






 本文介绍了基于Python的BaseSpider类,它是一个抽象基类,用于处理网络请求,包括设置用户代理、cookie、头部选项等。Spiders如SpiderTB继承自BaseSpider,专用于解析淘宝搜索和商品详情页面,提取商品信息并进行数据分析。
本文介绍了基于Python的BaseSpider类,它是一个抽象基类,用于处理网络请求,包括设置用户代理、cookie、头部选项等。Spiders如SpiderTB继承自BaseSpider,专用于解析淘宝搜索和商品详情页面,提取商品信息并进行数据分析。
# !/usr/bin/python3
# -*- coding:utf-8 -*-
"""
@author: JHC000abc@gmail.com
@file: base_spider.py
@time: 2024/03/20 20:56:48
@desc:
"""
import subprocess
import psutil
import random
from sdk.tools.load_env import LoadINI
from DrissionPage import WebPage, ChromiumOptions
from lxml import etree
from abc import abstractmethod, ABCMeta
class BaseSpider(metaclass=ABCMeta):
"""
"""
def __init__(self, ua, cookies, headless, incognito, timeout):
self.ua = ua
if not self.ua:
self.ua = BaseSpider.load_options_from_file("ua.list")
self.cookies = cookies
if not self.cookies:
self.cookies = BaseSpider.load_options_from_file("cookies.list")
self.urls = BaseSpider.load_options_from_file("urls.list")
self.headless = headless
self.incognito = incognito
self.timeout = timeout
self.page = None
self.init_chrome()
self.tree = None
def check_pid(self, pid_name="chrome"):
"""
:param pid_name:
:return:
"""
for process in psutil.process_iter(['pid', 'name']):
if process.info['name'] == pid_name:
return True
raise ValueError(
"Please start chrome PID with \n"
"nohup google-chrome --remote-debugging-port=9222 --remote-allow-origins=* & "
"before start this process")
def init_chrome(self):
"""
:return:
"""
# self.check_pid()
if not self.page:
co = ChromiumOptions()
co.set_argument('--window-size', '1920,1080')
co.auto_port(True)
co.headless(self.headless)
# 无痕模式
co.incognito(self.incognito)
# 忽略证书错误
co.ignore_certificate_errors(True)
co.mute(True)
co.set_timeouts(page_load=self.timeout)
if self.ua:
co.set_user_agent(user_agent=random.choice(self.ua))
self.page = WebPage()
if self.cookies:
self.page.set.cookies(random.choice(self.cookies))
return self.page
@staticmethod
def load_options_from_file(file):
"""
:param file:
:return:
"""
lis = []
with open(file, "r")as fp:
for i in fp:
lis.append(i.strip())
return lis
@classmethod
def load_options_from_config(cls, name="Spider Config"):
"""
:param name:
:return:
"""
config = LoadINI.load_ini(name)
return cls(config.get(name, "ua"), config.get(name, "cookies"), config.getboolean(name, "headless"),
config.getboolean(name, "incognito"), config.getint(name, "timeout"))
def hold_urls_all(self, main_url, feature, method=True, timeout=10):
"""
:param main_url:
:param feature:
:param method:
:param timeout:
:return:
"""
self.page.listen.start(method=method)
self.page.get(main_url)
self.page.scroll.to_bottom()
for packet in self.page.listen.steps(timeout=timeout):
for fet in feature:
if fet in packet.url:
yield {
"url": packet.url,
"response": packet.response.body,
"feature": fet
}
def hold_urls_immediately(self, main_url, feature, method=True, timeout=10):
"""
:param main_url:
:param feature:
:return:
"""
self.page.listen.start(targets=feature, method=method)
self.page.get(main_url)
packet = self.page.listen.wait(timeout=timeout)
self.page.listen.stop()
return {
"url": packet.url,
"response": packet.response.body,
"feature": packet.url
}
def init_tree(self):
"""
:return:
"""
if self.page.html:
self.tree = etree.HTML(self.page.html)
return self.tree
else:
raise ValueError("Please open at least one page before call this function")
@abstractmethod
def process(self, *args, **kwargs):
"""
:param args:
:param kwargs:
:return:
"""
# !/usr/bin/python3
# -*- coding:utf-8 -*-
"""
@author: JHC000abc@gmail.com
@file: spider_tb.py
@time: 2024/03/20 20:56:15
@desc:
"""
import re
import json
from .base_spider import BaseSpider
class SpiderTB(BaseSpider):
"""
"""
def __init__(self, ua, cookies, headless, incognito, timeout):
super(SpiderTB, self).__init__(ua, cookies, headless, incognito, timeout)
def anlise_search_page(self,search_config):
"""
:return:
"""
self.init_tree()
pages = self.tree.xpath('//div[@class="Pagination--pgWrap--kfPsaVv"]//span[@class="next-pagination-display"]//text()')
max_page = int(pages[-1].replace("/",""))
if search_config["page"] == "1":
for i in range(int(search_config["page"])+1,max_page+1):
search_pages_url = "https://s.taobao.com/search?page={}&q={}&tab=all".format(i,search_config["query"])
print(search_pages_url)
lis = self.tree.xpath('//div[@class="Content--contentInner--QVTcU0M"]/div')
for li in lis:
detail_url = li.xpath('./a/@href')
title = li.xpath('.//div[@class="Title--title--jCOPvpf "]//text()')
if detail_url and title:
detail_url = detail_url[0] if detail_url[0].startswith("https:") else f"https:{detail_url[0]}"
title = "".join(title)
yield title, detail_url
def anlise_detail_page_tb(self, res):
"""
:param res:
:return:
"""
item = res["response"]["data"]["item"]
title = item["title"]
componentsVO = res["response"]["data"]["componentsVO"]
image_list_main = componentsVO["headImageVO"]["images"]
videos_list = [i["url"] for i in componentsVO["headImageVO"]["videos"] if componentsVO["headImageVO"]["videos"]]
sku2info = res["response"]["data"]["skuCore"]["sku2info"]
sku_map = {}
for skuid, v in sku2info.items():
quantityText = v["quantityText"]
if v.get("subPrice"):
priceText = v["subPrice"]["priceText"]
else:
priceText = v["price"]["priceText"]
sku_map[skuid] = [quantityText, priceText]
color_map = {}
size_map = {}
out = []
skuBase = res["response"]["data"]["skuBase"]
if skuBase.get("props"):
for i in skuBase["props"]:
if i["name"] == "颜色分类":
for j in i["values"]:
color_map[j["vid"]] = j["name"]
elif i["name"] == "尺码":
for j in i["values"]:
size_map[j["vid"]] = j["name"]
else:
print(">>>", i["name"])
main_map = {}
skus = skuBase["skus"]
for i in skus:
_c, _z = i["propPath"].split(";")
main_map[i["skuId"]] = [_c.split(":")[1], _z.split(":")[1]]
for k, v in main_map.items():
out.append({
color_map.get(v[0]),
size_map.get(v[1]),
sku_map.get(k)[0],
sku_map.get(k)[1]
})
extension_map = {}
extensionInfoVO = res["response"]["data"]["componentsVO"]["extensionInfoVO"]
for i in extensionInfoVO["infos"]:
if i["title"] == "参数":
for j in i["items"]:
extension_map[j["title"]] = "".join(j["text"])
return {
"title": title,
"image_list_main": image_list_main,
"videos_list": videos_list,
"out": out,
"extension": extension_map,
}
def process_image_list(self, image_list):
"""
:param image_list:
:return:
"""
_img_lis = []
for i in image_list:
if i == "":
pass
elif i.startswith("http"):
_img_lis.append(i)
else:
_img_lis.append(f"https:{i}")
return _img_lis
def anlise_detail_page_images(self, res):
"""
:param res:
:return:
"""
image_list = []
response = res["response"].replace("mtopjsonp1(", "").replace("mtopjsonp2(", "")[:-1]
response = json.loads(response,strict=False)
componentData = response["data"]["components"]["componentData"]
for k, v in componentData.items():
image_list.append(v["model"].get("picUrl", ""))
image_list = self.process_image_list(image_list)
return image_list
def anlise_detail_page(self, url):
"""
:param url:
:return:
"""
features = ["https://h5api.m.taobao.com/h5/mtop.taobao.pcdetail.data.get/1.0/?jsv=2.6.1",
"https://h5api.m.taobao.com/h5/mtop.taobao.detail.getdesc/7.0/?jsv=2.7.2",
"https://h5api.m.tmall.com/h5/mtop.taobao.pcdetail.data.get/1.0/?jsv=2.6.1"
]
main_map_tb = {}
main_map_tm = {}
for res in self.hold_urls_all(url, features, method=("GET")):
if res["response"]:
if "taobao.com/h5/mtop.taobao.pcdetail.data.get/1.0/?jsv=2.6.1" in res["feature"]:
try:
main_map = self.anlise_detail_page_tb(res)
main_map_tb.update(main_map)
except Exception as e:
print(e,e.__traceback__.tb_lineno)
print("ERROR",res)
elif "taobao.com/h5/mtop.taobao.detail.getdesc/7.0/?jsv=2.7.2" in res["feature"]:
detail_image_list = self.anlise_detail_page_images(res)
main_map_tb["detail_image_list"] = detail_image_list
elif "h5api.m.tmall.com" in res["feature"]:
print("天猫")
print("main_map_tb",main_map_tb)
return main_map_tb, main_map_tm
def process(self, *args, **kwargs):
"""
:param args:
:param kwargs:
:return:
"""
with open("res.jsonl","a")as fp:
for search_url in self.urls:
self.page.get(search_url)
# https://s.taobao.com/search?page=1&q=python&tab=all
search_config = {
"page":re.findall("\?page\=(.*?)\&",search_url)[0],
"query":re.findall("\&q\=(.*?)\&tab",search_url)[0],
}
print("search_config",search_config)
for title, detail_url in self.anlise_search_page(search_config):
main_map_tb, main_map_tm = self.anlise_detail_page(detail_url)
fp.write(f"{json.dumps(main_map_tb,ensure_ascii=False)}\n")
fp.flush()
# self.page.get(detail_url)
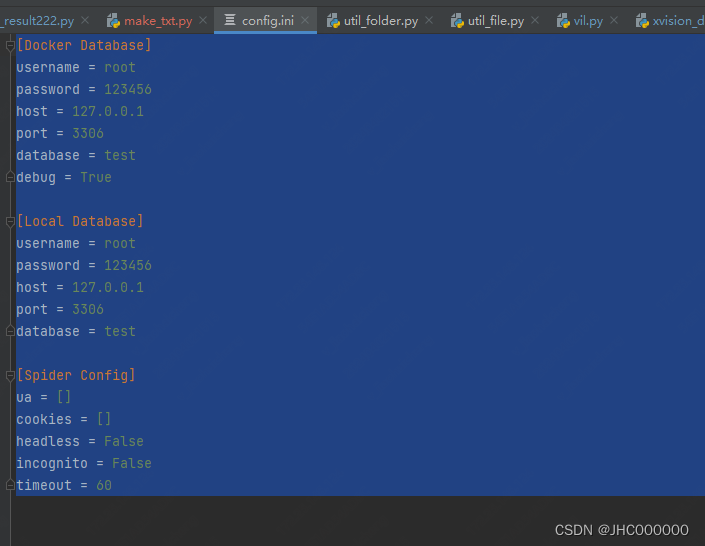
数据库部分有点多 不贴了,运行可以把数据库相关部分删掉
















 2027
2027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









