







序言
降温,回家休整数日。
各种意义上的降温。
爬完了一座山,以为已经走遍了山河湖海。
其实我们都知道,路还很长,只是那座无法再走回去的山上,留有几分红绿。
上山的人,下山的人。
道阻且长,且行,且珍惜。
文章目录
- 序言
- 20241118
- 20241119
- 20241120
- 20241121
- 20241122
- 20241123
- 20241124
- 20241125
- 20241126
- 20241127
- 20241128
- 20241129
- 20241130
- 20241201
- 20241202
- 20241203
- 20241204
- 20241205
- 20241206
- 20241207
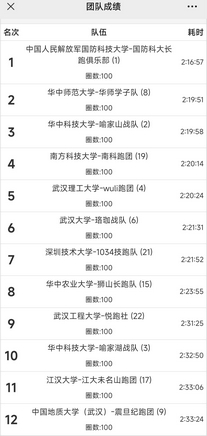
- 20241208(高百总决赛)
- 20241209
- 20241210 :umbrella:
- 20241211 :snowflake:
- 20241212:sunny:
- 20241213:cloud:
- 20241214:sunny:
- 20241215:sunny:(AK破240)
- 20241216:sunny:
- 20241217~20241218:sunny:
- 20241219:cloud:
- 20241220~20241222(完篇)
- 20241223(后记)
- 真·完篇
20241118
pytorch 高维张量 Tensor 维度操作与处理,einops
huggingface中的transformers跟pytorch有所区别,前者是语言建模,后者是纯序列建模
import torch
from torch import nn
import torch.nn.functional as F
import numpy as np
import pandas as pd
d = 4 # 模型维度
B = 2
T = 3
h = 2 # 多头注意力中的头数
ff = 8 # 前馈网络的维度
X = torch.randn(T, B, d) # [seq_len, batch_size, d_model]
X.shape # torch.Size([3, 2, 4])
encoder = nn.TransformerEncoderLayer(d, h, ff, dropout=0.0)
W_in, b_in = encoder.self_attn.in_proj_weight, encoder.self_attn.in_proj_bias
# (3d, d), (3d, )
W_in.shape, b_in.shape # (torch.Size([12, 4]), torch.Size([12]))
encoder(X).shape # torch.Size([3, 2, 4])
1 张量内存
[pytorch] Tensor shape 变化 view 与 reshape(contiguous 的理解))
https://stackoverflow.com/questions/26998223/what-is-the-difference-between-contiguous-and-non-contiguous-arrays
- 张量内存 layout
- 在大多数深度学习框架(如 PyTorch)中,(高维)张量的数据是以一维数组的形式在内存中连续存储的。对于多维张量,其高维结构是通过一维内存数组和步幅(strides)来实现的。
- pytorch 存储顺序(Storage Order)是 Row-major,最后一个维度变化最快。
- Strides(步幅)
- 对于一个形状为
(
D
0
,
D
1
,
D
2
)
(D_0,D_1,D_2)
(D0,D1,D2)(
2*3*4) 的 3D 张量,其步幅计算如下:- stride[2] = 1 \text{stride[2]} = 1 stride[2]=1
- stride[1] = D 2 × stride[2] = D 2 \text{stride[1]} = D_2\times \text{stride[2]}=D_2 stride[1]=D2×stride[2]=D2 (3)
- stride[0] = D 1 × stride[1] = D 1 × D 2 \text{stride[0]} = D_1\times \text{stride[1]}=D_1\times D_2 stride[0]=D1×stride[1]=D1×D2(3*4=12)
- 对于一个形状为
(
D
0
,
D
1
,
D
2
)
(D_0,D_1,D_2)
(D0,D1,D2)(
A = torch.randint(0, 5, (2, 3, 4))
"""
tensor([[[0, 0, 3, 0],
[3, 3, 1, 1],
[0, 3, 1, 4]],
[[1, 1, 0, 2],
[4, 1, 1, 0],
[4, 1, 0, 3]]])
"""
- 当张量在内存中的数据排列不再符合其形状和步幅之间的默认关系时,张量就是非连续的(is not contiguous)。
- 特征:
.is_contiguous()方法返回 False。 - 影响:某些操作在非连续张量上可能性能较差,或者需要额外的内存拷贝。
- 解决方法:使用 .contiguous() 方法,将张量拷贝为内存中连续的版本。
- 特征:
- 什么样的操作会导致内存的不连续
- permute, transpose, view;
- transpose 是 permute 的特例,transpose 只允许交换两个维度。
- permute, transpose, view;
reshape不改变内存中的数据顺序
A = torch.randn(3, 4)
A.shape, A.stride(), A.is_contiguous() # (torch.Size([3, 4]), (4, 1), True)
A = A.transpose(0, 1)
A.shape, A.stride(), A.is_contiguous() # (torch.Size([4, 3]), (1, 4), False)
A = A.contiguous()
A.shape, A.stride(), A.is_contiguous() # (torch.Size([4, 3]), (3, 1), True)
2 view v.s. reshape
- view(类比sql中的概念)
- 不会复制数据:view 创建的是原始张量的一个新的视图,内存数据保持不变,只是重新解释内存中的数据。因为它依赖于张量的内存布局,所以无法对非连续的张量使用。
- 不连续内存,view 时有可能报错;
- reshape: 它会自动处理非连续张量,尽可能返回视图,如果无法返回视图,则会拷贝
- 不要求内存连续:reshape 可以用于非连续的张量。如果张量不连续,reshape 会自动尝试创建一个新的连续张量并复制数据,以确保能够完成形状转换。
- 可能复制数据:当张量是内存不连续的,reshape 可能会进行数据复制,生成一个新的内存布局的张量。否则,它和 view 的行为是一样的,不复制数据。
- 不改变数据在内存中的顺序,只改变张量的形状解释。
A = torch.randn(2, 3, 4)
A.view(-1, 4).shape, A.view(-1, 4).stride(), A.view(-1, 4).is_contiguous(),
# (torch.Size([6, 4]), (4, 1), True)
A = torch.randn(2, 3, 4)
A_t = A.permute(1, 2, 0)
A.stride(), A_t.shape, A_t.stride(), A_t.is_contiguous()
# ((12, 4, 1), torch.Size([3, 4, 2]), (4, 1, 12), False)
3 encoder recap
https://pytorch.org/docs/stable/generated/torch.nn.TransformerEncoderLayer.html
- input:
X
∈
R
T
×
B
×
d
model
\mathbf{X} \in \mathbb{R}^{T \times B \times d_{\text{model}}}
X∈RT×B×dmodel (
batch_first=False) - multihead selfattn
- 线性变换(linear projection, 矩阵乘法)生成 Q、K、V矩阵
- X flat = X . reshape ( T × B , d m o d e l ) X_{\text{flat}}=\mathbf X.\text{reshape}(T\times B,d_{model}) Xflat=X.reshape(T×B,dmodel) (3d -> 2d)
-
Q
K
V
=
X
W
i
n
T
+
b
i
n
\mathbf{QKV}=\mathbf X\mathbf W_{in}^T+\mathbf b_{in}
QKV=XWinT+bin(
encoder_layer.self_attn.in_proj_weight,encoder_layer.self_attn.in_proj_bias)- W i n ∈ R 3 d model × d model \mathbf{W}_{in} \in \mathbb{R}^{3d_{\text{model}} \times d_{\text{model}}} Win∈R3dmodel×dmodel, b i n ∈ R 3 d model \mathbf{b}_{in} \in \mathbb{R}^{3d_{\text{model}}} bin∈R3dmodel
- Q K V ∈ R T × B , 3 d m o d e l \mathbf{QKV}\in \mathbb R^{T\times B,3d_{model}} QKV∈RT×B,3dmodel
- 拆分
Q
,
K
,
V
\mathbf Q, \mathbf K,\mathbf V
Q,K,V
- Q , K , V = split ( Q K V , d m o d e l ) \mathbf Q, \mathbf K,\mathbf V=\text{split}(\mathbf{QKV},d_{model}) Q,K,V=split(QKV,dmodel)(按列进行拆分)
- Q , K , V ∈ R T × B , d model \mathbf Q, \mathbf K,\mathbf V\in \mathbb R^{T \times B, d_{\text{model}}} Q,K,V∈RT×B,dmodel
- 调整形状以适应多头注意力
- d k = d model h d_k = \frac{d_{\text{model}}}h dk=hdmodel (4/2 = 2)
reshape_for_heads
Q heads = Q . reshape ( T , B , h , d k ) . permute ( 1 , 2 , 0 , 3 ) . reshape ( B × h , T , d k ) K heads = K . reshape ( T , B , h , d k ) . permute ( 1 , 2 , 0 , 3 ) . reshape ( B × h , T , d k ) V heads = V . reshape ( T , B , h , d k ) . permute ( 1 , 2 , 0 , 3 ) . reshape ( B × h , T , d k ) \begin{align*} \mathbf{Q}_{\text{heads}} &= \mathbf{Q}.\text{reshape}(T, B, h, d_k).\text{permute}(1, 2, 0, 3).\text{reshape}(B \times h, T, d_k) \\ \mathbf{K}_{\text{heads}} &= \mathbf{K}.\text{reshape}(T, B, h, d_k).\text{permute}(1, 2, 0, 3).\text{reshape}(B \times h, T, d_k) \\ \mathbf{V}_{\text{heads}} &= \mathbf{V}.\text{reshape}(T, B, h, d_k).\text{permute}(1, 2, 0, 3).\text{reshape}(B \times h, T, d_k) \end{align*} QheadsKheadsVheads=Q.reshape(T,B,h,dk).permute(1,2,0,3).reshape(B×h,T,dk)=K.reshape(T,B,h,dk).permute(1,2,0,3).reshape(B×h,T,dk)=V.reshape(T,B,h,dk).permute(1,2,0,3).reshape(B×h,T,dk)
- 计算注意力分数:
Scores
=
Q
heads
K
heads
⊤
d
k
\text{Scores} = \frac{\mathbf{Q}_{\text{heads}} \mathbf{K}_{\text{heads}}^\top}{\sqrt{d_k}}
Scores=dkQheadsKheads⊤
- Q heads ∈ R ( B × h ) × T × d k \mathbf{Q}_{\text{heads}} \in \mathbb{R}^{(B \times h) \times T \times d_k} Qheads∈R(B×h)×T×dk, K heads ⊤ ∈ R ( B × h ) × d k × T \mathbf{K}_{\text{heads}}^\top \in \mathbb{R}^{(B \times h) \times d_k \times T} Kheads⊤∈R(B×h)×dk×T,因此 Scores ∈ R ( B × h ) × T × T \text{Scores} \in \mathbb{R}^{(B \times h) \times T \times T} Scores∈R(B×h)×T×T。
- 计算注意力权重: AttentionWeights = softmax ( Scores ) \text{AttentionWeights}=\text{softmax}(\text{Scores}) AttentionWeights=softmax(Scores)
- 计算注意力输出:
AttentionOutput
=
AttentionWeights
×
V
heads
\text{AttentionOutput}=\text{AttentionWeights}\times{\mathbf V_\text{heads}}
AttentionOutput=AttentionWeights×Vheads
- V heads ∈ R ( B × h ) × T × d k \mathbf{V}_{\text{heads}} \in \mathbb{R}^{(B \times h) \times T \times d_k} Vheads∈R(B×h)×T×dk,因此 AttentionOutput ∈ R ( B × h ) × T × d k \text{AttentionOutput} \in \mathbb{R}^{(B \times h) \times T \times d_k} AttentionOutput∈R(B×h)×T×dk。
- 合并多头输出: AttentionOutput = AttentionOutput . reshape ( B , h , T , d k ) . permute ( 2 , 0 , 1 , 3 ) . reshape ( T , B , d model ) \text{AttentionOutput} = \text{AttentionOutput}.\text{reshape}(B, h, T, d_k).\text{permute}(2, 0, 1, 3).\text{reshape}(T, B, d_{\text{model}}) AttentionOutput=AttentionOutput.reshape(B,h,T,dk).permute(2,0,1,3).reshape(T,B,dmodel)
- 线性变换(linear projection, 矩阵乘法)生成 Q、K、V矩阵
4 qkv, mhsa
X flat = X . reshape ( T × B , d m o d e l ) X_{\text{flat}}=\mathbf X.\text{reshape}(T\times B,d_{model}) Xflat=X.reshape(T×B,dmodel)
X.shape, X
"""
(torch.Size([3, 2, 4]),
tensor([[[ 1.9269, 1.4873, 0.9007, -2.1055],
[ 0.6784, -1.2345, -0.0431, -1.6047]],
[[ 0.3559, -0.6866, -0.4934, 0.2415],
[-1.1109, 0.0915, -2.3169, -0.2168]],
[[-0.3097, -0.3957, 0.8034, -0.6216],
[-0.5920, -0.0631, -0.8286, 0.3309]]]))
"""
X_flat = X.reshape(-1, d)
# (T*B, d)
X_flat.shape # torch.Size([6, 4])
- Q K V = X flat W i n T + b i n \mathbf{QKV}=\mathbf X_{\text{flat}}\mathbf W_{in}^T+\mathbf b_{in} QKV=XflatWinT+bin
QKV = F.linear(X_flat, W_in, b_in)
QKV.shape # torch.Size([6, 12])
Q, K, V = QKV.split(d, dim=1)
Q.shape, K.shape, V.shape # (torch.Size([6, 4]), torch.Size([6, 4]), torch.Size([6, 4]))
# 调整Q、K、V的形状以适应多头注意力
d_k = d // h # 每个头的维度
def reshape_for_heads(x):
# x.shape: (T*B, h*d_k)
# 最末尾的维度上展开,d => h * d_k
# (T*B, h, d_k) => (T, B, h, d_k)
# permute(1, 2, 0, 3) => (B, h, T, d_k)
print(x.shape, x.is_contiguous())
y = x.contiguous().view(T, B, h, d_k).permute(1, 2, 0, 3).reshape(B * h, T, d_k)
print(y.shape)
return y
5 einsum ⇒ eninops
- einsum: 顾名思义,更多是求和约定;不太适合直接做 reshape
from einops import rearrange
Q heads = Q . reshape ( T , B , h , d k ) . permute ( 1 , 2 , 0 , 3 ) . reshape ( B × h , T , d k ) K heads = K . reshape ( T , B , h , d k ) . permute ( 1 , 2 , 0 , 3 ) . reshape ( B × h , T , d k ) V heads = V . reshape ( T , B , h , d k ) . permute ( 1 , 2 , 0 , 3 ) . reshape ( B × h , T , d k ) \begin{align*} \mathbf{Q}_{\text{heads}} &= \mathbf{Q}.\text{reshape}(T, B, h, d_k).\text{permute}(1, 2, 0, 3).\text{reshape}(B \times h, T, d_k) \\ \mathbf{K}_{\text{heads}} &= \mathbf{K}.\text{reshape}(T, B, h, d_k).\text{permute}(1, 2, 0, 3).\text{reshape}(B \times h, T, d_k) \\ \mathbf{V}_{\text{heads}} &= \mathbf{V}.\text{reshape}(T, B, h, d_k).\text{permute}(1, 2, 0, 3).\text{reshape}(B \times h, T, d_k) \end{align*} QheadsKheadsVheads=Q.reshape(T,B,h,dk).permute(1,2,0,3).reshape(B×h,T,dk)=K.reshape(T,B,h,dk).permute(1,2,0,3).reshape(B×h,T,dk)=V.reshape(T,B,h,dk).permute(1,2,0,3).reshape(B×h,T,dk)
Q, K, V = QKV.split(d, dim=1)
# (T*B, h*d_k)
Q.shape, K.shape, V.shape # (torch.Size([6, 4]), torch.Size([6, 4]), torch.Size([6, 4]))
torch.einsum('t b h k->(b h) t k', Q.contiguous().reshape(T, B, h, d_k))
"""
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[37], line 1
----> 1 torch.einsum('t b h k->(b h) t k', Q.contiguous().reshape(T, B, h, d_k))
File ~/anaconda3/lib/python3.10/site-packages/torch/functional.py:386, in einsum(*args)
381 return einsum(equation, *_operands)
383 if len(operands) <= 2 or not opt_einsum.enabled:
384 # the path for contracting 0 or 1 time(s) is already optimized
385 # or the user has disabled using opt_einsum
--> 386 return _VF.einsum(equation, operands) # type: ignore[attr-defined]
388 path = None
389 if opt_einsum.is_available():
RuntimeError: einsum(): invalid subscript given at index 9 in the equation string, subscripts must be in [a-zA-Z]
"""
其他一些使用案例:
rearrange(Q, '(T B) (h d_k) -> T B h d_k', T=T, B=B, h=h, d_k=d_k)
rearrange(Q, '(T B) (h d_k) -> B h T d_k', T=T, B=B, h=h, d_k=d_k)
rearrange(rearrange(Q, '(T B) (h d_k) -> B h T d_k', T=T, B=B, h=h, d_k=d_k), 'B h T d_k -> (B h) T d_k', T=T, B=B, h=h, d_k=d_k)
rearrange(Q, '(T B) (h d_k) -> (B h) T d_k', T=T, B=B, h=h, d_k=d_k)
20241119
上海降温,扬州就更冷了。一年这么快就又过去了,又到了这个季节。
宅了两天,只昨天出过一次门,这次主要是大腿太疼了,到今天都还是酸痛。脚其实不太清楚有没有肌肉疲劳,因为没走什么路,感受不出来,感觉这次脚上应该是没出什么问题。
总之南马确实办得很好,赛道设计很走心,沿途风景非常好,各方面都不输无锡。我想还是会破三的,我确信自己有这个实力,可能就在毕业之前,也可能在很久以后,或许再也不会到来。
另外,老爹老娘这次来唯一的作用就是帮我把房退了,早上没陪我去起点,跑完也没开车去终点接我,还得我自己坐地铁几十公里回去,虽然本也是说好就这样的,毕竟交通管制,车确实也不太好开,但还是显得草率了些。谁知道呢,这世界本来也就是个草台班子,人为赋予了些意义罢了,只是缺少这些虚无缥缈,也未免是太单调了。
PS:成绩证书出来了,排名3000多,前15%,太菜了,虽然好汉不提当年勇,但上半年扬马我可是能排到前1%的。另外,证书附带24张照片以及一段纪录片,30K之后全是痛苦面具,不忍直视,不过我找到了那个南师大小姐姐的照片,赛道上没看清脸,是真的又美又有实力,人家表情管理就超到位。

einops库杂记
https://einops.rocks/1-einops-basics/
快速开始
einops(Einstein Operations)提供了一种语法来便捷地操纵张量。einops 支持大多数张量库(当然包括 numpy 和 pytorch)。einops 针对所有张量库的语法都完全一致。einops 不会影响反向传播的正常进行。这些特性意味着 einops 可以和现有的深度学习框架和代码库无缝集成。
如果要跟着下面的步骤实操,需要先下载test_images.npy文件(可以从 einops 的 GitHub 仓库下载到,但是现在好像不行了),再将以下代码粘贴进一个util.py文件:
import numpy as np
from PIL.Image import fromarray
from IPython import get_ipython
def display_np_arrays_as_images():
def np_to_png(a):
if 2 <= len(a.shape) <= 3:
return fromarray(np.array(np.clip(a, 0, 1) * 255, dtype='uint8'))._repr_png_()
else:
return fromarray(np.zeros([1, 1], dtype='uint8'))._repr_png_()
def np_to_text(obj, p, cycle):
if len(obj.shape) < 2:
print(repr(obj))
if 2 <= len(obj.shape) <= 3:
pass
else:
print('<array of shape {}>'.format(obj.shape))
get_ipython().display_formatter.formatters['image/png'].for_type(np.ndarray, np_to_png)
get_ipython().display_formatter.formatters['text/plain'].for_type(np.ndarray, np_to_text)
from IPython.display import display_html
_style_inline = """<style>
.einops-answer {
color: transparent;
padding: 5px 15px;
background-color: #def;
}
.einops-answer:hover { color: blue; }
</style>
"""
def guess(x):
display_html(
_style_inline
+ "<h4>Answer is: <span class='einops-answer'>{x}</span> (hover to see)</h4>".format(x=tuple(x)),
raw=True)
在与util.py同级的目录中创建 Notebook,然后先执行以下代码段:
from utils import display_np_arrays_as_images
display_np_arrays_as_images()
这会将 numpy 的数组转换成图片显示出来。
比如:
ims = numpy.load('./resources/test_images.npy', allow_pickle=False)
# 有 6 张 96x96、带有 3 个色彩通道的图片,打包进同一个张量
print(ims.shape, ims.dtype) # (6, 96, 96, 3) float64
这是ims[0]:

这是 ims[1]:

常用的方法
重排rearrange
from einops import rearrange
# 交换 height 和 width 的顺序
rearrange(ims[0], 'h w c -> w h c')

组合图片(将加载的张量转换为一整张图片:)
rearrange(ims, 'b h w c -> (b h) w c')

横向组合:
rearrange(ims, 'b h w c -> h (b w) c')
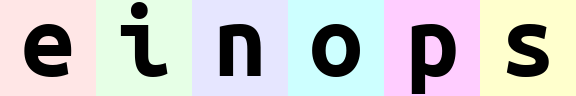
可以组合多个维度,比如rearrange(ims, 'b h w c -> (b h w c)').shape # (165888,)
20241120
只进不出撑得慌,晚饭前出去摇了5K@504,感觉不算太差,主要是大腿疼,脚确实是没啥问题,把伤痛越跑越好了属于是。
熬点东西出来呗。
PS:旧电脑里还是放了点东西的,丢了有点可惜,而且微信聊天记录全丢了,可能跟过去割裂一下也没啥不好的。
einops杂记(二)
对应组合,也可以分解:
rearrange(ims, '(b1 b2) h w c -> (b2 h) (b1 w) c ', b1=2)
同时可以将两者结合:
rearrange(ims, '(b1 b2) h w c -> (b1 h) (b2 w) c ', b1=2)

另一个例子:
rearrange(ims, '(b1 b2) h w c -> (b2 h) (b1 w) c ', b1=2)

下面的操作将每张图的高度加倍,宽度减半:
rearrange(ims, 'b h (w w2) c -> (h w2) (b w) c', w2=2)

也可以横向拉伸:
rearrange(ims, 'b (h h2) w c -> h (b w h2) c', h2=2)

纵向拉伸:
rearrange(ims, 'b (h h2) w c -> (b h) (w h2) c', h2=2)
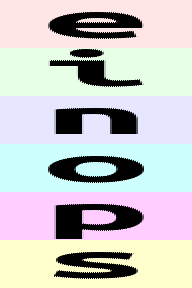
重点注意坐标轴的顺序:
比较下面两种操作的结果:
rearrange(ims, 'b h w c -> h (b w) c')
rearrange(ims, 'b h w c -> h (w b) c')
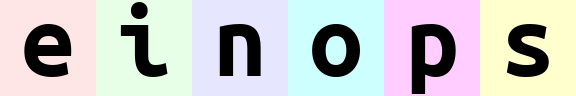

就像一串数字一样,最左侧的数字(最高位)是最重要的。einops 在组合时会先从低位(右侧)排列,排列完低位后再排列高位。对于上面的例子:
(b w)表示在水平方向上先排列w(表示每张图的所有水平像素),再排列b(表示每张图本身)。于是图片会一张一张地排出来。(w b)表示在水平方向上先排列b,再排列w。于是会先顺序排出e、i、n、o、p、s各自的第一列像素,然后排第二列,如此重复。
再看一个例子:
rearrange(ims, '(b1 b2) h w c -> h (b1 b2 w) c ', b1=2) # 输出 'einops'
rearrange(ims, '(b1 b2) h w c -> h (b2 b1 w) c ', b1=2) # 输出 'eoipns'
以上两行代码都将 w 放在最右侧,在输出水平方向的像素时,总是排完一张图,再排下一张。不同的是 b1 和 b2 的顺序。解构的模式是 (b1 b2),其中 b1=2,那么可以想象将原先的 b=6 重排成了一个 2×32×3 的矩阵:

- 第一行代码是先排列
b2(因为它在b1右边),再排列b1,而这与前面解构出的顺序是一致的,于是- 先固定
b1为第一行,输出该行的所有元素(ein) - 然后固定
b1为第二行,输出该行的所有元素(ops)
- 先固定
- 而第二行代码是先排列
b1,再排列b2,于是- 先固定
b2为第一列,然后输出该列的所有元素(eo) - 然后固定
b2为第二列,然后输出该列的所有元素(ip) - 然后固定
b2为第三列,然后输出该列的所有元素(ns)
- 先固定
20241121
- 好天气,好舒服。
堆叠和拼接张量
einops 还可以处理 list。将 ims 转换为一个 list:x = list(ims)
此时 x 是一个带有 6 个元素的 list,每个元素是一个 numpy.ndarray,对应一个字母的图片。当用 einops 处理 x 时,输入的第一个维度是 list 本身的维度,对于 x,就是原先的 b。
堆叠张量:
rearrange(x, 'b h w c -> h w c b')
# 等价于
numpy.stack(x, axis=3)
拼接张量:
rearrange(x, 'b h w c -> h (b w) c')
# 等价于
numpy.concatenate(x, axis=1)
增加和删除轴
可以通过在输入中写 1 来减少轴,也可以通过在输出中写 1 来增加轴。(unsqueeze)
x = rearrange(ims, 'b h w c -> b 1 h w 1 c') # 类似 numpy.expand_dims
print(x.shape)
print(rearrange(x, 'b 1 h w 1 c -> b h w c').shape) # 类似 numpy.squeeze
输出:
(6, 1, 96, 96, 1, 3)
(6, 96, 96, 3)
下面的代码将在 h 和 w 方向上分别取 b 和 c 的最大值,形成一个 (6, 1, 1, 3) 的张量:
reduce(ims, 'b h w c -> b () () c', 'max')
reduce操作
如果要在某个轴的方向上求平均,传统的写法是x.mean(-1)
但是这种代码可读性不佳。如果缺乏经验,那么我们难以立即知道 -1 指的是哪个轴。
在 einops 中,上面的代码可以写成:
reduce(x, 'b h w c -> b h w', 'mean')
如果某个轴在输入中出现,但在输出中没有出现,那么这个轴就是被执行 reduce 操作的轴。在上面的例子中,轴 c 被执行了求平均值操作。
在 batch 轴上执行求平均值操作:
# 等价于 ims.mean(axis=0)
reduce(ims, 'b h w c -> h w c', 'mean')
# 也等价于 reduce(ims, 'b h w c -> h w', 'mean')

有如下几种 reduce 操作:
mean求平均值min求最小值max求最大值sum求和prod求乘积
einops 的语法允许我们设计池化操作。下面的代码执行了 2×2 平均池化:
reduce(ims, 'b (h h2) (w w2) c -> h (b w) c', 'mean', h2=2, w2=2)
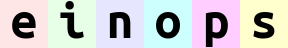
当然,这张图片的长和宽都减半了。
2×22×2 最大池化:
reduce(ims, 'b (h h2) (w w2) c -> h (b w) c', 'max', h2=2, w2=2)
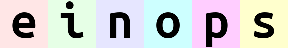
相比平均池化,最大池化没有那么平滑。
另一个例子:
reduce(ims, '(b1 b2) h w c -> (b2 h) (b1 w)', 'mean', b1=2)

20241122
嘴上说跑步的热情被浇灭了,这周一下子又疯得不行,估计是12.8镇江南山将至,家门口的比赛估计还是想好好跑一下的。
嘉伟在健身房黑练了一个多星期,跑步机5k完成大PB,16分17秒,差7秒达二级。其实这才是嘉伟真正的实力,以前他就是PB如喝水,说实话校运会那天他如果是认真跑,以那种天气和氛围,大概率也是能进17分的。
简单总结一下嘉伟神勇的历史:
21年9月入学,在田径队5000米测试中,最后半圈落后一哥WXY超过50米,完成绝杀,令人瞠目结舌,高百10K首秀44分06秒。
22年11月,场地测试5000米18分16PB(那天晚上我跟另一个人轮流带他1000米,他告诉我前一天跑步机跑了37分半,我都不敢相信,因为在那之前他的PB是一个月前高百跑出来的39分45秒),然后在12月的市运会,又跑出1500米4分40秒跟800米2分11的PB(雨战)。
23年上半年,4月上半马1小时24分29秒PB(这也是我目前唯一还能吹的,就是我的半马PB要比嘉伟快25秒),不过以嘉伟去年的表现,他半马至少应该是120以内的水平。
23年下半年,9月嘉伟在129测试赛中跑出17分46的5000米PB,紧接着10月闻泰安世10K36分25秒PB,然后11月11日高百10K36分33秒,11月26日首马破三(2:59:15),12月上旬市运会,再次5000米17分02PB,1500米4分39PB
24年上半年因为锡马跑崩受伤(342),以至于上半马也没跑好(128),消沉了很长时间,到下半年,NIKE校园精英接力赛也跑崩,加上紧张的日程,缺少训练,高百也没有跑出特别惊艳的成绩,嘉伟似乎真的已经不行了。结果,校运会1500米4分36秒PB拿捏白辉龙,5000米17分44秒拿捏小崔。
如今,那个PB如喝水的嘉伟又回来了。
PS:想想跟天赋怪真没法比,就嘉伟这男默女泪的大长腿,练一辈子也赶不上… 今天晚饭后慢跑半个小时,感觉身体已经完全恢复,没有明显的伤痛,确是一件好事。其实我不想再认真训练。嘉伟明年上半年大概率是要再跑一次全马的,之前他说是想去芜湖,觉得机场一马平川没有爬升很好跑,或许到时候再陪他跑一回吧。

做了个小玩意儿,最近不务正业了几天,学了点laya air3和unity的东西,看完觉得太好玩了,但是这几年游戏产业形势挺好,但是游戏策划是一顶一的一个没码,主要是想看看这种在canvas上画出来的H5页游应该怎么抓包和脚本自动化。小组件其实都能抓得到,都是在一张大图上割出来的,但是具体的位置,动画效果的捕捉就不太好搞了。
- .atlas文件里保存的是大贴图上各个小贴图所在的坐标及尺寸
- 皮肤图片来自:如https://web.sanguosha.com/10/pc/res/assets/runtime/general/big/static/542803.png,修改编号可以找到很多皮肤
- .sk或者.skel文件是骨骼文件,大多是一些动图,不仅是皮肤,包括UI上的一些动态元素
selenium确实无法定位canvas上的元素,除非扒JS看每个元素的位置。一些动态元素的点击,似乎没有什么特别好的办法,我其实不是特别懂,是不是后端会保存一个前端canvas的快照,这样每次点击的时候其实逻辑处理都在后端,所以前端并不能找到,而且H5页游经常出现一种情况,就是点击元素,没有反应,可能就是前后端快照不一致?瞎猜的。
总之可以用笨方法,就是自己先点一遍,然后让按键精灵记下来操作次序,然后模拟即可。下面是一个这种思路的脚本:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@stu.sufe.edu.cn
import time
import logging
from pynput import mouse, keyboard
# Initialize a logger
def initialize_logger(file_path, mode = 'w'):
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
formatter = logging.Formatter("%(asctime)s | %(filename)s | %(levelname)s | %(message)s")
file_handler = logging.FileHandler(file_path, mode=mode, encoding="utf8")
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
console = logging.StreamHandler()
console.setLevel(logging.INFO)
console.setFormatter(formatter)
logger.addHandler(console)
return logger
# Terminate the given logger
def terminate_logger(logger):
for handler in logger.handlers[:]:
logger.removeHandler(handler)
# Operate manually
def rubbing(rubbing_path = "./rubbing.log"):
def _on_move(x, y):
logging.info(f"move to ({x}, {y})")
def _on_click(x, y, button, pressed):
logging.info(f'{"press" if pressed else "release"} {button} at ({x}, {y})')
def _on_scroll(x, y, dx, dy):
logging.info(f"scroll at ({x}, {y}) by [{dx}, {dy}]")
logger = initialize_logger(rubbing_path, 'w')
with mouse.Listener(on_move=_on_move, on_click=_on_click, on_scroll=_on_scroll) as listener:
listener.join()
terminate_logger(logger)
# Simulate the action by rubbing
def printing(rubbing_path = "./rubbing.log"):
with open(rubbing_path, 'r', encoding="utf8") as f:
lines = f.read().splitlines()
mouse_controller = mouse.Controller()
for line in lines:
asctime, filename, levelname, message = line.split('|')
asctime, filename, levelname, message = asctime.strip(), filename.strip(), levelname.strip(), message.strip()
left = message.find('(')
right = message.find(')')
x, y = message[left + 1: right].split(', ')
x, y = int(x), int(y)
pos = mouse_controller.position
mouse_controller.move(x - pos[0], y - pos[1])
if message.startswith("move"):
pass
elif message.startswith("press"):
if "Button.left" in message:
mouse_controller.press(mouse.Button.left)
elif "Button.right" in message:
mouse_controller.press(mouse.Button.right)
else:
assert False, f"Unknown press operation: {message}"
elif message.startswith("release"):
if "Button.left" in message:
mouse_controller.click(mouse.Button.left)
elif "Button.right" in message:
mouse_controller.click(mouse.Button.right)
else:
assert False, f"Unknown release operation: {message}"
elif message.startswith("scroll"):
left = message.find('[')
right = message.find(']')
dx, dy = message[left + 1: right].split(', ')
dx, dy = int(dx), int(dy)
mouse_controller.scroll(dx, dy)
else:
assert False, f"Unknown message: {message}"
time.sleep(.001)
# Simulate the action by rubbing (easy)
def printing(rubbing_path = "./rubbing.log"):
with open(rubbing_path, 'r', encoding="utf8") as f:
lines = f.read().splitlines()
mouse_controller = mouse.Controller()
for line in lines:
asctime, filename, levelname, message = line.split('|')
asctime, filename, levelname, message = asctime.strip(), filename.strip(), levelname.strip(), message.strip()
if message.startswith("move") or message.startswith("release"):
time.sleep(.01)
continue
left = message.find('(')
right = message.find(')')
x, y = message[left + 1: right].split(', ')
x, y = int(x), int(y)
pos = mouse_controller.position
mouse_controller.move(x - pos[0], y - pos[1])
if message.startswith("press"):
if "Button.left" in message:
mouse_controller.click(mouse.Button.left)
time.sleep(.3)
elif "Button.right" in message:
mouse_controller.click(mouse.Button.right)
time.sleep(1)
else:
assert False, f"Unknown press operation: {message}"
continue
elif message.startswith("scroll"):
left = message.find('[')
right = message.find(']')
dx, dy = message[left + 1: right].split(', ')
dx, dy = int(dx), int(dy)
mouse_controller.scroll(dx, dy)
else:
assert False, f"Unknown message: {message}"
if __name__ == "__main__":
time.sleep(3)
# rubbing()
printing()
rubbing就是拓印,将操作拓印到日志中,然后printing就是根据拓印的日志来印刷操作,上一个printing控制不好间隔,容易出错,下面一个个性化地调了一下间隔,比较容易成功,主要是一些双击的操作对间隔有要求。键盘类似,但需要把键位映射一下。
def keyboard_listener():
def _on_press(key):
info = f'press key {key}'
logging.info(info)
def _on_release(key):
info = f'release key {key}'
logging.info(info)
with keyboard.Listener(on_press=_on_press, on_release=_on_release) as listener:
listener.join()
20241123
返沪,元气基本恢复。上海天气出奇的好,可惜下周大降温,凛冬将至。
骑上车才发现自己左膝盖疼,但不是一直疼,就是有时候突然来一下狠的,一整圈都疼。
晚上常规30箭步×8组(+20kg),发现是膝盖连接大腿前侧的那个点在疼,不是髌骨,说起来膝盖也几百年没疼过了,主要原因还是南马跑的时候左脚落地一直很别扭,后跟不稳,总觉得要往内崴下来,就很刻意地左脚外侧着地,避免向内崴伤,最后就这么全程别扭地跑下来也挺神奇的。
本来后跟跑也确实伤膝盖,没辙,不过应该问题不大,最近休息得也很充分了。力量训练后断断续续慢跑了3K多,LZR和韬哥在,晚上去蜀地源放纵了一下,撑得很,虽然本来也不太想跑,就这么养生也挺好的,跟刚开始跑步的时候一样的水平,返璞归真。
PS:今天小崔一个人又刷了30个400米,圈速1’15"-1’20",间歇60-90秒,现在的小朋友是真的越来越疯狂了,年轻耐造就是好。
基于LangGraph 实现 Reflexion Agent(generator vs. critic)
参考资料:https://blog.langchain.dev/reflection-agents/
相关的几篇论文
Agentic Reasoning Design Patterns
- Reflection 反思
Self-Refine: lterative Refinement with Sel.Feedback, Madaan et al. (2023)*Reflexion: Language Agents with Verbal Reinforcement Learing, Shinn et al., (2023) - Tool use 工具使用(目前主流的几个大模型都已经提供了工具调用,即函数调用的功能)
.Gorilla: Large Language Model Connected with Massive APis, Patil et al. (2023).MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action, Yang et al. (2023) - Planning(即思路)
Chain-of.Thought Prompting Elicits Reasoning in large Language Models, Wei et al. (2022) HuggingGPT: Solving Al Tasks with ChatGPT and its Friends in Hugging Face, Shen et al. (2023
4.Multi-agent collaboration(多智能体协同)
Communicative Agents for Software Development, Qlan et al… (2023)AutoGen: Enabling Next-Gen LLM Applications via Multi.Agent Conversation, Wu et al. (2023)
一些理解:
- prompt engineering
- 重在结构,structure/workflow/pipeline 的设计,而不只是措辞上;
- reflexion agent: https://arxiv.org/abs/2303.11366
- role design
- generator(student) & critic(teacher)
- reflect on and critique its past actions,
- sometimes incorporating additional external information such as tool observations.
- execution
- role design
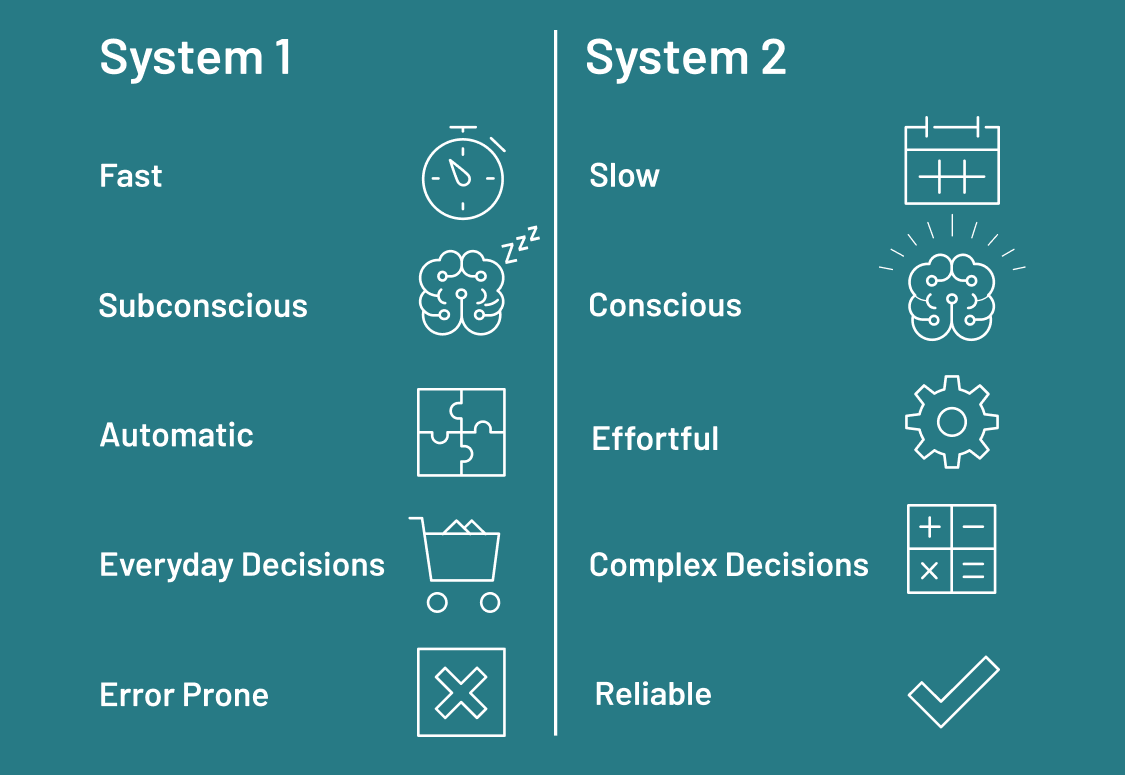
- “System 1” vs. “System 2” thinking,
- where System 1 is reactive or instinctive (fast thinking)
- 直觉的本能反应
- System 2 is more methodical and reflective (slow thinking)
- o1,learned implicit reasoing
- reflection can help LLM systems break out of purely System 1 “thinking” patterns and closer to something exhibiting System 2-like behavior.
- where System 1 is reactive or instinctive (fast thinking)
- reflexion agent
- 本质是对 messages 的操作和管理(左右互搏)
- generator vs. reflector
- 对于 generator 的输出,ai message(assistant),对于 reflector 则是 human message(user)
- 反之对于 reflector 的输出,ai message(assistant),对于 generator 则是 human message(user)
- generator vs. reflector
- 本质是对 messages 的操作和管理(左右互搏)
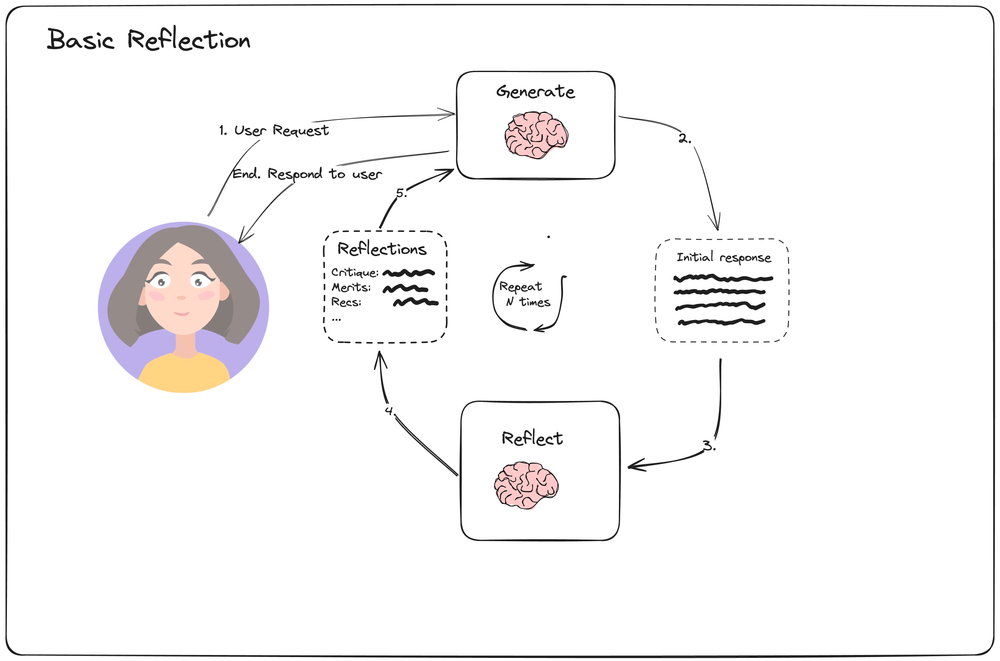
一个基础的反思:
from dotenv import load_dotenv
assert load_dotenv()
第一步是生成
ChatPromptTemplate实例化之后是ChatPromptValue.stream()而非.invoke(),长文的输出就显得没有那么耗时;- system prompt 不属于 messages
- messages 意味着是对话式的,一问一答的方式;
from langchain_core.messages import AIMessage, BaseMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are an essay assistant tasked with writing excellent 5-paragraph essays."
" Generate the best essay possible for the user's request."
" If the user provides critique, respond with a revised version of your previous attempts.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
prompt.pretty_print()
输出结果:
================================ System Message ================================
You are an essay assistant tasked with writing excellent 5-paragraph essays. Generate the best essay possible for the user's request. If the user provides critique, respond with a revised version of your previous attempts.
============================= Messages Placeholder =============================
{messages}
然后调用模型,串联prompt:
llm = ChatOpenAI(model='gpt-4o-2024-08-06')
generate = prompt | llm
prompt.invoke({'messages': [('human', 'write an essay on why the little prince is relevant in modern childhood')]}) # ChatPromptValue(messages=[SystemMessage(content="You are an essay assistant tasked with writing excellent 5-paragraph essays. Generate the best essay possible for the user's request. If the user provides critique, respond with a revised version of your previous attempts.", additional_kwargs={}, response_metadata={}), HumanMessage(content='write an essay on why the little prince is relevant in modern childhood', additional_kwargs={}, response_metadata={})])
prompt.invoke({'messages': [HumanMessage(content='write an essay on why the little prince is relevant in modern childhood')]}) # ChatPromptValue(messages=[SystemMessage(content="You are an essay assistant tasked with writing excellent 5-paragraph essays. Generate the best essay possible for the user's request. If the user provides critique, respond with a revised version of your previous attempts.", additional_kwargs={}, response_metadata={}), HumanMessage(content='write an essay on why the little prince is relevant in modern childhood', additional_kwargs={}, response_metadata={})])
resp = generate.invoke({'messages':
[HumanMessage(content='write an essay on why the little prince is relevant in modern childhood')]})
print(resp.content)
输出模型响应:
Antoine de Saint-Exupéry's "The Little Prince" is a timeless tale that continues to resonate with readers of all ages, especially children. While the book was first published in 1943, its themes remain pertinent in today's rapidly changing world. The story's exploration of imagination, the value of relationships, and the critique of adult behavior offers vital life lessons that modern children can benefit from. This essay will delve into these aspects, illustrating why "The Little Prince" is relevant in contemporary childhood.
Firstly, "The Little Prince" celebrates the boundless creativity and imagination inherent in children. In today's digital age, where structured activities and screen time often dominate, the book serves as a reminder of the importance of nurturing a child's imagination. The protagonist's journey across various planets and encounters with whimsical characters like the fox and the talking rose encourage children to think beyond the confines of their everyday experiences. This imaginative exploration fosters creativity, which is crucial for problem-solving and innovation, skills increasingly prioritized in the modern world.
Secondly, the story underscores the significance of relationships and emotional intelligence, areas often overlooked in modern childhood. The Little Prince's interactions emphasize understanding, empathy, and the invisible bonds that connect individuals. In a time when social media can sometimes replace face-to-face interactions, these lessons are invaluable. The prince's relationship with the fox, which highlights the idea that "you become responsible, forever, for what you have tamed," teaches children the importance of nurturing and maintaining relationships. This is especially relevant as they navigate friendships and family dynamics in a complex social landscape.
Moreover, "The Little Prince" offers a poignant critique of adult behavior and societal values, prompting children to question the world around them. The various grown-ups the prince encounters, preoccupied with power, wealth, and status, serve as caricatures of adult obsessions that often overshadow what truly matters. In an era where consumerism and material success are frequently idolized, the book's message encourages children to prioritize love, kindness, and the simple joys of life. This critical thinking skill is essential for young minds as they develop their own beliefs and values.
Furthermore, the story promotes introspection and philosophical inquiry, encouraging children to ponder existential questions. The Little Prince's reflections on life, death, and what it means to be truly happy provide a gentle introduction to these profound topics. This can be particularly beneficial in helping children develop resilience and emotional depth. In an unpredictable world, understanding such concepts can provide comfort and perspective, aiding children in coping with the challenges they face.
In conclusion, "The Little Prince" remains a relevant and vital story for modern children. Its celebration of imagination, emphasis on relationships, critique of adult priorities, and encouragement of philosophical thinking offer essential life lessons. As children grow up in a fast-paced, technology-driven society, the timeless wisdom of "The Little Prince" can help them navigate their world with creativity, empathy, and a sense of wonder. By revisiting this classic, children can learn to cherish the simple and important aspects of life, ensuring that they grow into thoughtful and compassionate individuals.
上面这种事invoke的方法,比较慢,可以用stream方法生成长文本更快:
essay = ""
request = HumanMessage(
content='write an essay on why the little prince is relevant in modern childhood'
)
for chunk in generate.stream({'messages': [request]}):
print(chunk.content, end="")
essay += chunk.content
生成的essay结果类似invoke的生成结果
20241124
- 今早高百分站赛最后一站——武汉站,之前看华中农大狮山长跑队的B站动态,迪哥说分站赛报名费1000块太坑了,不去参加了,结果是真香了。总成绩2小时23分,比我们快了有将近一刻钟吧,但是他们只能排到第8,相当于人均4000米14分20秒左右的水平。主要是华农女生很强,刘倩(华农大姐大,B站@小爷乐了)跑到16分04,另一个王宇晴也跑到16分17,都是女子前十水平,男生实力相对弱,但贵在均匀,厚度相当高。华农的氛围真心羡慕。
- 最终39所高校晋级总决赛,虽然没有我们啥事,但未来谁知道呢?都不用提老牌强校,就以华北电力、广西民族这两所一南一北的两所高校为例,男生最差都能跑出13分40秒的成绩,而且华电还都是本科文化生上场,最弱的比我们最强的还要快;广西民族大学一所双非,8个男生,1个11分55秒,5个12分台,2个13分台,令人咋舌的水平,只可惜他们女生弱了些(17分台),最终被中山大学反杀。说实话,全国各地,东华西北、川渝两广,到处都是猛人,就长三角这片最为孱弱,肥水沃田果真是养不出高手。
- PS:养老跑,改前掌,膝盖坐久了疼,不跑一点还是不行。


第二步进行反思(Reflect)
reflection_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a teacher grading an essay submission. Generate critique and recommendations for the user's submission."
" Provide detailed recommendations, including requests for length, depth, style, etc.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
reflection_prompt.pretty_print()
prompt如下:
================================ System Message ================================
You are a teacher grading an essay submission. Generate critique and recommendations for the user's submission. Provide detailed recommendations, including requests for length, depth, style, etc.
============================= Messages Placeholder =============================
{messages}
同理进行invoke:
reflect = reflection_prompt | llm
reflection_prompt.invoke({'messages': [HumanMessage(content=essay)]}).messages
"""
[SystemMessage(content="You are a teacher grading an essay submission. Generate critique and recommendations for the user's submission. Provide detailed recommendations, including requests for length, depth, style, etc.", additional_kwargs={}, response_metadata={}),
HumanMessage(content='Antoine de Saint-Exupéry\'s "The Little Prince" is a timeless classic that continues to hold significant relevance in modern childhood. Although first published in 1943, its themes of innocence, imagination, and the essence of human relationships resonate as deeply today as they did over seventy years ago. The story\'s ability to transcend time and cultural boundaries makes it a valuable tool for imparting important life lessons to children in the contemporary world. This essay will explore three key reasons why "The Little Prince" remains relevant: its emphasis on the value of imagination, its exploration of essential human connections, and its critique of adult perspectives.\n\nFirstly, "The Little Prince" serves as a profound reminder of the value of imagination in childhood. In today\'s digital age, children\'s imaginations are often stifled by screens and structured activities. The Little Prince, with his fantastical journey across planets, encourages children to engage their creativity and explore the world with wonder. This imaginative exploration is crucial for cognitive development, as it fosters problem-solving skills and emotional intelligence. By reading the story, children are inspired to dream, create, and view the world from a perspective that values curiosity over conformity.\n\nSecondly, the book explores the importance of essential human connections, a theme that is increasingly important in today\'s fast-paced society. The Little Prince\'s journey is marked by his encounters with various characters, each representing different aspects of human nature. Through these interactions, Saint-Exupéry emphasizes the importance of relationships, love, and empathy. In a world where digital communication often replaces face-to-face interaction, "The Little Prince" reminds children of the irreplaceable value of genuine human bonds. The story teaches that what truly matters is invisible to the eye, a lesson on prioritizing meaningful connections over superficial ones.\n\nLastly, "The Little Prince" offers a poignant critique of adult perspectives, urging children to question societal norms and values. The story highlights how adults often lose sight of what is truly important in life, becoming consumed by materialism and routine. The Little Prince’s encounters with grown-ups reveal the absurdities of adult priorities, encouraging children to maintain their sense of wonder and questioning. In a world that often pressures children to grow up too quickly, the book serves as a reminder to preserve the innocence and purity of childhood perspectives.\n\nIn conclusion, "The Little Prince" remains profoundly relevant for modern childhood through its celebration of imagination, its emphasis on the importance of human connections, and its critique of adult mindsets. As children navigate the complexities of the modern world, Saint-Exupéry\'s timeless story offers guidance on maintaining a sense of wonder and prioritizing what truly matters in life. "The Little Prince" not only entertains but also educates, making it an invaluable addition to any child\'s literary journey. Through its enduring wisdom, the book continues to touch the hearts and minds of new generations, ensuring its place in the canon of essential childhood literature.', additional_kwargs={}, response_metadata={})]
"""
resp = reflect.invoke({'messages': [HumanMessage(content=essay)]})
print(resp.content)
生成的内容(对essay的评价):
Your essay provides a thoughtful and engaging analysis of Antoine de Saint-Exupéry's "The Little Prince," highlighting its enduring relevance and appeal to modern readers, particularly children. Your focus on the themes of imagination, human connection, and critique of adult perspectives is well-chosen, and you effectively articulate why these themes resonate today. However, there are areas where your essay could be strengthened to provide a more comprehensive and nuanced exploration.
### Critique and Recommendations:
1. **Depth of Analysis:**
- While you touch on the themes effectively, consider delving deeper into specific instances from the text to illustrate your points. For example, when discussing the value of imagination, you could analyze particular episodes, such as the Little Prince's encounter with the fox, to show how these moments encapsulate the theme.
- Explore the philosophical underpinnings of the novel. For instance, how does Saint-Exupéry’s personal history as a pilot and his philosophical views inform the narrative and its themes?
2. **Cultural and Historical Context:**
- Including a brief discussion of the historical and cultural context of when the book was written could enrich your analysis. Consider how the events of World War II, during which the book was written, might have influenced its themes of connection and innocence.
- Discuss how the book has been received in various cultures and how its translation and adaptation into different media have helped maintain its relevance.
3. **Modern Relevance:**
- While you mention the digital age, it would be beneficial to explore how "The Little Prince" contrasts with current trends in children's media and literature. How does it offer an alternative to digital narratives?
- Consider discussing the educational implications of the book in contemporary settings, such as its use in classrooms or therapeutic contexts.
4. **Structure and Flow:**
- Your essay is well-structured, but consider adding transitional sentences at the beginning and end of each paragraph to enhance the flow between sections.
- The conclusion reiterates your main points effectively, but it could be strengthened by suggesting specific ways parents or educators can incorporate the lessons of "The Little Prince" into children's lives today.
5. **Length and Style:**
- The essay is concise, which is a strength, but expanding on the points mentioned above could add depth without sacrificing clarity.
- Maintain the engaging and accessible style, but ensure that any additional analysis remains clear and focused to avoid overwhelming the reader with too much information.
6. **Quotations and References:**
- Integrating direct quotations from the text can add authenticity and depth to your analysis. Consider including a few key quotes that encapsulate the themes you discuss.
- If relevant, reference scholarly analyses of "The Little Prince" to support your arguments and provide additional perspectives.
By addressing these areas, your essay will offer a more comprehensive and nuanced exploration of "The Little Prince," enhancing its appeal and educational value to modern readers. Overall, your essay is a solid foundation that, with further development, can provide deeper insights into the timeless relevance of this classic work.
注意这里的request.type是human。
打印reflection_prompt.invoke({'messages': [request, HumanMessage(content=essay)]}).messages如下:
[SystemMessage(content="You are a teacher grading an essay submission. Generate critique and recommendations for the user's submission. Provide detailed recommendations, including requests for length, depth, style, etc.", additional_kwargs={}, response_metadata={}),
HumanMessage(content='write an essay on why the little prince is relevant in modern childhood', additional_kwargs={}, response_metadata={}),
HumanMessage(content='Antoine de Saint-Exupéry\'s "The Little Prince" is a timeless classic that continues to hold significant relevance in modern childhood. Although first published in 1943, its themes of innocence, imagination, and the essence of human relationships resonate as deeply today as they did over seventy years ago. The story\'s ability to transcend time and cultural boundaries makes it a valuable tool for imparting important life lessons to children in the contemporary world. This essay will explore three key reasons why "The Little Prince" remains relevant: its emphasis on the value of imagination, its exploration of essential human connections, and its critique of adult perspectives.\n\nFirstly, "The Little Prince" serves as a profound reminder of the value of imagination in childhood. In today\'s digital age, children\'s imaginations are often stifled by screens and structured activities. The Little Prince, with his fantastical journey across planets, encourages children to engage their creativity and explore the world with wonder. This imaginative exploration is crucial for cognitive development, as it fosters problem-solving skills and emotional intelligence. By reading the story, children are inspired to dream, create, and view the world from a perspective that values curiosity over conformity.\n\nSecondly, the book explores the importance of essential human connections, a theme that is increasingly important in today\'s fast-paced society. The Little Prince\'s journey is marked by his encounters with various characters, each representing different aspects of human nature. Through these interactions, Saint-Exupéry emphasizes the importance of relationships, love, and empathy. In a world where digital communication often replaces face-to-face interaction, "The Little Prince" reminds children of the irreplaceable value of genuine human bonds. The story teaches that what truly matters is invisible to the eye, a lesson on prioritizing meaningful connections over superficial ones.\n\nLastly, "The Little Prince" offers a poignant critique of adult perspectives, urging children to question societal norms and values. The story highlights how adults often lose sight of what is truly important in life, becoming consumed by materialism and routine. The Little Prince’s encounters with grown-ups reveal the absurdities of adult priorities, encouraging children to maintain their sense of wonder and questioning. In a world that often pressures children to grow up too quickly, the book serves as a reminder to preserve the innocence and purity of childhood perspectives.\n\nIn conclusion, "The Little Prince" remains profoundly relevant for modern childhood through its celebration of imagination, its emphasis on the importance of human connections, and its critique of adult mindsets. As children navigate the complexities of the modern world, Saint-Exupéry\'s timeless story offers guidance on maintaining a sense of wonder and prioritizing what truly matters in life. "The Little Prince" not only entertains but also educates, making it an invaluable addition to any child\'s literary journey. Through its enduring wisdom, the book continues to touch the hearts and minds of new generations, ensuring its place in the canon of essential childhood literature.', additional_kwargs={}, response_metadata={})]
同理可以用stream的方式生成:
reflection = ''
for chunk in reflect.stream({'messages': [request, HumanMessage(content=essay)]}):
print(chunk.content, end="")
reflection += chunk.content
输出结果:
Your essay on the relevance of "The Little Prince" in modern childhood is well-structured and covers three significant themes: the value of imagination, the importance of human connections, and the critique of adult perspectives. Your points are clearly articulated, and you effectively demonstrate how these themes continue to resonate in today's world. However, there are areas where the essay could be further developed to enhance its depth and impact.
### Recommendations:
1. **Length and Depth:**
- **Expand on Examples:** While you touch upon the themes, adding specific examples from the book would strengthen your argument. For instance, discuss the Little Prince's interaction with the fox to illustrate the importance of relationships and how it teaches the lesson that "what is essential is invisible to the eye."
- **Contemporary Connections:** Consider drawing parallels between the book's themes and current issues or trends in childhood development. For instance, you could explore how modern educational practices (like play-based learning) align with the book's emphasis on imagination.
2. **Style and Tone:**
- **Engage with the Audience:** Include rhetorical questions or personal reflections to make the essay more engaging. Encourage readers to reflect on their own experiences with imagination and human connections.
- **Use of Language:** While the language is mostly clear, varying sentence structure can enhance readability. Mix longer, complex sentences with shorter, impactful ones to maintain reader interest.
3. **Additional Themes:**
- **Materialism and Consumerism:** Expand on the critique of adult perspectives by linking it to modern issues like consumerism and the pressure on children to conform to societal expectations.
- **Emotional Intelligence:** Delve deeper into how the story fosters emotional intelligence and empathy, which are crucial skills for children growing up in a diverse and globalized world.
4. **Conclusion:**
- **Call to Action:** Strengthen the conclusion by suggesting practical ways parents or educators can incorporate the lessons of "The Little Prince" into children's lives, such as through discussions or creative activities inspired by the book.
- **Broader Implications:** Reflect on the broader implications of maintaining these childhood values into adulthood, ensuring that the timeless wisdom of the book continues to influence future generations.
By incorporating these recommendations, your essay will not only provide a comprehensive analysis of "The Little Prince" but also effectively communicate its enduring relevance to modern childhood. This approach will offer a richer, more nuanced perspective that resonates with both young readers and those guiding them.
第三步就是repeat上面的操作
for chunk in generate.stream(
{"messages": [request, AIMessage(content=essay), HumanMessage(content=reflection)]}
):
print(chunk.content, end="")
这里的reflection就是上面的essay评价,request还是HumanMessage(content='write an essay on why the little prince is relevant in modern childhood', additional_kwargs={}, response_metadata={})
输出结果:
Antoine de Saint-Exupéry's "The Little Prince" is a timeless narrative that maintains its profound relevance in modern childhood. Despite being over seventy years old, the book's themes of imagination, the essence of human connections, and its critique of adult perspectives continue to resonate deeply with today's readers. As children grow up in an increasingly fast-paced, digital world, "The Little Prince" offers invaluable lessons that nurture their development. This essay will delve into specific examples from the book to explore its relevance, draw contemporary connections, and suggest practical ways to incorporate its lessons into children's lives.
Firstly, "The Little Prince" emphasizes the value of imagination, which is essential for children's cognitive and emotional development. In a world where screens often dominate children's attention, the book encourages imaginative exploration through its fantastical narrative. The Little Prince’s journey across different planets, each with its own unique inhabitants, serves as an invitation for children to dream and create. For example, the Little Prince's interaction with the rose on his home planet illustrates the depth of imagination required to appreciate beauty and uniqueness. Play-based learning, a modern educational practice that aligns with this theme, supports children's creativity and problem-solving skills. By fostering an environment where imagination is valued, children can learn to approach challenges with curiosity and innovation.
Secondly, the book poignantly explores the importance of human connections, a theme increasingly crucial in today's digital society. The Little Prince's encounter with the fox is a pivotal moment that underscores the significance of relationships. Through the fox, the Little Prince learns that "what is essential is invisible to the eye," highlighting the value of love, trust, and empathy. In an era where digital communication often overshadows face-to-face interactions, these lessons remind children of the irreplaceable value of genuine human bonds. Encouraging children to build meaningful relationships through shared experiences and empathy fosters emotional intelligence, a critical skill in our diverse and globalized world.
Moreover, "The Little Prince" offers a critique of adult perspectives, urging children to question societal norms and values. The story reveals how adults often become consumed by materialism and lose sight of what truly matters. For instance, the Little Prince's visit to the businessman’s planet, where the man is obsessed with counting stars as his possessions, serves as a satire of adult priorities. This critique is particularly relevant today, as children face pressures to conform to societal expectations from a young age. By encouraging children to preserve their sense of wonder and questioning, the book advocates for a world where inner values take precedence over materialistic pursuits.
In conclusion, "The Little Prince" remains profoundly relevant for modern childhood through its celebration of imagination, its emphasis on essential human connections, and its critique of adult mindsets. To incorporate these lessons into children's lives, parents and educators can engage children in discussions about the book's themes, encouraging them to reflect on their own experiences. Creative activities inspired by the story, such as drawing or storytelling, can also help children internalize its messages. By maintaining the timeless wisdom of the book, we can ensure that future generations grow up with the values of imagination, empathy, and introspection. Through its enduring insights, "The Little Prince" continues to touch the hearts and minds of new readers, making it an essential part of any child's literary journey.
第四步我们构建langgraph
from typing import Annotated, List, Sequence
from langgraph.graph import END, StateGraph, START
from langgraph.graph.message import add_messages
from langgraph.checkpoint.memory import MemorySaver
from typing_extensions import TypedDict
class State(TypedDict):
messages: Annotated[list, add_messages]
async def generation_node(state: State) -> State:
print('generation node', [msg.type for msg in state['messages']])
return {"messages": [await generate.ainvoke(state["messages"])]}
async def reflection_node(state: State) -> State:
print('reflection node raw', [msg.type for msg in state['messages']])
# Other messages we need to adjust
cls_map = {"ai": HumanMessage, "human": AIMessage}
# First message is the original user request. We hold it the same for all nodes
translated = [state["messages"][0]] + [
cls_map[msg.type](content=msg.content) for msg in state["messages"][1:]
]
print('reflection node processed', [msg.type for msg in translated])
res = await reflect.ainvoke(translated)
# We treat the output of this as human feedback for the generator
return {"messages": [HumanMessage(content=res.content)]}
- messages
- round 1
- generate
- input: [
human] - output: [
human,ai]
- input: [
- reflect
- input: [
human,ai] -> [human,human] - output: [
human,ai,human]- 问题,回答,反思
- input: [
- generate
- round 2
- generate
- input: [
human,ai,human] - output: [
human,ai,human,ai]- 问题,回答,反思,改进后的回答
- input: [
- reflect
- input: [
human,ai,human,ai] => [human,human,ai,human] - output: [
human,ai,human,ai,human]
- input: [
- generate
- round 3
- generate
- input: [
human,ai,human,ai,human] - output: [
human,ai,human,ai,human,ai]
- input: [
- reflect
- input: [
human,ai,human,ai,human,ai] => [human,human,ai,human,ai,human] - output: [
human,ai,human,ai,human,ai,human]
- input: [
- generate
- round4
- generate
- input: [
human,ai,human,ai,human,ai,human] - output: [
human,ai,human,ai,human,ai,human,ai]
- input: [
- generate
- round 1
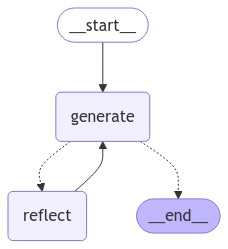
builder = StateGraph(State)
builder.add_node("generate", generation_node)
builder.add_node("reflect", reflection_node)
builder.add_edge(START, "generate")
def should_continue(state: State):
if len(state["messages"]) > 6:
# End after 3 iterations
return END
return "reflect"
builder.add_conditional_edges("generate", should_continue)
builder.add_edge("reflect", "generate")
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
pass
config = {"configurable": {"thread_id": "1"}}
async for event in graph.astream(
{
"messages": [
HumanMessage(
content="Generate an essay on the topicality of The Little Prince and its message in modern life"
)
],
},
config,
):
print(event)
print("---")
这样就会输出多轮的左右互搏结果👆
resp = await graph.ainvoke({
"messages": [
HumanMessage(
content="Generate an essay on the topicality of The Little Prince and its message in modern life"
)
],
},
config,
)
# generation node ['human', 'ai', 'human', 'ai', 'human', 'ai', 'human', 'ai', 'human']
for msg in resp['messages']:
print(msg.type)
"""
human
ai
human
ai
human
ai
human
ai
human
ai
"""
即验证了左右互搏的过程
20241125
华农高百的成绩(华农vlog),看起来如果他们全主力很有机会跑进总决赛(武大居然也没能进总决赛),有点可惜,2~8名咬得很紧,很难想象一年前他们的水平还跟我们差不多。值得注意的是,倩姐赛前测试能跑到15’44"(10月底校运会3000米倩姐只跑了12分06秒,这么看肯定是放海了),算上其他九分站赛,能跑进16分的女生也是屈指可数。
- 倩姐半马PB131,万米41分台,但是女生速度能力较于耐力要差不少,比如有些女跑者万米跑不进40分钟,都能成功全马破三,换算到4000米能干到15分44秒确实很惊艳👍
亦童、王京、张甜这周后三天要综合考,wyl那边破事放下,抱了一周佛脚,不过现在真的越来越水了,三门只用选两门考,而且课程成绩在前10%还能免考,真过分了,但他们外校过来的大部分都没怎么学过运筹优化,加上还非得考计量就很迷。我前年考完出来第一时间把题目记下来,未雨绸缪,其实这两年根本没什么人记题目,老师也不让外传。差不多得了,也不至于不及格。
晚饭后,风雨渐起,寒潮来了,慢跑了半个小时,遇到王长清,带他450跑了会儿,他3K就不行了,慢慢来吧小家伙,男生跑进5分配还是不难的。现在就是养老模式,一点不跑也不太好,那就带一些人慢慢练起来吧。前天我倒是看到何伟杰在跑,她也是挺奇怪,高百之后就退群,有些事也真对付不来。
PS:月跑量170K,均配4’24",上半月100K能有4’13"的均配,下半旬开摆。这个月还是凑个200K吧,之后每天就养老跑个5K,有人陪就多跑些,真不想再练了。

拓印键盘脚本的方法,因为有很多特殊键(非字母按键),可以在pynput.keyboard.Key下找到:
>>> from pynput import keyboard
>>> dir(keyboard.Key)
['__class__', '__doc__', '__members__', '__module__', 'alt', 'alt_gr', 'alt_l', 'alt_r', 'backspace', 'caps_lock', 'cmd', 'cmd_r', 'ctrl', 'ctrl_l', 'ctrl_r', 'delete', 'down', 'end', 'enter', 'esc', 'f1', 'f10', 'f11', 'f12', 'f13', 'f14', 'f15', 'f16', 'f17', 'f18', 'f19', 'f2', 'f20', 'f21', 'f22', 'f23', 'f24', 'f3', 'f4', 'f5', 'f6', 'f7', 'f8', 'f9', 'home', 'insert', 'left', 'media_next', 'media_play_pause', 'media_previous', 'media_volume_down', 'media_volume_mute', 'media_volume_up', 'menu', 'num_lock', 'page_down', 'page_up', 'pause', 'print_screen', 'right', 'scroll_lock', 'shift', 'shift_r', 'space', 'tab', 'up']
可以用keyboard.KeyCode来确认是否属于非字母键,下面是一个监听组合键的方法:
from pynput import keyboard
def on_press(key):
if isinstance(key, keyboard.KeyCode):
# 检查是否同时按下了Ctrl和Shift键
if key.char == 'a' and key.ctrl and key.shift:
print("Ctrl+Shift+A 被按下")
def on_release(key):
pass
with keyboard.Listener(on_press=on_press, on_release=on_release) as listener:
listener.join()
类似之前的鼠标拓印,键盘的具体拓印和自动化操作脚本:
# Operate manually on keyboard
def rubbing_keyboard(rubbing_path = "./keyboard.log"):
def _on_press(key):
logging.info(f"press {key}")
def _on_release(key):
logging.info(f"release {key}")
logger = initialize_logger(rubbing_path, 'w')
with keyboard.Listener(on_press=_on_press, on_release=_on_release) as listener:
listener.join()
terminate_logger(logger)
# Simulate the keyboard action by rubbing
def printing_keyboard(rubbing_path = "./keyboard.log"):
with open(rubbing_path, 'r', encoding="utf8") as f:
lines = f.read().splitlines()
keyboard_controller = keyboard.Controller()
for line in lines:
asctime, filename, levelname, message = line.split('|')
asctime, filename, levelname, message = asctime.strip(), filename.strip(), levelname.strip(), message.strip()
if message.startswith("press"):
key_string = message[6: ]
if key_string.startswith("Key"):
keyboard_controller.press(eval(f"keyboard.{key_string}"))
else:
keyboard_controller.press(eval(key_string))
elif message.startswith("release"):
key_string = message[8: ]
if key_string.startswith("Key"):
keyboard_controller.release(eval(f"keyboard.{key_string}"))
else:
keyboard_controller.release(eval(key_string))
else:
assert False, f"Unknown message: {message}"
time.sleep(.001)
也可以同时监听键盘和鼠标:
def rubbing_mouse_and_keyboard(rubbing_path = "./mouse_keyboard.log"):
def _on_move(x, y):
logging.info(f"move to ({x}, {y})")
def _on_click(x, y, button, pressed):
logging.info(f'{"press" if pressed else "release"} {button} at ({x}, {y})')
def _on_scroll(x, y, dx, dy):
logging.info(f"scroll at ({x}, {y}) by [{dx}, {dy}]")
def _on_press(key):
logging.info(f"press {key}")
def _on_release(key):
logging.info(f"release {key}")
logger = initialize_logger(rubbing_path, 'w')
mouse_listener = mouse.Listener(on_move=_on_move, on_click=_on_click, on_scroll=_on_scroll)
mouse_listener.start()
keyboard_listener = keyboard.Listener(on_press=_on_press, on_release=_on_release)
keyboard_listener.start()
mouse_listener.join()
keyboard_listener.join()
terminate_logger(logger)
注意必须按照start + join的多进程写法,如果还是用with ... as listener: ...join()的方法,只能监听最靠前的一个listener,改名字也不行,必须有start
20241126
寒潮降临,这波还挺有武德,半夜来半夜走,就是昨晚回去淋了一路,而且还是大顶风,冻死。
AK上马D区,PB很难,但他还是会去拼240,今年过去他就30岁,说起来AK生日也是在双十二,跑进240也是生日礼物了。而且去年嘉伟上马也是D区,枪声305,净成绩259,首马破三,含金量可见一斑。
赞助名额都在D区,D区才是大佬云集的地方,水平不比A区差,去年上马被诟病很多,就是因为分区不合理,而且,两万多人的规模就一枪出发,D区的人疯狂往前面挤,堵成麻瓜。
养老第四天,445跑了10K,改前掌跑,跟韬哥一起,左膝感觉好多了。状态基本回满,但也不太想再用力了,每天溜达一会儿很舒服,这才是初衷。上半年嘉伟锡马跑伤后,说好想跑一场不看成绩的比赛,韬哥也说想毕业前跑一次半马,他最近基本上天天下班回来跑五六公里,对于一个专项400和800的人来说,跑个半马也不算太难其实,明年上半年找个容易中签的一起呗。
PS:难得东哥晚上也在操场,在练往返跑。
repeat操作
在w轴上repeat:
repeat(ims[0], 'h w c -> h (repeat w) c', repeat=3)

像 rearrange 一样,repeat 同样对轴的顺序敏感。你可以通过改变括号内的轴的顺序来将一个像素重复三次,而不是将图片整体重复三次:
repeat(ims[0], 'h w c -> h (w repeat) c', repeat=3)

当然也可以在纵向上将一个像素重复三次:
repeat(ims[0], 'h w c -> (h repeat) w c', repeat=3)

同时在 w 和 h 轴的方向上重复:
repeat(ims[0], 'h w c -> (2 h) (2 w) c')
同样,通过调整顺序,可以将一个像素在 h 和 w 的方向上分别重复两次,这有点像 2×2 池化的逆操作。实际上 reduce 和 repeat 可以互相视为逆操作。
repeat(ims[0], 'h w c -> (h 2) (w 2) c')

在一个新的轴上重复:
print(ims[0].shape) # (96, 96, 3)
repeat(ims[0], 'h w c -> h new_axis w c', new_axis=5).shape # (96, 5, 96, 3)
新的张量是原先的 (96, 96, 3) 张量在第二个轴上重复了 5 次得到的。
更多的花里胡哨的操作
https://einops.rocks/1-einops-basics/#fancy-examples-in-random-order
# repeat along a new axis. New axis can be placed anywhere
repeat(ims[0], "h w c -> h new_axis w c", new_axis=5).shape
# interweaving along vertical for couples of images
rearrange(ims, "(b1 b2) h w c -> (h b1) (b2 w) c", b1=2)
# interweaving lines for couples of images
# exercise: achieve the same result without einops in your favourite framework
reduce(ims, "(b1 b2) h w c -> h (b2 w) c", "max", b1=2)
# color can be also composed into dimension
# ... while image is downsampled
reduce(ims, "b (h 2) (w 2) c -> (c h) (b w)", "mean")
# disproportionate resize
reduce(ims, "b (h 4) (w 3) c -> (h) (b w)", "mean")
# spilt each image in two halves, compute mean of the two
reduce(ims, "b (h1 h2) w c -> h2 (b w)", "mean", h1=2)
# split in small patches and transpose each patch
rearrange(ims, "b (h1 h2) (w1 w2) c -> (h1 w2) (b w1 h2) c", h2=8, w2=8)
# stop me someone!
rearrange(ims, "b (h1 h2 h3) (w1 w2 w3) c -> (h1 w2 h3) (b w1 h2 w3) c", h2=2, w2=2, w3=2, h3=2)
# stop me someone!
rearrange(ims, "b (h1 h2 h3) (w1 w2 w3) c -> (h1 w2 h3) (b w1 h2 w3) c", h2=2, w2=2, w3=2, h3=2)
rearrange(ims, "(b1 b2) (h1 h2) (w1 w2) c -> (h1 b1 h2) (w1 b2 w2) c", h1=3, w1=3, b2=3)
# patterns can be arbitrarily complicated
reduce(ims, "(b1 b2) (h1 h2 h3) (w1 w2 w3) c -> (h1 w1 h3) (b1 w2 h2 w3 b2) c", "mean", h2=2, w1=2, w3=2, h3=2, b2=2)
# subtract background in each image individually and normalize
# pay attention to () - this is composition of 0 axis, a dummy axis with 1 element.
im2 = reduce(ims, "b h w c -> b () () c", "max") - ims
im2 /= reduce(im2, "b h w c -> b () () c", "max")
rearrange(im2, "b h w c -> h (b w) c")
这个是变成黑白图👆,下面则是打马赛克:
# pixelate: first downscale by averaging, then upscale back using the same pattern
averaged = reduce(ims, "b (h h2) (w w2) c -> b h w c", "mean", h2=6, w2=8)
repeat(averaged, "b h w c -> (h h2) (b w w2) c", h2=6, w2=8)
翻转+旋转:
rearrange(ims, "b h w c -> w (b h) c")
# let's bring color dimension as part of horizontal axis
# at the same time horizontal axis is downsampled by 2x
reduce(ims, "b (h h2) (w w2) c -> (h w2) (b w c)", "mean", h2=3, w2=3)
rearrange不改变张量中元素的总个数。reduce在保持基本重排语法不变的同时引入了缩减操作(mean, min, max, sum, prod)repeat包括了重复和平铺操作- composition 和 decomposition 是
einops的基石。它们能够也应该被联合起来使用。
20241127
最近新食堂一楼晚上天天人山人海,原来是有大厨莅临,今晚的漳州鼎边趟,不知道为什么里面放了一堆花甲。
亦童准备了大半个月,结果今早高统准备的都没考,跟我说题目跟往年完全不一样,上来前两题都不会,直接就蒙了。说实话对比数院和统院的综合考,我们往年确实太简单了,应该给他们加点难度。
晚饭后慢跑半个小时消食,有一两个男生跟了我不到2K,没有回头看,提到415哥几个还是不太跟得住。另外,有一个这么冷的天还穿半弹的女跑者,大概是410-415在跑2K的间歇,我估摸不可能是学生,问了一下果然是外面的人,毕竟没见过这么强的.
PS:今年高百总决赛有11张外卡,也就是说如果没报满,我们还是有机会去玩一玩的,当然去了也是纯找虐,甚至会被关门,要知道10人×16KM的接力,关门时间只给了11个小时,意味着平均每个人只有66分钟,均配是4’07",这还包含了两个女生,基本上是必被关门。其实到最后还是拼女生,16KM他们男选手基本上也就是55-60分钟这个区间,女生差距就很大了,4分半已经不算差了,但有的甚至能4分以内跑完16KM,去年清华的女选手甚至跑进了1个小时…


-
信息量: I s = log 2 1 p ( s ) I_s=\log_2\frac1{p(s)} Is=log2p(s)1
-
熵:不确定性的度量
- 信息量的期望: ∑ s p ( s ) log 2 1 p ( s ) \sum_s p(s)\log_2 \frac{1}{p(s)} ∑sp(s)log2p(s)1
-
互信息(mutual information)
- 互信息的定义及其与熵/条件熵的关系
- 引入/给定 X X X, Y Y Y 不确定性的减少;
- 引入/给定 Y Y Y, X X X 不确定性的减少;
I ( X , Y ) = ∑ x ∈ X , y ∈ Y P X , Y ( x , y ) log P X , Y ( x , y ) P X ( x ) P Y ( y ) = H ( Y ) − H ( Y ∣ X ) = H ( X ) − H ( X ∣ Y ) \begin{split} I(X,Y)&=\sum_{x\in X,y\in Y} P_{X,Y}(x,y)\log \frac{P_{X,Y}(x,y)}{P_X(x)P_Y(y)}\\ &=H(Y)-H(Y|X)\\ &=H(X)-H(X|Y) \end{split} I(X,Y)=x∈X,y∈Y∑PX,Y(x,y)logPX(x)PY(y)PX,Y(x,y)=H(Y)−H(Y∣X)=H(X)−H(X∣Y)
- 互信息的定义及其与熵/条件熵的关系
条件熵 => 熵的降低/减少
- 天气分布( D D D),一个月内下雨/不下雨的天数均为 15 天,也就是概率为 50%
import numpy as np
-(0.5*np.log2(0.5) + 0.5*np.log2(0.5)) # 1.0
Entropy ( D ) = − ( p ( r ) log p ( r ) + p ( s ) log p ( s ) ) = − ( 0.5 log 0.5 + 0.5 log 0.5 ) = 1 b i t \begin{split} \text{Entropy}(D)&=-(p(r)\log p(r)+p(s)\log p(s))\\ &=-(0.5\log 0.5 + 0.5\log 0.5)\\ &=1bit \end{split} Entropy(D)=−(p(r)logp(r)+p(s)logp(s))=−(0.5log0.5+0.5log0.5)=1bit
这表明在没有任何其他信息的情况下,预测某天的天气(下雨或晴朗)的不确定性为1比特。现在,假设我们提供了一个上下文:如果天气预报说"今天空气湿度很高"。根据过去的经验,我们知道在空气湿度高的日子里,下雨的概率是0.75,不下雨的的概率是0.25。现在我们计算给定这个上下文后的条件熵:
Entropy ( D ∣ context ) = − ( 0.75 log 0.75 + 0.25 log 0.25 ) \text{Entropy}(D|\text{context})=-(0.75\log 0.75+0.25\log 0.25) Entropy(D∣context)=−(0.75log0.75+0.25log0.25)
-(0.75*np.log2(0.75) + 0.25*np.log2(0.25)) #
- probability vs. likelihood
- 概率:P(数据 | 参数)
- 在已知模型参数的情况下,某个特定结果或事件发生的可能性。
- 已知一枚硬币是公平的(正反面概率都是50%),那么抛出正面的概率是0.5。
- 似然:L(参数 | 数据)
- 在观察到特定数据的情况下,模型参数取特定值的支持程度。
- 观察到连续10次抛硬币都是正面,我们想知道这枚硬币是偏向正面的可能性有多大。
- 概率:P(数据 | 参数)
- 以LLM为例
- 训练阶段(似然):
- 在训练GPT模型时,模型通过调整内部参数,使得训练数据的似然最大化。这意味着模型会“学习”如何生成与训练数据分布相似的文本。
- 生成阶段(概率):
- 当模型生成文本时,它使用训练好的参数,基于当前的输入(上下文),计算下一个词的概率分布,并根据这些概率进行采样,从而生成连贯的文本。
- 训练阶段(似然):
from scipy.stats import norm
# Define mean and standard deviation
mean = 32
std_dev = 2.5
# Calculate the probability of the range 32 to 34
# Pr(weight between 32 and 34 grams|mean = 32 and std = 2.5)
probability = norm.cdf(34, mean, std_dev) - norm.cdf(32, mean, std_dev)
f'{probability:.2f}'
# # Pr(weight > 34 grams|mean = 32 and std = 2.5)
probability = 1 - norm.cdf(34, mean, std_dev)
f'{probability:.2f}'
# L(mean=32 and std=2.5 | weight equals 34 grams)
likelihood = norm.pdf(34, mean, std_dev)
f'{likelihood:.2f}'
# L(mean=32 and std=2.5 | weight equals 34 grams)
likelihood = norm.pdf(34, 34, std_dev)
f'{likelihood:.2f}'
带阴影的绘图:
import numpy as np
import matplotlib.pyplot as plt
# Define the range for visualization
x = np.linspace(mean - 4 * std_dev, mean + 4 * std_dev, 500)
y = norm.pdf(x, mean, std_dev)
# Plot the Gaussian curve
plt.figure(figsize=(10, 6))
plt.plot(x, y, label="Gaussian Distribution (Mean=32, Std Dev=2.5)", lw=2)
# Highlight the area for 24 to 32
x_fill = np.linspace(32, 34, 500)
y_fill = norm.pdf(x_fill, mean, std_dev)
plt.fill_between(x_fill, y_fill, color="skyblue", alpha=0.5, label="P(32 ≤ X ≤ 34)")
# Mark the likelihood at x = 34
plt.scatter([34], [norm.pdf(34, mean, std_dev)], color="red", label="Likelihood at X=34")
plt.annotate(
"Likelihood at X=34",
xy=(34, norm.pdf(34, mean, std_dev)),
xytext=(34.5, norm.pdf(34, mean, std_dev) + 0.02),
arrowprops=dict(facecolor='black', arrowstyle="->"),
fontsize=10
)
# Add labels and legend
plt.title("Gaussian Distribution with Mean=32 and Std Dev=2.5", fontsize=14)
plt.xlabel("X Value", fontsize=12)
plt.ylabel("Probability Density", fontsize=12)
plt.legend(fontsize=10)
plt.grid(alpha=0.3)
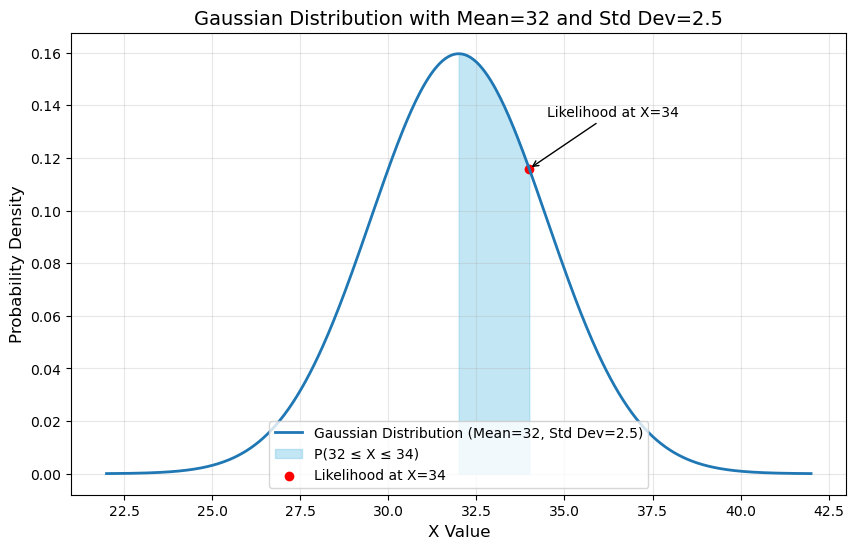
20241128
LXY最近一点没跑,原来是吃坏了。
总决赛给了外卡,现在真的是有机会参加总决赛了。
可是16KM×10人,关门时间只给了11小时,人均4’07"的配速,还要算上两个女生。
有能力跑到3’50"以内配速的只有嘉伟、小崔和我。其他人长距离想跑进4分配都够呛,几乎必然被关门。
但也有比我们水平更差的,我知道肯定不是那些强校的对手的。
而且还缺两个女生,DGL肯定是来不了的,而且16KM对女生实在是太长了。
其实很想去,对吧?晚上九点,认真跑了一会儿,是首马十天之后第一次认真跑,身上一点伤痛都没有了,这是最完好的状态。
PS:果然还是不太甘心,带兄弟们再冲一次吧。

MLE
θ
=
a
r
g
m
a
x
θ
p
θ
(
x
)
=
a
r
g
m
a
x
θ
log
p
θ
(
x
)
\theta = \underset{\theta}{\mathrm{argmax}}\ p_{\theta}(x) = \underset{\theta}{\mathrm{argmax}}\ \log p_{\theta}(x)
θ=θargmax pθ(x)=θargmax logpθ(x)
-
训练集 X = { x 1 , x 2 , ⋯ , x N } X=\left\{x_1,x_2,\cdots, x_N\right\} X={x1,x2,⋯,xN},则 marginal log likelihood( log p θ ( X ) \log p_\theta(X) logpθ(X))
log p θ ( X ) = log ∏ i = 1 N p θ ( x i ) = ∑ i = 1 N log p θ ( x i ) = ∑ i = 1 N log ∫ p θ ( x i , z i ) d z = ∑ i = 1 N log ∫ p θ ( x i ∣ z i ) p θ ( z i ) d z \begin{split} \log p_{\theta}(X) &= \log \prod_{i=1}^{N} p_{\theta}(x_i) \\ &= \sum_{i=1}^{N} \log p_{\theta}(x_{i}) \\ &= \sum_{i=1}^{N} \log \int p_{\theta}(x_i, z_i)dz \\ &= \sum_{i=1}^{N} \log \int p_{\theta}(x_i \lvert z_i)p_{\theta}(z_i)dz \end{split} logpθ(X)=logi=1∏Npθ(xi)=i=1∑Nlogpθ(xi)=i=1∑Nlog∫pθ(xi,zi)dz=i=1∑Nlog∫pθ(xi∣zi)pθ(zi)dz
- z z z 的维度,决定了最后有几重积分;
MLE估计参数 μ , σ \mu, \sigma μ,σ
- 假设观测数据来自正态分布
N
(
μ
,
σ
2
)
\mathcal N(\mu,\sigma^2)
N(μ,σ2),MLE 的目标是找到均值
μ
\mu
μ 和标准差
σ
\sigma
σ 的估计值,使得对数似然函数达到最大值。
ℓ ( μ , σ ; X ) = ∑ i = 1 n log f ( x i ; μ , σ ) \ell(\mu, \sigma; X) = \sum_{i=1}^n \log f(x_i; \mu, \sigma) ℓ(μ,σ;X)=i=1∑nlogf(xi;μ,σ) - 其中,正态分布的概率密度函数为:
f ( x ; μ , σ ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) . f(x; \mu, \sigma) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right). f(x;μ,σ)=2πσ1exp(−2σ2(x−μ)2). - 将其代入对数似然函数,得到:
ℓ ( μ , σ ; X ) = ∑ i = 1 n [ − log ( 2 π σ ) − ( x i − μ ) 2 2 σ 2 ] . \ell(\mu, \sigma; X) = \sum_{i=1}^n \left[ -\log(\sqrt{2\pi}\sigma) - \frac{(x_i - \mu)^2}{2\sigma^2} \right]. ℓ(μ,σ;X)=i=1∑n[−log(2πσ)−2σ2(xi−μ)2].
import numpy as np
from scipy.optimize import minimize
# 生成正态分布的样本数据
np.random.seed(0)
true_mu, true_sigma = 0, 0.1 # 真实的均值和标准差
samples = np.random.normal(true_mu, true_sigma, 1000)
# 定义对数似然函数
def log_likelihood(params, data):
mu, sigma = params
return -np.sum(np.log(np.sqrt(2 * np.pi * sigma**2)) + ((data - mu)**2 / (2 * sigma**2)))
# 定义初始参数估计
initial_params = [0, 1] # 初始猜测的均值和标准差
# 使用梯度下降法找到最大化对数似然函数的参数值
result = minimize(lambda params: -log_likelihood(params, samples), initial_params, method='BFGS')
estimated_mu, estimated_sigma = result.x
result.x
语言模型:
− log P -\log P −logP
- 训练损失的下降表示模型在逐步最大化似然,即模型参数在调整以更好地解释训练数据。
- 交叉熵损失等价于负对数似然(神经网络相同于一个概率分布),最小化损失即最大化似然。
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
corpus = [
"hello how are you",
"i am fine thank you",
"how about you",
"i am doing well",
"thank you very much"
]
word_list = " ".join(corpus).split()
vocab = list(set(word_list))
word2idx = {w: idx for idx, w in enumerate(vocab)}
idx2word = {idx: w for idx, w in enumerate(vocab)}
vocab_size = len(vocab)
vocab_size, word2idx
输出结果:
(13,
{'you': 0,
'very': 1,
'thank': 2,
'fine': 3,
'hello': 4,
'am': 5,
'well': 6,
'are': 7,
'how': 8,
'doing': 9,
'much': 10,
'about': 11,
'i': 12})
def make_dataset(corpus):
input_data = []
target_data = []
for sentence in corpus:
words = sentence.split()
for i in range(len(words)-1):
input_data.append(word2idx[words[i]])
target_data.append(word2idx[words[i+1]])
return input_data, target_data
inputs, targets = make_dataset(corpus)
inputs, targets
# ([4, 8, 7, 12, 5, 3, 2, 8, 11, 12, 5, 9, 2, 0, 1],
# [8, 7, 0, 5, 3, 2, 0, 11, 0, 5, 9, 6, 0, 1, 10])
inputs = torch.LongTensor(inputs)
targets = torch.LongTensor(targets)
class LanguageModel(nn.Module):
def __init__(self, vocab_size, embedding_dim=10):
super(LanguageModel, self).__init__()
self.embed = nn.Embedding(vocab_size, embedding_dim)
self.fc = nn.Linear(embedding_dim, vocab_size)
def forward(self, x):
x = self.embed(x) # [batch_size, embedding_dim]
out = self.fc(x) # [batch_size, vocab_size]
return out
model = LanguageModel(vocab_size)
- 上下文长度:在这个示例中,模型仅基于当前词预测下一个词,因此它实际上是一个二元模型(Bigram Model)。也就是说,它只考虑一个词的上下文来进行预测。
- 无记忆机制:与循环神经网络(RNN)或Transformer等更复杂的模型不同,前馈神经网络没有内部状态或记忆机制,无法捕捉长距离的依赖关系。
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
losses = []
# 训练模型
for epoch in range(100):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
losses.append(loss.item())
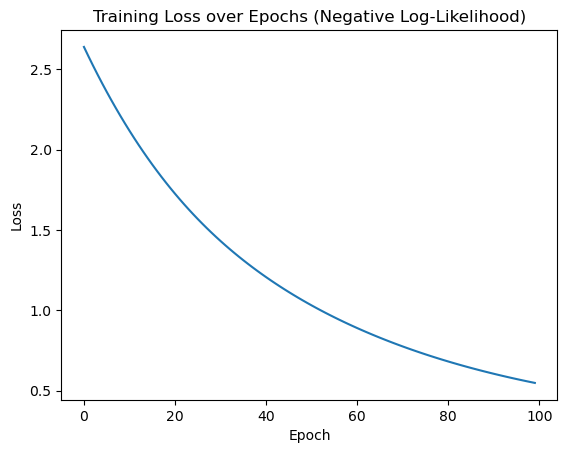
if (epoch+1) % 20 == 0:
print(f"Epoch [{epoch+1}/100], Loss: {loss.item():.4f}")
"""
Epoch [20/100], Loss: 1.7597
Epoch [40/100], Loss: 1.2261
Epoch [60/100], Loss: 0.9018
Epoch [80/100], Loss: 0.6894
Epoch [100/100], Loss: 0.5475
"""
np.log(vocab_size) #
训练损失绘图:
plt.plot(range(len(losses)), losses)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss over Epochs (Negative Log-Likelihood)")
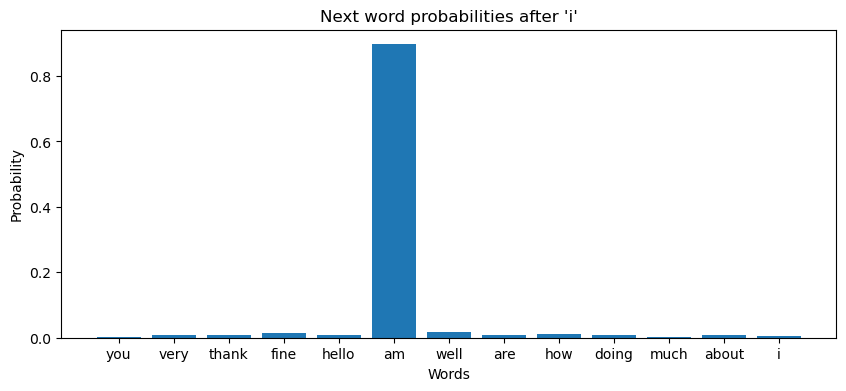
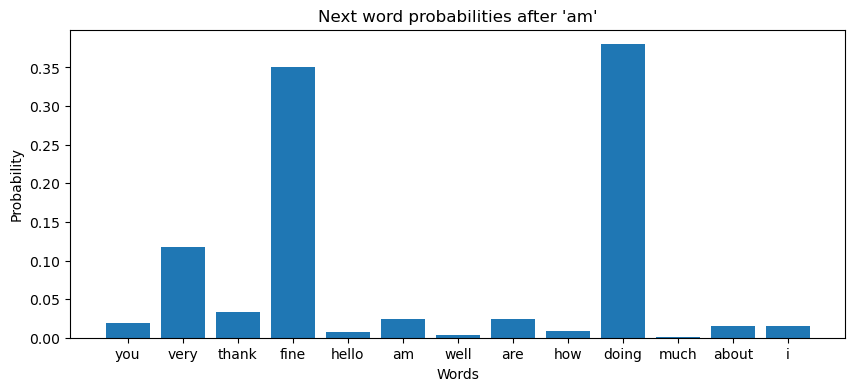
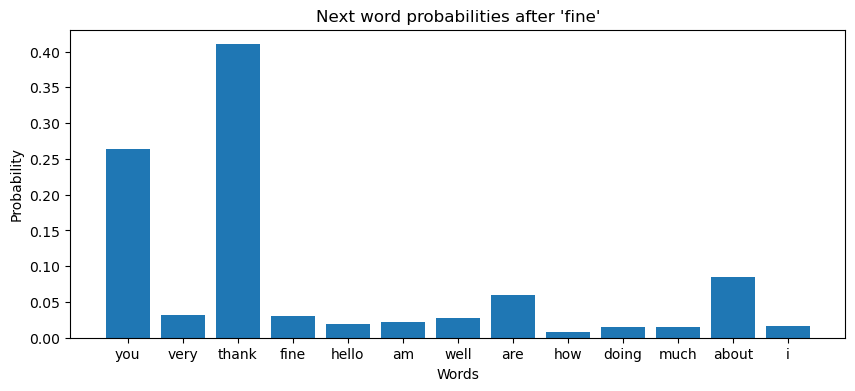
def generate_text(model, start_word, idx2word, word2idx, max_len=5):
model.eval()
words = [start_word]
input_word = torch.LongTensor([word2idx[start_word]])
with torch.no_grad():
for _ in range(max_len):
output = model(input_word)
# 计算概率分布
probabilities = torch.softmax(output, dim=1)
# 可视化概率分布
probs = probabilities.squeeze().cpu().numpy()
plt.figure(figsize=(10,4))
plt.bar([idx2word[i] for i in range(vocab_size)], probs)
plt.xlabel("Words")
plt.ylabel("Probability")
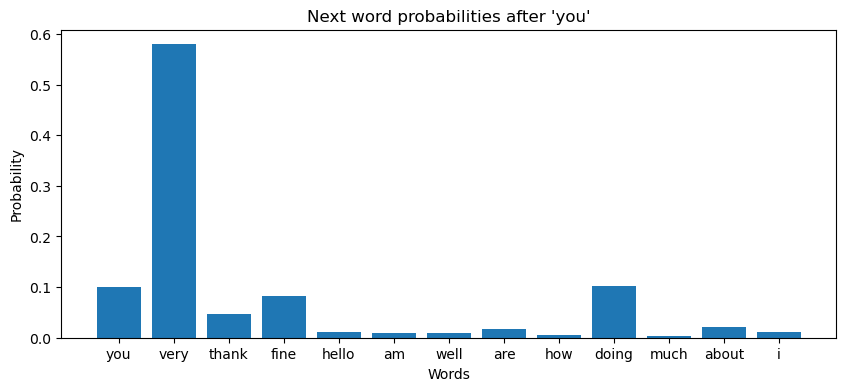
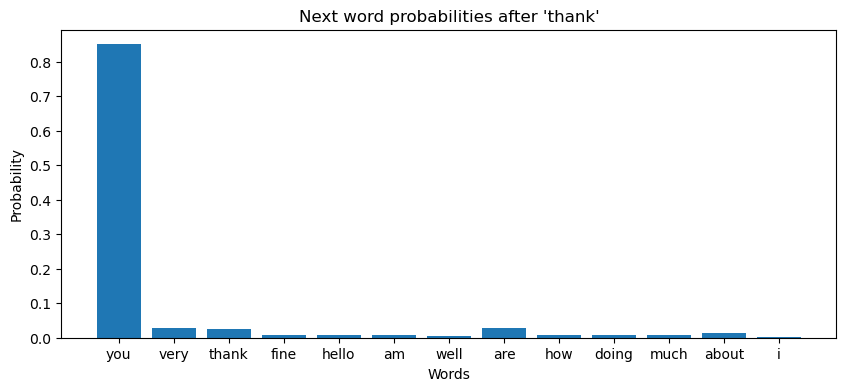
plt.title(f"Next word probabilities after '{words[-1]}'")
plt.show()
# 采样下一个词
predicted_idx = torch.multinomial(probabilities, 1).item()
predicted_word = idx2word[predicted_idx]
words.append(predicted_word)
input_word = torch.LongTensor([predicted_idx])
return ' '.join(words)
start_word = 'i'
generated_sentence = generate_text(model, start_word, idx2word, word2idx)
generated_sentence # 'i am fine you thank you'
20241129
没拿到外卡,已经结束咧!貌似是个拼手速的活,xs。终于可以安心养老了。
晚上下会慢跑5K,月跑凑到200K,月均配4’26",over
西交利物浦跟宁波诺丁汉,这俩发动钞能力拿到外卡就算了,特么南通大学上海站第28名咋也能拿外卡;反观东华上海站第7差10秒没能跑进前6晋级,结果都没拿到外卡,第9华政也给拿到了,换我准得气死不成。
PS:LXY傍晚47分多跑了个10K,一上来就这么用力。
LLM面试题记录
目前主流的LLMs开源模型体系有哪些(Prefix Decoder,Causal Decoder,Encoder-Decoder的区别是什么)
- 在与训练语言模型时代,自然语言处理领域广泛采用了预训练+微调的范式,并诞生了以BERT为代表的Encoder-only架构,以GPT为代表的Decoder-only架构,以T5为代表的Encoder-Decoder架构的大规模预训练语言模型
- 随着GPT系列模型的成功发展,当前自然语言处理领域走向了生成式LLM的道路,Decoder-only架构已成主流,进一步地,Decoder-only架构可以细分为因果解码器(Causal Decoder)和前缀解码器(Prefix Decoder)。学术界提到解码器架构时,通常指因果解码器
下图对三种解码器架构进行对比:

Encoder-Decoder
- Encoder-Decoder架构即原始Transformer的架构,机器翻译
- 编码器端:双向自注意力机制对输入信息编码处理
- 解码器端:交叉注意力与掩码自注意力机制,进而通过自回归方式生成
- 目前只有FLAN-T5等少数LLM是基于Encoder-Decoder搭建
Causal-Decoder
- 主流框架(GPT系列),因果语言模型,包括LLaMa也是
- 使用单向注意力掩码,以确保每个输入token只能注意到过去的token以及本身
- 输入和输出的token通过Decoder以相同方式进行处理
- 在图中,灰色代表两个token互相之间看不到,否则就可以看到,例如Survey可以看到前面的A,但看不到后面的of,Causal Decoder的Sequence Mask矩阵是一种典型的下三角矩阵
- 代表模型:GPT系列,LLaMa(Meta)
Prefix-Decoder
- 又称为非因果解码器架构,对掩码机制修改
- 前缀解码器对于输入(前缀)部分使用双向注意力进行编码,而对于输出部分利用单向掩码注意力,即利用该token本身和前面的token进行自回归预测
- 代表模型:GLM-130B和U-PaLM(Google)
总结:三者区别在于attention mask不同
-
Encoder-Decoder(T5)
- 输入采用双向注意力,对问题编码理解更充分
- 在偏理解的NLP任务上效果好
- 长文本生成效果差,训练效率低
-
Causal Decoder(GPT)
- 自回归LM,预训练和下游应用完全一致,严格遵守只有后面的token才能看到前面token的规则
- 文本生成效果好
- 训练效率高,zero-shot能力更强,具有涌现能力
-
Prefix Decoder(GLM)
- prefix部分的token相互能看到
- 文本生成效果好
LLMs中常用的预训练任务(目标)有哪些?
主要分为三类:

- 语言建模(LM):
- 目标函数:每个token的最大似然
- 本质上,是一种多任务学习过程,因为不同token的预测对应不同的任务(数量、情感等)
- 因此可以潜在地学习到解决不同任务的知识与能力
- 训练效率:Prefix Decoder < Causal Decoder
- Causal Decoder架构会在所有token上计算损失,而Prefix Decoder只在输出上计算损失
- 去噪自编码(Denoising AutoEncoder):
- BERT,T5
- 文本经过一系列随即替换、删除操作,形成损坏的文本,模型需要恢复原文本
- 目标函数就是被损坏的token的最大似然
- 任务设定更为复杂,需要设定token替换策略,替换长度,替换比例,都影响训练效果。目前应用有限,主要是FLAN-T5(不过我记得GLM的预训练任务也是类似的一种创新的任务)
- 混合去噪器(Mixture-of-Denoisers,MoD):统一了DAE和LM
20241130
- 冬日的暖晴,极好的天气,可惜明天这种太阳其实并不太适合跑比赛。
- 又是周六回血,中午鹅汤、三文鱼,晚上骨头汤,可算是吃撑了,最近虽然在养老,其实消耗也不算太少,吃得并没有什么压力。
- 希望AK明天能超常发挥吧,我要是能起得来就骑车去一趟,去年嘉伟毕竟是首马,我到38K处(下外白渡桥的折返)陪了他最后4K,AK都老油条了,说实话真不太想去,骑车太冷,而且不想早起。虽然这场对AK很重要,AK因为工作的原因已经两年没有跑上马了,以前上马都是他每年必跑的项目,今年也是他的第二春了,不知道他最近备赛得怎么样,就算破不了240,希望也能跑到接近240的水平吧。
- PS:CWY搞到了会长的合影,还有alphafly3的签名,这合影看着跟P得似的,xs


面试题记录:
7. LLMs中涌现能力是啥原因
参考资料:张俊林老师《大语言模型的涌现能力:现象与解释》
涌现能力:复杂系统由很多微小个体构成,当这些微小个体凑到一起,相互作用,当数量足够多时,在宏观层面上展现出微观个体无法解释的特殊现象(效果突然变好了)
猜想一:任务的评价指标不够平滑:
- 以Emoji_movie任务来解释,任务是输入Emoji图像,LLM给出完全正确的电影名称,一字不差算对
- 例子中,2M到128B后,模型完全猜对,但其实中途已经慢慢感觉猜对了,还差一点,但是评价指标是精准匹配,因此导致模型的评估出现突然增长。
- 改成平滑的指标就不会有这种跳跃了。
猜想二:复杂任务 v.s. 子任务
- 复杂任务是由多个子任务构成,只有当子任务都学会了,复杂任务才能做对
- 因此发生性能条约
- 这里以国际象棋AI训练为例,合法移动 v.s. 将死
- LLM预测下一步,最终评价指标是将死才算赢,如果按将死评估,发现模型增大,模型缓慢上升,符合涌现的表现。
- 若评估LLM合法移动,而在合法的移动步骤里进行正确选择才够最后将死是个子任务,所以其实这是比将死简单的子任务
- 我们看合法移动随着模型规模,效果持续上升,其实并没有涌现
8. 什么是Scaling Law?谈谈对它的理解
什么是Scaling Law?
-
在训练之前了解模型的能力,以改善大模型的对齐、安全和部署决定。
-
通过测试不同尺寸下模型的性能,然后对大尺寸模型的性能进行预测
-
GPT-4 technical report里对GPT-4性能边界的预测(https:/cdn.openai.com/papers/gpt-4.pdf)
-
定义:用计算量、数据集规模和模型尺寸,来预测模型的最终能力(通常以相对简单的函数形态,如Linear relationship)
在LLM中,我们期望模型能够理解人类语言的一般规律,从而做出与人类相似的表达方式,通过使用大量的数据进行训练从而获得使得模型学习到数据背后的一般规律。
LLM预训练,主要是围绕训练的计算量,数据集规模和模型规模的三方博弈
但是三者的作用到底是多少呢?Scaling Law就是做这个的

-
OpenAI和DeepMind这两家有代表性研究(前者是做AGI,后者着重于高精专的AI,如AlphaGo)
-
2020年,OpenAI的Kaplan团队在Scaling Laws for Neural Language Models,这个我之前看过,博客125139643,arxiv.2001.08361
- 他们发现模型尺寸,数据集大小和训练计算量,三者任一受限时,Loss与其之间存在幂律关系(即两个变量中的一个变量与另一个变量的某个幂次呈正比)
- 因此为了获得最佳性能,必须将三者同步扩大
- 当没有受到其他两个因素限制时,性能与每个单独因素之间呈幂律关系
- 影响模型性能的三个要素之间,每个参数会受到其他两个参数影响。当没有其他两个瓶颈时,性能会急剧上升,影响程度为计算量>参数量>>数据集大小
- 在固定计算预算下,最佳性能可以通过训练参数量非常大的模型,并非在远离收敛前停止实现(early stop)
- 更大的模型在样本效率方面表现更好,能以更少的优化步骤和使用更少的数据量达到相同的性能水平。
- 实际应用中,应该优先考虑训练较大的模型
-
2022年,DeeoMind的Hoffmann团队,在Training Compute-Optimal Large Language Models(arxiv.2203.15556)提出了与OpenAI截然不同的观点
- OpenAI建议在计算预算增加10倍的情况下,如果想保持效果,模型大小应该增加5.5倍,但DeepMind认为是增加1.8倍
- DeepMind认为模型大小和训练Token的数量都应该按等比例扩展,暗示GPT3过度参数化,也就是说参数量太多了,超过了实际所需,且训练不足
- 结论:
- 对于给定的FLOP预算,损失函数有明显的谷底值:
- 模型太小时,在较少数据上训练较大模型是一种改进
- 模型太大时,在更多数据上训练较小模型时一种改进
- 也就是说,在给定计算量下,数据量和模型参数量之间平衡存在最优解
- 在计算成本达到最优情况下,模型大小和训练数据量应该等比例放缩。对于给定参数量的模型,最佳训练数据集大小约为模型参数量的20倍,比如7B模型应该是140B的tokens训练
- 大模型训练需要更加关注数据集的扩展,高质量数据集,数据越多才有用
- 对于给定的FLOP预算,损失函数有明显的谷底值:
-
总结:
- 定义:计算量、数据集规模、模型大小,来预测性能
- OpenAI:三者两两相关,当两个没有瓶颈时,性能会急剧上升,重要性计算量>参数量>>数据集大小
- DeepMind:三者应等比例扩展
20241201
昨天搞得太晚,晚上去补了昨天该做的力量(30箭步×8,负重20kg),虽然不打算跟去年冬训一样拼,但是一周一次力量还是保证一下,不排除明年上半年再冲击一次全马破三的可能性,缺的只是状态。
结束跟白辉龙慢跑5K@418,感觉一般,老年人要有老年人样子。
战报:
上马会长国内第一209,不得不说会长确实是有东西的,贾俄还是拉了,跟AK一样太急,他俩是老乡,估计还是沾亲带故的。
丰配友瓦伦西纳20712(PB),只差不到20秒就能击破国家记录,一跃历史第二人。
AK上马245,D区突围,这个成绩的质量不比南马244差,但38K之后还是崩了,走了一段,不过就算没有崩也很难跑进240,前面肯定是急了,节奏不够好。而且就最近两个月,他跑了两个全马,以及柴古55K和宁海60K,身体可能还是没有完全调整过来。像我半年只能拼一次命,然后就只能躺平了,人和人的身体素质还是不能同日而语的。
YY首半马135,意料之中,他应该可以跑进130的,不过首半马能到135已经很好了。
蒋蔚文(86级金融)上马301(PB),令人咋舌,快60岁了,竟然还试图去破三?记得21年高百的时候,蒋蔚文当时10K是41分台,现在看起来比当时还要强,真的是令人羡慕。
大模型幻觉相关面试题记录:
1. 什么是大模型幻觉?
- 定义:(一本正经的胡说八道)模型生成的文本不遵循原文(一致性,Faithfulness)或者不符合事实(事实性,Factualness)
- Faithfulness:是否遵循输入的上下文
- Factualness:是否符合世界知识
- 在传统任务中,幻觉大都是指Faithfulness:
- 信息冲突(Instrinsic Hallucination):LMs在生成回复时,与输入信息产生了冲突,例如摘要问题里,abstract和document的信息不一致
- 无中生有(Extrinsic Hallucination):LMs在生成回复时,输出一些并没有体现在输入中的额外信息,比如邮箱地址、电话号码、住址,并且难以验证其真假
- 而面向LLMs,我们通常考虑的幻觉则是Factualness:
- 因为我们应用LLMs的形式是open-domain chat,而非局限于特定任务,所以数据源可以看作任意的世界知识。LLMs如果生成不在输入信息中的额外信息,但是符合事实的,也是有帮助的。
2. 为什么出现幻觉
- 从数据角度:训练数据可信度问题,重复数据问题
- 从模型角度(主要原因)
- 模型结构:如果是较弱的backbone(如RNN),可能导致严重的幻觉问题,但LLMs时代不太可能存在这一问题
- 解码算法:研究表明,如果使用不稳定性较高的采样算法(如top-p)会诱导LLMs出现严重的幻觉问题。甚至可以故意在解码算法中加入一些随机性,进一步让LLMs胡编乱造(利用该方法可以生成一些负样本)
- top-p采样(也称为核采样)是一种引入不确定性的采样算法,常用来生成更加多样化和创造性的问题,原理是模型从预测概率最高的token开始累加,当这些token的概率综合达到设定的阈值(p值)后停止,从而在这些候选token中随机选取一个词生成。可以避免仅生成概率最高的词,从而提升文本的流畅性和丰富度。
- 暴露偏差:训练和测试阶段不匹配的exposure bias问题可能导致LLMs出现幻觉,特别是生成long-form response的时候
- 训练阶段一切都是真实的文本,但生成时,模型只能按照自己之前生成的文本继续生成,蝴蝶效应。
- 参数知识:LLMs在预训练阶段记忆的错误知识,导致严重的幻觉问题
3. 如何评估大模型幻觉问题?
- 现有的传统幻觉评估指标和人类结果相关性往往较低,同时大多是task-specific的
- 主要评估方法:基于参考的评估和无参考的评估
-
方法一:基于参考的评估**(reference-based)
- 通常只能评价Faithfulness,无法评价Factualness,因此通常不适用于LLMs
- 指在评估生成内容的准确性时,使用参考文本(如人类标准答案)或原始信息源作为对比
- 衡量两者的重叠程度或相似度,指标如ROUGE和BLEU
- 优点:适合一些标准化的生成任务
- 缺点:许多任务标准答案可能并非唯一,生成内容多样化,因此该方法的灵活性不足。而且LLMs开放生成任务,很难找到完美的参考答案
- 指标主要有两类:
- BLEU和ROUGE这种统计重叠度的指标(Source information + Target Reference)
- Knowledge F1(Source information only)
- Knowledge F1时一种用于评估NLG的指标,主要用于检测幻觉
- 思路:比较模型生成内容和参考知识老远之间的匹配度,判断准确性和一致性
- 计算原理:
- 知识检索:首先,从任务相关的知识库或上下文信息中提取模型生成时可参考的源知识
- 知识匹配:然后,将模型的生成输出和源知识中的信息进行比对,找出哪些时和源知识一致的
- F1得分计算:最后,通过Precision和Recall来计算F1得分
-
方法二:无参考评估
- 旨在不用标准答案或特定参考来检测模型生成内容的准确性和一致性
- 各种方法:
- 基于信息抽取(IE):将生成内容转化为结构化知识,如RDF三元组,然后用另一个模型来验证三元组的真实性
- 缺点:IE模型本身可能出错,抽取的信息不对,后续检验也就无效了;且只能受限于三元组只知识,很多知识不能用三元组表达,局限性。
- 基于问答(QA):
- 首先,使用一个问题生成模型,根据模型的生成内容来产生一系列相关的问答对
- 然后,利用源信息,使用问答模型回答这些问题
- 最后,将问答模型的答案和最初生成的答案对比,通过匹配度评估生成内容的真实性
- 缺点:IE模型的错误传播,QA过程依然依赖IE模型生成的;而且难以评估Factualness,因为QA模型回答问题时,源信息未必包含所有所需知识,可能无法准确回答或验证的情况。
- 基于自然语言推理(NLI):
- 即通过验证生成文本是否由源信息的蕴含来判断其是否存在幻觉
- 但是问题是幻觉未必和蕴含划等号
- 缺点:
- 性能有限:目前NLI模型在事实喝茶方面表现一般,难以准确验证生成内容
- 无法检测世界知识相关的幻觉:世界知识太大了,很难检测蕴含关系
- 粒度有限:局限于句子级别的蕴含检测,无法更细粒度
- 幻觉和蕴含不等价:幻觉不仅仅是不蕴含,比如Putin is president和Putin is U.S. president在语义上并非幻觉,但是会被判断为蕴含
- NLI中,蕴含意味着一个句子能够逻辑推导出另一个句子,但不涉及判断信息的真实性
- 基于事实性分类指标(Factualness Classification Metric)
- 通过人工标注或构造包含幻觉和真实信息的数据集,训练分类模型来检测新生成的文本是否符合事实。但是依赖标注,成本高昂。
- 人工评估
- 基于信息抽取(IE):将生成内容转化为结构化知识,如RDF三元组,然后用另一个模型来验证三元组的真实性
-
总结:分为基于参考的评估和**无参考的评估
4. 如何缓解LLMs幻觉问题
- 基于数据的工作:高质量数据集构造
- 人工标注:训练数据、评测数据
- 自动筛选:筛除不良数据、数据加权,如给可靠度高的数据赋予高的权重,如wikipedia,不可靠的数据赋予低的权重
- 模型层面:从模型结构和训练方式入手
- 模型结构:模型结构方面的改进主要关注在设计能够更好地利用来源信息的结构,例如
- 编码更多信息:用GNN编码这种融入能反映人类思维偏好的结构,更好地专注输入信息
- 减少生成随机性:在解码时减少模型生成内容地随机性(多样性和准确性是互相掣肘的),提高准确性(temperature)
- 检索增强:引入外部检索系统(如LLaMaIndex)
- 训练方式:
- 可控文本生成:将幻觉控制设为一个可控属性,让模型生成时更少产生幻觉
- 提前规划内容框架:采用sketch-to-content方法,先规划一个大致的框架再生成具体内容,有助于结构化信息并减少偏差
- 强化学习:通常模型使用MLE来优化训练目标,这可能会暴露偏差。通过引入强化学习,将减少幻觉的目标作为奖励函数,调整模型生成过程
- 多任务学习:设计额外任务,使模型在执行多项任务时能提升应对幻觉的能力
- 后处理:纠错模块设计
一篇相关的论文:
- A Stitch in Time Savess Nine: Detecting and Mitigating Hallucinations of LLMs by Validating Low-Confidence Generation
- arxiv.2307.03987
- 幻觉的生成是会传播的,比如一句话出现幻觉,后续可能会更加严重。(预防很重要,防患于未然)
- logit输出值可以用来获取幻觉信号。比如,计算了一个logits值,并展示了当这个得分很低时,模型更容易出现幻觉。其实就是置信度很低的解码输出时不可信的,容易出幻觉
基于上述两个发现,作者提出了主动检测和减轻幻觉的方法,如图所示:
- 给定一个输入,通过迭代生成句子,并积极检测和缓解幻觉现象
- 在检测阶段,首先识别重要概念,计算模型在这些概念上的不确定性,并通过检索相关知识验证这些不确定概念的正确性
- 在缓解阶段,使用检测到的知识作为依据,修复存在幻觉的句子
- 最后,将修复后的句子添加到输入中(和之前生成的句子一起),然后生成下一个句子
20241202
原来柿子不能一天吃太多,容易胃结石。
最近亦童在搞三维高斯溅射(3D Gaussian Splatting)的东西,3D图像编辑,现在3D的特征表示还是以点云和高斯球这种形式,这就跟2D很不一样,像素的概念没有很自然地从2D升到3D,因为3D图形的内部是不可知的。跟计算机图形学有点关系,正好跟之前laya air3和unity很相关。目前3D图像生成,依赖多视(multi-view),其实还是以2D方法为主,只是拟合的参数是高斯球的协方差和球心,偏优化那边的方法,有很多非训练的手段来做。
晚饭后养生5K消食,感觉状态还行,有点想用些力气,但还是算了,就这么维持一下也差不多了。
PS:发现一到12月,就是LXY每天10K的时节。不过,最近天气确实很好,寒潮来就很痛苦了。
RAG相关面试题
- RAG为生成式模型提供了与外部世界互动的解决方案
- RAG的主要作用类似搜索引擎,找到用户提问最相关的知识或对话历史,并结合原始问题(查询),创造信息丰富的prompt,指导模型生成准确输出
- 本质是利用了In-context Learning的原理
- RAG = 检索技术 + LLM提示
RAG特点:
- 依赖大语言模型来强化信息检索和输出:RAG需要结合大型语言模型(LLM)来进行信息的检索和生成,但如果单独使用RAG它的能力会受到限制。也就是说,RAG需要依赖强大的语言模型支持,才能更有效地生成和提供信息。
- 能与外部数据有效继承:能与外部数据有效集成:RAG能够很好地接入和利用外部数据库的数据资源。这一特性弥补了通用大模型在某些垂直或专业领域的知识不足,比如行业特定的术语和深度内容,能提供更精确的答案。
- 数据隐私和安全保障:通常,RAG所连接的私有数据库不会参与到大模型的数据集训练中。因此,RAG既能提升模型的输出表现,又能有效地保护这些私有数据的隐私性和安全性,不会将敏感信息暴露给大模型的训练过程。
- 表现效果因多方面因素而异:RAG的效果受多个因素的影响,比如所使用的语言模型的性能、接入数据的质量、AI算法的先进性以及检索系统的设计等。这意味着不同的RAG系统之间效果差异较大,不能一概而论。
2. RAG的总体思路
总体思路:参考https://aibook.ren/archives/what-is-rag

- RAG可分为5个基本流程:知识文档准备、嵌入模型、向量数据库、查询检索、生产回答
-
知识文档准备:
- 文档格式:WORD,TXT,CSV,EXCEL,PDF,图片,视频
- 需要使用专门的文档加载器(如PDF提取)或多模态模型(如OCR技术),将丰富的知识源转换为LLMs可理解的纯文本数据
- 文档切片:针对长文档,需要切割,以便更高效地
-
嵌入模型:text-to-tensor,稀疏离散的文本转为密集精确的张量表征,捕捉上下文的关系和核心含义
-
向量数据库:嵌入模型生成的张量存储到数据库
-
Chroma:
- 轻量级、易用性、开源。
- 快速搭建小型语义搜索,提供高效的近似最近邻搜索(ANN),支持多种向量数据类型和索引方法,易于集成到现有的应用程序中。
- 小型语义搜索原型、研究或教学项目。
- 适合初学者和小型项目
-
Pinecone:
- 实时性、高性能、可扩展。
- 大规模数据集上的实时搜索,亚秒级的查询响应时间,支持大规模向量集的高效索引和检索,提供高度可伸缩的分布式架构。
- 实时推荐系统、大规模电商搜索引擎、社交媒体内容过滤。
- 适合需要高性能和实时性的大型应用
-
Weaviate:
- 语义搜索、图数据库、多模态。
- 构建智能助手、知识图谱,支持多模态数据(文本、图像等)的语义搜索,提供强大的查询语言和推理能力。
- 复杂知识图谱应用、智能问答系统、多模态内容管理平台。
- 适合需要复杂查询和推理能力的知识密集型应用
-
Milvus:
- 大规模数据、云原生、高可用性。
- 专为处理超大规模向量数据而设计,提供云原生的分布式架构和存储方案,支持多种索引类型和查询优化策略。
- 大规模内容检索平台、图像和视频搜索、智能安防系统。
- 适合需要处理超大规模数据的云端应用
-
Faiss:
- 高效性、灵活性、Facebook支持。
- 提供高效的相似度搜索和稠密向量聚类能力,支持多种索引构建方法和查询优化策略,易于与深度学习框架集成(如PyTorch)。
- Facebook内部语义搜索和推荐系统、广告技术平台、深度学习应用中的向量检索模块。
- 适合需要高效相似度搜索和丰富社区支持的大型应用
-
-
查询检索:用户问题会被输入到嵌入模型中进行向量化处理,然后系统在向量数据库中搜索与该问题语义相似的知识文本或历史对话记录返回。
-
生产回答:最终用户提问会和检索得到的信息结合,构建一个提示模板,输入到LLMs中,生成回答。
3. 如何评价RAG项目效果的好坏
-
针对检索环节的评估:
-
MRR(平均倒数排名),查询(或推荐请求)的排名倒数
- MEAN Reciprocal Rank,MRR,多用于衡量搜索引擎、推荐系统等根据查询返回的多个结果的相关性
- M R R = 1 n ∑ i = 1 n 1 r i MRR=\frac1n\sum_{i=1}^n \frac1{r_i} MRR=n1∑i=1nri1
-
Hits Rate(命中率):前k项中,包含正确信息的检索项数目占比
-
NDCG(归一化折扣累计增益):DCG的两个思想
- 高关联度的结果比一般关联度的结果更影响最终的指标得分
- 有高关联度的而己过出现在更靠前的位置时,指标会越高
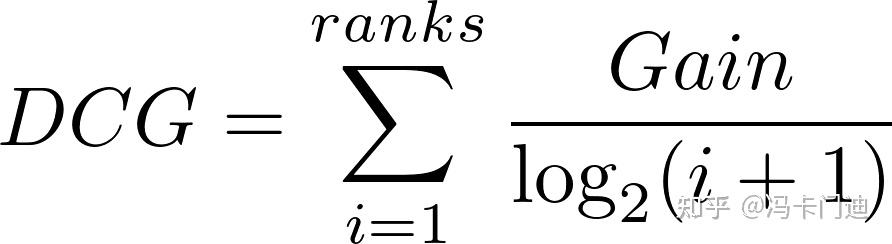
参考:排序算法评估:NDCG(归一化折扣累计增益Normalized Discounted Cumulative Gain)
-
-
针对生成环节的评估
-
非量化:完整性、正确性、相关性
-
量化:Rouge-L指标
-
Rouge-L是一种用于评价文本生成质量的指标,通常在自动病要、机器翻译和文本生成任务中使用。它是Rouge(Recall-Oriented Understudy for Gisting Evaluation)评估指标系列中的一种,专门通过**最长公共子序列(Longest Common Subsequence,LCS)**来测量生成文本和参考文本之间的相似性。
-
基本思想大由多个专家分别生成人工摘要,构成标准搞要集,将系统生成的自动摘要与人工生成的标准摘要相对比,通过统计二者之间重叠的基本单元(n-gram、词序列和词对)的数目,来评价摘要的质量。
-
Rouge-L的计算主要包括两个方面:
-
Recall:参考文本中与生成文本匹配的最长公共子序列的长度,与参考文本的总长度之比
-
Precision:生成文本中与参考文本匹配的最长公共子序列的长度,与生成文本的总长度之比
-
然后用这个PR值计算F1,即:
R o u g e − L = 2 P R P + R Rouge-L = \frac{2PR}{P+R} Rouge−L=P+R2PR
-
-
Rouge-L比Rouge-1或Rouge-2更能衡量文本生成的结构和顺序是否与参考文本接近,因此在长文段的连贯性和句子顺序检测上具有优势。
-
-
20241203
年底赶工,忙里偷闲整了个烂活,明天再优化一下,感觉很难剪枝,5×5很快,到7×7直接就卡死不动了。
PS:晚上5K慢跑,不知道被谁跟了一段,于是补了2K请他吃点辣堡,小伙子还得练。
每日演兵算法:
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@stu.sufe.edu.cn
import time
import itertools
from pprint import pprint
from copy import deepcopy
FORMATION_ABBR_TO_NAME = {
"BDQX": "北斗七星阵",
"FS": "锋矢阵",
"SLCS": "双龙出水阵",
"JQHH": "九曲黄河阵",
"JS": "金锁阵",
"F": "方阵",
"XX": "玄襄阵",
"GX": "钩形阵",
"YZCS": "一字长蛇阵",
"SC": "三才阵",
"TM": "天门阵",
"HY": "混元阵",
"YY": "鸳鸯阵",
}
FORMATION_NAME_TO_ABBR = {_abbr: _name for _name, _abbr in FORMATION_ABBR_TO_NAME.items()}
# 生成给定日期的日历拼图
def generate_calendar_puzzle(month = 12, day = 3):
month_days = [31, 28, 31, 30, 31, 60, 31, 31, 30, 31, 30, 31]
calendar_puzzle = [[0] * 7 for i in range(7)]
for i in range(35 - month_days[month - 1]):
calendar_puzzle[6][7 - i - 1] = 1
calendar_puzzle[(day - 1) // 7 + 2][(day - 1) % 7] = 1
calendar_puzzle[0][6] = 1
calendar_puzzle[1][6] = 1
calendar_puzzle[(month - 1) // 6][(month - 1) % 6] = 1
return calendar_puzzle
# 定义阵型及其变体
def define_formation_variants(names):
abbrs = map(lambda _name: FORMATION_NAME_TO_ABBR[_name], names)
# 北斗七星阵
BDQX = [
[[1, 0], [1, 1], [0, 1], [0, 1]],
[[0, 1], [1, 1], [1, 0], [1, 0]],
[[1, 0], [1, 0], [1, 1], [0, 1]],
[[0, 1], [0, 1], [1, 1], [1, 0]],
[[0, 0, 1, 1], [1, 1, 1, 0]],
[[1, 1, 0, 0], [0, 1, 1, 1]],
[[0, 1, 1, 1], [1, 1, 0, 0]],
[[1, 1, 1, 0], [0, 0, 1, 1]],
]
# 锋矢阵
FS = [
[[1, 1, 1], [1, 0, 0], [1, 0, 0]],
[[1, 1, 1], [0, 0, 1], [0, 0, 1]],
[[0, 0, 1], [0, 0, 1], [1, 1, 1]],
[[1, 0, 0], [1, 0, 0], [1, 1, 1]],
]
# 双龙出水阵
SLCS = [
[[1, 1], [1, 0], [1, 1]],
[[1, 1], [0, 1], [1, 1]],
[[1, 1, 1], [1, 0, 1]],
[[1, 0, 1], [1, 1, 1]],
]
# 九曲黄河阵
JQHH = [
[[0, 1, 1], [0, 1, 0], [1, 1, 0]],
[[1, 1, 0], [0, 1, 0], [0, 1, 1]],
[[1, 0, 0], [1, 1, 1], [0, 0, 1]],
[[0, 0, 1], [1, 1, 1], [1, 0, 0]],
]
# 金锁阵
JS = [
[[1, 0], [1, 1], [1, 1]],
[[0, 1], [1, 1], [1, 1]],
[[1, 1, 1], [1, 1, 0]],
[[1, 1, 1], [0, 1, 1]],
[[1, 1], [1, 1], [1, 0]],
[[1, 1], [1, 1], [0, 1]],
[[1, 1, 0], [1, 1, 1]],
[[0, 1, 1], [1, 1, 1]],
]
# 方阵
F = [
[[1, 1, 1], [1, 1, 1]],
[[1, 1], [1, 1], [1, 1]],
]
# 玄襄阵
XX = [
[[1, 1, 1, 1], [1, 0, 0, 0]],
[[1, 1, 1, 1], [0, 0, 0, 1]],
[[1, 1], [0, 1], [0, 1], [0, 1]],
[[1, 1], [1, 0], [1, 0], [1, 0]],
[[1, 0, 0, 0], [1, 1, 1, 1]],
[[0, 0, 0, 1], [1, 1, 1, 1]],
[[0, 1], [0, 1], [0, 1], [1, 1]],
[[1, 0], [1, 0], [1, 0], [1, 1]],
]
# 钩形阵
GX = [
[[1, 0], [1, 0], [1, 1], [1, 0]],
[[0, 1], [0, 1], [1, 1], [0, 1]],
[[1, 1, 1, 1], [0, 1, 0, 0]],
[[1, 1, 1, 1], [0, 0, 1, 0]],
[[0, 1], [1, 1], [0, 1], [0, 1]],
[[1, 0], [1, 1], [1, 0], [1, 0]],
[[0, 1, 0, 0], [1, 1, 1, 1]],
[[0, 0, 1, 0], [1, 1, 1, 1]],
]
# 一字长蛇阵
YZCS = [
[[1, 1, 1, 1, 1]],
[[1], [1], [1], [1], [1]],
]
# 三才阵
SC = [
[[1, 1, 1], [0, 1, 0], [0, 1, 0]],
[[0, 1, 0], [0, 1, 0], [1, 1, 1]],
[[1, 0, 0], [1, 1, 1], [1, 0, 0]],
[[0, 0, 1], [1, 1, 1], [0, 0, 1]],
]
# 天门阵
TM = [
[[0, 1, 0], [1, 1, 1], [0, 1, 0]],
]
# 混元阵
HY = [
[[0, 1, 0], [0, 1, 1], [1, 1, 0]],
[[0, 1, 0], [1, 1, 0], [0, 1, 1]],
[[1, 0, 0], [1, 1, 1], [0, 1, 0]],
[[0, 0, 1], [1, 1, 1], [0, 1, 0]],
[[0, 1, 1], [1, 1, 0], [0, 1, 0]],
[[1, 1, 0], [0, 1, 1], [0, 1, 0]],
[[0, 1, 0], [1, 1, 1], [0, 0, 1]],
[[0, 1, 0], [1, 1, 1], [1, 0, 0]],
]
# 鸳鸯阵
YY = [
[[0, 1, 1], [1, 1, 0], [1, 0, 0]],
[[1, 1, 0], [0, 1, 1], [0, 0, 1]],
[[0, 0, 1], [0, 1, 1], [1, 1, 0]],
[[1, 0, 0], [1, 1, 0], [0, 1, 1]],
]
formation_variants = dict()
for abbr in abbrs:
formations = eval(abbr)
index = -1
new_abbr = abbr
while True:
if not new_abbr in formation_variants:
formation_variants[new_abbr] = list(map(lambda _formation: {"matrix": _formation, "sparse": generate_sparse_formation(_formation)}, formations))
break
else:
# 可能出现的重复阵型,添加不同的序号后缀作为命名区分
index += 1
new_abbr = f"{abbr}_{index}"
return formation_variants
# 阵型稀疏表示:即只存储formation矩阵中数值为1的坐标
def generate_sparse_formation(formation):
sparse_formation = list()
formation_height, formation_width = len(formation), len(formation[0])
for i in range(formation_height):
for j in range(formation_width):
if formation[i][j] == 1:
sparse_formation.append((i, j))
return sparse_formation
# 快速检查当前拼图是否还可能有解
def can_prune(puzzle, puzzle_height, puzzle_width):
# 注意到阵型至少由5个块组成,且除了方阵之外,其他所有阵型出现的块数都是5
# 因此可以在代码中,把方阵放在第一个位置,优先放入,接下来只需要判断剩余连通块中的空余块的数量,是否是5的倍数即可
# 使用BFS递归算法判断给定坐标(_x, _y)所在连通块的连通块数
checked_blocks = list() # 存储已经检查过的拼图上的空闲块的坐标
def _bfs(_x, _y):
checked_blocks.append((_x, _y))
_neighbors = list()
if _x > 0:
_neighbors.append((_x - 1, _y)) # 上
if _y > 0:
_neighbors.append((_x, _y - 1)) # 左
if _x < puzzle_height - 1:
_neighbors.append((_x + 1, _y)) # 下
if _y < puzzle_width - 1:
_neighbors.append((_x, _y + 1)) # 右
for _i, _j in _neighbors:
if (_i, _j) in checked_blocks or puzzle[_i][_j] == 1:
# 已经遍历过该邻居了
continue
else:
_bfs(_i, _j)
for x in range(puzzle_height):
for y in range(puzzle_width):
if puzzle[x][y] == 1 or (x, y) in checked_blocks:
# 我们只找空闲的连通块
continue
print(x, y, checked_blocks)
_bfs(x, y)
print(checked_blocks, len(checked_blocks))
input()
if len(checked_blocks) % 5 == 0:
continue
else:
return True
return False
# 给定拼图与所有可用的阵型,给出解答
def solve(puzzle,
formation_matrix_and_sparse_list, # 可用阵型,形如:({"matrix": List[List[Int]], "sparse": List[Tuple(x, y)]}, ...)
solution_id = list(), # 用于迭代的求解列表List[Int],存储阵型的序号
solution_xy = list(), # 用于迭代的求解列表List[(x, y)],存储阵型放入位置的坐标
puzzle_height = 7,
puzzle_width = 7,
is_prune = False, # 是否采用剪枝策略
):
# 检查拼图上的空余块数是否和剩余阵型的总块数匹配,如果不匹配,问题显然无解
total_formation_blocks = 0
for formation_id, formation_matrix_and_sparse in enumerate(formation_matrix_and_sparse_list):
if not formation_id in solution_id:
total_formation_blocks += len(formation_matrix_and_sparse["sparse"])
total_empty_blocks = sum([row.count(0) for row in puzzle])
if total_formation_blocks != total_empty_blocks:
print(f"问题无解:当前所有阵型的块数总和{total_formation_blocks},拼图剩余块数{total_empty_blocks}")
return False
elif total_formation_blocks == 0:
# 拼图填满,成功!
print(f"成功找到一组解:{solution_id}, {solution_xy}")
with open("solution.txt", 'a', encoding="utf8") as f:
f.write(f"{solution_id}\t{solution_xy}\n")
return True
# 剪枝(关键技巧!!)
if is_prune:
if solution_id and can_prune(puzzle, puzzle_height, puzzle_width):
return False
# 准备一个拼图的副本
puzzle_copy = deepcopy(puzzle)
for formation_id, formation_matrix_and_sparse in enumerate(formation_matrix_and_sparse_list):
# 取一个阵型,试着把它放入拼图
# 首先检查该阵型是否已经被使用过了
if formation_id in solution_id:
continue
# 放入策略是该阵型的左上角的块(即formation[0][0])依次放入拼图的每一个位置
# 检查合法性,如果不合法则依次移动窗口
formation_matrix, formation_sparse = formation_matrix_and_sparse["matrix"], formation_matrix_and_sparse["sparse"]
formation_height, formation_width = len(formation_matrix), len(formation_matrix[0])
is_accommodate = False
for x in range(puzzle_height - formation_height + 1):
for y in range(puzzle_width - formation_width + 1):
# 遍历拼图每一个可以容纳阵型的位置:
# x: 0 => puzzle_height - formation_height
# y: 0 => puzzle_width - formation_width
# 判断当前阵型是否可以放入拼图的(x, y)位置
can_put_in = True
puzzle_updated = deepcopy(puzzle_copy)
for i, j in formation_sparse:
# 检查阵型的每一个块是否可以被容纳(基于阵型矩阵的稀疏表示来搜索,这样循环的次数会少一些)
# i, j就是阵型上块所在的相对坐标
# x + i, y + j是阵型上的块放入拼图的绝对坐标
if puzzle_copy[x + i][y + j] == 1:
# 当前位置已经被其他阵型的块占据,也可能本来就不能放入
can_put_in = False
break
else:
# 当前块空闲,直接放入
puzzle_updated[x + i][y + j] = 1
if can_put_in:
# 阵型可以放入拼图的(x, y)位置,则放入
# 更新拼图,求解列表
is_accommodate = True
solution_id_updated = solution_id + [formation_id]
solution_xy_updated = solution_xy + [(x, y)]
result_flag = solve(
deepcopy(puzzle_updated),
formation_matrix_and_sparse_list,
solution_id = solution_id_updated,
solution_xy = solution_xy_updated,
puzzle_height = puzzle_height,
puzzle_width = puzzle_width,
)
if result_flag:
# 说明接下来的存在某分支找到了正确的解答,则终止(需求只要找到一个正解即可)
return True
else:
# 不可放入,直接删除puzzle_update,释放内存
del puzzle_updated
if not is_accommodate:
# 说明当前阵型无法在拼图上的任何位置被放入
# 此时到达叶子节点
# print(f"分支无解:第{formation_id}块无法被放入拼图")
# pprint(puzzle)
return False
return False
# 运行每日练兵
def run():
with open("solution.txt", 'w', encoding="utf8") as f:
pass
# 生成今日拼图
month, day = int(time.strftime("%m")), int(time.strftime("%d"))
calendar_puzzle = generate_calendar_puzzle(month, day)
print(f"{month}月{day}日拼图:")
pprint(calendar_puzzle)
# 生成今日阵型
names = ["方阵", "北斗七星阵", "九曲黄河阵", "钩形阵", "金锁阵", "玄襄阵", "双龙出水阵", "锋矢阵"]
formation_variants = define_formation_variants(names)
n_products = 1
for formations in formation_variants.values():
n_products *= len(formations)
print(f"共计{n_products}种不同的阵型组合")
# 遍历所有阵型并求解
for i, formation_matrix_and_sparse_list in enumerate(itertools.product(*formation_variants.values())):
if i % 1 == 0:
print(i, time.strftime("%Y-%m-%d %H:%M:%S"))
# pprint(formation_matrix_and_sparse_list)
solve(puzzle = calendar_puzzle,
formation_matrix_and_sparse_list = formation_matrix_and_sparse_list,
solution_id = [],
solution_xy = [],
puzzle_height = len(calendar_puzzle),
puzzle_width = len(calendar_puzzle[0]),
is_prune = True,
)
# 测试样例一
def test_1():
with open("solution.txt", 'w', encoding="utf8") as f:
pass
calendar_puzzle = [[0] * 6 for i in range(6)]
pprint(calendar_puzzle)
formation_variants = define_formation_variants(names = ["方阵", "方阵", "方阵", "方阵", "方阵", "方阵"])
pprint(formation_variants)
n_products = 1
for formations in formation_variants.values():
n_products *= len(formations)
print(f"共计{n_products}种不同的阵型组合")
# 遍历所有阵型并求解
for i, formation_matrix_and_sparse_list in enumerate(itertools.product(*formation_variants.values())):
print(i, time.strftime("%Y-%m-%d %H:%M:%S"))
# pprint(formation_matrix_and_sparse_list)
solve(puzzle = calendar_puzzle,
formation_matrix_and_sparse_list = formation_matrix_and_sparse_list,
solution_id = [],
solution_xy = [],
puzzle_height = len(calendar_puzzle),
puzzle_width = len(calendar_puzzle[0]),
)
# 测试样例二
def test_2():
with open("solution.txt", 'w', encoding="utf8") as f:
pass
calendar_puzzle = [[0] * 5 for i in range(5)]
pprint(calendar_puzzle)
formation_variants = define_formation_variants(names = ["金锁阵", "双龙出水阵", "玄襄阵", "九曲黄河阵", "三才阵"]) # 不能找到
formation_variants = define_formation_variants(names = ["双龙出水阵", "九曲黄河阵", "三才阵", "玄襄阵", "金锁阵"]) # 能找到
formation_variants = define_formation_variants(names = ["双龙出水阵", "玄襄阵", "九曲黄河阵", "三才阵", "金锁阵"]) # 不能找到
# formation_variants = define_formation_variants(names = ["双龙出水阵", "金锁阵", "九曲黄河阵", "三才阵", "玄襄阵"]) # 能找到
pprint(formation_variants)
n_products = 1
for formations in formation_variants.values():
n_products *= len(formations)
print(f"共计{n_products}种不同的阵型组合")
# 遍历所有阵型并求解
for i, formation_matrix_and_sparse_list in enumerate(itertools.product(*formation_variants.values())):
if i % 1 == 0:
print(i, time.strftime("%Y-%m-%d %H:%M:%S"))
# pprint(formation_matrix_and_sparse_list)
solve(puzzle = calendar_puzzle,
formation_matrix_and_sparse_list = formation_matrix_and_sparse_list,
solution_id = [],
solution_xy = [],
puzzle_height = len(calendar_puzzle),
puzzle_width = len(calendar_puzzle[0]),
is_prune = True,
)
# 测试样例三(测试剪枝)
def test_3():
puzzle = [
[1, 1, 0, 0, 0, 0, 1],
[1, 1, 0, 0, 0, 1, 1],
[1, 1, 1, 0, 0, 0, 0],
[0, 1, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 1, 1, 1, 1, 1],
]
print(can_prune(puzzle, 7, 7))
if __name__ == "__main__":
run()
# test_1()
# test_2()
# test_3()
20241204
恢复了一些元气,嘉伟貌似去了tesla
又要下雨,大概寒潮又要来了,周末是总决赛,跟去年一样冻死人的天气。去年那天刚好是寒潮第二天,下午我在操场带着手套跑了10圈就被风吹得头疼不行,早上一堆人还背心二分裤,甚至女生都这么穿,有人跑完就倒地,局外人很难理解的疯狂。可惜,我现在也是局外人了。
PS:依然是5K慢跑,看到YZZ被薅去陪LXY跑了10K多。寒潮来该停了。
后来想了一个自以为很妙的剪枝法,就是说如果存在某个连通块的块数不是5的倍数,就剪掉,但实际下来速度还是很慢,5×5的拼盘,5个阵型,4096种组合,跑了有20多分钟。改写成可以装饰lru_cache的函数形式还是不好使,跟原先一点优化不带的方法几乎完全没区别。
# 快速检查当前拼图是否还可能有解
def can_prune(puzzle, puzzle_height, puzzle_width):
# 注意到阵型至少由5个块组成,且除了方阵之外,其他所有阵型出现的块数都是5
# 因此可以在代码中,把方阵放在第一个位置,优先放入,接下来只需要判断剩余连通块中的空余块的数量,是否是5的倍数即可
# 使用BFS递归算法判断给定坐标(_x, _y)所在连通块的连通块数
checked_block = list() # 存储已经检查过的拼图上的空闲块的坐标
def _bfs(_x, _y):
checked_block.append((_x, _y))
_neighbors = list()
if _x > 0:
_neighbors.append((_x - 1, _y)) # 上
if _y > 0:
_neighbors.append((_x, _y - 1)) # 左
if _x < puzzle_height - 1:
_neighbors.append((_x + 1, _y)) # 下
if _y < puzzle_width - 1:
_neighbors.append((_x, _y + 1)) # 右
for _i, _j in _neighbors:
if (_i, _j) in checked_block:
# 已经遍历过该邻居了
continue
else:
_bfs(_i, _j)
for x in range(puzzle_height):
for y in range(puzzle_width):
if puzzle[x][y] == 1 or (x, y) in checked_block:
# 我们只找空闲的连通块
continue
_bfs(x, y)
if len(checked_block) % 5 == 0:
continue
else:
return True
return False
# 使用缓存加速(失败,加速不明显)
def solve_cached(puzzle, # 原始日历拼图
formation_matrix_and_sparse_list, # 可用阵型,形如:({"matrix": List[List[Int]], "sparse": List[Tuple(x, y)]}, ...)
puzzle_height = 7,
puzzle_width = 7,
total_formation = 8,
is_prune = False,
):
@lru_cache(None)
def _solve_cached(_solution_id, # 以元组表示(列表不支持哈希缓存),比如给定5个阵型,已经放入第0个和第2个阵型,则可以记录为(0, 2)
_solution_xy, # 以元组表示,比如上面例举的阵型(列表不支持哈希缓存),第0个放在(0, 0),第2个放在(3, 4),则记录为((0, 0), (3, 4))
):
# 算法终止
if len(_solution_id) == total_formation:
# 阵型全部放入,意味着拼图填满,成功!
print(f"成功找到一组解:{_solution_id}, {_solution_xy}")
with open("solution.txt", 'a', encoding="utf8") as f:
f.write(f"{_solution_id}\t{_solution_xy}\n")
return True
# 根据_solution_id和_solution_xy复原当前的日历拼图情况
_puzzle = deepcopy(puzzle)
for _formation_id, (_x, _y) in zip(_solution_id, _solution_xy):
# 遍历每一个阵型及其放置的位置
_formation_sparse = formation_matrix_and_sparse_list[_formation_id]["sparse"]
for _i, _j in _formation_sparse:
assert not _puzzle[_x + _i][_y + _j], f"{(_x, _i, _y, _j)}, {_current_puzzle}"
_puzzle[_x + _i][_y + _j] = 1
# 剪枝(关键技巧!!)
if is_prune:
if _solution_id and can_prune(_puzzle, puzzle_height, puzzle_width):
print("剪枝")
return False
# 准备一个拼图的副本
_puzzle_copy = deepcopy(_puzzle)
for _formation_id, _formation_matrix_and_sparse in enumerate(formation_matrix_and_sparse_list):
# 取一个阵型,试着把它放入拼图
# 首先检查该阵型是否已经被使用过了
if _formation_id in _solution_id:
continue
# 放入策略是该阵型的左上角的块(即formation[0][0])依次放入拼图的每一个位置
# 检查合法性,如果不合法则依次移动窗口
_formation_matrix, _formation_sparse = _formation_matrix_and_sparse["matrix"], _formation_matrix_and_sparse["sparse"]
_formation_height, _formation_width = len(_formation_matrix), len(_formation_matrix[0])
_is_accommodate = False
for _x in range(puzzle_height - _formation_height + 1):
for _y in range(puzzle_width - _formation_width + 1):
# 遍历拼图每一个可以容纳阵型的位置:
# _x: 0 => puzzle_height - _formation_height
# _y: 0 => puzzle_width - _formation_width
# 判断当前阵型是否可以放入拼图的(_x, _y)位置
_can_put_in = True
_puzzle_updated = deepcopy(_puzzle_copy)
for _i, _j in _formation_sparse:
# 检查阵型的每一个块是否可以被容纳(基于阵型矩阵的稀疏表示来搜索,这样循环的次数会少一些)
# _i, _j就是阵型上块所在的相对坐标
# _x + _i, _y + _j是阵型上的块放入拼图的绝对坐标
if _puzzle_copy[_x + _i][_y + _j] == 1:
# 当前位置已经被其他阵型的块占据,也可能本来就不能放入
_can_put_in = False
break
else:
# 当前块空闲,直接放入
_puzzle_updated[_x + _i][_y + _j] = 1
if _can_put_in:
# 阵型可以放入拼图的(x, y)位置,则放入
# 更新拼图,求解列表
_is_accommodate = True
_solution_id_updated = list(_solution_id) + [_formation_id]
_solution_xy_updated = list(_solution_xy) + [(_x, _y)]
# # 我感觉不需要排序,因为_solution_id_updated应该本来就是升序的
# _xy_to_id = {_xy: _id for _id, _xy in zip(_solution_id_updated, _solution_xy_updated)}
# _solution_id_updated = sorted(_solution_id_updated)
# _solution_xy_updated = sorted(_solution_xy_updated, key = lambda _xy: _xy_to_id[_xy])
_result_flag = _solve_cached(
_solution_id = tuple(_solution_id_updated),
_solution_xy = tuple(_solution_xy_updated),
)
if _result_flag:
# 说明接下来的存在某分支找到了正确的解答,则终止(需求只要找到一个正解即可)
return True
else:
# 不可放入,直接删除puzzle_update,释放内存
del _puzzle_updated
if not _is_accommodate:
# 说明当前阵型无法在拼图上的任何位置被放入
# 此时到达叶子节点
return False
# 应该是到不了这里的
return False
_solve_cached(_solution_id = tuple(), _solution_xy = tuple())
_solve_cached.cache_clear() # 清除缓存
然后我想到一个绝妙的方法,把拼盘变成一个向量,阵型也变成向量,这样问题变成整数规划,类似背包,并且想到了更好的剪枝法:
- 考虑各种拼盘的各种旋转和翻折,事实上一个拼图对应8种不同的等价形式(旋转4次,翻转2次,4×2=8),我只取这8种当中二进制值最小的那个拼盘去做动态规划,这样状态就是拼盘的二进制码和剩余可用的阵型的编号。
- 而且这里面还有一个很妙的点,就是这刚好是一个正方形的拼盘,都不用考虑旋转翻折后长宽对调的问题,反正,都一样。
- 所以提前准备好所有阵型及其变体的二进制编码,直接避开了阵型旋转翻折排列组合的问题
这样如果不需要求解法,所有阵型都用0和1值表示块和空白即可,状态很少,考虑旋转翻折的话。
如果需要求解法,那么就需要给不同阵型使用不同的数字编码块(2,3,…),这样的坏处就是状态变多了,使用缓存时效率大大下降。
代码如下:
# 使用动态规划:这里我们用编码,所以无需用到稀疏表示,matrix即可
def solve_dp(puzzle, # 原始日历拼图
formation_variants, # 可用阵型及其变形,形如:{"XX": List[Dict{matrix: List[List[Int]], sparse: List[Tuple(x, y)]}], "XXX": 类似前面}
for_solution = False, # 是否找到解法
):
# 将给定的puzzle矩阵转为puzzle_height×puzzle_width长度的编码向量(以零一字符串表示)
def _puzzle_to_code(_puzzle):
return ''.join([''.join(map(str, _puzzle_row)) for _puzzle_row in _puzzle])
# _puzzle_to_code的逆运算
def _code_to_puzzle(_puzzle_code):
_puzzle = numpy.zeros((puzzle_height, puzzle_width))
_pointer = -1
for _i in range(puzzle_height):
for _j in range(puzzle_width):
_pointer += 1
_puzzle[_i, _j] = _puzzle_code[_pointer]
return _puzzle
# 注意到一个puzzle通过旋转/翻转操作,一共会有8种等价的变体(自身与翻转)
# 取最大的编码向量(以零一字符串的数值作为表示)作为唯一编码值,以减少很多重复
# 特别地,每日演兵是一个正方阵,所以连行列都不需要区分,这在下面的formation编码中有很大的助益
# 最大编码值对应的拼图,即块集中在左上角
def _puzzle_to_unique_code(_puzzle):
_rotate_puzzle_copy = _puzzle.copy()
_rotate_puzzle_copy_flip = numpy.fliplr(_rotate_puzzle_copy)
_codes = [_puzzle_to_code(_rotate_puzzle_copy), _puzzle_to_code(_rotate_puzzle_copy_flip)]
# 旋转3次
for _ in range(3):
_rotate_puzzle_copy = numpy.rot90(_rotate_puzzle_copy)
_rotate_puzzle_copy_flip = numpy.rot90(_rotate_puzzle_copy_flip)
_codes.append(_puzzle_to_code(_rotate_puzzle_copy))
_codes.append(_puzzle_to_code(_rotate_puzzle_copy_flip))
return max(_codes)
# 生成formation编码()的方法:
# - 将formation_matrix每行扩展到跟puzzle_width(零填充)
# - 然后类似_puzzle_to_code的方法,但是要把右侧的零给排除
# - _block_number表示用哪个数字表示块,一般用1,但是为了能看到最终求解的结果,还需要存一份区分不同阵型编码的(即colorful,五彩斑斓的)的阵型编码
def _formation_to_code(_formation_matrix, _block_number = 1):
_formation_matrix = numpy.array(_formation_matrix, dtype=int) * _block_number
_formation_matrix_expand = numpy.concatenate([_formation_matrix, numpy.zeros((_formation_matrix.shape[0], puzzle_width - _formation_matrix.shape[1]))], axis=1)
_formation_matrix_expand = numpy.asarray(_formation_matrix_expand, dtype=int)
_formation_code = ''.join([''.join(map(str, _formation_row)) for _formation_row in _formation_matrix_expand])
return _formation_code.rstrip('0')
# 将formation在指定的位置(pointer)插入puzzle
# 如果指定的位置无法插入,则返回False与空字符串
# 否则返回True和插入后的puzzle_code
def add_formation_code_to_puzzle_code(_puzzle_code, _formation_code, _pointer):
# print(_puzzle_code, len(_puzzle_code))
# print(_formation_code, len(_formation_code))
_result_code = str()
# 插入部分:_pointer, _pointer + 1, ..., _pointer + len(_formation_code) - 1
_start_pointer, _end_pointer = _pointer, _pointer + len(_formation_code)
for _i in range(_start_pointer, _end_pointer):
_formation_char_int = int(_formation_code[_i - _pointer])
_puzzle_char_int = int(_puzzle_code[_i])
if _formation_char_int == 0 or _puzzle_char_int == 0:
# 阵型和拼图至少有一个在当前位置是空的
_result_code += str(_formation_char_int + _puzzle_char_int)
else:
# 否则无法插入阵型
return False, None
# 补上头尾
_result_code = _puzzle_code[: _start_pointer] + _result_code + _puzzle_code[_end_pointer: ]
return True, _result_code
# 注意到,一个形状为(formation_height, formation_width)的阵型,只可能在以下的_pointer插入拼图:
# - _pointer = i × puzzle_width + j
# - 其中:i取值范围是(0, 1, ..., puzzle_height - formation_height),j取值范围是(0, 1, ...., puzzle_width - formation_width)
def _generate_possible_pointer(_formation_height, _formation_width):
for _i in range(puzzle_height - _formation_height + 1):
for _j in range(puzzle_width - _formation_width + 1):
yield _i * puzzle_width + _j
# 递归算法
@lru_cache(None)
def _dp(_puzzle_unique_code, # Str 当前拼图的编码值(唯一编码值)
_remained_formation_ids, # Tuple 剩余可用的阵型编码
_for_solution = False, # 是否需要找到确切的解法
):
# 终止条件:_puzzle_unique_code全是1,或者_remained_formation_ids为空
if not _remained_formation_ids:
# 找到一组解
print("成功找到一组解!")
for _char in _puzzle_unique_code:
assert int(_char) > 0
if _for_solution:
pprint(_code_to_puzzle(_puzzle_unique_code))
return True
# 遍历每个可用的阵型
for _remained_formation_id in _remained_formation_ids:
# 遍历每个可用阵型的变体
_can_put_in = False
if for_solution:
formation_variant_codes = formation_codes_num[_remained_formation_id]
else:
formation_variant_codes = formation_codes[_remained_formation_id]
for _formation_variant_code, (_formation_height, _formation_width) in zip(formation_variant_codes, formation_sizes[_remained_formation_id]):
# 遍历每个可能可以插入的位置
for _possible_pointer in _generate_possible_pointer(_formation_height, _formation_width):
# 试着插入
_add_flag, _updated_puzzle_code = add_formation_code_to_puzzle_code(
_puzzle_code = _puzzle_unique_code,
_formation_code = _formation_variant_code,
_pointer = _possible_pointer,
)
# 成功:可以插入阵型
if _add_flag:
# 则迭代
_remained_formation_ids_list_copy = list(_remained_formation_ids)
_remained_formation_ids_list_copy.remove(_remained_formation_id)
_updated_remained_formation_ids = tuple(_remained_formation_ids_list_copy)
_result_flag = _dp(
_puzzle_unique_code = _updated_puzzle_code,
_remained_formation_ids = _updated_remained_formation_ids,
_for_solution = _for_solution,
)
_can_put_in = True
if _result_flag:
# 找到一个即可
return True
# 失败:此处不可以插入阵型
else:
pass
if not _can_put_in:
# 当前阵型以及它的所有变体无法在任何位置插入
return False
# 将puzzle转为矩阵
if isinstance(puzzle, list):
puzzle = numpy.array(puzzle, dtype=int)
puzzle_height, puzzle_width = puzzle.shape
assert puzzle_height == puzzle_width, "动态规划算法目前仅支持正方阵的求解"
total_formation = len(formation_variants)
print(f"拼图形状:{(puzzle_height, puzzle_width)}")
print(f"阵型总数:{total_formation}")
# 将阵型转为矩阵:List[List[Str(formation_code)]]
formation_codes = list() # 零一字符串(块统一用1表示)
formation_codes_num = list() # 每个阵型的块用不同的数字表示
formation_sizes = list() # 记录阵型的高和宽
for i, formation_name in enumerate(formation_variants):
formation_variant_codes = list()
formation_variant_codes_num = list()
formation_variant_sizes = list()
for formation_variant in formation_variants[formation_name]:
formation_matrix = formation_variant["matrix"]
formation_variant_codes.append(_formation_to_code(formation_matrix, _block_number = 1))
formation_variant_codes_num.append(_formation_to_code(formation_matrix, _block_number = i + 2))
formation_variant_sizes.append((len(formation_matrix), len(formation_matrix[0])))
formation_codes.append(formation_variant_codes)
formation_codes_num.append(formation_variant_codes_num)
formation_sizes.append(formation_variant_sizes)
_puzzle_unique_code = _puzzle_to_unique_code(puzzle)
# _dp(_puzzle_unique_code, _remained_formation_ids=tuple(range(total_formation)), _for_solution = False)
_dp(_puzzle_unique_code, _remained_formation_ids=tuple(range(total_formation)), _for_solution = for_solution)
# 测试五(动态规划)
def test_5():
example_id = 1
calendar_puzzle, formation_variants = generate_test_example(example_id)
pprint(calendar_puzzle)
######################################################
time_string = time.strftime("%Y-%m-%d %H:%M:%S")
with open(f"{example_id}.txt", 'w', encoding="utf8") as f:
f.write("Start: " + time_string + '\n')
t = time.time()
solve_dp(
puzzle = numpy.array(calendar_puzzle, dtype=int),
formation_variants = formation_variants,
for_solution = True,
)
time_string = time.strftime("%Y-%m-%d %H:%M:%S")
with open(f"{example_id}.txt", 'a', encoding="utf8") as f:
f.write("End: " + time_string + '\n')
print(time_string)
print(time.time() - t)
5×5的情况快了极多,无论是否求解法,都能在0.1秒左右跑完动态规划,是之前用时的万分之一以内。(下面展示找解法的一种运行结果,不同数字表示不同阵型的块)
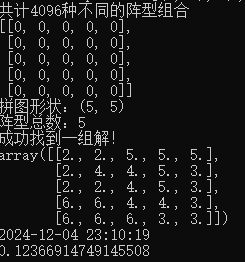
但是7×7依然很慢,之前的算法估测要100万小时跑一张图(估算,5×5有4096种阵型组合,7×7有激增到50万以上),现在还在测,但整数规划确实本来就很慢,这个问题显然是NP难的。肯定还有更快的方法,但是很难具有通用性(比如对任意拼图,任意阵型,不过可能对一些刁钻的位置可以先处理?)
试过让GPT来拼,它做不到。之前看机器人学的东西,其实GPT是有找图形规律的能力的,就是让它去做行测题那种。因为所有跟序列相关的都可以用LLM来生成

用到一些小技巧:
lru_cache清除缓存:
@lru_cache(None)
def f(a, b):
print("执行f")
return a + b + c
c = 100
print(f(1, 2))
f.cache_clear() # 清除缓存,否则执行结果是错误的,因此c改变了
c = 102
print(f(1, 2))
在NumPy中,可以使用numpy.flip或numpy.fliplr/numpy.flipud函数来翻转矩阵。
numpy.flip可以沿着指定的轴翻转数组。
numpy.fliplr(flip left/right)和numpy.flipud(flip up/down)分别实现了在水平方向和垂直方向上的翻转。
旋转矩阵则是np.rot90
20241205
去蜀地源放纵了一顿,感觉最近食堂有点不太走心。去之前凑了2K,回来等了会儿还是太撑,下去又消食凑了3K,养老跑者现状,狠不下心光吃不练。
本周日高百总决赛前瞻。兰交大有半马113的女选手首发,女子首发基本上都是半马130以内的选手,恐怖如斯。成都理工则是半马119的谷金锦锦首发,吉大说不怕大家笑话,他们队里连男子113的都没有(这么看我们好歹还有一个113的AK,也算是牌面了,虽然是11356)。民大派出4名半马110台的选手,重大男子最差都是半马117的选手。现在半马跑不进120真是拿不出手了,其实不是完全没有可能吧,扬马12405,如果能再靠前一些出发,肯定能跑到124以内的,其实也就配速再快个10秒而已。
开始轮椅,只用1000秒出头就跑出7×7的了(但是对比5×5只要0.1秒出头,这个差了得有10000倍),很舒服,其实测下来for_solution是True还是False区别几乎没有,虽然显然False的情况下,可以排除的重复情况要多得多。看来缓存的作用并没有想象得那么大。True的情况下,因为不同的formation用的是不同的编号,所以旋转翻折拼图就很难出现重复的情况了,能剪的枝就少很多。
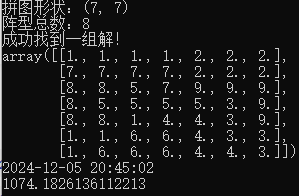
吃了方阵的福利,如果不是锁定方阵,时间应该是现在的4倍。
一个幻觉消除的思路:
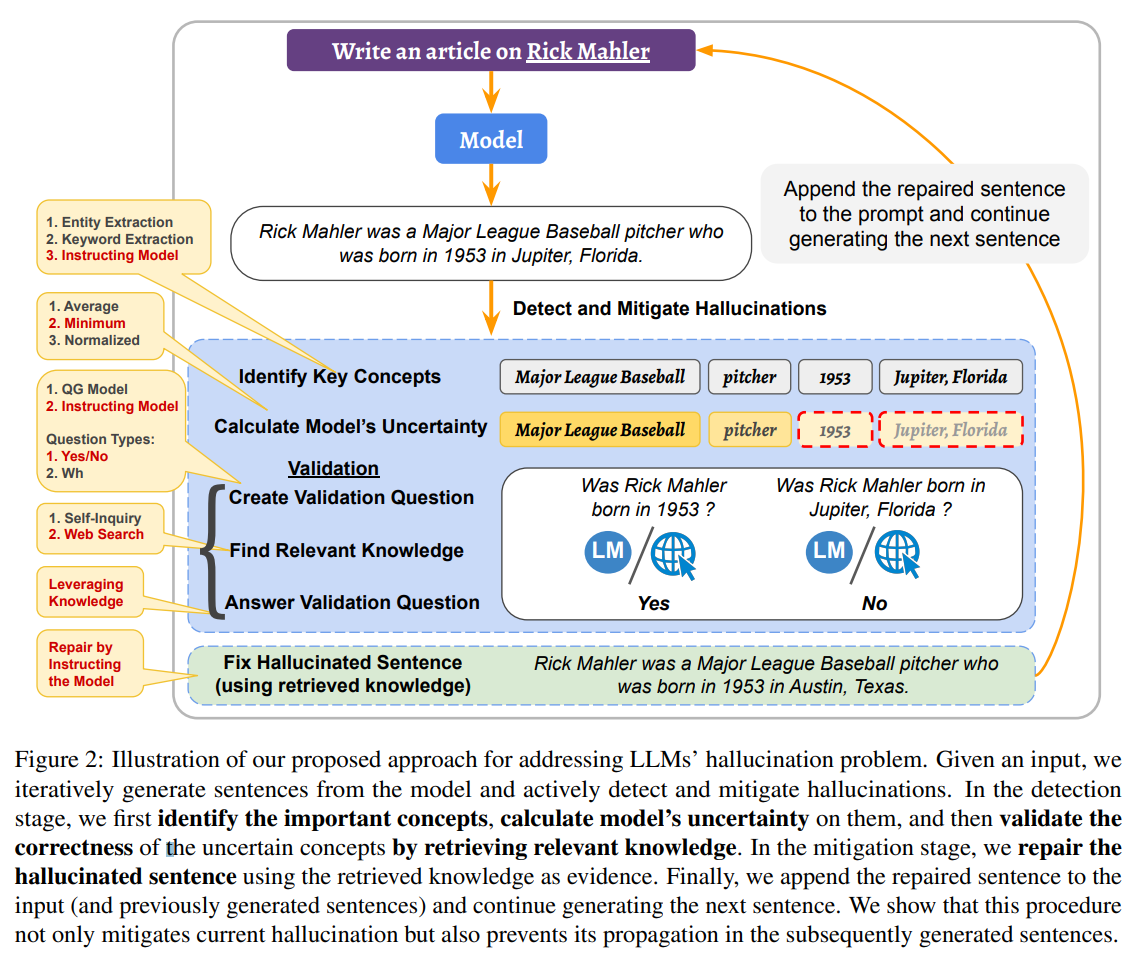
- 首先抽取输入语句种的关键概念(实体、关键词),然后计算它们的不确定性(这个就是单纯基于生成模型解码的logits来判断的,虽然解释性一般,但是的确有用)
- 这里就是发现出生地和出生日期是很不确定的
- 然后基于这些不确定的phrase,我们去检索相关的知识(self-inquiry,上下文搜索;网络搜索,外部搜索),作为辅助的信息
- 消除阶段,基于输入+检索得到的辅助信息,使用问题生成模型生成问答对,根据问答内容来修正这些实体,然后将修正好的句子放回去。
幻觉是有蝴蝶效应的,前面有幻觉,后面幻觉就会越来越大,有点像束搜索,所以要提前防控。
知识蒸馏相关面试题
1. 什么是知识蒸馏
-
把大的教师模型的知识萃取出来,浓缩到一个小的学生模型中,就是大模型转为小模型
-
这里有一个知识迁移的过程,从教师网络迁移到学生网络上

2. 知识蒸馏的目的
深度学习在计算机视觉、语音识别、自然语言处理等内的众多领域中均取得了令人难以置信的性能。但是,大多数模型在计算上过于昂贵,无法在移动端或嵌入式设备上运行。因此需要对模型进行压缩,这样小的模型就适用于部署在终端设备上了,
- 提升模型精度:如果对目前的网络模型A的精度不是很满意,那么可以先训练一个更高精度的teacher模型B(通常参数量更多,时延更大),然后用这个训练好的teacher模型B对student模型A进行知识蒸馏,得到一个更高精度的A模型。
- 降低模型时延,压缩网络参数:如果对目前的网络模型A的时延不满意,可以先找到一个时延更低,参数量更小的模型B。通常来讲,这种模型精度也会比较低,然后通过训练一个更高精度的teacher模型C来对这个参数量小的模型B进行知识蒸馏,使得该模型B的精度接近最原始的模型A、从而达到降低时延的目的。
- 标签之间的域迁移:假如使用狗和猫的数据集训练了一个teacher模型A,使用香蕉和苹果训练了一个teacher模型B、那么就可以用这两个模型同时蒸馏出-个可以识别狗、猫、香蕉以及苹果的模型,将两个不同域的数据集进行集成和过移。
3. 传统的知识蒸馏方法
根据蒸馏知识的不同,主要有两种类型:
- 基于反馈的知识蒸馏
- 基于特征的知识蒸馏
- 参考资料《大语言模型》赵鑫等著

-
基于反馈的知识蒸馏:
- 关注教师模型最后一层输出的logits,这些logits经过softmax变换后,可以用作学生模型的软标签进行学习
- 蒸馏损失函数为:
L
(
l
t
,
l
s
)
=
L
R
(
p
t
(
⋅
)
,
p
s
(
⋅
)
)
\mathcal{L}(l_t,l_s)=L_R(p_t(\cdot),p_s(\cdot))
L(lt,ls)=LR(pt(⋅),ps(⋅)),其中:
- l t l_t lt和 l s l_s ls分别表示教师模型和学生模型的输出logits
- L R L_R LR通常采用KL散度作为指标
- p t p_t pt和 p s p_s ps分别表示教师模型和学生模型的logits经过softmax变换后的概率值
- 核心就是让学生模型输出的logits去逼近教师模型输出的logits
-
基于特征的知识蒸馏:
- 与基于预测分布的蒸馏相比,基于中间特征表示的蒸馏关注教师模型中间层输出的激活值,并用这些激活值作为监督信息训练学生模型
- 例如在多层Transformer架构的模型中,每一层的输出特征都可以作为知识
- 相应的蒸馏损失就是: L ( f t ( x ) , f s ( x ) ) = L F ( Φ ( f t ( x ) ) , Φ ( f s ( x ) ) ) \mathcal{L}(f_t(x),f_s(x))=L_F(\Phi(f_t(x)),\Phi(f_s(x))) L(ft(x),fs(x))=LF(Φ(ft(x)),Φ(fs(x))),这里的 Φ \Phi Φ函数哟关于处理形状不匹配的情况的变换函数。
- 显然中间层特征包含更为丰富的信息,有助于模型蒸馏过程中实现更为有效的知识迁移
- 然而,这种方法也存在技术难点,如消除架构不一致的影响(两个模型架构不同),选哪些层的输出作为参考(目标层自动化选择)
4. 大语言模型的知识蒸馏方法
- 白盒模型蒸馏方法(开源),黑盒模型蒸馏方法(闭源)
- 白盒:可以获取模型权重来指导学生模型,典型方法为MINILLM,最大可将LLaMA的13B蒸馏到7B
- 黑盒:无法获取模型权重,只能使用输出信息来训练小模型。经典的方法主要是关注大模型的关键能力,如上下文学习能力,思维链推理能力,指令遵从能力

一篇综述:A Survey on Knowledge Distillation of Large Language Models(arxiv.2402.13116)
- Knowledge Elicitation(知识提取):标签、扩展、数据治疗,特征挖掘,反馈,自蒸馏(自己监督自己,学生教师合二为一)
- 蒸馏算法(右侧):SFT,缩小差异性,增加相似性,强化学习,排序优化
20241206
好累,晚上下会都不想去跑了,回去直接睡了。明天还要陪AK跑个半马,据说要340-350,好久不上强度,不知道有没有超量恢复的说法?感觉不太可能,但其实最近还是有每天做核心力量,应该顶一顶也能上的去吧,大概。
刷到个KR同人@戈谭噩梦,画风很对味,大赞。画师真的会被取代吗,AI真的能画出“好”的插画吗,好的画应该是有细节的,是有感情的,是活的。可是AI做的再灵动,也是很死板的东西,艺术不应该被条条框框的提示限死,需要一些灵感才对。
PS:截至今天月跑量31.5K,均配4’28",说是在养老,但也就这么回事儿呗,想跑,我随时能抬得起腿。
从总体上看,大模型的训练可以分为四个关键阶段:预训练、有监督微调、奖励建模和强化学习。
- 训练的四个关键阶段:
- 预训练:这是整个训练过程的核心和最耗时的部分,占据了99%的资源。需要大规模的计算能力(如超级计算机或大型GPU集群)和海量数据(例如文本语料库)。预训练的目的是让模型学习语言的基本规则、语义和上下文关系。由于资源需求巨大,普通开发者难以独立完成这一步。
- 有监督微调:基于预训练模型,通过提供带标签的数据(例如问题和正确答案),让模型学会执行具体任务。
- 奖励建模:创建一个模型(奖励模型)来评估生成结果的质量,并指导主模型朝更优质的方向优化。
- 强化学习:通常采用强化学习(如人类反馈的强化学习,RLHF)。通过奖励信号进一步优化模型,使其更贴近用户需求。
2.资源需求对比:
- 预训练:极高的硬件和计算成本,以及长时间的运行。
- 微调阶段(有监督微调、奖励建模、强化学习):相对轻量,仅需几块GPU和较短的时间(几小时到几天)。
3.微调的核心目标:微调是为了在预训练模型的基础上,针对特定任务(如写文章、回答问题)进一步优化模型性能。通过调整模型的参数,可以让它更加准确地完成具体任务。
1. 什么时候需要对大模型进行微调
微调(Fine-tuning)的需求主要取决于两个方面:模型现有表现是否达标 和 任务的具体需求。具体来说,当以下场景出现时,可以考虑对大型语言模型(LLM)进行微调:
-
任务复杂度高,情境学习效果不足
- 情境学习(in-context Learning) 是通过在提示中加入任务示例,让模型更好理解任务需求。虽然这种方法灵活且不需.要更新模型权重,但有时模型对复杂任务的理解力不足,
- 对较小规模的模型,这种方法的效果有限
- 如果单靠调整提示不能显著提升性能,就需要进一步优化模型。.
-
零样本或少样本推理效果欠佳
- 零样本推理(Zero-shot Inference):模型仅根据问题上下文和提示进行推理,不依赖任何示例。虽然适合通用任务,但对于专业任务,模型可能难以理解语境或任务逻辑。
- 少样本推理(Few·shotInference):在提示中加入一到多个示例,帮助模型更精准地生成期望的输出。如果这种方式仍然无法满足准确性或一致性需求,微调成为更有效的选择。
-
领域或任务需求高度专业化
- 预训练的大型语言模型(LLM)设计通用,覆盖广泛领域。但在以下情况下,模型可能需要微调以提升特定任务表现:
- 涉及专业术语、领域知识(如法律、医学、工程)。
- 需要模型对高度特定的输出格式或逻辑规则保持一致性。
- 某些任务需要高精度、低错误率,例如客户服务、医学诊断、自动化文档处理。
- 预训练的大型语言模型(LLM)设计通用,覆盖广泛领域。但在以下情况下,模型可能需要微调以提升特定任务表现:
-
输出结果不符合用户需求
- 即使通用模型输出具有一定准确性,但在用户偏好或特定任务中可能不够符合要求。例如:
- 输出风格、语气不匹配,
- 需要更个性化或品牌化的结果。
- 即使通用模型输出具有一定准确性,但在用户偏好或特定任务中可能不够符合要求。例如:
-
总结:当情境学习和零样本、单样本或少样本推理不能满足需求,或者需要在特定任务和领域中提升模型表现时,微调是有效策路。通过有监督学习过程,微调能显著提高模型在特定任务上的准确性和可靠性。
2. LLMs中微调方法有哪些
微调技术可以分为全量微调(FFT)和PEFT(参数高效微调)
下表展示了在一张A100 GPU(80G显存)以及CPU内存64GB以上硬件上进行模型全量微调以及PEFT对于CPU和GPU的消耗情况

- 全量微调会损失多样性,存在灾难性遗忘问题
- 微调策略方面,有SFT(监督微调)和**RLHF(人类反馈强化学习)**两种
- SFT的主要技术:
- 基本超参数调整
- 迁移学习
- 多任务学习
- 少样本学习
- 任务特定微调
- RLHF主要技术:
- 奖励建模
- 邻近策略优化(PPO):在确保策略更新平稳的情况下优化模型行为
- 比较排名:通过人类评估不同输出的优劣,来优化模型
- 偏好学习:从人类偏好中学习,优化输出
- 参数高效微调:最小化训练参数数量,提高特定任务性能
- SFT的主要技术:
3. 主流PEFT的方法有哪些
主要是Adapter,Prefix Tuning和LoRA三大类。各具特点,在模型结构中所嵌入的位置也有所不同

图来自论文:TOWARDS A UNIFED VIEW OF PARAMETER-EFFICIENT TRANSFER LEARNING(arxiv.2110.04366)
- Adapter类:
- PEFT 技术通过在预训练模型的各层之间插入较小的神经网络模块,这些新增的神经模块被称为“适配器",在进行下游任务的微调时,只需对适配器参数进行训练便能实现高效微调的目标。
- 此基础上衍生出了AdapterP、Parallel等高效微调技术
- Prefix Tuning类:
- PEFT 技术通过在模型的输入或隐层添加 k k k个额外可训练的前缀标记,模型微调时只训练这些前缀参数便能实现高效微调的目标。
- 在此基础上衍生出了P-Tuning、P-Tuningv2等高效微调技术;
- LoRA类:
- PEFT 技术则通过学习小参数的低秩矩阵来近似模型权重矩阵W的参数更新,微调训练时只需优化低秩矩阵参数便能实现高效微调的目标。
- 在此基础上衍生出AdaLORA、QLORA等高效微调技术
20241207
中午搞了个猪肚老母鸡汤(配芋头+山药+香菇),芋头还是不能下太早,否则汤都糊了,跟粥一样,虽然也挺好吃。红薯硬一些,没那么软,加到汤里其实也不错。这次过来从外婆那里拿了不少红薯,其实烤红薯也挺好吃。外加蒸了一只人参,是真的苦,而且越嚼越硬,突出一个良药苦口。
晚上陪AK猛干,小崔、白辉龙、尹越也来了,嘉伟估计是入职体检,否则一起可能今晚质量可以更高一些。计划是340-350的半马,不过今晚风太大,有一整根直道的大顶风,不是很好跑,实际没有起到这么快,起步差不多在350-355。
尹越3K不到就崩了,小崔5K岔气,5K之后AK把速度带到350以内,我到7K心率超过了180,实在是顶不住,最终是7K@352。我下去之后,AK进一步提速到345以内,10K拉爆了白辉龙,至此,AK拉爆全场,最后他独自顶到12K@348,你大爷还是你大爷。
5K慢跑收尾,把昨天的量补了一下,还是慢点舒服诶。其实首马回来就没有穿跑鞋跑过步了,每天都是风衣长裤慢摇。
PS:明早高百总决赛,在浦西滨江路段,黄雪梅将代表东南大学首发出战,势必是要请一堆男生吃辣堡了。我看LXY这个月7天每天至少是10K,其中两三天可能有12-15K的量,而且10K都能跑到47分上下,感觉认真跑至少能到45分以内,但这已是我们的天花板。不甘心总归是不甘心的,但相信后人智慧,在适当的时机,或许还是有能力再次冲击PB。

RAG的优化策略相关(重要)
4.1 知识文档准备阶段(数据清洗、分块处理)
-
数据清洗
-
RAG依赖准确和清洁的原始知识
-
表格结构会在单纯的文本转换后丢失原有结构,因此需要引入额外机制来保持表格结构(如使用分号或其他符号来区分数据)
-
其他数据清洗操作:
- 基本文本清理:规范格式、去除特殊字符、不相关信息、重复文档、冗余信息
- 实体解析:消歧,如将LLMs,大语言模型,大模型类似的标准化为通用术语
- 文档划分:按主题划分,不同主题的文档集中或分散?人类都不能判段用哪些文档来回答提问,检索系统也不能
- 数据增强:同义词、释义、其他语言的翻译来增加语料库的多样性
- RLHF:基于现实世界用户的反馈不断更新数据库,标记真实性
- 时间敏感数据:对于经常更新的主题,删除过期文档
-
-
分块处理:Chunk
-
在RAG系统中,文档需要分割成多个文本块再进行向量嵌入。
-
在不考虑大模型输入长度限制和成本问题情况下,其目的是在保持语义上的连贯性的同时,尽可能减少嵌入内容中的噪声,从而更有效地找到与用户查询最相关的文档部分
-
如果分块太大,可能包含太多不相关的信息,从而降低了检索的准确性。相反,分块太小可能会丢失必要的上下文信息,导致生成的回应缺乏连贯性或深度。
-
在RAG系统中实施合适的文档分块策略,旨在找到这种平衡,确保信息的完整性和相关性。一般来说,理想的文本块应当在没有周围上下文的情况下对人类来说仍然有意义,这样对语言模型来说也是有意义的。
-
分块方法的选择:
- 固定大小的分块:这是最简单和直接的方法,我们直接设定块中的字数,并选择块之间是否重复内容
- 通常,我们会保持块之间的一些重叠,以确保语义上下文不会在块之间丢失。与其他形式的分块相比,固定大小分块简单易用且不需要很多计算资源。
-
内容分块
- 顾名思义,根据文档的具体内容进行分块,例如根据标点符号(如句号)分割。或者直接使用更高级的NLTK或者spaCy库提供的句子分割功能。
-
递归分块
- 在大多数情况下推荐的方法。
- 其通过重复地应用分块规则来递归地分解文本
- 例如,在langchain中会先通过段落换行符(\n\n)进行分割。然后,检查这些块的大小。如果大小不超过一定阈值,则该块被保留。对于大小超过标准的块,使用单换行符(\n)再次分割。以此类推,不断根据块大小更新更小的分块规则(如空格,句号)。这种方法可以灵活地调整块的大小。例如,对于文本中的密集信息部分,可能需要更细的分割来捕捉细节;而对于信息较少的部分,则可以使用更大的块。而它的挑战在于,需要制定精细的规则来决定何时和如何分割文本。
-
从小到大分块
- 既然小的分块和大的分块各有各的优势,一种更为直接的解决方案是把同一文档进行从大到小所有尺寸的分割,然后把不同大小的分块全部存进向量数据库,并保存每个分块的上下级关系,进行递归搜索。但可想而知,因为我们要存储大量重复的内容,这种方案的缺点就是需要更大的储存空间。
-
特殊结构分块
- 针对特定结构化内容的专门分割器。这些分割器特别设计来处理这些类型的文档,以确保正确地保留和理解其结构。
- langchain提供的特殊分割器包括:Markdown文件,Latex文件,以及各种主流代码语言分割器。
-
分块大小的选择
- 上述方法中无一例外最终都需要设定一个参数——一块的大小,那么我们如何选择呢?
- 首先不同的嵌入模型有其最佳输入大小。比如Openai的text-embedding-ada-002的模型在256或512大小的块上效果更好。
- 其次,文档的类型和用户查询的长度及复杂性也是决定分块大小的重要因素。处理长篇文章或书籍时,较大的分块有助于保留更多的上下文和主题连贯性;而对于社交媒体帖子,较小的分块可能更适合捕捉每个帖子的精确语义。如果用户的查询通常是简短和具体的,较小的分块可能更为合适;相反,如果查询较为复杂,可能需要更大的分块。
- 实际场景中,我们可能还是需要不断实验调整,在一些测试中,128大小的分块往往是最佳选择,在无从下手时,可以从这个大小作为起点进行测试。
-
4.2 嵌入模型阶段
- 我们提到过嵌入模型能帮助我们把文本转换成向量,显然不同的嵌入模型带来的效果也不尽相同,例如,Word2Vec模型,尽管功能强大,但存在一个重要的局限性:其生成的词向量是静态的。一旦模型训练完成,每个词的向量表示就固定不变,这在处理一词多义的情况时可能导致问题。
- 语义完全不一样的词向量却是固定的。相比之下,引入自注意力机制的模型,如BERT,能够提供动态的词义理解。这意味着它可以根据上下文动态地调整词义,使得同一个词在不同语境下有不同的向量表示。
- 有些项目为了让模型对特定垂直领域的词汇有更好的理解,会嵌入模型进行微调。但在这里我们并不推荐这种方法,一方面其对训练数据的质量有较高要求,另一方面也需要较多的人力物力投入,且效果未必理想,最终得不偿失。
- 在这种情况下,对于具体应该如何选择嵌入模型,推荐参考HuggingFace推出的嵌入模型排行榜MTEB(https://huggingface.co/spaces/mteb/leaderboard)。这个排行榜提供了多种模型的性能比较,能帮助我们做出更明智的选择。同时,要注意并非所有嵌入模型都支持中文,因此在选择时应查阅模型说明。
- 目前SOTA表现是北大和腾讯团队开源的Conan embedding
- C-MTEB(Chinese Massive Text Embedding Benchmark):中文海量文本嵌入测试基准
4.3 向量数据库阶段(元数据)
- 当在向量数据库中存储向量数据时,某些数据库支持将向量与元数据(即非向量化的数据)一同存储、为向量添加元数据标注是一种提高检索效率的有效策略,它在处理搜索结果时发挥着重要作用。
- 例如,日期就是一种常见的元数据标签。它能够帮助我们根据时间顺序进行筛选。设想一下,如果我们正在开发一款允许用户查询他们电子邮件历史记录的应用程序。在这种情况下,日期最近的电子邮件可能与用户的查询更相关。然而,从嵌入的角度来看,我们无法直接判断这些邮件与用户查询的相似度。通过将每封电子邮件的日期作为元数据附加到其嵌入中,我们可以在检索过程中优先考虑最近日期的邮件,从而提高搜索结果的相关性。
- 此外,我们还可以添加诸如章节或小节的引用,文本的关键信息、小节标题或关键词等作为元数据。这些元数据不仅有助于改进知识检索的准确性,还能为最终用户提供更加丰富和精确的搜索体验。
4.4 查询索引阶段(检索找回、重排)
-
多级索引:
- 元数据无法充分区分不同上下文类型的情况下,我们可以考虑进一步尝试多重索引技术
- 多重索引技术的核心思想是将庞大的数据和信息需求按类别划分,并在不同层级中组织,以实现更有效的管理和检索。
- 这意味着系统不仅依赖于单一索引,而是建立了多个针对不同数据类型和查询需求的索引。
- 例如,可能有一个索引专门处理摘要类问题,另一个专门应对直接寻求具体答案的问题,还有一个专门针对需要考虑时间因素的问题。这种多重索引策略使RAG系统能够根据查询的性质和上下文,选择最合适的索引进行数据检索,从而提升检索质量和响应速度。
- 不过为了引入多重索引技术,我们还需配套加入多级路由机制。多级路由机制确保每个查询被高效引导至最合适的索引。查询根据其特点(如复杂性、所需信息类型等)被路由至一个或多个特定索引。这不仅提升了处理效率,还优化了资源分配和使用,确保了对各类查询的精确匹配。
- 例如,对干查询最新上映的科幻电影推荐,RAG系统可能首先将其路由至专门处理当前热点话题的索引,然后利用专注于娱乐和影视内容的索引来生成相关推荐。
- 总的来说,多级索引和路由技术可以进一步帮助我们对大规模数据进行高效处理和精准信息提取,从而提升用户体验和系统的整体性能。
-
索引或查询算法:
- 我们可以利用索引筛选数据,但说到底我们还是要从筛选后的数据中检索出相关的文本向量。
- 由于向量数据量庞大且复杂,寻找绝对的最优解变得计算成本极高,有时甚至是不可行的。加之,大模型本质上并不是完全确定性的系统,这些模型在搜索时追求的是语义上的相似性——一种合理的匹配即可。从应用的角度来看,这种方法是合理的。
- 例如,在推荐系统中,用户不太可能察觉到或关心是否每个推荐的项目都是绝对的最佳匹配
- 他们更关心的是推荐是否总体上与他们的兴趣相符
- 因此查找与查询向量完全相同的项通常不是目标,而是要找到足够接近或相似的项,这便是最近邻搜索(ApproximateNearest Neighbor Search,ANNS)。这样做不仅能满足需求,还为检索优化提供了巨大的优化潜力。
- 常用算法:
- 聚类:参数选择(如簇数)
- 位置敏感哈希:
- 沿着缩小搜索范围的思路(束搜索)
- 在传统哈希算法中,我们通常希望每个输入对应唯一输出,并努力减少输出的重复
- 然而,在位置敏感哈希中,目标恰恰相反,我们需要增加输出值碰撞的概率
- 这种碰撞正是分组的关键,哈希值相同的向量进入同一个组(桶),此外,哈希函数还需满足一个条件:空间上距离相近的向量更有可能分入同一个桶,这样在搜索时,只要获取目标向量的哈希值,找到相应的桶进行搜神记即可。
- 量化乘积:
- 上面我们介绍了两种牺牲搜索质量来提高搜索速度的方法,但除了搜索速度外,内存开销也是一个巨大挑战。
- 在实际应用场景中,每个向量往往都有上千个维度,数据数量可达上亿。每条数据都对应着一个实际的的信息,因此不可能删除数据来减少内存开销,那唯一的选择只能是把每个数据本身大小缩减。
- 图像有一种有损压缩的方法是把一个像素周围的几个像素合并(Superpixel),来减少需要储存的信息。同样我们可以在聚类的方法之上改进一下,用每个簇的中心点来代替簇中的数据点。虽然这样我们会丢失向量的具体值信息,但考虑到聚类中心点和簇中向量相关程度,再加上可以不断增加簇的数量来减少信息损失,所以很大程度上我们可以保留原始点的信息。而这样做带来的好处是十分可观的。
- 如果我们给这些中心点编码,我们就可以用单个数字储存一个向量来减少存储的空间。而我们把每个中心向量值和他的编码值记录下来形成一个码本,这样每次使用某个向量的时候,我们只需用他的编码值通过码本找到对应的的中心向量的具体值
- 虽然这个向量已经不再是当初的样子了,但就像上面所说,问题不大。而这个把向量用其所在的簇中心点表示的过程就是量化。
- 分层导航小世界:
- 从客户的角度来看,内存开销可能并不是最重要的考量因素。他们更加关注的是应用的最终效果,也就是回答用户问题的速度和质量。
- 导航小世界(Navigable Small World,NSW)算法正是这样一种用内存换取更快速度和更高质量的实现方式
- 这个算法的思路和六度分割理论类似——你和任何一个陌生人之间最多只隔六个人,也就是说,最多通过六个人你就能够认识任何一个陌生人。
- 我们可以将人比作向量点,把搜索过程看作是从一个人找到另一个人的过程。在查询时,我们从一个选定的起始点A开始,然后找到与A相邻且最接近查询向量的点B,导航到B点,再次进行类似的判断,如此反复,直到找到一个点C,其所有相邻节点都没有比它更接近目标。最终这个点C便是我们要找的最相似的向量。
-
查询转换:
-
在RAG系统中,用户的查询问题被转化为向量,然后在向量数据库中进行匹配。不难想象,查询的措辞会直接影响投索结果。
-
如果搜索结果不理想,可以尝试以下几种方法对问题进行重写,以提升召回效果:
-
a. 结合历史对话的重新表述
- 在向量空间中,对人类来说看似相同的两个问题其向量大小并不一定很相似。我们可以直接利用LLM 重新表述问题来进行尝试。
- 此外,在进行多轮对话时,用户的提问中的某个词可能会指代上文中的部分信息,因此可以将历史信息和用户提问一并交给LLM重新表述。
-
b. 假设文档嵌入
- 假设文档嵌入(Hypothetical DocumentEmbedding,HyDE)的核心思想是:
- 接收用户提问后,先让LLM在没有外部知识的情况下生成一个假设性的回复。
- 然后,将这个假设性回复和原始查询一起用于向量检索。
- 假设回复可能包含虚假信息,但蕴含着LLM认为相关的信息和文档模式,有助于在知识库中寻找类似的文档。
- 主要关注点:通过为传入查询生成一个假想文档,从而增强和改善相似性搜索。
- 假设文档嵌入(Hypothetical DocumentEmbedding,HyDE)的核心思想是:
-
c. 退后提示
- 如果原始查询太复杂或返回的信息太广泛,可以选择生成一个抽象层次更高的“退后“问题,与原始问题一起用于检索,以增加返回结果的数量。这就是退后提示(Step BackPrompting)的思想。
- 例如,原问题是张三 在 1954年8月至 1954年 11月期间去了哪所学校?,这类问题对于 LLM 来说很容易答错。但是如果后退一步,站在更高层次对问题进行抽象,提出一个新的问题:**张三的教育历史是怎样的?**那LLMs可以先将张三都列出来,然后将这些信息和原始问题放在一起,那么对于 LLM 来说就可以很容易给出正确的答案。
-
d.多查询检索/多路召回
- 多查询检索/多路召回(Multi-Query Retrieval)也是一种不错的方法。
- 使用LLM生成多个搜索查询,特别适用于一个问题可能需要依赖多个子问题的情况。
-
-
-
检索参数:
-
终于我们把查询问题准备好了,可以进入向量数据库进行检索。在具体的检索过程中,我们可以根据向量数据库的特定设置来优化一些检索参数,以下是一些常见的可设定参数:
-
稀疏和稠密搜索权重
-
稠密搜索即通过向量进行搜索。然而,在某些场景下可能存在限制,此时可以尝试使用原始字符串进行关键字匹配的稀疏搜索。
-
一种有效的稀疏搜索算法是最佳匹配25(BM25),它基于统计输入短语中的单词频率,频繁出现的单词得分较低,而稀有的词被视为关键词,得分会较高。我们可以结合稀疏和稠密搜索得出最终结果。
-
向量数据库通常允许设定两者对最终结果评分的权重比例,如langchain的某个参数,0.6表示40%的得分来自稀疏搜索,60%来自稠密搜索。
-
-
结果数量(topk)
-
检索结果的数量是另一个关键因素。
-
足够的检索结果可以确保系统覆盖到用户查询的各个方面。在回答多方面或复杂问题时,更多的结果提供了丰富的语境,有助于RAG系统更好地理解问题的上下文和隐含细节,
-
但需注意,结果数量过多可能导致信息过载,降低回答准确性并增加系统的时间和资源成本
-
-
相似度度量方法
- 计算两个向量相似度的方法也是一个可选参数。这包括使用欧式距离或Jaccard距离计算两个向量的差异,以及利用余弦相似度衡量夹角的相似性。
- 通常,余弦相似度更受青睐,因为它不受向量长度的影响,只反映方向上的相似度。这使得模型能够忽略文本长度差异,专注于内容的语义相似性。
- 需要注意的是,并非所有嵌入模型都支持所有度量方法,具体可参考所用嵌入模型的说明。
-
-
高级检索策略:
-
终于我们来到最为关键和复杂的步骤——在向量数据库检索之上如何具体开发或改进整个系统的策略,这部分的内容足够写成一篇独立文章。为了保持简洁,我们只讨论一些常用或者新提出的策略。
-
a. 上下文压缩:
-
我们提到过当文档文块过大时,可能包含太多不相关的信息,传递这样的整个文档可能导致更昂贵的LLM调用和更差的响应。
-
上下文压缩的思想就是通过LLM的帮助根据上下文对单个文档内容进行压缩,或者对返回结果进行一定程度的过滤仅返回相关信息。
-
b. 句子窗口搜索
-
相反,文档文块太小会导致上下文的缺失。
-
其中一种解决方案就是窗口搜索,该方法的核心思想是当提问匹配好分块后,将该分块周围的块作为上下文一并交给LLM进行输出。来增加LLM对文档上下文的理解
-
c. 父文档搜索
- 无独有偶,父文档搜索也是一种很相似的解决方案,父文档搜索先将文档分为尺寸更大的主文档,再把主文档分割为更短的子文档两个层级,用户问题会与子文档匹配,然后将该子文档所属的主文档和用户提问发送给LLMs。
-
d. 自动合并
- 自动合并是在父文档搜索上更进一步的复杂解决方案。
-
同样地,我们先对文档进行结构切割,比如将文档按三层树状结构进行切割,顶层节点的块大小为1024,中间层的块大小为512,底层的叶子节点的块大小为128。
-
而在检索时只拿叶子节点和问题进行匹配,当某个父节点下的多数叶子节点都与问题匹配上则将该父节点作为结果返回。
-
e. 多向量检索
-
多向量检索同样会给一个知识文档转化成多个向量存入数据库,不同的是,这些向量不仅包括文档在不同大小下的分块,还可以包括该文档的摘要,用户可能提出的问题等,有助于检索的信息。
-
在使用多向量查询的情况下,每个向量可能代表了文档的不同方面,使得系统能够更全面地考虑文档内容,并在回答复杂或多方面的查询时提供更精确的结果。
-
例如,如果查询与文档的某个具体部分或摘要更相关,那么相应的向量就可以帮助提高这部分内容的检索排名。
-
-
f. 多代理检索
-
多代理检索,简而言之就是选取我们提及的12大优化策略中的部分交给一个智能代理合并使用。
- 就比如使用子问题查询,多级索引和多向量查询结合,
-
先让子问题查询代理把用户提问拆解为多个小问题,再让文档代理对每个字问题进行多向量或多索引检索,最后排名代理将所有检索的文档总结再交给LLM。
-
这样做的好处是可以取长补短。比如,子问题查询引擎在探索每个子查询时可能会缺乏深度,尤其是在相互关联或关系数据中。相反,文档代理递归检索在深入研究特定文档和检索详细答案方面表现出色,以此来综合多种方法解决问题。
-
需要注意的是现在网络上存在不同结构的多代理检索,具体在多代理选取哪些优化步骤尚未有确切定论,我们可以结合使用场景进行探索。
-
-
g. Self-RAG(左右互搏)
-
自反思搜索增强是一个新的RAG框架,其与传统RAG最大的区别在于通过检索评分(令牌)和反思评分(令牌)来提高质量。
-
它主要分为三个步骤:检索、生成和批评。
-
SeIf-RAG首先用检索评分来评估用户提问是否需要检索,如果需要检索,LLM将调用外部检索模块查找相关文档。
- 接着,LLM分别为每个检索到的知识块生成答案,
- 然后为每个答案生成反思评分来评估检索到的文档是否相关,
-
最后将评分高的文档当作最终结果一并交给LLM。
-
-
-
重排模型:
-
在完成语义搜索的优化步骤后,我们能够检索到语义上最相似的文档,但不知你是否注意到一个关键问题:语义最相似是否总代表最相关?答案是不一定。
- 例如,当用户查询最新上映的科幻电影推荐时,可能得到的结果是科幻电影的历史演变,虽然从语义上这与科幻电影相关,但并未直接回应用户关于最新电影的查询。
-
重排(Re-ranking)模型可以帮助我们缓解这个问题,重排模型通过对初始检索结果进行更深入的相关性评估和排序,确保最终展示给用户的结果更加符合其查询意图。
-
该过程会考虑更多的特征,如查询意图、词汇的多重语义、用户的历史行为和上下文信息等。
- 举个例子,对于查询最新上映的科幻电影推荐,在首次检索阶段,系统可能基于关键词返回包括科幻电影的历史文章、科幻小说介绍、最新电影的新闻等结果。
- 然后,在重排阶段,模型会对这些结果进行深入分析,并将最相关、最符合用户查询意图的结果(如最新上映的科幻电影列表的评论或推荐)排在前面,同时将那些关于科幻电影历史或不太相关的内容排在后面。
- 这样,重排模型就能有效提升检索结果的相关性和准确性,更好地满足用户的需求。
-
在实践中,使用RAG构建系统时都应考虑尝试重排方法,以评估其是否能够提高系统性能。
-
4.5 生成回答阶段(提示工程)
-
提示词:
-
LLMs的解码器部分通常基于给定输入来预测下一个词。
-
这意味着设计提示词或问题的方式将直接影响模型预测下一个词的概率。这也给了我们一些启示:通过改变提示词的形式,可以有效地影响模型对不同类型问题的接受程度和回答方式,比如修改提示语,让LLM知道它在做什么工作,是十分有帮助的。
-
为了减少模型产生主观回答和幻觉的概率,一般情况下,RAG系统中的提示词中应明确指出回答仅基于搜索结果,不要添加任何其他信息。例如,可以设置提示词如:
你是一名智能客服。你的目标是提供准确的信息,并尽可能帮助提问者解决问题。你应保持友善,但不要过于啰嗦。请根据提供的上下文信息,在不考虑已有知识的情况下,回答相关查询。
-
当然你也可以根据场景需要,也可以适当让模型的回答融入一些主观性或其对知识的理解。
-
此外,使用少量样本(few-shot)的方法,将想要的问答例子加入提示词中,指导LLM如何利用检索到的知识,也是提升LLM生成内容质量的有效方法。这种方法不仅使模型的回答更加精准,也提高了其在特定情境下的实用性。
-
-
大语言模型:
- LLM是生成响应的核心组件。与嵌入模型类似,可以根据自己的需求选择LLM,例如开放模型与专有模型、推理成本、上下文长度等。
- 此外,可以使用一些LLM开发框架来搭建RAG系统,比如,Llamalndex或LangChain。这两个框架都拥有比较好用的debugging工具,可以让我们定义回调函数,查看使用了哪些上下文,检查检索结果来自哪个人档等等。
20241208(高百总决赛)
2018年:
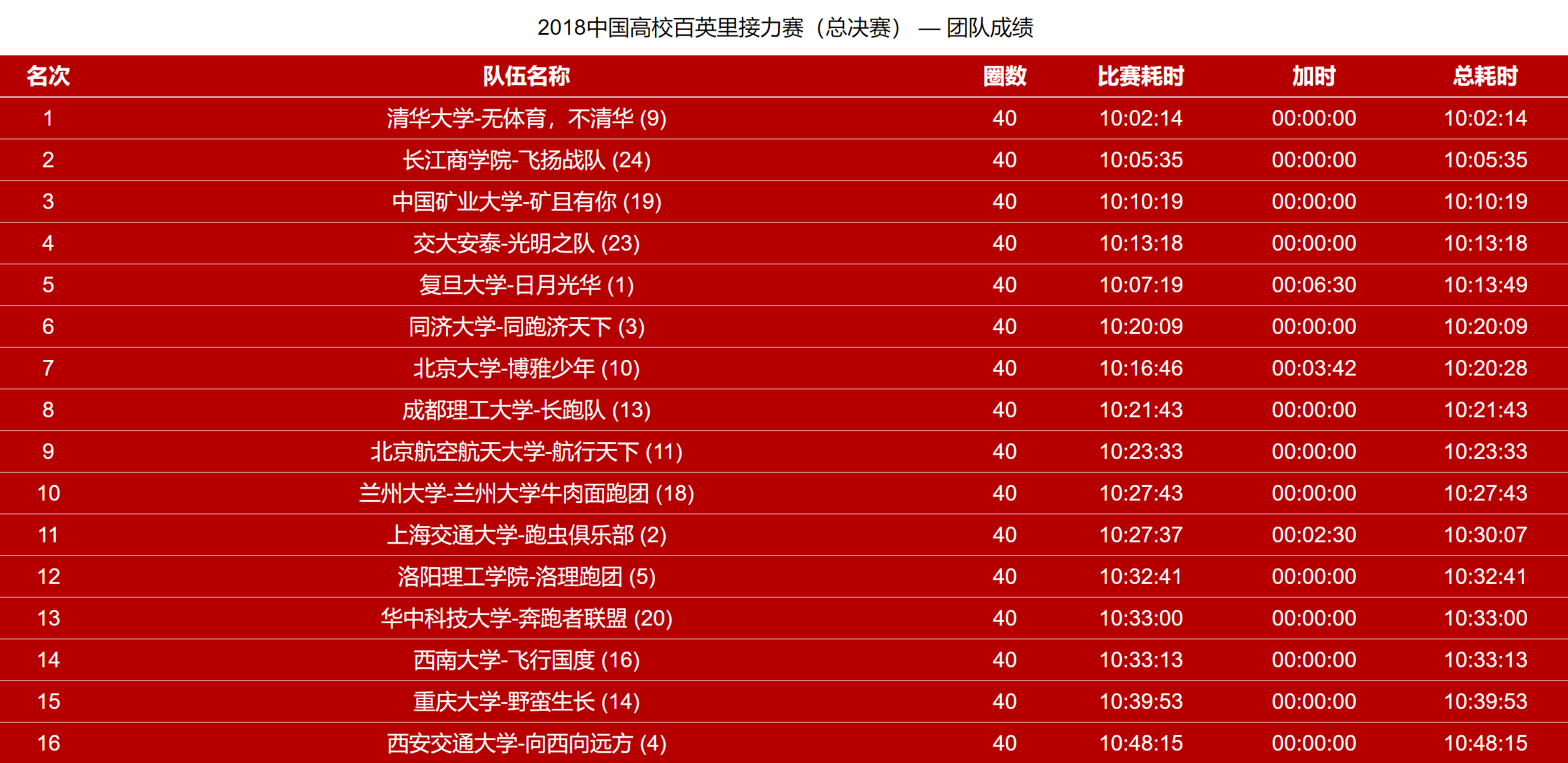
2024年:
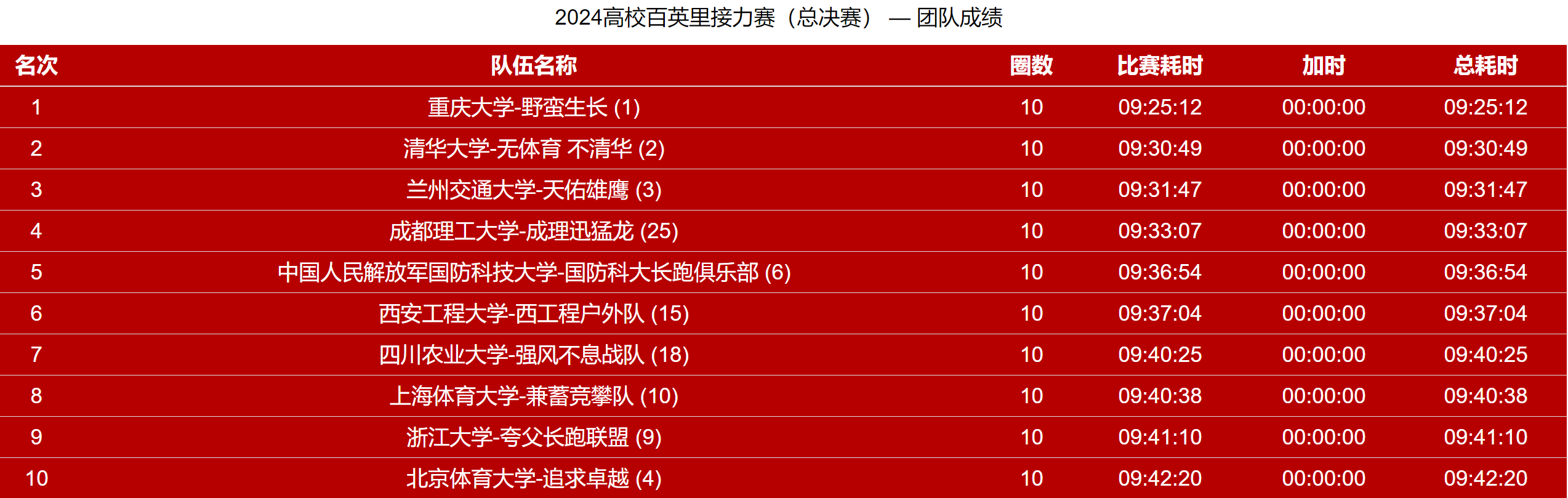
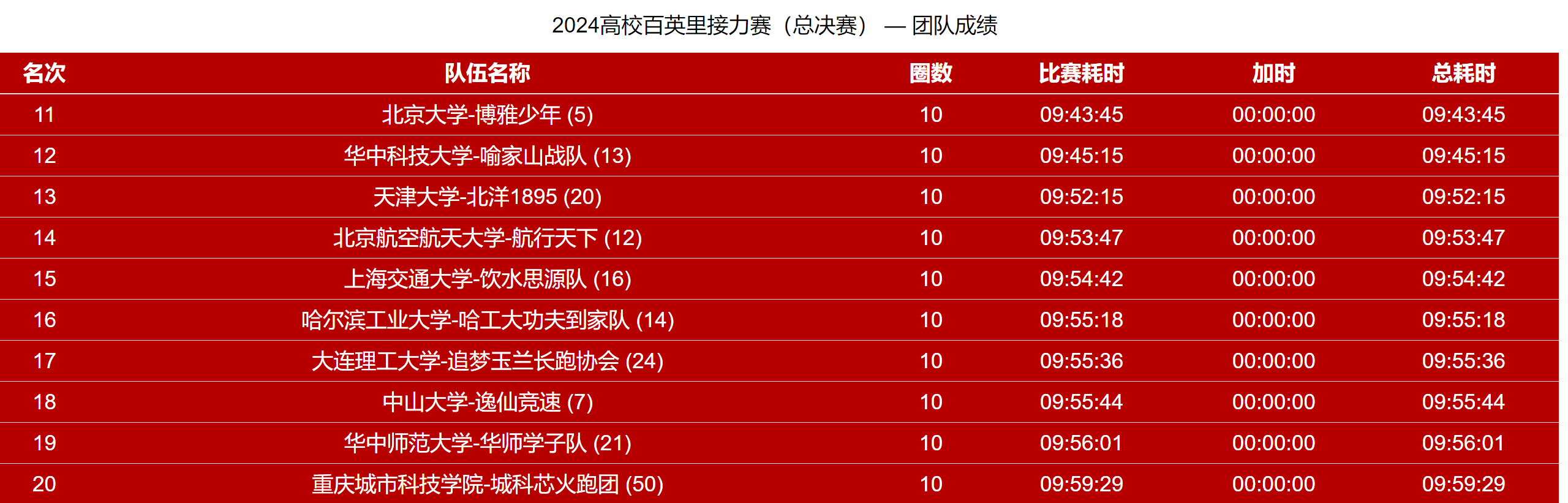
队伍名称后面括号内的数字表示该高校上一年度总决赛排名,今年成都理工异军突起,前三都是卫冕,北大拉垮,浙大还是稳的。
让我们恭喜重庆大学卫冕冠军,兰交大卫冕季军!把清北狠狠地踩在下面,尤其是冠军重大断层领先亚军清华,干得漂亮!
高百队长群里,复交浙南中科哈工各个学校的队长都在,偏偏就是没有清北的人,人家都不屑于陪你们一起玩。去年清华亚军,北大第五,清华带了一个全马237的女队员来参加,直接降维打击,结果也没能拿到冠军,赛后还被举报上了注册运动员。今年重大卫冕,人家可是纯文化生队伍。
- 个人情况,清华的郑铁50分38秒第一(均配3分09秒),领先男子第二天大的刘辛贝将近一分钟,估计清华今天又带了个BUG来
- 重大的实力在于均衡,他们男子正式队员都是全马230-240水平(万米34分台甚至只配替补),两个女生一个64分,一个65分,其他学校很难凑出这样强悍的中坚力量,比如我们230-240这个水平台的只有李朝松和叶凯浩,AK还差临门一脚破开240,而且叶凯浩本科华政,历年都是代表华政出战,今天也是代表华政跑的第一棒(华政拿到了外卡),56分台完赛,实力可见一斑,硬实力确实略在AK之上。
- 但是,今年很多学校是有业余顶尖高手,比如兰交大的潘江龙全马223,广西民大的庆敏也有接近全马健将的水平(可惜广西民大今天DNS,估计人没凑齐。分站赛的时候广西民大的男子表现可谓碾压,男子前6占据4人,亏在女生水平差了些屈居亚军)。
- 华北电力有4位半马70分台选手,但是还是亏在女生上了(一个75分,一个86分)。今天一共有3个女生跑进60分钟,64分钟以内跑完16K的女生12人,同济黄芳64分26秒,哪怕是4分半的配速跑完16K,也要72分钟,而72分钟,在100个女生中只能排到62名,何况女生4分半的配能跑完16K已经是相当厉害。
- 另外,特邀东南大学的黄雪梅代表东南大学出战,用时55分52秒,黄雪梅算是中国业余一姐,跟男子业余一哥狄鋆齐名,两个人都是非全职跑步,是有本职工作的,天赋异禀。黄雪梅巴黎奥运会马拉松大众组女子冠军,全马PB232
- 复交同三校人没凑齐,20名开外了,尤其是同济和交大,往年都是冠军的有力竞争,最后还是上体和浙大保全了江浙沪的颜面。
- 2018年,冠军10小时02分;今年,10小时整(也就是人均1小时,均配3’45",其中还要带2个女生)连前20名都进不了。而我们,除了嘉伟和AK,其他男生能跑进1小时都很难,包括我自己,想跑进1小时也很有难度。
虽然但是,真想跑一次总决赛。60分钟的成绩在今年男生里只能排在268/410的位置(65%),其实以前差不多也就是排在这个区间,我真的还能PB吗?不知道,晚上慢跑6K+30箭步×8组(+20kg),大概吧。(另外,中科院今天50所高校垫底,难绷哈哈哈)
PS:今天是镇江南山越野,之前是记得的,然后就忘了,算了。不过,看起来比虞山要好一些。
微调相关问题
从总体上看,大模型的训练可以分为四个关键阶段:预训练、有监督微调、奖励建模和强化学习。
- 训练的四个关键阶段:
- 预训练:这是整个训练过程的核心和最耗时的部分,占据了99%的资源。需要大规模的计算能力(如超级计算机或大型GPU集群)和海量数据(例如文本语料库)。预训练的目的是让模型学习语言的基本规则、语义和上下文关系。由于资源需求巨大,普通开发者难以独立完成这一步。
- 有监督微调:基于预训练模型,通过提供带标签的数据(例如问题和正确答案),让模型学会执行具体任务。
- 奖励建模:创建一个模型(奖励模型)来评估生成结果的质量,并指导主模型朝更优质的方向优化。
- 强化学习:通常采用强化学习(如人类反馈的强化学习,RLHF)。通过奖励信号进一步优化模型,使其更贴近用户需求。
2.资源需求对比:
- 预训练:极高的硬件和计算成本,以及长时间的运行。
- 微调阶段(有监督微调、奖励建模、强化学习):相对轻量,仅需几块GPU和较短的时间(几小时到几天)。
3.微调的核心目标:微调是为了在预训练模型的基础上,针对特定任务(如写文章、回答问题)进一步优化模型性能。通过调整模型的参数,可以让它更加准确地完成具体任务。
1. 什么时候需要对大模型进行微调
微调(Fine-tuning)的需求主要取决于两个方面:模型现有表现是否达标 和 任务的具体需求。具体来说,当以下场景出现时,可以考虑对大型语言模型(LLM)进行微调:
-
任务复杂度高,情境学习效果不足
- **情境学习(in-context Learning)**是通过在提示中加入任务示例,让模型更好理解任务需求。虽然这种方法灵活且不需.要更新模型权重,但有时模型对复杂任务的理解力不足,
- 对较小规模的模型,这种方法的效果有限
- 如果单靠调整提示不能显著提升性能,就需要进一步优化模型。.
-
零样本或少样本推理效果欠佳
- 零样本推理(Zero-shot Inference):模型仅根据问题上下文和提示进行推理,不依赖任何示例。虽然适合通用任务,但对于专业任务,模型可能难以理解语境或任务逻辑。
- 少样本推理(Few·shotInference):在提示中加入一到多个示例,帮助模型更精准地生成期望的输出。如果这种方式仍然无法满足准确性或一致性需求,微调成为更有效的选择。
-
领域或任务需求高度专业化
- 预训练的大型语言模型(LLM)设计通用,覆盖广泛领域。但在以下情况下,模型可能需要微调以提升特定任务表现:
- 涉及专业术语、领域知识(如法律、医学、工程)。
- 需要模型对高度特定的输出格式或逻辑规则保持一致性。
- 某些任务需要高精度、低错误率,例如客户服务、医学诊断、自动化文档处理。
- 预训练的大型语言模型(LLM)设计通用,覆盖广泛领域。但在以下情况下,模型可能需要微调以提升特定任务表现:
-
输出结果不符合用户需求
- 即使通用模型输出具有一定准确性,但在用户偏好或特定任务中可能不够符合要求。例如:
- 输出风格、语气不匹配,
- 需要更个性化或品牌化的结果。
- 即使通用模型输出具有一定准确性,但在用户偏好或特定任务中可能不够符合要求。例如:
-
总结:当情境学习和零样本、单样本或少样本推理不能满足需求,或者需要在特定任务和领域中提升模型表现时,微调是有效策路。通过有监督学习过程,微调能显著提高模型在特定任务上的准确性和可靠性。
2. LLMs中微调方法有哪些
微调技术可以分为全量微调(FFT)和PEFT(参数高效微调)
下表展示了在一张A100 GPU(80G显存)以及CPU内存64GB以上硬件上进行模型全量微调以及PEFT对于CPU和GPU的消耗情况
- 全量微调会损失多样性,存在灾难性遗忘问题
- 微调策略方面,有SFT(监督微调)和**RLHF(人类反馈强化学习)**两种
- SFT的主要技术:
- 基本超参数调整
- 迁移学习
- 多任务学习
- 少样本学习
- 任务特定微调
- RLHF主要技术:
- 奖励建模
- 邻近策略优化(PPO):在确保策略更新平稳的情况下优化模型行为
- 比较排名:通过人类评估不同输出的优劣,来优化模型
- 偏好学习:从人类偏好中学习,优化输出
- 参数高效微调:最小化训练参数数量,提高特定任务性能
- SFT的主要技术:
主流PEFT的方法有哪些
主要是Adapter,Prefix Tuning和LoRA三大类。各具特点,在模型结构中所嵌入的位置也有所不同
图来自论文:TOWARDS A UNIFED VIEW OF PARAMETER-EFFICIENT TRANSFER LEARNING(arxiv.2110.04366)
- Adapter类:
- PEFT 技术通过在预训练模型的各层之间插入较小的神经网络模块,这些新增的神经模块被称为“适配器",在进行下游任务的微调时,只需对适配器参数进行训练便能实现高效微调的目标。
- 此基础上衍生出了AdapterP、Parallel等高效微调技术
- Prefix Tuning类:
- PEFT 技术通过在模型的输入或隐层添加 k k k个额外可训练的前缀标记,模型微调时只训练这些前缀参数便能实现高效微调的目标。
- 在此基础上衍生出了P-Tuning、P-Tuningv2等高效微调技术;
- LoRA类:
- PEFT 技术则通过学习小参数的低秩矩阵来近似模型权重矩阵W的参数更新,微调训练时只需优化低秩矩阵参数便能实现高效微调的目标。
- 在此基础上衍生出AdaLORA、QLORA等高效微调技术,
4. Adapters类微调
论文:Parameter-Efficient Transfer Learning for NLP,发表于2019年,当时主要是基于BERT改进(arxiv.1902.00751)
背景:
- 预训练模型参数量越来越多,在训练下游任务时进行全量微调变得昂贵且费时
- 基于此,提出Adapter Tuning,Adapter在预训练模型每层中插入用于下游任务的参数(针对每个下游任务,仅增加3.6%的参数),在微调时将模型主体冻结,仅训练特定于任务的参数,从而减少了训练时的算力开销。
Adapter Tuning 主要思想:
-
作者设计了一种新的Adapter结构,并将其嵌入Transformer的结构里面
-
针对每一个Transformer层,增加了两个Adapter结构(分别是多头注意力的投影之后和第二个feed-forward层之后)
-
在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter 结构和Layer Norm 层进行微调,从而保证了训练的高效性。每当出现新的下游任务,通过添加Adapter模块来产生一个易于扩展的下游模型,从而避免全量微调与灾难性遗忘的问题。

- 适配器模块的结构及其在Transformer中的集成方式
- 左图:我们在每一层Transformer中两次插入适配器模块,分别位于多头注意力机制后的投影操作之后,以及两个前馈层之后
- 右图:适配器模块的核心是一个参数较少的瓶颈结构,相较于原始模型中的注意力和前馈层,它的参数量非常少。此外,适配器模块中还包含一个跳跃连接(skip-connection)。在适配器微调阶段,绿色部分的层会基于下游任务的数据进行训练,包括适配器模块、层归一化参数,以及最终的分类层(未在图中显示)。
具体细节:
-
每个 Adapter 模块主要由两个前馈(Feed forward)子层组成,
-
第一个前馈子层(down-project)将Transformer块的输出作为输入,将原始输入维度
d(高维特征)投影到m(低维特征)通过控制m的大小来限制Adapter模块的参数量,通常情况下,m<<d -
然后,中间通过一个非线形层(Nonlinearity)。
-
在输出阶段,通过第二个前馈子层(up·project)还原输入维度,将
m(低维特征)重新映射回d(原来的高维特征),作为Adapter模块的输出。。
-
-
同时,通过一个跳跃连接(skip·connection)来将Adapter的输入重新加到最终的输出中去,这样可以保证,即便 Adapter一开始参数初始化接近0,Adapter也由于skip connection的设置而接近于一个恒等映射,从而确保训练的有效性。
-
通过实验发现,只训练少量参数的Adapter方法的效果可以媲美全量微调,这也验证了Adapter是一种高效的参数训练方法,可以快速将语言模型的能力迁移到下游任务中去。
-
Adapter通过引入0.5%~5%的模型参数可以达到不落后全量微调模型1%的性能
Adapter类的其他微调方法:
- Adapter Fusion:
- 通过将Adapter的训练分为知识提取和知识组合两部分,解决了灾难性遗忘、任务间干扰和训练不稳定的问题
- 但是,Adapter模块的添加也导致模型整体参数量的增加,降低了模型推理时的性能
- Adapter Drop:
- 通过从较低的Transformer层删除可变数量的Adapter来提升推理速度(删除无关的Adapters)。当对多个任务执行推理时,动态地减少了运行时的计算开销,并保持任务性能。
实战中用的并不多,但也要做一些了解。
5. Prefix类微调
Prefix类微调的几种方法:
-
Prefix Tuning:
-
在Prefix Tuning之前的工作主要是人工设计离散的模版或者自动化搜索离散的模版。
-
对于人工设计的模版,模版的变化对模型最终的性能特别敏感,加一个词、少一个词或者变动位置都会造成比较大的变化。
-
而对于自动化搜索模版,成本也比较高
-
同时,以前这种离散化的token搜索出来的结果可能并不是最优的。
-
除此之外,传统的微调范式利用预训练模型去对不同的下游任务进行微调,对每个任务都要保存一份微调后的模型权重,一方面微调整个模型耗时长,另一方面也会占很多存储空间。
-
技术原理:
-
基于上述两点,Prefix Tuning(论文:prefix-Tuning: Optimizing Continuous Prompts for Generation)提出固定预训练语言模型,为语言模型添加可训练,任务特定的前缀,这样就可以为不同任务保存不同的前缀,微调成本也小。
-
Prefix Tuning,在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而PLM中的其他部分参数固定。

- 上图:微调(顶部)更新所有Transformer参数(红色的Transformer框),并要求为每个任务存储一个完整的模型副本
- 下图:Prefix Tuning提出了前缀调优,它冻结了Transformer参数,只优化了前缀(红色前缀块),因此只需要存储每个任务的前缀,使前缀调优模块化节约空间
-
-
-
Prompt Tuning:
-
大模型全量微调对每个任务训练一个模型,开销和部署成本都比较高。
-
同时,离散的 prompts 方法,成本比较高,并且效果不太好
-
除此之外,之前的 Prefix Tuning 在更新参数的时候还是有些复杂。
-
技术原理:
-
基于此,作者提出了Prompt Tuning,通过反向传播更新参数来学习prompts,而不是人工设计prompts,同时冻结模型原始权重,只训练prompts参数,训练完以后,用同一个模型可以做多任务推理。
-
Prompt Tuning(论文:The Power of Scale for Parameter-Efficient PromptTuning),该方法可以看作是Prefix Tuning的简化版本
-
它给每个任务定义了自己的prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入多层感知器(MLP)进行调整来解决难训练的问题。

-
Model Tuning 需要为每个下游任务制作整个预训练模型的任务特定副本,并且必须分批进行推理。
-
Prompt Tuning 只需要为每个任务存储一个特定于任务的小提示,并使用原始预训练模型进行混合任务推理。
-
通过实验发现,随着预训练模型参数量的增加,Prompt Tuning的方法会逼近全参数微调的结果。

- T5经过调优后模型可以实现不错的性能,但弊端是需要为每个最终任务存储单独微调后的模型
- 随着模型参数的增加,对T5的 prompt tuning与model tuning 的能力差不多。
- 该方法明显优于使用GPT-3 few-shot prompt 设计
-
-
-
Prefix Tuning和Prompt Tuning在微调上有哪些区别?
- PromptTuning 和 Prefix Tuning,都是在自然语言处理任务中对预训练模型进行微调的方法,但它们在实现细节和应用场景上有所不同。
- 以下是它们之间的主要区别:
- 参数更新位置:Prompt Tuning通常只在输入层添加参数,而Prefix Tuning在每一层都添加了参数。
- 参数数量:Prefix Tuning 通常比 Prompt Tuning 有更多的可学习参数(因为它为模型的每一层都添加了前缀)
- 适用任务:Prompt Tuning 更适合于分类任务,而 Prefix Tuning 更适合于生成任务(因为它可以在不同层次上调整模型的行为)
- 训练效率:Prompt Tuning 通常有更高的训练效率
-
P-tuning:
-
P-tuning 方法的提出同样是为了解决之前提到的两个问题:大模型的Prompt构造方式严重影响下游任务的效果,
- 比如:GPT-3采用人工构造的模版来做上下文学习(in-context learning),但人工设计的模版的变化特别敏感,加一个词或者少一个词,或者变动位置都会造成比较大的变化。
-
近期,自动化搜索模版工作成本也比较高,以前这种离散化的token的搜索出来的结果可能并不是最优的,导致性能不稳定。
-
技术原理:
-
基于此,作者提出了P-Tuning(论文:GPTUnderstands, Too),设计了一种连续可微的virtual token。
-
该方法将Prompt转换为可以学习的Embedding层,并对Prompt Embedding进行一层处理。

- 一个快速搜索**英国首都是[MASK]**的例子:
-
-
-
图示中,颜色代表内容:
-
上下文(蓝色区域,英国)
-
目标(红色区域,[MASK])
-
橙色区域指的是提示,
- 在左图(a)中,提示生成器仅接收离散奖励;相反,在**右图(b)**中,连续提示嵌入和提示编码器可以以可微的方式进行优化。
-
-
相比Prefix Tuning,P-Tuning加入了可微的virtual token,但仅限于输入层,没有在每一层都加;另外,virtual token的位置也不一定是前缀,插入的位置是可选的。这里的出发点实际是把传统人工设计模版中的真实token替换成可微的virtual token
-
P-tuning v2:
之前的Prompt Tuning和P-Tuning等方法存在两个主要的问题:
-
第一,缺乏模型参数规模和任务通用性。
- 缺乏规模通用性:Prompt Tuning论文中表明当模型参数规模超过10B时,提示优化可以与全量微调相媲美。但是对于那些较小的模型(从100M到1B),提示优化和全量微调的表现有很大差异,这大大限制了提示优化的适用性。
- 缺乏任务普遍性:尽管Prompt Tuning和P-tuning在一些NLU基准测试中表现出优势,但提示调优对硬序列标记任务(即序列标注)的有效性尚未得到验证。
-
第二,缺少深度提示优化。
在Prompt Tuning和P-tuning中,连续提示只被插入transformer第一层的输入embedding序列中。在接下来的transformer层中,插入连续提示的位置的embedding是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战:
- 由于序列长度的限制,可调参数的数量是有限的
- 输入embedding对模型预测只有相对间接的影响
考虑到这些问题,作者提出了P-tuningv2,它对PromptTuning和P-Tuning进行改进,作为一个跨规模和NLU任务的通用解决方案。
-
**技术原理:**P-Tuning v2(论文:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks)方法在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:
- 更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%)
- 加入到更深层结构中的Prompt能给模型预测带来更直接的影响。

从P-tuning到P-tuning v2的变化:
-
橙色块(即 h 0 h_0 h0, …, h i h_i hi)表示可训练的 prompt embeddings
-
蓝色块是有冻结的预训练语言模型存储或计算的embeddings
- P-Tuningv2是一种在不同规模和任务中都可与微调相媲美的提示方法。P-Tuning v2对从330M到10B的模型显示出一致的改进,并在序列标注等困难的序列任务上以很大的幅度超过了PromptTuning和P-Tuning

- SuperGLUE的平均得分:使用0.1%的任务特定参数,P-tuning v2可以在预训练模型的大范围内进行微调,而 P-tuning 可以在10B的范围内进行有条件的微调。
-
Prefix类微调方法总结:
-
Prefix Tuning
- 在每一个Transformer层都带上一些virtual token作为前缓,以适应不同的任务。
- 优化多层prefix
- 与fine-tuning比肩
-
Prompt Tuning
- 该方法可以看着是Prefx Tunine的简化版本,针对不同的任务,仅在输入层引入virtualtoken形式的软提示(soft prompt)
- 优化单层prefix
- 大尺寸模型下与fine-tuning比肩
-
P-Tuning
- 将 Prompt 转换为可以学习的Embedding层。相比Prefix Tuning;仅在输入层加入的可微的vitualtoken;另外,virtual token的位置也不一定是前缀,插入的位置是可选的,
- 优化单层prefix
- 大尺寸模型下与fine-tuning比肩
-
P-Tuning v2
- 该方法在每一个Transformer层都加入了prompt token作为输入,引入多任务学习,针对不同任务采用不同的提示长度,
- 优化多层prefix
- 小尺寸和大尺寸模型下均与fine-tuning比肩
Prefix类微调方法介绍
Prefix Tuning
- 在每一个Transformer层都带上一些virtual token作为前缓,以适应不同的任务。
- 优化多层prefix
- 与fine-tuning比肩
Prompt Tuning
- 该方法可以看着是Prefx Tunine的简化版本,针对不同的任务,仅在输入层引入virtualtoken形式的软提示(soft prompt)
- 优化单层prefix
- 大尺寸模型下与fine-tuning比肩
P-Tuning
- 将 Prompt 转换为可以学习的Embedding层。相比Prefix Tuning;仅在输入层加入的可微的vitualtoken;另外,virtual token的位置也不一定是前缀,插入的位置是可选的,
- 优化单层prefix
- 大尺寸模型下与fine-tuning比肩
P-Tuning v2
- 该方法在每一个Transformer层都加入了prompt token作为输入,引入多任务学习,针对不同任务采用不同的提示长度,
- 优化多层prefix
- 小尺寸和大尺寸模型下均与fine-tuning比肩
PrefixTuning (2021.01)
- 论文题目:Prefix-Tuning: Optimizing Continuous Prompts for Generation
- 论文地址:hups://arxiv.org/pdf/2101.00190.pdf
- 论文源码:https://github,comxiangLi1999/PrefixTuning
P-tuning(2021.03)
- 论文题目:GPT Understands,Too
- 论文地址:https://arxiv,org/pdf/2103.10385.pdf
- 论文源码:https://github,com/THUDM/P-tuning
Prompt Tuning(2021.09)
- 论文题目:The Power of Scale for Parameter-Efficient Prompt Tuning
- 论文地址:https://arxiv,org/pdf/2104.08691.pdf
- 论文源码:https://github.com/google-research/prompt-tuning
P-tuning-v2(2022.03)
- 论文题目: P-Tuning v2: Prompt Tuning Can Be Comparable to finetuning Universally Across Scales and Tasks
- 论文地址:htps://arxiv,org/pdf/2110.07602.pdf
- 论文源码:https://github.com/THUDM/P-tuning-v2
20241209
冬雨将至,今年的冬天还不算太冷。
九点多下去慢跑,遇安迪,稍微多跑了几步,半个小时6K多,天冷又是期末,操场都没啥人了。
PS:AK今晚40分钟10K,感觉他还是想在福马最后冲击一下PB240,太拼了,最近三个月五场大比赛,身体负荷太大了,有点太急了,不太看好。
无聊补了个翻转色块小游戏(在每日演兵可视化上加了点料):
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@stu.sufe.edu.cn
import pygame
from pygame.locals import *
class Puzzle:
color_map = {
"white": (255, 255, 255),
"black": (0, 0, 0),
"red": (255, 0, 0),
"orange": (255, 165, 0),
"yellow": (255, 255, 0),
"green": (0, 255, 0),
"blue": (0, 255, 0),
"turquoise": (64, 224, 208),
"purple": (128, 0, 128),
"grey": (128, 128, 128),
}
block_index_to_color = list(color_map.keys())
def __init__(self,
n_puzzle_rows = 7,
n_puzzle_columns = 7,
window_height_pixel = 800,
window_width_pixel = 800,
):
self.n_puzzle_rows = n_puzzle_rows
self.n_puzzle_columns = n_puzzle_columns
self.window_height_pixel = window_height_pixel
self.window_width_pixel = window_width_pixel
self.block_height_pixel = window_height_pixel // n_puzzle_rows
self.block_width_pixel = window_width_pixel // n_puzzle_columns
self.window = self.initialize_window()
self.puzzle = self.initialize_puzzle()
# 初始化窗口
def initialize_window(self):
window = pygame.display.set_mode((self.window_height_pixel, self.window_width_pixel))
pygame.display.set_caption("Calendar Puzzle")
window.fill(self.color_map["white"])
return window
# 初始化拼图及每个块
def initialize_puzzle(self):
puzzle = []
for row in range(self.n_puzzle_rows):
puzzle.append(list())
for column in range(self.n_puzzle_columns):
block = {"row": row,
"column": column,
"x_location": column * self.block_width_pixel,
"y_location": row * self.block_height_pixel,
"color": self.color_map["white"],
}
puzzle[row].append(block)
return puzzle
# 绘制网格线
def draw_grid(self):
row_interval_pixel = self.window_height_pixel // self.n_puzzle_rows
height_interval_pixel = self.window_width_pixel // self.n_puzzle_columns
for i in range(self.n_puzzle_rows):
pygame.draw.line(
self.window,
self.color_map["black"],
(0, i * row_interval_pixel),
(self.window_width_pixel, i * row_interval_pixel),
)
for j in range(self.n_puzzle_columns):
pygame.draw.line(
self.window,
self.color_map["black"],
(j * height_interval_pixel, 0),
(j * height_interval_pixel, self.window_height_pixel),
)
# 绘制块
def draw_block(self, block):
pygame.draw.rect(
self.window,
block["color"],
(block["x_location"],
block["y_location"],
self.block_width_pixel,
self.block_height_pixel,
),
)
# 绘制拼图
def draw_puzzle(self):
for row in range(self.n_puzzle_rows):
for column in range(self.n_puzzle_columns):
self.draw_block(self.puzzle[row][column])
self.draw_grid()
pygame.display.update()
# 将点击位置的像素数转为对应的图块
def pressed_pos_to_row_column(self, pressed_pos):
row = pressed_pos[1] // self.block_height_pixel
column = pressed_pos[0] // self.block_width_pixel
return row, column
# 简单展示一个拼图
def display(self, puzzle_matrix = None):
run = True
while run:
if puzzle_matrix is not None:
for row in range(self.n_puzzle_rows):
for column in range(self.n_puzzle_columns):
block_index = int(puzzle_matrix[row][column])
self.puzzle[row][column]["color"] = self.block_index_to_color[block_index]
self.draw_block(self.puzzle[row][column])
self.draw_grid()
pygame.display.update()
for event in pygame.event.get():
if event.type == pygame.QUIT:
run = False
if event.type == KEYDOWN:
if event.key == K_ESCAPE:
run = False
# 主程序(交互)
def interact(self):
run = True
clock = pygame.time.Clock()
while run:
self.draw_puzzle()
for event in pygame.event.get():
if event.type == pygame.QUIT:
run = False
if event.type == KEYDOWN:
if event.key == K_ESCAPE:
run = False
left, center, right = pygame.mouse.get_pressed()
# TODO: 事件触发(目前不必要)
if left:
# 将点击的块颜色变为反色
pressed_pos = pygame.mouse.get_pos()
row, column = self.pressed_pos_to_row_column(pressed_pos)
print(row, column, "pressed")
neighbors = [(row, column)]
if row > 0:
neighbors.append((row - 1, column))
if row < self.n_puzzle_rows - 1:
neighbors.append((row + 1, column))
if column > 0:
neighbors.append((row, column - 1))
if column < self.n_puzzle_columns - 1:
neighbors.append((row, column + 1))
print(neighbors)
for neighbor in neighbors:
neighbor_block_color = self.puzzle[neighbor[0]][neighbor[1]]["color"]
self.puzzle[neighbor[0]][neighbor[1]]["color"] = (
255 - neighbor_block_color[0],
255 - neighbor_block_color[1],
255 - neighbor_block_color[2],
)
# pygame.display.flip()
clock.tick(15)
def demo_1():
puzzle = Puzzle(
n_puzzle_rows = 7,
n_puzzle_columns = 7,
window_height_pixel = 800,
window_width_pixel = 800,
)
puzzle.display(
[[1, 1, 1, 1, 2, 2, 2,],
[5, 6, 6, 6, 2, 2, 2,],
[5, 6, 6, 7, 7, 7, 7,],
[5, 5, 9, 9, 9, 3, 7,],
[5, 1, 4, 4, 9, 3, 3,],
[1, 1, 4, 8, 9, 8, 3,],
[1, 4, 4, 8, 8, 8, 3,],]
)
def demo_2():
puzzle = Puzzle(
n_puzzle_rows = 5,
n_puzzle_columns = 5,
window_height_pixel = 800,
window_width_pixel = 800,
)
puzzle.display(
[[2, 2, 3, 3, 3],
[2, 4, 4, 3, 6],
[2, 2, 4, 3, 6],
[5, 5, 4, 4, 6],
[5, 5, 5, 6, 6],
]
)
def demo_3():
puzzle = Puzzle(
n_puzzle_rows = 4,
n_puzzle_columns = 4,
window_height_pixel = 800,
window_width_pixel = 800,
)
puzzle.interact()
if __name__ == "__main__":
demo_3()
20241210 ☔️
寒潮,一轮降温。冒雨出去吃火锅,但今天完全没练。王京那边做的MoE,试图从并行和串行上改进,应用在价值生成任务上,然串行理论上违背多元价值的无序性,而并行又似乎创新度不够。其实我一直觉得MoE不就是bagging集成吗,穿个马甲又从水里钻出来了。
PS:下雨练个鸟?吃就完了(打了一辈子仗,就不能享受享受吗?
关于watchdog
def virus_6():
# 触发特定任务
def on_created(event):
print(event.src_path)
if event.src_path.endswith(".py"):
print(f"New Python script {event.src_path} created. Running it...")
# exec(open(event.src_path).read())
observer = Observer()
event_handler = MyHandler()
print(dir(event_handler))
input()
event_handler.on_created = on_created
observer.schedule(event_handler, path='./', recursive=True)
run_watchdog(observer)
def run_watchdog(observer):
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
print("KeyboardInterrupt")
observer.stop()
observer.join()
if __name__ == "__main__":
virus_6()
watchdog如果handler不绑定任何函数,默认任何操作都会触发监听,哪怕只是鼠标移动到文件上,选定都会触发,看来事件不止是创建、删除、改动这几个,查了一下源码event_handler一共有'on_any_event', 'on_closed', 'on_created', 'on_deleted', 'on_modified', 'on_moved', 'on_opened'这几个监听项目。
[OpenAI API] logprobs 与 top_logprobs 模型输出的置信度(confidence)与困惑度(PPL)
跟之前提到的那个幻觉消除很相关,OpenAI居然公开了模型输出的logits,现在不算是纯黑盒了,有理论分析的途径了。
- GPTs
- researchGPT:https://chat.openai.com/g/g-NgAcklHd8-researchgpt-official
- 润色GPT:https://chat.openai.com/g/g-VX52iRD3r-ai-paper-polisher-pro
参考:
- https://jfan001.medium.com/how-we-cut-the-rate-of-gpt-hallucinations-from-20-to-less-than-2-f3bfcc10e4ec
- https://cookbook.openai.com/examples/using_logprobs
logp = log ( p ) p = exp ( log ( p ) ) \begin{split} &\text{logp}=\log(p)\\ &p=\exp(\log(p)) \end{split} logp=log(p)p=exp(log(p))
logprobs和top_logprobs两个参数
- 定量的感知模型 API 的输出;
logprobs: the API returns the log probabilities of each output token, along with a limited number of the most likely tokens at each token position and their log probabilities.logprobs: Whether to return log probabilities of the output tokens or not. If true, returns the log probabilities of each output token returned in the content of message. This option is currently not available on the gpt-4-vision-preview model.top_logprobs: An integer between 0 and 5 specifying the number of most likely tokens to return at each token position, each with an associated log probability. logprobs must be set to true if this parameter is used.
- 数值分析 & 应用
- 0 ≤ p ≤ 1 → log ( p ) ≤ 0 0 \leq p\leq 1 \rightarrow \log (p)\leq 0 0≤p≤1→log(p)≤0
- Logprob can be any negative number or 0.0.
- 0.0 corresponds to 100% probability.
- check if the
p=e^(logprob)of the true token is below 90%.
- Logprobs allow us to compute the joint probability of a sequence as the sum of the logprobs of the individual tokens. This is useful for scoring and ranking model outputs. Another common approach is to take the average per-token logprob of a sentence to choose the best generation.
- log P ( S ) = log P ( x 1 , x 2 , . . . , x n ) = ∑ i log ( x i ∣ x < x i − 1 ) \log P(S)=\log P(x_1,x_2,...,x_n)=\sum_i \log (x_i|x_{\lt x_{i-1}}) logP(S)=logP(x1,x2,...,xn)=∑ilog(xi∣x<xi−1)
- 1 n ∑ i log P ( x i ∣ x < i ) \frac1n\sum_i\log P(x_i|x_{<i}) n1∑ilogP(xi∣x<i)
就是模型对每个解码生成的token的置信度,这个和之前提过的幻觉有点关系。不自信,就是可能出错的。
下面是log函数图像:
import numpy as np
import matplotlib.pyplot as plt
probs = np.arange(0.00001, 1, 0.01)
log_ps = np.log(probs)
plt.figure(figsize=(8, 5))
plt.plot(probs, log_ps, marker='o')
plt.title('Log Probabilities')
plt.xlabel('Index')
plt.ylabel('Log Probability')
plt.grid()
plt.show()
# Example probabilities (ensure no zero values to avoid log issues)
p = np.arange(0.01, 1, 0.01)
logp = np.log(p)
# Plot: x-axis is log(p), y-axis is p
plt.figure(figsize=(8, 5))
plt.plot(logp, p, marker='o')
plt.title('Log Probabilities vs Probabilities')
plt.xlabel('Log Probability (log(p))')
plt.ylabel('Probability (p)')
plt.grid()
plt.show()
先看一个补全任务
# !pip install -U openai
from openai import OpenAI
from math import exp
import numpy as np
from IPython.display import display, HTML
import os
from dotenv import load_dotenv
assert load_dotenv()
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def get_completion(
messages: list[dict[str, str]],
model: str = "gpt-4o-2024-08-06",
max_tokens=500,
temperature=0,
stop=None,
seed=123,
tools=None,
logprobs=None, # whether to return log probabilities of the output tokens or not. If true, returns the log probabilities of each output token returned in the content of message..
top_logprobs=None,
) -> str:
params = {
"model": model,
"messages": messages,
"max_tokens": max_tokens,
"temperature": temperature,
"stop": stop,
"seed": seed,
"logprobs": logprobs,
"top_logprobs": top_logprobs,
}
if tools:
params["tools"] = tools
completion = client.chat.completions.create(**params)
return completion
20241211 ❄️
- 试了下新食堂夜宵的烤鱼,以及那些蚕蛹蚂蚱啥的,尝个鲜,感觉一般。
- XXP难得回一趟实验室,明天他要开题。
- PS:跟DCY慢跑10K,遇到人就跑多了点,就当补昨天的呗。
使用logprobs来衡量分类任务的置信度
- Let’s say we want to create a system to classify news articles into a set of pre-defined categories. Without logprobs, we can use Chat Completions to do this, but it is much more difficult to assess the certainty with which the model made its classifications.
- Now, with logprobs enabled, we can see exactly how confident the model is in its predictions, which is crucial for creating an accurate and trustworthy classifier.
- For example, if the log probability for the chosen category is high, this suggests the model is quite confident in its classification.
- If it’s low, this suggests the model is less confident.
- This can be particularly useful in cases where the model’s classification is not what you expected, or when the model’s output needs to be reviewed or validated by a human.
一个文章类别分类的任务
CLASSIFICATION_PROMPT = """You will be given a headline of a news article.
Classify the article into one of the following categories: Technology, Politics, Sports, and Art.
Return only the name of the category, and nothing else.
MAKE SURE your output is one of the four categories stated.
Article headline: {headline}"""
headlines = [
"Tech Giant Unveils Latest Smartphone Model with Advanced Photo-Editing Features.",
"Local Mayor Launches Initiative to Enhance Urban Public Transport.",
"Tennis Champion Showcases Hidden Talents in Symphony Orchestra Debut",
]
for headline in headlines:
print(f"\nHeadline: {headline}")
API_RESPONSE = get_completion(
[{"role": "user", "content": CLASSIFICATION_PROMPT.format(headline=headline)}],
)
print(f"Category: {API_RESPONSE.choices[0].message.content}\n")
输出:
Headline: Tech Giant Unveils Latest Smartphone Model with Advanced Photo-Editing Features.
Category: Technology
Headline: Local Mayor Launches Initiative to Enhance Urban Public Transport.
Category: Politics
Headline: Tennis Champion Showcases Hidden Talents in Symphony Orchestra Debut
Category: Art
然后直接开用(gpt-4o):
from rich.pretty import pprint
pprint(
get_completion(
[{"role": "user", "content": CLASSIFICATION_PROMPT.format(headline='Tech Giant Unveils Latest Smartphone Model with Advanced Photo-Editing Features.')}],
logprobs=True,
top_logprobs=2,
)
)
"""
ChatCompletion(
│ id='chatcmpl-AbRmzsYyvSmgWYf8udpB4fdnOxPyb',
│ choices=[
│ │ Choice(
│ │ │ finish_reason='stop',
│ │ │ index=0,
│ │ │ logprobs=ChoiceLogprobs(
│ │ │ │ content=[
│ │ │ │ │ ChatCompletionTokenLogprob(
│ │ │ │ │ │ token='Technology',
│ │ │ │ │ │ bytes=[84, 101, 99, 104, 110, 111, 108, 111, 103, 121],
│ │ │ │ │ │ logprob=0.0,
│ │ │ │ │ │ top_logprobs=[
│ │ │ │ │ │ │ TopLogprob(
│ │ │ │ │ │ │ │ token='Technology',
│ │ │ │ │ │ │ │ bytes=[84, 101, 99, 104, 110, 111, 108, 111, 103, 121],
│ │ │ │ │ │ │ │ logprob=0.0
│ │ │ │ │ │ │ ),
│ │ │ │ │ │ │ TopLogprob(
│ │ │ │ │ │ │ │ token=' Technology',
│ │ │ │ │ │ │ │ bytes=[32, 84, 101, 99, 104, 110, 111, 108, 111, 103, 121],
│ │ │ │ │ │ │ │ logprob=-19.375
│ │ │ │ │ │ │ )
│ │ │ │ │ │ ]
│ │ │ │ │ )
│ │ │ │ ],
│ │ │ │ refusal=None
│ │ │ ),
│ │ │ message=ChatCompletionMessage(
│ │ │ │ content='Technology',
│ │ │ │ refusal=None,
│ │ │ │ role='assistant',
│ │ │ │ audio=None,
│ │ │ │ function_call=None,
│ │ │ │ tool_calls=None
│ │ │ )
│ │ )
│ ],
│ created=1733488321,
│ model='gpt-4o-2024-08-06',
│ object='chat.completion',
│ service_tier=None,
│ system_fingerprint='fp_c7ca0ebaca',
│ usage=CompletionUsage(
│ │ completion_tokens=1,
│ │ prompt_tokens=81,
│ │ total_tokens=82,
│ │ completion_tokens_details=CompletionTokensDetails(
│ │ │ accepted_prediction_tokens=0,
│ │ │ audio_tokens=0,
│ │ │ reasoning_tokens=0,
│ │ │ rejected_prediction_tokens=0
│ │ ),
│ │ prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0)
│ )
)
"""
手动解码:
bytes([84, 101, 99, 104, 110, 111, 108, 111, 103, 121]).decode("utf-8")
# 'Technology'
这个第一个'Technology'的logprob是0,也就是100%的置信度。
for headline in headlines:
print(f"\nHeadline: {headline}")
API_RESPONSE = get_completion(
[{"role": "user", "content": CLASSIFICATION_PROMPT.format(headline=headline)}],
logprobs=True,
top_logprobs=2,
)
generated_response = API_RESPONSE.choices[0].message.content.replace('\n', '<br>')
top_two_logprobs = API_RESPONSE.choices[0].logprobs.content[0].top_logprobs
html_content = (
f"<span style='color: green'>Generated response:</span> {generated_response}<br>"
)
for i, logprob in enumerate(top_two_logprobs, start=1):
html_content += (
f"<span style='color: cyan'>Output token {i}:</span> '{logprob.token}', "
f"<span style='color: darkorange'>logprobs:</span> {logprob.logprob}, "
f"<span style='color: magenta'>linear probability:</span> {np.round(np.exp(logprob.logprob)*100,2)}%<br>"
)
display(HTML(html_content))
print("\n")
输出:
Headline: Tech Giant Unveils Latest Smartphone Model with Advanced Photo-Editing Features.
Generated response: Technology
Output token 1: 'Technology', logprobs: 0.0, linear probability: 100.0%
Output token 2: ' Technology', logprobs: -19.25, linear probability: 0.0%
Headline: Local Mayor Launches Initiative to Enhance Urban Public Transport.
Generated response: Politics
Output token 1: 'Politics', logprobs: 0.0, linear probability: 100.0%
Output token 2: 'Polit', logprobs: -18.0, linear probability: 0.0%
Headline: Tennis Champion Showcases Hidden Talents in Symphony Orchestra Debut
Generated response: Art
Output token 1: 'Art', logprobs: -0.002037607, linear probability: 99.8%
Output token 2: 'Sports', logprobs: -6.3770375, linear probability: 0.17%
第三个的困惑度变大了,Art和Sport相对不是那么确信了。
再一个案例:
for headline in headlines:
print(f"\nHeadline: {headline}")
API_RESPONSE = get_completion(
[{"role": "user", "content": CLASSIFICATION_PROMPT.format(headline=headline)}],
model='gpt-4o-mini',
logprobs=True,
top_logprobs=2,
)
generated_response = API_RESPONSE.choices[0].message.content.replace('\n', '<br>')
top_two_logprobs = API_RESPONSE.choices[0].logprobs.content[0].top_logprobs
html_content = (
f"<span style='color: green'>Generated response:</span> {generated_response}<br>"
)
for i, logprob in enumerate(top_two_logprobs, start=1):
html_content += (
f"<span style='color: cyan'>Output token {i}:</span> '{logprob.token}', "
f"<span style='color: darkorange'>logprobs:</span> {logprob.logprob}, "
f"<span style='color: magenta'>linear probability:</span> {np.round(np.exp(logprob.logprob)*100,2)}%<br>"
)
display(HTML(html_content))
print("\n")
输出:
Headline: Tech Giant Unveils Latest Smartphone Model with Advanced Photo-Editing Features.
Generated response: Technology
Output token 1: 'Technology', logprobs: 0.0, linear probability: 100.0%
Output token 2: ' Technology', logprobs: -19.0, linear probability: 0.0%
Headline: Local Mayor Launches Initiative to Enhance Urban Public Transport.
Generated response: Politics
Output token 1: 'Politics', logprobs: -3.1281633e-07, linear probability: 100.0%
Output token 2: 'Polit', logprobs: -16.0, linear probability: 0.0%
Headline: Tennis Champion Showcases Hidden Talents in Symphony Orchestra Debut
Generated response: Art
Output token 1: 'Art', logprobs: -0.032066498, linear probability: 96.84%
Output token 2: 'Sports', logprobs: -4.0320663, linear probability: 1.77%
20241212☀️
蚂蚱还真挺好吃。
晚上九点半多才放人,赶在操场关门前去瞎跑了会儿。
破事多。下周末wyl搞pic会,这事倒是乐意。去年fujita让wyl替他chair自己的会eaiiae,wyl加班加点给他搞,哼哧哼哧找session chair和keynote speaker,置办场地。结果aieeai被ieee一直卡检索,到头来wyl自己的pic会没办,老头子就很气,觉得被fujita坑,其实那天我也很气,一大早去502叫他起床,虽然老头子是通了个宵,但是开门那一副邋遢样实在一言难尽,加上最后一天没管我饭,emmm。
PS:另外今天祝AK30岁(虚)生日,是不是该跑个30K庆祝一下呢?总有一天我们也会到30岁。SXY水平似有提高,节奏很稳,心率也下来了,应该是有人带的。
最近还有个新东西,GPT-4o提供了一个canvas,可以将生成的代码直接在canvas上展示和运行,方便交互了。
Sora依然一言难尽,就像chatgpt之前的胡说八道文章生成器一样,不知道多久Sora才能像点样子。
2 检索置信度评分以减少幻觉
- To reduce hallucinations, and the performance of our RAG-based Q&A system, we can use logprobs to evaluate how confident the model is in its retrieval.
has_sufficient_context_for_answer
# Article retrieved
ada_lovelace_article = """Augusta Ada King, Countess of Lovelace (née Byron; 10 December 1815 – 27 November 1852) was an English mathematician and writer, chiefly known for her work on Charles Babbage's proposed mechanical general-purpose computer, the Analytical Engine. She was the first to recognise that the machine had applications beyond pure calculation.
Ada Byron was the only legitimate child of poet Lord Byron and reformer Lady Byron. All Lovelace's half-siblings, Lord Byron's other children, were born out of wedlock to other women. Byron separated from his wife a month after Ada was born and left England forever. He died in Greece when Ada was eight. Her mother was anxious about her upbringing and promoted Ada's interest in mathematics and logic in an effort to prevent her from developing her father's perceived insanity. Despite this, Ada remained interested in him, naming her two sons Byron and Gordon. Upon her death, she was buried next to him at her request. Although often ill in her childhood, Ada pursued her studies assiduously. She married William King in 1835. King was made Earl of Lovelace in 1838, Ada thereby becoming Countess of Lovelace.
Her educational and social exploits brought her into contact with scientists such as Andrew Crosse, Charles Babbage, Sir David Brewster, Charles Wheatstone, Michael Faraday, and the author Charles Dickens, contacts which she used to further her education. Ada described her approach as "poetical science" and herself as an "Analyst (& Metaphysician)".
When she was eighteen, her mathematical talents led her to a long working relationship and friendship with fellow British mathematician Charles Babbage, who is known as "the father of computers". She was in particular interested in Babbage's work on the Analytical Engine. Lovelace first met him in June 1833, through their mutual friend, and her private tutor, Mary Somerville.
Between 1842 and 1843, Ada translated an article by the military engineer Luigi Menabrea (later Prime Minister of Italy) about the Analytical Engine, supplementing it with an elaborate set of seven notes, simply called "Notes".
Lovelace's notes are important in the early history of computers, especially since the seventh one contained what many consider to be the first computer program—that is, an algorithm designed to be carried out by a machine. Other historians reject this perspective and point out that Babbage's personal notes from the years 1836/1837 contain the first programs for the engine. She also developed a vision of the capability of computers to go beyond mere calculating or number-crunching, while many others, including Babbage himself, focused only on those capabilities. Her mindset of "poetical science" led her to ask questions about the Analytical Engine (as shown in her notes) examining how individuals and society relate to technology as a collaborative tool.
"""
# Questions that can be easily answered given the article
easy_questions = [
"What nationality was Ada Lovelace?",
"What was an important finding from Lovelace's seventh note?",
]
# Questions that are not fully covered in the article
medium_questions = [
"Did Lovelace collaborate with Charles Dickens",
"What concepts did Lovelace build with Charles Babbage",
]
# JUST
PROMPT = """You retrieved this article: {article}. The question is: {question}.
Before even answering the question, consider whether you have sufficient information in the article to answer the question fully.
Your output should JUST be the boolean true or false, of if you have sufficient information in the article to answer the question.
Respond with just one word, the boolean true or false. You must output the word 'True', or the word 'False', nothing else.
"""
API_RESPONSE = get_completion(
[
{
"role": "user",
"content": PROMPT.format(
article=ada_lovelace_article, question="Did Lovelace collaborate with Charles Dickens"
),
}
],
model="gpt-4",
logprobs=True,
)
pprint(API_RESPONSE)
"""
ChatCompletion(
│ id='chatcmpl-AbRtxaI8UkXs9rrr7PCJBS3pAhkc3',
│ choices=[
│ │ Choice(
│ │ │ finish_reason='stop',
│ │ │ index=0,
│ │ │ logprobs=ChoiceLogprobs(
│ │ │ │ content=[
│ │ │ │ │ ChatCompletionTokenLogprob(
│ │ │ │ │ │ token='True',
│ │ │ │ │ │ bytes=[84, 114, 117, 101],
│ │ │ │ │ │ logprob=-0.06760397,
│ │ │ │ │ │ top_logprobs=[]
│ │ │ │ │ )
│ │ │ │ ],
│ │ │ │ refusal=None
│ │ │ ),
│ │ │ message=ChatCompletionMessage(
│ │ │ │ content='True',
│ │ │ │ refusal=None,
│ │ │ │ role='assistant',
│ │ │ │ audio=None,
│ │ │ │ function_call=None,
│ │ │ │ tool_calls=None
│ │ │ )
│ │ )
│ ],
│ created=1733488753,
│ model='gpt-4-0613',
│ object='chat.completion',
│ service_tier=None,
│ system_fingerprint=None,
│ usage=CompletionUsage(
│ │ completion_tokens=1,
│ │ prompt_tokens=698,
│ │ total_tokens=699,
│ │ completion_tokens_details=CompletionTokensDetails(
│ │ │ accepted_prediction_tokens=0,
│ │ │ audio_tokens=0,
│ │ │ reasoning_tokens=0,
│ │ │ rejected_prediction_tokens=0
│ │ ),
│ │ prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0)
│ )
)
"""
pprint(get_completion(
[
{
"role": "user",
"content": PROMPT.format(
article=ada_lovelace_article, question=question
),
}
],
model="gpt-4",
logprobs=True,
top_logprobs=3,
)
)
"""
ChatCompletion(
│ id='chatcmpl-AbRxyt8e62V0e5cMdR3y4b3DBUbMX',
│ choices=[
│ │ Choice(
│ │ │ finish_reason='stop',
│ │ │ index=0,
│ │ │ logprobs=ChoiceLogprobs(
│ │ │ │ content=[
│ │ │ │ │ ChatCompletionTokenLogprob(
│ │ │ │ │ │ token='True',
│ │ │ │ │ │ bytes=[84, 114, 117, 101],
│ │ │ │ │ │ logprob=-0.51145124,
│ │ │ │ │ │ top_logprobs=[
│ │ │ │ │ │ │ TopLogprob(token='True', bytes=[84, 114, 117, 101], logprob=-0.51145124),
│ │ │ │ │ │ │ TopLogprob(token='False', bytes=[70, 97, 108, 115, 101], logprob=-0.9153552),
│ │ │ │ │ │ │ TopLogprob(token='false', bytes=[102, 97, 108, 115, 101], logprob=-14.718182)
│ │ │ │ │ │ ]
│ │ │ │ │ )
│ │ │ │ ],
│ │ │ │ refusal=None
│ │ │ ),
│ │ │ message=ChatCompletionMessage(
│ │ │ │ content='True',
│ │ │ │ refusal=None,
│ │ │ │ role='assistant',
│ │ │ │ audio=None,
│ │ │ │ function_call=None,
│ │ │ │ tool_calls=None
│ │ │ )
│ │ )
│ ],
│ created=1733489002,
│ model='gpt-4-0613',
│ object='chat.completion',
│ service_tier=None,
│ system_fingerprint=None,
│ usage=CompletionUsage(
│ │ completion_tokens=1,
│ │ prompt_tokens=701,
│ │ total_tokens=702,
│ │ completion_tokens_details=CompletionTokensDetails(
│ │ │ accepted_prediction_tokens=0,
│ │ │ audio_tokens=0,
│ │ │ reasoning_tokens=0,
│ │ │ rejected_prediction_tokens=0
│ │ ),
│ │ prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0)
│ )
)
"""
开始问GPT-4o
html_output = ""
html_output += "Questions clearly answered in article"
for question in easy_questions:
API_RESPONSE = get_completion(
[
{
"role": "user",
"content": PROMPT.format(
article=ada_lovelace_article, question=question
),
}
],
model="gpt-4",
logprobs=True,
)
html_output += f'<p style="color:green">Question: {question}</p>'
for logprob in API_RESPONSE.choices[0].logprobs.content:
html_output += f'<p style="color:cyan">has_sufficient_context_for_answer: {logprob.token}, <span style="color:darkorange">logprobs: {logprob.logprob}, <span style="color:magenta">linear probability: {np.round(np.exp(logprob.logprob)*100,2)}%</span></p>'
html_output += "Questions only partially covered in the article"
for question in medium_questions:
API_RESPONSE = get_completion(
[
{
"role": "user",
"content": PROMPT.format(
article=ada_lovelace_article, question=question
),
}
],
model="gpt-4",
logprobs=True,
top_logprobs=3,
)
html_output += f'<p style="color:green">Question: {question}</p>'
for logprob in API_RESPONSE.choices[0].logprobs.content:
html_output += f'<p style="color:cyan">has_sufficient_context_for_answer: {logprob.token}, <span style="color:darkorange">logprobs: {logprob.logprob}, <span style="color:magenta">linear probability: {np.round(np.exp(logprob.logprob)*100,2)}%</span></p>'
display(HTML(html_output))
输出结果:
Questions clearly answered in article
Question: What nationality was Ada Lovelace?
has_sufficient_context_for_answer: True, logprobs: -1.9361265e-07, linear probability: 100.0%
Question: What was an important finding from Lovelace's seventh note?
has_sufficient_context_for_answer: True, logprobs: -4.3202e-07, linear probability: 100.0%
Questions only partially covered in the article
Question: Did Lovelace collaborate with Charles Dickens
has_sufficient_context_for_answer: True, logprobs: -0.027298978, linear probability: 97.31%
Question: What concepts did Lovelace build with Charles Babbage
has_sufficient_context_for_answer: True, logprobs: -0.29815888, linear probability: 74.22%
这个就是GPT-4o比GPT-4更自信
同样,另一个例子:
html_output = ""
html_output += "Questions clearly answered in article"
for question in easy_questions:
API_RESPONSE = get_completion(
[
{
"role": "user",
"content": PROMPT.format(
article=ada_lovelace_article, question=question
),
}
],
logprobs=True,
)
html_output += f'<p style="color:green">Question: {question}</p>'
for logprob in API_RESPONSE.choices[0].logprobs.content:
html_output += f'<p style="color:cyan">has_sufficient_context_for_answer: {logprob.token}, <span style="color:darkorange">logprobs: {logprob.logprob}, <span style="color:magenta">linear probability: {np.round(np.exp(logprob.logprob)*100,2)}%</span></p>'
html_output += "Questions only partially covered in the article"
for question in medium_questions:
API_RESPONSE = get_completion(
[
{
"role": "user",
"content": PROMPT.format(
article=ada_lovelace_article, question=question
),
}
],
logprobs=True,
top_logprobs=3,
)
html_output += f'<p style="color:green">Question: {question}</p>'
for logprob in API_RESPONSE.choices[0].logprobs.content:
html_output += f'<p style="color:cyan">has_sufficient_context_for_answer: {logprob.token}, <span style="color:darkorange">logprobs: {logprob.logprob}, <span style="color:magenta">linear probability: {np.round(np.exp(logprob.logprob)*100,2)}%</span></p>'
display(HTML(html_output))
Questions clearly answered in article
Question: What nationality was Ada Lovelace?
has_sufficient_context_for_answer: True, logprobs: -2.220075e-06, linear probability: 100.0%
Question: What was an important finding from Lovelace's seventh note?
has_sufficient_context_for_answer: True, logprobs: -2.2484697e-05, linear probability: 100.0%
Questions only partially covered in the article
Question: Did Lovelace collaborate with Charles Dickens
has_sufficient_context_for_answer: False, logprobs: -0.0011922525, linear probability: 99.88%
Question: What concepts did Lovelace build with Charles Babbage
has_sufficient_context_for_answer: True, logprobs: -0.008621786, linear probability: 99.14%
20241213☁️
最近又是越吃越饿,越饿越想吃,中午吃四个菜到四点,肚子都能咕咕叫,emmm
LYC下周二要回院里做报告,本科毕业去港中深之后就一直没听到他消息了,看照片还是老样子。他还是做的收益管理的东西,感觉RM本质上还是在如何优化上创新,目标和约束的建模已经很难再精进了,因为最简单的建模都是很难精确求解的。后来我就发现,三年前我看RM的时候,顺带做的稀疏训练的东西其实就是现在的LoRA,那时候还手写了份稀疏训练,那时候还叫SVD Training,其实现在看本质上跟LoRA没啥区别,而且SVD Training那篇是20年4月的东西(2004.09031),LoRA都到21年10月了(2110.04366),晚了有一年半,但现在根本没人提SVD Training
还有一件事,其实是十天前的事情了,前几天才看到,移动沙发问题被一个韩国数学家解决,119页的证明论文挂到arxiv上(https://arxiv.org/abs/2411.19826),这个问题大概两年前第一次看到,当时想写一个仿真来求解,但难点在于,你可以构造出更优的沙发,但是永远无法证明构造是最优的(沙发形状无穷多,至少那时候大家都觉得找不到好办法来论证),不过我现在看他证明的上界2.37好像就是前人构造好的那个版本的沙发(他似乎撤了一版稿,现在这版是最原始的),是不是伪证看不出来,但是这个问题其实已经是一种非常特殊的情况了(直角弯,且两边走廊等宽,而且还是二维,没有拓展到实际的三维情况,改变任意一个条件,问题都将复杂得多,然后这最简单的情况我们似乎也不能很好的解决)
PS:晚上有兴致八点多独自跑个倒金字塔,短袖猛干。状态尚可,原计划想自测万米,但是一个人根本顶不下来,也是太冷了点。有去年冬训的兴奋感,只是缺了一起疯的伴。
高亮输出(仅jupyter可用,使用html标签上色):
high_prob_completions = {}
low_prob_completions = {}
html_output = ""
for sentence in sentence_list:
PROMPT = """Complete this sentence. You are acting as auto-complete. Simply complete the sentence to the best of your ability, make sure it is just ONE sentence: {sentence}"""
API_RESPONSE = get_completion(
[{"role": "user", "content": PROMPT.format(sentence=sentence)}],
model="gpt-4o-mini",
logprobs=True,
top_logprobs=3,
)
html_output += f'<p>Sentence: {sentence}</p>'
first_token = True
for token in API_RESPONSE.choices[0].logprobs.content[0].top_logprobs:
html_output += f'<p style="color:cyan">Predicted next token: {token.token}, <span style="color:darkorange">logprobs: {token.logprob}, <span style="color:magenta">linear probability: {np.round(np.exp(token.logprob)*100,2)}%</span></p>'
if first_token:
if np.exp(token.logprob) > 0.95:
high_prob_completions[sentence] = token.token
if np.exp(token.logprob) < 0.60:
low_prob_completions[sentence] = token.token
first_token = False
html_output += "<br>"
display(HTML(html_output))
5 困惑度计算(perplexity, PPL)
- perplexity, a measure of the uncertainty.
- Perplexity can be calculated by exponentiating the negative of the average of the logprobs.
- exp(-avg(logp))
- a higher perplexity indicates a more uncertain result, and a lower perplexity indicates a more confident result.
- As such, perplexity can be used to both assess the result of an individual model run and also to compare the relative confidence of results between model runs.
- While a high confidence doesn’t guarantee result accuracy, it can be a helpful signal that can be paired with other evaluation metrics to build a better understanding of your prompt’s behavior.
P P L = exp ( − 1 n ∑ i log P ( x i ∣ x < i ) ) = exp ( log P ( S ) − 1 n ) = P ( S ) − 1 n \begin{split} PPL&=\exp\left(-\frac1n\sum_i\log P(x_i|x_{\lt i})\right)\\ &=\exp\left(\log P(S)^{-\frac1n}\right)\\ &=P(S)^{-\frac1n} \end{split} PPL=exp(−n1i∑logP(xi∣x<i))=exp(logP(S)−n1)=P(S)−n1
prompts = [
"In a short sentence, has artifical intelligence grown in the last decade?",
"In a short sentence, what are your thoughts on the future of artificial intelligence?",
]
for prompt in prompts:
API_RESPONSE = get_completion(
[{"role": "user", "content": prompt}],
model="gpt-3.5-turbo",
logprobs=True,
)
logprobs = [token.logprob for token in API_RESPONSE.choices[0].logprobs.content]
response_text = API_RESPONSE.choices[0].message.content
response_text_tokens = [token.token for token in API_RESPONSE.choices[0].logprobs.content]
max_starter_length = max(len(s) for s in ["Prompt:", "Response:", "Tokens:", "Logprobs:", "Perplexity:"])
max_token_length = max(len(s) for s in response_text_tokens)
formatted_response_tokens = [s.rjust(max_token_length) for s in response_text_tokens]
formatted_lps = [f"{lp:.2f}".rjust(max_token_length) for lp in logprobs]
perplexity_score = np.exp(-np.mean(logprobs))
print("Prompt:".ljust(max_starter_length), prompt)
print("Response:".ljust(max_starter_length), response_text, "\n")
print("Tokens:".ljust(max_starter_length), " ".join(formatted_response_tokens))
print("Logprobs:".ljust(max_starter_length), " ".join(formatted_lps))
print("Perplexity:".ljust(max_starter_length), perplexity_score, "\n")
输出结果:
Prompt: In a short sentence, has artifical intelligence grown in the last decade?
Response: Yes, artificial intelligence has grown significantly in the last decade.
Tokens: Yes , artificial intelligence has grown significantly in the last decade .
Logprobs: -0.00 -0.00 -0.00 -0.00 -0.00 -0.24 -0.08 -0.00 -0.00 -0.00 -0.00 -0.00
Perplexity: 1.0278720155134078
Prompt: In a short sentence, what are your thoughts on the future of artificial intelligence?
Response: The future of artificial intelligence holds great potential for transforming industries and improving efficiency, but also raises ethical and societal concerns that must be carefully addressed.
Tokens: The future of artificial intelligence holds great potential for transforming industries and improving efficiency , but also raises ethical and societal concerns that must be carefully addressed .
Logprobs: -0.18 -0.02 -0.00 -0.00 -0.00 -0.22 -0.53 -0.26 -0.04 -1.45 -0.20 -0.09 -0.24 -0.85 -0.18 -0.00 -0.34 -0.06 -0.47 -0.64 -0.20 -0.22 -0.01 -0.14 -0.00 -0.57 -0.48 -0.00
Perplexity: 1.3019616728795984
另一个例子:
prompts = [
"In a short sentence, has artifical intelligence grown in the last decade?",
"In a short sentence, what are your thoughts on the future of artificial intelligence?",
]
for prompt in prompts:
API_RESPONSE = get_completion(
[{"role": "user", "content": prompt}],
logprobs=True,
)
logprobs = [token.logprob for token in API_RESPONSE.choices[0].logprobs.content]
response_text = API_RESPONSE.choices[0].message.content
response_text_tokens = [token.token for token in API_RESPONSE.choices[0].logprobs.content]
max_starter_length = max(len(s) for s in ["Prompt:", "Response:", "Tokens:", "Logprobs:", "Perplexity:"])
max_token_length = max(len(s) for s in response_text_tokens)
formatted_response_tokens = [s.rjust(max_token_length) for s in response_text_tokens]
formatted_lps = [f"{lp:.2f}".rjust(max_token_length) for lp in logprobs]
perplexity_score = np.exp(-np.mean(logprobs))
print("Prompt:".ljust(max_starter_length), prompt)
print("Response:".ljust(max_starter_length), response_text, "\n")
print("Tokens:".ljust(max_starter_length), " ".join(formatted_response_tokens))
print("Logprobs:".ljust(max_starter_length), " ".join(formatted_lps))
print("Perplexity:".ljust(max_starter_length), perplexity_score, "\n")
Prompt: In a short sentence, has artifical intelligence grown in the last decade?
Response: Yes, artificial intelligence has significantly grown in the last decade, advancing in capabilities and applications.
Tokens: Yes , artificial intelligence has significantly grown in the last decade , advancing in capabilities and applications .
Logprobs: -0.00 0.00 -0.00 -0.00 -0.00 -0.80 -0.28 -0.58 -0.23 -0.00 0.00 -0.08 -0.26 -0.03 -0.40 -0.39 -0.03 -0.69
Perplexity: 1.2335266571550456
Prompt: In a short sentence, what are your thoughts on the future of artificial intelligence?
Response: The future of artificial intelligence holds immense potential for innovation and transformation across various sectors, but it also requires careful consideration of ethical and societal impacts.
Tokens: The future of artificial intelligence holds immense potential for innovation and transformation across various sectors , but it also requires careful consideration of ethical and societal impacts .
Logprobs: -0.10 -0.00 0.00 -0.00 0.00 -0.05 -0.39 -0.01 -0.02 -0.76 -0.13 -0.13 -0.19 -0.11 -0.25 -0.01 -0.17 -0.05 -0.07 -0.53 -0.02 -0.35 -0.00 -0.00 -0.45 -0.01 -0.43 -0.00
Perplexity: 1.163746216545455
20241214☀️
零下,大晴天,但还是太冷。然而wyl还在持续输出,烦呐。
回血,中午小排汤,晚上鸡汤面,熏鱼和蒸鱼,突出一个吃肉。晚
PS:上小练了一下力量,4组箭步×30个(+20kg),然后负重踮脚前掌和脚后跟一共走了一圈,膝盖窝有点疼,昨天太用力了,箭步做的有点疼。
所有解都跑出来了,平均每个求解时间20分钟左右:

LoRA的一些细节问题总结:
LoRA应该作用于Transformer的哪个参数矩阵(Q, K, V)?
答:根据之前2110.04366里的图,应该是作用于Q和K

拓展:
- 什么是rank?
- 在机器学习中,rank通常指矩阵的秩,表示矩阵中线性独立行或列的数量
- 在LoRA方法中,rank用于限制可训练参数的数量,通过低秩表示来高效调整模型。(本质上是通过将高维网络层改写为几个低维的网络层的迭加,矩阵表示类似于几个低秩矩阵的乘积)
- 通过降低秩,减少参数空间的自由度,使得模型在训练时更加高效,而不会显著影响性能,这是LoRA的核心思想。
上表中,当提到rank为8或4时,表示的是原始大的权重矩阵进行近似表示时所用的线性独立向量的数量,从而调整的可训练参数的数量。
-
表中部分内容的介绍:
- WikiSQL:专注于SQL生成任务的数据集,提供自然语言问题和SQL查询的对照
- MultiNLI:用于NLP推理的数据集,包含不同体裁的文本对,任务是判断一个给定前提和假设之间的关系,比如蕴含、矛盾还是中立。这个数据集用于评估模型在跨领域推理任务中的表现
- 几个权重矩阵: W q , W k , W v , W o W_q,W_k,W_v,W_o Wq,Wk,Wv,Wo,分别是生成 Q , K , V Q,K,V Q,K,V向量的权重矩阵,最后一个 W o W_o Wo是将多头注意力的输出组合起来的输出投影权重矩阵
-
表中内容的翻译:
- 在对GPT3的不同注意权重应用LoRA后,WikiSQL和MultiNLI数据集上的验证准确性。这里使用的是相同数量的可训练参数,调整 W q W_q Wq和 W v W_v Wv一起提供了最佳的整体性能。
- 需要注意的是,仅调整 Δ W q \Delta W_q ΔWq或 Δ W k \Delta W_k ΔWk会导致性能显著下降,而同时调整 Δ W q \Delta W_q ΔWq和 Δ W k \Delta W_k ΔWk能得到不错的效果。
- 这说明,即使秩设为4, Δ W \Delta W ΔW中也能捕获足够的信息,因此比起只调整单一类型的大秩权重,调整更多种类的权重矩阵效果会更好。
表总结:
- 将所有微调参数都放到attention的某一参数矩阵的效果并不好,将可微调参数分配到 W q W_q Wq和 W v W_v Wv的效果更好
- 即使是秩仅取4也能在 Δ W \Delta W ΔW中获得足够信息
- 因此在实际操作中,应当将可微调参数分配到多种类型权重矩阵中,而不应该用更大的秩单独微调某种类型的权重矩阵。
如何在已有LoRA模型上继续训练?
理解此问题的情形是:已有的lora模型只训练了一部分数据,要训练另一部分数据的话。
- 是在这个lora上继续训练呢?
- 还是和base模型合并后再套一层lora
- 或者从头开始训练一个lora?
-
直接在现有的lora模型上继续训练
- 适用情况:新的数据与之前数据相似,任务也相似
- 操作步骤
- 将新的数据用于继续训练现有的LoRA模型
- 这样,LoRA模型的权重将进一步更新,融合新知识
- 优点:保留模型之前学习的知识,节省训练资源和时间
- 注意事项:需要注意过拟合问题,可以适当使用正则化技术。且如果新数据分布有差异,可能需要调整学习率或其他超参。
-
将LoRA和BASE合并后得到新的BASE模型,再训练新的Lora
- 适用情况:想要在模型中固化之前的知识,然后再新任务上进一步微调
- 操作步骤:
- 将现有的Lora权重合并到Base模型中,得到新的Base模型
- 在新的Base模型上训练Lora层
- 优点:知识固化,新的Lora专注于学习新任务的特征。有助于模块化地管理不同任务的适应
- 缺点:模型容量增加,占用更多存储空间
-
从头训练Lora:
- 适用情况:新任务与之前任务完全不同,或者担心以前的知识会干扰新的学习
- 操作步骤:使用基础模型,直接训练Lora层
- 优点:模型更加专注,避免旧知识的干扰。模型更加专注于新任务
- 缺点:无法利用之前训练中获得的知识,可能需要更多的训练数据和时间。完全无法使用旧知识,有点浪费资源。
总结:根据任务需求选择(任务相似、任务不同但有相关性、任务完全不同)
LoRA权重是否可以合入原模型?
- 可以,将训练好的低秩矩阵 ( B × A ) + 原模型权重合并(即相加) (B\times A)+原模型权重合并(即相加) (B×A)+原模型权重合并(即相加),计算
LoRA微调方法为什么能加速训练
-
只更新了部分参数:比如LoRA原论文就选择只更新self-attention的参数,实际使用时我们还可以选择只更新部分层的参数
-
减少了通信时间:参数少,需要传输的数据量也就变少了
-
采用了各种低精度加速技术:FP16 FP8 INT8
-
低秩分解的直观性:LoRA使用低秩分解方式更新和表示参数。这种方法再不少场景种能够很好地保持与全量微调相同的效果,同时本身非常直观易于理解
-
预测阶段不增加推理成本:LoRA的设计确保再推理阶段不会额外增加计算成本。因为微调的调整是通过低秩矩阵的形式添加的,并且再应用时已经被整合到模型参数中,不需要额外的运算,这有利于保持推理速度。
LoRA中的rank如何选取?
- 作者对比了1-64的rank,效果上4-8之间最好,再高没有效果提升
- 不过论文的实验是面向下游单一监督任务的,因此在指令微调上根据指令分布的广度,rank选择还是需要在8以上的取值进行测试的。
LoRA如何避免过拟合?
在使用LoRA进行微调时,过拟合是一个常见的问题(训练数据表现得好,但是在测试集上表现差,通常因为模型过度学习训练数据细节和噪声,而未抓住数据得普遍规律)
具体方法:
- 减小rank值
- 增加数据集大小
- 增加优化器得权重衰减率(weight decay)
- 增加LoRA层的dropout值
- 解释:Dropout是一种防止过拟合的技术,通过在训练过程中随机忽略部分神经元,使模型不依赖于特定的神经元
- 如何避免过拟合:在LoRA层增加Dropout,可以随机屏蔽部分LoRA层的参数,使模型更具鲁棒性,减少对特定参数的过度依赖,从而降低过拟合的风险。
LoRA矩阵初始化?
前面我们已经知道:
- 降维 矩阵 A A A采用高斯分布(正态分布) 来初始化,以赋予其随即特性
- 而升维矩阵 B B B初始化为零矩阵,这样开始训练时就不会影响原有模型的输出,确保训练稳定性
权重更新方式为:
W = W 0 + A B ⊤ W=W_0 + AB^\top W=W0+AB⊤
这种操作有如下的考量:
-
为什么不把 A A A和 B B B都初始化为零?
- 此时 W = W 0 W=W_0 W=W0,意味着训练开始时,模型参数没有任何变化
- 缺点:
- 可能出现梯度消失和对称性问题:所有神经元的初始状态和更新方向都相同,导致网络无法打破对称性。这样一来,神经元无法学习到多样化的特征,影响模型的表达能力
- 训练困难:梯度更新可能会因为缺乏初始扰动而过于缓慢,导致训练过程收敛速度变慢,甚至无法收敛
-
为什么不把 A A A和 B B B都用高斯初始化?
-
此时,初始权重更新为: Δ W = A B ⊤ \Delta W=AB^\top ΔW=AB⊤,由于 A A A和 B B B都是随机初始化的,因此 Δ W \Delta W ΔW也是一个随机矩阵,并且可能具有较大的值。
-
缺点:
- 初始扰动过大:过大的 Δ W \Delta W ΔW会在训练开始时对原有的预训练模型参数造成过大扰动,可能导致模型的输出偏离预期,训练不稳定
- 收敛困难:过大的初始噪声可能导致梯度爆炸,模型难以找到正确的优化方向,从而影响训练效果。
-
-
为什么不用高斯分布初始化 A A A,零矩阵初始化 B B B
- 理论上,LoRA矩阵初始化可以对调,由于LoRA的核心思想是通过低秩分解来更新预训练权重矩阵 W 0 W_0 W0,最终训练的效果取决于模型对 Δ W = A B ⊤ \Delta W=AB^\top ΔW=AB⊤的学习能力,而不是特定的初始化方式。
- 可能的影响:
- 优化过程:梯度如何影响 B B B和 A A A的学习方向。
- 数值稳定性:论文中推荐的方式可能经过了实验验证,确保在实际应用中具有较好的数值稳定性,如果对调初始化,可能需要重新调试超参数。
总结:通过矩阵 A A A采用高斯分布(正态分布) 来初始化,升维矩阵 B B B初始化为零矩阵,可以:
- 保持模型初始输出与预训练模型一致,避免初始扰动过大
- 利用 A A A的随机性打破对称性,提供丰富的梯度信息
- 在训练过程中, B B B从零开始逐步学习,有效控制权重更新幅度,促进模型稳定收敛。
#@# AdaLoRA
LoRA通过低秩分解来模拟参数的该变量,从而以极小的参数量来实现大模型的间接训练
AdaLoRA是对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵,将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合,并节省计算成本。
AdaLoRA讨论了如何更好地进行秩的设置:
- 它引入了一种动态低秩适应技术,在训练过程中动态调整每个参数矩阵需要训练的秩同时控制训练的参数总量。
具体来说,模型在微调过程中通过损失来衡量每个参数矩阵对训练结果的重要性,重要性较高的参数矩阵被赋予比较高的秩,进而能够更好地学习到有助于任务的信息。相对而言,不太重要的参数矩阵被给予比较低的秩,来防止过拟合并节省计算资源。
代码:https://github.com/QingruZhang/AdaLoRA
20241215☀️(AK破240)
跟wyl一直搞到凌晨4点才睡,然后一觉醒来。。。
年末的奇迹!AK居然真的破240了,情理之中,又在意料之外。这个真的只能说懂得都懂了。虽然赛前确实不看好AK能破,但这确实是很振奋的消息。
- 后来才知道原来是有香风加持,有唐晓芬和唐晓芳姐妹的破风(不过AK这次应该比她俩快不少的,她俩应该是243左右跑完的)
我跟嘉伟讲,看来明年上半年,我俩真都得努力冲一下PB了,嘉伟至少是半马120,全马250,我还是保守一点先把3破了。
AK是真的太强了,五年了,五年没有PB,真给他在30岁生日之后的3天跑出来了,枪声24006,净时间23928,无需多言。
另外蒋蔚文(86级金融)破三,50多岁了,不跑到250,果真是拿不出手了如今。

QLoRA的思路
代码:https://github.com/artidoro/glora
- 尽管 LORA 已经轻量化了,但由于使用 BFloat16 进行训练,微调特别大的模型(65B以上)时无法使用单张卡或几张卡进行训练。
- QLORA是 LORA 的改进版,可以减少内存使用,可以在单个48GB GPU上微调 65B 的大模型,同时保留完整的16位微调任务性能。
- 其工作原理是首先将 LLM 进行4位量化,从而显著减少模型的内存占用;然后使用 LORA 对量化的LLM进行微调。
- 使用 QLORA可以节省 33%的GPU内存。然而,由于 QLORA 中预训练模型权重的额外量化和去量化,训练时间增加了39%。
大致思想:
- 使用一种新颖的高精度技术将预训练模型量化为 4bit;
- 然后添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行微调。
特点:
- 使用 QLORA 微调模型,可以显著降低对于显存的要求。但是,模型训练的速度会慢于LORA。
7. PEFT中,基座模型应该选用Chat版本还是Base版本?
-
如果监督任务是对话生成相关的任务
- 示例:生成对话回复、对话情感分析、多轮对话管理等
- 建议:选择ChatGPT类模型作为基座
- 原因:
- ChatGPT 模型经过专门的对话数据训练,具备更强的对话交互能力。
- 能更好地理解上下文,处理多轮对话中的语义关联。
- 在生成对话回复时,能够提供更加自然和连贯的回应。
-
如果监督任务是单轮文本生成或非对话生成任务:
- 示例:文本摘要、机器翻译、文本分类、问答系统(非对话式)等。
- 建议:选择 Base GPT 模型 作为基座模型
- 原因:
- Base 模型未经过对话数据的特化训练,保持了模型的通用性
- 在单轮文本生成和理解任务上表现出色,能够生成更加准确和贴合任务需求的结果。
- 避免了对话特征对非对话任务可能带来的干扰。
8. 预训练和微调哪个阶段注入知识?
简答:预训练和微调都注入知识,但注入的方式和范围不同。
- 预训练阶段注入的是通用的语言知识,使模型具备广泛的语言理解和生成能力。
- 微调阶段注入的是与特定任务相关的知识,使模型在特定任务上表现出色。
解析:
预训练:
-
目的:让模型从大量的未标注文本数据中学习语言的基本结构、语法、语义以及通用知识。
-
知识注入方式:
- 大规模数据学习:通过在海量的文本语料(如互联网数据、维基百科文章等)上进行训练,模型学习到了广泛的语言特征和常识性知识。
- 自监督学习:使用语言模型任务(如下一个词预测、掩码预测)让模型自我训练,学习词与词之间的关系、句法结构和上下文语义。
-
注入的知识类型:
- 通用语言知识:例如词汇含义、惯用表达、句法结构。
- 世界常识:由于训练数据的广泛性,模型也学习到了人类社会的常识性知识。
-
结果:预训练后的模型具备了对语言的基本理解和生成能力,能够在没有特定任务指导的情况下生成连贯的文本。
微调:
- 目的:让预训练模型适应特定的下游任务需求,提高在特定任务上的性能
- 知识注入方式:
- 监督学习:通过在标注了任务标签的数据集上训练,模型学习到了任务特定的模式和知识。
- 参数调整:在微调过程中,模型的参数会针对特定任务进行调整和优化。
- 注入的知识类型:
- 任务特定知识:例如对于情感分类任务,模型学习到哪些词语或表达与积极或消极情感相关。
- 领域专业知识:在特定领域的数据上微调,模型可以学习到该领域的专业知识和术语
- 结果:微调后的模型在特定任务上表现优异,能够准确完成任务,例如分类、问答、翻译等
总结:
- 预训练阶段:通过大规模未标注数据,模型学习到了通用的语言知识和世界常识,建立了语言理解的基础。
- 微调阶段:通过特定任务的标注数据,模型学习到了任务相关的知识,使其能够专注于具体任务并提升性能
两者的结合,使得模型既有广泛的语言理解能力,又能够在特定任务上发挥出色的表现。
20241216☀️
冷得离谱。
晚上养老跑了5K,结果膝痛加剧,甚至弯都弯不过来,跟骨折了一样,应该好好休息两天的。
算了,吃一堑长一智,真的是绷不住一点,周五不该这么用力的。
\bibliographystyle{ieeetr},一般用plain或者unsrt
ollama库,植入assistant角色,非常妙的一种prompt寄巧,以及用大写部分表示强调(强调输出推理步骤):
system + assistant + user
import streamlit as st
import ollama
import os
import json
import time
from pydantic import BaseModel
from typing import Literal
class ReasoningStep(BaseModel):
title: str
content: str
next_action: Literal["continue", "final_answer"]
class FinalAnswer(BaseModel):
title: str
content: str
def make_api_call(messages, max_tokens, is_final_answer=False):
for attempt in range(3):
try:
format_schema = ReasoningStep if not is_final_answer else FinalAnswer
response = ollama.chat(
model="llama3.1:latest",
messages=messages,
options={"temperature":0.2, "num_predict":max_tokens},
format=format_schema.model_json_schema(),
)
return format_schema.model_validate_json(response.message.content)
except Exception as e:
if attempt == 2:
if is_final_answer:
return FinalAnswer(title="Error", content=f"Failed to generate final answer after 3 attempts. Error: {str(e)}")
else:
return ReasoningStep(title="Error",
content=f"Failed to generate step after 3 attempts. Error: {str(e)}", next_action="final_answer")
time.sleep(1) # Wait for 1 second before retrying
def generate_response(prompt):
messages = [
{"role": "system", "content": """You are an expert AI assistant that explains your reasoning step by step. For each step, provide a title that describes what you're doing in that step, along with the content. Decide if you need another step or if you're ready to give the final answer. Respond in JSON format with 'title', 'content', and 'next_action' (either 'continue' or 'final_answer') keys. USE AS MANY REASONING STEPS AS POSSIBLE. AT LEAST 3. BE AWARE OF YOUR LIMITATIONS AS AN LLM AND WHAT YOU CAN AND CANNOT DO. IN YOUR REASONING, INCLUDE EXPLORATION OF ALTERNATIVE ANSWERS. CONSIDER YOU MAY BE WRONG, AND IF YOU ARE WRONG IN YOUR REASONING, WHERE IT WOULD BE. FULLY TEST ALL OTHER POSSIBILITIES. YOU CAN BE WRONG. WHEN YOU SAY YOU ARE RE-EXAMINING, ACTUALLY RE-EXAMINE, AND USE ANOTHER APPROACH TO DO SO. DO NOT JUST SAY YOU ARE RE-EXAMINING. USE AT LEAST 3 METHODS TO DERIVE THE ANSWER. USE BEST PRACTICES.
Example of a valid JSON response:
```json
{
"title": "Identifying Key Information",
"content": "To begin solving this problem, we need to carefully examine the given information and identify the crucial elements that will guide our solution process. This involves...",
"next_action": "continue"
}```
"""},
{"role": "user", "content": prompt},
{"role": "assistant", "content": "Thank you! I will now think step by step following my instructions, starting at the beginning after decomposing the problem."}
]
steps = []
step_count = 1
total_thinking_time = 0
while True:
start_time = time.time()
step_data = make_api_call(messages, 300)
end_time = time.time()
thinking_time = end_time - start_time
total_thinking_time += thinking_time
steps.append((f"Step {step_count}: {step_data.title}", step_data.content, thinking_time))
messages.append({"role": "assistant", "content": step_data.model_dump_json()})
if step_data.next_action == 'final_answer' or step_count > 25: # Maximum of 25 steps to prevent infinite thinking time. Can be adjusted.
break
step_count += 1
# Yield after each step for Streamlit to update
yield steps, None # We're not yielding the total time until the end
for msg in messages:
print(msg['role'], msg['content'][:20])
# Generate final answer
messages.append({"role": "user", "content": "Please provide the final answer based on your reasoning above."})
start_time = time.time()
final_data = make_api_call(messages, 200, is_final_answer=True)
end_time = time.time()
thinking_time = end_time - start_time
total_thinking_time += thinking_time
steps.append(("Final Answer", final_data.content, thinking_time))
yield steps, total_thinking_time
def main():
st.set_page_config(page_title="g1 prototype", page_icon="🧠", layout="wide")
st.title("g1: Using Llama-3.1 8b on local to create o1-like reasoning chains")
st.markdown("""
This is an early prototype of using prompting to create o1-like reasoning chains to improve output accuracy. It is not perfect and accuracy has yet to be formally evaluated. It is powered by Ollama.
Open source [repository here](https://github.com/bklieger-groq)
""")
# Text input for user query
user_query = st.text_input("Enter your query:", placeholder="e.g., How many 'R's are in the word strawberry?")
if user_query:
st.write("Generating response...")
# Create empty elements to hold the generated text and total time
response_container = st.empty()
time_container = st.empty()
# Generate and display the response
for steps, total_thinking_time in generate_response(user_query):
with response_container.container():
for i, (title, content, thinking_time) in enumerate(steps):
if title.startswith("Final Answer"):
st.markdown(f"### {title}")
st.markdown(content.replace('\n', '<br>'), unsafe_allow_html=True)
else:
with st.expander(title, expanded=True):
st.markdown(content.replace('\n', '<br>'), unsafe_allow_html=True)
# Only show total time when it's available at the end
if total_thinking_time is not None:
time_container.markdown(f"**Total thinking time: {total_thinking_time:.2f} seconds**")
if __name__ == "__main__":
main()
注意到上面的代码里:
Example of a valid JSON response:
```json
{
"title": "Identifying Key Information",
"content": "To begin solving this problem, we need to carefully examine the given information and identify the crucial elements that will guide our solution process. This involves...",
"next_action": "continue"
}```
"""},
{"role": "user", "content": prompt},
{"role": "assistant", "content": "Thank you! I will now think step by step following my instructions, starting at the beginning after decomposing the problem."}
]
latex伪代码:
\begin{algorithm}[hbt!]
\caption{Unite and Conquer Algorithm}\label{alg:three}
\textbf{Initialize} Choose a starting matrix $[I_1^0,\dots,I_{\ell}^0]$, let $k=0$.{ \ \ }\\
\textbf{For} $i=1$ to $\ell$ \textbf{do in parallel}{ \ \ }\\
\hspace*{0.2cm} Compute $S_i^k$ by applying $L_i$ to $P$ with initial condition $I_i^k$.\\
\hspace*{0.2cm} If $S_i^k$ is sufficiently accurate, STOP all $\ell$ process and return \\ \hspace*{0.2cm} $S_i^k$ as the solution of $P$.\\
\hspace*{0.3cm}\textbf{Share} $S_i^k$ information with all other processes $j$ \\ \hspace*{0.2cm} ($j=1,\dots,\ell$ and $j\neq i$).{ \ \ }\\
\textbf{Update and Restart} $[I_1^{k+1},\dots,I_l^{k+1}]$=$f(S_1^k,\dots,S_l^k)$ and increment $k$.
\end{algorithm}
\begin{algorithm}[H]
\caption{Boosting algorithm}\label{alg:two}
\textbf{Input:} Dataset $D$, $N$ weak learner ($L_1, \cdots, L_N$), a threshold precision $\theta$.\\
\textbf{Output:} Prediction $y^*$ for instance $x$, optimal learner $L_{opt}$.
Initialize instance weights $w$ to uniform values.
$L_{opt} \gets$ NULL, $maxAccuracy \gets 0$.
\For{$i \gets 1$ to $N$}{
\State{Train weak learner $L_i$ on $D$ with weights $w$.}
\State{Compute accuracy of $L_i$ on $D$.}
\If{accuracy of $L_i > maxAccuracy$} \textbf{then}
\hspace{1cm}$L_{opt} \gets L_i$, $maxAccuracy \gets$ accuracy of $L_i$.
\hspace{1cm}\textbf{if} ($maxAccuracy > \theta$) \ \textbf{then} {STOP.}}
\State{Update weights $w$ based on misclassified instances by $L_i$.}
\EndFor
Compute the final prediction $y^*$ for instance $x$ as:
$$y^* = \underset{y_i \in Y}{\arg\max} \sum_{i=1}^N L_i(x)$$
\textbf{Return} $y^*$ and $L_{opt}$.
\end{algorithm}
20241217~20241218☀️
昨天的冬日有多暖和,今天的西北风就有多刺骨。
总算是把难产儿终于投出去了。
但左膝还是没好,以前疼也是髌骨疼,这次有点像是半月板,是首马全程后跟跑落下的根,到今天还是跑不起来,
基于开源 LLM 实现 O1-like step by step 慢思考(slow thinking),ollama,streamlit
参考资料:
- https://github.com/bklieger-groq/g1(开源项目)
- 2 classical query(容易犯错的问题)
- Which is larger, 0.9 or 0.11?(这个gpt4o只有30%的准确率,但是用下面的prompt寄巧能达到70%)
- How many Rs are in strawberry?
2.1 ollama(Structured outputs)
- 下载最新版 ollama,然后
pip install -U ollama- https://ollama.com/blog/structured-outputs
- 资源释放:
- 还包括
ollama run llama3.1对话结束之后输入/bye还是不会自动资源释放; curl http://localhost:11434/api/generate -d '{"model": "qwen2.5", "keep_alive": 0}'
- 还包括
2.2 dynamic CoT(o1-like CoT)
"""You are an expert AI assistant that explains your reasoning step by step. For each step, provide a title that describes what you're doing in that step, along with the content. Decide if you need another step or if you're ready to give the final answer. Respond in JSON format with 'title', 'content', and 'next_action' (either 'continue' or 'final_answer') keys. USE AS MANY REASONING STEPS AS POSSIBLE. AT LEAST 3. BE AWARE OF YOUR LIMITATIONS AS AN LLM AND WHAT YOU CAN AND CANNOT DO. IN YOUR REASONING, INCLUDE EXPLORATION OF ALTERNATIVE ANSWERS. CONSIDER YOU MAY BE WRONG, AND IF YOU ARE WRONG IN YOUR REASONING, WHERE IT WOULD BE. FULLY TEST ALL OTHER POSSIBILITIES. YOU CAN BE WRONG. WHEN YOU SAY YOU ARE RE-EXAMINING, ACTUALLY RE-EXAMINE, AND USE ANOTHER APPROACH TO DO SO. DO NOT JUST SAY YOU ARE RE-EXAMINING. USE AT LEAST 3 METHODS TO DERIVE THE ANSWER. USE BEST PRACTICES.
Example of a valid JSON response:
```json
{
"title": "Identifying Key Information",
"content": "To begin solving this problem, we need to carefully examine the given information and identify the crucial elements that will guide our solution process. This involves...",
"next_action": "continue"
}```
"""
- messages 是对话式的
- system
- user (query)
- assistant (植入的)
- assistant (step by step)
- assistant (step by step)
- …
- 不断地追加进 messages,实现 dynamic 的 reasoning process
2.3 streamlit run
- 命令行执行如下命令:
streamlit run struct_llama_reasoning_app.py
llama_reasoning_app.py
import streamlit as st
import ollama
import os
import json
import time
def make_api_call(messages, max_tokens, is_final_answer=False):
for attempt in range(3):
try:
response = ollama.chat(
model="llama3.1:latest",
messages=messages,
options={"temperature":0.2, "num_predict":max_tokens},
format='json',
)
return json.loads(response['message']['content'])
except Exception as e:
if attempt == 2:
if is_final_answer:
return {"title": "Error", "content": f"Failed to generate final answer after 3 attempts. Error: {str(e)}"}
else:
return {"title": "Error", "content": f"Failed to generate step after 3 attempts. Error: {str(e)}", "next_action": "final_answer"}
time.sleep(1) # Wait for 1 second before retrying
def generate_response(prompt):
messages = [
{"role": "system", "content": """You are an expert AI assistant that explains your reasoning step by step. For each step, provide a title that describes what you're doing in that step, along with the content. Decide if you need another step or if you're ready to give the final answer. Respond in JSON format with 'title', 'content', and 'next_action' (either 'continue' or 'final_answer') keys. USE AS MANY REASONING STEPS AS POSSIBLE. AT LEAST 3. BE AWARE OF YOUR LIMITATIONS AS AN LLM AND WHAT YOU CAN AND CANNOT DO. IN YOUR REASONING, INCLUDE EXPLORATION OF ALTERNATIVE ANSWERS. CONSIDER YOU MAY BE WRONG, AND IF YOU ARE WRONG IN YOUR REASONING, WHERE IT WOULD BE. FULLY TEST ALL OTHER POSSIBILITIES. YOU CAN BE WRONG. WHEN YOU SAY YOU ARE RE-EXAMINING, ACTUALLY RE-EXAMINE, AND USE ANOTHER APPROACH TO DO SO. DO NOT JUST SAY YOU ARE RE-EXAMINING. USE AT LEAST 3 METHODS TO DERIVE THE ANSWER. USE BEST PRACTICES.
Example of a valid JSON response:
```json
{
"title": "Identifying Key Information",
"content": "To begin solving this problem, we need to carefully examine the given information and identify the crucial elements that will guide our solution process. This involves...",
"next_action": "continue"
}```
"""},
{"role": "user", "content": prompt},
{"role": "assistant", "content": "Thank you! I will now think step by step following my instructions, starting at the beginning after decomposing the problem."}
]
steps = []
step_count = 1
total_thinking_time = 0
while True:
start_time = time.time()
step_data = make_api_call(messages, 300)
end_time = time.time()
thinking_time = end_time - start_time
total_thinking_time += thinking_time
steps.append((f"Step {step_count}: {step_data['title']}", step_data['content'], thinking_time))
messages.append({"role": "assistant", "content": json.dumps(step_data)})
if step_data['next_action'] == 'final_answer' or step_count > 25: # Maximum of 25 steps to prevent infinite thinking time. Can be adjusted.
break
step_count += 1
# Yield after each step for Streamlit to update
yield steps, None # We're not yielding the total time until the end
# Generate final answer
messages.append({"role": "user", "content": "Please provide the final answer based on your reasoning above."})
start_time = time.time()
final_data = make_api_call(messages, 200, is_final_answer=True)
end_time = time.time()
thinking_time = end_time - start_time
total_thinking_time += thinking_time
steps.append(("Final Answer", final_data['content'], thinking_time))
yield steps, total_thinking_time
def main():
st.set_page_config(page_title="g1 prototype", page_icon="🧠", layout="wide")
st.title("g1: Using Llama-3.1 8b on local to create o1-like reasoning chains")
st.markdown("""
This is an early prototype of using prompting to create o1-like reasoning chains to improve output accuracy. It is not perfect and accuracy has yet to be formally evaluated. It is powered by Ollama.
Open source [repository here](https://github.com/bklieger-groq)
""")
# Text input for user query
user_query = st.text_input("Enter your query:", placeholder="e.g., How many 'R's are in the word strawberry?")
if user_query:
st.write("Generating response...")
# Create empty elements to hold the generated text and total time
response_container = st.empty()
time_container = st.empty()
# Generate and display the response
for steps, total_thinking_time in generate_response(user_query):
with response_container.container():
for i, (title, content, thinking_time) in enumerate(steps):
if title.startswith("Final Answer"):
st.markdown(f"### {title}")
st.markdown(content.replace('\n', '<br>'), unsafe_allow_html=True)
else:
with st.expander(title, expanded=True):
st.markdown(content.replace('\n', '<br>'), unsafe_allow_html=True)
# Only show total time when it's available at the end
if total_thinking_time is not None:
time_container.markdown(f"**Total thinking time: {total_thinking_time:.2f} seconds**")
if __name__ == "__main__":
main()
20241219☁️
试着倒跑,发现倒跑不疼,因为主要小腿发力,有点像跳绳,这也是眼下的权宜之计。20分钟2K出头一点,将近十分配,但感觉还挺快,以前看倒跑快的能跑到4开头的配速,事实上能跑到7分配以内就已经是非常非常快了。
晚上跟wyl把最后的准备工作弄完,这次wyl确实下血本了,最后一次帮他搞,老头子也不容易确实。20-22号三天,管吃管住,差不多得了,反正最近也得养伤。
PS:很克制地减餐,但还是超想吃东西,估计又要养膘起来。其实膝盖真很久没疼过,周一晚上真的是弯都弯不过来,骑车都骑不了。
NIPS24一篇关于量化算法的工作,很有意思,如果它是真的,那是极好的事情,因为感觉主流的Jittor还是不太稳定,没有宣称的那么强,本质上是用磁盘空间换内存空间,时间换空间,而且经常量化失败。
- DuQuant通过学习旋转和置换变换矩阵,在Activation矩阵内部将outliers转移到其他通道,最终得到平滑的激活矩阵,从而大幅降低了量化难度。实验显示,使用DuQuant方法,在4位权重和激活量化的设置下,模型达到了SOTA。同时,DuQuant的训练非常快速,可以在50s内完成7B模型的量化过程,即插即用。
项目主页:https://duquant.github.io/
论文:https://arxiv.org/abs/2406.01721
代码:https://github.com/Hsu1023/DuQuant
多轮对话任务如何微调模型?(以实际项目来说明具体的一个RAG流程)
在多轮对话任务中,微调模型的目标是使模型能够理解和生成连贯的多轮对话回复,具备上下文理解和一致性回复的能力。
下面详细解释如何在多轮对话任务中微调模型,包括每个步骤的目的和方法。
1. 数据准备
-
目标:收集或创建适用于多轮对话任务的数据集。
-
方法:
- 收集现有数据集:使用公开的多轮对话数据集,如Persona-Chat、DailyDialog等。这些数据集包含大量的人类对话,涵盖各种话题和情境。
- 创建自定义数据集:如果有特定的领域或任务需求,可能需要自行收集或生成对话数据。
- 数据清洗和预处理:确保数据质量,去除噪声、重复或不相关的内容。
-
注意:
- 上下文信息:确保每条对话包含足够的上下文,多轮对话的连续性对模型的训练至关重要
- 数据多样性:包含不同的话题、情感和语言风格,有助于模型学习更丰富的表达方式
2. 构建输入输出格式
- 目标:将原始对话数据转换为适合模型训练的格式。
- 方法:
- 输入格式:将多轮对话的历史(上下文)拼接成一个输入序列。
- 示例:
[用户] 你好! [机器人] 你好,请问有什么可以帮到您的吗? [用户] 我想预定一张去北京的火车票。 - 输出格式:模型需要生成的下一轮回复(y标签,即标注),即问题的答案
- 使用特殊标记,在不同的说话者之间添加特殊标记(如[用户][机器人]这样的)有助于模型区分不同角色,提高对话连贯性
- 输入长度限制:模型的最大输入长度有限,需要合理截断或摘要过长的对话历史
3. 模型选择
- 目标:选择适合多轮对话任务的预训练模型。
- 常用模型:
- DialoGPT:微软发布的对话生成模型,基于GPT-2,专为对话生成设计,适合多轮对话任务
- OLLAMA:通用的语言生成模型,具备强大的文本生成能力。
- BERT:主要用于理解任务(如分类、问答),不适合直接用于生成对话回复,但可用于理解型对话任务
- 其他:Qwen,ChatGLM,Pangu等
- 考虑因素:
- 任务类型:生成型任务选择生成模型(如GPT系列),理解型任务可考虑BERT等
- 模型大小:朴根据可用的计算资源和任务需求,选择合适的模型规模。
- 预训练数据:选择已经在对话数据上预训练的模型有助于提升初始性能。
4. 微调模型
-
初始化模型参数:
- 加载预训练模型:从预训练模型中加载参数,作为微调的起点。
-
定义损失函数:
- 生成任务:通常使用交叉熵损失函数,计算模型生成的回复与真实回复之间的差异。
- 特殊任务:根据任务需求,可能需要自定义损失函数,如引入情感倾向、特定词汇等。
-
进行反向传播和参数更新:
- 前向传播:将输入数据传入模型,得到模型输出。
- 计算损失:根据模型输出和真实标签(或目标回复),计算损失值。
- 反向传播:计算损失对模型参数的梯度。
-
重复训练步骤:
- 多轮迭代:遍历整个训练数据集多个epoch,不断更新模型参数
- 验证:在验证集上评估模型性能,防止过拟合。
- 注意:
- 学习率设定:微调时通常采用较小的学习率,防止模型参数发生过大变化,导致预训练知识遗失
- 梯度剪裁:防止梯度爆炸,保持训练的稳定性
5. 超参数调优
-
可调超参数:lr(影响参数更新速度),batchsize(英雄模型训练速度和泛化性能),epoches(过多可能过拟合,反之欠拟合),权重衰减(wd,用于正则化的参数,防止过拟合)
-
方法:gridsearch,random search,Bayesian Optimization(利用贝叶斯理论智能地探索参数空间)
-
评估:
- 验证集表现:根据验证集的损失或评价指标,选择最佳的超参数组合。
- 早停(Early Stopping):当验证集性能不再提升时,提前停止训练。
6. 评估和测试
-
目标:客观评价模型在多轮对话任务上的性能,确保模型的有效性和可靠性
-
评估指标:
- 自动评估:
- BLEU,ROUGE:统计匹配程度
- Perplexity(困惑度,PPL),衡量模型对测试集地拟合程度
- Distinct-N:评估生成回复的多样性,计算生成文本中不同n-gram的比例。
- 人工评估:
- 流畅性:回复是否语法正确、表达流畅,
- 相关性:回复与上下文是否相关。
- 连贯性:在多轮对话中,回复是否前后连贯,
- 信息性:回复中是否包含有用的信息。
- 自动评估:
-
测试集评估:使用未参与训练和验证的测试集,评估模型的泛化能力和实际表现,
-
错误分析:
- 类别分析:识别模型在哪些类型的对话中表现较差,如涉及特定话题、情感等
- 案例分析:深入分析错误案例,理解模型的不足之处,指导后续改进
7. 特定技巧的应用
-
使用对话策略进行训练:
- 目标:让模型学习合理的对话行为,提高对话的有效性和用户满意度。
- 方法:
- 策略建模:定义一系列对话策略,让模型学习何时提问、何时提供信息、如何引导对话等。
- 强化学习:使用奖励信号,训练模型在对话中采取最优策略。
-
数据增强:
- 目标:扩大训练数据的规模和多样性,提升模型的泛化能力。
- 方法:
- 同义替换:用同义词或短语替换原有的词汇。
- 随机插入或删除:在句子中随机插入或删除词语,生成新的对话实例。
- 翻译回译:将原句翻译成另一个语言,再翻译回来,产生语义相近的句子
-
情感和个性化建模:
- 目标:使模型的回复具有特定的情感倾向或人设,提升用户体验。
- 方法:
- 情感标签:在训练数据中标注情感,指导模型生成带有特定情感的回复。
- 人格特征:为模型设定特定的性格特征,在生成回复时体现出来
总结:
- 数据是基础:高质量、多样化的多轮对话数据集是成功微调模型的关键,
- 模型选择与调整:根据任务需求选择合适的预训练模型,并通过微调使其适应特定的对话任务。
- 训练过程:细心设计训练流程,注意超参数的设置和模型的稳定性。
- 评估与改进:持续评估模型性能,针对不足之处进行改进,如引入注意力机制、策略训练等
- 创新应用:结合任务特点,应用特殊技巧(如情感建模、数据增强)提升模型的实际效果。
20241220~20241222(完篇)
Day 1
趣闻两则:
-
注册来了一个XJU的,他是做cv的area mapping,注册时支支吾吾了半天,说这块被LLM压榨得很厉害,这几年顶会都看不到几篇做这个方向的,巴拉巴拉讲了一堆。我表示大家都是过来人,可以理解。最后,图穷匕见,说自己能不能明天线上报告,羞于跟公开展示自己的academic rubbish。我说可以,但是一定要报告,不陈述就撤稿,你自己看着办,emmm。
-
这两年,会议论文大致可以分为两类,一类是看得懂的水文,另一类是看不懂的水文。反正都是水就对了。
-
下午芬兰佬做的tutorial speech,基于RDF的QA,其实就是知识图谱问答,这也是老老老老老东西了,甚至里面用的还是句法结构分析的方法,泪目了。
-
-
wyl让王京负责餐饮和茶歇,王京看晚餐菜单上的菜摆不满桌子,瞒着wyl自己去对面熟食店买了点熟食,送过去让后厨摆盘。我还以为是赠送的几例凉菜(花生胡萝卜芹菜、烤麸、麻辣猪耳),我说你脸皮可真厚,人家居然能同意给你摆,组里就需要你这样的人才,属实是居家好男人了。
另外,膝盖好像康复,大概,似乎是这样的。
Day 2
早七晚九,一日牢,累死。不上班适应不了这种强度。不过下午复旦Henghui Ding作的关于pixel-level scene understanding in wild讲得太好了,不愧是中了多篇cvpr和nips的佬,姓丁的都挺牛逼,不管是按姓氏还是笔画都排得挺靠前。也是才知道现在cv方向关于in wild这块的研究居然已经独成一派了,就专门研究这种场景的识别、分类、以及各种编辑的操作。我记得本科毕业设计的时候,wyl跟上大那边也是做的一个野生动物识别的东西。
晚上welcome dinner,王京提议,今天冬至,搞点水饺?wyl赞成,问了一下,说只剩两例水饺了,一例二三十个,48块,wyl迟疑的态度让我们看出了他嫌贵了。叫王京去点外卖,今晚普遍饺子馄饨都比平时贵了10块钱左右,划下来比酒店的还贵。(虽然最后还是拿了酒店的,不好吃,去年冬至饺子是真炫到饱,吧台上一堆没人吃)。
PS:甜品蛋糕各种炫,指定肥一圈。到今天月跑量都没到100K,落魄了。晚上回来勉为其难去摇了会儿。
Day 3
昨天好几个鸽子都重新安排到今天的SESSION了。下午连着三小时,连TEA BREAK都没有,坐牢。
亦童和王京都准备润了,可是我还润不了,不知道今年又得拖到啥时候才回家。
PS:膝伤似乎没有想象那么乐观,快十天了,还是不太能跑,2K就已经比较疼了,目前多以倒跑形式在维持。
字数溢出,这篇应该是不够写到跨年了,草草收个笔呗。
END
20241223(后记)
补个后记,明天亦童回新疆,今晚趁组里人还在一起聚了一下,除了张甜,cgy和zfl,其他还没毕业的6个人都来了。
28号正式建AI学院,目前还不知道谁来担任院长,虽然事都是wyl在忙,但估计是轮不到老头子,不过混个副院退休,也算是个了结。
学院最近十年的变迁很难讲得明白,从gdd在2014年加入,到去年正式退出,几乎是目睹了一切,其中的利益纠纷太多,好好的信管被瓜分为三,可能是好事,也可能是坏事。有新鲜血液进来,重新划一下蛋糕似乎也没什么不好的。
在炎韩炫肉,今年新招的研一td看似稚嫩,其实已经工作了4年,比我还大1岁,确实没看出来。总之,最近是真的摄入远大于消耗了,老寒腿似乎没那么快能好,但晚上还是很慢很慢地跑了2K,本来3圈已经感觉很疼,但是看到一个跑得很好的小伙子,一问是大二的学生,还是本院的,我很高兴,膝盖的疼痛似乎就消退了,陪他跑了会儿,但很快还是疼得不行,还是算了。
怎么说呢,亦童确实是个有野心的人,可惜时势造英雄。或许这是黎明之前,也可能是长夜未央。
真·完篇
年底还是写一点吧,2024最后一周是在伤痛困扰中度过,也有人是在肺炎中度过。13号那晚一时起兴,竟然伤了这么久都没好。
不过本来事情也很赶,28号新学院挂牌,把wyl破事摆平一件,而我也终于可以安心赶下个月ijcai的ddl,今年也是难得wyl在学期结束之后还要频繁开会,亦童那边带来的消息是接下来应该是马不停蹄的连环本,老头子也是push上自己了。
这么多天没有写,一个是感觉并不是很好的开篇,总觉得上一篇还没有写完。但字数限制又写不了太多,我也懒得每天来这里啰嗦上几句。
当然应该看得出来,我自己的状态也不是很好,因为伤痛的缘故,每日的消耗大大减少,虽然没有太影响食欲,但确实是没敢再出去多放纵,尽量在减少每日的摄入。
死气很重,遇不到熟人,大家似乎都已经回家了,每天在实验室对着几个老面孔,循规蹈矩地做着事情,这种感觉真的很糟糕。
12月的跑量是125K,并不算太偷懒,即便是伤痛的下半月,每天都还是会练会儿的,再少也要跑个两三圈,然而也不会超过3K,想是每天确认膝盖的耐受,总是希望一天能比一天好些,可是直到今晚我还是没能跑到4K以上,很明显地能感觉到膝盖接近极限,还指望能搞个跨年跑,果真是想多了。
总之,早睡吧,新年新面貌,祝好。

















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









