






作者 | Xiaoshuai Hao 编辑 | 深蓝AI
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『BEV感知』技术交流群
本文只做学术分享,如有侵权,联系删文
自动驾驶系统包括感知、预测、决策、规划等不同的功能模块。对于其中的自动驾驶规划模块而言,要想实现准确安全的路径规划,就需要利用自动驾驶车辆上配置的传感器采集周围的环境信息构建地图。
本文介绍了MapFusion:一种用于多模态地图构建的新型BEV特征融合网络。
©️【深蓝AI】编译
论文标题:MapFusion: A Novel BEV Feature Fusion Network for Multi-modal Map Construction
论文作者:Xiaoshuai Hao, Yunfeng Diao, Mengchuan Wei, Yifan Yang, Peng Hao, Rong Yin, Hui Zhang, Weiming Li, Shu Zhao, Yu Liu
论文地址:https://arxiv.org/abs/2502.04377

▲图1| 自动驾驶系统中地图构建任务示意图©️【深蓝AI】编译
图1展示了高精地图(HD Map)与地图分割(Map Segmentation)两类地图构建任务示意图。
现有的地图构建算法根据所使用的传感器数据进行划分,大体可以分成三种。分别是基于纯视觉的、基于纯激光雷达的以及基于相机和激光雷达融合的。在这三类方法当中,由于多模态融合算法可以充分利用不同模态数据之间的信息互补优势,其性能明显高于其他两类单模态的地图构建算法。
近年来,学术界已经提出了不少采用多模态的地图构建算法,比如,X-Align采用基于元素相加的方式进行多模态BEV特征的融合过程;BEVFusion采用两种模态加权平均的BEV特征融合方式;HDMapNet采用两种不同模态通道拼接的方式完成BEV特征的融合。尽管上述融合方式取得了不错的性能,但是这些方法通常忽略了不同模态特征之间的交互过程,影响了最终的地图构建效果。
在本文中,提出了跨模态交互变换器(CIT)模块,通过采用自注意力的方式实现了两种模态BEV特征之间的更加有效交互。同时,文中还进一步提出了双向动态融合(DDF)模块实现自适应的从不同模态之间选择有价值的信息构建最终的BEV融合特征。
本文的主要贡献总结如下:
提出了一种名为MapFusion的多模态地图构建算法,实现对于不同模态之间的更加高效的交互和集成,提高最终的高精地图和地图分割任务的效果。
为了解决视觉和点云模态语义特征不对齐问题,设计了名为跨模态交互变换器模块,通过自注意力的方式实现两类模态特征的有效交互。
为了更好的解决两类模态的特征融合问题,提出了名为双向动态融合模块,自适应的从两类特征中选择有价值的信息完成融合特征的构建。
大量实验表明,提出的MapFusion算法模型高于nuScenes数据集中高精地图和BEV地图分割任务的SOTA算法3.6%和6.2%。

MapFusion算法模型的网络结构如图2所示。具体而言,给定传感器采集的环视图像和点云数据,分别利用2D编码器和3D编码器完成各自模态的特征提取和BEV特征构建;然后将两个模态的BEV特征喂入提出的跨模态交互变换器中实现两类特征的交互,接下来利用双向动态融合模块实现两类特征的融合,最后接Map Decoder输出地图的构建结果。
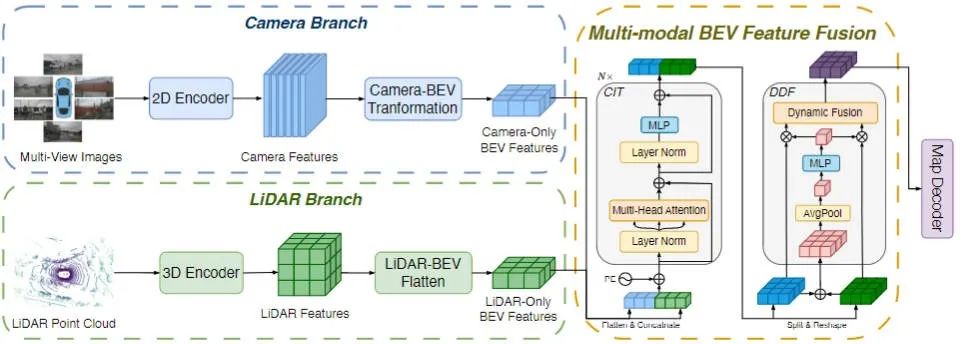
▲图2| MapFusion算法模型的整体框架图©️【深蓝AI】编译
■ 1.1. 跨模态交互变换器(CIT)
在上文中提到,由于不同模态之间存在语义不对齐问题,本文采用了跨模态交互变换器来缓解这一问题的发生。具体而言,CIT模块的整体流程可以总结为以下几步。
1.将相机分支和雷达分支输出的BEV特征进行展平,并按照矩阵的顺序进行排列,从而得到和。
2.为了能够让不同模态的token在训练的过程中进行区分,本文添加了PE位置编码。
3.由于跨模态交互变换器采用了Transformer中自注意力的思想,所以将添加了位置编码后的多模态数据利用线性层进行转换,得到矩阵。
4.按照Transformer中自注意力的计算公式,计算 之间的相似性矩阵,最终与 进行加权;同时为了获得来自不同位置的子空间的多种复杂注意力关系,本文也采用了多头注意力的计算方式完成自注意力部分的计算。
5.最后对上一步得到的多头注意力输出结果采用非线性变换的方式得到输出特征 。这一步得到的输出特征会被转换为和用于后续的特征融合。
■ 1.2. 双向动态融合模块(DDF)
本文提出了双向动态融合模块实现多模态特征的融合。与其他主流的特征融合方法相比,提出的双向动态融合模块可以自适应的从两种不同的模态中选取有价值的特征信息来完成最终多模态融合特征的构建。提出的方法与其他主流融合方法的对比如图3所示。
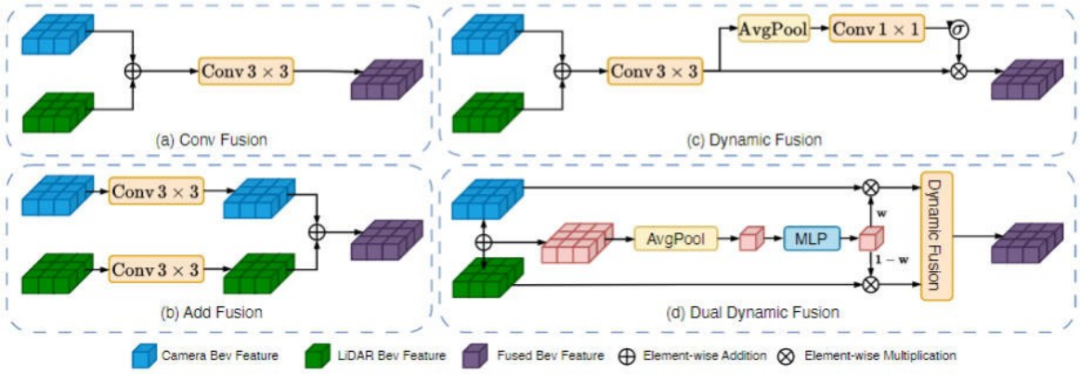
▲图3| 不同特征融合方案与本文提出的双向动态特征融合模块区别示意图©️【深蓝AI】编译
具体而言,本文提出的双向动态融合模块的输入是视觉和激光雷达的多模态特征。为了生成有意义的融合权重,本文将两类模态的特征进行加和并实现空间特征的聚合,从而得到相应的加权系数。其中代表sigmoid激活函数,代表线性层。
为了实现自适应的模态加权过程,从不同模态特征中选择有价值的信息,本文将公式(4)中的得到的权重与两类模态进行加权,并将二者加权后的特征进行通道维度的拼接,然后采用卷积实现降维减少计算量。
最终融合后的特征将会输入到模块中完成地图的构建任务

本文研究在nuScenes和Argoverse2两类自动驾驶数据集上进行了实验分析。在高精地图构建任务中,整体的实验设置遵循MapTR模型的配置方案。在地图分割任务中,整体实验设置遵循BEVFusion的配置方案。
图4和图5分别展示了MapFusion在nuScenes和Argoverse2数据集上高精地图构建任务与其他算法模型的比较结果。通过结果可以看出,MapFusion算法模型在两个数据集上均实现了最佳的结果。
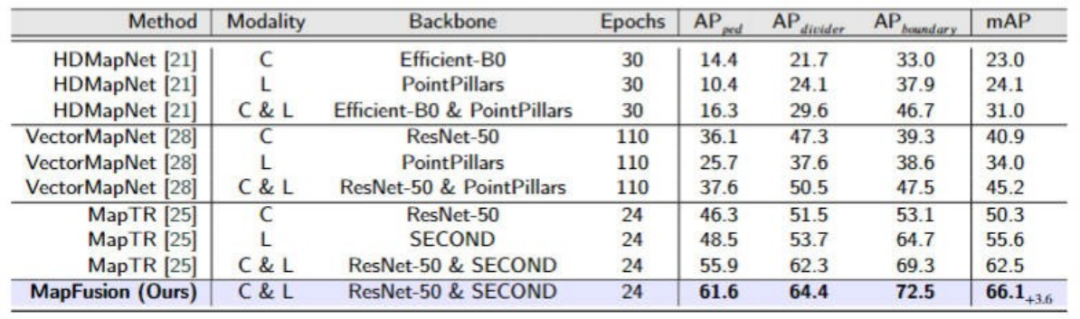
▲图4| 不同算法模型高精地图构建任务在nuScenes数据集上的对比©️【深蓝AI】编译

▲图5| 不同算法模型高精地图构建任务在Argoverse2数据集上的对比©️【深蓝AI】编译
图6和图7展示了MapFusion在nuScenes和Argoverse2数据集上地图构建任务与其他算法模型的比较结果。通过结果可以看出,无论是哪类数据集,MapFusion均展现出了最佳的性能指标。
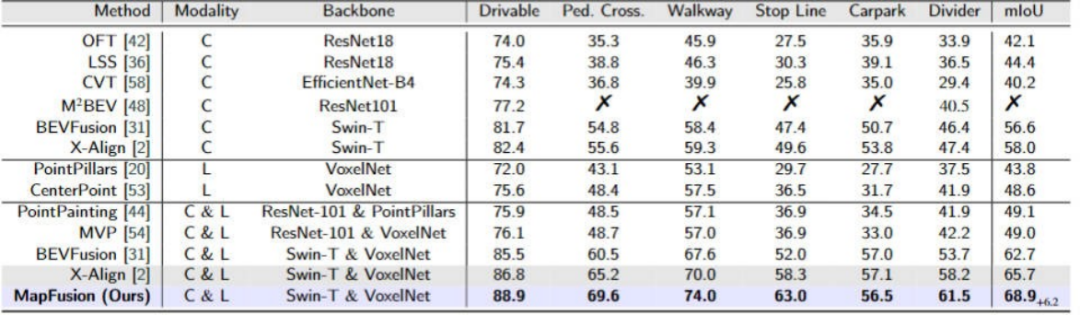
▲图6| 不同算法模型地图分割任务在nuScenes数据集上的对比©️【深蓝AI】编译

▲图7| 不同算法模型地图分割任务在Argoverse2数据集上的对比©️【深蓝AI】编译
论文中还通过消融实验来评估提出的跨模态交互变换器和双向动态融合模块的有效性,通过图8的实验结果证明了两类模块都可以提升模型的最终表现性能。

▲图8| DDF和CIT模块的消融对比实验©️【深蓝AI】编译
此外,论文为了更加直观的展示所提出的两个创新点对于高精地图构建和地图分割任务的贡献,对相关任务的结果进行了可视化分析,如图9和图10所示,进一步证明了DDF和CIT模块的性能。
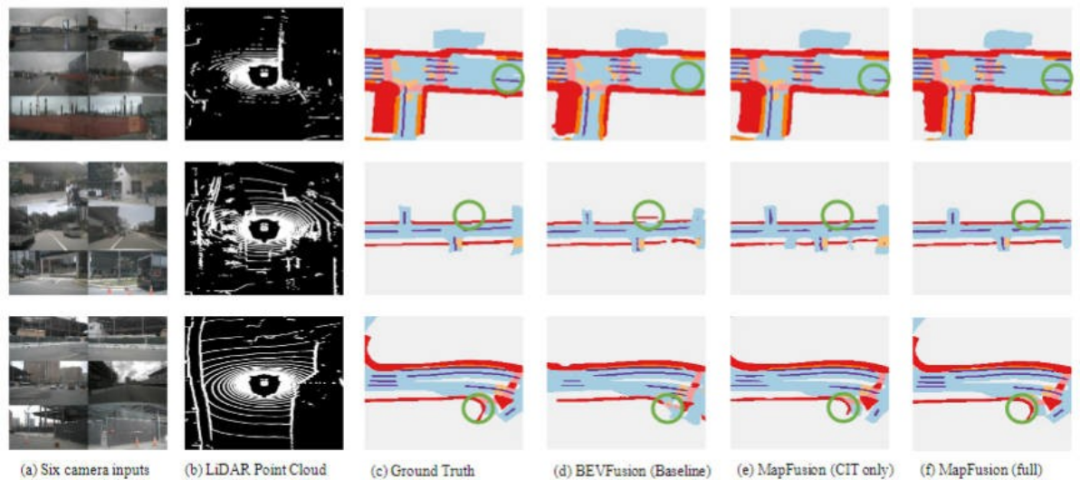
▲图9| DDF和CIT模块在地图分割任务上的效果可视化图©️【深蓝AI】编译
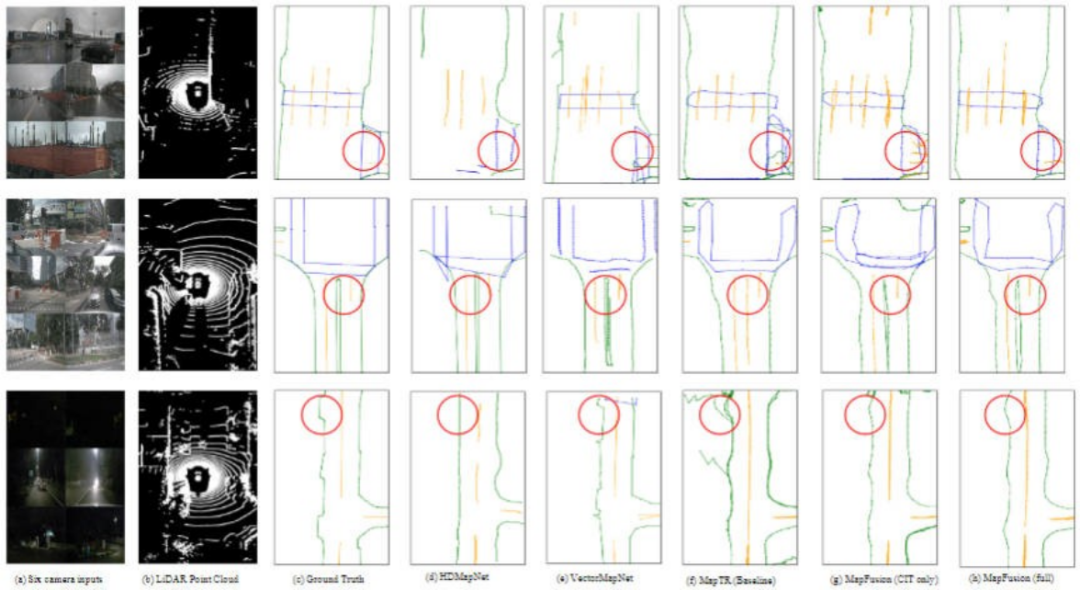
▲图10| DDF和CIT模块在高精地图构建任务上的效果可视化图©️【深蓝AI】编译

本文主要聚焦于相机-激光雷达多模态的地图构建任务,提出了一种新颖的多模态地图构建算法 MapFusion。为了缓解两类不同模态特征之间的语义不对齐问题,提出了跨模态交互变换器模块,通过自注意力的方式达到有效交互的目的。
此外,本文还提出了双向动态融合模块实现自适应的选择不同模态特征的有效信息,构建更加精准的多模态融合特征。在nuScenes和Argoverse2数据集上的大量实验表明,提出的MapFusion在高精地图构建和地图分割任务上均实现了最佳的表现性能。
Ref:
MapFusion: A Novel BEV Feature Fusion Network for Multi-modal Map Construction
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









