






观察网页
网页地址:https://www.gmw.cn/

目的:分析网页是静态网页还是动态网页,找到数据存放的真实网址。
步骤:
1、通过浏览器进入光明网,点击进入光明日报页面后右键点击“检查”
2、点击“Network”后按 Ctrl+r刷新页面
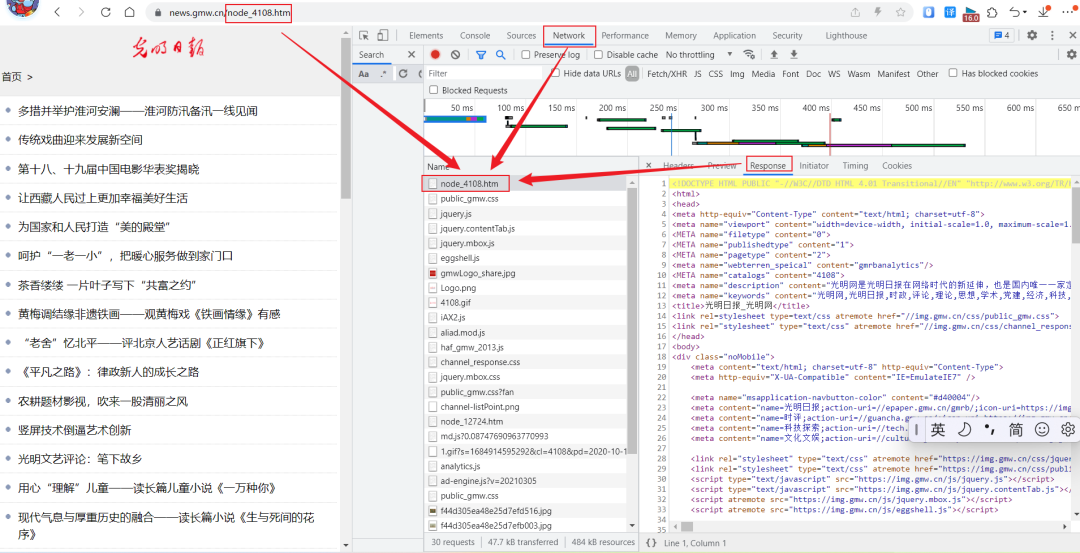
3、点击“Response”或者“Preview”,较容易找到我们所需数据的链接为第一个“node_4108.htm”,可发现对应本网页地址栏网址为https://news.gmw.cn/node_4108.htm的尾端
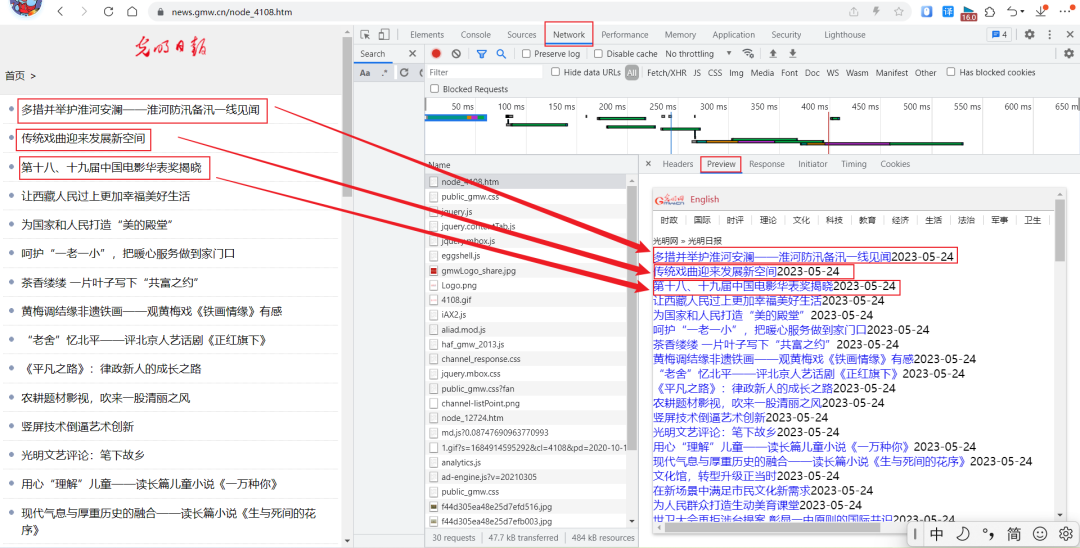
4、点击不同页面,发现网页网址发生改变,可判断该网页为静态网页。同时观察页面数据,发现Preview里面有我们所需数据

导入第三方库
引入需要的第三方库,编程代码如下:
import requests import pandas as pd from bs4 import BeautifulSoup
请求数据
针对静态网页,我们可以使用Requests库请求数据,在此之前,需要了解该网站的请求方式和编码格式。
点击Headers可知,网站的请求方式为“GET”,并通过python软件运行可得请求结果为<Response[200]>,数字是200说明请求成功,验证通过,采用 get 请求。
 编写代码如下所示:
编写代码如下所示:
import requests url = 'https://news.gmw.cn/node_4108.htm' headers = {'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.4031 SLBChan/105'} response = requests.get(url=url,headers=headers) print(response.status_code) response.encoding=response.apparent_encoding
解析数据
可以发现,所有新闻资讯储存在‘ul’标签下的class=“channel-newsGroup”中,每行新闻资讯数据在上述标签的‘li’标签下,因此我们可以采用BeautifulSoup库解析数据。
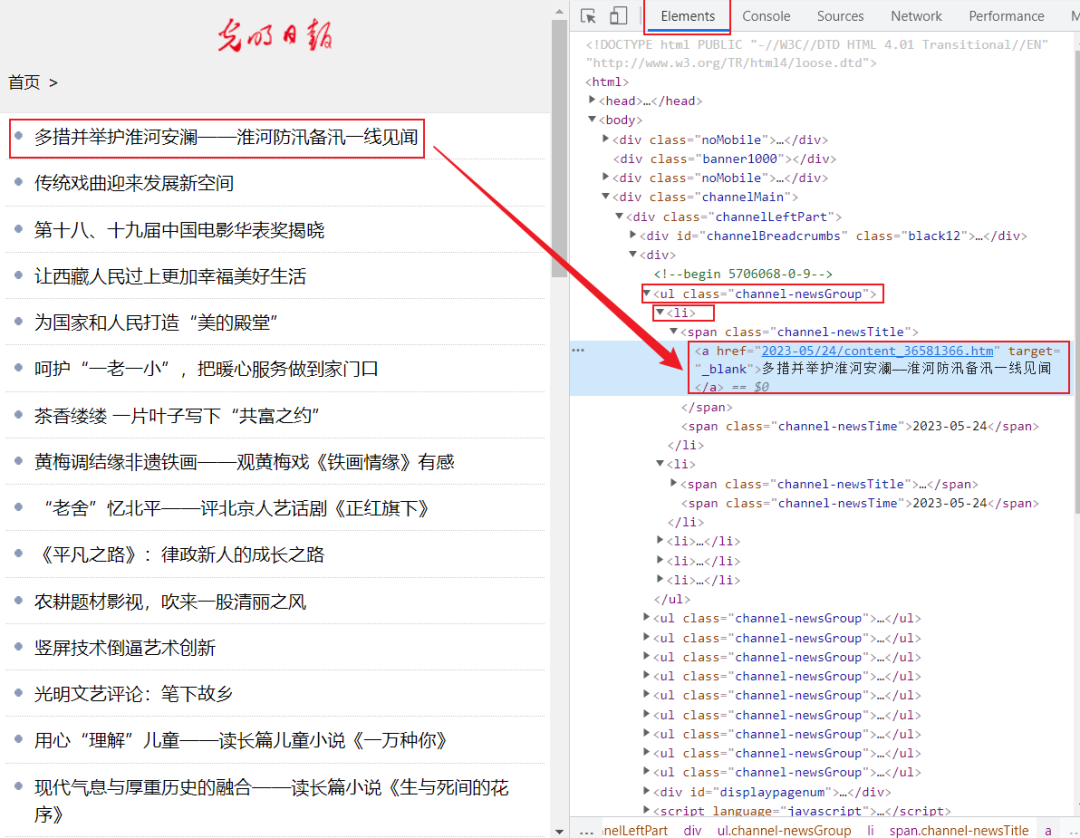
同时可以观察发现,在上述’li’标签中,不同新闻资讯的子链接位于’a’标签中的’href’中,并且存在规律性,即子链接的形式都为[https://news.gmw.cn/'+child_url],新闻资讯标题位于’a’标签的’title’中,对应新闻资讯发布时间位于’span’标签中。
编写代码如下所示:
from bs4 import BeautifulSoup items=[] soup=BeautifulSoup(response.text,'html.parser') Group_list=soup.find_all('ul',class_='channel-newsGroup') for Group in Group_list: li_list=Group.find_all('li') for g in li_list: title=g.find('a').text child_url=g.find('a').get('href') href= 'https://news.gmw.cn/'+child_url data=g.find('span').text item=[title,href,data] items.append(item)
储存数据
利用 pandas 库将所爬取数据信息存储下来。该阶段代码如下:
`import pandas as pd df=pd.DataFrame(items,columns=['标题','网页链接','发布时间']) df.to_excel(r'C:\Users\蓝胖子\Desktop\t.xlsx',encoding='utf_8_sig')`
爬取所有页面数据
通过寻找页面规律可得:
首页网址:https://news.gmw.cn/node_4108.htm]
其他页网址都是:https://news.gmw.cn/node_4108_{i}.htm的形式,只是不同网页中i取值不同。
截止至 2023 年 5 月 24 号,光明日报新闻页数为 10 页,因此 i=1,2,3…10。
设置 for 循环语句,如下:
`for i in range(1,11): if i==1: url='https://news.gmw.cn/node_4108.htm' else: url=f'https://news.gmw.cn/node_4108_{i}.htm'`
全套代码及运行结果
全套代码如下:
`import requests import pandas as pd from bs4 import BeautifulSoup items=[] for i in range(1,11): if i==1: url='https://news.gmw.cn/node_4108.htm' else: url=f'https://news.gmw.cn/node_4108_{i}.htm' headers = {'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.4031 SLBChan/105'} response= requests.get(url=url,headers=headers) response.status_code response.encoding=response.apparent_encoding soup=BeautifulSoup(response.text,'html.parser') Group_list=soup.find_all('ul',class_='channel-newsGroup') for Group in Group_list: li_list=Group.find_all('li') for g in li_list: title=g.find('a').text child_url=g.find('a').get('href') href= 'https://news.gmw.cn/'+child_url data=g.find('span').text item=[title,href,data] items.append(item) df=pd.DataFrame(items,columns=['标题','网页链接','发布时间']) df.to_excel(r'C:\Users\蓝胖子\Desktop\t.xlsx',encoding='utf_8_sig')`
运行结果如下: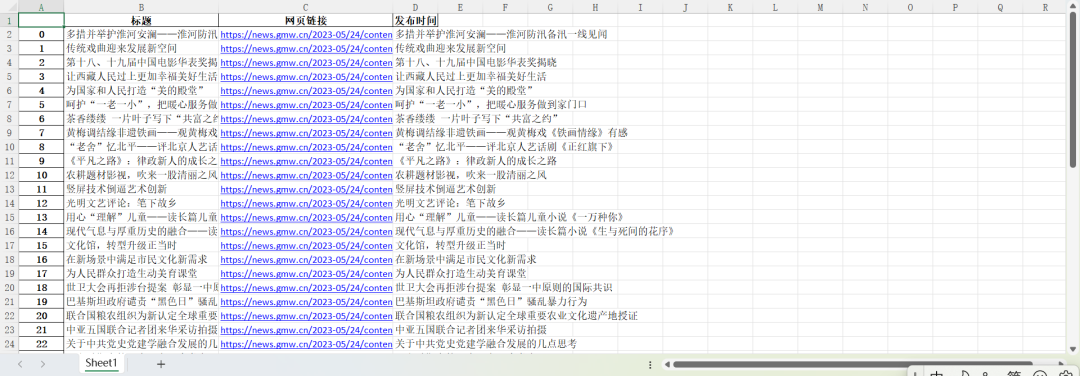
以上就是“Python爬取光明网新闻资讯”的全部内容,希望对你有所帮助。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。


















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









