






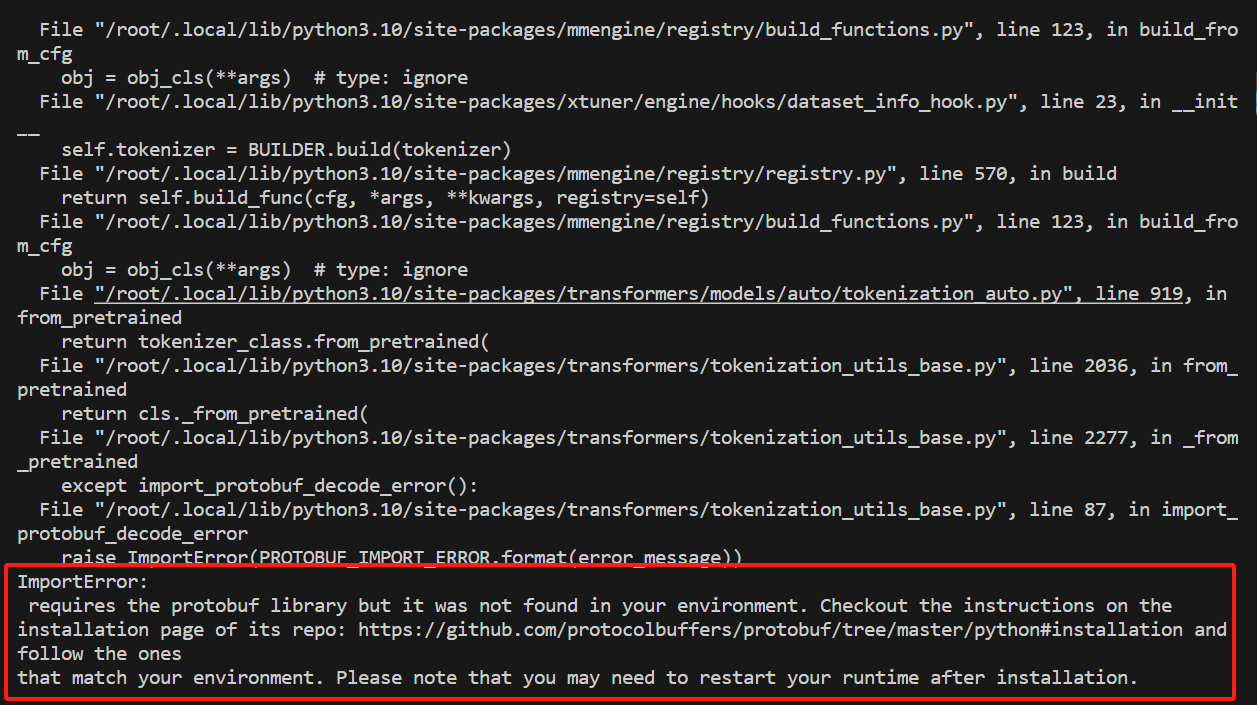
 问题核心在于 缺少 protobuf 库(
问题核心在于 缺少 protobuf 库(ImportError: InternLM2Converter requires the protobuf library)。以下是完整解决方案:
🔧 解决方案步骤
1. 安装 protobuf 编译器(protoc)
- Ubuntu/Debian:
sudo apt-get update sudo apt-get install protobuf-compiler libprotobuf-dev - CentOS:
sudo yum install protobuf-compiler protobuf-devel - 验证安装:
protoc --version # 应显示版本号(如 libprotoc 3.20.1)
2. 安装 Python 的 protobuf 包
pip install protobuf==5.27.2 # 与 InternLM 兼容的版本[3](@ref)直接安装 最新版本 pip install --upgrade protobuf
3. 检查环境变量(关键!)
- 确保 Python 能识别 protobuf 库:
预期输出:python -c "import google.protobuf; print(google.protobuf.__version__)"5.27.2(或其他版本号)。若报错,需检查 Python 环境是否匹配。
4. 重启运行时环境
- 若在 Jupyter/Notebook 中运行:重启内核。
- 若在终端运行:关闭并重新打开终端。
- 若在容器中:重启容器实例。
5. 验证修复
重新执行训练命令:
xtuner train /root/xtuner/internlm2_5_chat_7b_qlora_alpaca_e3_copy.py --deepspeed deepspeed_zero1若不再出现 ImportError 即修复成功。
⚠️ 常见问题排查
-
多 Python 环境冲突
若使用conda或virtualenv,确保 protobuf 安装在当前环境的 Python 中:which pip # 检查 pip 是否属于当前环境 pip list | grep protobuf # 确认已安装 -
版本不兼容
若仍报错,尝试升级 protobuf:pip install --upgrade protobuf -
系统级依赖缺失(仅 Linux)
安装编译依赖:sudo apt-get install autoconf automake libtool curl make g++ unzip
💡 问题原因分析
- 报错根源:InternLM2 的分词器(Tokenizer)依赖
protobuf解析模型配置,但环境中未安装或无法找到该库1,4。 - 配置注意点:在微调 InternLM2 时,
protobuf版本需与 transformers 库兼容(建议 ≥3.20.0)3,4。
如按上述步骤操作后仍失败,请提供完整的
pip list输出和环境信息(cat /etc/os-release),以便进一步排查。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









