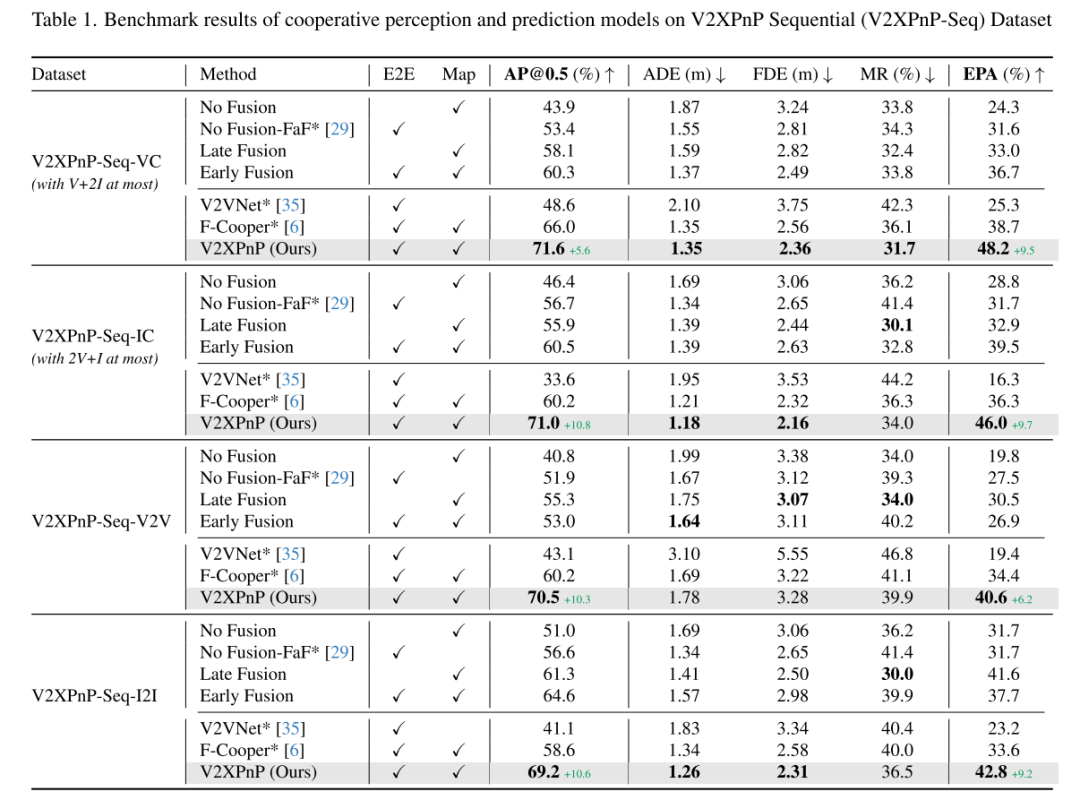
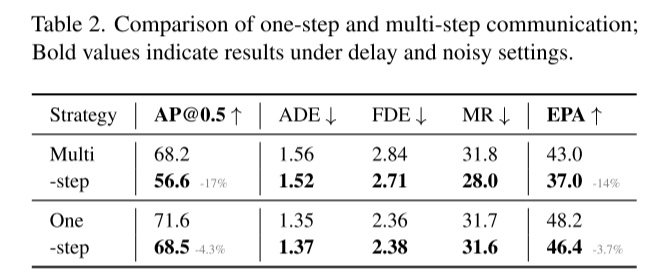
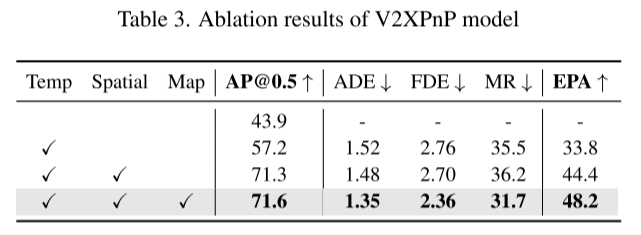
总结:
本文提出了V2XPnP,一种用于协同时间感知和预测的新型V2X时空融合框架。该框架的核心是一个基于统一Transformer模型的时空融合和地图融合机制。此外,本文探讨了关于“传输什么信息”、“何时传输”和“如何融合”的不同融合策略,并提供了全面的基准。本文还引入了V2X Sequential数据集,该数据集支持所有V2X协作模式。大量实验评估结果表明,所提框架具有优越的性能,证明了其在推进V2X支持的协同时间任务中的有效性。未来的工作将集中于开发更有效的融合模型和自适应通信策略,以动态优化带宽利用率。
引用:
@article{zhou2024v2xpnp,
title={V2XPnP: Vehicle-to-Everything Spatio-Temporal Fusion for Multi-Agent Perception and Prediction},
author={Zhou, Zewei and Xiang, Hao and Zheng, Zhaoliang and Zhao, Seth Z. and Lei, Mingyue and Zhang, Yun and Cai, Tianhui and Liu, Xinyi and Liu, Johnson and Bajji, Maheswari and Pham, Jacob and Xia, Xin and Huang, Zhiyu and Zhou, Bolei and Ma, Jiaqi},
journal={arXiv preprint arXiv:2412.01812},
year={2024}
}① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









