









微服务重点解析
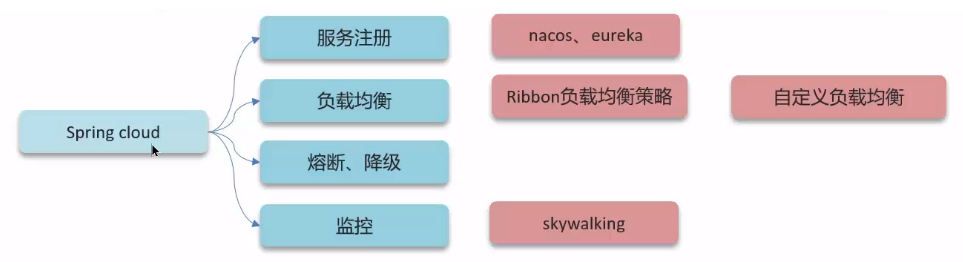
1. Spring Cloud 组件有哪些?
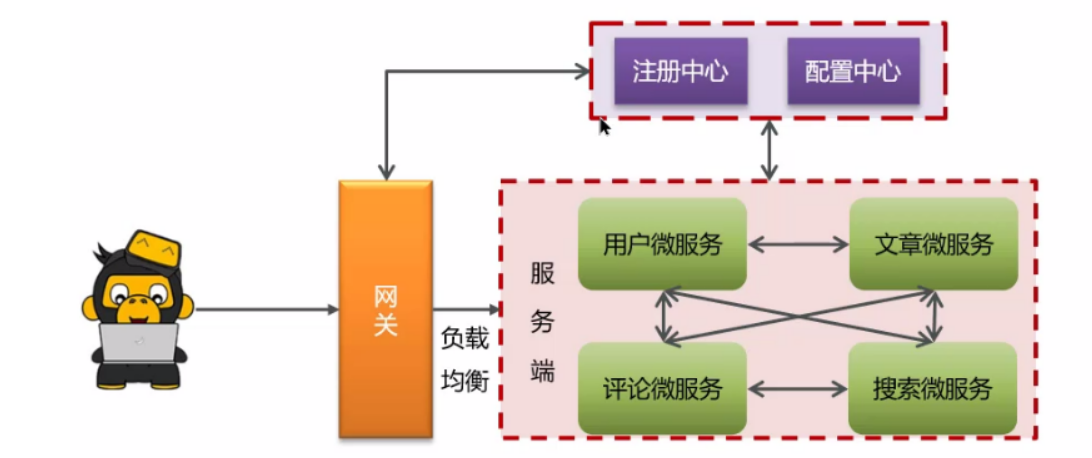
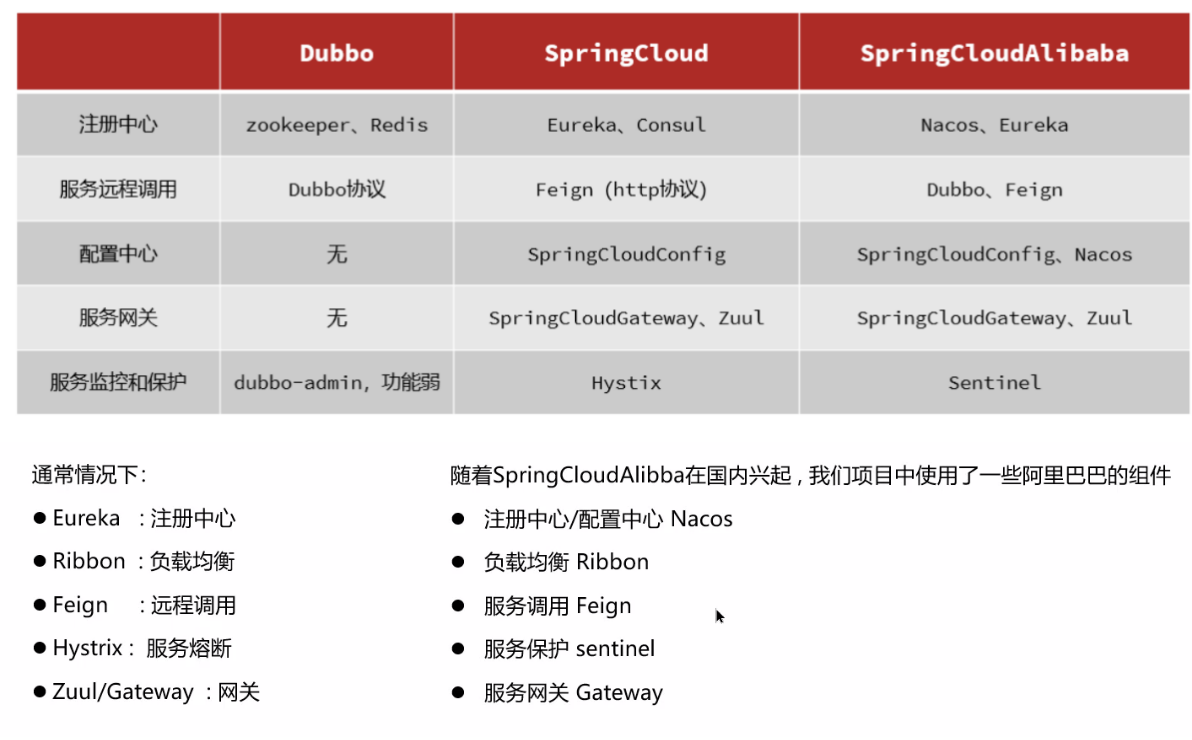
2. 服务注册和发现是什么意思?Spring Cloud 如何实现服务注册和发现的?
如果写过微服务项目,可以说做过的哪个微服务项目,使用了哪个注册中心,常见的有 eureka、nacos;
对于 eureka:
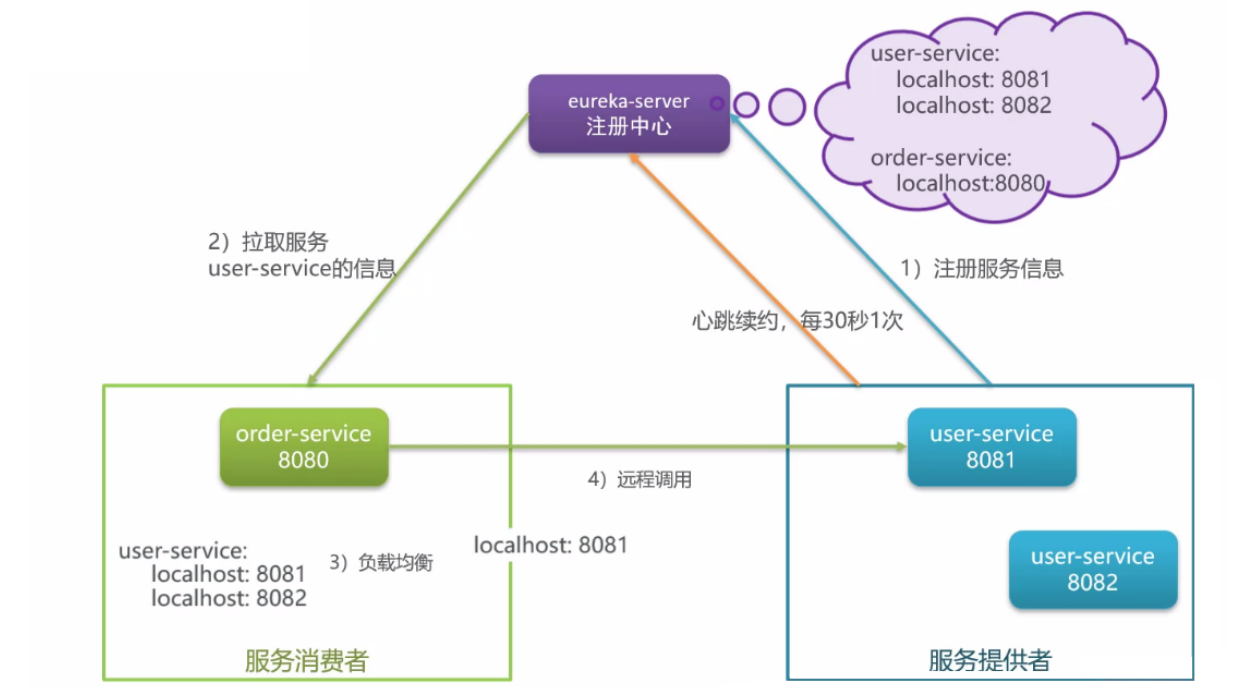
- 服务注册:服务提供者需要把自己的信息注册到 eureka 中,由 eureka 来保存这些信息,比如服务名称、ip、端口等等;
- 服务发现:消费者向 eureka 拉取指定的服务列表信息,如果服务提供者有集群,则消费者会利用负载均衡算法,选择一个进行调用;
- 服务监控:服务提供者会每隔 30 秒向 eureka 发送心跳,报告健康状态,如果 eureka 服务 90 秒没接受到心跳,从 eureka 中剔除;
对于 nacos(与 eureka 的区别):
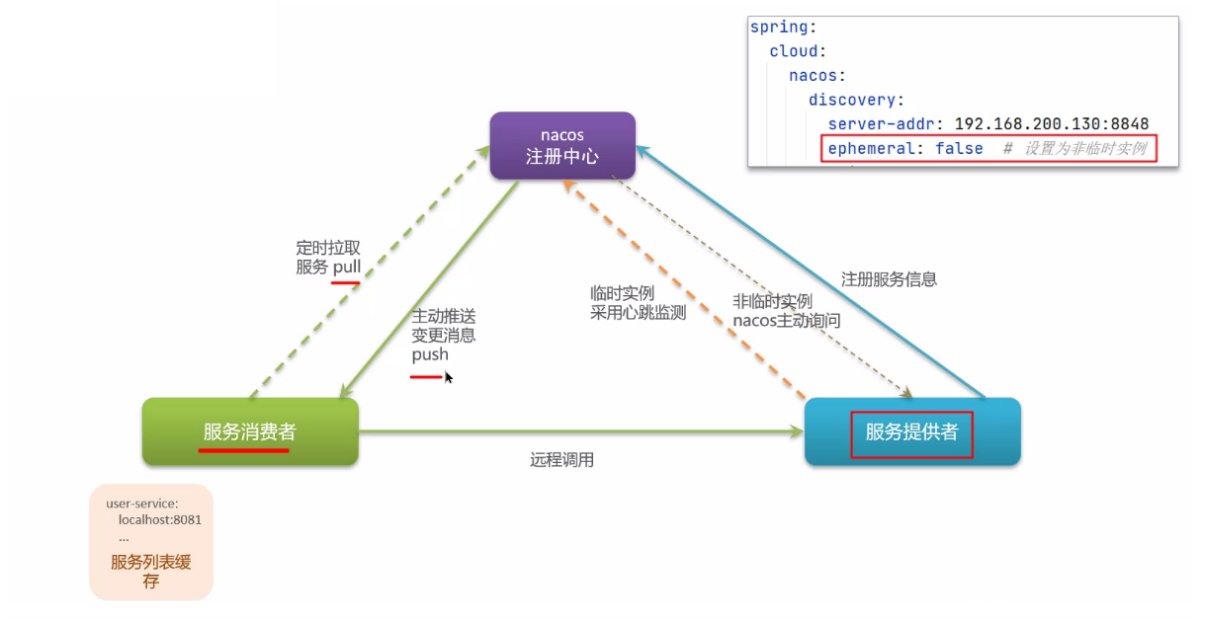
- 服务注册和服务发现跟 eureka 差不多;
- 主要是服务监控上有区别:服务分为两大类,临时实例与非临时实例,两种服务收到的待遇还不一样;
- nacos 服务端支持主动检测服务提供者的状态:临时实例采用心跳模式(与 eureka 一致),非临时实例采用主动检测心跳模式;
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除;
- nacos 支持服务列表变更的消息推送模式,服务列表更新更加及时;
- nacos 集群默认采用 AP(高可用),当集群中存在非临时实例的时候,采用 CP(强一致);Eureka 采用 AP;
- nacos 还支持配置中心,eureka 只支持注册中心,这也是选择使用 nacos 的一个重要原因;
3. 你们项目负载均衡是如何实现的?
(结合实际情况回答)负载均衡用的是 Ribbon,在发起远程调用的时候(RestTemplate 或者 Feign),会使用到 Ribbon 选取服务;
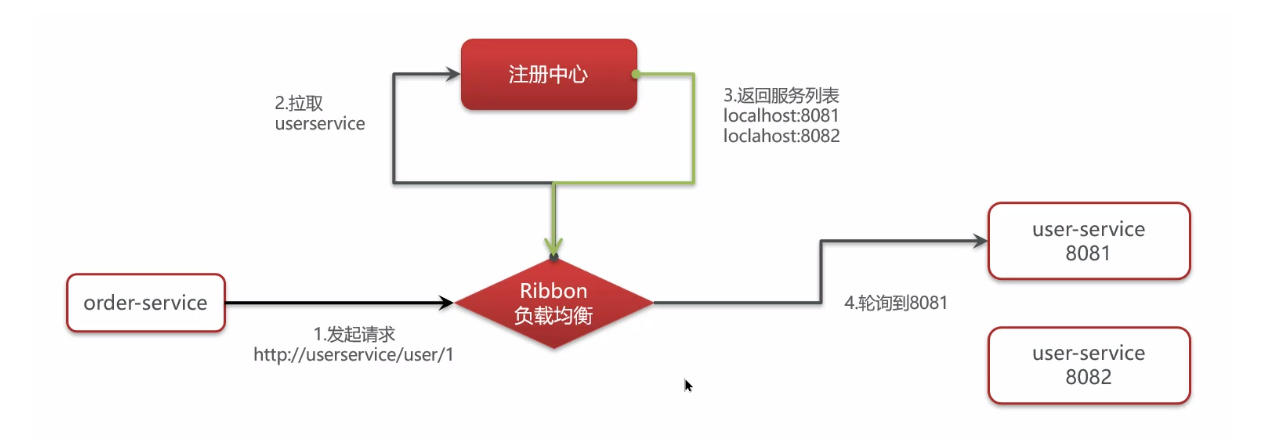
3.1 Ribbon 负载均衡策略有哪些?
- RoundRobinRule:简单轮询服务列表来选择服务器;
- WeightedResponseTimeRule:按照权重来选择服务器,响应时间越长,权重越小;
- RandomRule:随机选择一个可用的服务器;
- BestAvailableRule:忽略那些短路的服务器,并选择并发数较低的服务器;
- RetryRule:重试机制的选择逻辑;
- AvailabilityFilteringRule:可用性敏感策略,先过滤非健康的,再选择连接数较小的实例;
- ZoneAvoidanceRule:以区域可用的服务器为基础进行服务器的选择。使用 Zone 对服务器进行分类,这个 Zone 可以理解为一个机房/机架等。而后再对 Zone 内的多个服务做轮询;
3.2 如果想自定义负载均衡策略如何实现?
- 如何配置负载均衡策略:
- Bean 注入容器法:全局
- 配置文件指定法:局部
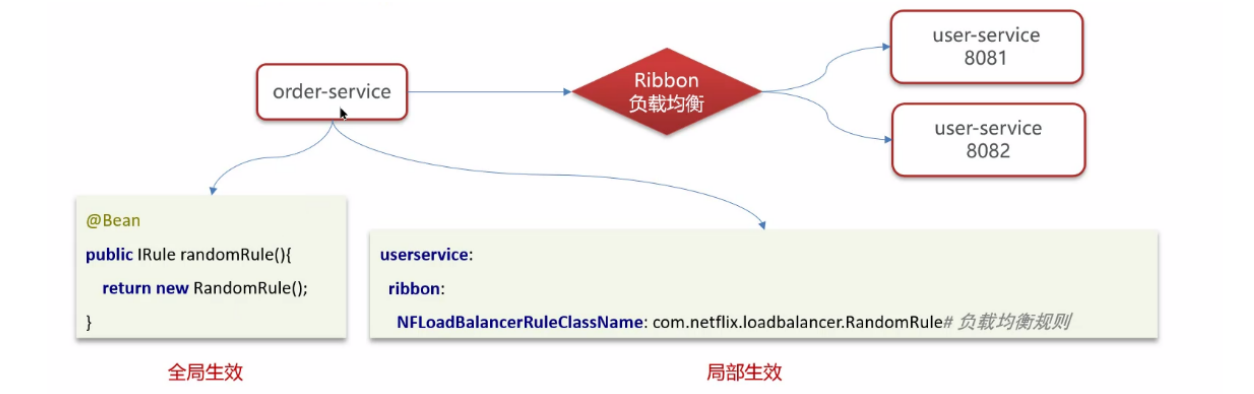
- 自己创建类实现 IRule(自定义 IRule 实现 => 自定义负载均衡规则),然后配置一下即可;
4. 什么是服务雪崩?怎么解决这个问题?
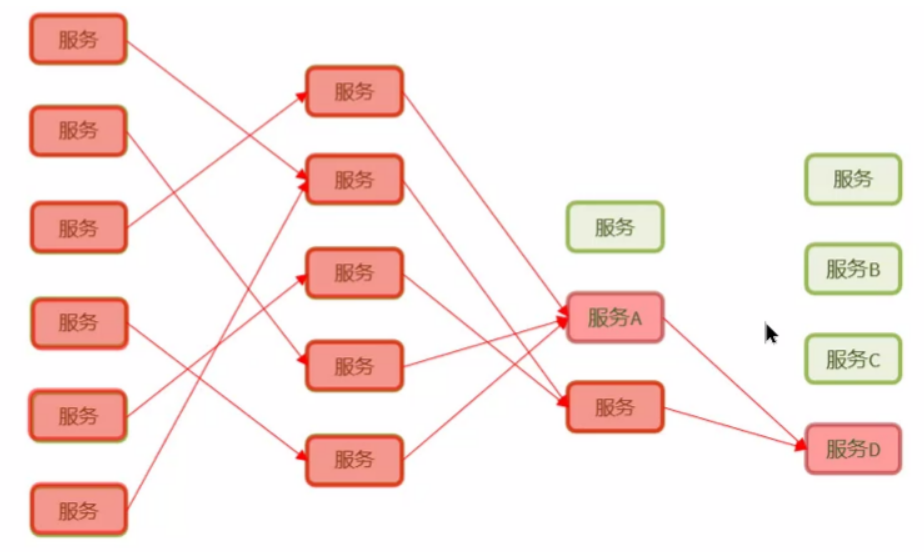
例如图中表示的:
- 服务 D 宕机,服务 A 无法建立连接,仍然进行额外的尝试;
- 服务 D 宕机,服务 A 建立了连接,消耗了连接池的连接数,阻塞等待服务 D 的响应/心跳检测服务 D 的活性,甚至请求会重传;
- 服务 A 很可能撑不住就也故障了,而越往上层的服务调用者,阻塞的时间几何增长,也压根支持不了多少并发量,也会雪崩式的崩溃;
这样服务 D 宕机可能会导致依赖于它的其他服务出现连锁反应式的故障,最终导致整个系统崩溃!
- 服务故障但是没拒绝或直接响应异常导致的;
服务限流也是不错的处理方法,可以用 nginx,网关,sentinel 限流…
- 非本章重点,之后会讲;
4.1 服务降级(解决)
服务降级是服务自我保护的一种方式,或者保护下游服务(雪崩下面的服务消费者)的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不会崩溃;
- 当访问失败、响应时间过长、资源不足之类的就会触发服务降级;
其做法就是,换另一个服务,也就是一个 Plan B:
- 返回“稍后尝试”;
- 执行其他的业务…
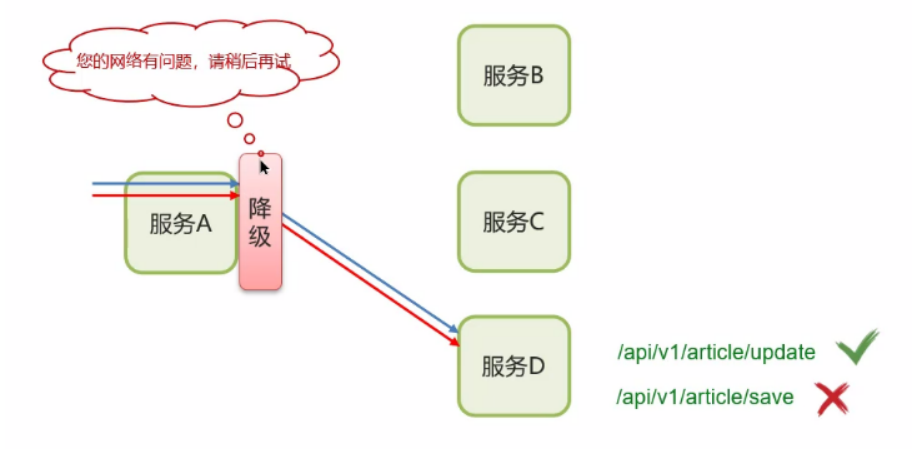
一般在实际开发中与 Feign 接口整合,编写降级逻辑:

4.2 服务熔断(预防)
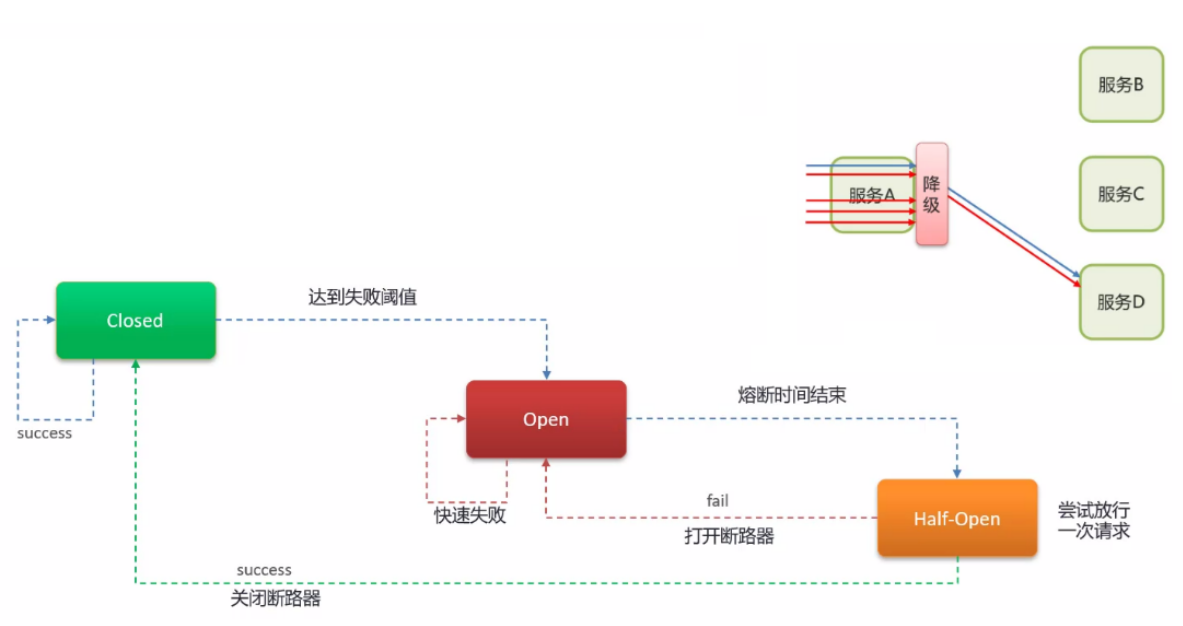
服务熔断是通过监控对特定服务的调用响应时间和错误率等指标,当达到设定的阈值时,触发的机制,即停止对该服务的调用,并且在一段时间内拒绝对该服务的调用,从而避免故障的扩散。
这里主要说说 Hystrix 熔断机制,用于监控微服务调用情况:
- 默认是关闭的,如果需要开启需要在引导类上添加注解:@EnableCircuitBreaker
- 启动后,如果检测到 10 秒内请求的失败率超过 50%(这里可以理解为请求走“降级”逻辑的比率),就触发熔断机制;之后每隔5秒重新尝试请求微服务,如果微服务不能响应,继续走熔断机制。如果微服务可达,则关闭熔断机制,恢复正常请求;
5. 你们微服务是怎么进行监控的?
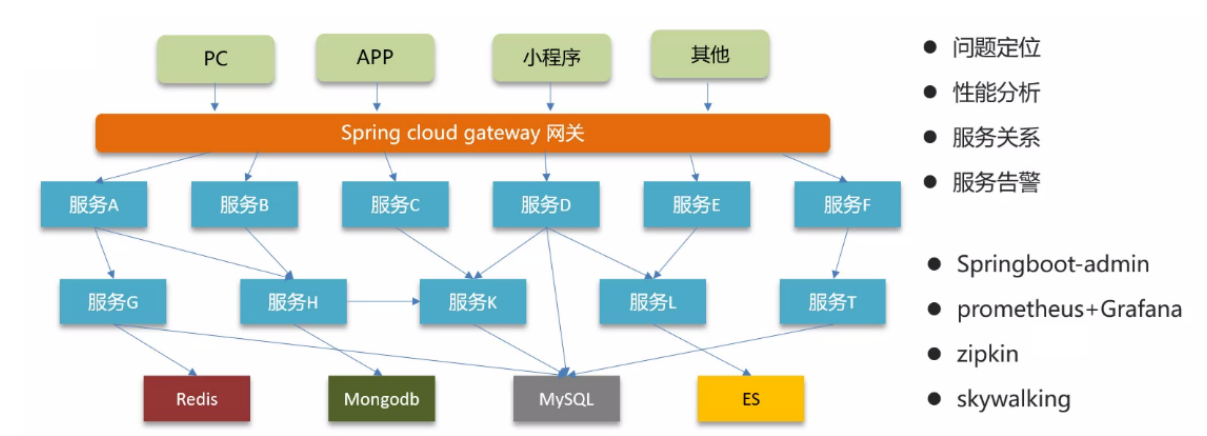
为什么需要监控?
- 服务与服务之间的远程调用链太过于复杂,并且来自各个地方的不同的请求可能会通过网关、服务 A、…、服务 B、使用中间件/使用数据库…
- 就可能出现以下几个问题:
- 问题定位
- 性能分析
- 服务关系
- 服务告警
常见的服务监控工具:
- 或者说是分布式系统应用程序性能监控工具(APM,Application Performance Management)
- SpringBoot-admin
- 简单,局限性大;
- prometheus + Grafana
- 企业常用,很不错,搭建困难;
- zipkin(链路追踪工具)
- 与业务代码耦合;
- skywalking(链路追踪工具)
- 搭建容易,可以很好地解决刚才提到的问题;
5.1 skywalking
skywalking 是一个分布式系统的 APM 工具,提供了完善的链路追踪能力,是 apache 的顶级项目;
- 如何搭建可以自己去网上搜,开源的,看看就会;
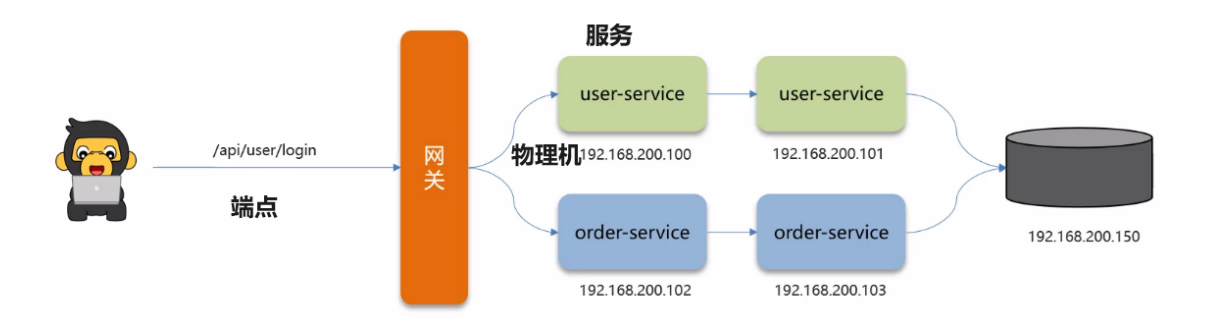
监控的对象:
- 服务(service):业务资源应用系统(微服务);
- 端点(endpoint):应用系统对外暴露的功能接口;
- 实例(instance):服务所在的物理机;
5.2 微服务监控
- 对服务、端点、物理实例的访问时长与健康程度的监控并排名
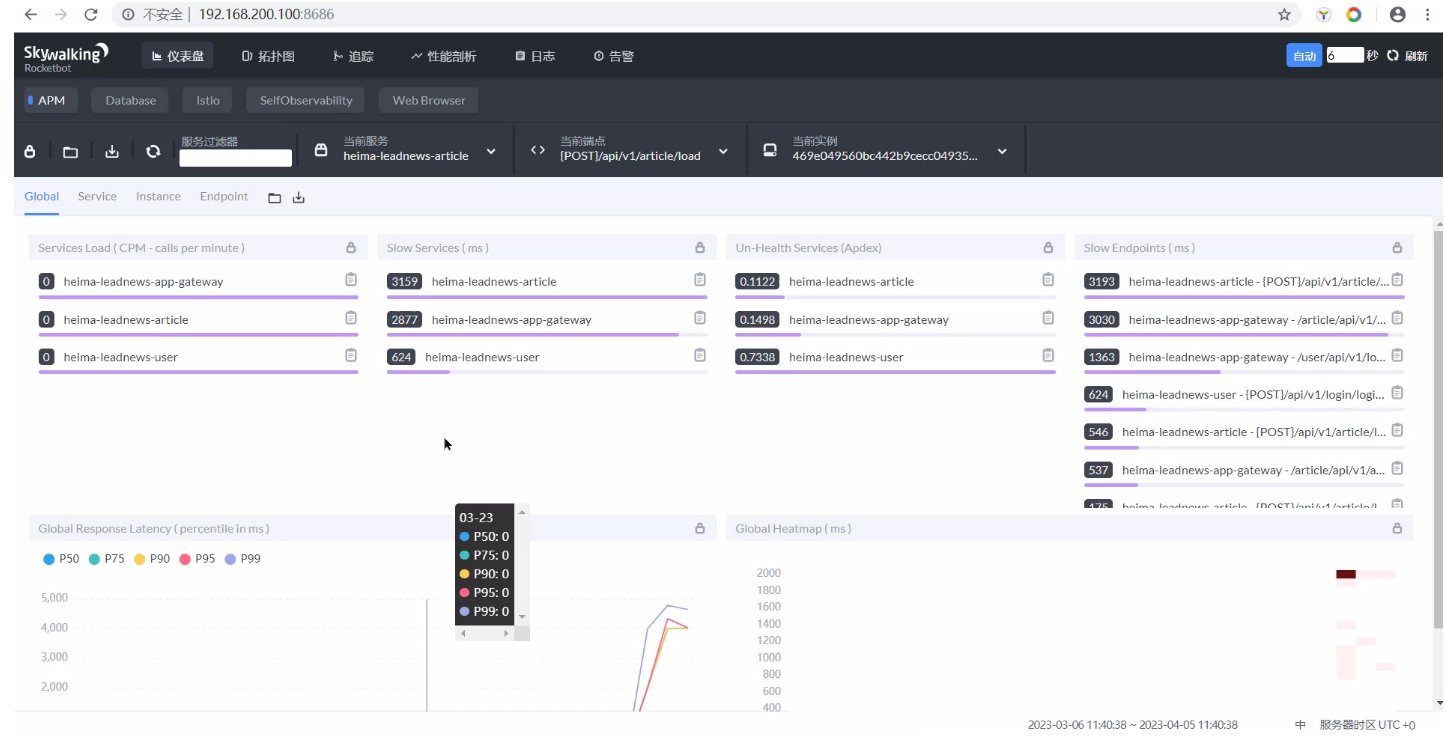
- 链路追踪(服务到服务、服务内部的 MySQL 访问等等)
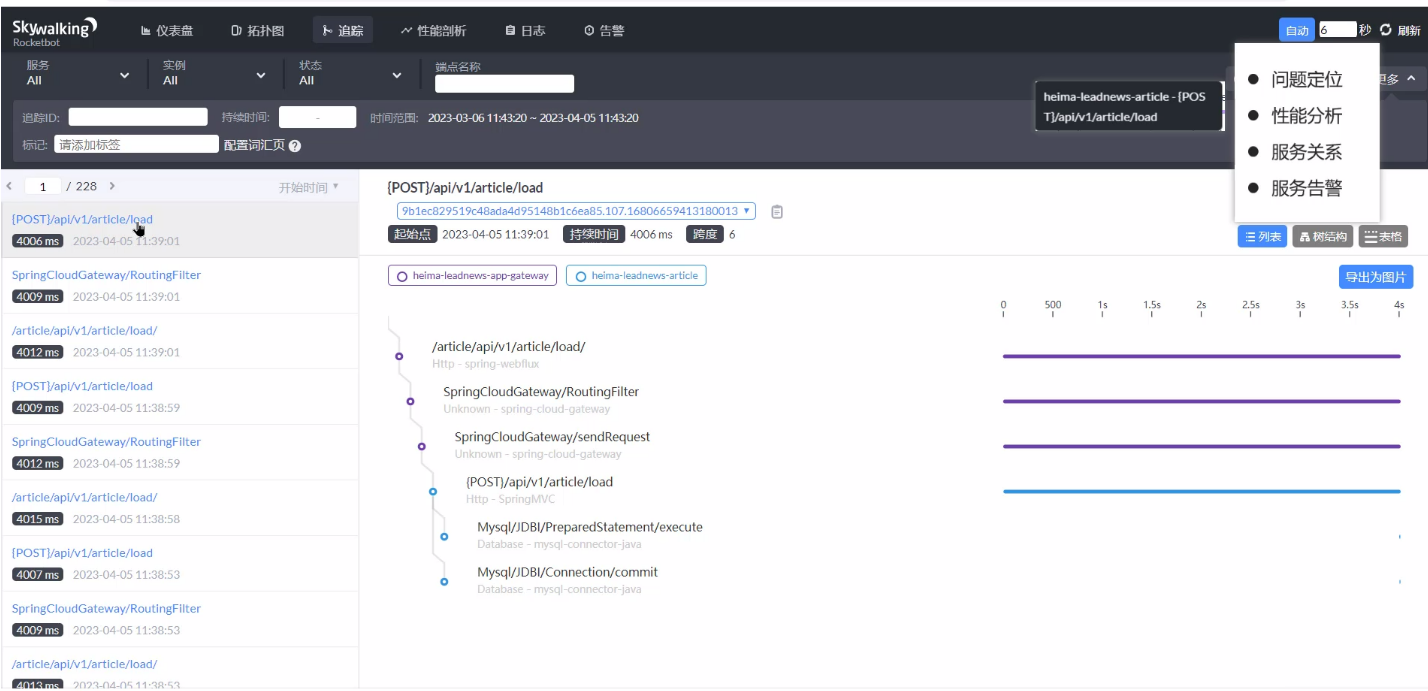
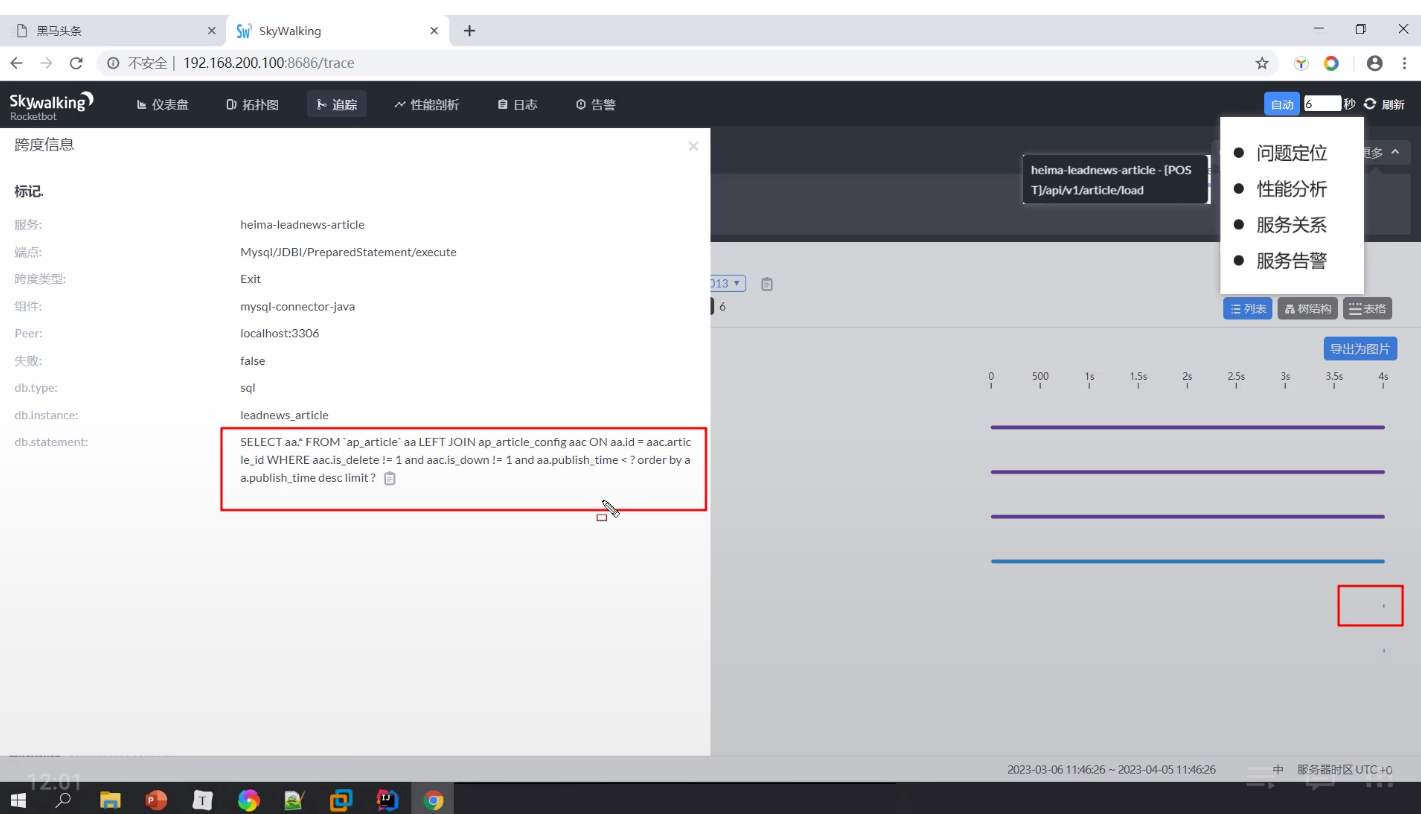
可见,也可以用一些APM工具来发现 SQL 慢查询和定位慢查询,例如 skywalking;
- 还可以用调试工具:Arthas;运维工具:Prometheus;
- 服务关系
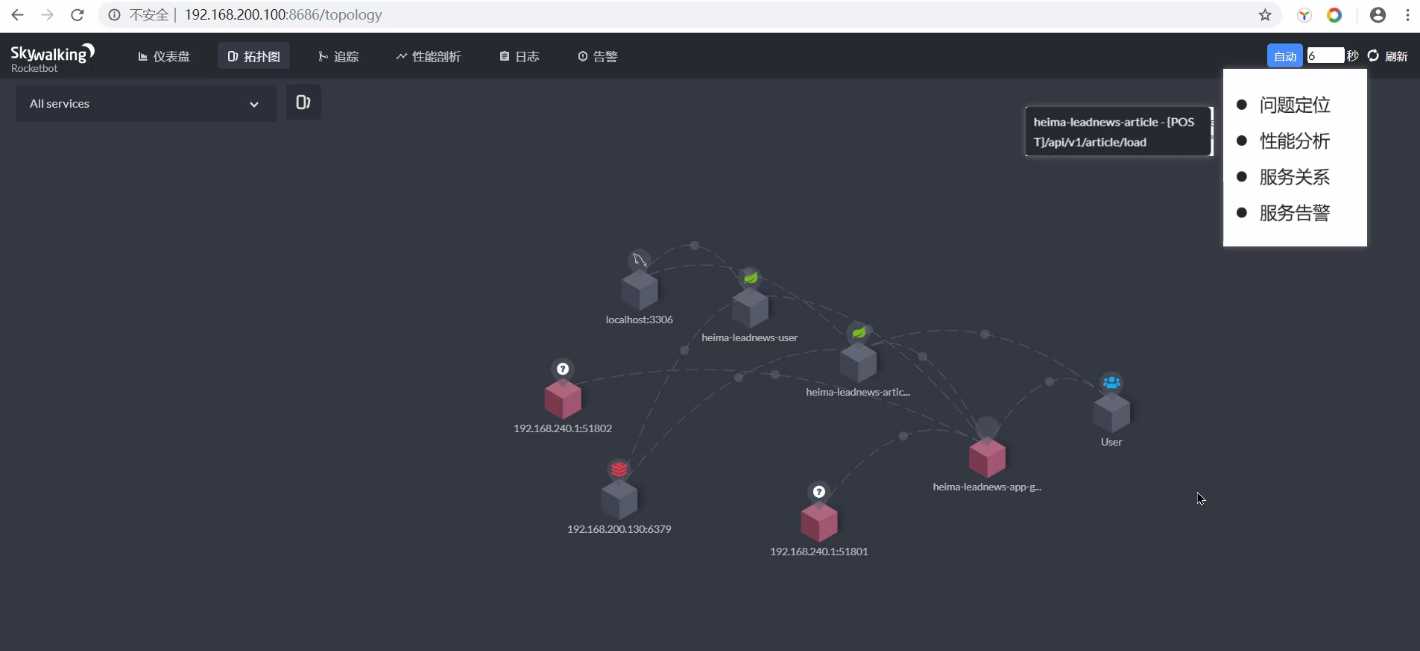
- 服务告警
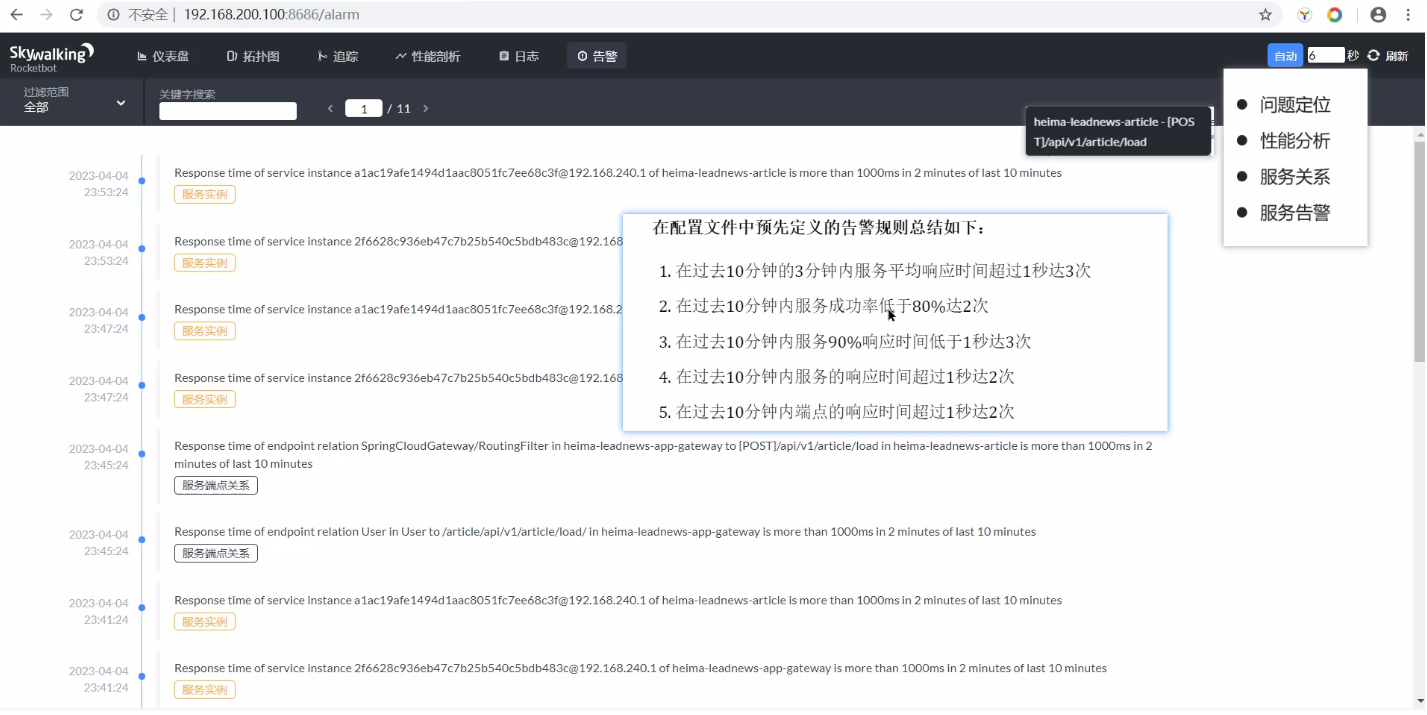
当然,可以设置自己的告警规则,也可以设置发现问题发送短信/邮件给指定负责人的;
5.3 回答
采用的是 skywalking 进行监控:
- skywalking 主要可以监控接口、服务、物理实例的一些状态。特别是在压测的时候可以看到众多服务中的哪些服务和接口比较慢,例如慢查询之类的,我们可以针对性的分析与优化;
- 我们还在 skywalking 设置了告警规则,特别是在项目上线后,我们分别给微服务设置了给相关负责人,如果出错,可以给 TA 发送短信/邮件,第一时间知道项目的 bug 情况,并尽可能快的去修复;
















 2589
2589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











