






1. 环境介绍
操作系统:Ubuntu 16.04 LTS
编译器:Python 2.7
2. 安装 Beautiful Soup
apt-get install python-bs4 python-bs4-doc
3. 基本测试
import requests
from bs4 import BeautifulSoup
res = requests.get("http://www.nationmaster.com/country-info/stats/Media/Internet-users")
soup = BeautifulSoup(res.content,'lxml')
print soup
获取指定网站页面的html文本数据如下,
4. Table 数据写入 Pandas Dataframe 的功能实现
import requests
from bs4 import BeautifulSoup
import pandas as pd
# get soup
res = requests.get("http://www.nationmaster.com/country-info/stats/Media/Internet-users")
soup = BeautifulSoup(res.content,'lxml')
# get tables
table = soup.find_all('table')[0]
df = pd.read_html(str(table))[0]
# get a record from table
print df["COUNTRY"]
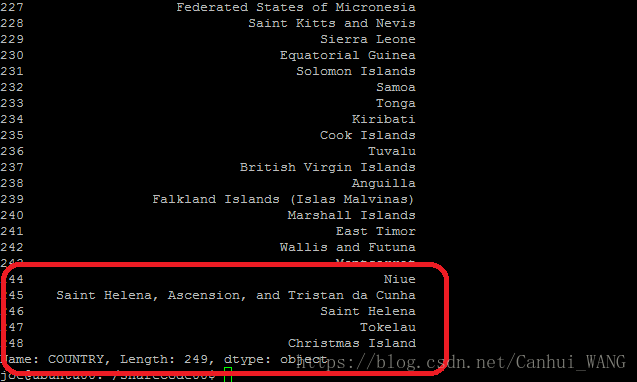
获取DataFrame中"COUNTRY"字段的查询数据如下,
参考文献
[1. 用户手册] http://beautiful-soup-4.readthedocs.io/en/latest/#
[2. 数据网站] http://www.nationmaster.com/country-info/stats/Media/Internet-users

















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









