







英文标题:JEC-QA: A Legal-Domain Question Answering Dataset
中文标题:法律领域问答数据集
论文下载:arxiv@1911.12011
项目地址:GitHub@CAIL2021
比赛链接:CAIL2021@司法考试
序言
本论文是关于中国法律智能技术评测 2021 2021 2021比赛中司法考试任务数据集的构成与一些测试模型的评估。在上面的项目地址GitHub@CAIL2021中已有测试模型,但是它完全没有应用到数据集中给到的参考书目文档,笔者在阅读本论文前认为参考书目文档可能可以用于数据增强,或用于构建知识图谱以预训练得到更好的题干及选项的语义表示。诸多尝试后,笔者决定还是先参考原作者已完成的工作,事实上原作者是将司法考试任务视为阅读理解任务来评估的,其中使用到 ElasticSearch \text{ElasticSearch} ElasticSearch检索以及多级推理等技术,这意味着该任务的解决思路将会十分开阔,但是该任务本身的困难程度是非常高的,因为目前机器做题的成绩远远差于普通人类的水平。
笔者建议对该任务感兴趣的朋友可以先阅读本文以熟悉前人的解决思路,然后再加以改进并测试。项目地址GitHub@CAIL2021中的基线模型的正确率大约为 26 % 26\% 26%,这已经足以通过该评测任务第一阶段的测试了。
其实这个任务目前也没有多少队伍在做,笔者只是对这个话题非常感兴趣,所以花了一些功夫。个人觉得对参考书目文档的预处理是非常重要的,其中有许多冗余的信息,然后数据集中的subject字段是存在缺失的,而这个字段其实对信息检索是非常有帮助的,所以需要额外训练模型对该字段进行预测,这个笔者之前也想到了,在本论文中原作者也强调了这一点的必要性。
文章目录
- 序言
- 摘要 Abstract \text{Abstract} Abstract
- 1 1 1 引入 Introduction \text{Introduction} Introduction
- 2 2 2 相关工作 Related Work \text{Related Work} Related Work
- 3 3 3 数据集构成与分析 Dataset Construction and Analysis \text{Dataset Construction and Analysis} Dataset Construction and Analysis
- 4 4 4 实验 Experiments \text{Experiments} Experiments
- 4.1 4.1 4.1 检索策略 Retrieve Strategy \text{Retrieve Strategy} Retrieve Strategy
- 4.2 4.2 4.2 实验配置 Experiment Settings \text{Experiment Settings} Experiment Settings
- 4.3 4.3 4.3 基线 Baselines \text{Baselines} Baselines
- 4.4 4.4 4.4 实验结果 Experimental Results \text{Experimental Results} Experimental Results
- 4.5 4.5 4.5 比较分析 Comparative Analysis \text{Comparative Analysis} Comparative Analysis
- 4.6 4.6 4.6 案例分析 Case Study \text{Case Study} Case Study
- 5 5 5 结论 Conclusion \text{Conclusion} Conclusion
- 6 6 6 致谢 Acknowledgements \text{Acknowledgements} Acknowledgements
- 附录 A \text{A} A:参考文献
- 后记
摘要 Abstract \text{Abstract} Abstract
-
本文提出目前规模最大的法律领域问答数据集 JEC-QA \text{JEC-QA} JEC-QA,数据源为中国国家司法考试(National Judicial Examination of China,下简称为 NJEC \text{NJEC} NJEC)真题,每年 NJEC \text{NJEC} NJEC的通过率约为 10 % 10\% 10%。
-
司法考试中通常需要检索相关法条以完成答题,这属于逻辑推理的过程,因此常规的问答模型在 JEC-QA \text{JEC-QA} JEC-QA数据集上的表现并不是很好,最先进的问答模型也只能取得 28 % 28\% 28%的正确率,而专业人员平均能够达到 81 % 81\% 81%的正确率,即便是非专业人员稍加训练一般也能达到 64 % 64\% 64%的正确率,因此人类与机器在司法考试任务上的表现差异巨大。
-
JEC-QA \text{JEC-QA} JEC-QA数据集可以从官网获得:该数据集需要发送邮件向原作者申请获得,如果急需使用的可以通过笔者分享的链接下载👇
链接: https://pan.baidu.com/s/1vDvklLaFFqNtT7T9-mZ0iw 提取码: s3u5此外, JEC-QA \text{JEC-QA} JEC-QA比CAIL2021@司法考试提供的数据集更加完整,两者训练集完全相同,但 JEC-QA \text{JEC-QA} JEC-QA中额外提供测试集与法学参考教材的文档数据。
1 1 1 引入 Introduction \text{Introduction} Introduction
-
法律问答(Legal Question Answering,下简称为 LQA \text{LQA} LQA)旨在为法律问题提供解释,建议以及解决方案。合格的 LQA \text{LQA} LQA系统不仅可以为非专业人员提供专业咨询服务,而且还能帮助专业人员提高工作效率(如更加准确地分析真实案件)。
-
LQA \text{LQA} LQA的两大难点:
① 高质量的 LQA \text{LQA} LQA训练数据集稀缺;
② 法律领域的案例与问题都是复杂且细致的;
-
大部分 LQA \text{LQA} LQA问题可以划分为两种典型的类别,如Table 1所示:

① 知识驱动的(knowledge-driven,下简称为 KD \text{KD} KD)问题:理解特定法律概念;
② 案例分析的(case-analysis,下简称为 CA \text{CA} CA)问题:分析真实案件;
两类问题都要求模型具有复杂推理能力与文本理解能力,因此 LQA \text{LQA} LQA是自然语言处理中非常困难的任务。
-
JEC-QA \text{JEC-QA} JEC-QA数据集概述:
① 数据集中共计 26365 26365 26365条多项选择题,每条选择题包含 4 4 4个选项,规模是参考文献 [ 23 ] [23] [23]中数据集的 50 50 50倍;
② 数据集中包含一套全国统一法律职业资格考试辅导书和中国法律规定构成的参考书目文档(详见 JEC-QA \text{JEC-QA} JEC-QA数据集中 reference_book \text{reference\_book} reference_book目录下的内容);
③ 数据集中标注了部分问题所属的 KD \text{KD} KD和 CA \text{CA} CA类别,以及问题所属的法律类型(如属于国际经济法问题,刑法问题等),如何由专家提供的额外标签对 LQA \text{LQA} LQA的深度分析是很有帮助的;
-
原作者可能是希望我们从 JEC-QA \text{JEC-QA} JEC-QA的参考书目中检索相关文档,再使用阅读理解模型来回答相关问题,其中又涉及单词匹配(word matching),概念理解(concept understanding),数词分析(numerical analyis),多段落阅读(multi-paragraph reading),多级推理(multi-hop reasoning)等技术。
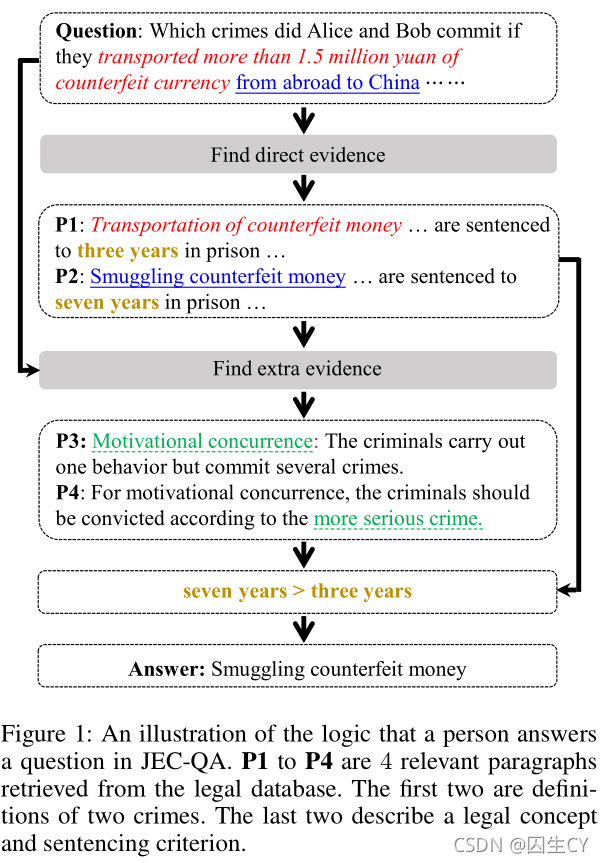
以Figure 1为例,图中描述的是一种犯罪行为导致两种不同的犯罪类型,要求模型必须理解Motivational Concurrence并推理出除单词级别的语义匹配(lexical-level semantic matching)外的其他证据。此外,模型需要通过多段落阅读与多级推理来结合直接证据和其他证据来回答问题,数词分析需要被用来比较哪一种犯罪行为是更加严重的。
-
本文设计了统一的问答架构并实现了 7 7 7种代表性的神经阅读理解模型,通过将这些方法在 JEC-QA \text{JEC-QA} JEC-QA数据集上进行测试,发现最好的方法也只能取得大约 25 % 25\% 25%和 29 % 29\% 29%的正确率(分别在 KD \text{KD} KD和 CA \text{CA} CA问题类别上),该水平远远低于人类的表现。实验结果表明现存的问答方法无法在 JEC-QA \text{JEC-QA} JEC-QA上进行复杂的多级推理,并且难以理解法律概念。
2 2 2 相关工作 Related Work \text{Related Work} Related Work
2.1 2.1 2.1 阅读理解 Reading Comprehension \text{Reading Comprehension} Reading Comprehension
-
阅读理解数据集(近十年内提出):
① 相对早期的数据集( 2013 2013 2013至 2016 2016 2016年):基于以下数据集,参考文献 [ 11 , 42 , 43 , 52 ] [11,42,43,52] [11,42,43,52]中都提出了不同的深度阅读理解模型并取得很好的评估结果。
-
CNN/DailyMail \text{CNN/DailyMail} CNN/DailyMail:参考文献 [ 17 ] [17] [17]
-
MCTest \text{MCTest} MCTest:参考文献 [ 35 ] [35] [35]
-
SQuAD \text{SQuAD} SQuAD:参考文献 [ 33 ] [33] [33]
-
WikiQA \text{WikiQA} WikiQA:参考文献 [ 50 ] [50] [50]
-
NewsQA \text{NewsQA} NewsQA:参考文献 [ 39 ] [39] [39]
② 回答问题涉及概括多篇不同文本的数据集( 2016 2016 2016至 2017 2017 2017年):基于以下数据集,参考文献 [ 07 , 44 , 45 , 47 ] [07,44,45,47] [07,44,45,47]提出汇总多文本信息的技术。
-
TrivialQA \text{TrivialQA} TrivialQA:参考文献 [ 21 ] [21] [21]
-
MS-MARCO \text{MS-MARCO} MS-MARCO:参考文献 [ 31 ] [31] [31]
-
DuReader \text{DuReader} DuReader:参考文献 [ 16 ] [16] [16]
③ 回答问题涉及逻辑推理的数据集( 2017 2017 2017至 2018 2018 2018年):目前依然缺乏具有逻辑推理能力的阅读理解模型。
-
RACE \text{RACE} RACE:参考文献 [ 28 ] [28] [28]
-
HotpotQA \text{HotpotQA} HotpotQA:参考文献 [ 49 ] [49] [49]
-
ARC \text{ARC} ARC:参考文献 [ 07 ] [07] [07]
-
2.2 \text{2.2} 2.2 开放领域问答 Open-domain Question Answering \text{Open-domain Question Answering} Open-domain Question Answering
-
开放领域问答(下简称为 OpenQA \text{OpenQA} OpenQA)的概念在参考文献 [ 14 ] [14] [14]种首次提出,其旨在借助外部知识库来回答问题,早期的研究一般借助人工收集的知识文档(参考文献 [ 03 , 27 , 41 ] [03,27,41] [03,27,41]),近年来多借助结构化的知识库(参考文献 [ 01 , 02 , 53 ] [01,02,53] [01,02,53])。
-
OpenQA \text{OpenQA} OpenQA模型的设计一般分为两部分,首先阅读可供检索的材料,然后进行答案的选择或挖掘。若没有文档级别的标注信息,一般需要借助无监督的信息检索方法,如 TF-IDF \text{TF-IDF} TF-IDF或 BM25 \text{BM25} BM25检索算法,但是这些方法一般只能处理文档与问题间单词级别的相似度,而难以挖掘出两者语义上的关联性。
因此近期的方法(参考文献 [ 07 , 29 , 46 ] [07,29,46] [07,29,46])都是首先对文档重排序以过滤掉噪声内容,尽管这些方法已经在某些场景下取得了超越人类水平的性能,但是他们依然缺乏推理能力。
2.3 2.3 2.3 法律智能 Legal Intelligence \text{Legal Intelligence} Legal Intelligence
-
参考文献 [ 51 ] [51] [51]:生成法庭意见(generating court views)来解释判决结果(interpret charge results)。
-
参考文献 [ 06 , 32 ] [06,32] [06,32]:检索相关或类似的案件。
-
参考文献 [ 15 , 18 , 30 , 37 , 48 , 55 ] [15,18,30,37,48,55] [15,18,30,37,48,55]:预测判决结果以及确定适用条款(applicable articles)。
-
参考文献 [ 12 , 13 , 23 , 24 ] [12,13,23,24] [12,13,23,24]:法律问答竞赛及相关研究成果。
-
尽管如此,可用的 LQA \text{LQA} LQA系统依然很遥远。
3 3 3 数据集构成与分析 Dataset Construction and Analysis \text{Dataset Construction and Analysis} Dataset Construction and Analysis
3.1 3.1 3.1 数据集构成 Dataset Construction \text{Dataset Construction} Dataset Construction
- 如前文所述, JEC-QA \text{JEC-QA} JEC-QA数据集中包含题库和参考书目文档两部分内容。
-
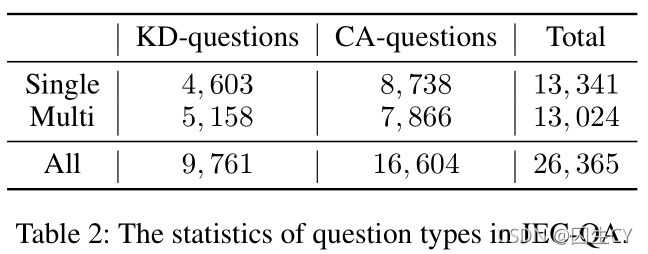
题库:题库中共计 2700 2700 2700条多项选择题(数据源为 2009 2009 2009年至 2017 2017 2017年 NJEC \text{NJEC} NJEC真题)与 30371 30371 30371条来自各类考试网站的练习题,去重后剩余 26365 26365 26365条题目构成 JEC-QA \text{JEC-QA} JEC-QA的题库。
笔者注:笔者在本博客摘要章节提供了数据集的下载链接,题库由 JSON \text{JSON} JSON数据形式构成,每个问题包含六个字段,如下所示:
字段名称 字段描述 样本示例 statement题干内容 "宪法的基本原则主要有"option_list问题选项 {"A": "人民主权原则", "B": "基本人权原则", "C": "权力制约原则", "D": "法治原则"}answer问题答案 ["A", "B", "C", "D"]id问题编号 "2_1211"subject问题所属法律类型
本字段存在缺失,训练集上 21072 21072 21072条题目中有 13254 13254 13254条缺失该字段,测试集上 5289 5289 5289条题目全部缺失该字段"宪法"type表示问题属于 KD \text{KD} KD类别(记为 0 0 0)或 CA \text{CA} CA类别(记为 1 1 1) "0"题库的统计信息可见Table 2:
-
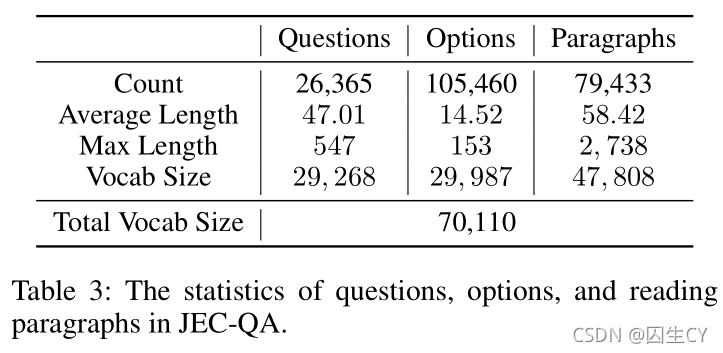
参考书目文档:参考书目文档由司法考试辅导书和法律规定构成,共计 15 15 15个专题, 215 215 215个章节的考试内容提要, 3382 3382 3382条法律规定。
注意这部分文档并非利用 OCR \text{OCR} OCR技术图像转文字得到,而是确实地耗费人工手动转成电子版本,文档段落已做好划分。
参考书目的统计信息可见Table 3:
3.2 3.2 3.2 推理类型 Reasoning Types \text{Reasoning Types} Reasoning Types
-
本文总结了 5 5 5种不同的推理类型用于解答 JEC-QA \text{JEC-QA} JEC-QA中的问题,示例详见Table 4:
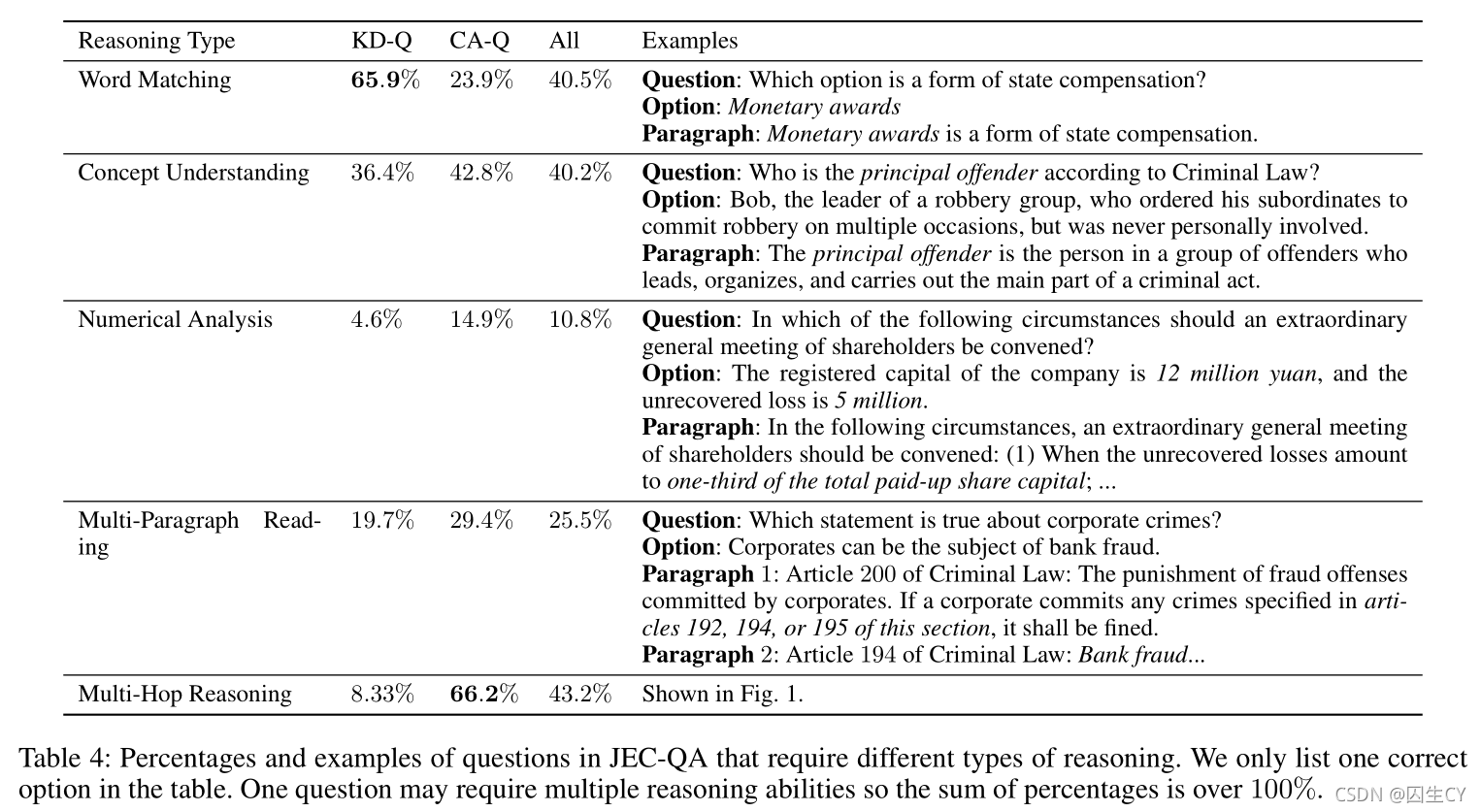
① 单词匹配(word matching):通过单词级别的匹配度确定相关性最高的文档段落,并从中检索有助于解题的信息;
② 概念理解(concept understanding):法律领域存在大量专有名词,如Table 4示例中模型需要理解的principal offender的含义;
③ 数词分析(numerical analyis):量刑标准通常涉及简单的数字运算,如Table 4示例中的模型需要得出 12 × 1 3 = 4 < 5 12\times\frac13=4<5 12×31=4<5的证明结论;
④ 多段落阅读(multi-paragraph reading):综合不同段落的文档推导出问题答案;
⑤ 多级推理(multi-hop reasoning):从Table 4可以发现, 66 % 66\% 66%的 CA \text{CA} CA问题需要多级推理能力;
笔者注:多级推理是目前NLP中非常热门的话题,以multi-hop或reason为关键词检索ACL或EMNLP近两年收录的论文中可以寻得大量相关内容,笔者已知的方法如通过树形证明图来构建逻辑推理的过程,这类任务往往不仅要求得到正确的答案,并且需要给出推导出答案的证据(即证明过程),而图的构建往往会涉及算法分析以及运筹规划的方法,论文链接如下:
- 论文标题:PRover: Proof Generation for Interpretable Reasoning over Rules
- 中文标题:通过在规则上进行可解释的推理生成证明过程
- 论文下载地址: 2020.emnlp-main.9 \text{2020.emnlp-main.9} 2020.emnlp-main.9
- 论文项目地址: GitHub@PRover \text{GitHub@PRover} GitHub@PRover
@inproceedings{saha2020prover, title={{PR}over: Proof Generation for Interpretable Reasoning over Rules}, author={Saha, Swarnadeep and Ghosh, Sayan and Srivastava, Shashank and Bansal, Mohit}, booktitle={EMNLP}, year={2020} }
4 4 4 实验 Experiments \text{Experiments} Experiments
- 本文主要实现了 OpenQA \text{OpenQA} OpenQA方法框架并在 JEC-QA \text{JEC-QA} JEC-QA数据集上评估模型性能。
- OpenQA \text{OpenQA} OpenQA方法框架的解题思路分为两步:首先检索相关段落,然后再使用解题模型给出答案。
4.1 4.1 4.1 检索策略 Retrieve Strategy \text{Retrieve Strategy} Retrieve Strategy
-
本文使用 ElasticSearch \text{ElasticSearch} ElasticSearch(笔者编写的 ElasticSearch6 \text{ElasticSearch6} ElasticSearch6简易教程)对参考书目文档进行检索,注意参考书目文档的层次架构是比较清晰的,因此直接将内容存入 ElasticSearch \text{ElasticSearch} ElasticSearch搜索引擎即可(需要标注章节标题和其他标签),此外问题的每个选项都需要分别检索,因为它们往往指向完全不同的文档内容。
-
本文为了缩小检索范围并降低噪声数据带来的影响,需要首先确定问题所属的法律类型(即题库中的
subject字段,经过观察发现该字段一共包含 15 15 15种不同的类型,刚好可以与参考书目文档的 15 15 15个专题相匹配)。这里原作者测试了三种典型模型:① BERT \text{BERT} BERT(参考文献 [ 10 ] [10] [10])
② TextCNN \text{TextCNN} TextCNN(参考文献 [ 25 ] [25] [25])
③ DPCNN \text{DPCNN} DPCNN(参考文献 [ 20 ] [20] [20])
在问题所属法律类型预测上的性能,实验结果如Table 5所示:
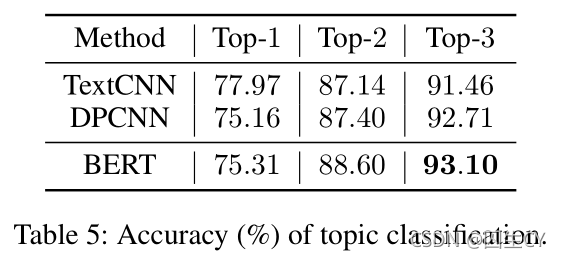
实验结果显示,平均而言 BERT \text{BERT} BERT表现出最好的预测性能,因此本文采用 BERT \text{BERT} BERT作为话题分类器(topic classifier),选取与题目相关度最高的 2 2 2个法律类型下的文档进行检索,并从中分别检索出 K K K个相关度最高的段落用于解题,另外还将从法律法规文档中检索 K K K个相关度最高的段落,共计检索出 3 K 3K 3K个段落。本文设定超参数 K = 6 K=6 K=6用于实验评估(原因详见 4.5 4.5 4.5节中的比较分析)。
-
本文为了评估检索策略的性能,随机选取 377 377 377个问题进行人工标注,每个问题标注 3 3 3种标签之一:
① All Hit \text{All Hit} All Hit(下简称为 AH \text{AH} AH):即每个相关段落都被成功检索出来;
② Partial Miss \text{Partial Miss} Partial Miss(下简称为 PM \text{PM} PM):即部分相关段落未能检索出来;
③ All Miss \text{All Miss} All Miss(下简称为 AM \text{AM} AM)即所有相关段落都未能检索出来;
评估结果如Table 6所示:
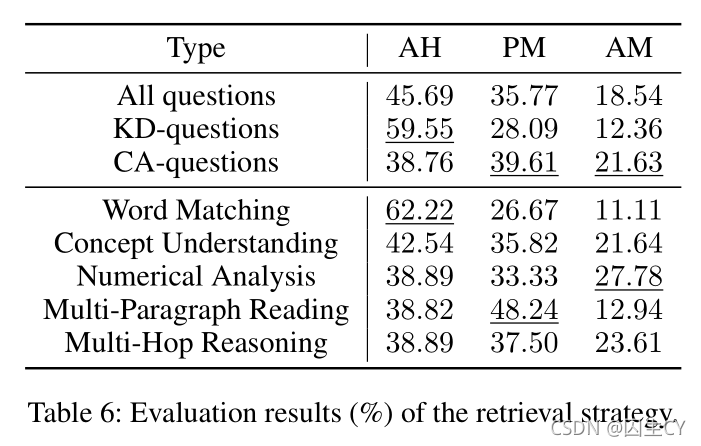
实验结果显示,大约 46 % 46\% 46%的问题都可以根据检索得到的材料正确地被作答, KD \text{KD} KD问题的命中率显著高于 CA \text{CA} CA问题,因为前者通常与特定的概念相关联,因此可以更容易地进行检索。
4.2 4.2 4.2 实验配置 Experiment Settings \text{Experiment Settings} Experiment Settings
-
本文采用控制变量法在各种问答模型上进行比较实验,采用 fastText \text{fastText} fastText方法(参考文献 [ 22 ] [22] [22])在大规模法律领域语料集上预训练词向量,所有模型的词向量维度都是 w = 200 w=200 w=200,隐层节点数量为 d = 256 d=256 d=256
-
本文设计的统一问答架构说明:
① 框架的输入为三元组 ( q , o , r ) (q,o,r) (q,o,r),分别表示题干,选项和检索得到的段落:
- q = ( q 1 , q 2 , . . . , q ∣ q ∣ ) q=(q_1,q_2,...,q_{|q|}) q=(q1,q2,...,q∣q∣)是经过分词处理后的单词序列;
- o = ( ( o 1 , 1 , o 1 , 2 , . . . , o 1 , ∣ o 1 ∣ ) , . . . , ( o n , 1 , o n , 2 , . . . , o n , ∣ o 1 ∣ ) o=((o_{1,1},o_{1,2},...,o_{1,|o_1|}),...,(o_{n,1},o_{n,2},...,o_{n,|o_1|}) o=((o1,1,o1,2,...,o1,∣o1∣),...,(on,1,on,2,...,on,∣o1∣)是经过分词处理后的选项序列,在本题库的背景下 n n n恒等于 4 4 4,即问题选项数量总是为 4 4 4个;
- 假设每个选项检索得到 m = 3 K = 18 m=3K=18 m=3K=18个相关段落, r i , j r_{i,j} ri,j表示第 i i i个选项的第 j j j个段落,即有 r i , j = ( r i , j , 1 , r i , j , 2 , . . . , r i , j , ∣ r i , j ∣ ) r_{i,j}=(r_{i,j,1},r_{i,j,2},...,r_{i,j,|r_{i,j}|}) ri,j=(ri,j,1,ri,j,2,...,ri,j,∣ri,j∣),其中 1 ≤ i ≤ n , 1 ≤ j ≤ m 1\le i\le n,1\le j\le m 1≤i≤n,1≤j≤m;
② 框架的输出分为两种不同的任务:
- 对于单选题而言,本质是一个 4 4 4分类问题,因此输出即为 score s i n g l e ∈ R n \text{score}^{\rm single}\in\R^n scoresingle∈Rn,表示每个选项正确的概率;
- 对于多选题而言,所有可能的输出结果就是 2 n − 1 2^n-1 2n−1种不同的情况,因此输出即为 score m u l t i ∈ R 2 n − 1 \text{score}^{\rm multi}\in\R^{2^n-1} scoremulti∈R2n−1,表示每种选项组合正确的概率;
- 笔者注:其实这是一件很有趣的问题,官方提供的示例代码中选择将四个选项分别表示为 1 , 2 , 4 , 8 1,2,4,8 1,2,4,8,然后加和得到对应的答案标签值,这类似于 Linux \text{Linux} Linux中权限设置指令 umask \text{umask} umask的语法逻辑。可能有人会问为什么不直接输出一个 4 4 4维向量(表示每个选项正确的概率),然后设定一个概率阈值来筛选出多选题的答案不就完事了,感觉上似乎也是可行且更加合理,而且更加容易实现,但是原作者的观点是这样的效果显然会稍差于输出 15 15 15维向量,而且事实上是很难通过传统的多分类激活函数 SoftMax \text{SoftMax} SoftMax来实现的,因为本质上其实是需要做 4 4 4次二分类。
-
考虑到部分问答模型无法适用于上述的方法框架,本文对这些方法做了一些调整:
- 若原模型只接受题干和检索段落作为输入(即不输入问题选项),则将题干和每个选项分别拼接后输入原模型,原模型将会输出第 i i i个选项的得分 s i s_i si,如此输入 4 4 4次即可得到所有选项的得分向量,相当于把选择题当成 4 4 4个判断题来解答。
- 若原模型是设计用于从检索段落中挖掘答案的句子,则将模型的输出层修改为一个线性层,使得能够输出每个选项的得分(这个笔者没有搞明白是什么意思,猜测可能是将选项添加到检索段落中去,然后得到选项的得分)。
- 若原模型是设计用于多段落阅读理解任务,则将模型分别应用于问题的每个选项对应的 m = 3 K = 18 m=3K=18 m=3K=18个检索段落,原模型将会针对第 i i i个选项的第 j j j个段落输出隐层表示 h i , j ∈ R d h_{i,j}\in\R^d hi,j∈Rd,然后对同一选项的所有隐层表示进行最大值池化(max-pooling),从而获得第 i i i个选项的隐层表示 h i ′ = [ h i , 1 ′ , h i , 2 ′ , . . . , h i , d ′ ] h_i'=[h_{i,1}',h_{i,2}',...,h_{i,d}'] hi′=[hi,1′,hi,2′,...,hi,d′],其中 h i , j ′ = max ( h i , k ∣ ∀ 1 ≤ k ≤ m ) h_{i,j}'=\max(h_{i,k}|\forall 1\le k\le m) hi,j′=max(hi,k∣∀1≤k≤m),最后将 h i ′ h_i' hi′输出到线性层以获得第 i i i个选项的得分。
- 大部分原模型都是针对单选题的,对于多选题而言,在 score s i n g l e \text{score}^{\rm single} scoresingle后面添加一个线性层(从 4 4 4维映射到 15 15 15维)即可得到多选题的向量值 score m u l t i \text{score}^{\rm multi} scoremulti,其实笔者觉得这个做法不太说得通的,个人觉得不如人工设定阈值更加合理,我想可能说 [ 0 , 0 , 0 , 1 ] [0,0,0,1] [0,0,0,1]和 [ 0.2 , 0.2 , 0.2 , 0.4 ] [0.2,0.2,0.2,0.4] [0.2,0.2,0.2,0.4]所代表的单选题答案都是 D \rm D D,但是显然它们在同一个线性层权重下大概率指向完全不同的多选题的选项组合。
-
本文使用的优化器为 Adam \text{Adam} Adam(参考文献 [ 26 ] [26] [26]),特别地对 BERT \text{BERT} BERT模型使用 BertAdam \text{BertAdam} BertAdam优化器(参考文献 [ 10 ] [10] [10])。
-
本文划分 20 % 20\% 20%的数据作为测试集。
4.3 4.3 4.3 基线 Baselines \text{Baselines} Baselines
-
本文使用的 7 7 7个代表性的阅读理解问答基线模型:
模型 参考文献 模型特点 Co-matching \text{Co-matching} Co-matching [ 44 ] [44] [44] 在 RACE \text{RACE} RACE数据集上取得好的效果 BERT \text{BERT} BERT [ 10 ] [10] [10] 主流模型,研究主要在 SQUAD \text{SQUAD} SQUAD数据集 SeaReader \text{SeaReader} SeaReader [ 54 ] [54] [54] 原作者在医药领域训练的问答模型 Multi-Matching \text{Multi-Matching} Multi-Matching [ 38 ] [38] [38] 提出Evidence-Answer模块和Question-Passage-Answer模块 CSA \text{CSA} CSA [ 05 ] [05] [05] Convolutional Spatial Attention,创新的注意力机制与文档级表示 CBM \text{CBM} CBM [ 07 ] [07] [07] Confidence-based Model,用于多段落阅读理解任务 DSQA \text{DSQA} DSQA [ 29 ] [29] [29] Distantly Supervised Question Answering,开放领域问答模型
4.4 4.4 4.4 实验结果 Experimental Results \text{Experimental Results} Experimental Results
-
实验结果详见Table 7:
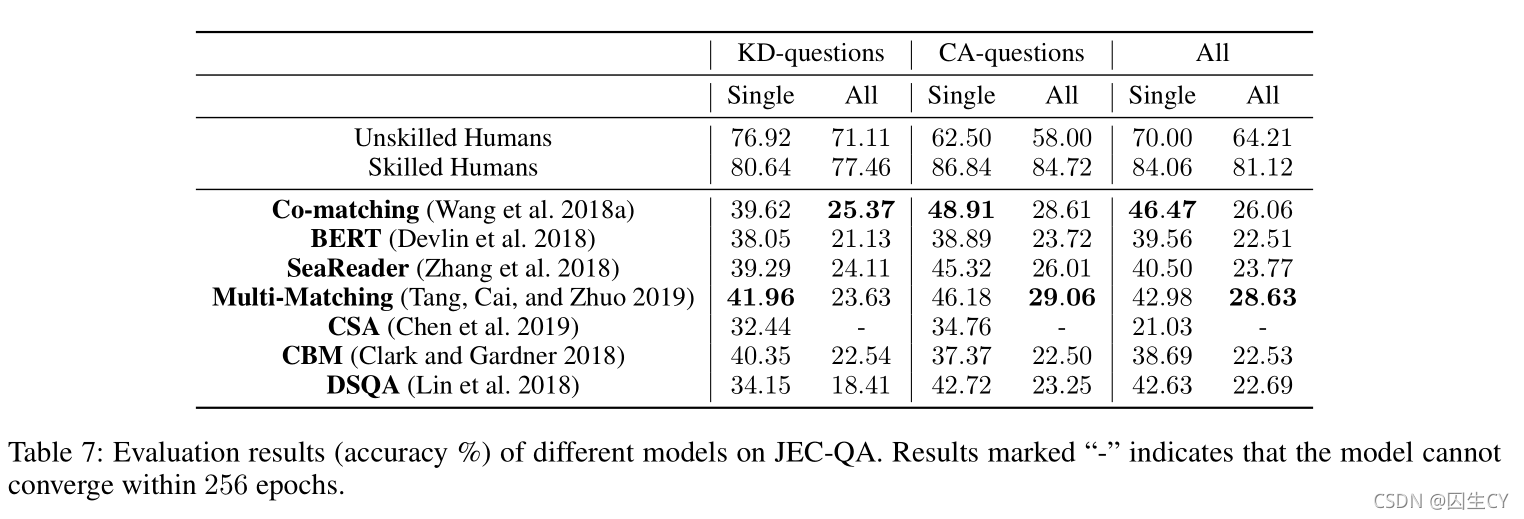
结果显示最好的模型在多选题上也只能取得 28.63 % 28.63\% 28.63%的正确率,这与非专业人员 64 % 64\% 64%的水平相差甚远(人类可以阅读同样的参考文档),而非专业人员与专业人员在 CA \text{CA} CA问题上的表现差距非常大,原因是非专业人员检索得到的段落不足以解题,因此检索质量是解题正确率的重要因素。
虽然 CA \text{CA} CA问题的表现显著低于 KD \text{KD} KD问题,但是事实上 CA \text{CA} CA问题中涉及的概念都要比 KD \text{KD} KD问题中的简单(如抢劫、盗窃、谋杀等),所以前者检索起来会更加容易。尽管如此,现存的方法在概念理解上的表现都很差。
4.5 4.5 4.5 比较分析 Comparative Analysis \text{Comparative Analysis} Comparative Analysis
-
本文针对表现较好的 Co-matching \text{Co-matching} Co-matching模型进一步深层分析,实验结果详见Table 8:
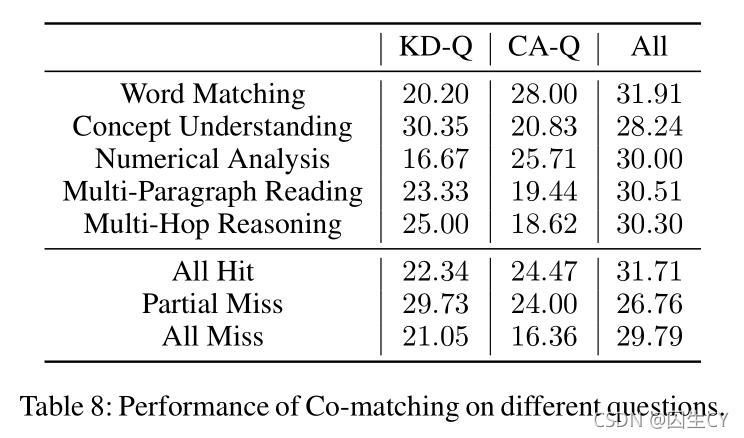
结果显示即便在给定充足相关段落的条件下,现存的模型也只能正确回答 32 % 32\% 32%的问题,这意味着模型无法完全理解相关材料,注意到模型在多级推理和多段落阅读理解上的 CA \text{CA} CA问题表现尤其差。
-
不同 K K K值的表现如Table 9所示:

结果显示 K = 6 K=6 K=6是一个较为经济且高效的选择。
4.6 4.6 4.6 案例分析 Case Study \text{Case Study} Case Study
-
如Table 10所示,这是一个需要多级推理的例题:

无需阅读题干,就会发现选项 D \rm D D与其他三个选项是冲突的,而现存的方法不具备发现冲突的选项的能力。
进一步地,若忽视选项 D \rm D D,现存的模型依然会选择所有其他选项,事实上正确选项只有 C \rm C C,原因是现存的模型只能实现一级推理,只要阅读相关段落,发现犯罪主体的年龄低于 16 16 16岁,即可排除选项 A \rm A A和选项 B \rm B B。因此多级推理能力的训练是必要的。
5 5 5 结论 Conclusion \text{Conclusion} Conclusion
In this work, we present JEC-QA as a new and challenging dataset for LQA, and JEC-QA is the largest dataset in LQA. Both retrieving documents and answering questions in JEC-QA require multiple types of reasoning ability, and our experimental results show that existing state-of-the-art models cannot perform well on JEC-QA. We hope our JEC-QA can benefit researchers on improving the reasoning ability of reading comprehension and QA models, and also making advances for legal question answering. In the future, we will explore how to improve the reasoning ability of question answering model and integrate legal knowledge into question answering, which are necessary for answering questions in JEC-QA.
- 总结就是现存的方法不能在 JEC-QA \text{JEC-QA} JEC-QA上有好的表现,期待大家在该数据集上进一步的研究。
6 6 6 致谢 Acknowledgements \text{Acknowledgements} Acknowledgements
This work is supported by the National Key Research and Development Program of China (No. 2018YFC0831900) and the National Natural Science Foundation of China (NSFC No. 61572273, 61661146007)
附录 A \text{A} A:参考文献
[01] Berant, J.; Chou, A.; Frostig, R.; and Liang, P. 2013. Semantic parsing on freebase from question-answer pairs. In Proceedings of EMNLP.
[02] Bordes, A.; Usunier, N.; Chopra, S.; and Weston, J. 2015. Large-scale simple question answering with memory networks. arXiv preprint arXiv:1506.02075.
[03] Chen, T., and Van Durme, B. 2017. Discriminative information retrieval for question answering sentence selection. In Proceedings of EACL.
[04] Chen, D.; Fisch, A.; Weston, J.; and Bordes, A. 2017. Reading wikipedia to answer open-domain questions. In Proceedings of ACL.
[05] Chen, Z.; Cui, Y.; Ma, W.; Wang, S.; and Hu, G. 2019. Convolutional spatial attention model for reading comprehension with multiple-choice questions. In Proceedings of AAAI.
[06] Chen, Y.-L.; Liu, Y.-H.; and Ho, W.-L. 2013. A text mining approach to assist the general public in the retrieval of legal documents. Journal of ASIS&T 64(2):280–290.
[07] Clark, C., and Gardner, M. 2018. Simple and effective multi-paragraph reading comprehension. In Proceedings of ACL.
[08] Clark, P.; Cowhey, I.; Etzioni, O.; Khot, T.; Sabharwal, A.; Schoenick, C.; and Tafjord, O. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
[09] Cui, Y.; Chen, Z.; Wei, S.; Wang, S.; Liu, T.; and Hu, G. 2017. Attention-over-attention neural networks for reading comprehension. In Proceedings of ACL.
[10] Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[11] Dhingra, B.; Liu, H.; Yang, Z.; Cohen, W. W.; and Salakhutdinov, R. 2017. Gated-attention readers for text comprehension. In Proceedings of ACL.
[12] Do, P.-K.; Nguyen, H.-T.; Tran, C.-X.; Nguyen, M.-T.; and Nguyen, M.-L. 2017. Legal question answering using ranking svm and deep convolutional neural network. arXiv preprint arXiv:1703.05320.
[13] Fawei, B.; Pan, J. Z.; Kollingbaum, M.; and Wyner, A. Z. 2018. A methodology for a criminal law and procedure ontology for legal question answering. In Proceedings of JIST.
[14] Green Jr, B. F.; Wolf, A. K.; Chomsky, C.; and Laughery, K. 1961. Baseball: an automatic question-answerer. In Proceedings of IRE-AIEE-ACM.
[15] He, C.; Peng, L.; Le, Y.; and He, J. 2018a. Secaps: A sequence enhanced capsule model for charge prediction. arXiv preprint arXiv:1810.04465.
[16] He, W.; Liu, K.; Liu, J.; Lyu, Y.; Zhao, S.; Xiao, X.; Liu, Y.; Wang, Y.; Wu, H.; She, Q.; et al. 2018b. Dureader: a chinese machine reading comprehension dataset from real-world applications. In Proceedings of ACL workshop.
[17] Hermann, K. M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; and Blunsom, P. 2015. Teaching machines to read and comprehend. In Proceedings of NIPS.
[18] Hu, Z.; Li, X.; Tu, C.; Liu, Z.; and Sun, M. 2018. Few-shot charge prediction with discriminative legal attributes. In Proceedings of COLING.
[19] Jia, R., and Liang, P. 2017. Adversarial examples for evaluating reading comprehension systems. In Proceedings of EMNLP.
[20] Johnson, R., and Zhang, T. 2017. Deep pyramid convolutional neural networks for text categorization. In Proceedings of ACL.
[21] Joshi, M.; Choi, E.; Weld, D. S.; and Zettlemoyer, L. 2017. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. arXiv preprint arXiv:1705.03551.
[22] Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; J´egou, H.; and Mikolov, T. 2017. Fasttext. zip: Compressing text classification models. In Proceedings of ICLR.
[23] Kim, M.-Y.; Goebel, R.; Kano, Y.; and Satoh, K. 2016. Coliee-2016: evaluation of the competition on legal information extraction and entailment. In Proceedings of JURISIN.
[24] Kim, M.-Y.; Lu, Y.; Rabelo, J.; and Goebel, R. 2018. Coliee-2018: Evaluation of the competition on case law information extraction and entailment.
[25] Kim, Y. 2014. Convolutional neural networks for sentence classification. In Proceedings of EMNLP.
[26] Kingma, D., and Ba, J. 2015. Adam: A method for stochastic optimization. In Proceedings of ICLR.
[27] Kwok, C.; Etzioni, O.; and Weld, D. S. 2001. Scaling question answering to the web. ACM Transactions on Information Systems.
[28] Lai, G.; Xie, Q.; Liu, H.; Yang, Y.; and Hovy, E. 2017. RACE: Large-scale reading comprehension dataset from examinations. In Proceedings of EMNLP.
[29] Lin, Y.; Ji, H.; Liu, Z.; and Sun, M. 2018. Denoising distantly supervised open-domain question answering. In Proceedings of ACL.
[30] Luo, B.; Feng, Y.; Xu, J.; Zhang, X.; and Zhao, D. 2017. Learning to predict charges for criminal cases with legal basis. In Proceedings of EMNLP.
[31] Nguyen, T.; Rosenberg, M.; Song, X.; Gao, J.; Tiwary, S.; Majumder, R.; and Deng, L. 2016. Ms marco: A human generated machine reading comprehension dataset. arXiv preprint arXiv:1611.09268.
[32] Raghav, K.; Reddy, P. K.; and Reddy, V. B. 2016. Analyzing the extraction of relevant legal judgments using paragraph-level and citation information. In Proceedings of ECAI.
[33] Rajpurkar, P.; Zhang, J.; Lopyrev, K.; and Liang, P. 2016. Squad: 100,000+ questions for machine comprehension of text. In Proceedings of EMNLP.
[34] Rajpurkar, P.; Jia, R.; and Liang, P. 2018. Know what you don’t know: Unanswerable questions for squad. In Proceedings of ACL.
[35] Richardson, M.; Burges, C. J.; and Renshaw, E. 2013. Mctest: A challenge dataset for the open-domain machine comprehension of text. In Proceedings of EMNLP.
[36] Seo, M.; Kembhavi, A.; Farhadi, A.; and Hajishirzi, H. 2017. Bidirectional attention flow for machine comprehension. In Proceedings of ICLR.
[37] Shen, Y.; Sun, J.; Li, X.; Zhang, L.; Li, Y.; and Shen, X. 2018. Legal article-aware end-to-end memory network for charge prediction. In Proceedings of ICCSE.
[38] Tang, M.; Cai, J.; and Zhuo, H. H. 2019. Multi-matching network for multiple choice reading comprehension. In Proceedings of AAAI.
[39] Trischler, A.; Wang, T.; Yuan, X.; Harris, J.; Sordoni, A.; Bachman, P.; and Suleman, K. 2016. Newsqa: A machine comprehension dataset. arXiv preprint arXiv:1611.09830.
[40] Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. In Proceedings of NIPS.
[41] Voorhees, E. M., et al. 1999. The trec-8 question answering track report. In Proceedings of Trec.
[42] Wang, S., and Jiang, J. 2016. Machine comprehension using match-lstm and answer pointer. arXiv preprint arXiv:1608.07905.
[43] Wang, W.; Yang, N.; Wei, F.; Chang, B.; and Zhou, M. 2017. Gated self-matching networks for reading comprehension and question answering. In Proceedings of ACL.
[44] Wang, S.; Yu, M.; Chang, S.; and Jiang, J. 2018a. A co-matching model for multi-choice reading comprehension. In Proceedings of ACL.
[45] Wang, S.; Yu, M.; Guo, X.; Wang, Z.; Klinger, T.; Zhang, W.; Chang, S.; Tesauro, G.; Zhou, B.; and Jiang, J. 2018b. R3: Reinforced reader-ranker for open-domain question answering. In Proceedings of AAAI.
[46] Wang, S.; Yu, M.; Jiang, J.; Zhang, W.; Guo, X.; Chang, S.; Wang, Z.; Klinger, T.; Tesauro, G.; and Campbell, M. 2018c. Evidence aggregation for answer re-ranking in opendomain question answering. In Proceedings of ICLR.
[47] Wang, Y.; Liu, K.; Liu, J.; He, W.; Lyu, Y.; Wu, H.; Li, S.; and Wang, H. 2018d. Multi-passage machine reading comprehension with cross-passage answer verification. In Proceedings of ACL.
[48] Xiao, C.; Zhong, H.; Guo, Z.; Tu, C.; Liu, Z.; Sun, M.; Feng, Y.; Han, X.; Hu, Z.; Wang, H.; et al. 2018. Cail2018: A large-scale legal dataset for judgment prediction. arXiv preprint arXiv:1807.02478.
[49] Yang, Z.; Qi, P.; Zhang, S.; Bengio, Y.; Cohen, W.; Salakhutdinov, R.; and Manning, C. D. 2018. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of EMNLP.
[50] Yang, Y.; Yih, W.-t.; and Meek, C. 2015. Wikiqa: A challenge dataset for open-domain question answering. In Proceedings of EMNLP.
[51] Ye, H.; Jiang, X.; Luo, Z.; and Chao, W. 2018. Interpretable charge predictions for criminal cases: Learning to generate court views from fact descriptions. In Proceedings of NAACL.
[52] Yih, W.-t.; Chang, M.-W.; He, X.; and Gao, J. 2015. Semantic parsing via staged query graph generation: Question answering with knowledge base. In Proceedings of ACL.
[53] Yu, M.; Yin, W.; Hasan, K. S.; Santos, C. d.; Xiang, B.; and Zhou, B. 2017. Improved neural relation detection for knowledge base question answering. In Proceedings of ACL.
[54] Zhang, X.; Wu, J.; He, Z.; Liu, X.; and Su, Y. 2018. Medical exam question answering with large-scale reading comprehension. In Proceedings of AAAI.
[55] Zhong, H.; Zhipeng, G.; Tu, C.; Xiao, C.; Liu, Z.; and Sun, M. 2018. Legal judgment prediction via topological learning. In Proceedings of EMNLP.
后记
可能有人已经发现我已经转到其他平台写自己的日志博客了。
最近的更新频率确实很低,因为自己有很多其他事情需要忙,可能对我来说最重要的就是 11 11 11月 21 21 21日的舟山群岛马拉松了。
月初结识 WXY \text{WXY} WXY后,现在参加了高校百英里接力赛,本来 10 10 10月 3 3 3日队内选拔时自己经验匮乏, 10 k m 10\rm km 10km被人带崩,差点没跑下来,不过还是入选了正式队员名单,昨日预选赛在源深体育场跑出 20 20 20分 55 55 55秒的 5000 5000 5000米场地成绩,在自己第一场正式比赛中就跑出了个人最好成绩,真的是特别特别的高兴,也让其他校友顿时刮目相看。现在就等着 10 10 10月 23 23 23日的城市接力赛了,在首马前与一众同好进行一场快乐的路跑实在是非常痛快的事情。
去年 1 1 1月份开始跑步的时候,我可能想不到自己能够跑到这种程度,跑步对我的改变实在是太大太大,最重要的是它完全没有影响到我在学业上的强劲势头,我在第一学年评测中依然位于前三的位置。事实证明本科时还是太放纵自己,我确实应该可以做得更好。人总是会给自己找各种各样的借口,事实上真的没有什么事情是不可能的,一切贵在坚持罢了。
我一直以来都是个很自负的人,只是现在我会更加肆无忌惮地毕露锋芒,因为已经完全无需隐忍。我始终认为模仿别人的套路总是落了下乘,这也是内卷的本质,我宁可去走一条很少有人会选择的道路,即便这一路布满荆棘。

















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









