







使用idea运行hbase程序(功能 hbase数据导入hdfs) 出现如下错误:
(这个没有打成jar包到服务器运行 而是打成jar包在本地运行)
网上每个人遇到的这个问题的原因不同的 我看了好多都不一样
我这里是因为 缺失了ha的配置文件 即 hdsfs-site.xml 加上就好了
还有下面我写的1. 和2.这两点 有知道原因的请指点一下
Exception in thread "main" java.lang.ExceptionInInitializerError
at org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.convertScanToString(TableMapReduceUtil.java:556)
at org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.initTableMapperJob(TableMapReduceUtil.java:201)
at org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.initTableMapperJob(TableMapReduceUtil.java:162)
at org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.initTableMapperJob(TableMapReduceUtil.java:285)
at org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil.initTableMapperJob(TableMapReduceUtil.java:86)
at com.qf.mr.HBase2HDF_SDemo1.run(HBase2HDF_SDemo1.java:87)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at com.qf.mr.HBase2HDF_SDemo1.main(HBase2HDF_SDemo1.java:116)
Caused by: java.lang.IllegalArgumentException: java.net.UnknownHostException: qf
at org.apache.hadoop.security.SecurityUtil.buildTokenService(SecurityUtil.java:418)
at org.apache.hadoop.hdfs.NameNodeProxiesClient.createProxyWithClientProtocol(NameNodeProxiesClient.java:130)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:343)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:287)
at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:156)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2811)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:100)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2848)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2830)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:389)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:356)
at org.apache.hadoop.hbase.util.DynamicClassLoader.initTempDir(DynamicClassLoader.java:120)
at org.apache.hadoop.hbase.util.DynamicClassLoader.<init>(DynamicClassLoader.java:98)
at org.apache.hadoop.hbase.protobuf.ProtobufUtil.<clinit>(ProtobufUtil.java:243)
... 8 more
Caused by: java.net.UnknownHostException: qf
... 22 more
Process finished with exit code 1
首先
我这是在idea这边运行将hbase数据导入hdfs的一个小Demo
没有使用key value的方式 而是使用加载xml文件的方式 这两种方式在我另一篇博客有介绍(写完这篇就写)

我先说我的解决办法
1.我原先只有两个文件 core-site.xml hbase-site.xml
加上了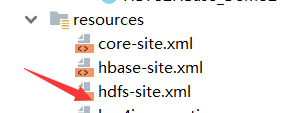
hdfs-site.xml文件
这个东西加到idea中去就好了 去掉就出错误 就是上面的 我反复试了好几遍
猜想:我觉得可能是我这的hdfs使用了ha 高可用 但是找不到相关配置文件
导致出现错误
因为刚开始我搜的是第一句Exception in thread "main" java.lang.ExceptionInInitializerError
没找到答案
然后过了一会儿才看到下面的Caused by: java.lang.IllegalArgumentException: java.net.UnknownHostException: qf
一看是我的ha的虚拟名字 qf
猜想这里出了问题
然后 我又想到了
我的另一篇博客 HBase全分布式搭建
还有解决我以前问题的博客
hadoop配置ha后,hbase配置的变化
这俩里面是让 hdfs-site.xml和core-site.xml复制到hbase的conf目录下。不然会报找不到qf的错误
然后我就 想到会不会是我在idea的错误也缺少这个
所以就这样了
2.同时 我还注意到 我只加载了 这俩文件
新加进resources的hdfs-site.xml并没有使用代码加载 也行竟然 可能是 自动加载了吧 知道的请指点一下

下面贴出我的代码 不看也行

在idea的配置
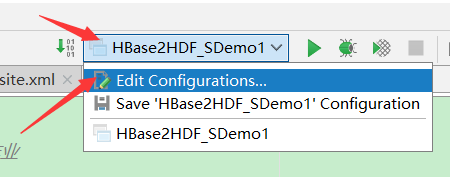
1.第一个是表示以root用户方式运行
-DHADOOP_USER_NAME=root
2.第二个是写输出路径 到hdfs上

然后直接运行即可
对了 我那个 Windows系统下运行hadoop、HBase程序出错Could not locate executablenull\bin\winutils.exe in the Hadoop binaries 这个东西也装上了
/**
* 作者:Shishuai
* 文件名:HBase2HDFS
* 时间:2019/8/17 16:00
*/
package com.qf.mr;
import cn.qphone.mr.Demo1_HBase2HDFS;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellScanner;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
//不要导错了包 org.apache.hadoop.mapred.FileOutputFormat 这个不对
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class HBase2HDF_SDemo1 extends ToolRunner implements Tool {
private Configuration configuration;
private final String HDFS_KEY = "fs.defaultFS";
private final String HDFS_VALUE = "hdfs://qf";
private final String MR_KEY = "mapreduce.framework.name";
private final String MR_VALUE = "yarn";
private final String HBASE_KEY = "hbase.zookeeper.quorum";
private final String HBASE_VALUE = "hadoop01:2181,hadoop02:2181,hadoop03:2181";
private Scan getScan(){
return new Scan();
}
static class HBase2HDFSMapper extends TableMapper<Text, NullWritable> {
private Text k = new Text();
/**
* 001 column=base_info:age, timestamp=1558348072062, value=20
* 001 column=base_info:name, timestamp=1558348048716, value=lixi
*
*
* 001 base_info:age 20 base_info:name lixi
*/
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
//1. 创建StringBuffer用于拼凑字符串
StringBuffer sb = new StringBuffer();
//2. 遍历result中的所有的列簇
CellScanner scanner = value.cellScanner();
int index = 0;
while(scanner.advance()){
//3. 获取到当前的cell,然后决定拼串的方式
Cell cell = scanner.current();
if(index == 0){
sb.append(new String(CellUtil.cloneRow(cell))).append("\t");
index++;
}
sb.append(new String(CellUtil.cloneQualifier(cell))).append(":")
.append(new String(CellUtil.cloneValue(cell))).append("\t");
}
//4. 输出
k.set(sb.toString());
context.write(k, NullWritable.get());
}
}
@Override
public int run(String[] args) throws Exception {
configuration = getConf();
//2. 获取到job
Job job = Job.getInstance(configuration);
//3. map,reduce(mapper/reducer的class,还要设置mapper/reducer的输出的key/value的class)
job.setMapperClass(HBase2HDFSMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//4. 输出和输入的参数(输入的目录和输出的目录)
TableMapReduceUtil.initTableMapperJob("user_info", getScan(), HBase2HDFSMapper.class,Text.class, NullWritable.class, job);
FileOutputFormat.setOutputPath(job, new Path(args[0]));
//5. 设置驱动jar包的路径
job.setJar("C:\\Users\\HP\\IdeaProjects\\HBaseHighRank\\target\\HBaseHighRank-1.0-SNAPSHOT.jar");
// job.setJarByClass(Demo1_HBase2HDFS.class);
//6. 提交作业(job)
return job.waitForCompletion(true) ? 0 : 1;// 打印提交过程的日志记录并且提交作业
}
@Override
public void setConf(Configuration configuration) {
//1. 保证连接hdfs、连接yarn、连接hbase
// configuration.set(HDFS_KEY,HDFS_VALUE);
// configuration.set(MR_KEY,MR_VALUE);
// configuration.set(HBASE_KEY,HBASE_VALUE);
configuration.addResource("core-site.xml");
configuration.addResource("hbase-site.xml");
this.configuration = configuration;
}
@Override
public Configuration getConf() {
return configuration;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(HBaseConfiguration.create(), new HBase2HDF_SDemo1(), args);
}
}
/**
* 作者:Shishuai
* 文件名:HBaseUtils
* 时间:2019/8/17 16:01
*/
package com.qf.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import java.io.IOException;
import java.util.Iterator;
public class HBaseUtilsDemo {
private final static String KEY = "hbase.zookeeper.quorum";
private final static String VALUE = "hadoop01:2181,hadoop02:2181,hadoop03:2181";
private static Configuration configuration;
static {
//1. 创建配置对象
configuration = HBaseConfiguration.create();
configuration.set(KEY, VALUE);
}
public static Admin getAdmin(){
try {
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin();
return admin;
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
public static Table getTable(){
return getTable("user_info");
}
private static Table getTable(String tablename) {
try {
Connection connection = ConnectionFactory.createConnection(configuration);
return connection.getTable(TableName.valueOf(tablename));
} catch (IOException e) {
e.printStackTrace();
return null;
}
}
public static void showResult(Result result) throws IOException {
StringBuffer stringBuffer = new StringBuffer();
CellScanner scanner = result.cellScanner();
while(scanner.advance()){
Cell cell = scanner.current();
stringBuffer.append("Rowkey=").append(new String(CellUtil.cloneRow(cell))).append("\t")
.append("columnfamily=").append(new String(CellUtil.cloneFamily(cell))).append("\t")
.append("cloumn=").append(new String(CellUtil.cloneQualifier(cell))).append("\t")
.append("value=").append(new String(CellUtil.cloneValue(cell))).append("\t").append("\n");
}
System.out.println(stringBuffer.toString());
}
public static void showResult(Filter filter) throws IOException {
if(filter instanceof SingleColumnValueFilter){
SingleColumnValueFilter singleColumnValueFilter = (SingleColumnValueFilter)filter;
singleColumnValueFilter.setFilterIfMissing(true);
}
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner scanner = getTable().getScanner(scan);
Iterator<Result> iterator = scanner.iterator();
while(iterator.hasNext()){
Result result = iterator.next();
showResult(result);
}
}
public static void close(Admin admin){
if(admin != null){
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void close(Table table){
if(table != null){
try {
table.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void close(Admin admin, Table table){
close(admin);
close(table);
}
}
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- hdfs的默认的内部通信uri -->
<!--配置hdfs文件系统的命名空间-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://qf</value>
</property>
<!--配置操作hdfs的缓存大小-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--配置临时数据存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hahadoopdata/tmp</value>
</property>
<!-- 指定zk的集群地址 用来协调namenode的服务 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
</configuration>
hdfs-site.xml
?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--副本数 也叫副本因子 不是容错嘛-->
<!--副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--块大小_hadoop2_128M_hadoop1_64M_hadoop3.0_256M-->
<property>
<name>dfs.block.size</name>
<value>134217728</value>
</property>
<!--hdfs的元数据存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hahadoopdata/dfs/name</value>
</property>
<!--hdfs的数据存储位置-->
<property>
<name>dfs.datanode.dir</name>
<value>/home/hahadoopdata/dfs/data</value>
</property>
<!--指定hdfs的虚拟服务名-->
<property>
<name>dfs.nameservices</name>
<value>qf</value>
</property>
<!--指定hdfs的虚拟服务名下的namenode的名字-->
<property>
<name>dfs.ha.namenodes.qf</name>
<value>nn1,nn2</value>
</property>
<!--指定namenode的rpc内部通信地址-->
<property>
<name>dfs.namenode.rpc-address.qf.nn1</name>
<value>hadoop01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.qf.nn2</name>
<value>hadoop02:8020</value>
</property>
<!--指定namenode的web ui界面地址-->
<property>
<name>dfs.namenode.http-address.qf.nn1</name>
<value>hadoop01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.qf.nn2</name>
<value>hadoop02:50070</value>
</property>
<!--指定jouranlnode数据共享目录 namenode存放元数据信息的Linux本地地址 这个目录不需要我们自己创建-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/qf</value>
</property>
<!--指定jouranlnode本地数据共享目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hahadoopdata/jouranl/data</value>
</property>
<!-- 开启namenode失败进行自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--指定namenode失败进行自动切换的主类 datanode存放用户提交的大文件的本地Linux地址 这个目录不需要我们自己创建-->
<property>
<name>dfs.client.failover.proxy.provider.qf</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--防止多个namenode同时active(脑裂)的方式 采用某种方式杀死其中一个-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://qf/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<!--将hbase的分布式集群功能开启-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/zkdata</value>
</property>
</configuration>
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.qf</groupId>
<artifactId>HBaseHighRank</artifactId>
<version>1.0-SNAPSHOT</version>
<name>HBaseHighRank Maven Webapp</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>1.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-hbase-handler</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
</project>















 949
949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









