






人类的耳朵是可以听到声音后对声音的源头进行定位的,就好比走在路上时你可以分辨出身后是否有疾驰而来的汽车,并且还能大致地判断和你之间的距离。
这种通过耳朵带来的空间听觉感称之为“双耳效应”:声音传递到两个耳朵存在时间差、能量差,大脑利用该两个差别对声源进行定位。
更具体的,
声源频率<1.5KHz时,声音先到达靠近声源一侧的耳朵,即时间差(interaural time difference,简称ITD);
声源频率>1.5KHz时,由于波长比人的头颅宽度短,导致声音在传播到较远侧耳朵时部分被头颅阻挡,所接收到的能量值低于另一侧耳朵,即声级差(interaural leveldifference,简称ILD)。
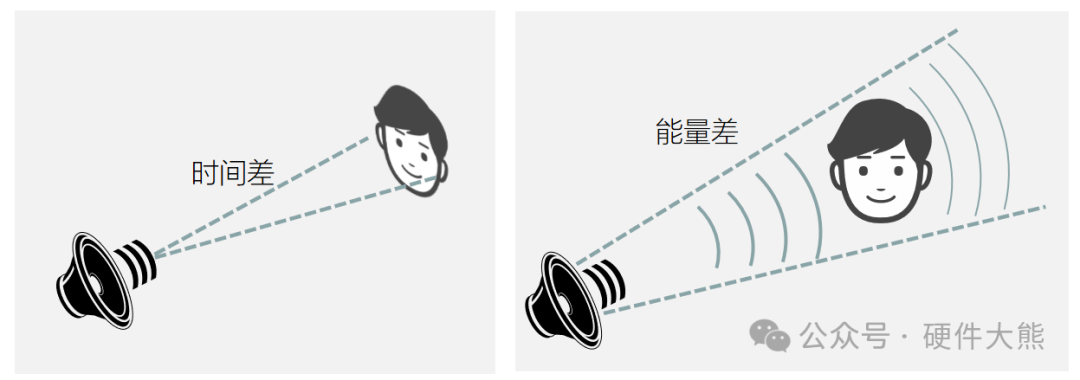
人类能够分辨的最短时间差为10us,最小的声级差为1dB。
时间到达差算法
这里要先有个基础理论,即:双曲线上的点到两个焦点的距离之差为常数。
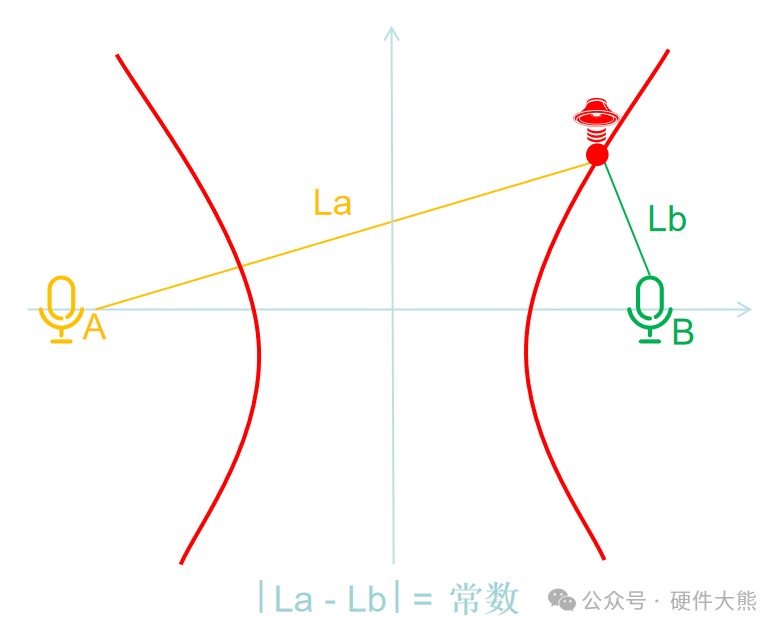
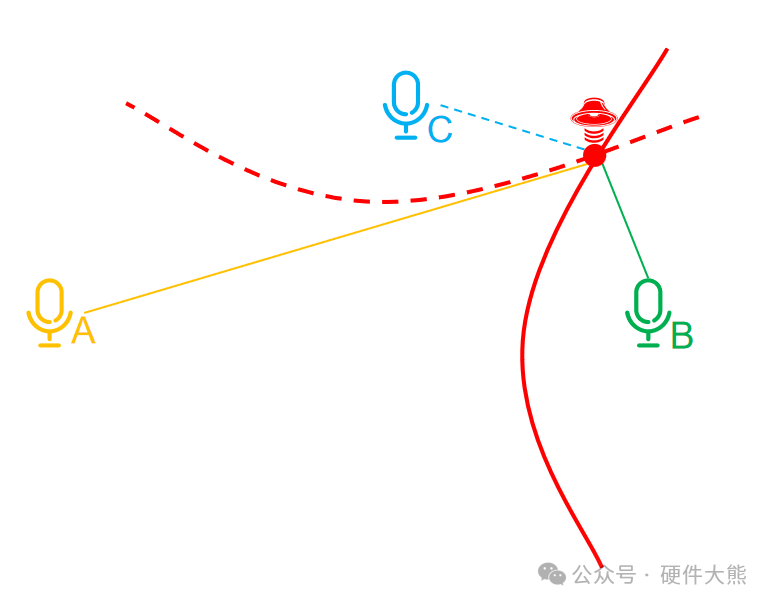
根据麦克风A、B的时间差,我们可以以A、B为焦点画出一条双曲线,
根据麦克风B、C的时间差,我们可以以B、C为焦点画出一条双曲线,
此时两条双曲线交汇的点即为声源位置。
波束形成算法
阵列麦克风采集到的信号,由于距离间隔不同,声音到达每个麦克风都会存在一定的时延t,因此将采集到的声波进行叠加时,声波会出现不同程度的衰减,但如果我们将每个麦克风采集到的声波进行时延τ处理,并逐渐将其时延至相位差为0时,其相加起来的功率可以达到最大值。此时可以通过τ反向推算,可以得出声源的位置。
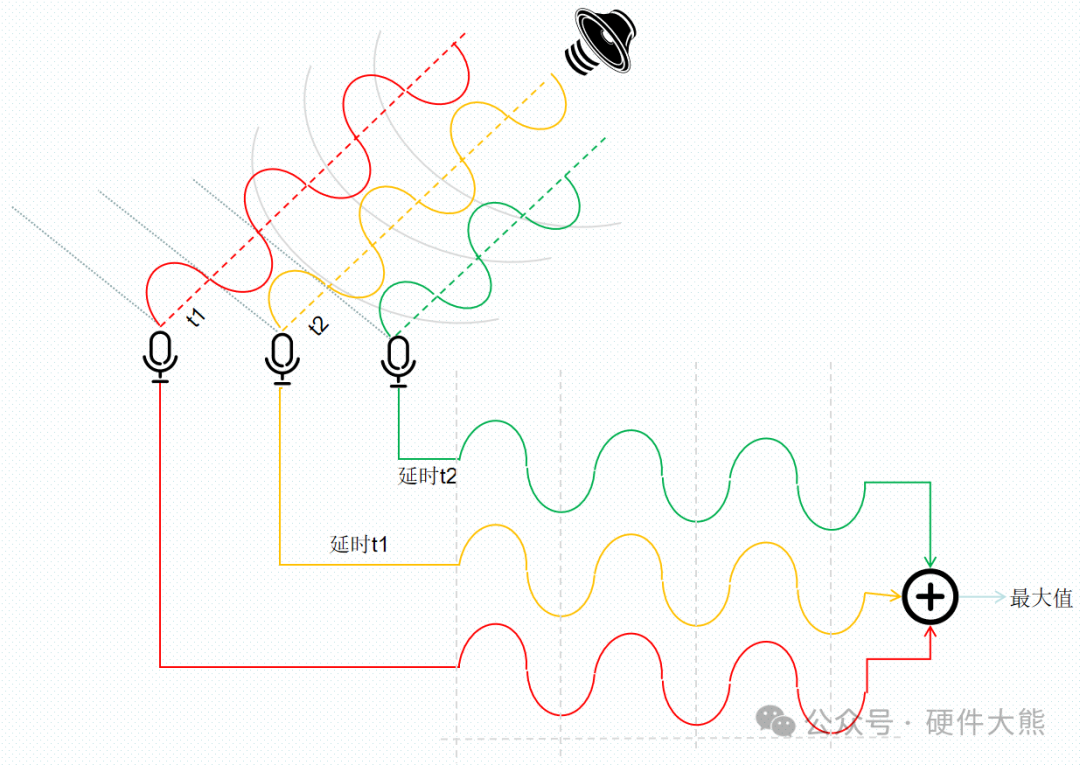
这个原理和我们经常听到的TWS耳机所宣传的Beamforming指向增强技术(利用两个麦克风采集到的语音进行相位差处理实现定向拾音)的底层原理是一致的。
除了以上两种算法,还有基于声压幅度比的定位算法、高分辨率频谱的定位算法,
基于声压幅度比的算法利用不同麦克风接收的来自于同一个声音的信号强度差异来定位声源的位置;
高分辨率频谱的定位算法利用麦克风接收信号相关矩阵的空间谱求解麦克风之间的相关矩阵来确定方向角进而确定声源位置。
由于篇幅有限,我们分为下一个篇章进行解析。
推荐阅读:


















 4380
4380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









