







概念:
样本空间:随机试验E的所有基本结果组成的集合称为样本空间。
随机事件:随机试验E中的样本空间的子集称为E的随机事件,简称为事件。
基本事件:由一个样本点组成的单点集,称为基本事件。
以上概念是概率论中基本的概念。
(1)发现问题:
随机事件中有些是直接用数量来标识的,有的则不是用数量来标识的。要想更深入地了解随机事件中的规律,那些不能用数字来标识随机事件,必须能够写到纸上来,也就是说必须数量化。数学建模是必不可少的。
(2)解决问题:
如何建模呢?怎么建已经被那些高人想明白了,我们就看看人家怎么建吧!
为了将事件数量化,高人把对每个事件对应一个数值X,X=f(e) X就叫 随机变量 其中的e就是一个基本事件,那个f 是某种对应关系(注意f是一个单值函数),所以说随机变量是建立在样本空间上的。下面看看随机变量的定义:
随机变量 :设随机实验的样本空间为W,如果对于每一个元素e,都有一个数X与之相对应,
我们就称为随机变量。(注意啊,随机变量的各个取值是有一定概率的 因为这个事件e的发生是有一定概率的)。
接下来问题又来了,我们把基本事件数量化后,我们发现如果随机事件中包含的基本事件太多,我们根本无法一一去 观察,去研究。那怎么办呢?我们可以研究随机变量X的取值范围在某一区间上(x1,x2]中的概率,注意啊,我们研究的依然是概率的问题,只不过把那些基本事件用的概率,转换成了数字在某个区间上的概率,他们是等价的。
所以CLIMAX来了:
随机变量X的取值范围在某一区间上(x1,x2] 中的概率 P{x1<X<=x2} 可以转换求 p{x1<X<=x2}=P{X<=x2} --P{X<=x1} 这个是可以很简单证明的:

太精彩了!因为有了统一的形式也就是说,我们只需要研究 P{X<=x}就好了。
分布函数:
设X是随机变量,x为任意实数,函数F(x)=P{X<=x} //这个说是F(x)是来研究概率的。
如果知道了X的分布函数 ,我们就能知道X在任一区间的概率,分布函数完整的描述了随机变量的统计规律性。
有了分布函数的概念,我们该如何表示它呢?如何求出它来呢?
分布函数的意义:
F(x)=P{X<=x} F(x)表示的在整个样本空间中,那些通过单值函数映射并且映射后的值在(—∞,x)这个区间内的事件集合(随机事件)发生的概率是多少?
我们可以对每个基本事件求并因为是连续的我们就可以用积分的知识来解决的了
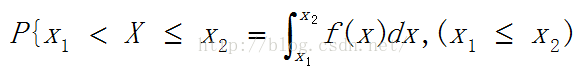
其中的每个基本事件(这样叫可能不正确)都的发生都有一定的概率。
只要我们知道了随机变量X的密度函数,就能随便的求分布函数了。关于这个密度函数 是怎么来的,我现在还没有查明白,到底是通过统计出来的,还是理论推导出来的呢?参考书目:概率论与数理统计(复旦大学出版社)。















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









