




 Apache Storm 是一个开源的实时计算系统,用于处理无限数据流。其核心组件包括Spout和Bolt,通过不同的分组策略如Shuffle、Fields、Global等实现数据流的定向。Storm具有高容错性和可扩展性,适用于实时分析、在线机器学习等场景。在集群中,Nimbus负责调度,Supervisor管理Worker进程,保证任务的执行。Storm的编程模型以Topology为基础,Spout作为数据源,Bolt执行处理逻辑。
Apache Storm 是一个开源的实时计算系统,用于处理无限数据流。其核心组件包括Spout和Bolt,通过不同的分组策略如Shuffle、Fields、Global等实现数据流的定向。Storm具有高容错性和可扩展性,适用于实时分析、在线机器学习等场景。在集群中,Nimbus负责调度,Supervisor管理Worker进程,保证任务的执行。Storm的编程模型以Topology为基础,Spout作为数据源,Bolt执行处理逻辑。
Strom 简介
Apache Storm(http://storm.apache.org)是由Twitter 开源的分布式实时计算系统,Storm 可以非常容易并且可靠的处理无线的数据流,对比Hadoop的批处理,Storm是一个实时的、分布式的、具备高容错的计算系统。
Storm的核心代码使用clojure书写,实用程序使用python开发,使用java开发拓扑。
Storm 的使用场景非常广泛,比如实时分析、在线机器学习、分布式RPC、ETL等。Storm非常高效,在一个多节点集群每秒可以轻松处理上百万条的消息。Storm还具有良好的可扩展性和容错性以及保证数据可以至少被处理一次等特性。
下图中水龙头和后面水管组成的拓补图就是一个Storm应用(Topology),其中的水龙头是Spout,用来源源不断地读取消息并发送出去,水管的每一个接口就是Bolt,通过Storm的分组策略转发消息流
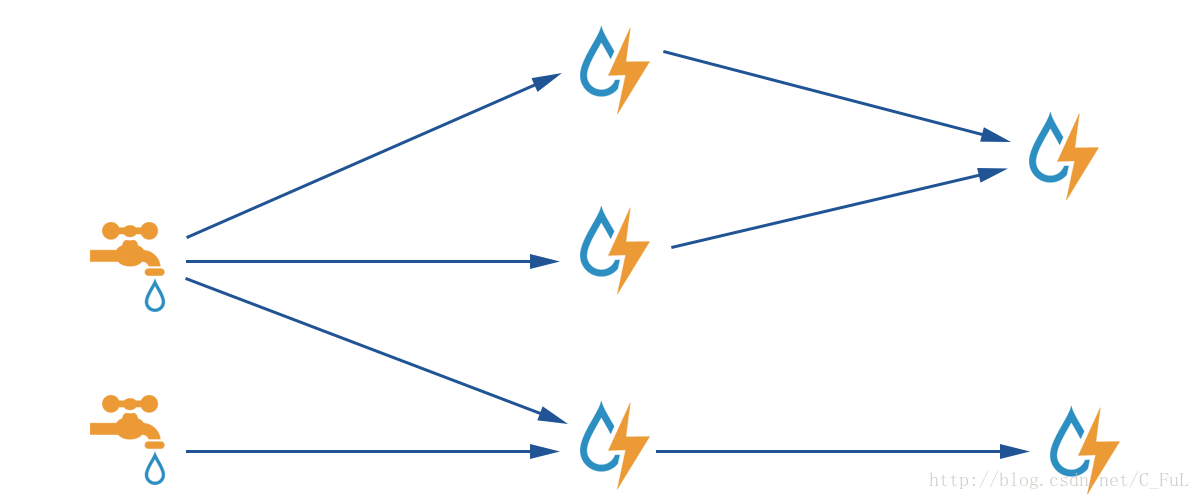
Storm 核心组件
Storm 的集群表面上看和Hadoop的非常像,但是在Hadoop上运行的是MapReduce的作业(job),而在Storm上运行的是是Topology,Storm和Hadoop一个非常关键的区别是Hadoop的MapReduce作业最终会结束,而Storm的Topology会一直运行(除非显示的杀掉它)
如果说批处理的Hadoop需要一桶一桶地搬走水,那么Storm 就好比自来水水管,只要预先接好水管,然后打开水龙头,水就源源不断地流出来了,即消息就会被实时地处理。
在Storm 集群中有两种节点:主节点(Master Node)Nimbus和工作节点(Worker Node)S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1815
1815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









