



作者 | BigBite 来源 | BigBite思维随笔
原文链接:FSD V14的技术突破——ICCV Ashok技术分享解析
点击下方卡片,关注“自动驾驶之心”公众号
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
Tesla FSD V14系列推出约两周以来,已连续迭代了4个小版本,展现了快速的进化节奏。初始版本14.1在驾驶AI能力上实现了显著突破,让人初步窥见“觉醒”的驾驶AI的雏形。随后的14.1.1版本重点优化了初版存在的刹车顿挫问题;14.1.2引入了广受好评的极致高效的Mad Max模式;而14.1.3则扩大了对Model S/X车型的支持,并开始向更广泛的非KOL用户推送。这种高速的版本迭代表明,自动驾驶技术在融入其他AI领域的进展后,正进入一个加速演化的新阶段。
在14.1版本发布后不久,我曾撰写了一篇V14的初步探索文章,汇总了相关传闻和实车表现亮点。感兴趣的朋友可以点击链接FSD V14 自动驾驶AI的觉醒时刻?阅读。端到端架构下的FSD实车体验进步迅猛,但自2022年AI Day后,Tesla对其自动驾驶技术的详细进展披露甚少。在10月20日于夏威夷举办的ICCV国际计算机视觉学术会议上,Tesla AI副总裁Ashok分享了公司自动驾驶技术的最新进展,为我们解析Tesla的端到端自动驾驶理念以及V14可能整合的技术升级提供了宝贵信息。

Tesla端到端自动驾驶理念
从V12版本开始,Tesla FSD转向了全面的端到端架构,这也带动了业界对端到端技术的研究热潮。端到端本质就是马老板时常挂在嘴边的“Photon In,Control Out”,也就是从传感器像素输入到车辆控制信号(如油门、刹车)输出,都由一个宏观意义上的神经网络模型完成。该架构减少了中间规则处理环节,使得模型训练的梯度能够从输出端无缝反向传播至感知端,从而实现模型各部分的整体协同优化。以此类模型为核心的自动驾驶系统即为端到端系统。业界目睹了Tesla V12版本带来的拟人化、丝滑的驾驶体验后,纷纷加大了对端到端系统的投入。而直到此次分享,Tesla AI团队才更系统地阐释了采用端到端方案解决自动驾驶问题的核心理由。

编码人类价值判断的复杂性:Ashok现场举例说明了自动驾驶中常见的两难抉择,例如车辆在遇到路边水坑的双向单车道上,是应该稍微偏离车道绕开水坑,还是严格避免侵入对向车道?基于预设规则很难完美定义此类情境下的合理行为。而端到端系统通过大量学习人类驾驶数据,能够掌握这些细微的价值权衡,在恰当时机做出类似“借道绕行”的决策。

感知与决策规划间的接口定义难题:传统模块化自动驾驶系统中,各模块间通过预设接口通信,例如使用边界框(Bounding Box)定义车辆行人,用多段线描述车道线。但Ashok展示的FSD应对鸡、鹅等动物过马路的实拍视频表明,传统感知接口难以定义这些动物的类型、过马路意图等属性。既定接口会形成信息瓶颈,而端到端模型中神经网络间的直接信息传递,能最大程度减少这种信息损失,确保决策模块获取更全面的环境信息
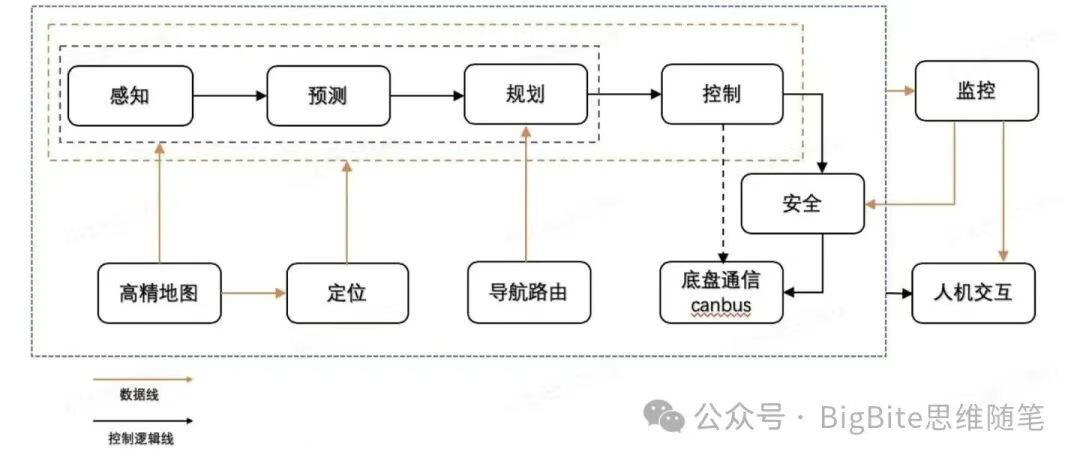
应对现实世界的长尾问题:此优势直接源于上述信息瓶颈的解决。端到端模型确保在罕见场景下,决策系统仍能基于丰富的输入信息做出合理判断,并通过学习人类驾驶行为获得处理长尾场景的能力。
同构计算带来的确定性延迟:自动驾驶系统对时延极其敏感。传统基于规则和优化的规控方案,其求解时间受环境复杂性、初始解质量等多种因素影响,难以保证稳定。而端到端神经网络具有固定的模型结构和参数量,其单帧计算延迟是确定性的,有利于控制系统的时间波动。
更好地契合AI领域的数据规模效应:端到端自动驾驶是彻底的数据驱动范式,它摒弃了大量人为设计的规则和评价指标(即Sutton在“Bitter Lesson”中提及的“人类知识”),从而能更充分地利用计算力和数据的增长来提升系统性能。
端到端自动驾驶的三大挑战
端到端模型维度诅咒


Ashok指出,一个理想的端到端模型结构看似简单:输入包括过去30秒时间窗口内以36Hz频率采集的7路500万像素摄像头视频、长达数英里的导航地图、100Hz的车速与IMU信息,甚至包括48KHz的音频信息(可能为FSD V14新增),其信息维度相当于20亿token。而输出仅为方向盘和加减速信号,约等于2个token。因此端到端系统要解决的是一个从极高维度到极低维度的映射问题,而高维到低维的映射本质上是多对一的,这个映射还要反馈正确逻辑,这就好比要从一团乱麻中要找到最终指引向出口的那唯一的一根,其训练难度可想而知。
Tesla通过强大的数据引擎(Data Engine)来应对此挑战,致力于采集大量高质量数据。Tesla车队每日可产生相当于500年驾驶时长的数据,但其中多数为常规场景。为此,Tesla采用了复杂的触发机制来回传长尾场景数据,如使用专用模型采集特殊车辆数据、基于预测偏差回传bad cases、收集所有用户接管数据,以及感知状态突变的场景。高效的数据筛选与回传机制,使得Tesla能收集海量的极端场景和主动避险数据,确保FSD模型具备极强的泛化能力。
VLA架构端到端保障可解释性和安全性
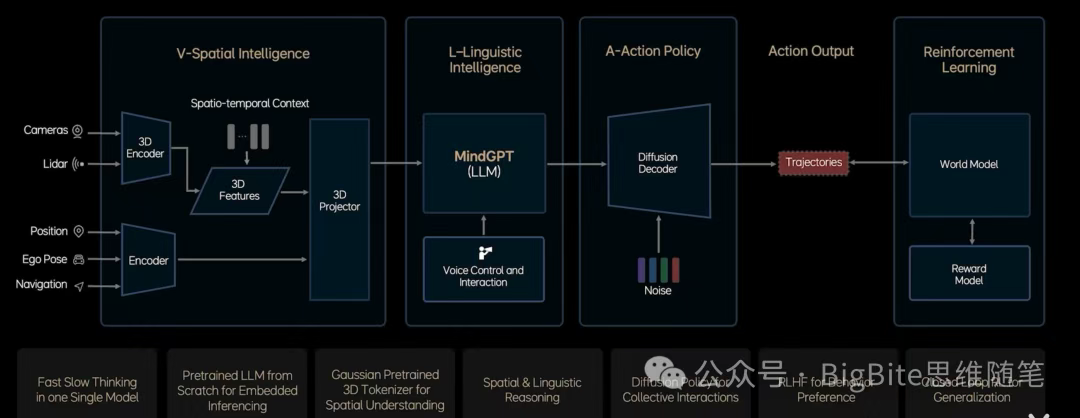
简单的端到端系统作为“黑箱”,在问题分析、行为解释和安全验证方面存在隐患。Ashok介绍说,Tesla的端到端系统并非彻头彻尾的“黑箱”系统,他看起来更加像是下图的样子。

可以看到这样的端到端系统不仅输出了下一个驾驶控制指令,还在决策规划信号前输出了很多中间结果,包括了带速度信号的3D占据网格,3D高斯特征,车辆,行人,骑行人等动态障碍物,交通信号灯,信号牌,道路边沿、车道线等静态物体,还有限速,道路属性,以及语言模式表达的决策信息。

这些中间结果信息不仅仅用于车机可视化渲染,更加可以通过条件概率,也就是大语言模型中广泛应用的思维链COT(Chain-of-Thought)形式以及过程校验手段,确保了最终输出驾驶控制信号的正确性。Tesla是强视觉方案,具备语言形式的决策输出,还有动作控制信号输出,不用说大家可能也意识到了,Tesla FSD V14很可能采用的就是基于VLA的端到端技术方案,而这一技术路线其实与国内头部自动驾驶团队不谋而合,比如理想、小鹏都在最新的智驾功能中采用了VLA为核心的技术方案。
在所有COT中间输出中,自然语言决策和3D高斯表征尤为引人注目。
1. 自然语言实现了慢系统思考

Ashok在分享中给出了一个利用快慢双系统思维中慢思考应对施工长尾场景的实际例子。在这个场景中,Tesla驾驶AI不仅通过文字识别道路封路(Road Closed)标志,还通过逻辑推理得出无法直行,并识别左侧绕行标志,最终做出左转决策,展现了逻辑推理能力在复杂决策中的关键作用。
2. Feedforward 3D Gaussian提供丰富的监督信号和空间理解能力
Ashok还在分享中展示了Tesla基于生成重建范式FeedForward 3D Gaussian,在生成效率,初始化条件,动态物体重建,还有新视角生成上都有着非常明显的优势。
这里简单介绍下3D Gaussian,它是目前在3D重建领域非常流行的一种表征方式,基本上他利用了众多具备位置信息,作用范围(协方差),以及相应颜色,透明度属性的高斯椭球体对场景进行表征,然后再利用投影关系将可微分性能良好的高斯椭球投影到图像平面进行可微分渲染,并利用渲染出来的图像与相机捕捉的真实图像差异作为监督信号对场景重建表征进行优化,最终达到照片级的逼真场景重建效果。相比点云或多边形,3D高斯表达更高效可微;相比NeRF等隐式表达,其几何信息更明确,因此3D Gaussian成为了目前自动驾驶领域最主流的场景重建表征。
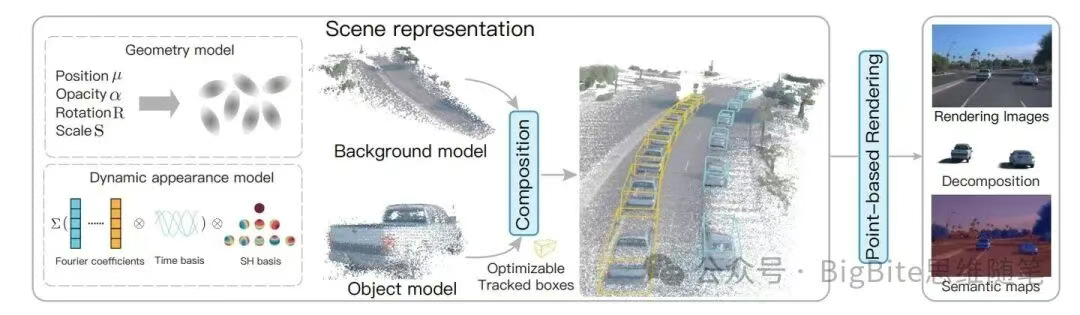
然而一般的3D场景重建需要进行逐场景优化,重建效率仍旧是比较低的。最近的一些工作则通过利用神经网络模型的泛化能力,通过重建模型的前向推理推导出场景几何信息和颜色属性,不需要点云的初始化,在重建效率上获得了极大提升,并且对于新视角生成有非常大的灵活性。从Tesla的效果上看,不仅重建过程生成了语义分割信息,还能够支持非常大的新角度渲染,这样的能力一方面解决了Tesla端到端模型训练时候单纯监督驾驶动作监督信号过于稀疏单一的问题,也确保了Tesla对周围环境的良好空间理解,类似的重建技术也支撑了Tesla实现闭环仿真系统。
评测体系是实现端到端系统的核心壁垒

Ashok本次分享的最重要的观点莫过于完善的评测体系对于端到端系统的重要性了。上面这页PPT可以说每一条信息都代表了Tesla AI团队对于端到端自动驾驶的核心认知。
无论数据集质量多高,训练Loss不能代表端到端模型性能(合理的评测指标是关键)
开环指标不能保证闭环性能(所以闭环的评测是必要的)
自动驾驶存在多种驾驶行为来避免驾驶失败,评测指标需要正确的反应这种驾驶行为的多模态性(对不起L2 Loss,你还差得远呢)
一种方法是来评估对驾驶行为结果的预测(个人理解意思是类似Maximize Reward + Imitation Loss)
一个平衡且全面的评测集非常关键(数据,核心关键还是数据)
枯燥乏味,但是告诉你个秘密,评测至关重要(都跟你说是秘密,要不要重点关注由你)
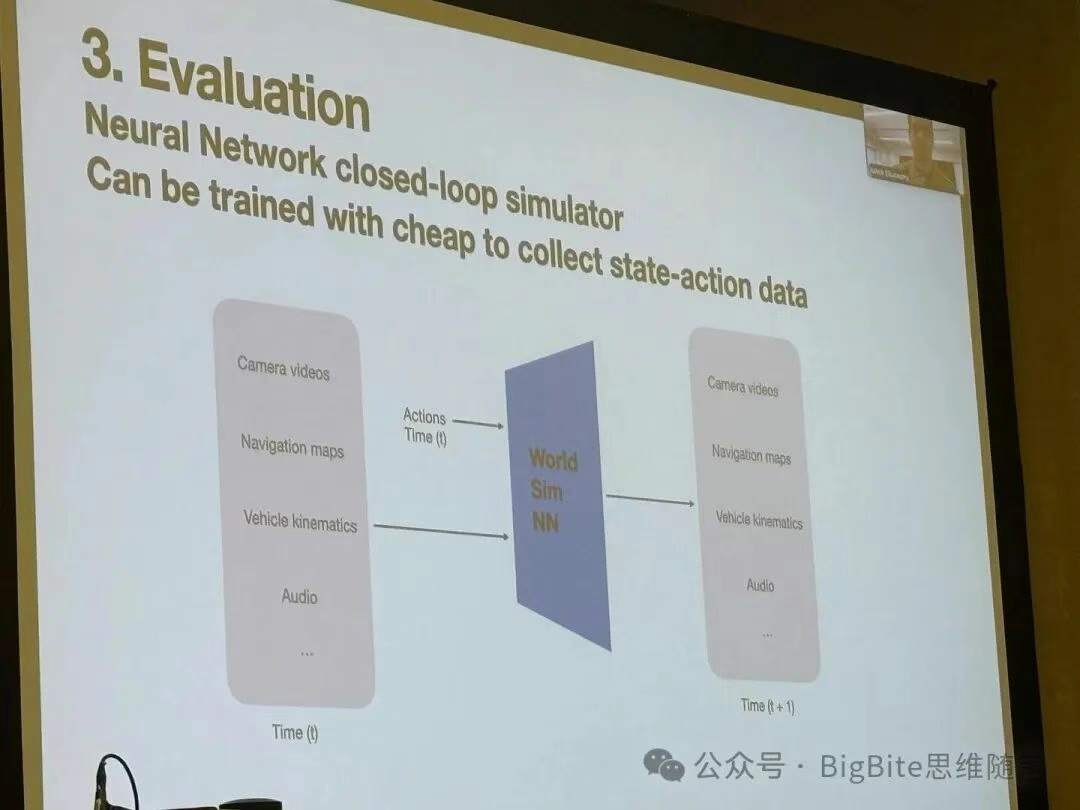
Tesla完善的评测体系中的核心就是基于神经网络的闭环仿真系统。这个仿真系统可以通过收集大量廉价的离线状态-动作数据对进行训练。Ashok展示了这样的闭环仿真系统的几大作用:
1. 利用闭环仿真验证端到端Policy的正确性
2. 利用场景编辑生成能力生成对抗样本检验模型能力
3. 利用模拟器在闭环仿真系统中获取人驾真值
从Tesla闭环仿真分享中我们可以发现Tesla的场景重建,生成,编辑能力都非常强大,不过Tesla的所有场景都是基于真实场景进行训练,编辑修改而来。我想这很好的解答了为什么无论世界模型/世界引擎多么强大,丰富多样的真实数据永远都是自动驾驶中的核心资源,因为无论多强大的世界模型,其训练数据都来自于真实数据,训练数据的多样性和质量决定世界模型的性能。而无论世界模型的性能多么强大,单纯坐在办公室的研发工程师无法想象真实世界的驾驶场景可以变得多么多样且复杂,所以最复杂的长尾场景一定是基于真实数据衍生来的,而不能无中生有。因此在自动驾驶领域,拥有众多丰富多样真实数据的车企,就是在端到端数据驱动的自动驾驶系统研发中拥有巨大的优势。
最后Tesla的强大闭环仿真引擎同样可以迁移到机器人领域,而机器人Optimus和自动驾驶FSD技术栈的统一,也为后续Cross Embodiment带来的更泛化的具身AI发展带了巨大的想象空间!
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 45
45

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









