






点击下方卡片,关注“具身智能之心”公众号
作者 | Zechuan Li 编辑 | 具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
写在前面&出发点
三维场景问答(3D SQA)是一项跨学科任务,它融合了三维视觉感知和自然语言处理,使智能体能够理解并与复杂的三维环境进行交互。大型多模态建模领域的最新进展推动了多种数据集的创建,并促进了3D SQA指令调优和零样本方法的发展。然而,这一快速进展也带来了挑战,尤其是在实现跨数据集和基线模型的统一分析和比较方面。这里首次对3D SQA进行了全面综述,系统地回顾了数据集、方法和评估指标,同时强调了数据集标准化、多模态融合和任务设计方面的关键挑战和未来机遇。
内容出自国内首个具身智能全栈学习社区:具身智能之心知识星球,这里包含所有你想要的。
领域发展介绍
视觉问答(VQA)通过融入视觉内容,扩展了传统基于文本的问答系统范围,能够解释图像、图表和文档,以提供情境感知的回复。这一能力促进了更广泛的应用,包括医疗诊断、财务分析以及学术研究辅助。然而,随着对沉浸式三维环境需求的不断增长,对更加自然和交互式的问答系统的需求也日益迫切。三维场景问答(3D SQA)通过连接三维环境中的视觉感知、空间推理和语言理解,解决了这一问题,见图1。
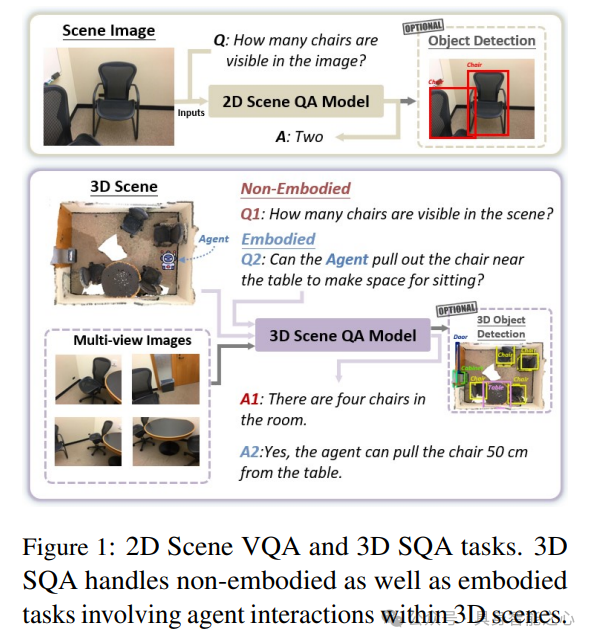
与传统侧重于物体检测或分割的三维任务不同,3D SQA整合了多模态数据,例如视觉输入和文本查询,使具身系统能够进行复杂推理。通过利用动态三维环境中的空间关系、物体交互和层次场景结构,3D SQA推动了机器人技术、增强现实和自主导航的发展,拓展了多模态人工智能的边界及其在复杂现实世界场景中的潜力。
3D SQA的早期发展依赖于手动标注的数据集,如ScanQA和SQA,这些数据集将三维点云与文本查询进行了对齐。最近,程序化生成方法,如3DVQA和MSQA中使用的方法,已能够创建具有更丰富问题类型的大型数据集。大型视觉-语言模型(LVLMs)的整合进一步自动化了数据标注,推动了更全面的数据集的开发,如LEO和Spartun3D。
随着数据集的发展,方法论也随之演进,从封闭集方法转变为低资源视觉语言模型(LVLM)支持的技术。早期方法采用了自定义架构,结合了点云编码器和文本编码器,以及基于注意力的融合模块。然而,这些方法受到预定义答案集的限制。最近的基于LVLM的方法在适应如GPT-4等模型时,采用了指令调优或零样本技术,从而减少了对特定任务标注的依赖。然而,这些方法在确保数据集质量和解决评估不一致性方面也面临着挑战。
为了分析三维场景问答(3D SQA)中出现的新挑战,并促进这些挑战的系统性处理,我们首次对这一研究方向进行了全面综述。重点关注了该领域的三个基本方面,即:(i)3D SQA的目标,(ii)支持这些目标所需的数据集,以及(iii)为实现这些目标而开发的模型。我们回顾了数据集和方法论的演变,突出了文献中的趋势,如从手动标注向LVLM辅助生成的转变,以及从封闭集方法向零样本方法的演进。此外还讨论了多模态对齐和评估标准化方面的挑战,为该领域的未来发展方向提供了见解。

预备知识
3D场景问答(3D SQA)任务涉及理解一个3D场景S和一个查询Q,以生成文本答案T,并可选地生成空间信息B,如相关物体的边界框。3D场景可以使用点云、多视图图像或其组合等方式来表示,而查询可能包括文本输入、以自车为中心的图像或物体级别的点云。该任务被正式定义为F:(S,Q) → (T,B),它融合了多模态推理和空间理解,以进行全面的3D场景分析。
Datasets
3D场景问答(3D SQA)中数据集的重要性再怎么强调也不为过。现有数据集在场景表示、规模和查询复杂性方面存在很大差异。为了系统地概述现有数据集,这里分为两个主要部分:数据集结构,探讨场景和查询的表示及规模;以及问答对创建,研究生成问答对的方法论。
1)数据结构
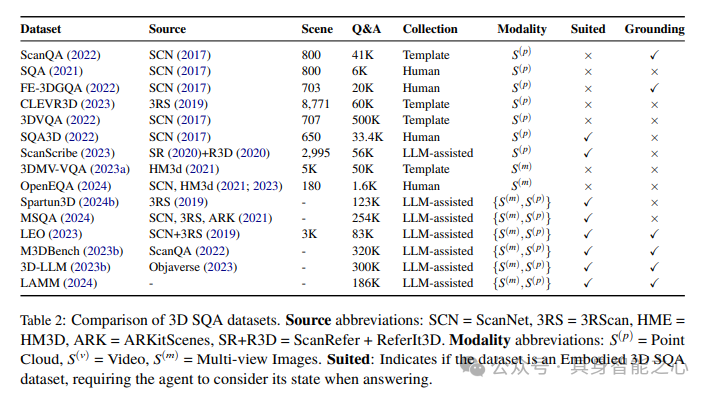
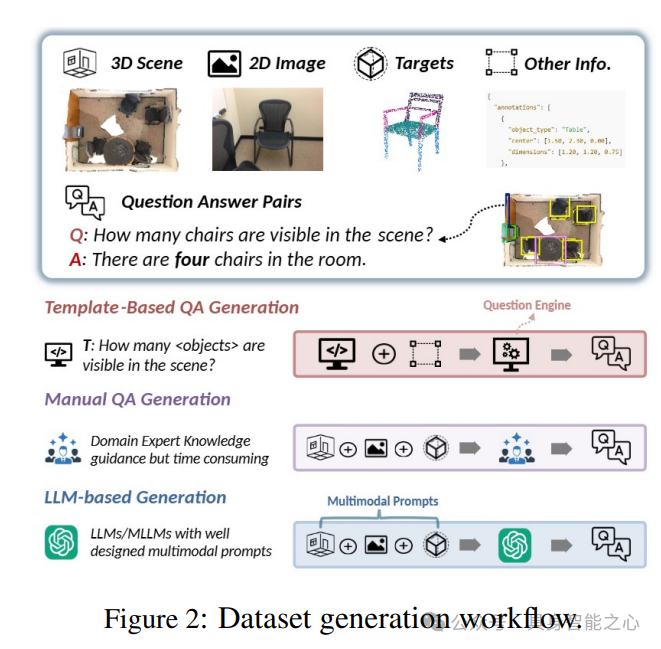
在3D场景问答(3D SQA)这一数据驱动领域,数据集的结构对其所支持的任务范围有着显著影响。当前的数据集在3D场景的表示上存在巨大差异,包括点云、多视图图像和以自我为中心的视角等,同时其查询格式也从基本的文本输入到复杂的多模态、具体化描述不等。数据集的关键属性,如规模、模态多样性以及查询复杂性,对3D SQA模型的设计要求和性能能力有着重要影响。表2总结了现有真实世界3D SQA数据集的关键特征,概述了它们的场景表示、查询模态和规模。在图2中,我们以更高级的抽象层次展示了典型的数据集生成工作流程。
场景模态与规模
3D场景问答(3D SQA)数据集的发展经历了从合成环境到真实3D表示的时间线演变。合成3D数据集:3D SQA的发展始于利用合成环境模拟场景级问答任务的伪3D数据集。例如,EmbodiedQA通过在House3D模拟器中选择SUNCG子集的真实场景来生成数据集。这些数据集经过人工标注者的验证以确保质量。IQA通过引入IQUAD V1数据集扩大了这一努力,该数据集包含75,000个问题,每个问题都与独特的场景配置相匹配,利用了AI2-THOR环境。MP3D-EQA和MT-EQA分别进一步纳入了深度图和多目标问答任务,但仍局限于合成SUNCG场景。
点云数据集:基于3D点云的数据集的引入标志着向现实世界3D场景问答(3D SQA)任务的转变。ScanQA和SQA为这一方向奠定了基准。这两个数据集都是使用ScanNet构建的,其中ScanQA在800个场景中生成了41,000个问答对,而SQA提供了6,000个经过人工精心挑选、语言准确性更高的问答对。在这些工作的基础上,FE-3DGQA从ScanNet中选择了703个特定场景并标注了20,000个问答对,强调带有密集边界框标注的基础问答任务,以实现空间定位。CLEVR3D利用功能程序和文本模板生成了ScanQA中问题数量四倍的问题,引入了更广泛的属性和问题类型。随后,3DVQA在CLEVR3D框架的基础上进行了扩展,利用3D语义场景图和基于模板的管道来生成问题和答案。通过选择707个场景,3DVQA生成了500,000个问答对,极大地丰富了任务的多样性和复杂性。同样地,SQA3D在650个场景中精心挑选并标注了33,400个问答对,专注于将查询与agent的位置和方向相关联。
多视图数据集:为了更好地与人类感知相契合,引入了多视图数据集,该数据集侧重于从不同视角进行推理,而不仅仅依赖于单一的点云表示。在这一方向上,3DMVVQA包含了来自HM3D数据集的5,000个场景,并生成了50,000个问答对。这些图像是使用Habitat框架渲染的,强调了多视图推理。另一方面,OpenEQA不仅从HM3D中选择了场景,还结合了Gibson和ScanNet数据集,最终选择了180个高质量场景,包含1,600个问答对。与其他数据集不同,它优先考虑质量而非规模,为高质量3D问答基准做出了重要贡献。
多模态数据集:近年来,3D场景问答(3D SQA)数据集的发展强调了点云、图像和文本数据的融合,以形成丰富的多模态表示。这些方法旨在捕捉空间、语义和上下文线索,以实现更全面的场景理解。一个值得注意的例子是Spartun3D,它从3RScan中选择了场景,并生成了123,000个专注于情境任务的问答对。同样,MSQA从多模态数据集中构建了254,000个问答对,使用点云和对象图像作为输入,以更好地与现实世界的具身智能场景相契合。
随着大型语言模型(LLMs)的普及,指令调优数据集也作为多模态数据集的一个重要扩展而出现,它通过将3D数据与文本描述相结合,增强了3D场景问答(3D SQA)模型的泛化能力。例如,ScanScribe收集了ScanNet和3R-Scan中的室内场景的RGB-D扫描数据,并整合了来自Objaverse的多样化物体实例。它使用了ScanQA中的问答对以及ScanRefer和ReferIt3D中的指代表达式,通过模板和GPT3从2,995个场景中生成了56,100个物体实例。同样地,LEO通过收集对象级、对象在场景中级和场景级的描述,构建了83,000个3D-文本对。
沿着相似的思路,M3DBench利用多个现有的大型语言模型生成了320,000个指令-响应对,为广泛的3D-语言任务丰富了多模态3D数据。3D-LLM使用Objaverse、ScanNet和HM3D等资源创建了超过300,000个3D-文本对,而LAMM则采用GPT-API和自我指令方法生成了186,000个语言-图像对和10,000个语言-3D对。
查询模态与复杂性
在3D场景问答(3D SQA)中,查询代表输入的问题或提示,当与3D场景配对时,它指导提供答案的任务。随着时间的推移,3D SQA中的查询模态已经从简单的基于文本的输入演变为更复杂、多模态和以agent为中心的格式。在此,我们从查询模态的角度对数据集进行总结,这是性能评估中数据集选择的关键考虑因素。
基本文本查询:早期的3D SQA数据集主要采用直接的基于文本的查询,这些查询侧重于场景级别的属性,如物体计数或识别。这些数据集旨在评估基础的3D场景理解能力,通常不考虑agent在环境中的位置、交互或视角。例如,ScanQA和SQA等数据集包含诸如“房间里有多少把椅子?”之类的问题。这些纯文本问题由于缺乏对agent与场景之间的空间或上下文关系的描述,无法捕捉复杂的具身场景。因此,这些数据集的范围有限,如表2所示,其中缺乏适合的查询表明它们省略了以agent为中心的上下文。这一局限性凸显了后来3D SQA研究向更丰富、更具上下文化的数据集发展的趋势。
以agent为中心的文本查询:引入以agent为中心的描述标志着查询复杂性的重大转变。SQA3D是最早纳入情境化问题的数据集之一,其中文本查询通过引用agent的位置或方向得到了增强。在这种情况下,一个典型的查询可能会描述agent的位置,如“坐在床边,面向沙发”。在表2中将能够执行此类查询的数据集标记为“适合”。
多模态以agent为中心的查询:最近,SPARTUN3D和MSQA引入了更丰富的空间描述和多模态查询输入。前者提供了详细的空间信息,使得可以执行如“你站在垃圾桶旁边,前面有一个厕所”之类的查询。同样,MSQA在查询中整合了文本描述、明确的空间坐标和agent方向。此外,还包括第一人称视角的图像。这些多模态方法通过结合空间、视觉和语言上下文,实现了更逼真的场景。
指令调优查询:最近的数据集,如ScanScribe、LEO和M3DBench,也进一步扩展了查询模态,以支持指令调优任务。它们利用以agent为中心的查询,并结合多模态输入,如基于空间位置的文本描述和多模态指令。例如,LEO纳入了多模态指令来微调模型,以执行如实时导航或物体交互等agent任务。M3DBench则通过利用丰富的多模态数据,专注于跨多种现实世界任务的泛化。这些指令调优数据集通过将文本指令与空间和视觉上下文相结合,确保模型能够很好地解决实际的现实世界任务。
2)问答对创建
问答对(QA对)的创建定义了3D场景问答(3D SQA)任务的范围和复杂性。早期数据集依赖于人工标注,而最近的研究工作则采用了模板和大型视觉语言模型(LVLMs)来提高可扩展性和多样性。这些进展使得数据集能够包含更广泛的问题类型,从物体识别到空间关系到任务特定查询。
问答对生成方法
在3D场景问答(3D SQA)数据集中,问答对(QA对)的生成需要在人工标注、基于模板的流程和大型语言模型(LLM)辅助方法之间取得平衡。人工标注确保了高质量和上下文准确性,而基于模板的方法则能够实现具有逻辑一致性的可扩展生成。最近,大型语言模型进一步自动化了这一过程,使得能够大规模生成多样化的多模态QA对。这一进展在图2中也显而易见,反映了数据集创建技术的演变。
基于模板的生成:基于模板的生成方法是早期为实现可扩展问答对(QA对)创建而引入的一种解决方案。ScanQA通过利用基于T5的QA生成模型从ScanRefer中生成种子问题,展示了这种方法。同样,CLEVR3D、3DVQA和3DMV-VQA等数据集利用3D语义场景图以编程方式生成多样且逻辑一致的问答对,从而提高了可扩展性和任务多样性。虽然基于模板的方法能够生成大规模数据集,但生成的问题往往缺乏上下文特异性,有时可能导致过于泛化的查询。
手动标注:研究人员还采用了手动标注的方法来解决基于模板方法的局限性。手动方法注重语言精确度和上下文相关性,创建的数据集规模较小但质量更高。例如,SQA精心挑选了6000个问答对,重点强调语言准确性;而FE-3DGQA则从ScanNet中选取了703个场景并标注了20000个问答对,同时通过边界框标注来确定答案。同样,OpenEQA从180个高质量场景中精选了1600个问答对。SQA3D在650个场景中贡献了33400个问答对,专门针对以agent为中心的任务。尽管手动标注耗时较长,但经过精心策划的数据集在确保准确性和上下文一致性方面发挥着关键作用,是对基于模板方法的补充。
大型语言模型辅助生成:最近的方法越来越多地利用大型语言模型(LLMs)来自动化生成问答对,从而提高了可扩展性和多样性。值得注意的例子包括Spartun3D和MSQA,它们都利用场景图来结构化空间和语义关系。Spartun3D采用GPT-3.5生成以agent为中心的问题,强调情境推理和探索,最终生成了123000个问答对。MSQA则采用类似的方法,使用GPT-4V,侧重于由语义场景图指导的情境问答生成,产生了254000个问答对。
此外,大型语言模型(LLMs)在构建指令调优数据集方面发挥了关键作用,这些数据集有助于提高模型在多种多模态任务上的泛化能力。ScanScribe利用GPT-3将ScanRefer的标注通过基于模板的细化转化为场景描述。LEO采用GPT-4并结合以对象为中心的思维链(O-CoT)提示,以确保逻辑一致性。M3DBench和3D-LLM则使用GPT-4根据对象属性和场景级输入创建多模态提示。这些数据集共同展示了大型语言模型在自动化生成高质量、多模态3D场景问答(3D SQA)数据方面日益增长的作用。
3D场景问答中的问题设计
随着语言和视觉建模的发展,3D场景问答(3D SQA)中的问题已经从多个维度上得到了演变:从简单任务到复杂任务,从非情境化语境到情境化语境,以及从静态场景到动态场景。为了举例说明这些问题的性质,我们在附录中的表A中列出了常见的3D SQA任务和代表性问题。
任务复杂性—从基础到高级:
3D SQA涵盖了多种问题任务,旨在评估模型对3D环境的理解能力和推理能力。基础任务,如对象识别、空间推理、属性查询、对象计数和属性比较,在诸如SQA、ScanQA、FE-3DGQA、3DVQA和CLEVR3D等数据集中都有体现。其中,FE-3DGQA引入了更复杂、更自由形式的问题,这些问题要求模型不仅要定位与答案相关的对象,还要识别它们之间的上下文关系。同样,CLEVR3D通过纳入整合了对象、属性及其相互关系的问题,强调了关系推理,从而进一步推动模型处理复杂的上下文依赖关系。
随着3D场景问答(3D SQA)的发展,出现了要求更深入理解空间和视觉上下文的任务,这些任务挑战模型进行动态和情境感知推理。这些任务包括多跳推理(如SQA3D)、导航(如SQA3D、LEO、3D-LLM、M3DBench、MSQA)、机器人操作(如LEO)、对象功能(如Spartun3D)、功能推理(如OpenEQA)、多轮对话(如LEO、M3DBench、3D-LLM)、规划(如LEO、M3DBench、Spartun3D)和任务分解(如3D-LLM)。这些高级任务挑战模型在捕捉复杂空间和关系细节的同时,动态推理并导航复杂的3D环境。值得注意的是,OpenEQA作为首个用于具身问答的开放词汇数据集而脱颖而出。
情境化与非情境化问题:根据所需的交互水平和情境理解程度,3D视觉问答(VQA)问题可分为情境化和非情境化类型。后者侧重于静态推理,测试模型在固定3D场景中解释空间关系、属性和对象属性的能力。像SQA、ScanQA、FE-3DGQA、3DVQA、CLEVR3D和LAMM这样的数据集主要包含评估静态空间上下文中理解能力的非情境化问题。相反,情境化问题涉及动态推理,需要与3D环境进行交互并理解上下文或顺序信息。这些问题测试模型导航、规划和适应动态场景的能力,并且通常包含时间或具身元素。情境化问题出现在如SQA3D、LEO、3D-LLM、M3DBench、MSQA、Spartun3D、3DMVVQA和OpenEQA等数据集中。这种分类有助于对3D VQA系统进行全面评估。
3)评估LLM生成的3D数据集
尽管大型语言模型(LLM)的应用极大地推动了3D场景问答(3D SQA)数据集的发展,但确保其质量、可靠性和实用性仍然是一个亟待解决的挑战。当前的评估方法主要依赖于人工评估。例如,LEO通过专家评审来评估问答对,报告了包括整体准确率和上下文相关性等指标。MSQA采用比较方法,从其数据集中抽样问答对,并与基准数据集(如SQA3D)进行对比,根据上下文准确性、事实正确性和整体质量进行评分。同样,Spartun3D通过随机抽样实例进行专家验证,以确保生成的数据符合预期的质量标准。这些人工评估为数据集质量提供了有价值的见解,但在可扩展性、劳动强度和主观性方面存在局限。
为了解决这些局限,目前需要自动化评估框架。潜在的解决方案包括用于语义对齐的嵌入式指标、用于问答连贯性的逻辑一致性检查,以及用于空间准确性和多模态集成的特定任务指标。
评估指标
标准化的评估指标对于衡量3D场景问答(3D SQA)的进步和确保数据集适用于下游任务至关重要。当前的3D SQA文献在评估时要么使用传统指标,要么使用基于大型语言模型(LLM)的指标。
传统指标:3D SQA方法通常采用语言相关性和正确性的定量指标进行评估。常用的指标包括精确匹配(Exact Match,如EM@1、EM@10),它评估生成的答案是否与真实答案完全匹配,以及语言生成指标,如BLEU、ROUGE-L、METEOR、CIDEr和SPICE。这些指标最初由ScanQA采用,并自此被用于CLEVR3D、3DGQA和ScanScribe等数据集。虽然这些传统指标在评估语言准确性和多样性方面很有效,但它们在捕捉3D SQA任务所需的细致推理和上下文理解方面通常存在局限性。
基于LLM的指标:3D场景问答(3D SQA)中新兴的评价范式采用基于LLM(大型语言模型)的指标,利用如GPT等模型的推理能力。例如,OpenEQA利用GPT来评估生成答案的上下文相关性和正确性,并引入了一个最终计算平均相关性分数的指标。同样,MSQA也使用GPT来基于细致推理评估答案的质量,使其与上下文期望保持一致。与传统指标相比,基于LLM的方法在模拟现实世界推理和捕捉语义微妙之处方面目前表现优异,对于评估复杂的多模态任务特别有价值。
综上所述,传统指标为评估语言和结构质量提供了坚实的基础,而基于LLM的指标则提供了对上下文对齐和推理的更深入见解。结合这些指标的互补特性,可以为评估3D SQA性能提供一个全面的框架。
3D场景问答(3D SQA)方法的分类
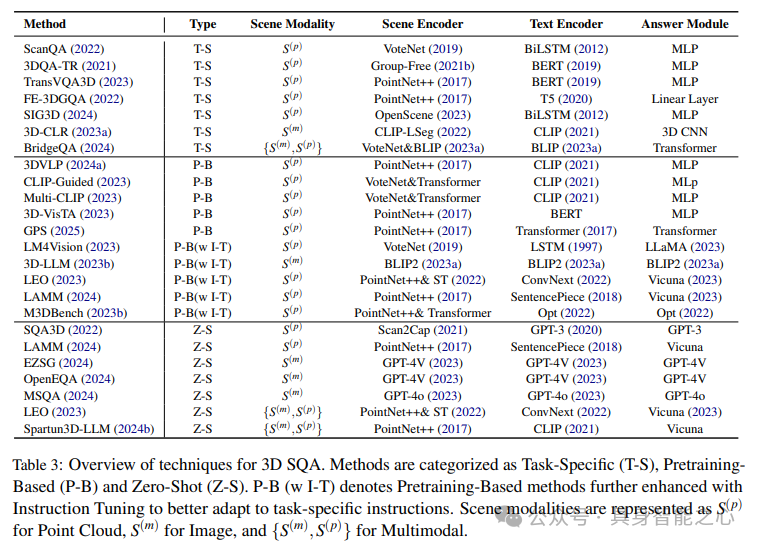
3D场景问答(3D SQA)方法可以分为三类,如表3所示。i) 任务特定方法依赖于预定义的答案和专门设计的架构来解决特定任务。ii) 基于预训练的方法利用大规模数据集来对齐多模态表示,并针对特定任务目标进行微调。iii) 零样本学习方法同样利用预训练的大型语言模型(LLM)和视觉语言模型(VLM)来泛化到新任务,尽管没有额外的微调。这些类别支撑了3D SQA领域从任务特定方法向可扩展方法的演进,这些方法利用了先进多模态模型的能力,反映了3D SQA系统对灵活性和适应性的日益重视。
1)Task-Specific Methods
这些方法采用封闭集分类方法为特定任务而设计。
点云方法:针对点云的3D场景问答(3D SQA)方法遵循一个模块化的流程,包括场景和查询编码、特征融合以及答案预测。早期的方法,如ScanQA,采用VoteNet和PointNet++来提取空间特征,而文本查询则使用GloVe和BiLSTM进行编码。融合则是通过基于Transformer的模块实现的。在此基础上,后来的方法引入了更复杂的编码器和融合策略。例如,3DQA-TR用Group-Free替换了VoteNet以实现更细粒度的场景编码,并采用BERT进行查询编码。融合过程通过直接通过文本到3D的Transformer整合特征来进一步简化,从而实现更直接的问题到答案的映射。同样,TransVQA3D通过引入用于融合的SGAA来增强特征交互,重点关注场景中的全局和局部语义。对于需要空间定位的数据集,FE3DGQA通过使用PointNet++进行空间特征提取和使用T5进行文本编码来改进流程,同时辅以注意力机制来使文本与密集空间注释对齐。最近提出的SIG3D专注于具身智能中的上下文感知任务。它使用基于体素的标记化对场景进行编码,并采用基于锚点的上下文估计来确定agent的位置和方向。
多视图和2D-3D方法:还有一些方法使用多视图图像来增强3D场景问答(3D SQA)的性能。例如,3D-CLR通过利用多视图图像并优化3D体素网格来构建紧凑的3D场景表示。另一方面,像BridgeQA这样的2D-3D方法结合了来自预训练视觉语言模型(VLMs)的2D图像特征与通过VoteNet获得的3D对象级特征。这两种特征类型都与VLM的文本编码器编码的文本特征对齐,并通过视觉语言Transformer进行融合,从而实现自由形式的答案。
2)基于预训练的方法
3D场景问答(3D SQA)中的基于预训练的方法已经从强调空间嵌入和文本嵌入显式对齐的传统方法,转变为利用大型预训练模型的指令调优范式。这些方法在任务特定适应性和泛化能力之间取得了平衡,以应对可扩展性的挑战。
传统预训练方法:这些方法侧重于将3D空间特征与丰富的2D视觉和语言表示对齐。Parelli等人利用基于VoteNet的可训练3D场景编码器提取对象级特征,并使用Transformer层进一步细化这些特征,以建模对象间的关系。Multi-CLIP引入了多视图渲染和鲁棒的对比学习,以增强3D空间特征与2D表示的结合。Zhang等人在预训练期间引入了对象级交叉对比学习和自对比学习任务,以提高跨模态对齐。Jia等人采用分层对比对齐策略,结合对象级、场景级和指代嵌入,以增强跨模态和模态内特征的融合。
与这些对比学习方法不同,3D-VisTA采用基于Transformer的统一框架来对齐3D场景特征与文本表示。它不依赖于大量的标注,而是利用自监督目标来优化多模态对齐。从任务特定的预训练转向自监督学习,是高效且稳健的3D SQA的一个值得注意的发展。
指令调优方法:预训练的基础模型以高昂的计算成本从大规模无监督数据中学习通用的几何和语义表示。指令调优方法通过利用预训练的大型语言模型(LLMs)或视觉语言模型(VLMs)作为冻结的编码器,来利用这些模型的泛化能力。这些方法保留了编码器的参数,仅进行最小程度的修改,通常是通过轻量级的任务特定层,以适应下游任务。最近的方法,如LM4Vision、3D-LLM、LEO、M3DBench和LAMM,都体现了这一转变。
LM4Vision采用冻结的LLaMA编码器,并训练轻量级的任务特定层,以与3D问答任务对齐。同样,3D-LLM在BLIP2的基础上构建,同时添加了一个任务特定的头,而保持基础模型冻结。相比之下,LEO、M3DBench和LAMM利用LLaMA的衍生模型Vicuna来整合文本和多模态输入。LEO结合了以对象为中心和场景级别的字幕,以增强多模态推理。通过利用LLMs或VLMs中编码的广泛知识,这些方法避免了需要大量任务特定预训练数据集的需求。此外,指令调优方法在零样本和少样本场景下也有效。
3)零样本学习方法
零样本学习已成为3D场景问答(3D SQA)领域一种有前景的学习范式,它使模型能够在不进行任务特定微调的情况下推断出未见任务的答案。当前的零样本3D SQA方法大致可分为:文本驱动方法、图像驱动方法和多模态对齐方法。
文本驱动方法:这些方法将3D场景信息转换为文本描述,然后将其与问题一起用于预训练的大型语言模型(LLMs)或视觉语言模型(VLMs)中进行零样本推理。例如,SQA3D使用Scan2Cap生成场景描述,并将其输入GPT-3以回答问题。然而,这种方法忽略了点云和图像的空间结构,限制了其充分利用3D信息的能力。同样,LAMM从点云和文本中提取特征,但对3D数据的使用方式有限。
图像驱动方法:这些方法使用VLMs结合图像或多视图数据等视觉特征以及文本。例如,MSQA使用GPT-4o与VLMs。Singh等人在3D-VQA和ScanQA等数据集上测试了未经微调的GPT-4V,在某些任务中表现出了具有竞争力的性能。这些方法灵活且资源高效,但它们仍然依赖于文本来表示空间和对象关系,这可能是一个潜在的局限性。
多模态对齐方法:诸如LEO和Spartun3D-LLM等技术,在预训练过程中明确地对齐视觉和文本信息。LEO通过对齐对象和场景级别的特征来提高零样本性能,而Spartun3D-LLM则使用一个明确的模块来对齐点云和文本。由于需要额外的计算,这些方法需要相对更多的训练资源。然而,它们在性能和效率之间提供了一个有吸引力的权衡。总体而言,在当代零样本3D场景问答(3D SQA)中,文本驱动方法成本效益高且灵活,但对3D数据的利用有限。图像驱动方法直接利用视觉语言模型(VLMs)进行推理,但由于对3D信息的利用不足,也面临局限性。多模态对齐方法虽然性能优越,但资源需求更高。
挑战与未来方向
尽管3D场景问答(3D SQA)已经取得了显著进展,但仍存在若干关键挑战,限制了其在现实世界应用中的潜力。我们概述了主要挑战,并提出了未来研究的方向。
数据集质量与标准化。近年来,3D SQA数据集发展迅速,导致数据集领域分散,范围和模态差异巨大。将这些数据集整合为统一的基准测试集,可以为该领域的研究提供急需的标准化评估,从而推动研究的发展。此外,虽然大型语言模型(LLMs)促进了可扩展的数据集生成,但它们往往会引入虚假信息和上下文不一致。未来的研究应聚焦于稳健的验证框架,利用人类参与的系统或LLMs作为验证器。
增强零样本中的3D感知。当前的零样本模型严重依赖于文本agent,对3D空间和几何特征的利用有限。尽管多视图方法在一定程度上缓解了这一问题,但缺乏明确的3D表示阻碍了它们在空间复杂任务中的有效性。指令调整方法也面临类似的限制。未来的工作需要探索能够深度整合3D特征、语言模态和视觉模态的架构,以增强在不同任务上的泛化能力。此外,未来研究的一个明显方向是探索在零样本3D SQA中多模态对齐与预训练模型之间的平衡,以提高效率和性能。
统一评估。目前,缺乏标准化和针对3D场景问答(3D SQA)目标的特定评估指标,这使得跨数据集和模型的有意义评估和比较变得复杂。为了进行准确的基准测试和推动3D SQA的方法创新,目前需要开发统一的框架,这些框架应包含用于空间推理、上下文准确性和任务特定性能的多模态指标。
动态和开放世界场景。大多数现有的方法和数据集都集中在静态、预定义的环境上,这限制了它们在现实世界任务中的应用。未来的工作应更多地关注动态、开放世界的设置,使模型能够处理实时场景变化和新颖查询。将实体交互(如导航和多步推理)纳入其中,将进一步使3D SQA系统符合现实世界的要求。
可解释和可阐释的3D SQA模型。当前的3D SQA模型通常充当“黑箱”,这限制了它们在医疗等信任关键领域的采用。开发能够可视化3D特征、突出相关区域或提供自然语言解释的可解释模型,可以增强用户信任并拓宽其应用范围。
多模态交互与协作。3D SQA系统正朝着更自然和交互式的界面发展。未来的研究可以探索整合语言、手势和视觉输入,以实现与3D场景的直观交互。此外,多个用户实时与系统交互的协作场景(如建筑设计或教育培训)提供了一个有前景的方向。这样的系统可以增强沟通和联合解决问题的能力,为3D SQA解锁更广泛的应用。
融入时间动态。大多数当前的3D SQA模型忽略了场景的时间动态,而大多数现实世界应用(如交通监控、机器人导航)都涉及动态环境。未来的研究应旨在将时间动态融入3D SQA,使模型能够随时间推理场景变化。利用时间信息(如物体移动)将使这些系统能够更好地处理需要长期时间推理的任务。
模型效率与部署。将3D场景问答(3D SQA)系统部署到资源受限的设备上(如移动机器人和边缘人工智能agent)仍然具有挑战性,因为这些系统对计算和内存的需求很高。未来的工作应聚焦于轻量级架构和优化技术,包括剪枝、量化和知识蒸馏,以实现高效且实时的推理。针对嵌入式系统量身定制的节能算法和可扩展设计将进一步提升3D SQA在现实世界应用中的实用性。通过解决这些挑战,3D SQA可以朝着构建健壮、可扩展和多功能系统的方向迈进,推动实体智能和多模态推理领域取得重大进展。
参考
[1] Embodied Intelligence for 3D Understanding: A Survey on 3D Scene Question Answering

【具身智能之心】技术交流群
具身智能之心是国内首个面向具身智能领域的开发者社区,聚焦大模型、视觉语言导航、VLA、机械臂抓取、双足机器人、四足机器人、感知融合、强化学习、模仿学习、规控与端到端、机器人仿真、产品开发、自动标注等多个方向,目前近60+技术交流群,欢迎加入!扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

【具身智能之心】知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1000人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、大模型、视觉语言模型、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近40+开源项目、近60+具身智能相关数据集、行业主流具身仿真平台、强化学习全栈学习路线、具身智能感知学习路线、具身智能交互学习路线、视觉语言导航学习路线、触觉感知学习路线、多模态大模型学理解学习路线、多模态大模型学生成学习路线、大模型与机器人应用、机械臂抓取位姿估计学习路线、机械臂的策略学习路线、双足与四足机器人开源方案、具身智能与大模型部署等方向,涉及当前具身所有主流方向。
扫码加入星球,享受以下专有服务:
1. 第一时间掌握具身智能相关的学术进展、工业落地应用;
2. 和行业大佬一起交流工作与求职相关的问题;
3. 优良的学习交流环境,能结识更多同行业的伙伴;
4. 具身智能相关工作岗位推荐,第一时间对接企业;
5. 行业机会挖掘,投资与项目对接;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









