







使用Hive存储数据
- hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
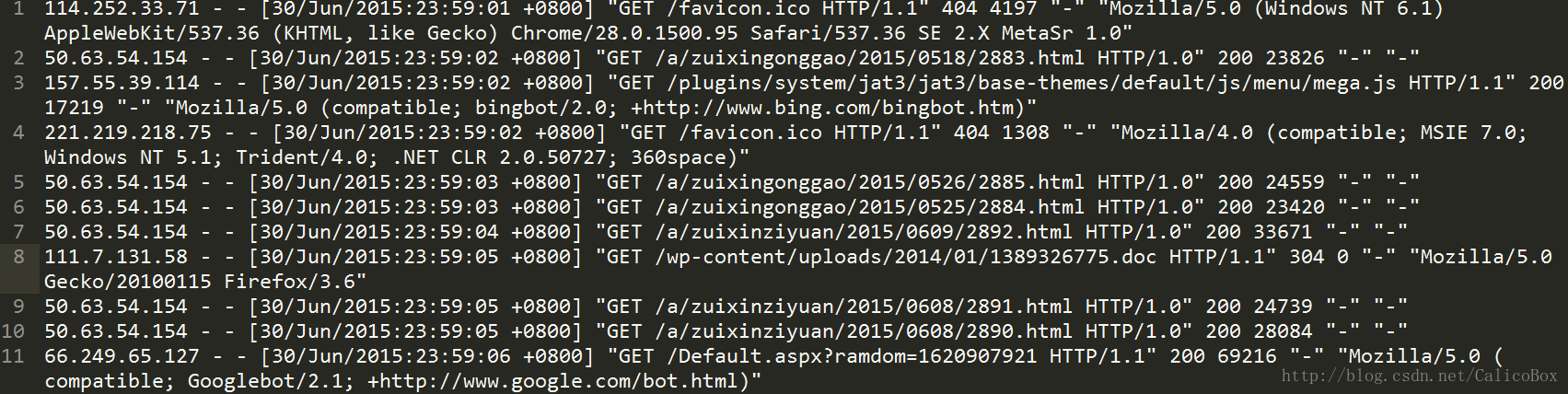
- 这里我们需要对学校nginx服务器上的日志进行分析,我们选择通过Hive来进行存储和分析。首先要完成日志文件存入Hive中,需要存入的nginx日志文件数据具体如下:
这条日志里面有九项,每项之间是用空格分割的,每项的含义分别是客户端访问IP、用户标识、用户、访问时间、请求页面、请求状态、返回文件的大小、跳转来源、浏览器UA。如果想用一般的方法来解析这条日志的话,有点困难。但是我们可以如果我们用正则表达式去匹配这九列的话还是很简单的:
([^ ]) ([^ ]) ([^ ]) ([.]) (\”.?\”) (-|[0-9]) (-|[0-9]) (\”.?\”) (\”.*?\”)
这样就可以匹配出每一列的值。而在Hive中我们是可以指定输入文件的解析器(SerDe)的,并且在Hive中内置了一个org.apache.hadoop.hive.contrib.serde2.RegexSerDe正则解析器,我们可以直接使用它。 - 首先进入hive
# hive在hive shell 中输入一下命令创建要使用的表。(该语句中使用了通过日期建立分区表)
CREATE EXTERNAL TABLE data(
ip STRING,
identity STRING,
user STRING,
time STRING,
request STRING,
status STRING,
size STRING,
referer STRING,
agent STRING)
PARTITIONED BY (date STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (\\[.*\\]) (\".*?\") (-|[0-9]*) (-|[0-9]*) (\".*?\") (\".*?\")",
"output.format.string"="%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s"
)表中的各个列即对应日志中的各项数据。注意这里最好将所建的Hive表建为外部表(即含有external关键字),这样在我们删除这个表时不会删除掉其中的数据。
4. 由于在创建的过程中使用了contrib包中的SerDe工具,需要进行配置修改将下面的配置语句,加在配置文件: $HIVE_INSTALL/conf/hive-site.xml中,其中value中的值为hive-contrib-*.jar的路径,是为你机器上实际的放置,在$HIVE_INSTALL/lib目录下寻找。
<property>
<name>hive.aux.jars.path</name>
<value>file:///opt/cloudera/parcels/CDH/lib/hive/lib/hive-contrib-1.1.0-cdh5.7.0.jar</value>
<description> These JAR file are available to all users for all jobs</description>
</property>然后退出hive shell,重新启动hive shell,即可。
5. 然后在命令行中通过desc 表名语句查看所创建的表,下图是创建test表的情况:
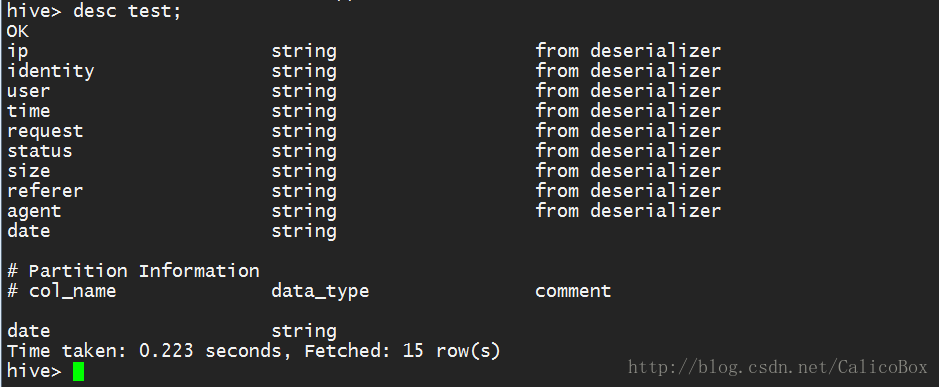
可以看到各列的情况以及分区的依据。
6. 在表完成创建后,就把日志存入创建的表中,首先可以先把文件从本地上传到集群中的HDFS中进行存储,通过下列语句:
sudo –u root hdfs dfs –put /local path/file /hdfs path然后通过在存入创建的表中(在导入数据时请注意切换到hdfs或root用户权限下进入hive命令行),例如:
从hdfs导入:
load data inpath '/user/hdfs/nginx/accesslog.20150701' overwrite into table 表名 partition (date=’20150701’);从本地导入:
load data local inpath '/home/networkcenter/Data/10.3.181.28/nginxlog/accesslog.20150701' overwrite into table 表名 partition (date=’20150701’);使用overwrite将进行覆盖写入。
(参考:http://blog.csdn.net/yfkiss/article/details/7776406)
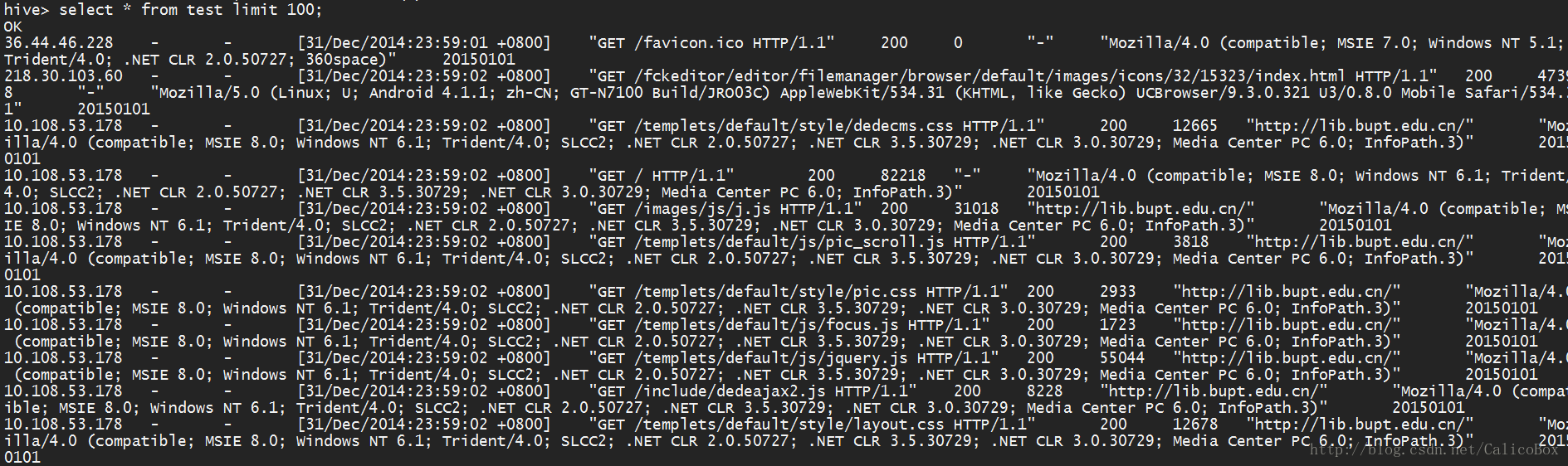
7. 导入成功后,就可以查看在表中的数据了,直接通过
select * from 表名;
查看所有的数据,查看数据是否匹配,并可以通过
select count(*) from 表名;
查看数据总量是否正确。下图是根据导入数据的查询结果:
利用批量数据导入HDFS
- 日志服务器产生的日志数据最好全部导入HDFS中集中存储,可以方便我们日后对如何时间段的日志进行分析,并且能够稳定存储。
- 首先将日志通过FTP的方式保存在本地,然后通过下面的shell脚本将本地现有的日志文件全部存入HDFS中。下面的脚本是将本地上所有的日志全部上传:
#!/bin/sh
#!导入日志从20150101开始 startday="20150101"
#!设置导入的数量 for i in `seq 0 234` do dayNum=$(date -d "$startday +$i day" "+%Y%m%d") echo $dayNum
#!将本地日志文件先导入到hdfs上 sudo -u hdfs hadoop fs -put /home/networkcenter/Data/10.3.181.28/nginxlog/accesslog.${dayNum}
/user/hdfs/nginx
#!将已经上传的日志文件导入hive的分区表test中 sudo -u hdfs hive -e " LOAD data inpath '/user/hdfs/nginx/accesslog.${dayNum}' overwrite into table data
partition (date='${dayNum}');" done
并将上述脚本保存为.sh文件,如下图所示:
然后在保存当前文件,并在当前文件夹下对该文件添加权限,执行下面代码:
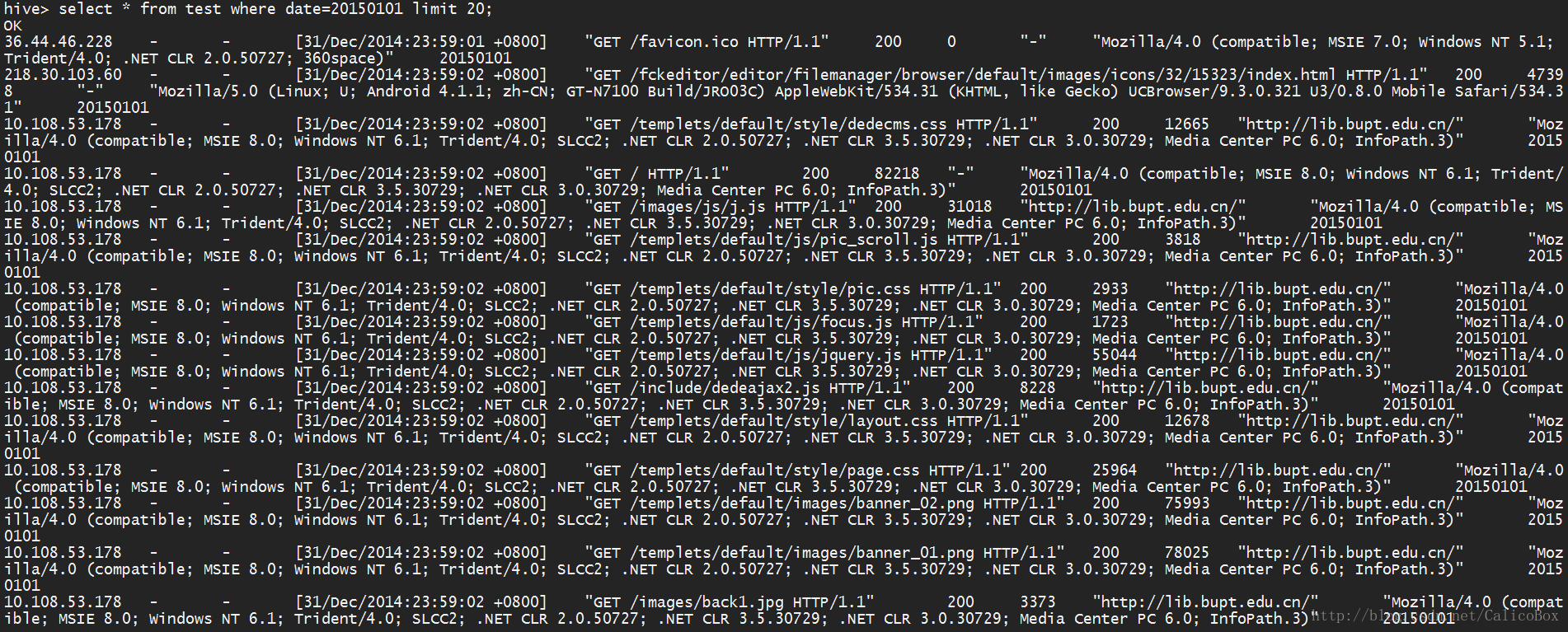
Chmod 777 test.sh- 接下来就可以在分区表test查询到对应的日期的日志数据,例如下图查询了日期20150101的日志(只显示20条):
- 当然如果要对前一天的数据进行存储分析,下面的脚本即可以将前一天的数据进行导入HDFS,如下:

#!/bin/sh
yesterday=`date --date='1 days ago' +%Y%m%d`
#!echo ${yesterday}
#!将本地日志文件先导入到hdfs上
sudo -u root hdfs dfs -put /home/cloudera/Project/accesslog.${yesterday} /user/hdfs/nginx
#!将本地的日志文件导入hive的分区表中
hive -e "LOAD data local inpath '/home/cloudera/Project/accesslog.${yesterday}' overwrite into table test partition (date='${yesterday}');"
#!数据导入hive后将本地的日志文件删除
rm /home/cloudera/Project/accesslog.${yesterday}同样对上述脚本保存为.sh文件,然后对该文件添加权限,最后可以通过添加定时任务crontab让脚本能够定时执行,即输入crontab –e,加入如下代码:
#import nginxlog
0 05 * * * /opt/bin/hive_opt/import_tracklog.sh就可以实现将上述脚本在每天凌晨00:05执行一次。
利用sqoop完成关系数据库数据导入
- Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如: MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
- 安装配置sqoop(CDH里已经集成好了)
- 这里举例利用sqoop完成从Oracle数据库中将一个视图存入HDFS中,首先下图是在Oracle数据库中保存的视图数据的情况:
- 然后通过sqoop命令将该视图导入本地的文件中进行存储,使用的sqoop命令是(注意要切换用户权限):
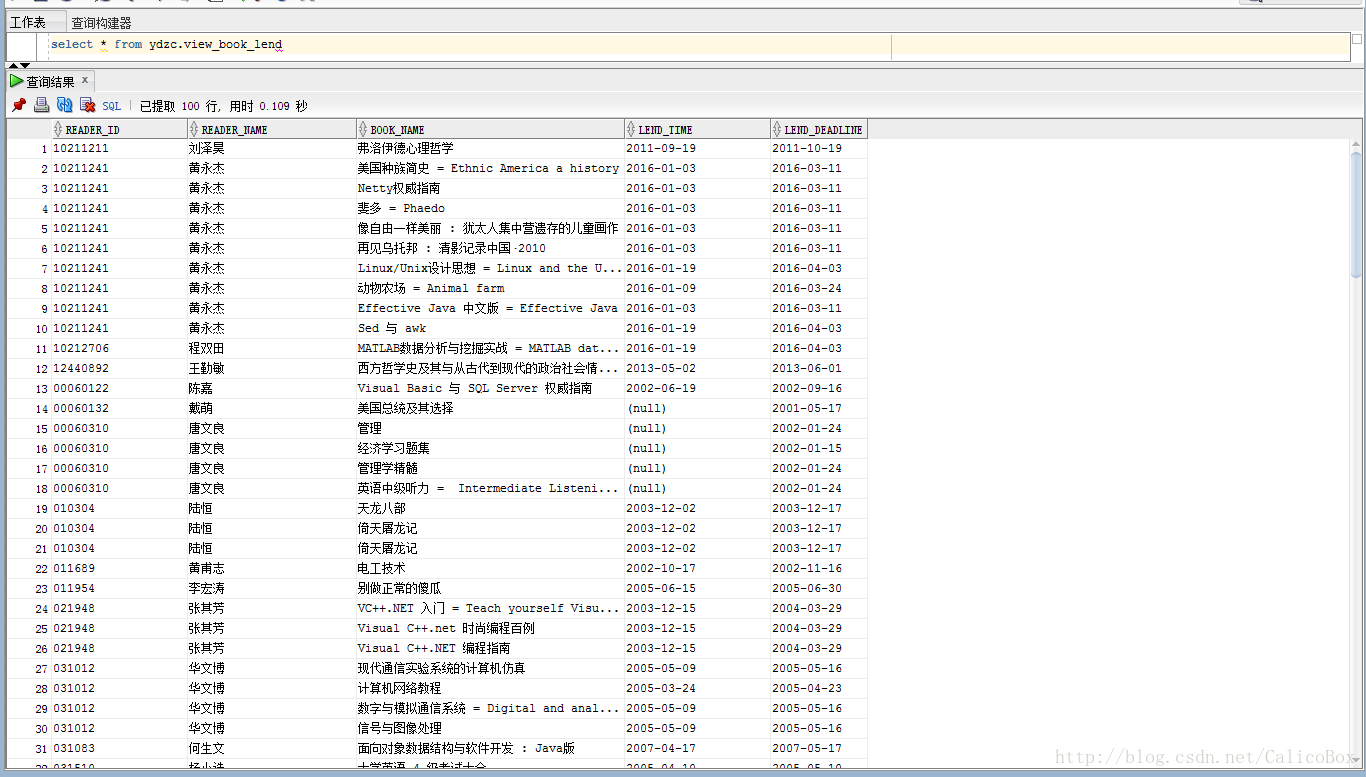
Sudo –u hdfs sqoop import
--connect jdbc:oracle:thin:@10.3.55.52:1521:ywkdb
--username lzc
--password 123456
--query 'select * from ydzc.view_book_lend WHERE $CONDITIONS'
--split-by READER_ID
--target-dir "/tmp/root/test1.ydzc.view_book_lend"导入完成后就可以在相应的目录下查看保存的文件,查看相应的文件如下:
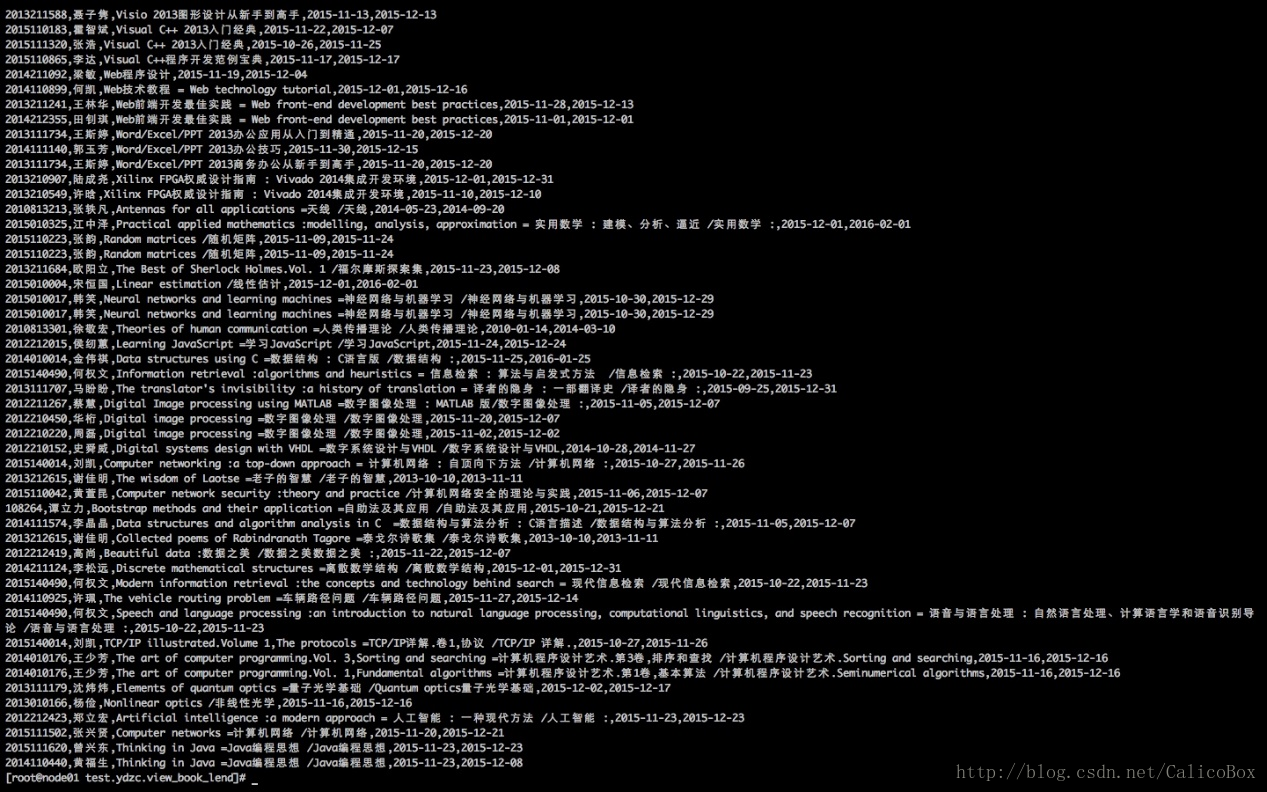
5. 具体更多的sqoop命令行命令可以参考:
https://sqoop.apache.org/docs/1.99.5/CommandLineClient.html
利用Hive的UDF来进行ip地址映射
- UDF(User-Defined-Function),即为用户自定义函数。UDF函数可以直接应用于select语句,对查询结构做格式化处理后,再输出内容;编写UDF函数的时候需要注意一下几点自定义UDF需要继承org.apache.hadoop.hive.ql.UDF;另外编写UDF时需要实现evaluate函数;并且evaluate函数支持重载。因为UDF只能实现一进一出的操作,如果需要实现多进一出,则需要实现UDAF。
- 这里实现的即为根据日志数据中的IP地址数据段得到用户访问的地理位置的分布,这里使用了国外的地理数据库GeoIP的数据包(http://dev.maxmind.com/zh-hans/geoip/legacy/geolite/),并编写好如下的UDF:
import java.io.IOException;
import org.apache.hadoop.hive.ql.exec.UDF;
import com.maxmind.geoip.Location;
import com.maxmind.geoip.LookupService;
import java.util.regex.*;
public class IPToCC extends UDF {
private static LookupService cl = null;
private static String ipPattern = "\\d+\\.\\d+\\.\\d+\\.\\d+";
private static String ipNumPattern = "\\d+";
static LookupService getLS() throws IOException{
String dbfile = "GeoLiteCity.dat";
if(cl == null)
cl = new LookupService(dbfile, LookupService.GEOIP_MEMORY_CACHE);
return cl;
}
/**
* @param str like "114.43.181.143"
**/
public String evaluate(String str) {
try{
Location Al = null;
Matcher mIP = Pattern.compile(ipPattern).matcher(str);
Matcher mIPNum = Pattern.compile(ipNumPattern).matcher(str);
if(mIP.matches())
Al = getLS().getLocation(str);
else if(mIPNum.matches())
Al = getLS().getLocation(Long.parseLong(str));
return String.format("%s\t%s", Al.countryName, Al.city);
}catch(Exception e){
e.printStackTrace();
if(cl != null)
cl.close();
return null;
}
}
}接下来的步骤为:
● 可以在My Eclipse中进行编译,并且打包成一个jar包;
● 将该jar包上传到集群中,同时将该UDF需要的jar包和数据库文件一起上传;
● 进入Hive命令行添加所需的jar包,如:
add file GeoLiteCity.dat
add jar demo2.jar
add jar geoip-api-1.2.15.jar;● 添加完成后,就可以进行创建临时函数,这也是不可缺少的一步,如:
create temporary function ip2cc as 'udf.demo.IPToCC';ip2cc即是创建的临时函数名,引号中的即是对应jar包当中的实现功能的类名。
● 最后,就可以用HQL语句进行ip地址的查询,如:
select host,ip2cc(host) from zblog_isnfo limit 135;最后可以查看到host字段以及其对应的地理位置信息的情况,如下所示:


















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









