







 本文介绍了自动机理论的基础知识,涵盖了有限状态机的各种类型及其应用,包括确定性与非确定性有限状态机、Moore与Mealy机等。同时探讨了正则语言、上下文无关语言等概念,并涉及图灵机的强大计算能力。
本文介绍了自动机理论的基础知识,涵盖了有限状态机的各种类型及其应用,包括确定性与非确定性有限状态机、Moore与Mealy机等。同时探讨了正则语言、上下文无关语言等概念,并涉及图灵机的强大计算能力。
目录
这是对Neso Academy课程Theory of Computation & Automata Theory的一个知识记录,不是很全面,但是能在系统分析与验证的学习中用到。
前置知识
符号(Symbol)
a,b,c,0,1,2
字母表(alphabet)
字母表Σ是符号的集合,例如{a,b},{0,1,2}
字符串(string)
符号的序列,如a,aa,bb,aba
语言(language)
字符串的集合,如{00,11,01,10}
字母表的幂(power)
如果字母表Σ={0,1}
Σ
0
Σ_{0}
Σ0=所有长度为0的字符串的集合:
Σ
0
=
{
ϵ
}
Σ_{0}=\{\epsilon\}
Σ0={ϵ}
Σ
1
Σ_{1}
Σ1=所有长度为1的字符串的集合:
Σ
1
=
{
0
,
1
}
Σ_{1}=\{\ 0,1\}
Σ1={ 0,1}
Σ
2
Σ_{2}
Σ2=所有长度为2的字符串的集合:
Σ
2
=
{
00
,
01
,
10
,
11
}
Σ_{2}=\{\ 00,01,10,11\}
Σ2={ 00,01,10,11}
Σ
n
Σ_{n}
Σn=所有长度为n的字符串的集合
Σ n Σ_{n} Σn中元素的个数为 2 n 2^n 2n
Σ ∗ = Σ 0 ∪ Σ 1 ∪ Σ 2 ∪ Σ 3 . . . Σ^{*}=Σ_{0}\cup Σ_{1}\cup Σ_{2}\cup Σ_{3}... Σ∗=Σ0∪Σ1∪Σ2∪Σ3...=字母表可能组成的所有字符串的集合
有限状态机
分类
有限状态机(finite state machine)也被称为有限自动机(finite automata),可以根据有没有输出分为两类
有输出的有限状态机:Moore Machine,Mealy Machine
无输出的有限状态机:DFA,NFA,
ϵ
\epsilon
ϵ-NFA
确定的有限状态机(DFA)
这是一种最最简单的模型,并且存储非常有限
DFA由一个五元组 ( S , Σ , s 0 , F , δ ) (S,Σ,s_{0},F,δ) (S,Σ,s0,F,δ)构成:
- S S S是一组状态的集合
- Σ Σ Σ是输入字母表
- s 0 s_{0} s0是初始状态
- F F F是终止状态的集合
- δ δ δ是转换函数: S × Σ → S S×Σ\rightarrow S S×Σ→S
有如下确定有限状态机,DFA表示为一个有向图,没有源的箭头指向的是初始状态,两个圆圈代表终止状态,状态又圆圈表示,转换函数由有向线段表示,由一个状态指向另一个状态,线段上的字符代表着输入字符,所以:
- S={A,B,C,D}
- Σ={0,1}
- s 0 = A s_{0}=A s0=A
- F={D}
- δ(A,1)=B,δ(B,1)=A,δ(B,0)=D,δ(D,0)=B,δ(D,1)=C,δ(C,1)=D,δ(C,0)=A,δ(A,0)=C
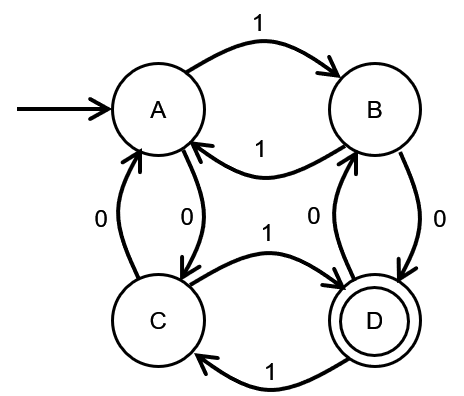
如果一个字符串t能够使得一个DFA M从初始状态最终达到终止状态,那么我们称t可以被M所接受(accept,也可以叫做识别recognize)。对于上面的例子,一个可被接受的输入为10
正则语言(regular language)
如果一个语言能被称为正则语言,当且仅当它能被某些有限状态机接受。
我们已经知道了接受这个概念,那么有哪些语言不是正则语言呢?
- 不能被有限状态机识别
- 需要存储空间(memory)
因为有限状态机的存储空间非常小,所以它不能存储或者计数字符串。
反例
- abaababaab
这个语言由abaab重复组成,因为有限状态机不能存储字符串,所以它不是一个正则语言。 -
a
n
b
n
a^nb^n
anbn
这个语言化简出来就是n个a和n个b,假如n=4,那么就是aaaabbbb,所以需要对a和b的个数进行计数,但是我们知道有限状态机不能计数,所以它也不是一个正则语言。
正则语言的操作
Union:
A
∩
B
=
{
x
∣
x
∈
A
o
r
X
∈
B
}
A\cap B=\{x|x∈A\; or\; X∈B\}
A∩B={x∣x∈AorX∈B}
Concatenation:
A
∘
B
=
{
x
y
∣
x
∈
A
a
n
d
y
∈
B
}
A\circ B=\{xy|x∈A\; and\; y∈B\}
A∘B={xy∣x∈Aandy∈B}
Star:
A
∗
=
{
x
1
x
2
x
3
.
.
.
x
k
∣
k
≥
0
a
n
d
e
a
c
h
x
i
∈
A
}
A^*=\{x_{1}x_{2}x_{3}...x_{k}|k\ge0 \; and\; each\; x_{i}∈A\}
A∗={x1x2x3...xk∣k≥0andeachxi∈A}
定理1:两个正则语言的交集(union)仍然是正则语言
定理2:两个正则语言的级联(concatenation)仍然是正则语言
不确定的有限状态机(NFA)
在DFA中,给定一个状态和一个输入,它的下一个状态只有唯一的一种情况,但是对于不确定的有限状态机(NFA)来说,给定状态和输入,它的下一个状态可能会有多种情况。
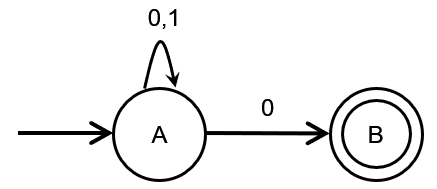
NFA的定义与DFA一样也是一个五元组
(
S
,
Σ
,
s
0
,
F
,
δ
)
(S,Σ,s_{0},F,δ)
(S,Σ,s0,F,δ),含义与DFA的一样,不过转换函数
δ
δ
δ定义为
S
×
Σ
→
2
S
S×Σ\rightarrow 2^S
S×Σ→2S,因为对于同一个输入来说,转换有多种可能。
对于上面的例子,表示为:
- S={A,B}
- Σ={0,1}
- s 0 = A s_{0}=A s0=A
- F={B}
- δ(A,1)={A},δ(A,0)={AB},δ(B,1)=∅,δ(B,0)=∅
ε ε ε-NFA
我们看到它前面带了一个 ε ε ε,这个符号表示空字符, ε ε ε-NFA与NFA的区别就是,接受空字符也能发生状态转换。对于一般状态机来说,接受空字符的结果仍然为当前状态,但是 ε ε ε-NFA接受空字符后可以转变为另一个状态,这就产生了一种不确定性(undetermined),是一种NFA。
ε
ε
ε-NFA的定义与NFA一样,不过转换函数
δ
δ
δ:
S
×
Σ
∪
ϵ
→
2
Q
S×Σ\cup \epsilon \rightarrow 2^Q
S×Σ∪ϵ→2Q,表示不同状态之间的转换允许提供空字符。

Moore Machine
前面讲了几种不带有输出的自动机,另外两种mealy machine和moore machine是带有输出的自动机
摩尔状态机由六元组组成:
- S S S是一组状态的集合
- Σ Σ Σ是输入字母表
- Δ Δ Δ是输出字母表
- s 0 s_{0} s0是初始状态
- F F F是终止状态的集合
- δ δ δ是转换函数: S × Σ → S S×Σ\rightarrow S S×Σ→S
- λ λ λ是输出函数: Q → Δ Q\rightarrow Δ Q→Δ
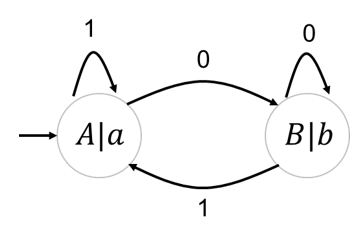
这是一个摩尔状态机的示例图,如果我们输入1010,它的输出将会是a,a,b,a,b,
∣
|
∣左边大写的字母代表状态,右边小写的字母代表的是输出,因为初始状态是A,所以它先会输出一个a,然后按照1010的输入顺序,每访问一个状态就输出该状态下对应的输出。
Mealy Machine
Mealy Machine由六元组组成:
- S S S是一组状态的集合
- Σ Σ Σ是输入字母表
- Δ Δ Δ是输出字母表
- s 0 s_{0} s0是初始状态
- F F F是终止状态的集合
- δ δ δ是转换函数: S × Σ → S S×Σ\rightarrow S S×Σ→S
- λ λ λ是输出函数: Σ × Q → Δ Σ×Q\rightarrow Δ Σ×Q→Δ
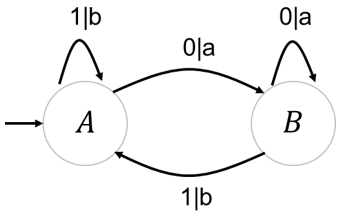
这是一个Mealy Machine的示例图,如果我们输入1001,它的输出为b,a,a,b,可以看到,Mealy Machine的输出是在转换关系上的,
∣
|
∣左边代表转换,右边代表输出,对于Mealy来说它的输出主要和转换有关,而对于Moore Machine来说,它的输出与状态和转换都有关。
正则表达式(regular expression)
正则表达式用于以代数方式表示某些字符串集
- 任何终结符号(terminal symbol)包括ε(代表空字符),
ϕ
\phi
ϕ(代表null)都属于正则表达式
像什么a,b,c,ε, ϕ \phi ϕ都是正则表达式 - 两个正则表达式的并集也是正则表达式
a,b是正则表达式那么a+b(表示关系或)也是 - 两个正则表达式的级联也是正则表达式
a,b是正则表达式那么ab也是 - 正则表达式的迭代(或闭包)也是正则表达式
a是正则表达式,那么a*也是正则表达式,a*=^,a,aa,aaa,… - 遵循上述规则组合在一起的表达式也是正则表达式
上述规则用符号定义为:
E
:
:
=
∅
| ε | A | E+E’ | E.E’ | E*
E ::= \varnothing\text{ | ε | A | E+E' | E.E' | E*}
E::=∅ | ε | A | E+E’ | E.E’ | E*
语法(grammar)
首先我们要知道什么是语法(grammar),语法就是适用于交流的一组规则,用在计算机领域,Noam Chomsky给出了一种语法的数学模型,用于有效地编写计算机语言。
他给出了四种类型的语法:
| Grammar type | Grammar Accept | Language Accept | Automaton |
|---|---|---|---|
| TYPE-0 | Unrestricted Grammar | Recursively Enumerable Language | Turing Machine |
| TYPE-1 | Context Sensitive Grammar | Context Sensitive Language | Linear Bounded Automaton |
| TYPE-2 | Context Free Grammar | Context Free Language | Pushdown automaton |
| TYPE-3 | Regular Grammar | Regular Language | Finite State Automaton |
一个语法G,可以描述为一个四元组G=(V,T,S,P)
- V:变量或者非终结符号(non-terminal symbol)的集合
- T:终结符号(terminal symbol)的集合
- S:初始符号
- P:终结符合非终结符的生成规则(production rules)
生成规则P形如 α → β α\rightarrow β α→β,α和β是 V ∪ T V\cup T V∪T中的字符串,并且α中至少有一个字符属于V
举例:G=({S,A,B},{a,b},S,{S->AB,A->a,B->b})
展示由语法生成字符串的过程:
从开始符号开始S,看到生成规则
S
→
A
B
S\rightarrow AB
S→AB,又因为
A
→
a
A\rightarrow a
A→a,并且
B
→
b
B\rightarrow b
B→b,所以我们可以得出:
S
→
A
B
→
a
b
S\rightarrow AB\rightarrow ab
S→AB→ab
由语法推导(derivation)出的字符串的集合,我们称之为语法生成的语言(language)
例如,上面的那个例子,生成的语言可以记为L(G)={ab}
正规文法(regular grammar)
正规文法可以分为两个类别,右线性文法(right linear grammar)和左线性文法(left linear grammar)
如果所有的生成规则具有如下形式,那么我们称这种文法为右线性文法
A
→
x
B
A
→
x
A \rightarrow xB \\ A \rightarrow x
A→xBA→x
A
,
B
∈
V
,
x
∈
T
A,B∈V,x∈T
A,B∈V,x∈T
左线性文法也就同样的定义为
A
→
B
x
A
→
x
A \rightarrow Bx \\ A \rightarrow x
A→BxA→x
A
,
B
∈
V
,
x
∈
T
A,B∈V,x∈T
A,B∈V,x∈T
上下文无关文法(context free grammar)
上下文无关文法还是由四元组G=(V,T,S,P)组成,含义也一样
生成规则P定义为 A → a A\rightarrow a A→a, a = { V ∪ T } ∗ a=\{V\cup T\}^* a={V∪T}∗且A∈V
举例 G = { ( S , A ) , ( a , b ) , ( S → a A b , A → a A b ∣ ϵ ) } G=\{(S,A),(a,b),(S\rightarrow aAb,A\rightarrow aAb|ϵ)\} G={(S,A),(a,b),(S→aAb,A→aAb∣ϵ)}
上面的|符号两边均可以生成,我们可以尝试看看会生成什么字符串
S
→
a
A
b
→
a
a
A
b
b
→
a
a
a
A
b
b
b
→
a
a
a
b
b
b
=
a
3
b
3
(
最
后
一
步
A
生
成
ϵ
)
S\rightarrow aAb\rightarrow aaAbb\rightarrow aaaAbbb\rightarrow aaabbb=a^3b^3(最后一步A生成ϵ)
S→aAb→aaAbb→aaaAbbb→aaabbb=a3b3(最后一步A生成ϵ)
可以想见该上下文无关文法生成的是形如ab次幂形式的语言,记为 L ( G ) = a n b n L(G)=a^nb^n L(G)=anbn
下推自动机(pushdown automata)
下推自动机(PDA)是一种上下文无关文法的实现方式,类似于有限状态机与正则表达式
- PDA比有限状态机更加强大
- PDA拥有更多的存储空间
- PDA=有限状态机+一个栈(stack)
PDA由三个部分组成
- an input tape(就当成输入字符串)
- 有限控制单元(a finite control unit)
- 无限空间栈(a stack with infinite size)
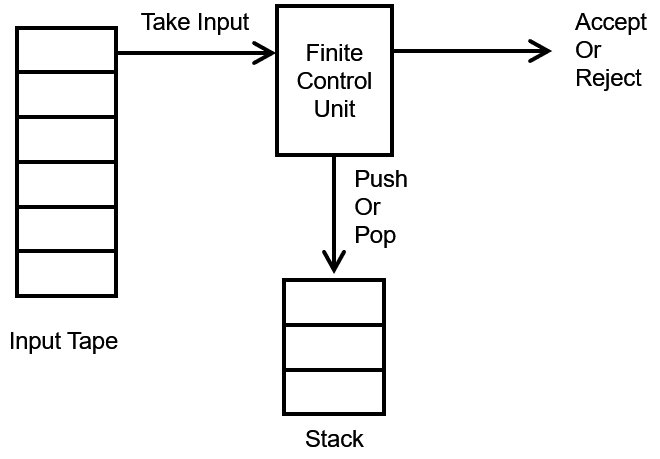
PDA可以表示为一个七元组 ( S , Σ , Γ , δ , s 0 , z 0 , F ) (S,Σ,Γ,δ,s_{0},z_{0},F) (S,Σ,Γ,δ,s0,z0,F)
- S S S是一组状态的集合
- Σ Σ Σ是输入字母表
- Γ Γ Γ栈的字母表
- δ δ δ是转换函数
- s 0 s_{0} s0是初始状态
- z 0 z_{0} z0是初始栈符号
- F F F是终止状态的集合
δ δ δ有三个参数δ(s,a,X)
- s是S中的一个状态
- a是输入字母表中的字符或者是空字符(ε)
- X是栈字母表中的字符
δ δ δ的输出是(p,γ)的集合
- p是新状态
- γ是字符串,用来代替栈顶的元素
如果γ=ε,说明栈是空的
如果γ=X,说明栈没有改变,因为我们输入的栈元素就是X,如果输出还是为X,说明栈没有改变
如果y=YZ,代表X被替换成了Z,并且Y被压入栈中(这个我个人理解就是把一个字符串按照字符从左到右一个个压入栈中,Z代表字符串最后一位,位于栈顶)
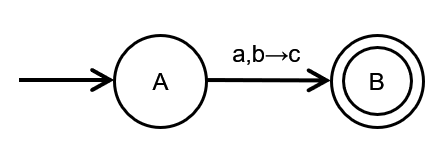
上图就是一个PDA,转换上的三个字符分别为a,b,c,a代表输入数字,可以为空(ε),b代表栈顶中要被pop的字符,当b为空时,代表没有元素会被pop,c代表被push入栈的字符,可以为空,代表没有字符压入栈。相比较于NFA,PDA会在状态转换的过程中处理额外的一个栈。
图灵机(turing machine)
图灵机是一种比下推自动机更为强大的自动机,在上面我们看到下推自动机在状态转换过程中操作一个栈,而图灵机会在状态转换过程中操作一个无限的tape
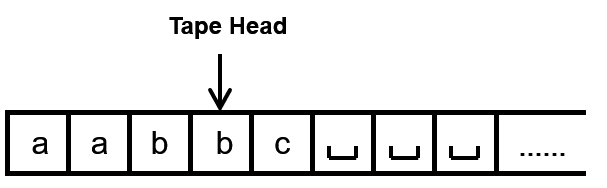
tape里面包含字符,其中后面那个两竖一横的符号是blank的意思,它是一个特殊的字符,用来填满无限的tape
tape head指向当前tape上的字符
tape上的操作
- 可以对tape head指向的字符进行读/扫描操作
- 可以对tape head指向的字符进行写/更新操作
- 将tape head左移一格
- 将tape head右移一格
操作规则:
1、
每一步操作都要执行一下操作
- 读取当前的字符
- 更新当前格子中的字符
- 左移一格或者右移一格
如果当前tape指向最左边的格子,那么执行左移操作将不会发生移动
如果你不想更改当前格的字符,那么执行更新操作的时候只要让它更新为和当前字符一样即可
2、
操作行为类似于有限状态机
有初始状态
终止状态有两种:
- accept state
- reject state
计算结束后状态会变成下列三种中的一种:
- 终止并且接受(accept)
- 终止并且拒绝(reject)
- 循环(loop,就是说没有终止)
Turing Machine可以表示为一个七元组 ( S , Σ , Γ , δ , s 0 , b , F ) (S,Σ,Γ,δ,s_{0},b,F) (S,Σ,Γ,δ,s0,b,F)
- S是一组状态的集合
- Σ Σ Σ是输入字母表
- Γ Γ Γ是tape的字母表
- δ δ δ是转换函数
- s 0 s_{0} s0是初始状态
- b b b是空符号
- F F F是终止状态的集合(accept or reject)
转换函数
δ
δ
δ定义为:
S
×
Σ
→
Γ
×
(
R
/
L
)
×
S
S×Σ\rightarrow Γ×(R/L)×S
S×Σ→Γ×(R/L)×S
这里的(R/L)就是执行左移或者右移操作
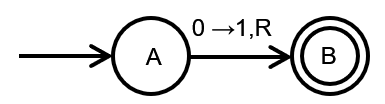
以下面这张图为例,在状态A时接收字符0,那么将会转变为状态B,并且在当前磁头位置写下1这个字符,然后磁头向右移动一格
Turing’s Thesis
1、任何能被数字计算机执行的事情,Turing Machine同样也能够完成(从这里可以看出Turing Machine能力相当强大)
2、如果你能写出一个算法来解决某个问题,那么同样可以写出一个图灵机程序来解决相同的问题
最后,在上面的那张表里面我们知道,图灵机能接受的语言是Recursively Enumerable Language

















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









