






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
arXiv论文“CoBEVT: Cooperative Bird’s Eye View Semantic Segmentation with Sparse Transformers“,22年7月上传,几个美国大学工作。

BEV地图理解方面大多基于基于智体的摄像机系统,难以处理复杂交通场景中的遮挡和检测远处的目标。车对车(V2V)通信技术使自主车辆能够共享传感信息,与单智体系统相比,这可以显著提高感知性能和范围。本文CoBEVT,是多智体多摄像机感知框架,可以协同生成BEV地图预测。为了在底层Transformer架构中有效地融合来自多视图和多智体数据的摄像机特征,设计了一个融合轴向注意力(fused axial attention,FAX)模块,该模块可以捕捉跨视图和智体的稀疏局部和全局空间交互。在V2V感知数据集OPV2V上的大量实验表明,CoBEVT在协作BEV语义分割方面达到了最先进的性能。
如图是CoBEVT的框架图:用于BEV特征计算的SinBEVT、特征压缩和共享和用于多智体BEV融合的FuseBEVT。

这里提出一种新的3D注意机制,称为FAX,作为SinBEVT和FuseBEVT的核心组件,可以有效地在局部和全局的智体或摄像机视图中聚合特征。这种FAX注意具有很大的通用性,在多个感知任务的不同模式下表现出有效性,包括基于多视图摄像机的协作/单智体BEV分割和协作3D激光雷达目标检测。
融合来自多智体的BEV特征需要局部和全局交互以及所有智体的空间位置。一方面,相邻AV在同一目标上通常具有不同的遮挡级别,因此更关心细节的局部注意可以帮助在该目标上构建像素到像素的对应关系。
如图(a)场景为例,自车应聚合来自附近AVs每个位置的所有BEV特征,以获得可靠的估计。另一方面,长期的全局上下文感知也有助于理解道路拓扑语义或交通状态——车辆前方的道路拓扑和交通密度通常与车辆后方高度相关。这种全局推理也有利于多摄像机视图的理解。图(b)中将同一辆车拆分为多个视图,全局注意能够很好地将其连接起来进行语义推理。
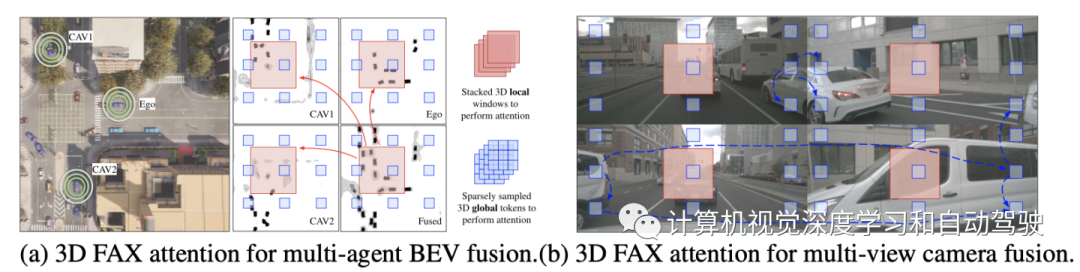
采用类似于CVT(Cross-view transformers)的BEV处理架构,其中可学习的BEV嵌入初始化为query,与编码的多视图摄像机特征交互,如图(a)所示。将这种3D局部和全局注意与Transformer的典型设计相结合,包括LayerNorm、MLP和跳连接,形成了FAX注意模块,如图(b)所示。
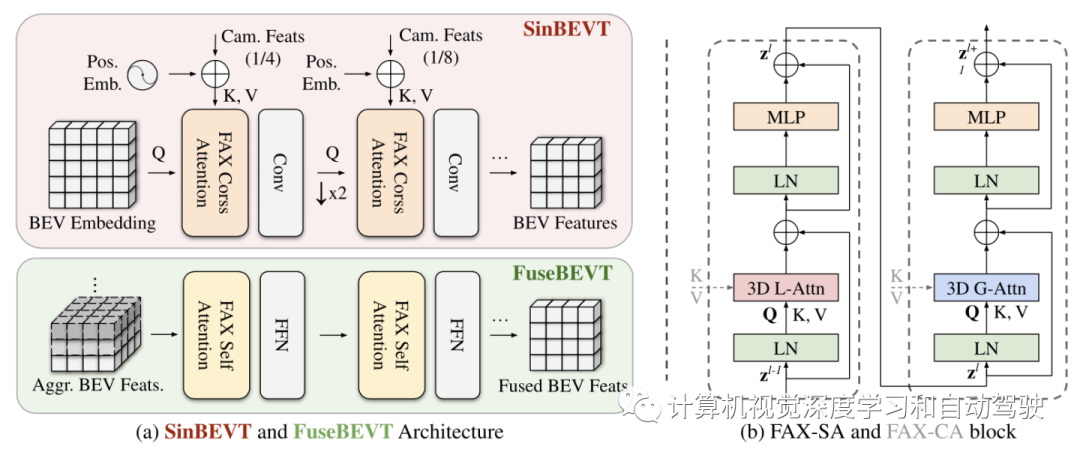
3D FAX 自注意(FAX-SA) 模块定义为
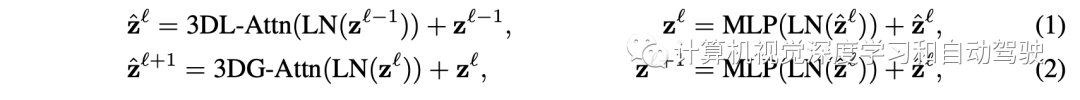
CVT使用低分辨率BEV query,全交叉注意图像特征,这导致小目标的性能下降,尽管效率很高。因此,CoBEVT学习高分辨率BEV嵌入,用层次结构降低分辨率来细化BEV特征。为了高效地高分辨率摄像机编码器中特征query,进一步扩展FAX-SA模块构建FAX交叉注意力(FAX-CA)模型(前面图b),其中用BEV嵌入获得query向量,而Key/Value向量从多视图摄像机特征投影得到。遵循CVT,在应用交叉注意之前,添加一个从摄像机内外参推出的摄像机-觉察位置编码,学习从单摄像机视图到经典地图视角表征的隐式几何推理。
传输数据大小对V2V应用至关重要,因为大带宽需求可能会导致严重的通信延迟。因此,有必要在广播之前压缩BEV特征。用一个简单的1x1卷积自动编码器来压缩和解压BEV特征。一旦接收到包含中间BEV表示和发送者姿态的播放消息,自车应用可微空间变换算子Γξ,将接收的特征几何warp到自车坐标系。
FuseBEVT是一个3-D视觉transformer,可以专注地融合来自多智体的BEV特征信息。自车首先将接收到的和投影的BEV特征H堆叠成高维张量,然后馈入到由多层FAX-SA块组成的FuseBEVT编码器,如图(a)。受益于FAX注意的线性复杂性,这种智体融合Transformer也很有效。每个FAX-SA块通过等式(1-2)进行3-D全局和局部BEV特征转换。3D FAX-SA可以处理从多个智体提取的相同估计区域,导出最终聚合表示。此外,稀疏采样的令牌(token)进行全局交互,获得地图语义(如道路、交通等)上下文理解。
对聚集的BEV表示应用一系列轻量级卷积层和双线性上采样操作,并生成最终分割输出。
除了NuScenes,还有OPV2V,一个大规模的V2V感知数据集,收集在CARLA和协作驾驶自动化工具OpenCDA。它包含73种不同的场景,平均持续时间为25秒。在每种场景中,同时出现各种数量(2到7)的AV,每个AV配备一个激光雷达传感器和4个摄像头,覆盖360°水平视野。主要实验仅利用数据集的摄像机装置,并使用地图预测和真值地图视图标签之间的IoU作为性能指标。
由于OPV2V在同一场景中有多个AV,在测试期间选择一个固定的AV作为自车,并评估其周围100m×100m的区域,地图分辨率为39cm。
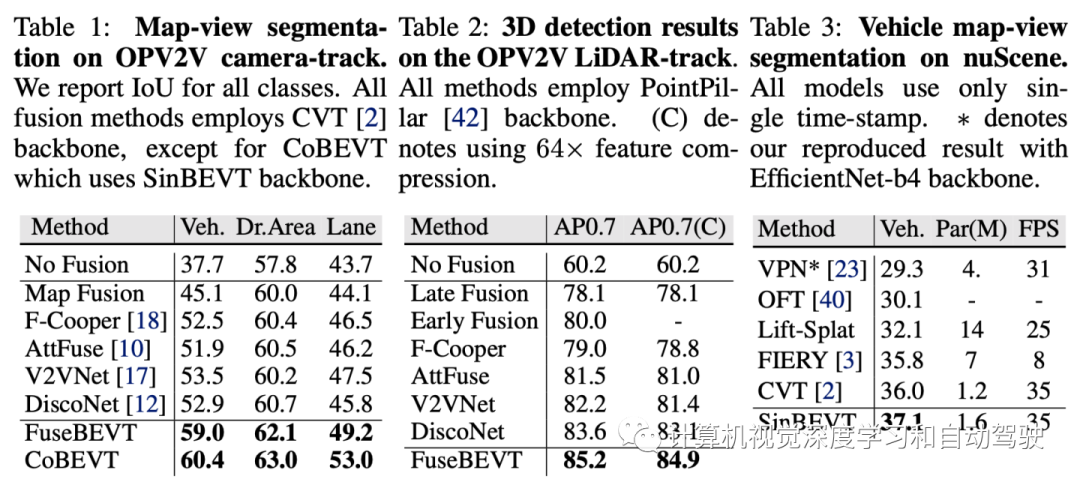
实验结果如下:

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!


















 5850
5850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









