






简介
Beautiful Soup就是Python的一个HTML或XML的解析库,可以用它来方便地从网页中提取数据。Beautiful Soup在解析时实际上依赖解析器, 可以选择的解析器如下表所示:
常用前两种

基本用法
from bs4 import BeautifulSoup
#BeaufulSoup对象的初始化, 并指定html解析器是lxml
soup = BeautifulSoup(html, ‘lxml’)
#把要解析的字符串以标准的缩进格式输出
soup.prettify()
BeautifulSoup选择器
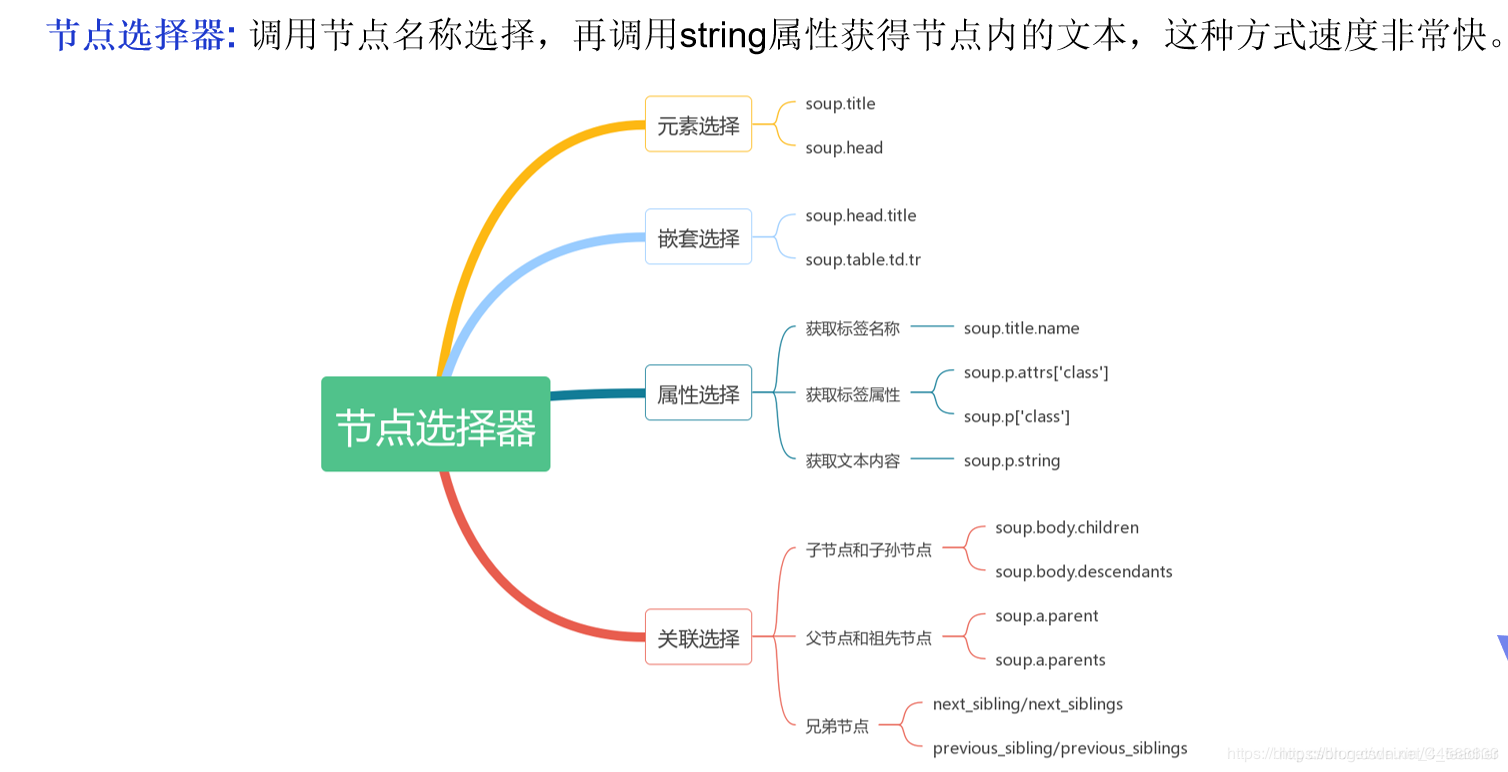
节点选择器
直接调用节点的名称就可以选择节点元素,再调用string属性就可以得到节点内的文本了,这种选择方式速度非常快。如果单个节点结构层次非常清晰,可以选用这种方式来解析。
text = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<table class="table table1" id="userinfo">
<tr>
<td>姓名</td>
<td>年龄</td>
</tr>
<tr>
<td>张三</td>
<td>10</td>
</tr>
<tr>
<td>李四</td>
<td>20</td>
</tr>
</table>
<div>
<img src="download_images" title="image" alt="image alt">
</div>
</body>
</html>
"""
from bs4 import BeautifulSoup
html = text
soup = BeautifulSoup(html,'lxml')
# string = soup.prettify()
# print(string)
# 节点选择器
# 1、元素选择:只返回html里面查询符和条件的第一个标签内容
# print(soup.title)
# print(soup.img)
# print(soup.td)
# 2、嵌套选择器
# print(soup.html.head.title)
# print(soup.body.table.td) # 也是只返回找到的第一个
# 3、属性选择
# 获取标签名称:当爬虫的过程中,标签对象赋值给一个变量传递函数时,想要获取变量对应的标签,name属性就很有用
# print(soup.img.name)
# print(soup.img.title)
# movieimg = soup.img
# print(movieimg.name)
# 获取标签属性
# print(soup.table.attrs) # 返回标签所有属性信息{'class': ['table'], 'id': 'userinfo'}
# print(soup.table.attrs['class']) # 获取class属性对应的值
# print(soup.table['class']) # 获取class属性对应的值
# 获取文本内容
# print(soup.title.string)
# print(soup.title.get_text())
# 关联选择 父节点和祖父节点
# first_tr_tags = soup.table.tr
# # print(first_tr_tags.parents)
# parents = first_tr_tags.parents
# for parent in parents:
# print('**************************')
# print(parent)
# 孙节点和子孙节点
# table_tag = soup.table
# for child in table_tag.children:
# if child:
# print('**************************************')
# print(child)
# 兄弟节点
tr_tag = soup.table.tr
print(tr_tag.next_siblings)
for bro in tr_tag.next_siblings:
print(bro)
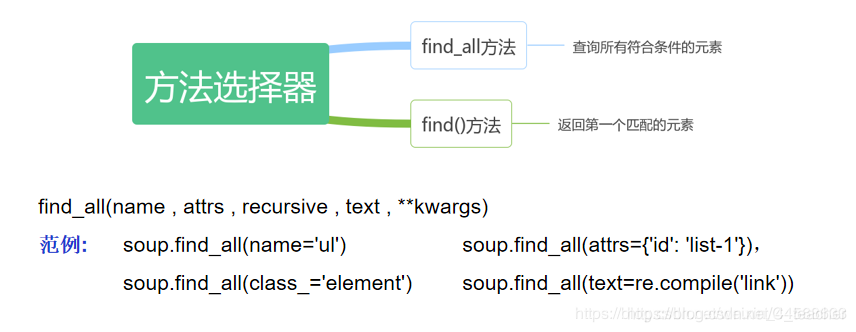
方法选择器
节点选择器速度非常快,但面对复杂的选择不够灵活。Beautiful Soup提供的查询方法,比如find_all()和find()等实现灵活查询。
- find_all方法,查询所有符合条件的元素。
- find_all(name , attrs , recursive , text , **kwargs)
- soup.find_all(name=‘ul’), soup.find_all(attrs={‘id’: ‘list-1’}), soup.find_all(class_=‘element’), soup.find_all(text=re.compile(‘link’))
- find()方法,返回第一个匹配的元素
"""
File:17_BS4方法选择器.py
Author:Tcyw
Date:2020-04-15
Connect:741047561@qq.com
Description:
"""
import re
from bs4 import BeautifulSoup
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<table class="table" id="userinfo">
<tr class="item-1">
<td>姓名</td>
<td>年龄</td>
</tr>
<tr class="item-2">
<td>张三</td>
<td>10</td>
</tr>
<tr class="item-3">
<td>李四</td>
<td>20</td>
</tr>
</table>
<div>
<img src="download_images" title="image" alt="image alt">
</div>
</body>
</html>
"""
soup = BeautifulSoup(html,'lxml')
# 友好的显示
# string = soup.prettify()
# print(string)
# 使用方法选择器灵活的查找标签元素
# 1、根据表签名进行查找
# print(soup.find_all('tr'))
# print('**************************************')
# print(soup.find('tr'))
# 2、根据表签名和属性信息进行查找
# print(soup.find_all('table',attrs={'class':'table','id':'userinfo'}))
# print(soup.find('table',attrs={'class':'table','id':'userinfo'}))
# print(soup.find('table',attrs={'class':'table','id':'userinfo'},recursive=False)) # 默认是递归查找,设置为False就是不递归
# print(soup.find_all('table',id='userinfo'))
# print(soup.find_all('table',class_='table'))
# *********规则可以和正则表达式结合
# print(soup.find_all('tr',class_=re.compile('item-\d+')))
# print(soup.find_all('tr',class_=re.compile('item-\d+'),limit=2))
print(soup.find_all('td',text=re.compile('\d{1,2}')))
CSS选择器
"""
File:18_BS4css选择器.py
Author:Tcyw
Date:2020-04-15
Connect:741047561@qq.com
Description:
"""
import re
from bs4 import BeautifulSoup
html = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<table class="table" id="userinfo">
<tr class="item-1">
<td>姓名</td>
<td>年龄</td>
</tr>
<tr class="item-2">
<td>张三</td>
<td>10</td>
</tr>
<tr class="item-3">
<td>李四</td>
<td>20</td>
</tr>
</table>
<div>
<img src="download_images" title="image" alt="image alt">
</div>
</body>
</html>
"""
soup = BeautifulSoup(html,'lxml')
# css选择器
print(soup.select('.item-3'))
#
print(soup.select('#userinfo'))
print(soup.select('table tr td'))
项目案例:基于requests和bs4的三国演义定向爬虫
项目介绍:
应用requests库和BeautifulSoup来采集三国演义名著每章节的内容
项目分析:
1、根据网址http://www.shicimingju.com/book/sanguoyanyi.html获取三国演义主页的章节信息.
2、分析章节信息的特点, 提取章节的详情页链接和章节的名称。
<div class=“book-mulu”><ul><li>,li的详情信息如下:
<li><a href="/book/sanguoyanyi/1.html">第一回·宴桃园豪杰三结义 斩黄巾英雄首立功</a></li>
3、根据章节的详情页链接访问章节内容 <div class=“chapter_content”>
4、提取到的章节内容包含特殊的标签, eg: <br/> ==> ‘\n’<p>, </p> => ‘’
5、将章节信息存储到文件中
"""
File:19_三国演义定向爬虫.py
Author:Tcyw
Date:2020-04-19
Connect:741047561@qq.com
Description:
根据网址http://www.shicimingju.com/book/sanguoyanyi.html获取三国演义主页的章节信息.
分析章节信息的特点, 提取章节的详情页链接和章节的名称。
<div class="book-mulu"><ul><li>,li的详情信息如下:
<li><a href="/book/sanguoyanyi/1.html">第一回·宴桃园豪杰三结义 斩黄巾英雄首立功</a></li>
根据章节的详情页链接访问章节内容 <div class="chapter_content">
提取到的章节内容包含特殊的标签, eg: <br/> ==> '\n' <p>, </p> => ''
将章节信息存储到文件中
"""
import csv
import json
import os
import re
import lxml
import requests
from colorama import Fore
from fake_useragent import UserAgent
from lxml import etree
from requests import HTTPError
from bs4 import BeautifulSoup
def download_page(url,params=None):
"""
根据url下载html页面
:param url:
:return:
"""
try:
ua = UserAgent()
headers = {'User-Agent':ua.random,
}
response = requests.get(url,params=params,headers=headers)
# print(response)
except HTTPError as e:
print(Fore.RED + '[-] 爬取网站%s失败:%s' %(url,str(e)))
else:
return response.text
def parse_html(html):
# 实例化Beautiful对象,并通过指定的解析器(4种)解析html字符串的内容
soup = BeautifulSoup(html,'lxml')
# 根据bs4的选择器获取章节的详情页链接和章节的名称
book = soup.find('div',class_="book-mulu") # 获取该书籍对象
chapters = book.find_all('li') # 获取该书籍的所有章节对应的li标签,返回的是列表
for chapter in chapters:
detail_url = chapter.a['href']
chapter_name = chapter.a.string
yield {
'detail_url': detail_url,
'chapter_name': chapter_name
}
def get_one_page():
base_url = 'http://www.shicimingju.com'
url = 'http://www.shicimingju.com/book/sanguoyanyi.html'
dirname = '三国演义'
if not os.path.exists(dirname):
os.mkdir(dirname)
print(Fore.GREEN + '创建书籍目录%s成功' %(dirname))
html = download_page(url)
items = parse_html(html)
for item in items:
# 访问详情页
detail_url = base_url + item['detail_url']
chapter_name = os.path.join(dirname,item['chapter_name'])
chapter_html = download_page(detail_url)
chapter_content = parse_detail_html(chapter_html)
with open(chapter_name,'w',encoding='utf-8') as f:
f.write(chapter_content)
print(Fore.RED + "写入文件%s成功" %(chapter_name))
# print(detail_url)
# print(item)
def parse_detail_html(html):
# 实例化Beautiful对象,并通过指定的解析器(4种)解析html字符串的内容
soup = BeautifulSoup(html, 'lxml')
# 根据章节的详情页链接访问章节内容 <div class="chapter_content">
# string属性只能拿出当前标签的文本信息,get_text方法返回当前标签和子孙标签的所有文本信息
chapter_content = soup.find('div',class_="chapter_content").get_text()
# 提取到的章节内容包含特殊的标签, eg: <br/> ==> '\n' <p>, </p> => ''
# re.sub(r'<br/>','\n',chapter_content)
# re.sub(r'<p>|</p>','',chapter_content)
return chapter_content
if __name__ == '__main__':
get_one_page()















 1459
1459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









