






Jetson Nano

Jetson Nano系统安装
系统安装参考Jetson nano (4GB B01) 系统安装
基本配置
首先SD卡扩容,一般只有32G及以上的卡才能装上Nano系统,打开disk选择resize将剩下的空间补上。

安装基础依赖
sudo apt install -y make build-essential libssl-dev zlib1g-dev \
libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm \
libncurses5-dev libncursesw5-dev xz-utils tk-dev libffi-dev liblzma-dev python-openssl git输入法
nano没有中文输入法,国内网络搜索会有很大的阻碍,因此安装fcitx-googlepinyin输入法:
sudo apt-get install fcitx fcitx-tools fcitx-config* fcitx-frontend* fcitx-module* fcitx-ui-* presage fcitx-googlepinyin在语言支持language support当中的键盘输入方法系统keyboard input method system当中选择fcitx

然后再输入下列指令重启:
sudo reboot
重启后在右上角键盘设置当中选择配置Fcitx

在输入方法配置选择框当中按左下角加号添加google pinyin后即可

同时在全局配置选项当中可以设置中英切换按键,默认是ctrl加空格

基础软件
Jetson nano相当于一台小电脑,为了方便开发需要一部分好用的软件帮助我们达成目的。
远程桌面
nano开发板其中一个好处在于其便携性,但不可能每次都带一个nano加显示屏幕,安装一款远程桌面可以方便我们控制nano
option1:Todesk
利用todesk可以跨平台控制,只要连接上任意的网络就可以实现远程桌面控制,控制的方便程度和网络传输相关,但同时需要注意的是todesk只支持gnome-desktop的桌面,部分系统如果没有连接显示屏幕那么就不会输出显示画面,导致todesk显示的是黑屏。解决方法通常有修改系统配置或者购买一个显卡欺骗器
我们只需要在Jetson当中打开浏览器搜索todesk然后下载:

选择arm64架构并在下载目录打开终端按照界面内的安装指令输入即可

登录自己的账号,然后在任意其他平台设备上下载todesk便可以远控各种设备了:

option2:nomachine或者VNC
VNC或者nomachine都是利用jetson nano连接的网络的IP来连接控制的,因此需要控制设备和Jetson nano连接在同一个网络下,通过IP访问。
以Nomachine为例:
网络浏览器搜索Nomachine进入官网并选择linux操作平台arm64,网址:NoMachine - NoMachine for Arm

安装后会自动在右上角显示NoMachine Services,它自己会设置一个开机自启服务用于开启NoMachine服务,服务口能够显示IP地址。同样可以在终端输入:
ifconfig会显示如下界面:
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:14:7c:d1:0b txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
ether 48:b0:2d:c1:27:3c txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
device interrupt 151 base 0x7000
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1 (Local Loopback)
RX packets 8548 bytes 664893 (664.8 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8548 bytes 664893 (664.8 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
rndis0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
ether 4a:4c:3a:fd:ea:e9 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
usb0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
ether ##:##:##:##:##:## txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
wlan0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet ###.###.###.### netmask 255.255.255.0 broadcast ###.###.###.###
inet6 fe80::### prefixlen ## scopeid 0x##<link>
ether ##:##:##:c0:5e:e7 txqueuelen 1000 (Ethernet)
RX packets 111615 bytes 40187332 (40.1 MB)
RX errors 0 dropped 1584 overruns 0 frame 0
TX packets 260908 bytes 198071760 (198.0 MB)
TX errors 0 dropped 6 overruns 0 carrier 0 collisions 0根据你的nano连接的网络类型选择,例如你连接的是wifi那么就从wlan0或者wlan1当中找ip,一般wlan当中连接的是inet后的ip地址,如果是usb网络共享或者RJ45网口则可能需要从usb或者eth当中寻找ip,详见:使用 ifconfig 查看本机 ip_终端怎么查看本地ip
通过在其他设备上安装Nomachine连接查看远程桌面,点击Add添加设备,名字任意取,Host当中输入对应的IP地址即可


编程开发
VScode或者VScode-OSS
VScode支持多种编程语言,还可以添加插件,相当好用。因此在nano上面安装VScode可以极大提高开发效率
由于老版本的ubuntu可能不一定支持最新版本的VScode,可以安装旧版本的VScode或者直接安装VScode-OSS
我们前往网址Visual Studio Code September 2023点击Linux:后的deb便可以下载安装包


安装方式(注意jetson应该安装arm版本,由于我在x86-64设备上下载的安装包成了AMD,下载时注意即可,下面的指令当中也要将amd改为arm):
sudo dpkg -i code_1.83.1-1696982868_amd64.deb安装完成后在开始菜单当中搜索code便可以找到VScode,可以将其Pin到左侧菜单栏当中

可以在extension拓展插件,必要插件有Python、C/C++等。

以python为例,在vscode界面右下角点击python可以选择对应版本的python的解释器

文件下载
例如迅雷等软件,直接前往网址【免费】WPS、迅雷等软件的arm64linux版本deb直接安装所有软件包
安装方式:
sudo dpkg -i #对应的安装包名字#工作空间
输入下列指令创建ROS1工作空间
mkdir -p ~/catkin_ws/src
cd ~/catkin_ws/src
catkin_init_workspace
catkin_make
source devel/setup.bash然后可以参考机器人Rviz+matlab仿真详细步骤,从solidworks到urdf以及机器人编程控制,以ER50-C20为例-CSDN博客
正文部分并利用此环境开发机器人仿真以及运动学分析
外接设备
PWM风扇
Jetson nano的功耗还是较大的,为了及时散热需要使用PWM风扇连接主板上的PWM风扇口,然后我们在系统终端输入:
sudo apt install lm-sensors
sudo -H pip3 install -U jetson-stats
sudo sh -c 'echo 100 > /sys/devices/pwm-fan/target_pwm'就可以控制风扇转到到正常转速,同时我们需要让转速和温度正相关,编写下列函数:
import os
import time
def get_cpu_temp():
temp = os.popen("cat /sys/devices/virtual/thermal/thermal_zone0/temp").readline()
return int(temp) / 1000
def set_fan_speed(pwm_value):
pwm_value = max(0, min(255, pwm_value))
os.system(f"sudo sh -c 'echo {pwm_value} > /sys/devices/pwm-fan/target_pwm'")
def adjust_fan_speed():
temp = get_cpu_temp()
if temp < 40:
pwm_value = 0
else:
pwm_value = int((temp - 40) * 6.375)
set_fan_speed(pwm_value)
print(f"Current CPU Temp: {temp}°C, Fan Speed PWM: {pwm_value}")
if __name__ == "__main__":
while True:
adjust_fan_speed()
time.sleep(10) 上述代码可以实现温控PWM风扇,其中get_cpu_temp函数主要用于读取CPU温度并转化为一个数值,并设置一个函数adjust_fan_speed将PWM的0到255和CPU温度数值对应起来,如果温度低于40PWM为0,如果温度大于40则建立线性表达式pwm_value = int((temp - 40) * 6.375),最后将这个对应的PWM数值利用set_fan_speed函数控制风扇转动。
注意有些PWM风扇刚好逻辑是反的,例如此处0是不转,但是有些是255不转,只需要在set_fan_speed函数开头添加一句代码即可:
pwm_value = 255 - pwm_value将上述代码命名为fanctrl.py然后输入下列指令:
crontab -e选择nano或者vim来显示内部代码,然后在最后加入下列指令,其中“/home/jetson/Workspace/Startup/”代表的是你的fanctrl.py所在的路径,注意路径不要输入错误
@reboot python3 /home/jetson/Workspace/Startup/fanctrl.py这样就可以在每次开机的时候自启动该程序实现自动风扇控制。同时我们也可以使用系统自带的服务来实现开机自启,详见:Jetson Nano开机自动启动Python程序
OLED
OLED是许多嵌入式板子都支持的显示模块,有SPI协议和IIC协议两种。此处利用IIC协议的OLED为例显示NANO的部分信息。
首先是准备工作,在终端输入下列指令安装必要的库:
sudo apt-get install python3-tk
sudo apt-get install python3-pip
sudo apt-get install python3-dev
sudo pip3 install psutil smbus requests datetime Jetson.GPIO eyed3 adafruit-circuitpython-ssd1306 board adafruit-blinka adafruit-circuitpython-typing引用对应库并设置显示OLED的分辨率,一般OLED设置有128*64和128*32这两种。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import time
import smbus
import board
import busio
import psutil
import subprocess
from adafruit_ssd1306 import SSD1306_I2C
from datetime import datetime
from PIL import Image, ImageDraw, ImageFont
i2c = busio.I2C(board.SCL, board.SDA)
disp = SSD1306_I2C(128, 32, i2c)
width = disp.width
height = disp.height
image = Image.new("1", (width, height))
draw = ImageDraw.Draw(image)
font = ImageFont.load_default()
padding = -2
top = padding
bottom = height - padding
x = 0设置下列函数用于显示IP、磁盘空间、CPU占用率、网络收发速度(wlan)、CPU温度、时间、内存这7类信息,由于选择的是128*32分辨率因此设置了切换变量display_mode切换显示信息:
def mainrun():
count = 0
start_time = time.time()
display_mode = 0
switch_interval = 10
while True:
draw.rectangle((0, 0, width, height), outline=0, fill=0)
if count % 60 == 0:
cmd = "ifconfig wlan0 | grep 'inet ' | awk '{print $2}'"
wlan0_IP = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
if display_mode == 0:
cpu_usage_percentage = psutil.cpu_percent(1)
CPU_usage = "CPU: {:.2f}%".format(cpu_usage_percentage)
cmd = "free -m | awk 'NR==2{printf \"Mem: %s/%sMB %.0f%%\", $3,$2,$3*100/$2 }'"
MemUsage = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
cmd = "cat /sys/class/thermal/thermal_zone0/temp"
temp = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
CPU_temp = str(round(float(temp) / 1000, 2)) + "°C"
draw.text((x, top + 0), "IP: " + wlan0_IP, font=font, fill=255)
draw.text((x, top + 8), CPU_usage, font=font, fill=255)
draw.text((x, top + 16), MemUsage, font=font, fill=255)
draw.text((x, top + 24), "CPU Temp: " + CPU_temp, font=font, fill=255)
elif display_mode == 1:
cmd = 'df -h | awk \'$NF=="/"{printf "Disk: %d/%d GB %s", $3,$2,$5}\''
Disk = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
cmd = "cat /sys/class/net/wlan0/statistics/rx_bytes"
rx_bytes_before = int(subprocess.check_output(cmd, shell=True).decode("utf-8").strip())
cmd = "cat /sys/class/net/wlan0/statistics/tx_bytes"
tx_bytes_before = int(subprocess.check_output(cmd, shell=True).decode("utf-8").strip())
time.sleep(1)
cmd = "cat /sys/class/net/wlan0/statistics/rx_bytes"
rx_bytes_after = int(subprocess.check_output(cmd, shell=True).decode("utf-8").strip())
cmd = "cat /sys/class/net/wlan0/statistics/tx_bytes"
tx_bytes_after = int(subprocess.check_output(cmd, shell=True).decode("utf-8").strip())
rx_speed = (rx_bytes_after - rx_bytes_before) / 1024 # KB/s
tx_speed = (tx_bytes_after - tx_bytes_before) / 1024 # KB/s
rUNITS = 'KB'
tUNITS = 'KB'
if rx_speed > 1024:
rx_speed = rx_speed / 1024
rUNITS = 'MB'
if tx_speed > 1024:
tx_speed = tx_speed / 1024
tUNITS = 'MB'
NetSpeed = "RT: {:.1f}{} {:.1f}{}".format(rx_speed, rUNITS, tx_speed, tUNITS)
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
draw.text((x, top + 0), "IP: " + wlan0_IP, font=font, fill=255)
draw.text((x, top + 8), Disk, font=font, fill=255)
draw.text((x, top + 16), NetSpeed, font=font, fill=255)
draw.text((x, top + 24), current_time, font=font, fill=255)
disp.image(image)
disp.show()
if time.time() - start_time >= switch_interval:
display_mode = (display_mode + 1) % 2
start_time = time.time()
time.sleep(1)
count += 1同样将上述代码命名为ssd1306startup.py同样输入下列指令用于开机自启
@reboot python3 /home/jetson/Workspace/Startup/ssd1306startup.py如果出现AttributeError: module 'board' has no attribute 'SCL'解决方案是前往board.py 将python3安装目录下的board.py替换为该网址下的board.py,然后根据接下来的报错将报错的py文件内部的地址大小写修改一下。
PCF8581T (content update_V1.1)
通过下列指令检查i2c地址:
sudo i2cdetect -y 1该设备i2c地址为0x48 总共四个通道,每个通道单独检测一路模拟信号
编写代码如下:
#!/usr/bin/env python
import smbus
import time
bus = smbus.SMBus(1)
def setup(Addr):
global address
address = Addr
def read(chn): #channel
if chn == 0:
bus.write_byte(address,0x40)
if chn == 1:
bus.write_byte(address,0x41)
if chn == 2:
bus.write_byte(address,0x42)
if chn == 3:
bus.write_byte(address,0x43)
bus.read_byte(address)
return bus.read_byte(address)
def write(val):
temp = val
temp = int(temp)
# print temp to see on terminal else comment out
bus.write_byte_data(address, 0x40, temp)
if __name__ == "__main__":
setup(0x48)
while True:
print('光敏电阻 AIN0 = ', read(0)) #光敏模拟信号转化的数字值
print('磁敏电阻 AIN1 = ', read(1)) #磁敏电阻模拟信号转化的数字
print('热敏电阻 AIN2 = ', read(2)) #热敏电阻模拟信号转化的数字值
print('没有电阻 AIN3 = ', read(3)) #--用sudo和python运行程序(2.7.0)即可
外接拓展组合
拓展板原理图
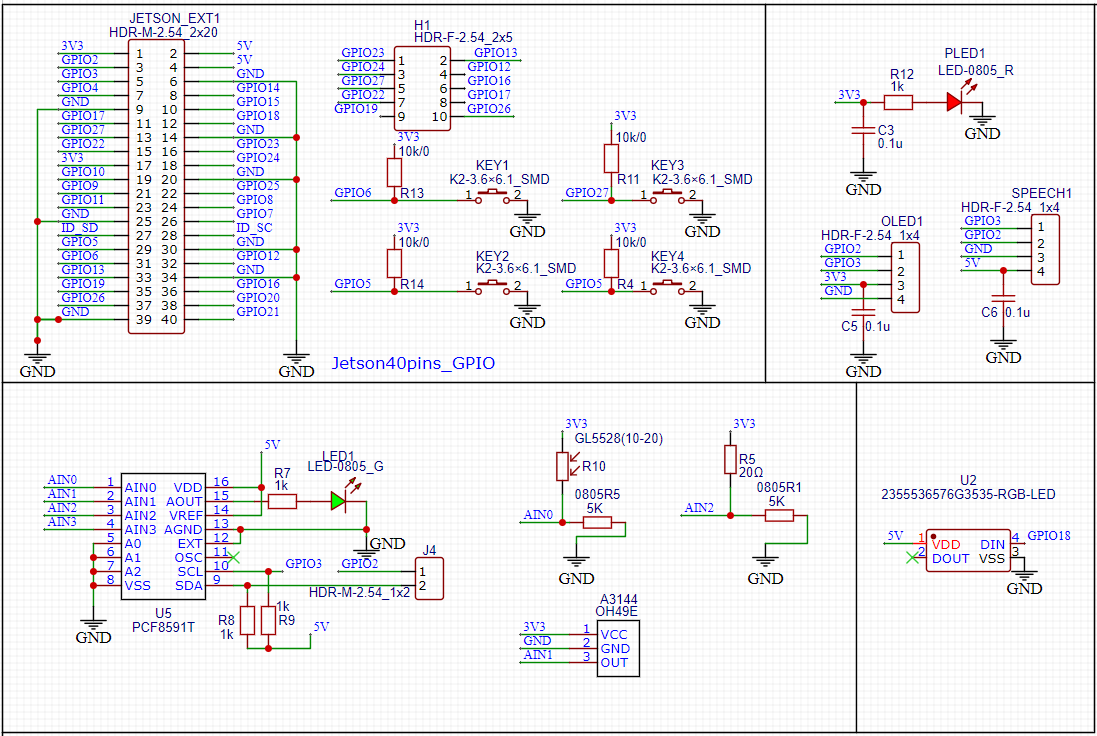
包含GPIO口、四路按键、H1代表闲置的GPIO口、PLED电源指示灯、I2Coled接口和其余I2C设备槽口、PCF8591T连接光敏电阻,热敏电阻,磁感芯片A3144、RGB灯
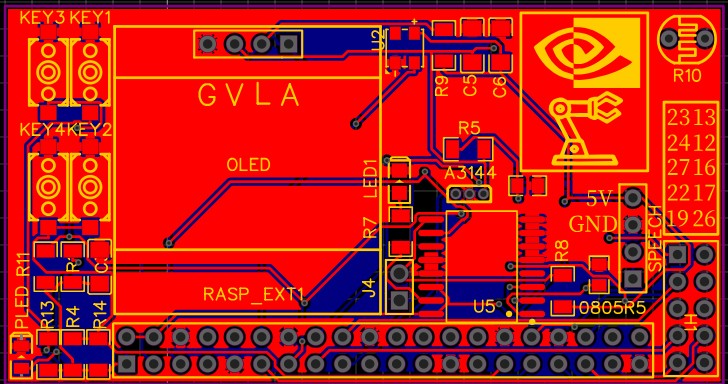
PCB图
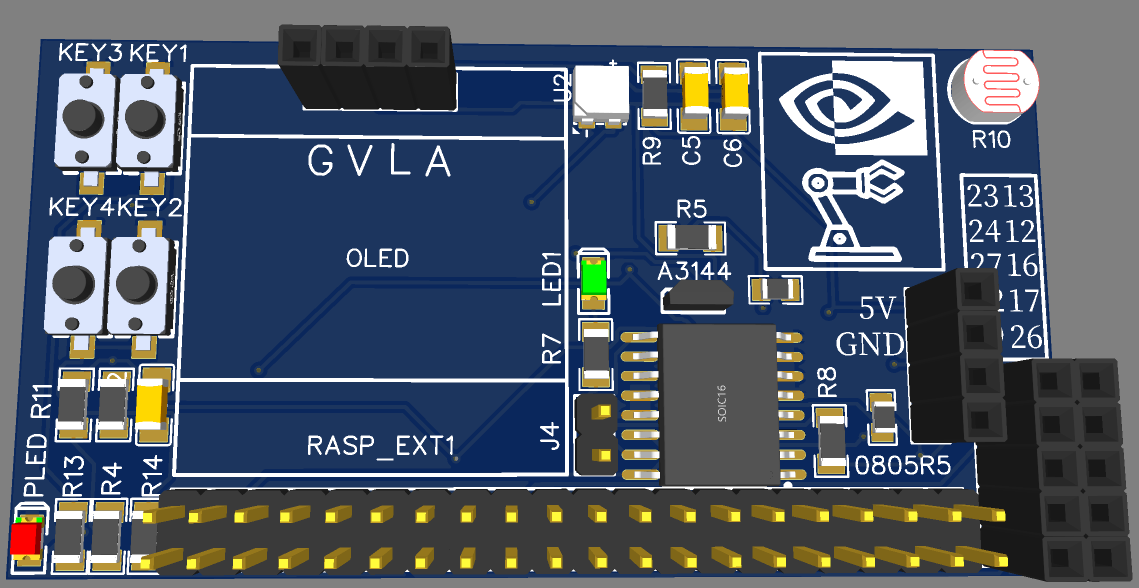
理论3D模型
代码
下列代码作为I2C oled64高度显示屏以及PWM风扇、PCF8591设备、网卡设备合并的自启动项目代码:
ssd1306_display_v3.py:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import time
import smbus
import board
import busio
import psutil
import subprocess
import adafruit_ssd1306
import Jetson.GPIO as GPIO
from datetime import datetime
from PIL import Image, ImageDraw, ImageFont
try:
# Create the I2C interface
i2c = busio.I2C(board.SCL, board.SDA)
# Create the SSD1306 OLED class.
disp = adafruit_ssd1306.SSD1306_I2C(128, 64, i2c)
# Create blank image for drawing.
# Make sure to create image with mode '1' for 1-bit color.
width = disp.width
height = disp.height
image = Image.new("1", (width, height))
# Get drawing object to draw on image.
draw = ImageDraw.Draw(image)
# Draw a black filled box to clear the image.
draw.rectangle((0, 0, width, height), outline=0, fill=0)
# Load default font.
font = ImageFont.load_default()
# Define some constants to allow easy resizing of shapes.
padding = -2
top = padding
bottom = height - padding
x = 0
count = 0
ts = 0.01
bus = smbus.SMBus(1)
font = ImageFont.load_default()
font1 = ImageFont.truetype("/usr/share/fonts/truetype/dejavu/DejaVuSans.ttf", 16)
font2 = ImageFont.truetype("/usr/share/fonts/truetype/dejavu/DejaVuSans.ttf", 24)
font3 = ImageFont.truetype("/usr/share/fonts/truetype/dejavu/DejaVuSansMono-Bold.ttf", 12)
draw.text((x, top + 0), " JETSON NANO", font=font1, fill=255)
ypos = 52
draw.text((x - 2, top + ypos + 1), ".", font=font, fill=255)
draw.text((x - 2, top + ypos + 2), ".", font=font, fill=255)
draw.text((x - 2, top + ypos + 3), ".", font=font, fill=255)
draw.text((x - 2, top + ypos + 4), ".", font=font, fill=255)
draw.text((x - 2, top + ypos + 5), ".", font=font, fill=255)
draw.text((x + 126, top + ypos + 1), ".", font=font, fill=255)
draw.text((x + 126, top + ypos + 2), ".", font=font, fill=255)
draw.text((x + 126, top + ypos + 3), ".", font=font, fill=255)
draw.text((x + 126, top + ypos + 4), ".", font=font, fill=255)
draw.text((x + 126, top + ypos + 5), ".", font=font, fill=255)
draw.text((x + 0, top + 16), "Warning:Dont close it", font=font, fill=255)
draw.text((x + 0, top + 24), " by pressing button", font=font, fill=255)
draw.text((x + 0, top + 40), " User: CapRogers", font=font, fill=255)
draw.text((x + 14, top + 48), " System booting...", font=font, fill=255)
for i in range(-1,129):
draw.text((x + i, top + ypos), ".", font=font, fill=255)
draw.text((x + i, top + ypos + 5), ".", font=font, fill=255)
for i in range(0,128):
draw.text((x + i, top + ypos + 2), ".", font=font, fill=255)
draw.text((x + i, top + ypos + 3), ".", font=font, fill=255)
disp.image(image)
disp.show()
time.sleep(0.05)
time.sleep(0.5)
disp.fill(0)
disp.show()
except:
pass
def get_wifi_ssid():
try:
result = subprocess.check_output(['nmcli', '-t', '-f', 'ACTIVE,SSID', 'dev', 'wifi'], encoding='utf-8')
for line in result.splitlines():
active, ssid = line.split(':')
if active == 'yes':
return ssid
return "No Singal"
except subprocess.CalledProcessError as e:
return f"ERROR: {e}"
except Exception as e:
return f"ERROR: {e}"
def setup(Addr):
global address
address = Addr
def read(chn):
if chn == 0:
bus.write_byte(address,0x40)
if chn == 1:
bus.write_byte(address,0x41)
if chn == 2:
bus.write_byte(address,0x42)
if chn == 3:
bus.write_byte(address,0x43)
bus.read_byte(address)
return bus.read_byte(address)
def write(val):
temp = val
temp = int(temp)
bus.write_byte_data(address, 0x40, temp)
def calculate_pwm(temp,topt,belowt):
# stop fan when below below_t°C
if temp < belowt:
return 255
# full speed when reach top_t°C
elif temp > topt:
return 0
# linarly adjust PWM value
else:
return int(255 - (temp - 30) * (255 / (topt - belowt)))
def fanctl(temp):
pwm_value = calculate_pwm(temp,70,30)#you can turn up topt value if it is too nosiy
os.system(f"sudo sh -c 'echo {pwm_value} > /sys/devices/pwm-fan/target_pwm'")
def get_cpu_usage():
# Read the CPU statistics file
with open('/proc/stat', 'r') as f:
lines = f.readlines()
# Extract the first line (overall CPU usage)
cpu_line = lines[0].split()
# Get the time spent on different CPU states
user_time = int(cpu_line[1])
nice_time = int(cpu_line[2])
system_time = int(cpu_line[3])
idle_time = int(cpu_line[4])
iowait_time = int(cpu_line[5])
irq_time = int(cpu_line[6])
softirq_time = int(cpu_line[7])
steal_time = int(cpu_line[8])
# Calculate total and idle time
total_time = user_time + nice_time + system_time + idle_time + iowait_time + irq_time + softirq_time + steal_time
idle_all_time = idle_time + iowait_time
# Return total and idle time
return total_time, idle_all_time
def main_show():
setup(0x48)
# os.system("clear")
count = 0
count1 = 0
ct1 = 0
ct2 = 0
cnt3 = 0
low_readings_count = 0
press_detected = False
press_end_time = 0
ssid_n = get_wifi_ssid()
while True:
# current_value = read(0)
current_value = 100
# print(str(read(0)))
if current_value < 40:
low_readings_count += 1
else:
low_readings_count = 0
if low_readings_count >= 6 and not press_detected:
draw.rectangle((0, 0, width, height), outline=0, fill=0)
draw.text((0, 0), "Light Button Pressed", font=font, fill=255)
draw.text((0, 10), "press 3 more seconds", font=font, fill=255)
disp.image(image)
disp.show()
'''while True:
current_value = read(0)
time.sleep(0.01)
count1 = count1 + 1
if current_value > 40:
break
if count1 > 300:
draw.rectangle((0, 0, width, height), outline=0, fill=0)
draw.text((0, 0), "Pls Dont keep pressing", font=font, fill=255)
disp.image(image)
disp.show()
count1 = 0
while True:
current_value = read(0)
time.sleep(0.01)
count1 = count1 + 1
if current_value < 40:
ct1 = ct1 + 1
if current_value > 40:
ct2 = ct2 + 1
if count1 > 500:
break
if ct2 > 300:
os.system("sudo poweroff")
count1 = 0
ct1 = 0
ct2 = 0'''
# Draw a black filled box to clear the image.
draw.rectangle((0, 0, width, height), outline=0, fill=0)
if (count==0 or count%60==0):
# Get wlan0 IP address
cmd = "ifconfig wlan0 | grep 'inet ' | awk '{print $2}'"
wlan0_IP = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
# Get CPU load
cmd = 'cut -f 1 -d " " /proc/loadavg'
CPU = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
if (count==0 or count%3==0):
# Get memory usage
cmd = "free -m | awk 'NR==2{printf \"Mem: %s/%sMB %.0f%%\", $3,$2,$3*100/$2 }'"
MemUsage = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
if (count==0 or count%180==0):
# Get disk usage
cmd = 'df -h | awk \'$NF=="/"{printf "Disk: %d/%d GB %s", $3,$2,$5}\''
Disk = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
# Get CPU temperature
cmd = "cat /sys/class/thermal/thermal_zone0/temp"
temp = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
CPU_temp = str(round(float(temp) / 1000, 2)) + "°C"
cpu_usage_percentage = psutil.cpu_percent(1)
# print(cpu_usage_percentage)
if cpu_usage_percentage > 60:
# write(215+int(cpu_usage_percentage))
write(255)
else:
write(0)
# Format CPU usage percentage
CPU_usage = "CPU: {:.2f}%".format(cpu_usage_percentage)
# Get network speed
cmd = "cat /sys/class/net/wlan0/statistics/rx_bytes"
rx_bytes_before = int(subprocess.check_output(cmd, shell=True).decode("utf-8").strip())
cmd = "cat /sys/class/net/wlan0/statistics/tx_bytes"
tx_bytes_before = int(subprocess.check_output(cmd, shell=True).decode("utf-8").strip())
time.sleep(ts)
cmd = "cat /sys/class/net/wlan0/statistics/rx_bytes"
rx_bytes_after = int(subprocess.check_output(cmd, shell=True).decode("utf-8").strip())
cmd = "cat /sys/class/net/wlan0/statistics/tx_bytes"
tx_bytes_after = int(subprocess.check_output(cmd, shell=True).decode("utf-8").strip())
rx_speed = (rx_bytes_after - rx_bytes_before) / 1024 / ts # KB/s
tx_speed = (tx_bytes_after - tx_bytes_before) / 1024 / ts # KB/s
rUNITS = 'KB'
tUNITS = 'KB'
if rx_speed > 1024:
rx_speed = rx_speed / 1024
rUNITS = 'MB'
if tx_speed > 1024:
tx_speed = tx_speed / 1024
tUNITS = 'MB'
NetSpeed = "RT: {:.1f}{} {:.1f}{}".format(rx_speed, rUNITS, tx_speed, tUNITS)
# Get current time
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# Write lines of text.
draw.text((x, top + 0), "IP: " + wlan0_IP, font=font, fill=255)
# draw.text((x, top + 8), CPU_usage + " (" + str(low_readings_count) + ")", font=font, fill=255)
draw.text((x, top + 8), CPU_usage + " " + str(ssid_n), font=font, fill=255)
draw.text((x, top + 16), MemUsage, font=font, fill=255)
draw.text((x, top + 25), Disk, font=font, fill=255)
draw.text((x, top + 34), "CPU Temp: " + CPU_temp, font=font, fill=255)
draw.text((x, top + 43), NetSpeed, font=font, fill=255)
draw.text((x, top + 52), current_time, font=font, fill=255)
fanctl(int(temp) / 1000)
# subprocess.Popen(['python3', 'GPIO_CTRL.py'])
# Display image.
count = count + 1
cnt3 = cnt3 + 1
if cnt3 == 100:
ssid_n = get_wifi_ssid()
cnt3 = 0
disp.image(image)
disp.show()
def main_show_backup():
count = 0
while True:
# Draw a black filled box to clear the image.
draw.rectangle((0, 0, width, height), outline=0, fill=0)
if (count==0 or count%60==0):
# Get wlan0 IP address
cmd = "ifconfig wlan0 | grep 'inet ' | awk '{print $2}'"
wlan0_IP = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
# Get CPU load
cmd = 'cut -f 1 -d " " /proc/loadavg'
CPU = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
if (count==0 or count%3==0):
# Get memory usage
cmd = "free -m | awk 'NR==2{printf \"Mem: %s/%sMB %.0f%%\", $3,$2,$3*100/$2 }'"
MemUsage = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
if (count==0 or count%180==0):
# Get disk usage
cmd = 'df -h | awk \'$NF=="/"{printf "Disk: %d/%d GB %s", $3,$2,$5}\''
Disk = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
# Get CPU temperature
cmd = "cat /sys/class/thermal/thermal_zone0/temp"
temp = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
CPU_temp = str(round(float(temp) / 1000, 2)) + "°C"
cpu_usage_percentage = psutil.cpu_percent(1)
# print(cpu_usage_percentage)
# Format CPU usage percentage
CPU_usage = "CPU: {:.2f}%".format(cpu_usage_percentage)
# Get network speed
cmd = "cat /sys/class/net/wlan0/statistics/rx_bytes"
rx_bytes_before = int(subprocess.check_output(cmd, shell=True).decode("utf-8").strip())
cmd = "cat /sys/class/net/wlan0/statistics/tx_bytes"
tx_bytes_before = int(subprocess.check_output(cmd, shell=True).decode("utf-8").strip())
time.sleep(ts)
cmd = "cat /sys/class/net/wlan0/statistics/rx_bytes"
rx_bytes_after = int(subprocess.check_output(cmd, shell=True).decode("utf-8").strip())
cmd = "cat /sys/class/net/wlan0/statistics/tx_bytes"
tx_bytes_after = int(subprocess.check_output(cmd, shell=True).decode("utf-8").strip())
rx_speed = (rx_bytes_after - rx_bytes_before) / 1024 / ts # KB/s
tx_speed = (tx_bytes_after - tx_bytes_before) / 1024 / ts # KB/s
rUNITS = 'KB'
tUNITS = 'KB'
if rx_speed > 1024:
rx_speed = rx_speed / 1024
rUNITS = 'MB'
if tx_speed > 1024:
tx_speed = tx_speed / 1024
tUNITS = 'MB'
NetSpeed = "RT: {:.1f}{} {:.1f}{}".format(rx_speed, rUNITS, tx_speed, tUNITS)
# Get current time
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# Write lines of text.
draw.text((x, top + 0), "IP: " + wlan0_IP, font=font, fill=255)
draw.text((x, top + 8), CPU_usage + " (" + str(low_readings_count) + ")", font=font, fill=255)
draw.text((x, top + 16), MemUsage, font=font, fill=255)
draw.text((x, top + 25), Disk, font=font, fill=255)
draw.text((x, top + 34), "CPU Temp: " + CPU_temp, font=font, fill=255)
draw.text((x, top + 43), NetSpeed, font=font, fill=255)
draw.text((x, top + 52), current_time, font=font, fill=255)
fanctl(int(temp) / 1000)
# subprocess.Popen(['python3', 'GPIO_CTRL.py'])
# Display image.
count = count + 1
disp.image(image)
disp.show()
def backup_fan_ctrl():
# Get CPU temperature
while True:
cmd = "cat /sys/class/thermal/thermal_zone0/temp"
temp = subprocess.check_output(cmd, shell=True).decode("utf-8").strip()
fanctl(int(temp) / 1000)
time.sleep(1)
if __name__ == "__main__":
os.system("clear")
try:
os.system("python /home/jetson/Workspace/cleargg.py")
except:
pass
print("===============================================================")
print("| /$$$$$ /$$$$$$$$ /$$$$$$$$ /$$$$$$ /$$$$$$ /$$ /$$ |")
print("| |__ $$| $$_____/|__ $$__//$$__ $$ /$$__ $$| $$$ | $$ |")
print("| | $$| $$ | $$ | $$ \__/| $$ \ $$| $$$$| $$ |")
print("| | $$| $$$$$ | $$ | $$$$$$ | $$ | $$| $$ $$ $$ |")
print("| /$$ | $$| $$__/ | $$ \____ $$| $$ | $$| $$ $$$$ |")
print("| | $$ | $$| $$ | $$ /$$ \ $$| $$ | $$| $$\ $$$ |")
print("| | $$$$$$/| $$$$$$$$ | $$ | $$$$$$/| $$$$$$/| $$ \ $$ |")
print("| \______/ |________/ |__/ \______/ \______/ |__/ \__/ |")
print("===============================================================")
print("")
print("Jetson startup programe")
try:
main_show()
except:
try:
print("Device PCF8581 not available!")
main_show_backup()
except:
print("Device SSD1306 not available!")
print("Device PCF8581 not available!")
backup_fan_ctrl()
代码分为启动部分,模块部分和SSD1306显示部分
启动部分:也即从import开始到try结尾部分,主要功能是导入必要模块然后引入i2c设备、字体、给oled显示启动进度条
模块部分:包含多个被调用的功能模块,例如get_wifi_ssid()函数用于读取wifi名称,setup(Addr)函数用于pcf8591t初始化,read(chn)函数用于读取模拟信号,write(val)函数用于输出模拟信号,calculate_pwm(temp,topt,belowt)和fanctl(temp)共同用于控制PWM风扇,get_cpu_usage()函数检测CPU占有率
SSD1306显示部分:主要代表main_show_backup()和main_show()函数,为了确保程序可以有无oled以外的外接都能运行,设置了备用函数,能够显示IP等信息
注意:程序运行后会占用GPIO资源,同时按键硬件还未配置,还可以设置按键触发指令
编程开发
此案例当中的系统:ubuntu18.04
python3.6
ubuntu18.04自带的python3版本是3.6,用python3.6两个案例开发
face_recognition
face_recognition是一个基于Python的人脸识别库,它使用dlib顶尖的深度学习人脸识别技术构建。这个库不仅提供了丰富的API接口,还封装了许多复杂的操作,能够更加简单快捷地进行人脸识别相关的工作。
安装face_recognition
pip3 install boost cmake build
pip3 install dlib
pip3 install face_recognition在./datasets/known文件夹放置一张人脸图片命名为starlight.jpg,如果还需要在添加人脸则继续添加但是每一张人脸图片要对应名字,
放置完成后编写下列代码可以让face_recognition读取文件夹下的starlight图片并利用库中用于生成图像中人脸的128维特征向量的函数返回一个人脸特征向量。这些特征向量可以被用于面部识别或比较两个面部是否相似
starlight_image = face_recognition.load_image_file("datasets/known/starlight.jpg")
starlight_face_encoding = face_recognition.face_encodings(starlight_image)[0]利用opencv读取摄像头并将摄像头读取的每一帧图片人脸特征向量数据和库比对,如果对应上其中的某个特征向量则返回对应名字,否则返回未知:
face_locations = face_recognition.face_locations(frame)
face_encodings = face_recognition.face_encodings(frame, face_locations)
for (top, right, bottom, left), face_encoding in zip(face_locations, face_encodings):
# Matching faces
matches_starlight = face_recognition.compare_faces([starlight_face_encoding], face_encoding)
matches_alice = face_recognition.compare_faces([alice_face_encoding], face_encoding)
name = "unknown"
if True in matches_starlight:
name = "starlight"
elif True in matches_alice:
name = "XW"总体代码如下:
import face_recognition
import cv2
import tkinter as tk
from PIL import Image, ImageTk
print("Loading faces data")
try:
starlight_image = face_recognition.load_image_file("datasets/known/starlight.jpg")
starlight_face_encoding = face_recognition.face_encodings(starlight_image)[0]
alice_image = face_recognition.load_image_file("datasets/known/XW.jpg")
alice_face_encoding = face_recognition.face_encodings(alice_image)[0]
except:
rootpath = "/home/jetson/Workspace/Py36Script/FaceRecognition-master/"
starlight_image = face_recognition.load_image_file(rootpath + "datasets/known/starlight.jpg")
starlight_face_encoding = face_recognition.face_encodings(starlight_image)[0]
alice_image = face_recognition.load_image_file(rootpath + "datasets/known/XW.jpg")
alice_face_encoding = face_recognition.face_encodings(alice_image)[0]
print("Warming Camera")
root = tk.Tk()
root.title("Cam")
lmain = tk.Label(root)
lmain.pack()
cap = cv2.VideoCapture(0)
def show_frame():
_, frame = cap.read()
frame = cv2.resize(frame,(280,320))
# Searching faces
face_locations = face_recognition.face_locations(frame)
face_encodings = face_recognition.face_encodings(frame, face_locations)
for (top, right, bottom, left), face_encoding in zip(face_locations, face_encodings):
# Matching faces
matches_starlight = face_recognition.compare_faces([starlight_face_encoding], face_encoding)
matches_alice = face_recognition.compare_faces([alice_face_encoding], face_encoding)
name = "unknown"
if True in matches_starlight:
name = "starlight"
elif True in matches_alice:
name = "Zhao"
# Show name
cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 0), 2)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6, bottom - 6), font, 0.5, (0, 255, 0), 2)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = Image.fromarray(frame)
imgtk = ImageTk.PhotoImage(image=img)
lmain.imgtk = imgtk
lmain.configure(image=imgtk)
lmain.after(200, show_frame)
show_frame()
root.mainloop()结果图如下:例如本案例导入了星光starlight的人脸图片然后将摄像头对准星光的其他图片便可以识别,而其余人脸图片输出unknown


mediapipe
MediaPipe 是由 Google 开发的一个开源跨平台框架,旨在实现高效、实时的机器学习和计算机视觉管道。MediaPipe 提供了一系列的预构建模型和工具,支持开发者在设备端进行实时的视频和图像处理,适用于多个平台,包括 Android、iOS、Web 和桌面系统。MediaPipe 的高性能和跨平台特性使其在手势识别、姿态估计、面部表情识别、物体检测等任务中得到了广泛应用。
以下编写一个简单案列实现用mediapipe检测人体姿态:
首先安装mediapipe:
pip3 install mediapipe编写代码:
利用 mp_pose.Pose() 初始化姿态检测模型,设置最小置信度为 0.5即至少有 50% 的置信度,才认为检测到有效姿态),pose.process() 处理输入的 RGB 图像并检测姿态,返回的 results 包含检测到的姿态关键点数据。如果成功检测到姿态,results.pose_landmarks 会包含这些关键点的位置,否则返回无姿态检测文本信息
with mp_pose.Pose(static_image_mode=True, min_detection_confidence=0.5) as pose:
results = pose.process(image_rgb)
if results.pose_landmarks:
print("Detected pose landmarks.")
mp_drawing.draw_landmarks(
image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
mp_drawing.DrawingSpec(color=(0, 255, 0), thickness=2, circle_radius=2),
mp_drawing.DrawingSpec(color=(0, 0, 255), thickness=2, circle_radius=2)
)
else:
print("No pose detected.")总体代码如下:
import cv2
import mediapipe as mp
mp_pose = mp.solutions.pose
mp_drawing = mp.solutions.drawing_utils
image_path = "input_image.png"
image = cv2.imread(image_path)
cv2.imshow("original",image)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
with mp_pose.Pose(static_image_mode=True, min_detection_confidence=0.5) as pose:
results = pose.process(image_rgb)
if results.pose_landmarks:
print("Detected pose landmarks.")
mp_drawing.draw_landmarks(
image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
mp_drawing.DrawingSpec(color=(0, 255, 0), thickness=2, circle_radius=2),
mp_drawing.DrawingSpec(color=(0, 0, 255), thickness=2, circle_radius=2)
)
else:
print("No pose detected.")
cv2.imshow("Pose Detection", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
显示结果如下:

python3.10
下列工程直接利用python3.6会存在版本不支持的问题,安装python3.10可以参考机器人Rviz+matlab仿真详细步骤,从solidworks到urdf以及机器人编程控制,以ER50-C20为例-CSDN博客利用三个案列显示python可以完成的编程开发任务
ultralytics
YOLOv8 是由 Ultralytics 开发的最新一代 YOLO(You Only Look Once)目标检测模型,它延续了 YOLO 系列在计算机视觉任务中的高效表现,并在准确性和推理速度上进行了进一步改进。YOLOv8 可以用于多种视觉任务,包括目标检测、实例分割和图像分类。它是 YOLO 家族的最新版本,结合了前代 YOLOv5、YOLOv6、YOLOv7 的优势,并引入了新的特性和改进。
安装ultralytics
~/python3.10/bin/python3.10 -m pip install ultralytics注意上述指令会默认安装最新版本的ultralytics以及最新版本的torch和torchvision,根据nano的cuda版本自行提前安装对应版本的CPU或者GPU版本的torch以及torchvision、torchaudio,如果接下来运行出现类似于“core dumped”的报错基本是安装的torch或者numpy等库版本不兼容导致的。
假设已经安装完成,如果出现:“AttributeError: module 'collections' has no attribute ###”那么就卸载重装:
~/python3.10/bin/python3.10 -m pip uninstall ultralytics -y
~/python3.10/bin/python3.10 -m pip install ultralytics同时也可以安装指定版本的ultralytics,如果不兼容可以适当降低版本。
编写核心部分代码:
import cv2
from ultralytics import YOLO
model = YOLO(model="./weights/detect/yolov8n.pt")
def process_frame(self, frame):
res = model(frame)
annotated_img = res[0].plot()
results_frames = cv2.cvtColor(annotated_img, cv2.COLOR_BGR2RGB)
return results_frames其中从模型库当中导入yolov8n.PT,模型可以从huggingface或者github下载:Ultralytics/YOLOv8 at main (huggingface.co)![]() https://huggingface.co/Ultralytics/YOLOv8/tree/main
https://huggingface.co/Ultralytics/YOLOv8/tree/main
Releases · ultralytics/assets (github.com)![]() https://github.com/ultralytics/assets/releasesprocess_frame函数使用加载的YOLO模型对输入的
https://github.com/ultralytics/assets/releasesprocess_frame函数使用加载的YOLO模型对输入的frame进行推理。model(frame)调用会返回检测结果,这些结果通常包括检测到的目标的位置(边界框)、类别和置信度等信息。这里的res变量接收了这些结果。
利用TK界面显示每一帧处理后的图像并显示,总体代码如下:
import cv2
from tkinter import *
from PIL import Image, ImageTk
from ultralytics import YOLO
model = YOLO(model="./weights/detect/yolov8n.pt")
#model = YOLO(model="./custom_PT/detect/trees.pt")
class App:
def __init__(self, window, window_title, video_source):
self.window = window
self.window.title(window_title)
self.video_source = video_source
self.vid = cv2.VideoCapture(video_source)
if not self.vid.isOpened():
raise ValueError("Unable to open video source", video_source)
self.width = self.vid.get(cv2.CAP_PROP_FRAME_WIDTH)
self.height = self.vid.get(cv2.CAP_PROP_FRAME_HEIGHT)
self.canvas = Canvas(window, width=self.vid.get(cv2.CAP_PROP_FRAME_WIDTH), height=self.vid.get(cv2.CAP_PROP_FRAME_HEIGHT))
#self.canvas = Canvas(window, width=self.width, height=self.height)
self.canvas.pack()
self.delay = 1
self.update()
self.window.mainloop()
def update(self):
ret, frame = self.vid.read()
if ret:
processed_frame = self.process_frame(frame)
self.photo = ImageTk.PhotoImage(image=Image.fromarray(processed_frame))
self.canvas.create_image(0, 0, image=self.photo, anchor=NW)
self.window.after(self.delay, self.update)
def process_frame(self, frame):
res = model(frame)
annotated_img = res[0].plot()
results_frames = cv2.cvtColor(annotated_img, cv2.COLOR_BGR2RGB)
return results_frames
def __del__(self):
if self.vid.isOpened():
self.vid.release()
App(Tk(), "Tkinter and OpenCV", video_source=0)结果如下:

yolov8还支持归类、姿态检测、人脸检测、语义分割等图像处理,只需要下载对应的模型文件即可。
Speech-recognition
SpeechRecognition 是 Python 生态系统中的一个流行库,旨在帮助开发者通过编程处理语音识别任务。它支持多种语音识别引擎和 API,允许从音频文件或实时麦克风音频中识别语音并将其转换为文本。SpeechRecognition 库非常易用,适用于各种语音识别任务,如语音命令控制、自动字幕生成等。
安装:
~/python3.10/bin/python3.10 -m pip install speechrecognition利用下列代码创建TK GUI界面选择翻译语言然后将wav文件当中的语音转化为对应语言的文字
import tkinter as tk
from tkinter import filedialog, ttk, messagebox
import speech_recognition as sr
import os
def open_results_folder():
current_file_directory = os.path.dirname(os.path.abspath(__file__))
try:
abspath = current_file_directory + "\\results"
os.system(f"xdg-open '{abspath}'")
except Exception as e:
messagebox.showerror("Error", f"Could not open folder: {e}")
def show_help():
help_window = tk.Toplevel(app)
help_window.title("Help")
help_window.geometry("300x150")
help_text = tk.Text(help_window, height=8, width=40, bg="white", fg="black")
help_text.pack()
help_message = "Here is how to use this application:\n1. Select a WAV file.\n2. Choose a language.\n3. Click 'Convert to Text'.\n4. View the results or open the results folder."
help_text.insert(tk.END, help_message)
def on_right_click(event):
try:
popup_menu.tk_popup(event.x_root, event.y_root)
finally:
popup_menu.grab_release()
def convert_to_text():
try:
language = lang_var.get()
audio_file = file_var.get()
r = sr.Recognizer()
with sr.AudioFile(audio_file) as source:
audio = r.record(source)
text = r.recognize_sphinx(audio, language=language)
text_box.delete("1.0", tk.END)
text_box.insert(tk.END, text)
with open(f'./results/{os.path.basename(audio_file).replace(".wav", ".txt")}', 'w') as f:
f.write(text)
except Exception as e:
messagebox.showerror("Error", f"Could not convert audio: {e}")
def select_file():
filename = filedialog.askopenfilename(initialdir='./datasets', title="Select a file", filetypes=[("WAV files", "*.wav")])
file_var.set(filename)
app = tk.Tk()
app.title("STT_v1")
app.geometry("305x400")
#app.iconbitmap('speech2txt.ico')
app.configure(background="white")
file_var = tk.StringVar()
lang_var = tk.StringVar()
lang_var.set('zh-CN')
style = ttk.Style()
style.configure("TButton", background="white", foreground="black")
open_file_btn = ttk.Button(app, text="Select WAV File", command=select_file)
open_file_btn.grid(row=0, column=0, padx=10, pady=10, sticky="ew")
language_options = ['zh-CN', 'en-US', 'fr-FR', 'ru-RU', 'de-DE']
lang_menu = ttk.Combobox(app, textvariable=lang_var, values=language_options)
lang_menu.grid(row=1, column=0, padx=10, pady=10, sticky="ew")
confirm_btn = ttk.Button(app, text="Convert to Text", command=convert_to_text)
confirm_btn.grid(row=2, column=0, padx=10, pady=10, sticky="ew")
open_results_btn = ttk.Button(app, text="Open Results Folder", command=open_results_folder)
open_results_btn.grid(row=3, column=0, padx=10, pady=10, sticky="ew")
text_box = tk.Text(app, height=15, width=40, bg="white", fg="black")
text_box.grid(row=4, column=0, padx=10, pady=10, sticky="ew")
popup_menu = tk.Menu(app, tearoff=0)
popup_menu.add_command(label="Help", command=show_help)
app.bind("<Button-3>", on_right_click)
app.mainloop()由于默认识别的是英文,因此需要下载模型到pocketsphinx的模型文件当中下载其他语言模型,下载网址CMU Sphinx - Browse /Acoustic and Language Models at SourceForge.net

Depth-anything
Depth-Anything 是一个用于深度估计的开源项目,旨在从单张图像中推断出场景的深度信息。深度估计可以应用于诸如自动驾驶、增强现实(AR)、机器人视觉等领域,帮助系统理解场景中的距离和空间结构。
从github当中克隆该项目
git clone https://github.com/LiheYoung/Depth-Anything.git在下载的项目目录当中打开终端输入下列指令安装依赖:
~/python3.10/bin/python3.10 -m pip install -r requirements.txt降低huggingface_hub版本:
~/python3.10/bin/python3.10 -m pip install huggingface_hub==0.12.1编写核心代码并利用CPU推理,self.depth_anything从指定的模型路径加载预训练模型,并将模型设置为评估模式 (eval()),其中self.model_path代表深度估计模型的路径,模型分为s,m,l分别是小中大,可以从huggingface下载:LiheYoung/Depth-Anything at main (huggingface.co)
import tkinter as tk
from PIL import Image, ImageTk
import cv2
import numpy as np
import torch
import torch.nn.functional as F
from torchvision.transforms import Compose
from depth_anything.dpt import DepthAnything
from depth_anything.util.transform import Resize, NormalizeImage, PrepareForNet
self.model_path = './models/depth_anything_vits14'
self.DEVICE = 'cpu'
self.depth_anything = DepthAnything.from_pretrained(self.model_path, local_files_only=True).to(self.DEVICE)
self.depth_anything.eval()在该工程界面编写总体代码:
import tkinter as tk
from PIL import Image, ImageTk
import cv2
import numpy as np
import torch
import torch.nn.functional as F
from torchvision.transforms import Compose
from depth_anything.dpt import DepthAnything
from depth_anything.util.transform import Resize, NormalizeImage, PrepareForNet
class DepthEstimationApp:
def __init__(self, root, image_path):
self.root = root
self.root.title("Depth Estimation")
self.left_frame = tk.Frame(self.root)
self.right_frame = tk.Frame(self.root)
self.left_frame.pack(side=tk.LEFT)
self.right_frame.pack(side=tk.RIGHT)
self.original_label = tk.Label(self.left_frame)
self.processed_label = tk.Label(self.right_frame)
self.original_label.pack()
self.processed_label.pack()
self.model_path = './models/depth_anything_vits14'
self.DEVICE = 'cpu'
self.depth_anything = DepthAnything.from_pretrained(self.model_path, local_files_only=True).to(self.DEVICE)
self.depth_anything.eval()
self.transform = Compose([
Resize(width=256, height=256, resize_target=False, keep_aspect_ratio=True, ensure_multiple_of=14,
resize_method='lower_bound', image_interpolation_method=cv2.INTER_LINEAR),
NormalizeImage(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
PrepareForNet(),
])
self.image_path = image_path
self.show_image()
def show_image(self):
frame = cv2.imread(self.image_path)
if frame is not None:
original_height, original_width = frame.shape[:2]
original_img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
original_img = Image.fromarray(original_img)
original_imgtk = ImageTk.PhotoImage(image=original_img)
self.original_label.imgtk = original_imgtk
self.original_label.configure(image=original_imgtk)
depth_image = self.process_frame(frame)
depth_image = cv2.resize(depth_image, (original_width, original_height))
depth_image = cv2.cvtColor(depth_image, cv2.COLOR_BGR2RGB)
processed_img = Image.fromarray(depth_image)
processed_imgtk = ImageTk.PhotoImage(image=processed_img)
self.processed_label.imgtk = processed_imgtk
self.processed_label.configure(image=processed_imgtk)
def process_frame(self, frame):
frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25)
raw_image = frame
image = cv2.cvtColor(raw_image, cv2.COLOR_BGR2RGB) / 255.0
h, w = image.shape[:2]
image = self.transform({'image': image})['image']
image = torch.from_numpy(image).unsqueeze(0).to(self.DEVICE)
with torch.no_grad():
depth = self.depth_anything(image)
depth = F.interpolate(depth[None], (h, w), mode='bilinear', align_corners=False)[0, 0]
depth = (depth - depth.min()) / (depth.max() - depth.min()) * 255.0
depth = depth.cpu().numpy().astype(np.uint8)
depth_color = cv2.applyColorMap(depth, cv2.COLORMAP_INFERNO)
return depth_color
def close(self):
pass
if __name__ == '__main__':
image_path = "/home/jetson/Workspace/Py310Script/DepthAnything-master/sitgirl.png"
root = tk.Tk()
app = DepthEstimationApp(root, image_path)
root.mainloop()
运行结果图:

Stable-Diffusion(content update_V1.1)
利用下列代码尝试部署stable-diffusion,Jetsonnano的性能一般不支持,建议在NX上部署。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd ./stable-diffusion-webui/
~/Workspace/py310scripts/bin/python3.10 -m venv venv
source ./venv/bin/activate
pip install -r requirements.txt
pip install --upgrade pip
./webui.sh --skip-torch-cuda-test
export HF_ENDPOINT=https://hf-mirror.com
./webui.sh --skip-torch-cuda-test虽然SD无法正常运行(资源不足),但是可以考虑安装TinySD
首先打开一个目录并准备在此目录下打开终端并创建Python310虚拟环境(本案例本身自带p310venv环境,在此环境下创建新环境):
先克隆项目:
git clone https://github.com/ThisisBillhe/tiny-stable-diffusion.git然后创建环境venv分开:
python -m venv venv
source ./venv/bin/activate安装tsd:
python setup.py install 然后安装依赖:
pip install torch torchvision transformers pillow tqdm itertools einops pytorch_lightning taming-transformers如果其中某个安装失败了不用一直重复指令,单独先将其他安装好,然后再安装失败的基本可以安装成功,如果还不行参考pytorch和torchvision以及torchaudio、xformers、torchtext、torchdata、pytorch_lightning依赖库的自动安装脚本_cuda、python版本对应的torch、torchvision与torchaudio-CSDN博客
安装适配版本的torch和其对应包
其中最主要难安装的是taming-transformers
如果pip install taming-transformers一直失败那么运行下列代码:
pip install -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
git clone https://github.com/CompVis/taming-transformers.git
cd ./taming-transformers
pip install -e .
cd ..配置国内源方便下载:
export HF_ENDPOINT="https://hf-mirror.com"给文生图脚本添加目录防止索引失败:
gedit ./tiny_optimizedSD/tiny_txt2img.py在开头添加目录:

可以加绝对路径:
sys.path.append("/home/xw9527/Workspace/tiny-stable-diffusion/taming-transformers")或者相对路径:
sys.path.append(".")然后从此网站下载模型:
将模型full_int2_sd.pth直接放置到这个目录下:
运行程序:
python tiny_optimizedSD/tiny_txt2img.py --prompt "A peaceful lakeside cabin with a dock, surrounded by tall pine trees and a clear blue sky" --H 256 --W 256 --seed 27 --device cpu编写一个tk交互界面tk_tinySD.py(注意别忘了修改代码内部的cmd路径):
import tkinter as tk
from tkinter import ttk
def generate_command():
# Get values from UI and ensure they are integers
prompt = prompt_entry.get("1.0", "end-1c").strip() or default_prompt
seed = int(seed_entry.get() or 100)
device = device_var.get()
steps = int(steps_entry.get() or 50)
width = int(width_var.get())
height = int(height_var.get())
# Build command with integer values
cmd = f"~/Workspace/Py310Scripts/bin/python3.10 tiny_optimizedSD/tiny_txt2img.py " \
f"--prompt \"{prompt}\" " \
f"--seed {seed} " \
f"--device {device} " \
f"--ddim_steps {steps} " \
f"--H {height} " \
f"--W {width}"
command_var.set(cmd)
command_entry.config(state='normal')
command_entry.delete(1.0, tk.END)
command_entry.insert(tk.END, cmd)
command_entry.config(state='disabled')
def run_command():
import subprocess
cmd = command_var.get()
if cmd:
subprocess.Popen(cmd, shell=True)
def validate_numeric_input(new_value):
return new_value.isdigit() or new_value == ""
# Default values
default_prompt = "A peaceful lakeside cabin with a dock, surrounded by tall pine trees and a clear blue sky"
# Create main window
root = tk.Tk()
root.title("Tiny Stable Diffusion Configurator")
root.geometry("510x410")
# Main frame
main_frame = ttk.Frame(root, padding="10")
main_frame.pack(fill=tk.BOTH, expand=True)
# Prompt
ttk.Label(main_frame, text="Prompt:").grid(row=0, column=0, sticky="w", pady=(0, 5))
prompt_entry = tk.Text(main_frame, height=4, width=60)
prompt_entry.grid(row=1, column=0, columnspan=2, pady=(0, 10))
prompt_entry.insert(tk.END, default_prompt)
# Parameters frame
params_frame = ttk.Frame(main_frame)
params_frame.grid(row=2, column=0, columnspan=2, sticky="ew")
# Integer variables for width and height
width_var = tk.IntVar(value=128)
height_var = tk.IntVar(value=128)
# Seed with validation
ttk.Label(params_frame, text="Seed:").grid(row=0, column=0, sticky="w", padx=(0, 10))
validate_cmd = root.register(validate_numeric_input)
seed_entry = ttk.Entry(params_frame, width=10, validate="key", validatecommand=(validate_cmd, '%P'))
seed_entry.grid(row=0, column=1, sticky="w", pady=5)
seed_entry.insert(0, "100")
# Device
ttk.Label(params_frame, text="Device:").grid(row=1, column=0, sticky="w", padx=(0, 10))
device_var = tk.StringVar(value="cpu")
ttk.Radiobutton(params_frame, text="CPU", variable=device_var, value="cpu").grid(row=1, column=1, sticky="w")
ttk.Radiobutton(params_frame, text="GPU", variable=device_var, value="cuda").grid(row=1, column=2, sticky="w")
# Steps with validation
ttk.Label(params_frame, text="DDIM Steps:").grid(row=2, column=0, sticky="w", padx=(0, 10))
steps_entry = ttk.Entry(params_frame, width=10, validate="key", validatecommand=(validate_cmd, '%P'))
steps_entry.grid(row=2, column=1, sticky="w", pady=5)
steps_entry.insert(0, "50")
# Width controls
ttk.Label(params_frame, text="Width:").grid(row=3, column=0, sticky="w", padx=(0, 10))
width_slider = ttk.Scale(params_frame, from_=64, to=1024, length=200, variable=width_var)
width_slider.grid(row=3, column=1, sticky="w", pady=5)
width_spin = ttk.Spinbox(params_frame, from_=64, to=1024, width=5, textvariable=width_var)
width_spin.grid(row=3, column=2, sticky="w", padx=(5, 0))
# Height controls
ttk.Label(params_frame, text="Height:").grid(row=4, column=0, sticky="w", padx=(0, 10))
height_slider = ttk.Scale(params_frame, from_=64, to=1024, length=200, variable=height_var)
height_slider.grid(row=4, column=1, sticky="w", pady=5)
height_spin = ttk.Spinbox(params_frame, from_=64, to=1024, width=5, textvariable=height_var)
height_spin.grid(row=4, column=2, sticky="w", padx=(5, 0))
# Command display
ttk.Label(main_frame, text="Generated Command:").grid(row=3, column=0, sticky="w", pady=(10, 5))
command_var = tk.StringVar()
command_entry = tk.Text(main_frame, height=3, width=60, state='disabled')
command_entry.grid(row=4, column=0, columnspan=2, pady=(0, 10))
# Buttons
button_frame = ttk.Frame(main_frame)
button_frame.grid(row=5, column=0, columnspan=2, pady=(10, 0))
generate_btn = ttk.Button(button_frame, text="Generate Command", command=generate_command)
generate_btn.pack(side=tk.LEFT, padx=(0, 10))
run_btn = ttk.Button(button_frame, text="Run Command", command=run_command)
run_btn.pack(side=tk.LEFT)
# Generate initial command
generate_command()
root.mainloop()编写一个启动程序命名为tinySD.sh:
#!/bin/bash
# Change to the tiny-stable-diffusion directory
cd ~/Workspace/AI/tiny-stable-diffusion || {
echo "Error: Could not change to ~/Workspace/AI/tiny-stable-diffusion directory"
exit 1
}
# Check if the Python interpreter exists
if [ ! -f ~/Workspace/Py310Scripts/bin/python3.10 ]; then
echo "Error: Python interpreter not found at ~/Workspace/Py310Scripts/bin/python3.10"
exit 1
fi
# Run the tk_tinySD.py script with the specified Python interpreter
~/Workspace/Py310Scripts/bin/python3.10 ./tiny_optimizedSD/tk_tinySD.py || {
echo "Error: Failed to run tk_tinySD.py"
exit 1
}运行sh文件得到GUI界面:
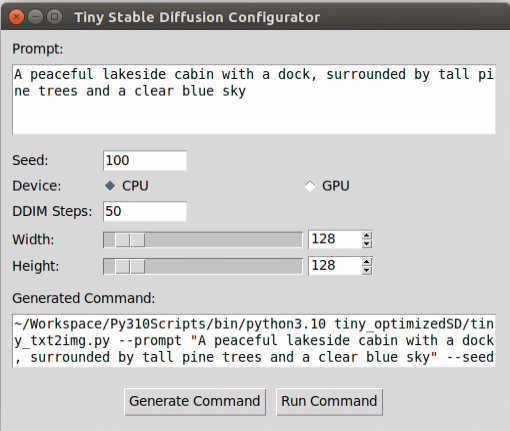
点击Generate Cmd可以得到终端运行指令,或者直接Run运行
运行显示:
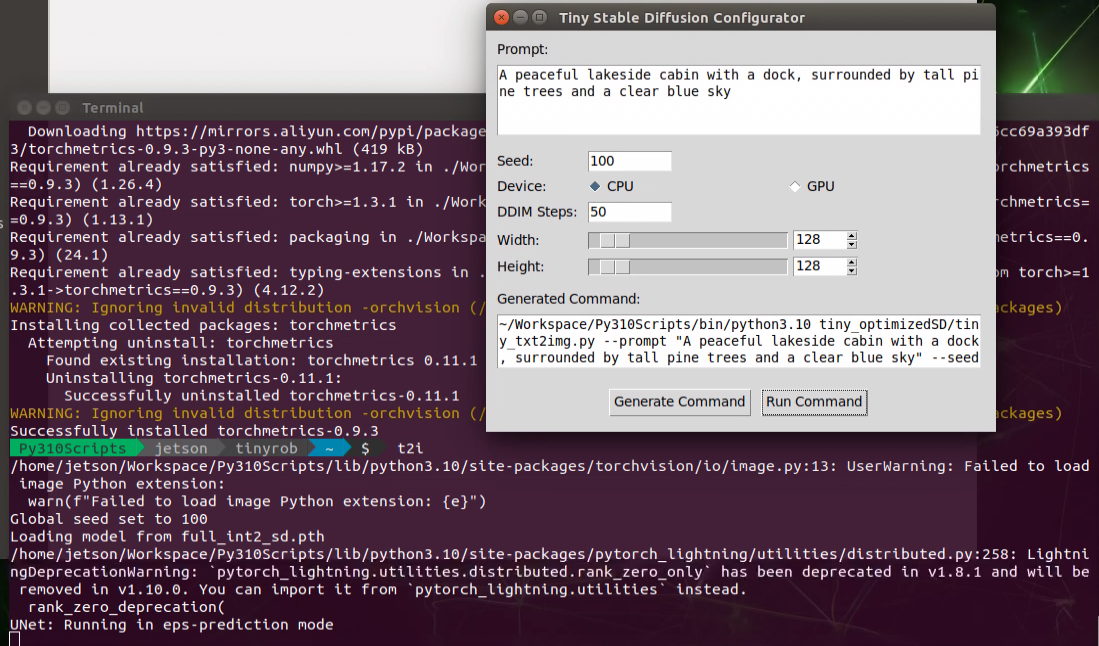
到达这一步大概两分钟
如果跳出下面界面表示正在运行:
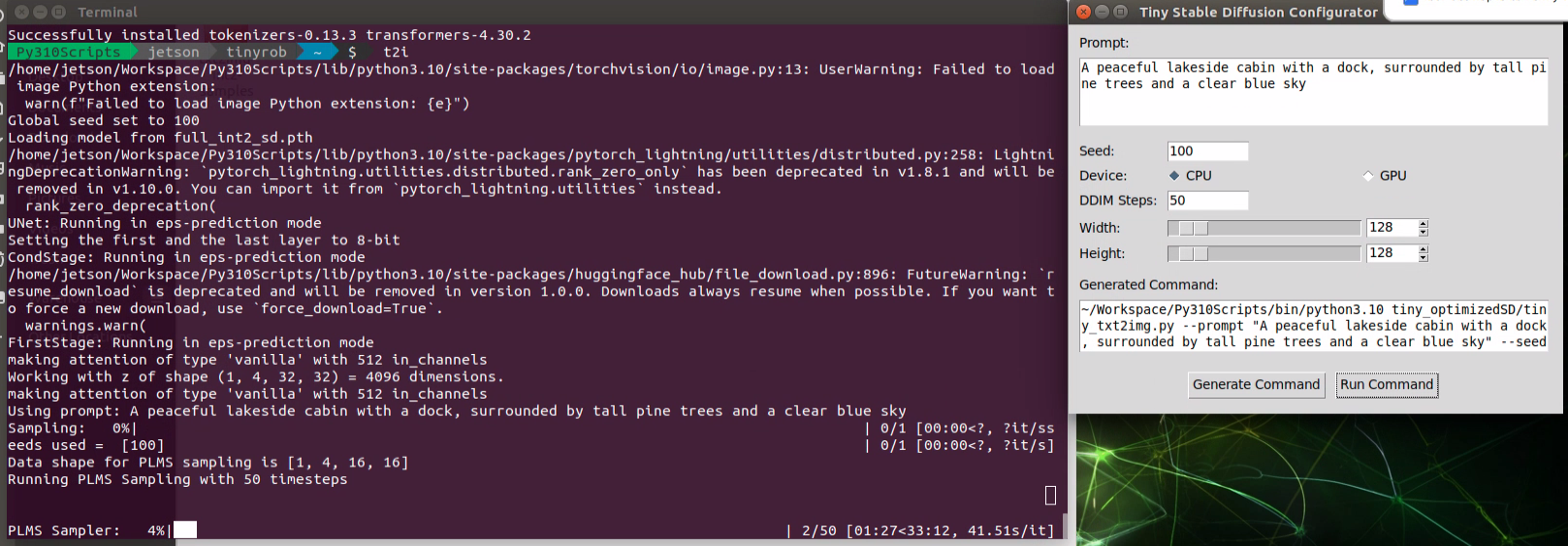
得到结果:
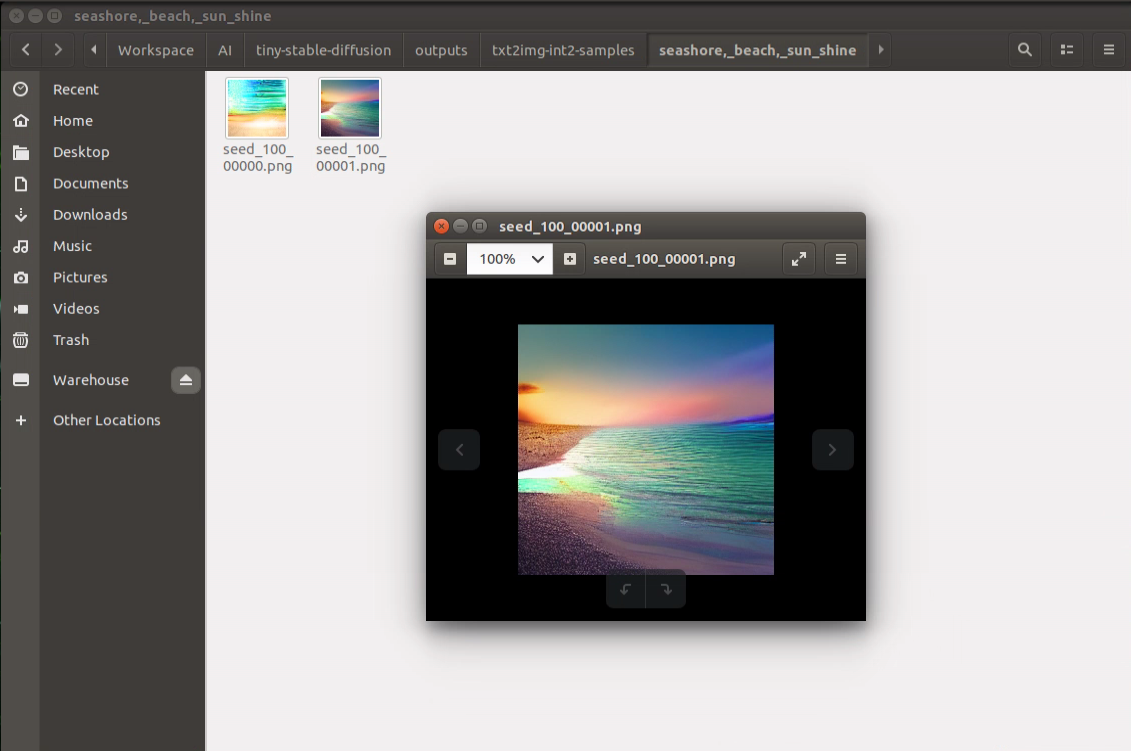
当然我们还可以通过diffusers来运行(以win为例):
安装依赖:
pip install torch==2.3.1+cu121 torchaudio==2.3.1+cu121 torchvision==0.18.1+cu121 transformers==4.30.2 xformers==0.0.27 diffusers==0.31.0 -f https://download.pytorch.org/whl/torch_stable.html编写代码:
from diffusers import StableDiffusionPipeline
import torch
from PIL import Image
import os
def generate_image(
prompt: str,
width: int = 512,
height: int = 512,
seed: int = -1,
negative_prompt: str = "",
steps: int = 20,
cfg_scale: float = 7.0,
sampler: str = "Euler a",
) -> Image.Image:
model_path = os.path.expanduser(
"./dreamshaper_8.safetensors"
)
pipe = StableDiffusionPipeline.from_single_file(
model_path,
torch_dtype=torch.float16,
).to("cuda")
generator = torch.Generator("cuda").manual_seed(seed) if seed != -1 else None
image = pipe(
prompt,
width=width,
height=height,
num_inference_steps=steps,
guidance_scale=cfg_scale,
negative_prompt=negative_prompt,
generator=generator,
).images[0]
return image
image = generate_image(
prompt="A beautiful sunset over mountains, 4K, photorealistic",
width=768,
height=512,
seed=42,
)
image.show()
image.save("output.png")
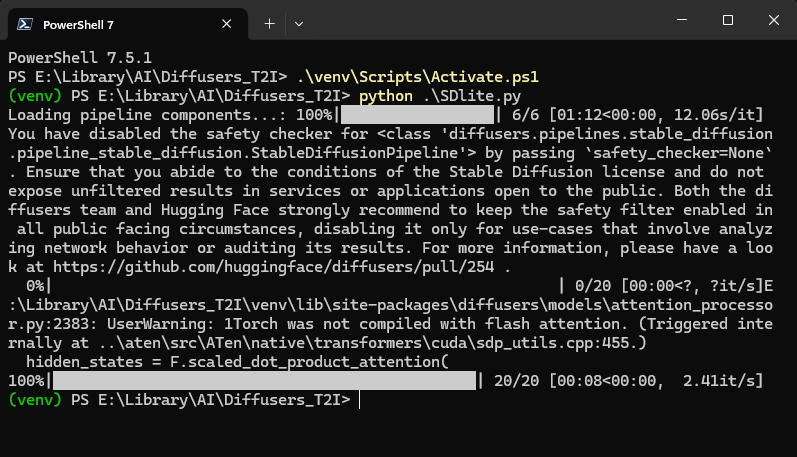
从Civitai或者liblib.art下载模型,以dreamshaper_8.safetensors为例(直接放到和代码同目录下即可),运行此程序:
python .\SDlite.py得到输出显示:
显示结果:

发现和prompt:“A beautiful sunset over mountains, 4K, photorealistic” 完全对应的上,该有的日落以及山,拍摄效果等都有
总结
本文可以帮助jetson nano从开始搭配好部分基础库,方便在开发某项工程的时候利用jetson当中的这些工具达到事半功倍的效果。
(Attention:本栏会不定时更新)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}