






作者 | 的泼墨佛给克呢 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/405983694
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标跟踪】技术交流群
后台回复【目标跟踪综述】获取单目标、多目标、基于学习方法的领域综述!
介绍
多目标跟踪的评价指标有很多,本文就来详细汇总解释一下,并使用介绍了用于计算这些指标的py-motmetrics库的使用方法。由于自己刚入门MOT领域,本文只是基于自己目前的理解,如有错误请指正。在MOTChallenge中,有下面这些常用的指标:
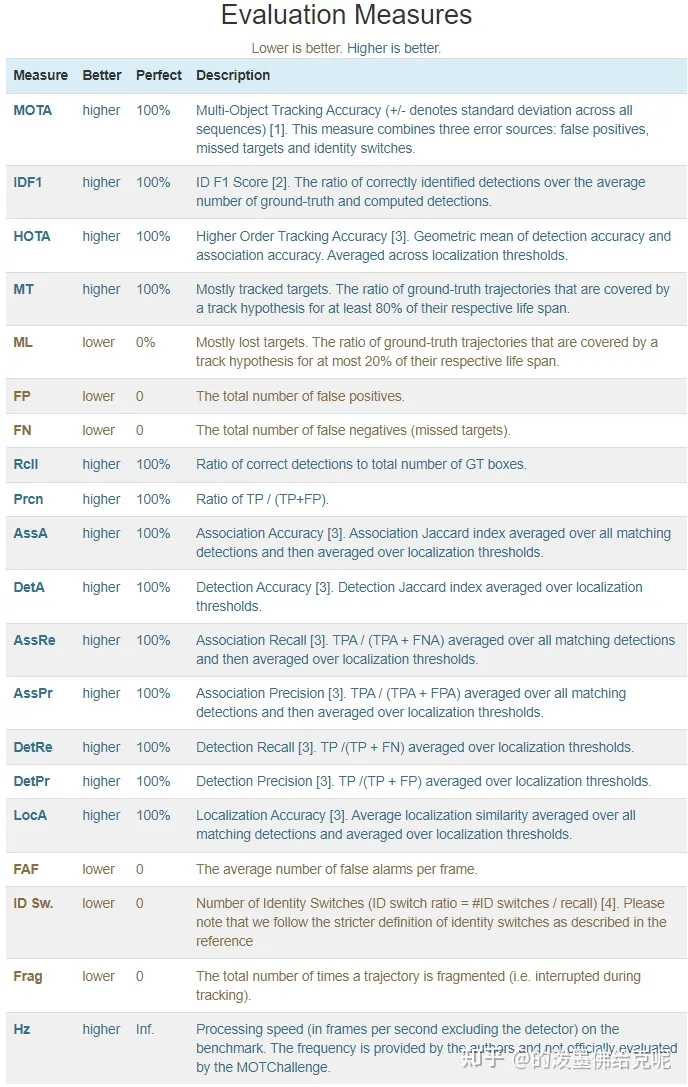
总览如下:
基础
要理解这些指标,首先回顾一下在分类和检测任务中常见的几种基本概念:
GT:Ground Truth,是指真实的标签或真实的对象
TP:真正(True Positive)是指被模型预测为正的正样本(或被检测出来的GT)
TN:真负(True Negative)是指被模型预测为负的负样本。
FP:假正(False Positive,)是指被模型预测为正的负样本,也称为误报。
FN:假负(FALSE Negative,)是指被模型预测为负的正样本,也称为漏报。
后面四个概念很容易混淆,怎么记忆呢,可以把第一个字母看成是模型是否预测正确(对T或错F),把第二个字母看成是标签(正样本P和负样本N)。这些概念在分类任务里面的含义十分清楚,在检测任务中可以用下图来帮助理解:

最左边的图中有个企鹅,而且被检测出来了,是我们希望的;中间图是背景,但也被错误地检测出来了,误报;最右边有企鹅但没有检测出来,漏报。在检测任务中TN没有啥意义,因为背景中的任何地方都可以看作是负样本,我们也不希望模型关注背景。其实在MOT中,这些概念与在检测任务中的差不多,毕竟Detection-Based Tracking(基于检测的跟踪)的第一步就是检测。
由这几个概念又可以推导出下面几个指标:
Accuracy:准确度是指被分类器判定正确的比重,这个指标就太简单了,其实就是分类正确的例子占总数的比例:
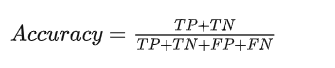
Precision:精确度是指被分类器判定的正例中真正的正例样本的比重:
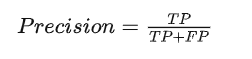
Recall:召回率是指被分类器正确判定的正例占总的正例的比重:
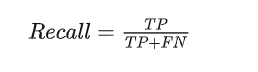
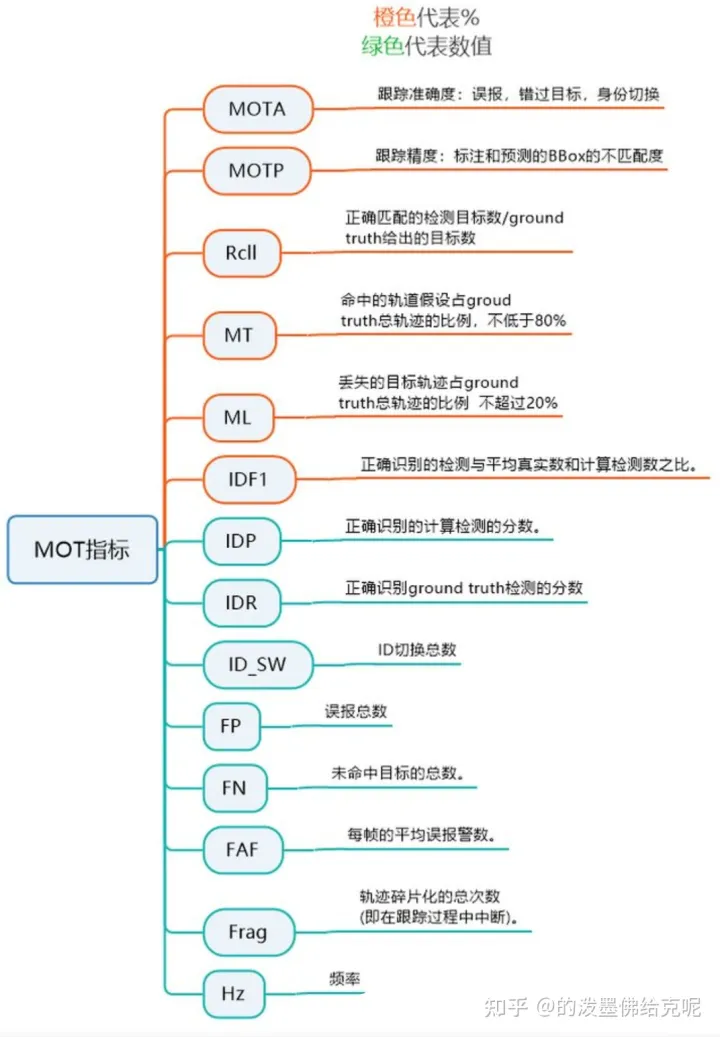
MOT指标
接下来会按时间顺序分三个种类来介绍MOT指标,我是照搬了[1]中的分类方式,感兴趣的可以看原论文。其中在MOTChallenge中出现的指标我会强调显示。
Classical metrics
MT:Mostly Tracked trajectories,成功跟踪的帧数占总帧数的80%以上的GT轨迹数量
Fragments:碎片数,成功跟踪的帧数占总帧数的80%以下的预测轨迹数量
ML:Mostly Lost trajectories,成功跟踪的帧数占总帧数的20%以下的GT轨迹数量
False trajectories:预测出来的轨迹匹配不上GT轨迹,相当于跟踪了个寂寞
ID switches:因为跟踪的每个对象都是有ID的,一个对象在整个跟踪过程中ID应该不变,但是由于跟踪算法不强大,总会出现一个对象的ID发生切换,这个指标就说明了ID切换的次数,指前一帧和后一帧中对于相同GT轨迹的预测轨迹ID发生切换,跟丢的情况不计算在ID切换中。
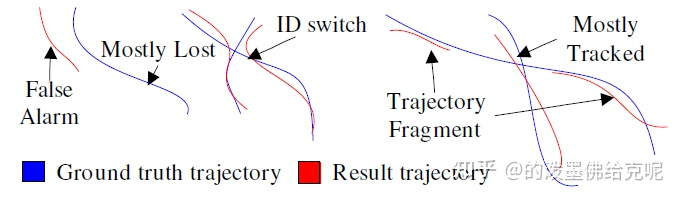
注意上图中箭头的指向,是红色线还是蓝色线。
CLEAR MOT metrics
FP:总的误报数量,即整个视频中的FP数量,即对每帧的FP数量求和
FN:总的漏报数量,即整个视频中的FN数量,即对每帧的FN数量求和
Fragm(FM):总的fragmentation数量,every time a ground truth object tracking is interrupted and later resumed is counted as a fragmentation,注意这个指标和Classical metrics中的Fragments有点不一样
IDSW:总的ID Switch数量,即整个视频中的ID Switch数量,即对每帧发生的ID Switch数量求和,这个和Classical metrics中的ID switches基本一致
MOTA:注意MOTA最大为1,由于IDSW的存在,MOTA最小可以为负无穷。
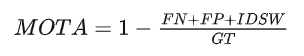
MOTP:衡量跟踪的位置误差,其中t表示第t帧, 表示第t帧中预测轨迹和GT轨迹成功匹配上的数目, 表示t帧中第i个匹配对的距离。这个距离可以用IOU或欧式距离来度量,IOU大于某阈值或欧氏距离小于某阈值视为匹配上了。可以看出来MOTP这个指标相比于评估跟踪效果,更注重检测质量。
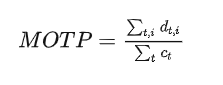
ID scores
MOTA的缺点如下图描述:
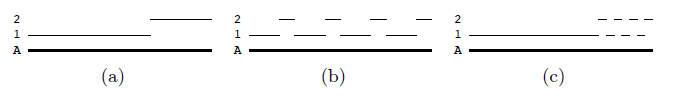
有如上三个跟踪器,对于GT轨迹A的跟踪效果如图显示。在(a)中有2个fragments,在(b)(c)中有8个。在(a)(b)中预测轨迹1占据了4/6的帧数,而在(c)中占据了5/6的帧数。由于(c)的IDSW会更多,它的MOTA指标会更低。但(c)中匹配时间要更长一些,如果我们关注跟踪时长的话,显然(c)这个跟踪器会更好一些,于是ID scores就被提出来了。总之,MOTA的主要问题是它考虑了跟踪器做出错误决定的次数,比如IDSW。而在某些情况下不想丢失跟踪对象的位置,我们更关心这个跟踪器跟踪某个对象的时间长短。因此,ID scores被提出,它们是在介绍MTMC的一篇论文中被提出的。
但目前的问题是如何将GT和预测出来的轨迹匹配上,比如(a)中为何不将GT与预测轨迹2匹配来算出正确跟踪时间是2/6 ?因此,我们希望将每一个GT与一个计算轨迹匹配起来,并最小化所有GT轨迹和计算轨迹的不匹配帧数(FP+FN的数量),可以建立一个二分匹配问题来解决。然后ID scores相关指标都基于匹配的结果来进行计算。具体的二分匹配问题如下:
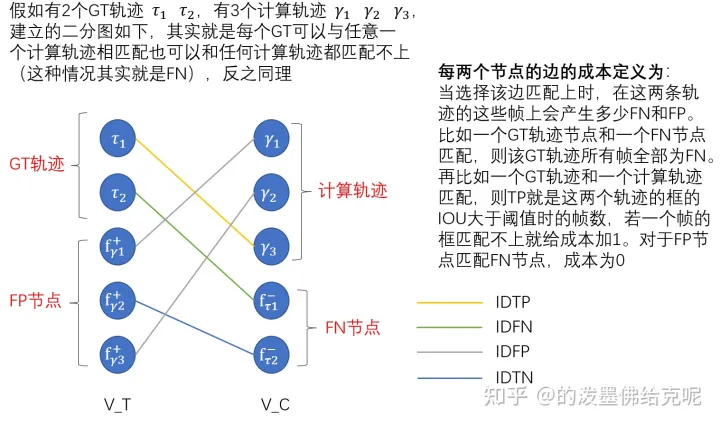
具体的举例如下

根据这几个概念又可以推导出以下三个指标,其中前两个指标的公式和前文中提到的精确度和召回率差不多
IDP:Identification precision
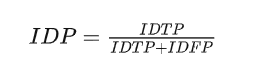
IDR:Identification recall
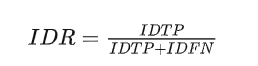
IDF1:Identification F1,是IDP和IDR的调和均值
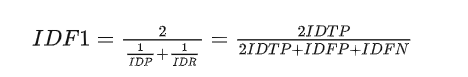
其他指标
Recall和Precision:计算公式同基础中的介绍
待补充
具体过程
MOT评价指标的计算一般分为两步:
将真实和计算的ID一一映射对应(Mapping true and computed identities)
在这种对应下计算再具体指标(Computing a score on top of the mapping)
如前文中ID scores节的介绍:第一步一般是构建一个二分图,左侧节点包含真实ID(和FP),右侧节点包含计算ID(和FN),如果两个ID对应,则边上的成本为错误分配的帧数。然后使用最小成本二分匹配寻找最佳对应。找到对应后再计算具体指标。
Clear MOT指标和ID指标的区别:
Clear MOT指标映射通常是多对多,而ID指标依赖于一对一关系。
Clear MOT的多对多映射允许存在IDSW,而ID指标中没有IDSW的概念。
当计算出的ID正确切换回其原始真实ID时(比如在遮挡后),MOTA和FRG仍会将其计为错误。
Clear MOT指标映射没有优化全局目标,而ID指标中的映射找到二分图的最优匹配,最大化IDF1。
Clear MOT指标在应用于不相交的摄像机时存在问题,因为它对每个摄像机中离开\进入的情况敏感,而ID指标不受此问题的影响,因为ID映射时全局的。
代码(py-motmetrics的使用方式)
调用别人写好的轮子,即py-motmetrics库:
https://github.com/cheind/py-motmetrics
安装方式:
pip install motmetrics
使用这个库的流程就是,先导入两个txt文件(分别是GT和自己生成的结果,且都是标准的MOTChallenge格式,具体格式在MOTChallenge网站上有详细介绍),再创建accumulator,然后逐帧将每帧的GT和自己跟踪的结果(用hypotheses表示)填充至该accumulator中,然后使用度量器计算即可得到字符串summary,里面就是计算的结果,再将summary打印出来即可。
创建accumulator并填充
首先介绍一下不导入txt文件,直接使用自己定义的数组来创建accumulator并填充
import motmetrics as mm # 导入该库
import numpy as np
metrics = list(mm.metrics.motchallenge_metrics) # 即支持的所有metrics的名字列表
"""
['idf1', 'idp', 'idr', 'recall', 'precision', 'num_unique_objects', 'mostly_tracked', 'partially_tracked', 'mostly_lost', 'num_false_positives', 'num_misses', 'num_switches', 'num_fragmentations', 'mota', 'motp', 'num_transfer', 'num_ascend', 'num_migrate']
"""
acc = mm.MOTAccumulator(auto_id=True) #创建accumulator
# 用第一帧填充该accumulator
acc.update(
[1, 2], # Ground truth objects in this frame
[1, 2, 3], # Detector hypotheses in this frame
[
[0.1, np.nan, 0.3], # Distances from object 1 to hypotheses 1, 2, 3
[0.5, 0.2, 0.3] # Distances from object 2 to hypotheses 1, 2, 3
]
)
# 查看该帧的事件
print(acc.events) # a pandas DataFrame containing all events
"""
Type OId HId D
FrameId Event
0 0 RAW 1 1 0.1
1 RAW 1 2 NaN
2 RAW 1 3 0.3
3 RAW 2 1 0.5
4 RAW 2 2 0.2
5 RAW 2 3 0.3
6 MATCH 1 1 0.1
7 MATCH 2 2 0.2
8 FP NaN 3 NaN
"""
# 只查看MOT事件,不查看RAW
print(acc.mot_events) # a pandas DataFrame containing MOT only events
"""
Type OId HId D
FrameId Event
0 6 MATCH 1 1 0.1
7 MATCH 2 2 0.2
8 FP NaN 3 NaN
"""
# 继续填充下一帧
frameid = acc.update(
[1, 2], # GT
[1], # hypotheses
[
[0.2],
[0.4]
]
)
print(acc.mot_events.loc[frameid])
"""
Type OId HId D
Event
2 MATCH 1 1 0.2
3 MISS 2 NaN NaN
"""
# 继续填充下一帧
frameid = acc.update(
[1, 2], # GT
[1, 3], # hypotheses
[
[0.6, 0.2],
[0.1, 0.6]
]
)
print(acc.mot_events.loc[frameid])
"""
Type OId HId D
Event
4 MATCH 1 1 0.6
5 SWITCH 2 3 0.6
"""再介绍一下导入txt文件来创建accumulator并填充
gt_file="/path/gt.txt"
""" 文件格式如下
1,0,1255,50,71,119,1,1,1
2,0,1254,51,71,119,1,1,1
3,0,1253,52,71,119,1,1,1
...
"""
ts_file="/path/test.txt"
""" 文件格式如下
1,1,1240.0,40.0,120.0,96.0,0.999998,-1,-1,-1
2,1,1237.0,43.0,119.0,96.0,0.999998,-1,-1,-1
3,1,1237.0,44.0,117.0,95.0,0.999998,-1,-1,-1
...
"""
gt = mm.io.loadtxt(gt_file, fmt="mot15-2D", min_confidence=1) # 读入GT
ts = mm.io.loadtxt(ts_file, fmt="mot15-2D") # 读入自己生成的跟踪结果
acc=mm.utils.compare_to_groundtruth(gt, ts, 'iou', distth=0.5) # 根据GT和自己的结果,生成accumulator,distth是距离阈值创建度量器并计算
mh = mm.metrics.create()
# 打印单个accumulator
summary = mh.compute(acc,
metrics=['num_frames', 'mota', 'motp'], # 一个list,里面装的是想打印的一些度量
name='acc') # 起个名
print(summary)
"""
num_frames mota motp
acc 3 0.5 0.34
"""
# 打印多个accumulators
summary = mh.compute_many([acc, acc.events.loc[0:1]], # 多个accumulators组成的list
metrics=['num_frames', 'mota', 'motp'],
name=['full', 'part']) # 起个名
print(summary)
"""
num_frames mota motp
full 3 0.5 0.340000
part 2 0.5 0.166667
"""将summary转为自己想要的显示格式
# 自定义显示格式
strsummary = mm.io.render_summary(
summary,
formatters={'mota' : '{:.2%}'.format}, # 将MOTA的格式改为百分数显示
namemap={'mota': 'MOTA', 'motp' : 'MOTP'} # 将列名改为大写
)
print(strsummary)
"""
num_frames MOTA MOTP
full 3 50.00% 0.340000
part 2 50.00% 0.166667
"""
# mh模块中有内置的显示格式
summary = mh.compute_many([acc, acc.events.loc[0:1]],
metrics=mm.metrics.motchallenge_metrics,
names=['full', 'part'])
strsummary = mm.io.render_summary(
summary,
formatters=mh.formatters,
namemap=mm.io.motchallenge_metric_names
)
print(strsummary)
"""
IDF1 IDP IDR Rcll Prcn GT MT PT ML FP FN IDs FM MOTA MOTP
full 83.3% 83.3% 83.3% 83.3% 83.3% 2 1 1 0 1 1 1 1 50.0% 0.340
part 75.0% 75.0% 75.0% 75.0% 75.0% 2 1 1 0 1 1 0 0 50.0% 0.167
"""总结
通常,几乎别人论文中报告的指标都是CLEAR MOT metrics中的所有指标,再加上MT、ML和IDF1。此外,跟踪器可以处理的每秒帧数(FPS)经常被报告,然而,这种度量很难在不同的算法之间进行比较,因为有些方法包括检测阶段的计算,而另一些方法跳过了该计算,而且该指标与使用的硬件有关。
附加内容(关于代码运行)
因为有很多人在评估时出了问题,因此我新建了一个github仓库,给出了一些数据格式和代码解释,也可以直接跑,结果是正常的。这个库的说明还是比较全面的,应该能解决评论区的大部分问题。如果有其他问题可以在这个库里提issue,附链接:
https://github.com/ddz16/py-motmetrics
References
DEEP LEARNING IN VIDEO MULTI-OBJECT TRACKING: A SURVEY
Multi-Target Multi-Camera Tracking评价指标
https://zhuanlan.zhihu.com/p/35391826
深入理解MOT评价指标
https://blog.csdn.net/jackzhang11/article/details/110456883
MOT Metrics—MOTA vs IDF1?
https://blog.csdn.net/qq_42191914/article/details/105057117
ID measures for Multi-Target Tracking
web.archive.org/web/20190413133409/http://vision.cs.duke.edu:80/DukeMTMC/IDmeasures.html
MOT多目标跟踪评价指标代码py-motmetrics
https://blog.csdn.net/sleepinghm/article/details/119538354
py-motmetrics官方库
GitHub - cheind/py-motmetrics: Benchmark multiple object trackers (MOT) in Python
(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、多传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









