






点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享理想汽车&中科院&清华最新的工作!TransDiffuser:生成式端到端自动驾驶最新方案。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶之心『端到端自动驾驶』技术交流群
论文作者 | Xuefeng Jiang等
编辑 | 自动驾驶之心
写在前面
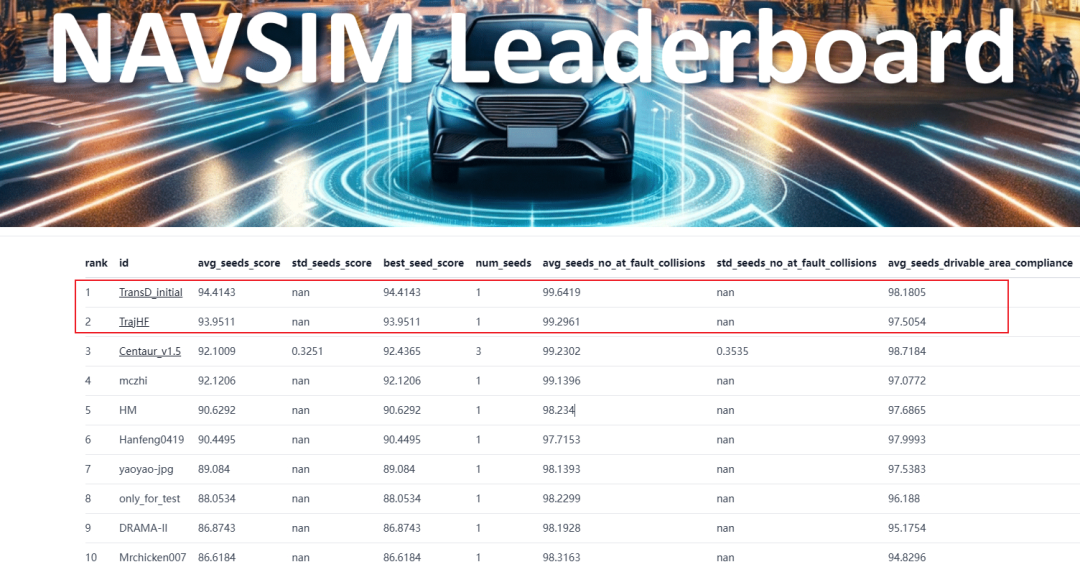
自从UniAD在CVPR’23获得了Best Paper奖项,近两年来,端到端自动驾驶在近年来吸引了许多学术界与工业界的关注。近期一个研究趋势从传统的轨迹规划方案转向了对多模式生成式轨迹规划的探索,典型的两个代表工作为录用于CVPR'25的GoalFlow与DiffusionDrive。近期,理想汽车放出了两篇在生成式端到端自动驾驶这一领域的探索,分别为3月的TrajHF与5月最新放出的TransDiffuser,其中TransDiffuser是基于TrajHF做的进一步改进,这两个方案目前在HuggingFace的NAVSIM leaderboard这一权威榜单上居于前两名,进一步提高了生成式轨迹规划模型的性能上限。本篇文章将主要分享TransDiffuser这一论文的主要技术思路。
TransDiffuser论文链接:https://arxiv.org/abs/2505.09315
一作主页:https://sprinter1999.github.io/website/
实验结果表明TransDiffuser在NAVSIM数据集上实现了94.85的PDMS,并且不需要任何基于Anchor的先验轨迹。

简介
TransDiffuser 是一种生成式端到端自动驾驶轨迹规划模型,由理想汽车、中科院计算所与清华大学的研究人员合作完成。模型的输入为前视相机图像、激光雷达与当前车辆的运动信息,通过作者所设计的基于DDPM的Denoising Decoder架构进行多模态信息的融合,并通过多模态表示解相关策略对融合信息进行进一步优化,最后解码出规划轨迹。笔者认为,本文的核心创新在于所引入的多模态表示解相关化的优化策略。TransDiffuser在 NAVSIM 基准测试中取得了最新State-of-the-art效果,目前在Leaderboard上提交的结果也取得了榜首,并且相较于GoalFlow与DiffusionDrive这两个相关工作,该模型无需依赖任何锚点轨迹或预定义轨迹词汇表,而是直接从高斯噪声解码潜在轨迹。这表明该模型在复杂交通场景中具有出色的泛化能力和适应性,能够生成高质量且多样化的轨迹规划方案。另外值得注意的是,本文沿着DiffusionDrive,进一步强调了生成轨迹多样性的重要性,并汇报了对应量化指标。
相关工作
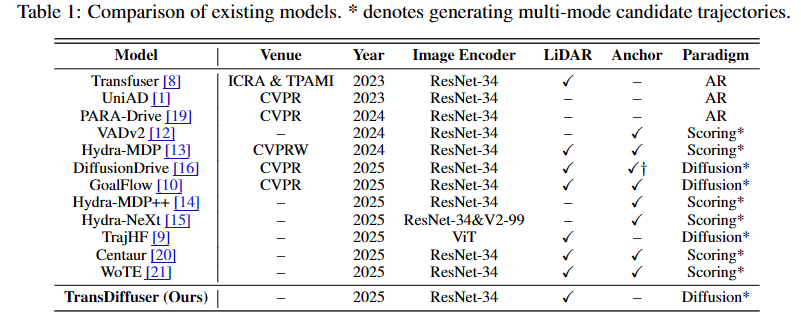
在论文中,作者将现有方法分为自回归(AR)、评分(Scoring)与扩散生成(Diffusion)三类方法。以UniAD为代表,传统模型往往只回归一条规划轨迹。以英伟达Hydra-MDP为代表,基于Scoring的方案往往先采样或者选出多条候选的轨迹,结合不同指标或者策略选出一条最优轨迹。以DiffusionDrive和GoalFlow为代表,基于扩散生成的方案,往往将环境信息与自车状态进行编码,利用基于扩散策略的生成式模型来生成可能轨迹。值得注意的是,现有工作的一个显著研究趋势为生成多个候选轨迹,再选取最优轨迹作为最终轨迹。
方法
和之前理想提出的TrajHF框架相似,本文所提的TransDiffuser是一个“编码器-解码器”架构的模型。作者使用冻结的Transfuser模型对当前自车的图像与激光雷达采集的点云进行特征融合与编码,同时对自车的运动信息通过简单的MLP架构进行编码。所编码的多模态信息会通过基于扩散策略的去噪解码器(Denoising Decoder)完成多模态特征进一步融合,最终解码最终轨迹。
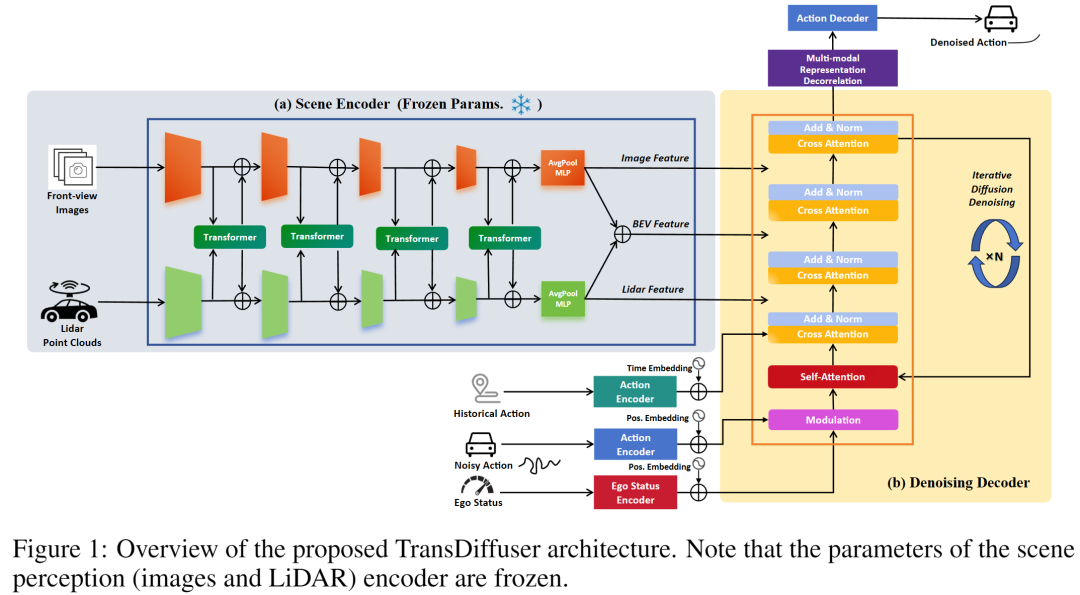
作者冻结了用于编码图像与激光雷达的Transfuser模块,在训练部分,作者参考DiffusionDrive的实现,使用去噪扩散概率模型作为优化框架,主要训练Denoising Decoder部分,关注从高斯噪声向无噪声状态的逆向去噪过程,通过特定方程实现状态的逐步去噪。需要注意的是,作者并不依赖轨迹词表或者锚点信息作为先验,这体现了使用纯高斯噪声也可以生成高质量候选轨迹的可能性。

本文创新之处在于,作者强调生成规划轨迹这一任务中潜在的模式坍塌(Mode collapse)挑战。这一挑战最初在DiffusionDrive这篇工作中被提出,具体是指不同初始化下,模型生成的多条轨迹的多样性受限。为缓解这一问题,作者通过约束多模态表示矩阵的相关矩阵的非对角相关系数趋近于零,降低不同模态维度间的冗余信息,从而拓展潜在表征空间的利用率。该机制在训练阶段作为附加优化目标,由权重因子平衡主要损失。具体而言,这里的多模态表示作为最终动作解码器的输入,通过提高此处的信息量,鼓励动作解码器生成更具多样性的轨迹,提高在连续动作空间采样可行动作的效果。在图2的子图(d)中,作者对表示矩阵的奇异值谱进行了可视化,可以看出优化后的多模态表示空间得到了进一步的利用。

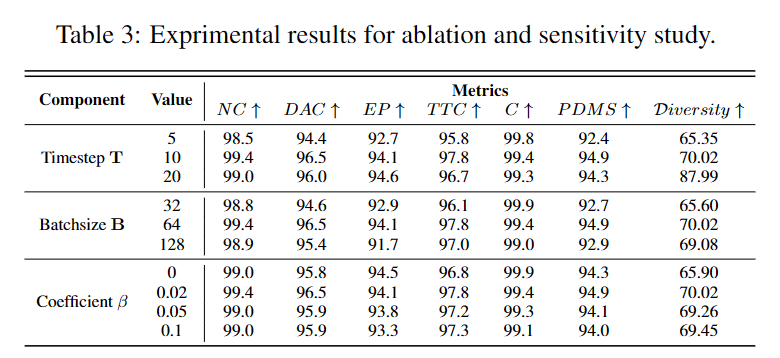
作者也给出了这一优化目标的计算伪代码,从实现上看,这一优化目标并不会带来过重的计算开销,但能够提升模型对于多模态表示空间的利用率,从表3的实验结果也能看出这一目标可进一步提高生成轨迹的多样性(Diversity从65.90提升到70.02)。

实验分析
数据集使用适用于闭环评估,基于非反应式仿真NAVSIM 数据集,包含相机图像、激光雷达数据、自身状态和地图及目标注释。作者使用了多个最新方案进行对比,并且包括匀速模型、Ego-status-MLP等用于评估下界的基线方案。实现是基于 PyTorch lightening 框架和 NAVSIM 官方工具包,作者冻结了用于编码图像和激光雷达的Transfuser模块,仅训练 120 个全局训练轮次,反映了这一模型的训练效率。评估指标则包括预测驾驶员模型分数(PDMS),另外包含DiffusionDrive这一工作提出的多样性指标(Diversity)。
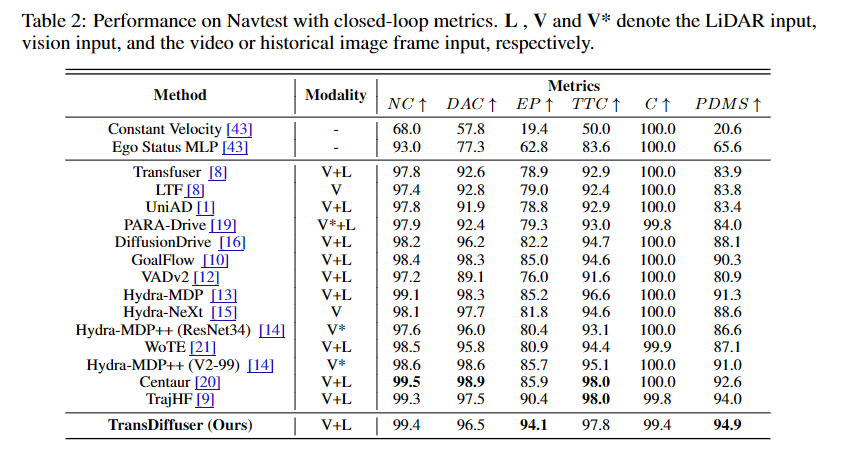
从NAVSIM的结果上看,作者所提模型的最大改进在于EP(Ego Progress)指标。同时,作者对Batchsize、权重因子和去噪步数进行了消融分析,并且汇报了不同参数配置下的多样性指标,从结果上看,即使降低去噪步数也能取得相对不错的性能,同时提高去噪步数,可在一定程度额外时间开销下,进一步显著提高多样性分数。
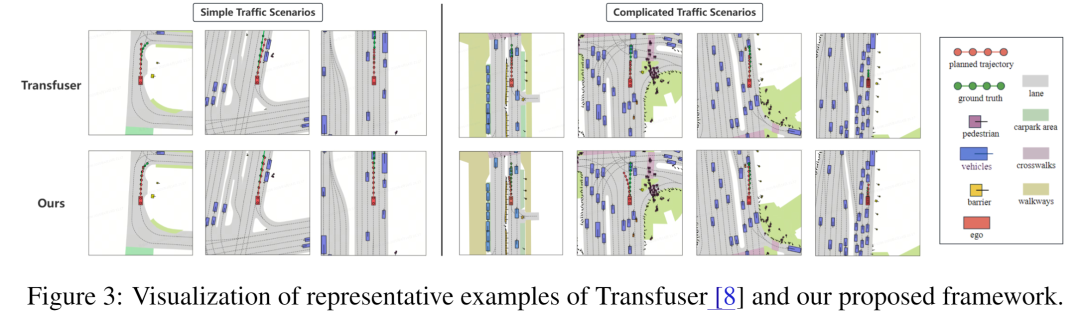
作者进行了可视化分析,显示了不同交通场景下和Transfuser模型的规划轨迹的区别。从可视化分析上可以看出,作者所提的模型在简单场景场景或复杂交通场景,可以在遵守安全的前提下提出相对更激进的规划轨迹。
结论
本文提出 TransDiffuser,一种基于”编码器-解码器“的端到端自动驾驶生成式轨迹模型,并且引入多模态表示去相关优化机制以鼓励从连续空间中采样更多样化的轨迹。这一模型在 NAVSIM 基准测试中证明了其优越性,未来工作可考虑结合强化学习技术和”视觉 -语言-行动“模型架构,以更好地与人类驾驶员指令或风格对齐生成多条规划轨迹。就技术局限性,作者声称在联合训练Transfuser的编码器存在一定挑战,需要进一步探索,并且作者鼓励未来工作考虑结合本文提出的多模态表示解相关的策略,来进一步提高其余模型与方法的性能的可能性。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 5266
5266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









