









# ref: <How to Fine-Tune BERT for Text Classification? >
from transformers import AdamW
# 分层学习率衰减
# 基础学习率
lr_base = 5e-6
lr_classifier = 5e-5
# 衰减系数
xi = 0.95
lr = dict()
lr[23] = lr_base
for k in range(23,0,-1):
lr[k-1] = 0.95*lr[k]
print('lr_decay: ', lr)
adamw_lr = [{"params": model.roberta.encoder.layer[i].parameters(), "lr": lr[i]} for i in range(24)]
adamw_lr.append({"params": model.classifier.parameters(),"lr": lr_classifier})
print(adamw_lr)
optimizer = AdamW(
adamw_lr,
lr=lr_classifier
)
# 在finetune时使用这个optimizer根据论文<How to Fine-Tune BERT for Text Classification? >
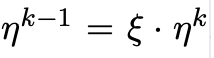
![]() 为基础leaning rate,
为基础leaning rate,
ξ<1越低层有越低的学习率
decay factor=1时为默认方式

论文中的结论是对于bert模型 base lr=2e-5, decay factor=0.95效果最好















 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









