






似乎每个人都在去年开始谈论CUDA :它是深度学习的支柱,是新型硬件难以竞争的原因,也是NVIDIA 护城河和飙升市值的核心。DeepSeek的出现,让我们获得了一个惊人的发现:它的突破是通过“绕过” CUDA,直接进入 PTX 层实现的……但这究竟意味着什么?似乎每个人都想打破这种锁定,但在制定计划之前,我们必须了解我们面临的是什么。
本文是 Modular “ AI 计算民主化”系列文章的第二部分。更多信息,请参阅:
第一部分:DeepSeek 对 AI 的影响
第二部分:“CUDA”到底是什么?(本文)
第 3 部分:CUDA 如何取得成功?
第 4 部分:CUDA 是现任者,但它好用吗?
第 5 部分:OpenCL 和 CUDA C++ 替代品怎么样?
第 6 部分:TVM、XLA 和 AI 编译器怎么样?
第 7 部分:Triton 和 Python eDSL 怎么样?
第 8 部分:MLIR 编译器基础设施怎么样?
第九部分:硬件公司为何难以构建人工智能软件?
第十部分:Modular 打破矩阵格局的策略
CUDA 在人工智能领域的主导地位毋庸置疑,但大多数人并不完全理解 CUDA 的真正含义。有人认为它是一种编程语言,有人称之为框架,还有许多人认为它只是“NVIDIA 用来加速 GPU 的东西”。这些说法都没错,许多才华横溢的人也试图解释这一点,但没有人能够完全理解“CUDA 平台”的含义。
CUDA 并非只是单一概念。它是一个庞大的分层平台,汇集了各种技术、软件库和底层优化,共同构成了一个庞大的并行计算生态系统。它包括:
一种低级并行编程模型,允许开发人员使用类似 C++ 的语法来利用 GPU 的原始功能。
一组复杂的库和框架——为 AI 等关键垂直用例提供支持的中间件(例如,PyTorch 和 TensorFlow 的 cuDNN)。
TensorRT-LLM 和 Triton 等一套高级解决方案,无需深厚的 CUDA 专业知识即可实现 AI 工作负载(例如 LLM 服务)。
…这只是皮毛而已。
在本文中,我们将分解CUDA 平台的关键层级,探索其历史演变,并解释它为何对当今的人工智能计算如此重要。这为我们系列的下一篇奠定了基础,我们将在下一篇中深入探讨CUDA 如此成功的原因。提示:这与其说是技术本身,不如说是市场激励机制。
让我们开始吧。🚀
CUDA 之路:从图形到通用计算
在 GPU 成为人工智能和科学计算的强大引擎之前,它们只是图形处理器——专门用于渲染图像的处理器。早期的 GPU将图像渲染硬编码到芯片中,这意味着渲染的每个步骤(变换、光照、光栅化)都是固定的。虽然这些芯片在图形处理方面非常高效,但它们缺乏灵活性——无法用于其他类型的计算。
2001年, NVIDIA推出了GeForce3 ,这是第一款配备可编程着色器的GPU ,一切都发生了改变。这在计算领域掀起了一场翻天覆地的变化:
🎨之前:固定功能 GPU 只能应用预定义的效果。
🖥️之后:开发人员可以编写自己的着色器程序,解锁可编程图形管道。
这一进步源于Shader Model 1.0 的出现,它允许开发人员编写小型的、由 GPU 执行的程序,用于顶点和像素处理。NVIDIA 看到了未来的发展方向: GPU 不仅可以提升图形性能,还可以成为可编程的并行计算引擎。
与此同时,研究人员很快就提出以下问题:
“🤔如果 GPU 可以运行图形小程序,我们可以将它们用于非图形任务吗?” 斯坦福大学的BrookGPU
项目是这方面的首批认真尝试之一。Brook 引入了一种编程模型,允许CPU 将计算任务转移给 GPU——这一关键理念为 CUDA
奠定了基础。
此举具有战略意义和变革意义。NVIDIA 不再将计算视为边缘实验,而是将其作为首要任务,将 CUDA 深深嵌入其硬件、软件和开发者生态系统中。
CUDA 并行编程模型
2006年,NVIDIA推出了CUDA(“统一计算设备架构”) ——第一个用于GPU的通用编程平台。CUDA编程模型由两部分组成:“CUDA编程语言”和“NVIDIA驱动程序”。
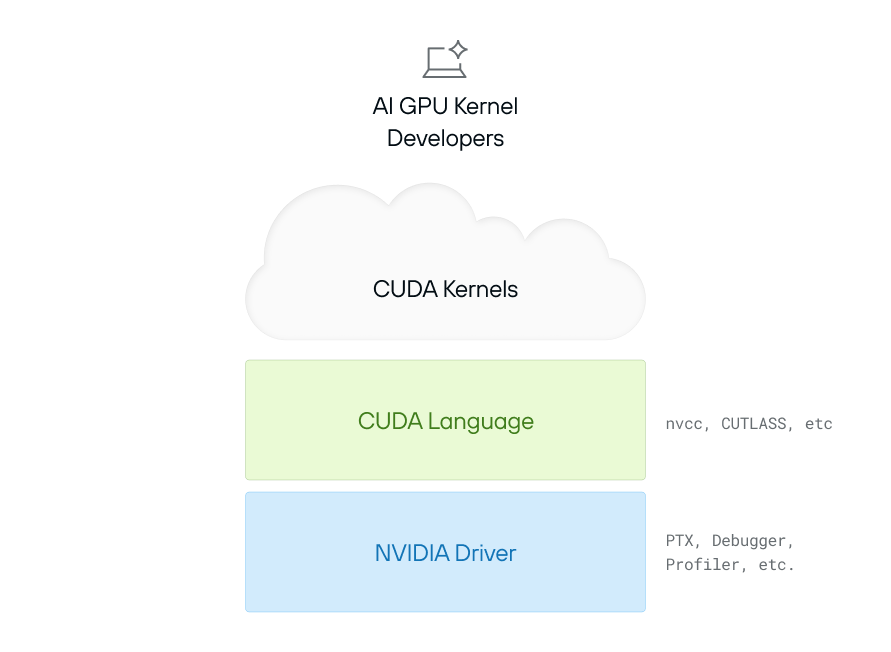
CUDA 语言源自 C++,并进行了增强,可以直接公开 GPU 的底层功能,例如“GPU 线程”和内存的概念。程序员可以使用该语言定义“CUDA 内核”,即在 GPU 上运行的独立计算。一个非常简单的示例如下:
__global__ void addVectors(float *a, float *b, float *c, int n) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < n) {
c[idx] = a[idx] + b[idx];
}
}
CUDA 内核允许程序员定义自定义计算,访问本地资源(例如内存),并将 GPU 用作高速并行计算单元。该语言被翻译(“编译”)为“PTX”,这是一种汇编语言,是 NVIDIA GPU 支持的最低级接口。
但是程序实际上是如何在 GPU 上执行代码的呢?这就是NVIDIA 驱动程序的作用所在。它充当CPU 和 GPU 之间的桥梁,处理内存分配、数据传输和内核执行。一个简单的例子是:
cudaMalloc(&d_A, size);
cudaMalloc(&d_B, size);
cudaMalloc(&d_C, size);
cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice);
int threadsPerBlock = 256;
// Compute the ceiling of N / threadsPerBlock
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
addVectors<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
cudaMemcpy(C, d_C, size, cudaMemcpyDeviceToHost);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
请注意,所有这些都是非常底层的——充满了繁琐的细节(例如指针和“魔法数字”)。如果出错,通常会通过难以理解的崩溃来告知。此外,CUDA 公开了许多特定于 NVIDIA 硬件的细节,例如“warp 中的线程数”(我们这里就不展开讨论了)。
尽管面临挑战,这些组件还是让整整一代硬核程序员得以利用 GPU 强大的计算能力来解决数值问题。例如, 2012 年的AlexNET开启了现代深度学习的先河。这得益于定制的 CUDA 内核,它能够执行卷积、激活、池化和归一化等 AI 操作,并充分利用了 GPU 提供的强大计算能力。
虽然大多数人听到“CUDA”时通常会想到的是 CUDA 语言和驱动程序,但这远非其全部,它只是其中的馅料。随着时间的推移,CUDA 平台不断发展壮大,包含的内容也越来越多,而原始首字母缩略词的含义也逐渐丧失,不再适合用来描述 CUDA。
高级 CUDA 库:让 GPU 编程更易于访问
CUDA编程模型打开了通用GPU计算的大门,功能强大,但也带来了两个挑战:
- CUDA很难使用,甚至更糟糕……
- CUDA 对性能可移植性没有帮助
大多数为 N 代 GPU 编写的内核在 N+1 代 GPU 上都能“继续工作”,但性能通常相当糟糕——远低于 N+1 代 GPU 所能达到的峰值水平,尽管 GPU 的核心在于性能。这使得 CUDA 成为专业工程师的强大工具,但对大多数开发人员来说,学习难度却很高。这也意味着,每次推出新一代 GPU(例如 Blackwell GPU)时,都需要进行大量重写。
随着 NVIDIA 的发展,它希望 GPU 能够帮助那些在各自问题领域拥有专业技能,但自身并非 GPU 专家的人们。NVIDIA 的解决方案是构建丰富而复杂的闭源高级库,抽象出底层 CUDA 细节。这些库包括:
- cuDNN(2014)——加速深度学习(例如卷积、激活函数)。
- cuBLAS——优化的线性代数例程。
- cuFFT ——GPU
上的快速傅里叶变换 (FFT)。 - …以及许多其他。
有了这些库,开发人员无需编写自定义 GPU 代码即可充分利用 CUDA 的强大功能,NVIDIA 则负责为每一代硬件重写这些代码。这对 NVIDIA 来说是一笔巨大的投资,但它确实奏效了。
cuDNN 库在这段历史中尤为重要——它为谷歌的TensorFlow(2015 年)和 Meta 的PyTorch(2016 年)铺平了道路,使深度学习框架得以腾飞。虽然之前也存在一些 AI 框架,但这些是第一批真正实现规模化的框架——现代 AI 框架如今拥有数千个CUDA 内核,每个内核的编写都非常困难。随着 AI 研究的蓬勃发展,NVIDIA 积极推动扩展这些库,以涵盖重要的新用例。
该图描绘了一个分层堆栈,顶部是 AI 模型开发人员,用一个带闪光的笔记本电脑图标表示。下方是一朵标有 PyTorch 生态系统的云,位于标有 PyTorch 的红色块上方。下方还有三层:一个绿色块表示 CUDA 库,另一个绿色块表示 CUDA 语言,底部是标有 NVIDIA 驱动程序的蓝色块。该结构突出显示了在 CUDA 框架内支持 PyTorch 所需的深度依赖链。

NVIDIA 对这些强大 GPU 库的投入,让全世界能够专注于构建像 PyTorch 这样的高级 AI 框架和像 HuggingFace 这样的开发者生态系统。他们的下一步是打造开箱即用的完整解决方案——完全无需了解 CUDA 编程模型。
完全垂直解决方案,以缓解人工智能和 GenAI 的快速增长
人工智能的繁荣远不止于研究实验室——如今,人工智能无处不在。从图像生成到聊天机器人,从科学发现到代码助手,生成式人工智能 (GenAI) 已在各行各业蓬勃发展,为该领域带来了大量新的应用和开发者。
与此同时,一波新的 AI 开发者涌现,他们的需求截然不同。早期,深度学习需要高度专业化的工程师,他们精通 CUDA、HPC 和底层 GPU 编程。现在,一类新的开发者——通常被称为AI 工程师——正在构建和部署 AI 模型,而无需接触底层 GPU 代码。
为了满足这一需求,NVIDIA 不仅提供库,现在还提供交钥匙解决方案,将所有底层细节抽象化。这些框架无需深厚的 CUDA 专业知识,而是允许 AI 开发者以最小的努力优化和部署模型。
- Triton Serving——一种用于 AI 模型的高性能服务系统,允许团队在多个 GPU 和 CPU 上高效地运行推理。
- TensorRT——一种深度学习推理优化器,可自动调整模型以在 NVIDIA 硬件上高效运行。
- TensorRT-LLM –一种更加专业的解决方案,专为大规模大型语言模型 (LLM) 推理而构建。
- …还有许多(许多)其他的东西。

这些工具完全保护了AI工程师免受CUDA低级复杂性的影响,使他们能够专注于AI模型和应用,而不是硬件细节。这些系统提供了显著的杠杆作用,实现了AI应用的横向扩展。
整个“CUDA 平台”
CUDA 通常被认为是一种编程模型、一组库,甚至仅仅是“NVIDIA GPU 上运行 AI 的东西”。但实际上,CUDA 远不止于此——它是一个统一的品牌、一个真正庞大的软件集合以及一个高度优化的生态系统,所有这些都与 NVIDIA 的硬件深度集成。因此,“CUDA”一词含义模糊——我们更喜欢使用“CUDA 平台”来澄清,我们所讨论的是在本质上更接近 Java 生态系统,甚至是操作系统的东西,而不仅仅是一种编程语言和运行时库。
该图展示了 CUDA 生态系统的分层堆栈。顶部是 AI GPU 内核开发者、AI 模型开发者和 AI 工程师的图标,以及 CUDA 内核和 PyTorch 生态系统的云。下方是 PyTorch、TensorRT-LLM、CUDA 库、CUDA 语言和基础 NVIDIA 驱动程序,突出显示了 CUDA 的复杂依赖关系。
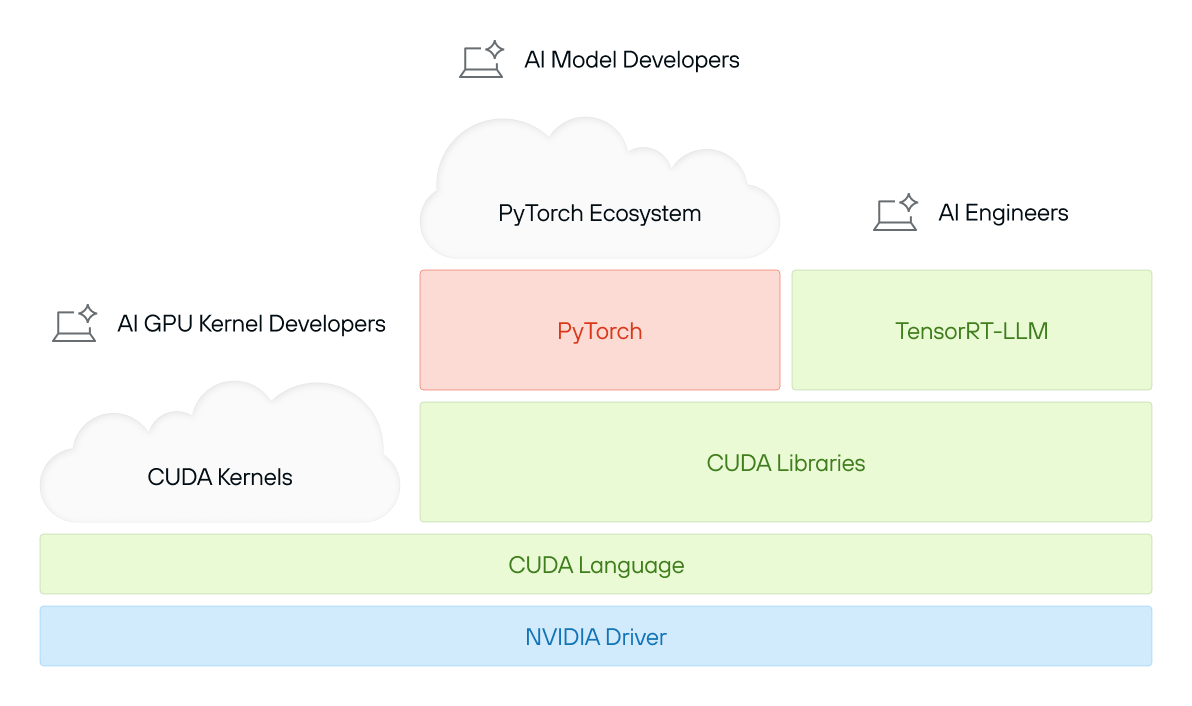
CUDA 平台的核心包括:
- 庞大的代码库——数十年优化的 GPU 软件,涵盖从矩阵运算到 AI 推理的所有内容。
- 庞大的工具和库生态系统——从用于深度学习的cuDNN到用于推理的 TensorRT,CUDA 涵盖了广泛的工作负载。
- 硬件调整性能——每个 CUDA 版本都针对NVIDIA 最新的GPU 架构进行深度优化,确保顶级效率。
- 专有且不透明——当开发人员与 CUDA 的库 API交互时,底层发生的许多事情都是闭源的,并且与NVIDIA 的生态系统紧密相关。 CUDA 是一套功能强大但范围广泛的技术——一个完整的软件平台,是现代 GPU计算的基础,甚至超越了人工智能。
既然我们已经了解了“CUDA”是什么,我们需要了解它是如何取得如此成功的。提示:CUDA 的成功并非源于性能,而在于战略、生态系统和发展势头。在下一篇文章中,我们将探讨是什么让 NVIDIA 的 CUDA 软件能够塑造并巩固现代 AI 时代。

















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









