






点击下方卡片,关注“自动驾驶之心”公众号
Generative AI for Autonomous Driving
论文标题:Generative AI for Autonomous Driving: Frontiers and Opportunities
论文链接:https://arxiv.org/abs/2505.08854

核心创新点:
1. 多模态数据生成与增强
高保真传感器数据合成:利用扩散模型(Diffusion Models)生成逼真的LiDAR点云(如LiDMs、RangeLDM)和相机图像(如BEVGen、MagicDrive),解决长尾场景数据稀缺问题。
3D/4D场景重建:基于NeRF(如Block-NeRF、UrbanNeRF)和3D高斯泼溅(3D Gaussian Splatting,如OmniRe、DrivingGaussian)的动态场景建模,支持高精度时空一致性渲染与编辑。
合成数据流水线:通过物理模拟(CARLA、SUMO)与生成模型结合,构建涵盖天气变化、事故场景的多样化数据集(如DeepAccident、Shift),提升感知模型泛化能力。
2. 大语言模型与多模态推理
感知-动作一体化架构:DriveVLM、EMMA等模型将视觉-语言大模型(VLM)与自动驾驶任务结合,通过链式推理(Chain-of-Thought)实现场景理解、轨迹预测与规划的统一框架。
端到端决策生成:GPT-Driver、LMDrive等模型直接映射多模态输入(图像、LiDAR、文本指令)为控制信号或轨迹,降低传统模块化系统的误差累积。
交互式场景编辑:ChatSim、DriveEditor等工具利用LLM和扩散模型实现语义驱动的场景动态修改(如物体增减、轨迹调整),支持闭环仿真测试。
3. 轨迹与行为建模
多模态轨迹生成:扩散模型(MotionDiffuser、Scenario Diffusion)与条件VAE(Trajectron++)生成社会合规的交互轨迹,支持复杂交通场景的仿真与测试。
交通流模拟:基于Transformer的生成策略(TrafficBots、BehaviorGPT)学习真实驾驶日志,生成可扩展的异构交通参与者行为,提升模拟真实性。
数字孪生与Sim2Real技术
高保真数字孪生系统:通过Real2Sim(Occ3D、UrbanDiffusion)与Sim2Real(Stag-1、LidarDM)双向闭环,构建虚实一致的动态环境,支持边缘案例测试与策略优化。
物理一致性增强:结合神经辐射场(NeRF)与物理引擎(Isaac Sim),生成几何与动力学一致的合成数据,缩小仿真与现实的传感差距。
5. 可信与安全验证
不确定性建模:扩散模型与贝叶斯框架(CTPS)生成多样化假设,量化预测与规划的不确定性,支持安全边界评估。
伦理与合规性研究:提出生成式AI的评估指标(如FlowEval、TIFA)与联邦学习框架(Federated GenAI),确保数据隐私与算法透明度。
大额新人优惠!欢迎扫码加入~

Camera-Only 3D Panoptic Scene Completion
论文标题:Camera-Only 3D Panoptic Scene Completion for Autonomous Driving through Differentiable Object Shapes
论文链接:https://arxiv.org/abs/2505.09562
代码:https://github.com/nicolamarinello/OffsetOcc
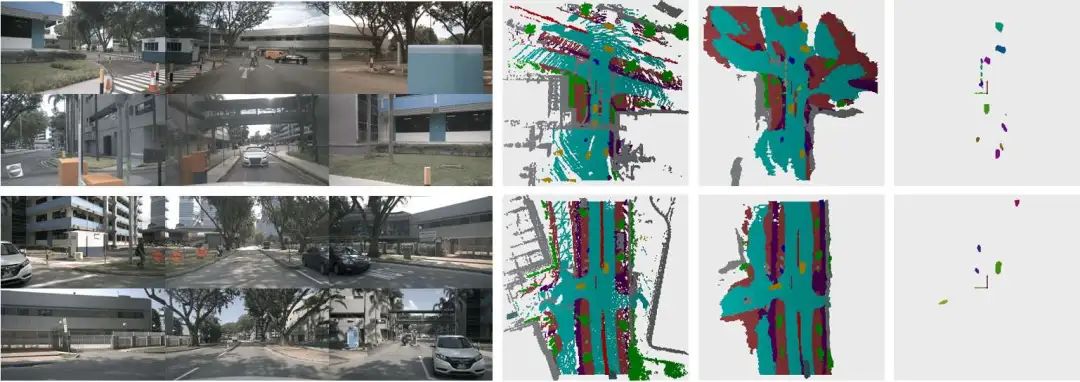
核心创新点:
1. 可微分对象形状建模
首创将3D对象形状建模为连续可微的偏移量集合,通过预测对象中心坐标与相对偏移向量(offsets)构建对象点云,实现了端到端的对象形状学习。该方法突破传统体素掩模的离散表示局限,以参数化方式高效表征任意尺度对象的几何形态。
2. 双模块扩展架构
Object Module:基于DETR框架设计,通过3D可变形注意力机制解码对象查询(object queries),同步预测对象类别、3D中心位置及形状偏移量,实现实例级对象建模。
Panoptic Module:提出无参数的投票融合机制,结合基线语义预测与对象实例预测,通过半径投票(radius voting)优化实例ID分配,有效校正定位误差,生成全景占用网格。
3. 解耦式监督策略
采用两阶段训练范式:首阶段冻结基线语义场景补全模型,次阶段通过解耦监督策略分离对象中心定位与形状学习。训练时,偏移量损失基于真实对象中心计算,避免定位误差干扰形状优化,显著提升实例分割质量(PQTh提升7.6%)。
4. 轻量化全景扩展
模块化设计使全景能力扩展仅增加2.3M参数,推理延迟控制在714ms(NVIDIA L40S),较基线模型仅增加42.8%,为实时自动驾驶系统提供高效解决方案。
MoRAL
论文标题:MoRAL: Motion-aware Multi-Frame 4D Radar and LiDAR Fusion for Robust 3D Object Detection
论文链接:https://arxiv.org/abs/2505.09422
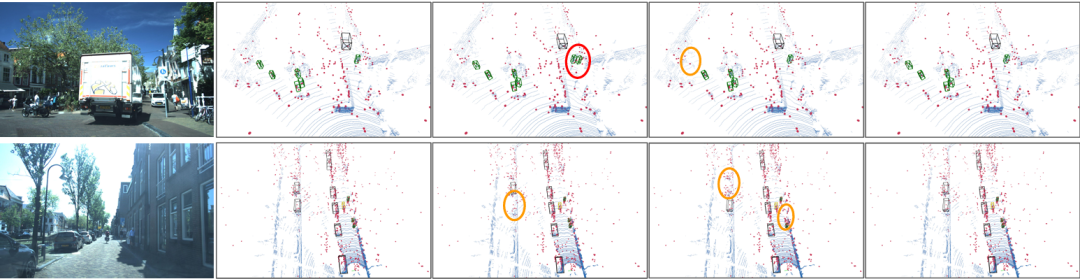
核心创新点:
1. 运动感知雷达编码器(Motion-aware Radar Encoder, MRE)
针对多帧4D雷达点云中动态物体跨帧错位(inter-frame misalignment)导致的"拖尾(tail)"问题,提出基于运动分割(Moving Object Segmentation, MOS)的点级运动补偿机制。
通过雷达径向速度(radial velocity)与绝对径向速度(absolute radial velocity)增强编码,结合注意力机制(Velocity Attention)优化动态点表征,并利用层级特征提取(Set Abstraction)与特征传播(Feature Propagation)实现运动状态预测,最终通过运动掩码(Motion Mask)对动态点进行时序对齐补偿。
2. 运动注意力门控融合(Motion Attention Gated Fusion, MAGF)
设计多尺度运动特征融合策略:通过雷达运动特征(Fsa-全局特征、Ffp-局部特征)的加权聚合生成统一运动表征(Fmotion R),结合通道注意力(Channel Attention)增强LiDAR空间特征(FL)的动态目标敏感性。
引入门控机制(Gating Map G)实现LiDAR特征的空间选择性增强
3. 多模态运动感知框架集成
构建端到端融合架构,将运动补偿后的4D雷达点云(经雷达稀疏编码器提取空间特征)与LiDAR特征通过自适应融合(Adaptive Fusion)结合,并引入动态前景增强机制,在VoD数据集上实现73.30% mAP(全区域)与88.68% mAP(行车通道),尤其对行人(69.67% AP)和骑行者(96.25% AP)检测性能显著提升,验证了运动信息对动态目标检测的有效性。
FreeDriveRF
论文标题:FreeDriveRF: Monocular RGB Dynamic NeRF without Poses for Autonomous Driving via Point-Level Dynamic-Static Decoupling
论文链接:https://arxiv.org/abs/2505.09406
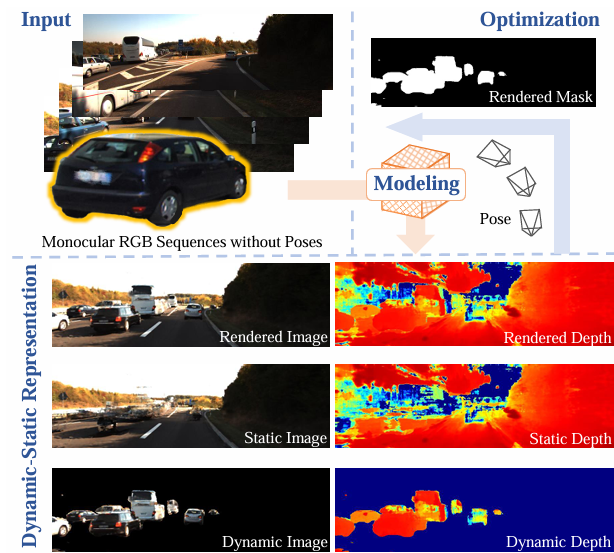
核心创新点:
1. 无姿态输入的单目动态场景建模
创新点 :首次实现仅依赖单目RGB视频序列的动态NeRF重建,无需真实相机姿态(poses)或外部传感器(如LiDAR)。
技术细节 :通过联合优化相机姿态与辐射场,结合语义监督的动态-静态分离策略,解决了传统方法对多传感器依赖的问题。
2. 采样点级动态-静态解耦(Dynamic-Static Decoupling)
创新点 :在射线采样层面引入语义监督分离场(Semantic-Supervised Separation Field) ,将动态与静态点分配至独立模型。
技术细节 :
利用六平面结构(Six-plane Structure)编码时空特征,通过MLP生成动态概率掩码(Dynamic Probability Mask),以可学习阈值τ区分动态/静态点。
独立建模动态场(Dynamic Field)与静态场(Static Field),减少因动态物体运动导致的模糊与伪影。
3. 光流引导的动态对象一致性策略
创新点 :提出Warped Ray-Guided Rendering Consistency Loss ,通过光流追踪动态对象运动,缓解遮挡与运动模糊问题。
技术细节 :
基于3D场景流(Scene Flow)对动态点进行时序对齐,生成偏移射线(Warped Ray),绕过遮挡区域。
利用相邻帧的2D光流构建一致性损失(L_adjacent),约束动态对象的时空连续性。
4. 动态流约束的联合姿态优化
创新点 :将动态场景流(Dynamic Scene Flow)引入相机姿态与辐射场的联合优化,提升姿态估计鲁棒性。
技术细节 :
通过预测动态点的3D运动流(f_{w,bw}),结合深度先验(DPT逆深度)与光流损失(L_flow),联合优化相机位姿。
有效避免传统方法中因遮挡或动态物体遮蔽导致的姿态漂移问题。
5. 多尺度时空特征建模与优化
创新点 :结合VM分解(Vector-Matrix Product)与多平面结构,高效捕捉大规模场景的时空动态。
技术细节 :
采用非线性映射将无界场景压缩至立方空间(side length=4),并引入时间戳重映射(t∈[-2,2])。
通过渐进式网格优化(Coarse-to-Fine Grid)提升小尺度变形与动态元素的建模精度。
TransDiffuser
论文标题:TransDiffuser: End-to-end Trajectory Generation with Decorrelated Multi-modal Representation for Autonomous Driving
论文链接:https://arxiv.org/abs/2505.09315
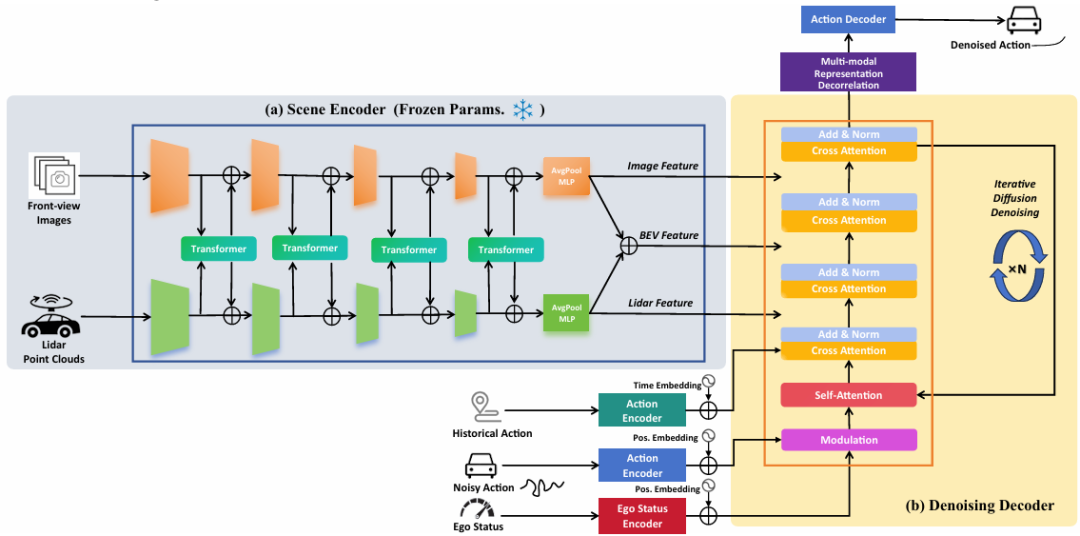
核心创新点:
1. 编码器-解码器架构与多模态融合
基于冻结的Transfuser骨干网络,构建多模态场景编码器 ,融合前视图像、激光雷达(LiDAR)及自车状态(Ego Status)信息,生成BEV(Bird's Eye View)特征空间中的场景表征。通过Transformer模块实现跨模态注意力机制,增强多尺度特征交互,为轨迹生成提供条件输入。
2. 去相关多模态表征优化机制
针对扩散模型生成轨迹的模式崩溃 (Mode Collapse)问题,提出计算高效的多模态表征去相关正则化 (Multi-modal Representation Decorrelation)。通过约束多模态特征矩阵的非对角相关系数趋近于零,降低不同模态维度间的冗余信息,从而拓展潜在表征空间的利用率。该机制在训练阶段作为附加损失项嵌入,无需依赖锚定轨迹(Anchor Trajectories)或预定义词汇库(Vocabulary),显著提升生成轨迹的多样性(多样性指标提升6.3%)。
3. 扩散模型驱动的连续动作空间生成
采用去噪扩散概率模型 (DDPM),以迭代方式从高斯噪声中解码连续动作空间的轨迹。通过优化反向扩散过程(Reverse Denoising Process),将多模态条件输入与噪声状态逐步解耦,最终生成符合场景约束的多样化候选轨迹。推理阶段结合拒绝采样(Rejection Sampling)筛选可行性轨迹,在保证效率的前提下减少冗余计算(仅生成30个候选轨迹,对比GoalFlow的128/256个)。
4. 性能与泛化能力突破
在规划导向的NAVSIM基准测试中,TransDiffuser以94.85 PDMS分数 刷新SOTA,超越所有基于锚定先验或固定词汇的方法。消融实验验证了去相关机制对轨迹多样性(EP↑1.3%)与舒适性(C↑0.5%)的协同提升,同时证明其对扩散步长(Timesteps)与批量大小(Batchsize)的鲁棒性。
Embodied Intelligent Industrial Robotics
论文标题:Embodied Intelligent Industrial Robotics: Concepts and Techniques
论文链接:https://arxiv.org/abs/2505.09305
项目主页:https://github.com/jackeyzengl/Embodied_Intelligent_Industrial_Robotics_Paper_List
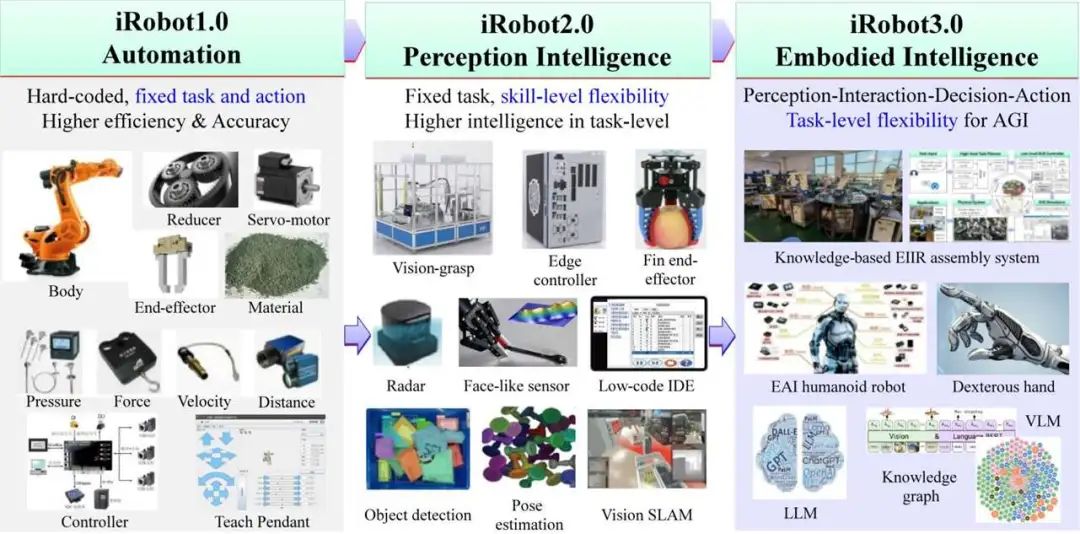
核心创新点:
1. 知识驱动的具身智能框架
多模态知识图谱 :融合制造过程中的产品、工艺、资源等异构数据,构建动态语义知识图谱(如KGAssembly、KG-driven ASP),支持跨品类产品的可重构装配规划与实时决策。
知识增强型问答系统 :通过术语增强的检索增强生成(RAG)技术(如AMGPT、Manufacturing QA),实现工业知识的精准解析与自然语言交互。
2. 高层次任务规划与低层次技能控制的协同
分层任务规划 :
基于知识图谱与深度强化学习(DRL)的细粒度装配序列规划(如M. Jiang等)。
结合大语言模型(LLM)的视觉-语言-动作(VLA)世界模型(如3D-VLA、Spatial VLA),实现自然语言到机器人动作的映射。
技能表示与复用 :
提出技能本体论框架 (如SkiROS2、ROSPlan),通过行为树(Behavior Tree)与运动基元(Dynamic Movement Primitives)实现技能的模块化建模与跨任务迁移。
基于人类示教的多模态技能解码(MASD)与几何零空间学习。
3. 自主演化与自适应控制
强化学习与动态适应 :
面向复杂车间物流的深度强化学习导航。
基于接触感知的柔性操作技能与多任务技能学习框架(MT-RSL)。
人机协作与知识迁移 :
提出人机共享装配分类法(Human-Robot Shared Assembly Taxonomy),支持无缝知识转移。
结合LLM的示教学习优化。
4. 虚实融合的仿真验证体系
高保真工业仿真平台 :
集成物理引擎与多模态交互的仿真环境(如iGibson 2.0、ThreeDWorld),支持家庭任务与工业场景的预训练。
基于数字孪生的虚实交互验证(如Open X-Embodiment数据集与RT-X模型)。
5. 工业基础模型与领域专用语言
工业通用模型 :
提出工业基础模型 (Industrial Foundation Model),整合多模态数据与领域知识,支持跨场景泛化。
领域专用语言 (DSL):
开发面向装配、物流等场景的编程语言(如RoboLang、EzSkiROS、PyDSLRep),降低机器人编程门槛。
Extending Large Vision-Language Model
论文标题:Extending Large Vision-Language Model for Diverse Interactive Tasks in Autonomous Driving
论文链接:https://arxiv.org/abs/2505.08725
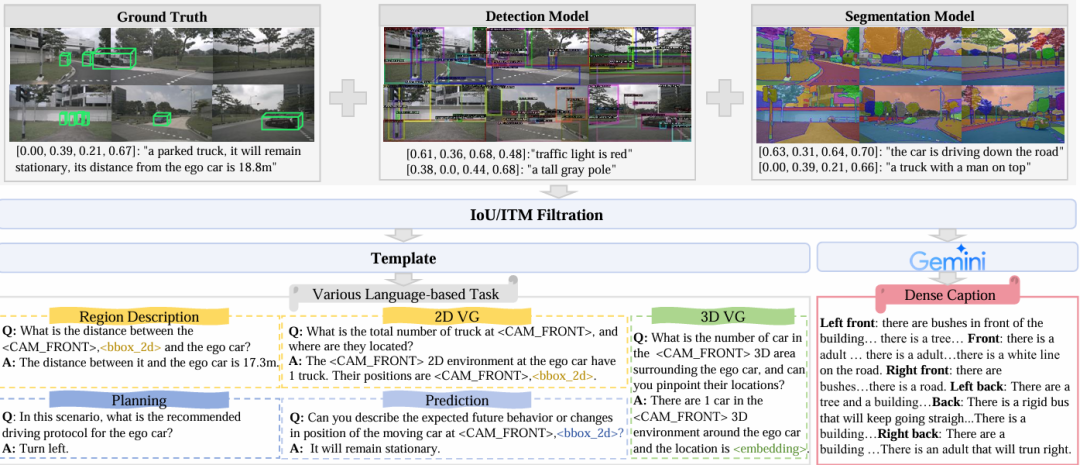
核心创新点:
1. NuInteract数据集
提出首个面向自动驾驶场景的大规模多视角图像-语言基准数据集 ,包含239K图像、34K视频帧及1.5M图像-语言对,覆盖850个复杂驾驶场景。
支持密集场景描述生成 (Dense Caption)、3D视觉基础(3D Visual Grounding)、轨迹预测与规划等多任务,提供细粒度环境上下文与空间标注(如3D包围盒、指代表达)。
2. DriveMonkey框架
构建基于大视觉-语言模型(LVLMs)的多任务交互式自动驾驶框架 ,通过空间处理器(Spatial Processor)与LVLM的端到端集成,实现高精度文本响应生成与3D视觉基础任务性能。
支持动态指令解析(如自然语言规划指令),并优化区域级理解(Region-level Understanding)与标记化(Token-based Localization)。
3. 细粒度3D感知与环境建模
提出融合区域到文本生成(Region-to-Text)、分割模型与图像描述模型的多模态信息聚合方法 ,增强物体属性(距离、运动状态)与场景语义的联合推理能力。
通过辅助标记(Auxiliary Tokens)与分割网络(如SAM)集成,提升3D目标定位与环境密集理解精度。
4. 模型架构优化
结合混合专家(MoE)与多模态旋转位置嵌入(M-RoPE),扩展LVLMs至视频、音频等多模态输入,支持统一任务解码(如检测、分割、生成)。
提出超链接机制 (Super Link)连接任务专用解码器与大语言模型(LLM),实现跨任务知识迁移与多模态协同。
5. 性能验证与基线提升
在3D视觉基础、密集描述等任务上显著超越现有模型(如Uni-MoE、Qwen2VL),以InternLM2.5-7B为基座模型取得SOTA性能(如BLEU-4达67.50,mAP达59.36)。
揭示当前模型在时序信息建模 与低层轨迹规划 上的局限性,为未来研究提供方向。
A Physics-informed End-to-End Occupancy Framework
论文标题:A Physics-informed End-to-End Occupancy Framework for Motion Planning of Autonomous Vehicles
论文链接:https://arxiv.org/abs/2505.07855
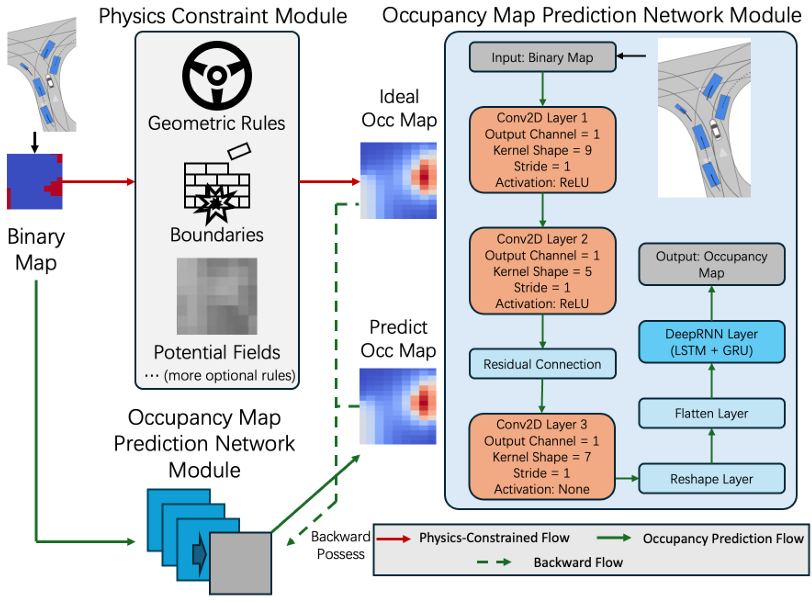
核心创新点:
1. 物理信息嵌入的端到端占位预测框架
提出了一种将物理约束(如人工势场APF)直接集成到神经网络学习过程的统一框架。通过结构化嵌入物理规则(如吸引力/排斥力模型),确保预测的占位图(occupancy maps)在数据驱动学习的基础上满足物理可行性(如碰撞规避与目标导向性),解决了传统方法依赖后处理或外部模块导致的实时性不足问题。
2. 时空特征融合的网络架构设计
构建了结合卷积神经网络(CNN)与循环神经网络(RNN)的混合架构:
CNN部分 :采用残差连接(Residual Connections)与多层卷积提取空间特征,保留输入二值地图的几何信息;
RNN部分 :融合LSTM与GRU单元捕捉动态环境中的时间依赖性,实现高精度时序预测。
3. 物理约束引导的损失函数优化引入基于APF的物理引导损失函数:
最小化预测占位图与物理理想占位图间的均方误差(MSE),实现数据与物理规则的联合优化。
4. 可扩展的物理先验模块化集成
框架支持灵活替换物理约束形式(如更换其他动力学模型),无需修改网络结构,适应不同任务需求(如复杂交通规则或动态优先级调整),提升了模型的泛化能力与实用性。
5. 实验验证性能提升
在2000个CommonRoad场景中验证,相较传统APF方法:
安全性 :任务完成率提升4.8%(0.946 vs. 0.902),平均碰撞时间(TTC)增加6.4%;
舒适性 :轨迹抖动(Jerk)降低34.2%(1.361 m/s³ vs. 2.079 m/s³);
效率 :规划时间缩短5.26倍(0.0019s vs. 0.01s),满足实时性要求。
本文均出自『自动驾驶之心知识星球』,求职招聘-技术解读-行业动态-专业问答四位一体的专业技术社区。
大额新人优惠!欢迎扫码加入~


















 2504
2504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









