






作者 | PACE7 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1903107931316130458
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『大模型』技术交流群
本文只做学术分享,如有侵权,联系删文
AIGC新手,内容理解如有不对请多多指正。
原文:One Step Diffusion via Shortcut Models
github:GitHub - kvfrans/shortcut-models
摘要
为了缓解目前diffusion架构+flow matching生成速度慢且训练阶段复杂的问题提出了一个叫shortcut model的模型,整个训练过程采用单一网络、单一训练阶段。condition包括当前噪声强度,还取决于stepsize(为了在去噪过程中直接跳过),这个方法在作者的实验中比蒸馏的方法好,并且在推理的时候可以改变step budgets。
之前SD3采直流匹配训练,但是仍然需要28步,这篇论文在首页放了一张效果图,效果看起来很惊艳。

整个网络设置是端到端且只需要一次训练就可以完成一个one-step模型,不像之前的关于蒸馏的工作(参考Progressive Distillation for Fast Sampling of Diffusion Models、http://arxiv.org/abs/2211.12039、Relational Diffusion Distillation for Efficient Image Generation,这三个工作都基于教师-学生来蒸馏,通过多阶段的训练来逐渐折半DDIM的采样步数)。
前置知识
Flow-matching
流匹配的内容在网络上的很多博客都有讲解,这部分就简单带过一下。
流匹配实际上就是通过学习将噪声转化为数据的常微分方程(ODE)来解决生成模型问题,在直流匹配中,整个模型就把真实图像的概率分布和噪声的概率分布之间的路径当作一条直线进行传输,在给定 x0 和 x1 的情况下,速度 vt 是完全确定的。但是,如果只给定 xt,就会有多个可信的配对(x0、x1),因此速度会有不同的值,这就使得 vt 成为一个随机变量。Flow-matching模型就是用来估计预期值在xt条件下的vt是多少,然后vt是xt处所有可信速度的平均值。最后可以通过对随机采样的噪声 x0 和数据 x1 对的经验速度进行回归来优化流量模型。
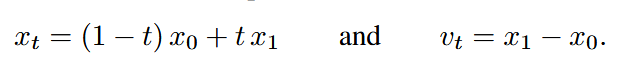
这个速度vt就是直接用xt对t求导,就得到了x1-x0,然后整个模型优化就靠下面这个损失函数。
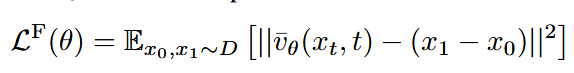
实际上就是用回归的损失去尽量让预测的速度能够符合直流匹配定义的速度。
然后去噪过程就是从流量模型中采样,首先从正态分布中采样一个噪声点 x0。然后根据学习到流模型从x0到x1迭代更新该点,整个过程可通过在较小的离散时间间隔内进行欧拉采样来近似实现,因为是直线传输。
为什么提出ShortCut models?
作者通过一个实验去研究了完美训练的ODE在步数减少之后的缺陷,具体来说就是步长有限的情况下,还是很难做到能够将噪声分布确定性地映射到我们需要的数据分布。
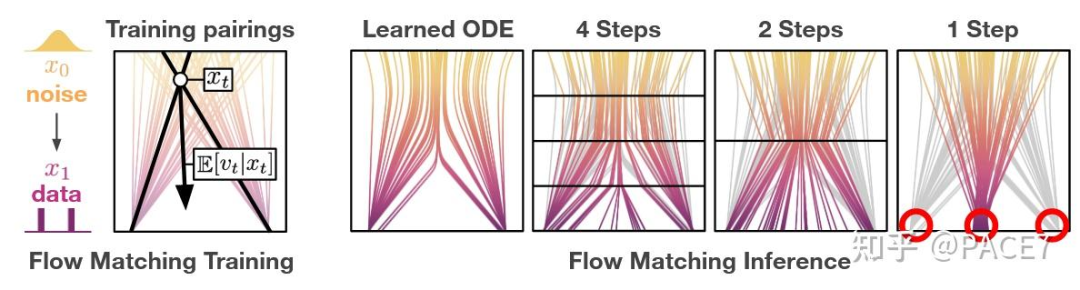
流量匹配学习预测从 xt 到数据的平均方向,因此跟随预测的步长越大,将跳转到多个数据点的平均值。在 t=0 时,模型接收纯噪声输入,并且(x0,x1)在训练过程中随机配对,因此 t=0 时的预测速度指向数据集平均值。因此,即使在流量匹配目标的最优状态下,对于任何多模式数据分布,一步生成都会失败。这段是作者原话,感觉说得蛮清晰,就不加个人理解了。
ShortCut Models
insight:可以训练一个支持不同sampling budgets的一个模型,以时间步长t和步长d为作为条件。那么就顺势提出了下面这个公式。
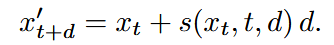
这个s就是输入Xt,t,d之后的出来的捷径,得到这个路径之后就可以直接让Xt从这个s出发跳步得到Xt+d,OK,那么整个model的训练目标就很明确了,就是通过shortcut model去学习这个s,条件是Xt,t,d。其实整个公式就是直流匹配的跳步模式,当d≈0的时候,就是flow-matching的训练模式,s就直接退化成了v。
那么要学的东西出来了,用什么去约束呢?第一种方法当然就是用小步长去接近flow-matching的forward过程,但是这样做的话训练成本也还是很高,尤其是对直接端到端训练来说,并且小步长实际上对flow-matching的改进不是很大。第二种就是本文用的方法,直接用shortcut model自己的性质,就是一个s步等于两个s/2步。也就是以下公式。
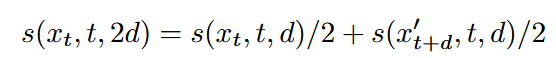
初步看这个公式可能会疑惑为什么会除以2,请注意,上一个公式在s求出来之后还需要乘d,所以s其实不是最终路程,最终的路程是s*d,而整个式子左边的步长为2d,路程相同的情况下,两边同时除以2d才得出来右边等式的1/2系数。
d>0的时候就直接用这个公式,d=0就直接用流匹配去训练。整体流程如下
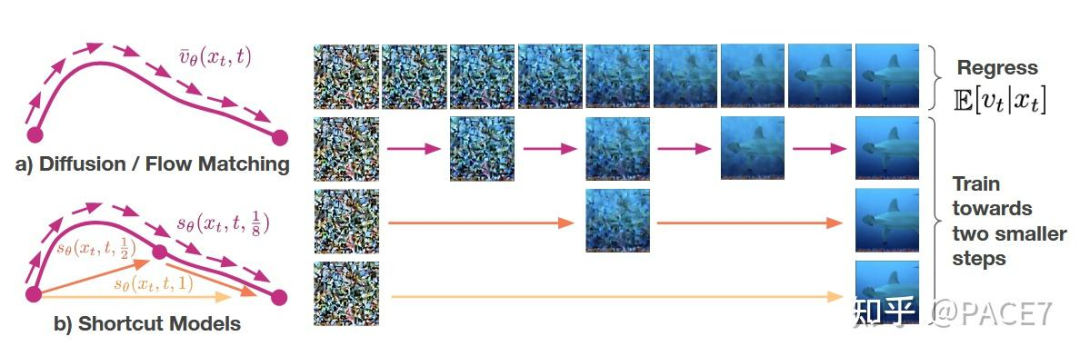
其实就是将flow-matching当作连续的一条线,shortcut直接输入了步长,然后网络获得步长之后直接去获得应道到路径上的哪个路径点,就是上面图左边曲线的黄色部分。整个训练过程把flow-matching综合起来构成了下面的损失函数:
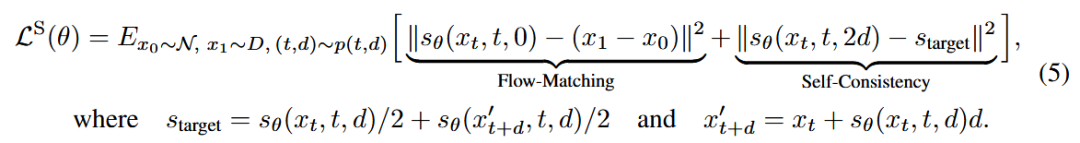
上述目标学习的是从噪声到数据的映射,在任何步长序列下查询时都是一致的,包括直接在单步中查询。目标中的流量匹配部分将捷径模型建立在小步长的基础上,以匹配经验速度样本。这就确保了捷径模型在多步长查询时具有基础生成能力,这与等效的流量匹配模型完全相同。第二部分的话,通过串联两个较小shortcut的序列,为较大步长构建适当的目标。这样,生成能力就从多步到少步再到一步。综合目标可通过单一模型和单一端到端训练运行进行联合训练。
训练细节
名词定义:经验目标就是对应损失函数第一项需要的目标,一致性目标就是对应损失函数第二项所需要的目标
当 d → 0 时,s等同于vt。因此可以使用flow-matching的损失来训练d=0时的捷径模型,即随机抽样 (x0, x1) 对并拟合vt的期望值。这个项可以看作是小步s的基础,以匹配数据去噪ODE,然后对t ∼ U (0, 1) 进行均匀采样。为了限制复合误差,并且限制引导路径的总长度。因此,我们选择了一种二元递归模型,即用两条捷径来构建一条两倍大的捷径。
然后确定一个步数 M 来表示逼近 ODE 的最小时间单位;在实验中使用了 128 步。根据 d∈ (1/128, 1/64 ... 1/2, 1),这将产生 log2(128) + 1 = 8 种可能的捷径长度。在每个训练步骤中,我们对 xt、t 和随机 d < 1 进行采样,然后使用shortcut连续进行两步。然后将这两步的并集作为目标,并且在2d处训练模型。
将 1-k 个经验目标与k个一致性目标的比例结合起来,构建一个训练批次。k=1/4是合理的。其实这部分也很好理解,因为这个端到端模型实际上就是需要先训练一个flow-matching较好的模型,然后第二项只是在flow-matching的基础上进行优化,如果flow-matching训练得不好,后一项自然训练不好,因为s_target是需要从flow-matching模型中采样的,后一项只能在d=0训练的基础模型上去拟合这个模型,本质上shortcut还是一个教师-学生的思路,但是不同于之前教师和学生都是模型,shortcut将教师-学生拆分为两个损失函数去训练同一个模型,从而实现了端到端。
CFG设定:评估 d = 0 时的捷径模型时使用 CFG,而在其他情况下则放弃 CFG。CFG 在捷径模型中的一个局限性是,必须在训练前指定 CFG 比例。
EMA:用EMA去从d=0的模型上生成d=1的一致性目标,本质上就是平滑一下误差。
其他就是一些网络设置,这里就不一一阐述了,有兴趣可以自己查看一下原论文。
实验结果
FID-50K分数评估
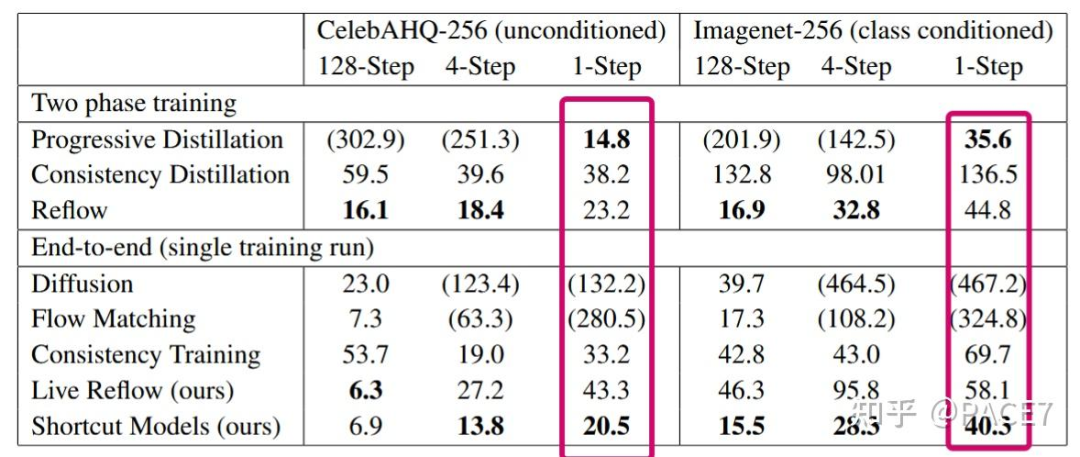
可以看到在端到端的训练框架中,shortcut models的FID-50k是SOTA,但是相对于PD的蒸馏方式来说,在一步蒸馏中效果还是有待提高。
对ShortCut提出需解决问题的验证
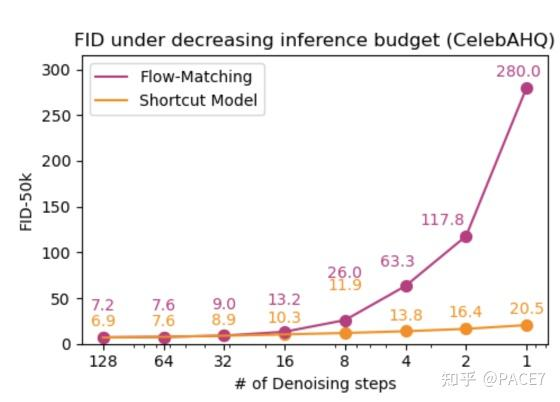
在文章开投我们就提到了这篇论文的insight,他是为了缓解flow-matching在步数极低的情况下的崩塌而提出了,这个实验也证明了这一点,在1步模型中,Shortcut的表现完全暴打直接用flow-matching训练的diffusion(但实际上这个对比没有什么特别大意义,flow-matching确实就不适合一步训练,这个问题SD3当时也提出来了)。
作者在后续甚至验证了shortcut在其他领域的鲁棒性,确实是一项非常完善的工作,有其他领域的读者可以去看下原文。
总结
shortcut models确实提供了一个直接在flow-matching上蒸馏的好办法,但是训练过程中的参数设定个人感觉还是靠多种尝试,例如K的选取或许会较大程度影响shortcut models的发挥。反观多阶段的训练方法,至少多阶段确保了一个训练得较为完善的教师模型能够作为参考,而shortcut models如果参数设置不对,flow-mathcing的基础模型可能会不够完善,进而倒是损失第二项会出现较大程度的累计误差。
其次,作者本人也提到了,虽然shortcut能够抑制flow-matching直接在1步训练上的崩溃,但是在步数太低的时候仍然和多步采样存在较大的性能差距(不过1步能做到这个程度已经很好了。。。)。
总的来说,这篇论文的工作很完善,也是一个比较新颖的减少采样步数的方案,但是本质上也是蒸馏的一种,并且端到端的训练相比于多阶段的训练确实更依靠经验,一不注意就会训练失败。
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









