







 朴素贝叶斯算法提供数据实例属于类别的概率值,避免了分类时的不确定性。文章介绍了如何通过多项式模型实现朴素贝叶斯,以过滤垃圾邮件为例,展示算法应用,并讨论了独立性假设对准确性的影响。
朴素贝叶斯算法提供数据实例属于类别的概率值,避免了分类时的不确定性。文章介绍了如何通过多项式模型实现朴素贝叶斯,以过滤垃圾邮件为例,展示算法应用,并讨论了独立性假设对准确性的影响。
之前博客提到的KNN算法以及决策树算法都是要求分类器给出“该数据实例属于哪一类”这类问题的明确答案,正因为如此,才出现了使用决策树分类时,有时无法判定某一测试实例属于哪一类别。使用朴素贝叶斯算法则可以避免这个问题,它给出了这个实例属于某一类别的概率值,然后通过比较概率值,可以找到该实例最有可能属于哪一类别。
该算法可以用如下形式表示:

直接求解概率值很困难,因此我们可以通过下列式子进行变化。
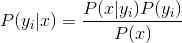
因为分母对于所有类别都是固定值,所以我们只要求能使得分子最大化的类别即可。又因为朴素贝叶斯假设各特征属性条件独立,所以有:

朴素贝叶斯分类器通常有两种实现方式:一种基于贝努利模型实现,一种基于多项式模型实现。贝努利实现方式也称“词集模型”,其不考虑词在文档中出现的次数,只考虑出不出现,因此在这个意义上相当于假设词是等权重的。而多项式模型也称“词袋模型”,它考虑词在文档中的出现次数。本文采用的是多项式模型。
这次的案例使用的是使用朴素贝叶斯过滤垃圾邮件。训练集如下所示:

第一个文件夹下放的是25篇正常的纯文本邮件,第二个文件夹放的是25篇纯文本垃圾邮件。
首先是邮件内容的封装。
package naivebayesian;
import java.util.List;
public class Email {
private List<String> wordList;
private int flag;
public int getFlag() {
return flag;
}
public void setFlag(int flag) {
this.flag = flag;
}
public List<String> getWordList() {
return wordList;
}
public void setWordList(List<String> wordList) {
this.wordList = wordList;
}
}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 718
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









