






点击下方卡片,关注“自动驾驶之心”公众号
最近Arxiv上放出来很多自动驾驶工作,『自动驾驶之心知识星球』一直follow技术第一线,每天更新最新的技术进展和行业动态,今天就为大家分享下星球日常的论文更新:
端到端新算法Centaur;
自动驾驶VLM DynRsl-VLM;
基于扩散模型的3D目标检测算法DriveGEN;
稀疏感知SparseAlign;
知识星球大额优惠!欢迎扫码加入~

Centaur
论文标题:Centaur: Robust End-to-End Autonomous Driving with Test-Time Training
论文链接:https://arxiv.org/abs/2503.11650
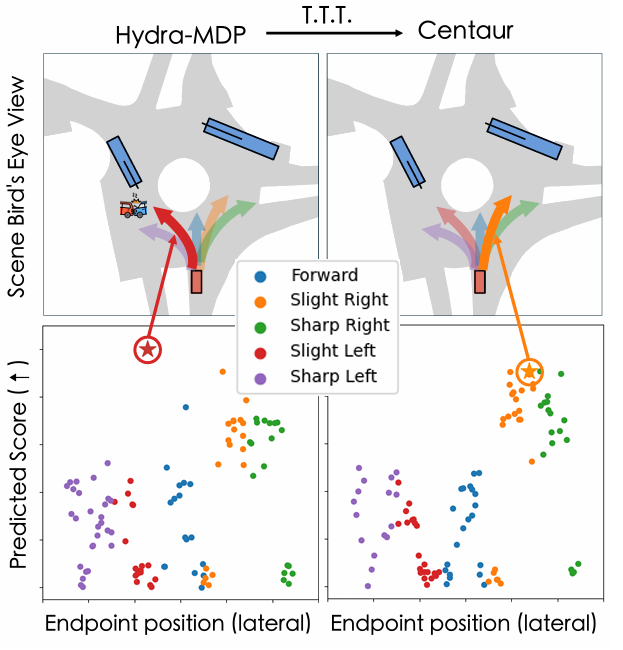
核心创新点:
1. 测试时训练(Test-Time Training, TTT)在端到端自动驾驶中的首次应用
提出一种在线优化框架,通过在部署阶段对模型参数进行单步梯度更新,最小化簇熵(Cluster Entropy),动态调整规划器行为。该方法无需依赖预定义的备用层(fallback layer)或人工设计成本函数(expert-crafted cost functions),直接通过数据驱动提升安全性和适应性。
2. 簇熵(Cluster Entropy)——新型不确定性度量方法
针对轨迹评分(trajectory scoring)类规划器,提出基于方向聚类的无监督不确定性度量:
将候选轨迹按行驶方向(如“急左转”“缓右转”)聚类为5类,构建类别分布。
通过计算分布的香农熵(Shannon Entropy),量化规划决策的置信度,指导测试时训练的目标函数。
该方法简单、可解释,且兼容主流轨迹评分模型(如Hydra-MDP)。
3. 安全关键场景基准navsafe的构建
基于NHTSA事故类型框架,从真实数据中筛选并标注10类安全关键场景(如环岛、无保护左转、恶劣天气等),形成细粒度测试集navsafe。该基准揭示了现有模型在边缘案例(edge cases)中的潜在失效模式,推动自动驾驶安全性研究。
A Framework
论文标题:A Framework for a Capability-driven Evaluation of Scenario Understanding for Multimodal Large Language Models in Autonomous Driving
论文链接:https://arxiv.org/abs/2503.11400
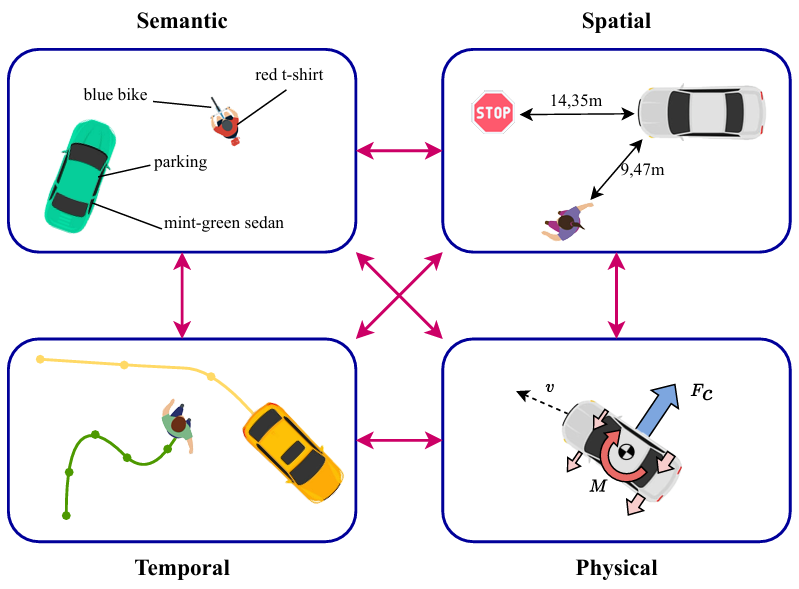
核心创新点:
1. 四维能力评估框架
提出首个系统性评估MLLMs在自动驾驶场景理解能力的框架,整合语义(Semantic)、空间(Spatial)、时间(Temporal)、物理(Physical)四大核心维度,并引入 预测能力(Anticipation)作为跨维度关联的关键纽带,突破传统单一维度评估的局限性。
2. 结构化能力映射体系
基于6层场景模型(6LM)、责任敏感安全模型(RSS)及Safety of the Intended Functionality(SOTIF)标准,构建从环境上下文→多模态感知→场景描述→预测推理→任务执行 的完整映射链,实现对动态交通场景的细粒度解析。
3. 多模态融合机制
创新性整合视觉(Camera/LiDAR)、运动学(IMU)、地理空间(HD Map)等7类输入模态,通过显式空间拓扑建模 (如相对距离/朝向/占用空间)和隐式物理约束推理 (如材质属性/运动学模型),解决传统VLMs在空间-时序信息耦合处理上的缺陷。
4. 任务驱动的评估范式
定义四大下游任务类型(感知任务τ_p、决策任务τ_d、交互任务τ_i、学习任务τ_l),并通过链式思维推理(CoT)机制强制模型输出结构化描述(如对象属性-状态-行为预测),提升自动驾驶决策的可解释性与安全性验证效率。
本文内容均出自『自动驾驶之心知识星球』,欢迎加入交流。这里已经汇聚了近4000名自动驾驶从业人员,每日分享前沿技术、行业动态、岗位招聘、大佬直播等一手资料!欢迎加入~
DynRsl-VLM
论文标题:DynRsl-VLM: Enhancing Autonomous Driving Perception with Dynamic Resolution Vision-Language Models
论文链接:https://arxiv.org/abs/2503.11265
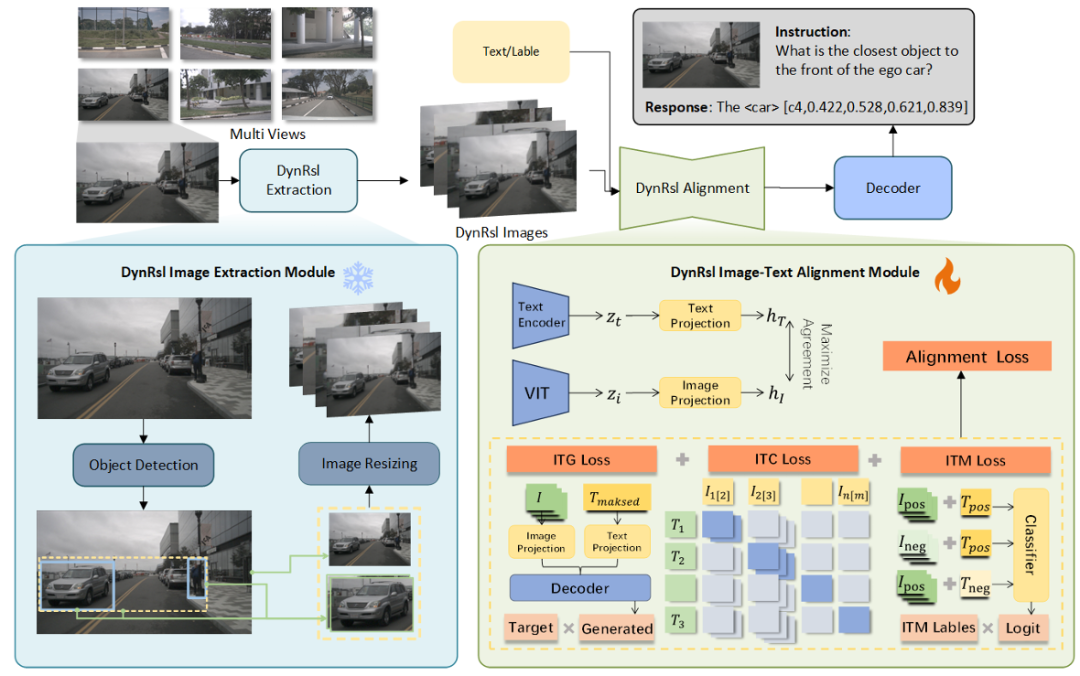
核心创新点:
1. 动态分辨率图像输入处理模块
多尺度特征保留机制 :通过YOLOv8目标检测生成高分辨率的感兴趣区域(ROIs)及合并区域(Combined Regions),在降低全局图像分辨率的同时保留关键实体(如行人、车辆)的细节特征。
计算效率优化 :结合下采样全局图像与高分辨率区域图像,平衡细节保留与计算复杂度,解决传统下采样导致的小目标特征丢失问题。
2. 动态分辨率图像-文本对齐模块
多粒度特征交互 :替代传统Q-Former,通过注意力机制融合多分辨率视觉特征(全局、ROI、合并区域),实现跨模态细粒度对齐。
对比学习增强 :采用对称InfoNCE损失函数,结合图像-文本对比(ITC)、图像引导文本生成(ITG)及图文匹配(ITM)任务,提升跨模态语义一致性。
3. 自动驾驶场景适配性
多视角融合 :适配NuInstruct数据集的6视角输入,通过时空适配器(ST-Adapter)扩展基模型(如BLIP-2)处理视频序列的能力。
性能提升验证 :在感知、预测、风险评估等任务中,对比基线模型(BLIP-2、BEV-InMLLM)平均提升3-4%的准确率,尤其在小目标检测与空间关系推理中表现显著。
DriveGEN
论文标题:DriveGEN: Generalized and Robust 3D Detection in Driving via Controllable Text-to-Image Diffusion Generation
论文链接:https://arxiv.org/abs/2503.11122
论文代码:https://github.com/Hongbin98/DriveGEN
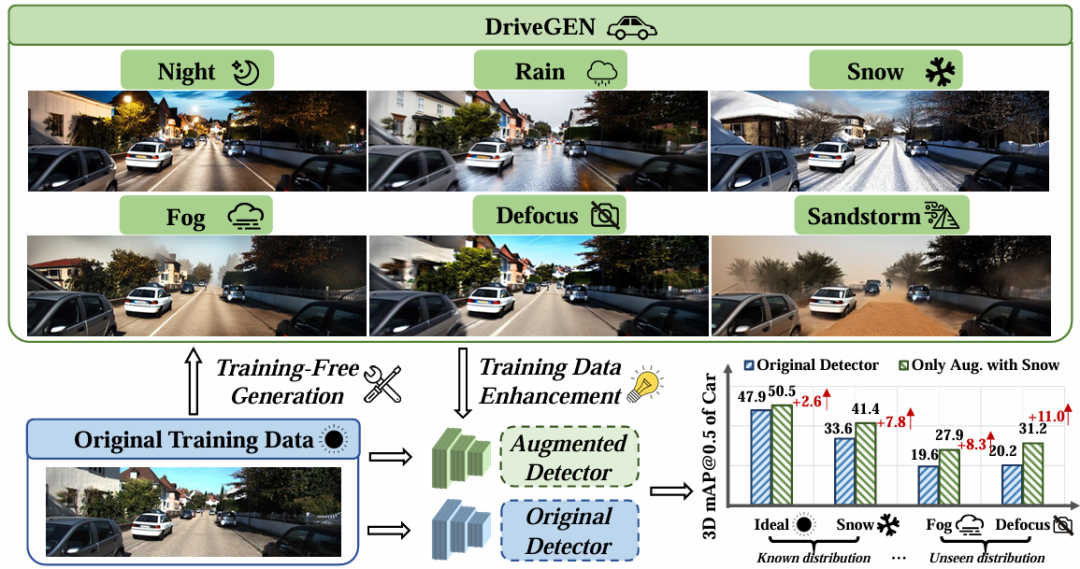
核心创新点:
1. 无训练可控扩散生成框架
首次提出训练-free的可控文本-图像(T2I)扩散生成方法 ,直接利用预训练扩散模型(如Stable Diffusion)生成多样化OOD驾驶场景(如雪天、雾天),无需额外训练扩散模型,显著降低测试时计算成本。
2. 双阶段几何保真增强机制
自原型提取(Self-Prototype Extraction)
通过布局(bounding box)引导的峰值函数重加权 ,从自注意力特征中提取细粒度自原型(Self-Prototypes) ,精准定位多物体区域,解决传统方法因依赖粗粒度自注意力导致的物体遗漏/错位问题。
原型引导扩散(Prototype-Guided Diffusion)
语义感知特征对齐(Semantic-aware Alignment) :在去噪阶段对齐自原型与自注意力特征,保留物体语义结构;
浅层特征对齐(Shallow Feature Alignment) :通过约束浅层噪声潜在特征,补偿语义对齐在小物体几何细节上的不足,确保微小物体(如骑行者)的3D几何精度。
3. 跨场景泛化性提升
在KITTI和nuScenes数据集验证,仅需单次增强(如生成"雪天"场景),即可使3D检测器在13种OOD场景(噪声、模糊、天气变化等)平均mAP提升7.6%,且在未见过的"雾天""散焦"场景中亦有显著泛化能力。
AugMapNet
论文标题:AugMapNet: Improving Spatial Latent Structure via BEV Grid Augmentation for Enhanced Vectorized Online HD Map Construction
论文链接:https://arxiv.org/abs/2503.13430
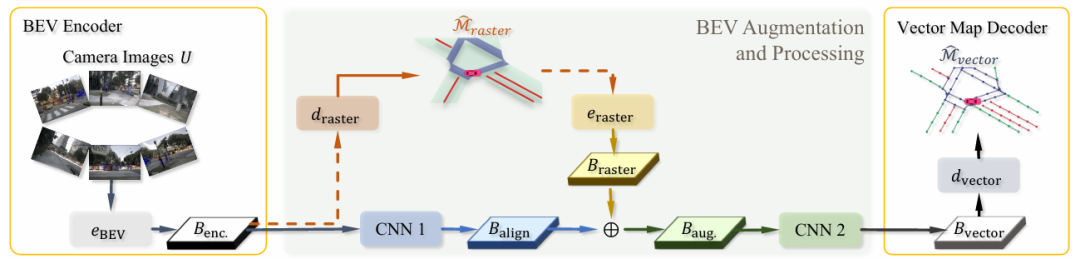
核心创新点:
1. BEV网格增强(BEV Grid Augmentation)
提出一种新型潜在空间增强机制,通过将光栅解码器预测的中间光栅地图(Raster Map)编码为空间特征,并与原始BEV潜在网格相加,直接注入密集空间监督信息,从而强化BEV潜在空间的结构化表征能力。
2. 梯度隔离策略(Gradient Stopping)
引入梯度停止技术,阻断光栅解码分支的梯度反向传播至BEV编码器,避免光栅监督任务干扰矢量解码器的潜在空间优化,确保矢量解码的稳定性和独立性。
3. 双阶段BEV特征优化
设计两级卷积网络(CNN1和CNN2),分别对原始BEV特征进行对齐(Align)和增强后特征融合,进一步优化潜在空间的结构化特性,提升长距离感知与复杂场景(如人行横道)的检测精度。
4. 密集与稀疏监督的协同优化
通过并行光栅解码任务提供密集像素级监督,同时结合矢量解码的实例级稀疏监督,在无需复杂后处理的情况下实现高效矢量化地图生成,显著提升模型对动态环境(如施工区域、天气变化)的鲁棒性。
5. 潜在空间结构验证
采用Silhouette评分、主成分分析(PCA)和互信息(Mutual Information)量化潜在空间的结构化程度,证明增强后的BEV网格具有更高的类内聚类性和类间区分度,且与真实光栅地图的语义一致性显著提升,直接关联矢量化预测性能的改进。
SparseAlign
论文标题:SparseAlign: A Fully Sparse Framework for Cooperative Object Detection
论文链接:https://arxiv.org/abs/2503.12982
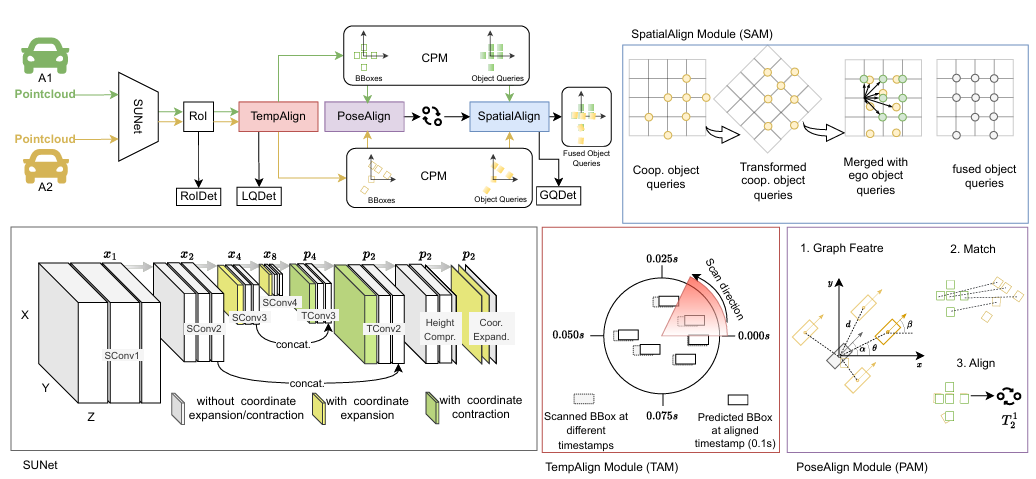
核心创新点:
1. 全稀疏架构设计
提出SUNet稀疏3D主干网络,通过坐标扩展卷积(CEC)解决稀疏卷积的两大固有问题:
中心特征缺失(CFM) :通过2D CEC扩展BEV坐标覆盖物体中心区域
孤立卷积域(ICF) :通过3D CEC增强远距离/遮挡区域的点云连通性
2. 时空对齐模块
TempAlign模块 :基于查询的时序上下文学习,通过历史帧特征补偿通信延迟和传感器异步
PoseAlign模块 :提出姿态无关邻域图特征匹配 ,结合PGO优化实现鲁棒的相对位姿校正
SpatialAlign模块 :设计坐标自适应融合机制 ,通过MLP变换与最近邻特征聚合实现多智能体特征对齐
3. 高效通信机制
采用对象查询特征共享 ,相比传统BEV特征图减少98%带宽消耗
提出CompassRose编码 优化3D框方向回归,通过四锚点角度嵌入提升方向预测鲁棒性
4. 性能突破
在OPV2V/DairV2X等数据集上,以全稀疏架构超越现有密集方法,在TA-COOD任务中AP@0.7 指标提升达14.4%
通过自由空间增强(FSA)和 梯度计算调度 策略,显著提升远距离检测和训练效率
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫码加入~
星球大额优惠!欢迎扫码加入~


















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









