







你好,我是Qiuner. 为记录自己编程学习过程和帮助别人少走弯路而写博客
这是我的 github https://github.com/Qiuner ⭐️
gitee https://gitee.com/Qiuner 🌹
如果本篇文章帮到了你 不妨点个赞吧~ 我会很高兴的 😄 (^ ~ ^)
想看更多 那就点个关注吧 我会尽力带来有趣的内容 😎
2024黑马程序员 SpringCloud微服务开发与实战,Java黑马商城项目微服务实战开发(涵盖MybatisPlus、Docker、MQ、ES、Redis高级等)的个人学习心得与代码记录!Day1
SpringCloud微服务课程导学_哔哩哔哩_bilibili
官方文档 day01-MybatisPlus - 飞书云文档 (feishu.cn)
我这份文档是对官方文档的补充,比如官方文档没有记载P10的请求参数,这种东西没有什么营养,又容易漏写些东西,因此我记录了下来,您可以通过文字的目录快捷需要的东西
{
“balance”: 2000,
“info”: “{“age”:21}”,
“password”: “123”,
“phone”: “13899776876”,
“username”: “WangWu”
}还记录了一些我自己开发中遇到的bug,如果您也遇到了可以直接地解决 不用去网上找了半天,也没能找到合适的解决方案
又比如说 P15 DB静态工具练习 没有给出修改后的代码 但我这里写了
还有一些我对技术点的理解
文章目录
- 2024黑马程序员 SpringCloud微服务开发与实战,Java黑马商城项目微服务实战开发(涵盖MybatisPlus、Docker、MQ、ES、Redis高级等)的个人学习心得与代码记录!Day1
- Day 1 MyBatis学习
- 原理
- 条件构造器wrapper
- 自定义SQL
- Service接口
- @Autowired处爆红
- 案例 基于Restful风格实现下列接口(有重点)
- 用到的请求参数
- Lambda
- 批量新增
- 代码生成工具 MybatisPlus
- 讲师推荐的插件安装后 导航栏没有出现Other
- 静态工具
- 静态工具使用报错 The server time zone value '�й���ʱ��' is unrecognized or represents more than one time zone. You must configure either the server or JDBC driver (via the serverTimezone configuration property) to use a more specifc time zone value if you want to utilize time zone support.
- 静态Db
- 逻辑删除
- 枚举处理器
- JSON处理器
- MybatisPlus 内部拦截器

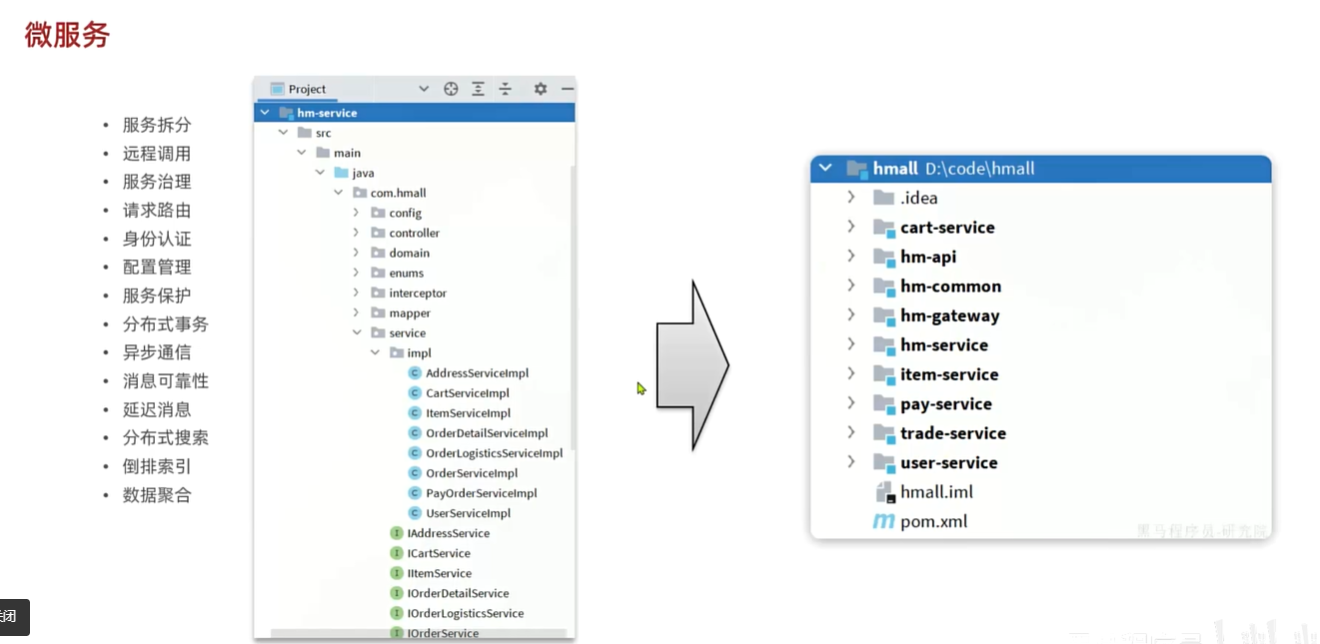
Day 1 MyBatis学习
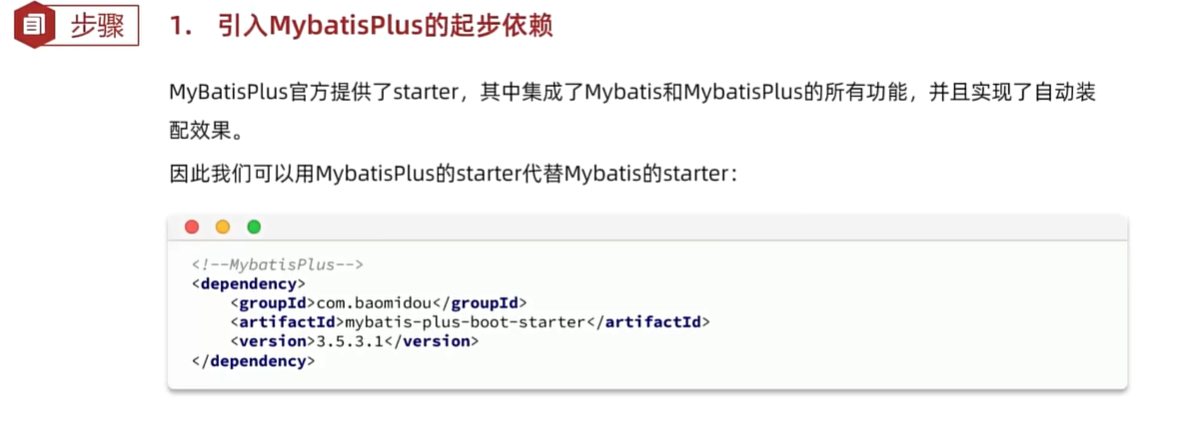
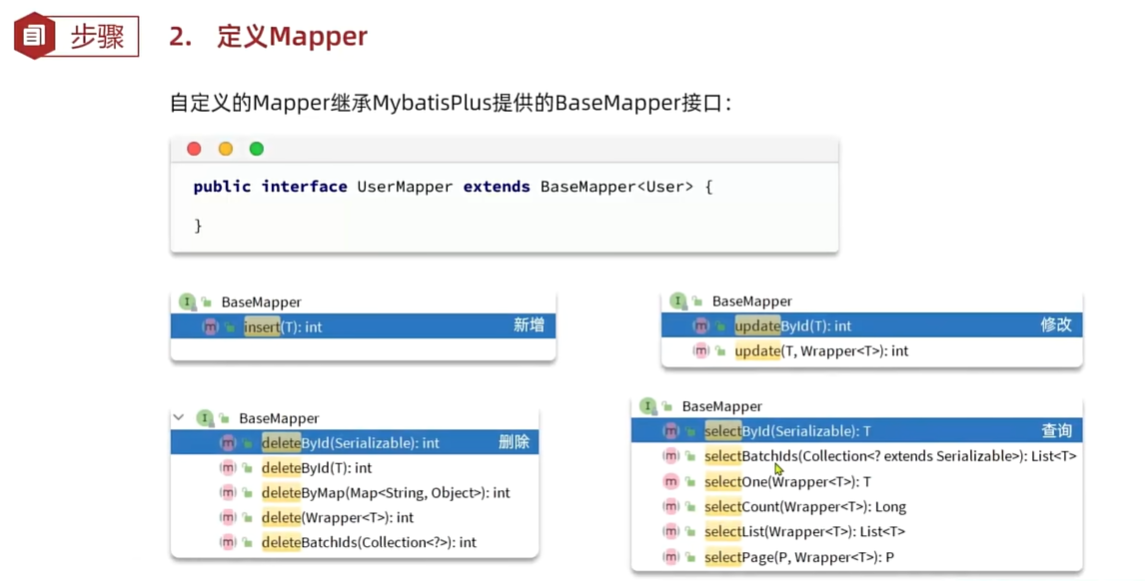

原理
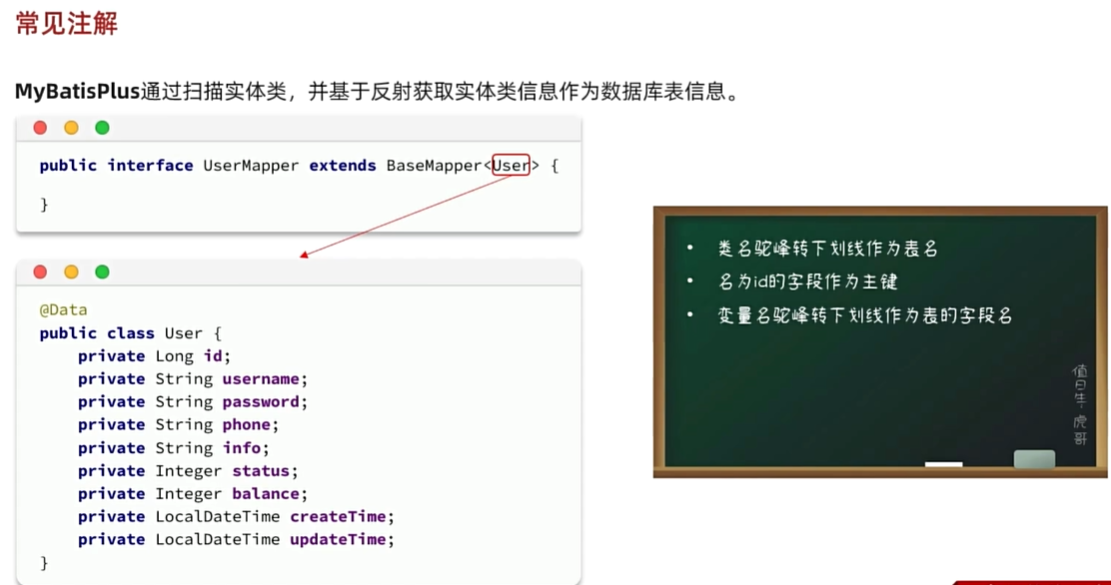
- 约定大于配置的原理 导致能使用它的代码
常见注解及使用场景

MyBatisPlus配置文件
- 如果全局配置与局部配置冲突 会先使用局部配置

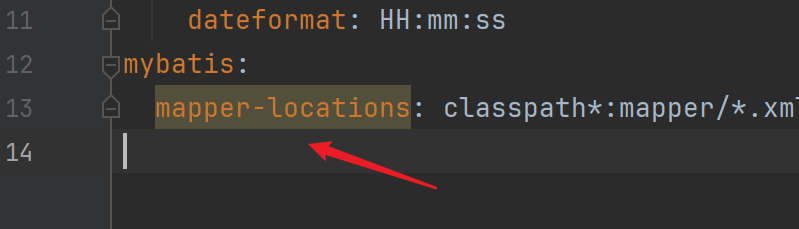
- 这个黄色是无效的意思
java.lang.IllegalStateException: Failed to load ApplicationContext
Caused by: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name ‘com.baomidou.mybatisplus.autoconfigure.MybatisPlusAutoConfiguration’: Unsatisfied dependency expressed through constructor parameter 0; nested exception is org.springframework.boot.context.properties.ConfigurationPropertiesBindException: Error creating bean with name ‘mybatis-plus-com.baomidou.mybatisplus.autoconfigure.MybatisPlusProperties’: Could not bind properties to ‘MybatisPlusProperties’ : prefix=mybatis-plus, ignoreInvalidFields=false, ignoreUnknownFields=true; nested exception is org.springframework.boot.context.properties.bind.BindException: Failed to bind properties under ‘mybatis-plus.global-config.db-config’ to com.baomidou.mybatisplus.core.config.GlobalConfig$DbConfig
- 换成这行代码就可以了
mybatis-plus:
type-aliases-package: com.itheima.mp.domain.po
global-config:
db-config:
id-type: assign_id

条件构造器wrapper
QueryWrapper 是 MyBatis Plus 中的一个查询条件封装器,用于构建 SQL 查询条件。它提供了一种更加便捷和灵活的方式来构建复杂的查询条件,而不需要直接编写 SQL 语句。
通过 QueryWrapper,你可以在 Java 代码中以面向对象的方式构建查询条件,而不必担心 SQL 注入等安全问题,同时也提高了代码的可读性和可维护性。
以下是 QueryWrapper 的一些常用方法和用法:
- eq(String column, Object val):等于查询,指定列的值等于给定的值。
- ne(String column, Object val):不等于查询,指定列的值不等于给定的值。
- gt(String column, Object val):大于查询,指定列的值大于给定的值。
- lt(String column, Object val):小于查询,指定列的值小于给定的值。
- ge(String column, Object val):大于等于查询,指定列的值大于等于给定的值。
- le(String column, Object val):小于等于查询,指定列的值小于等于给定的值。
- like(String column, String likeValue):模糊查询,指定列的值类似于给定的值。
- in(String column, Collection<?> coll):包含查询,指定列的值在给定的集合中。
- orderByAsc(String… columns):升序排序,根据指定的列进行升序排序。
- orderByDesc(String… columns):降序排序,根据指定的列进行降序排序。
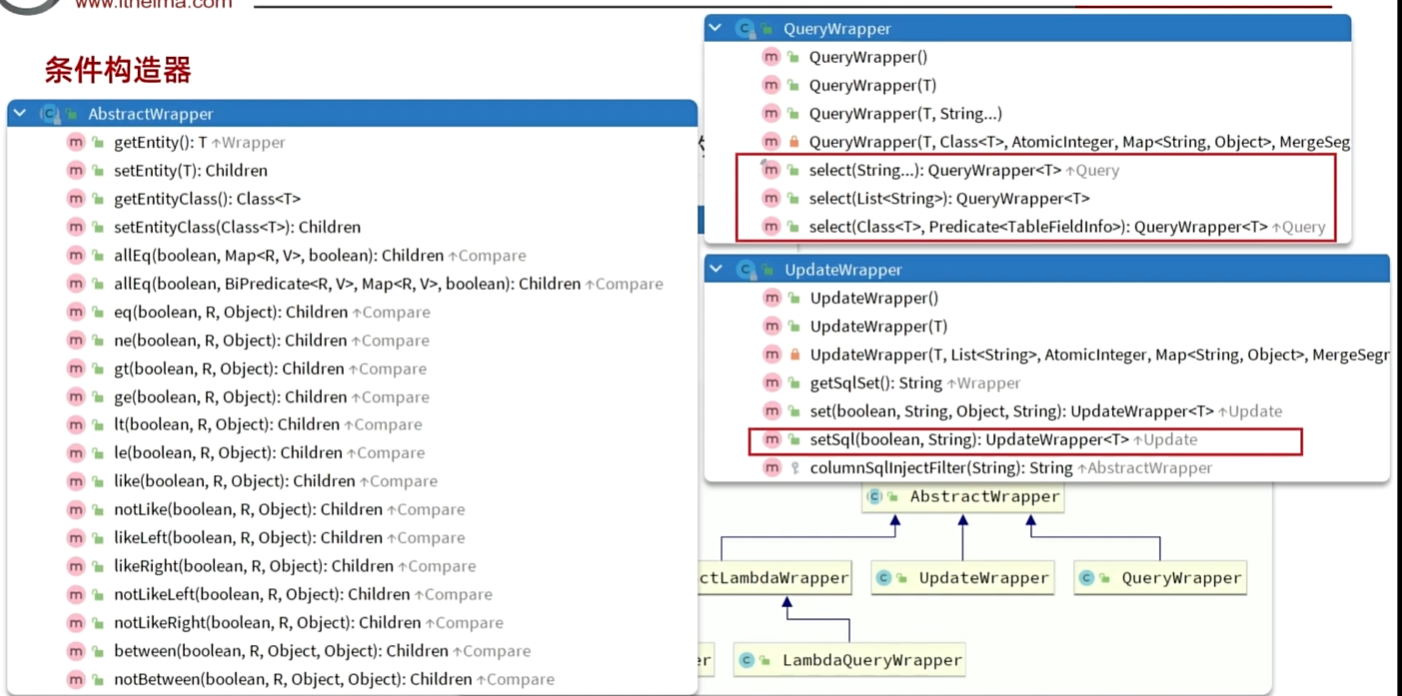
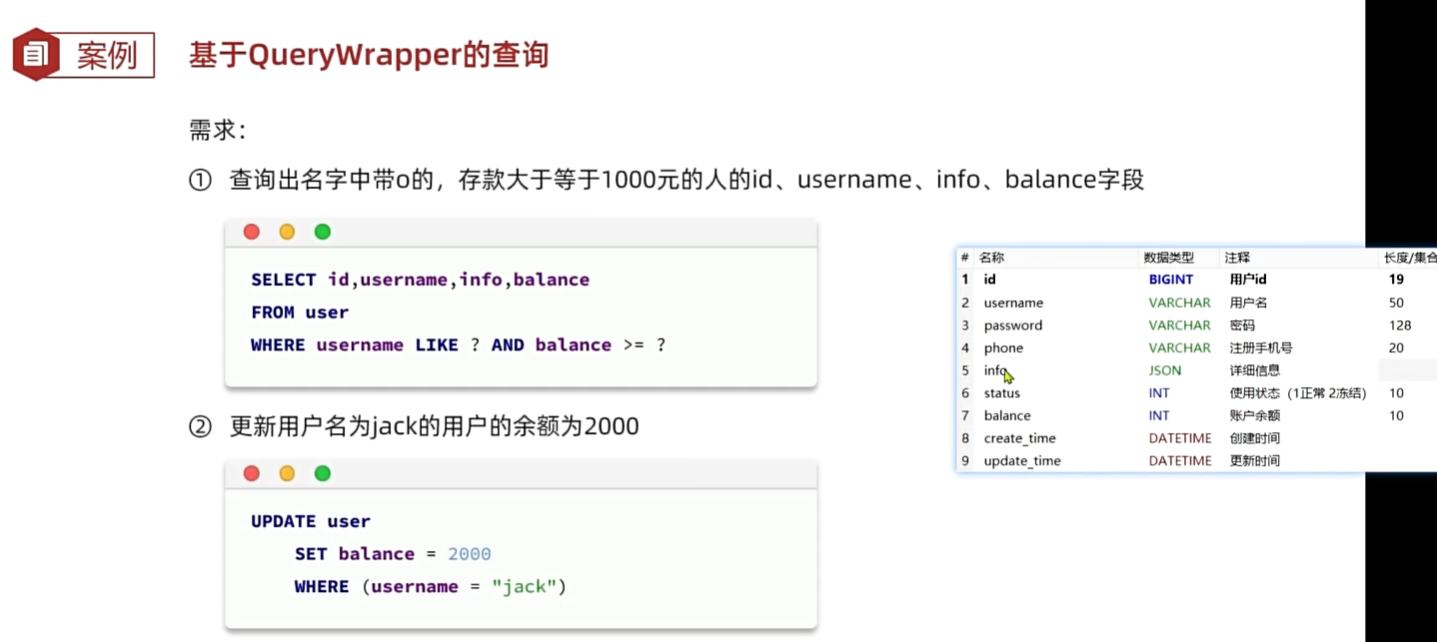

- lambda使用获取函数的方式来实现避免硬编码,通过反射机制
@Test
void testLambdaQueryWrapper() {
// 1.构建条件 WHERE username LIKE "%o%" AND balance >= 1000
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.lambda()
.select(User::getId, User::getUsername, User::getInfo, User::getBalance)
.like(User::getUsername, "o")
.ge(User::getBalance, 1000);
// 2.查询
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}
- 条件构造器 的缺点就是将持久层和业务层混杂在一起了
自定义SQL
- 为了解决MP编写SQL很快但占用了一部分业务层逻辑

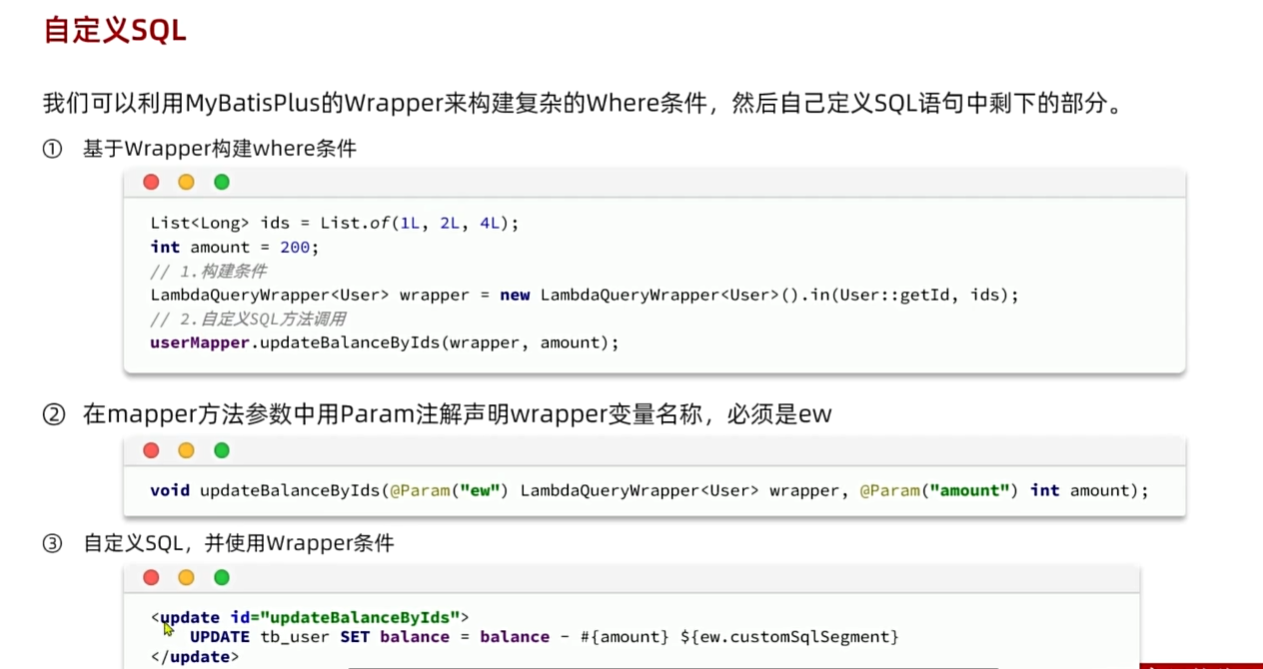
理解
- 自定义SQL是语法糖,很好的将业务层和持久层分开来
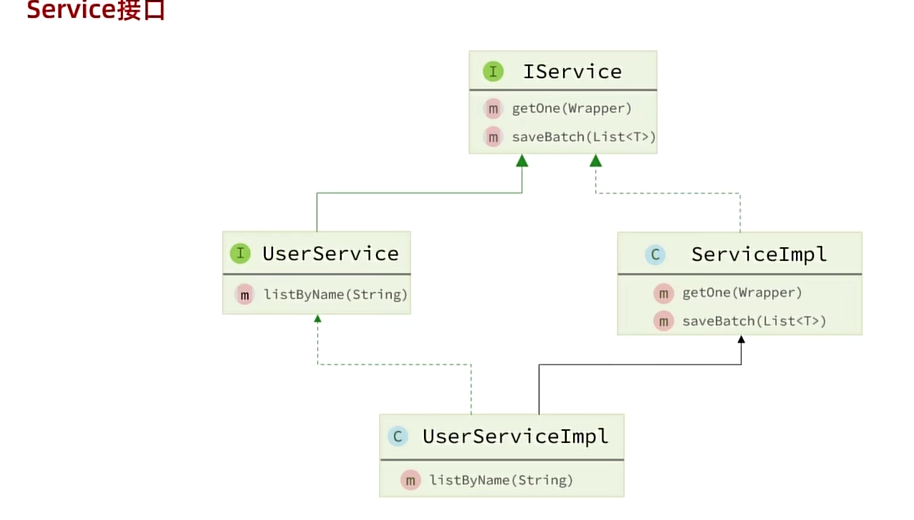
Service接口
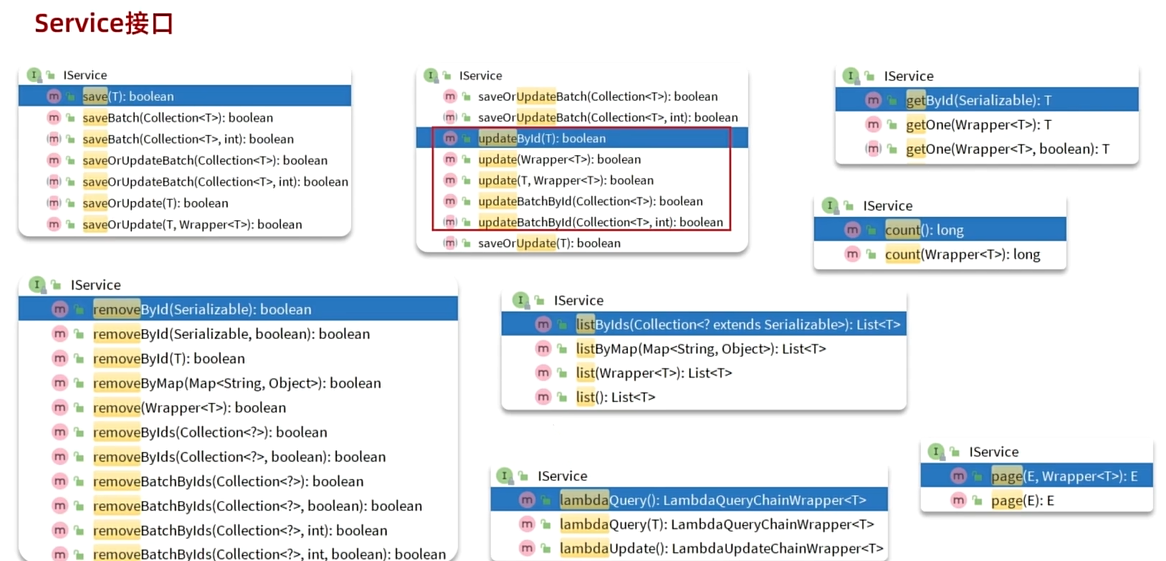
- 这里的Service层,原本要写下图这样的业务,但是有了MP就可以写,直接调用
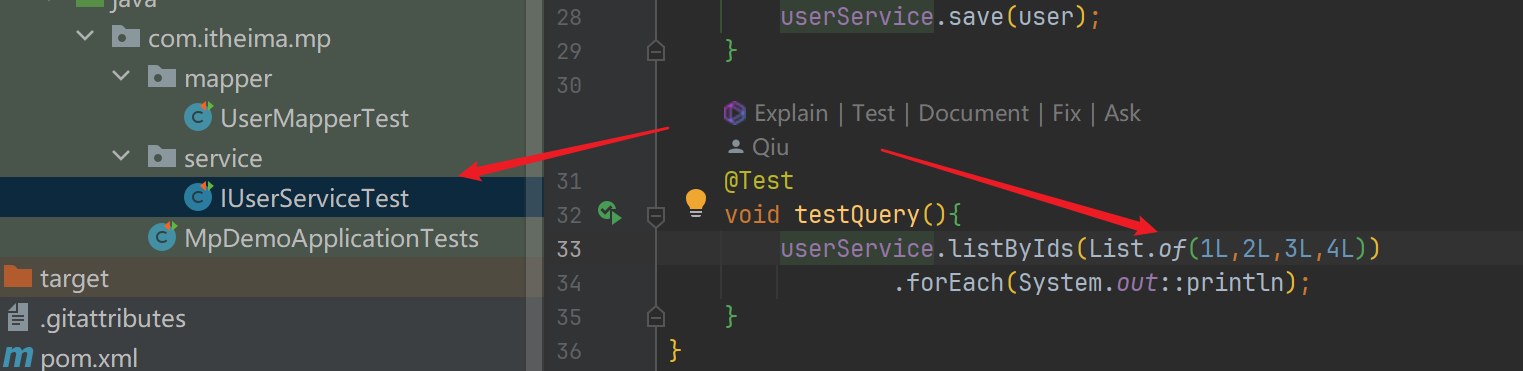
- 使用单元测试模仿Control层
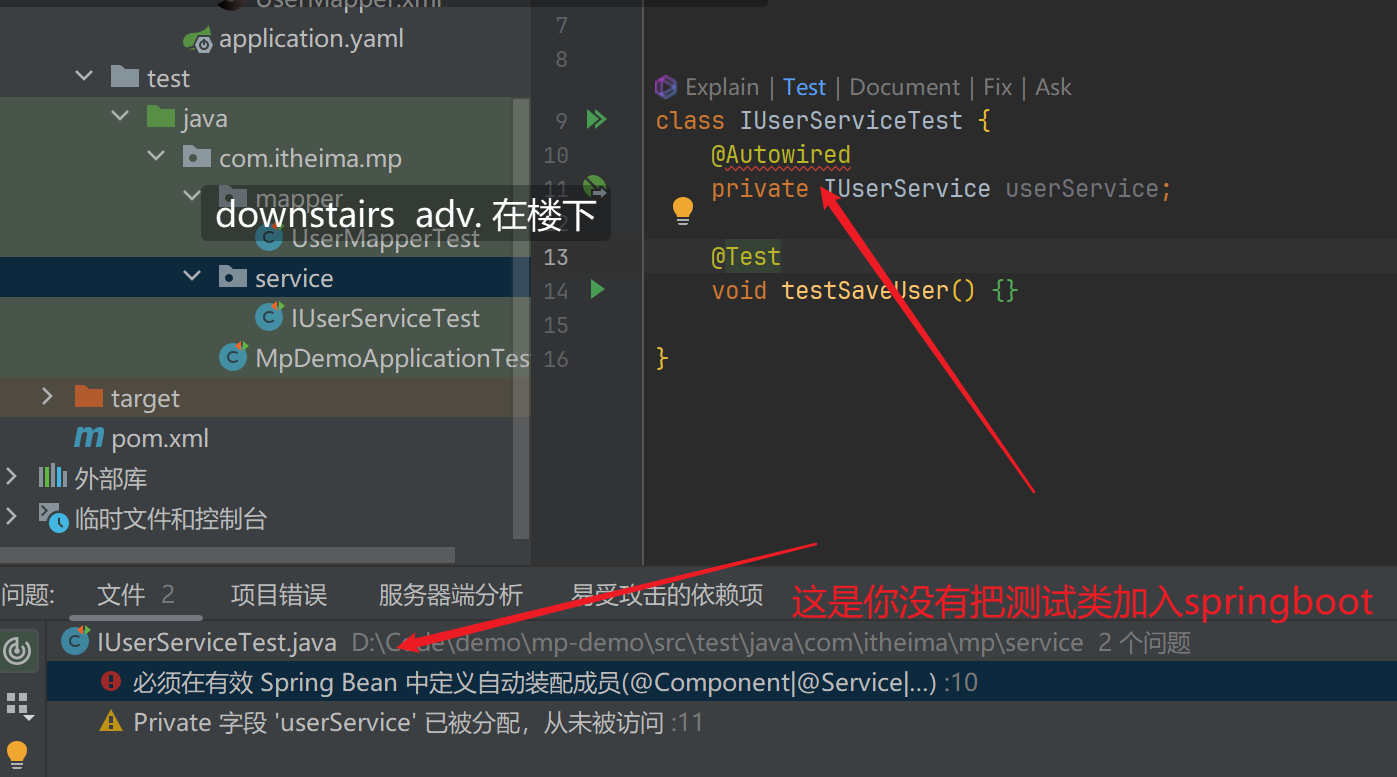
@Autowired处爆红

案例 基于Restful风格实现下列接口(有重点)
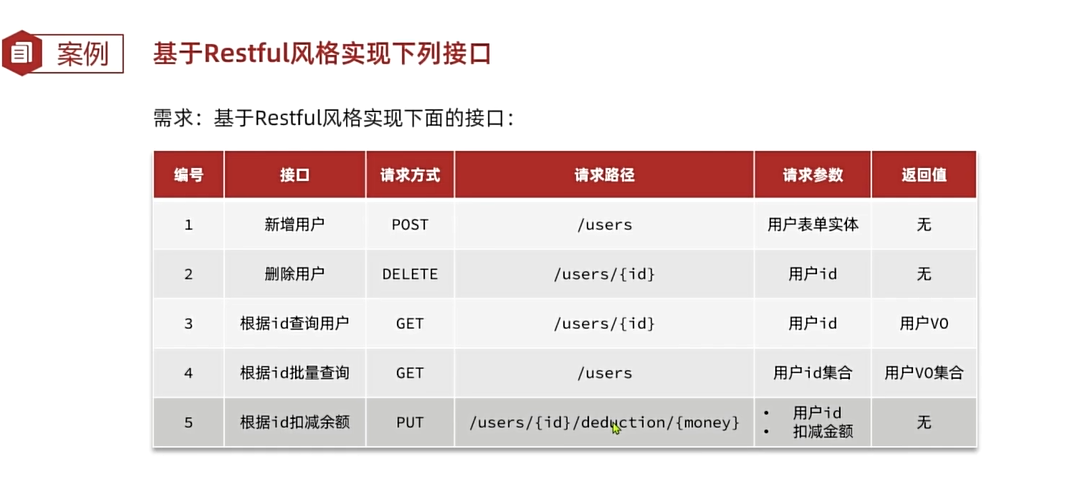
重点
-
这里代码写的很巧妙,代码的目的是将User Service交给Spring自动装配
-
@Autowired private IUserService userService;- 但这种做法是spring所不推荐的
- springboot推荐使用构造函数注入
public UserController(IUserService userService) {
this.userService = userService;
}
但太繁琐了 于是采用
@Api(tags = "用户管理接口")
@RequiredArgsConstructor
@RestController
@RequestMapping("users")
public class UserController {
private final IUserService userService;
-
使用了
@RequiredArgsConstructor注解,这是Lombok库提供的功能之一。它会为带有final关键字的成员变量生成构造函数参数,并在构造函数中进行初始化。因此,在这种情况下,不需要使用@Autowired注解来进行依赖注入,因为Lombok会自动为userService生成一个构造函数参数,并且在初始化UserController对象时将其注入。 -
这种方式的好处是代码更简洁,不需要显式地声明
@Autowired,而且对于final成员变量的使用更加规范,因为它们只能在构造函数中被初始化一次。 -
使用了mp之后 简单service层代码能直接在控制层使用,简单的mapper层代码能直接在service层使用
- 使用alt加8弹出服务窗口
端口被占用报错Web server failed to start. Port 8080 was already in use.Identify and stop the process that’s listening on port 8080 or configure this application to listen on another port.
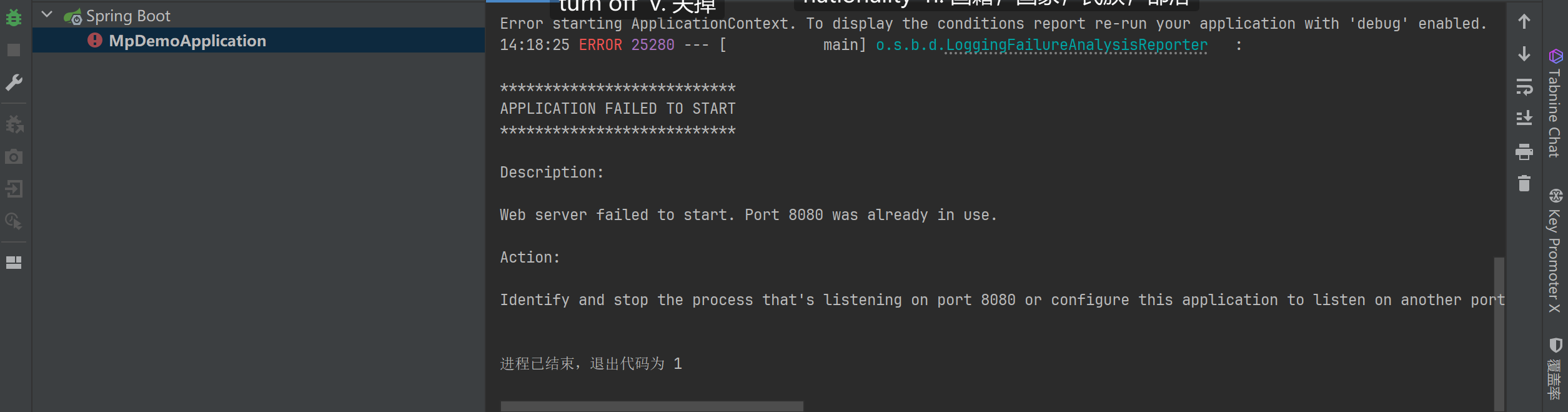
-
这个报错是项目端口好已经被占用的报错
-
打开cmd窗口 输入
netstat -ano | findstr :8080
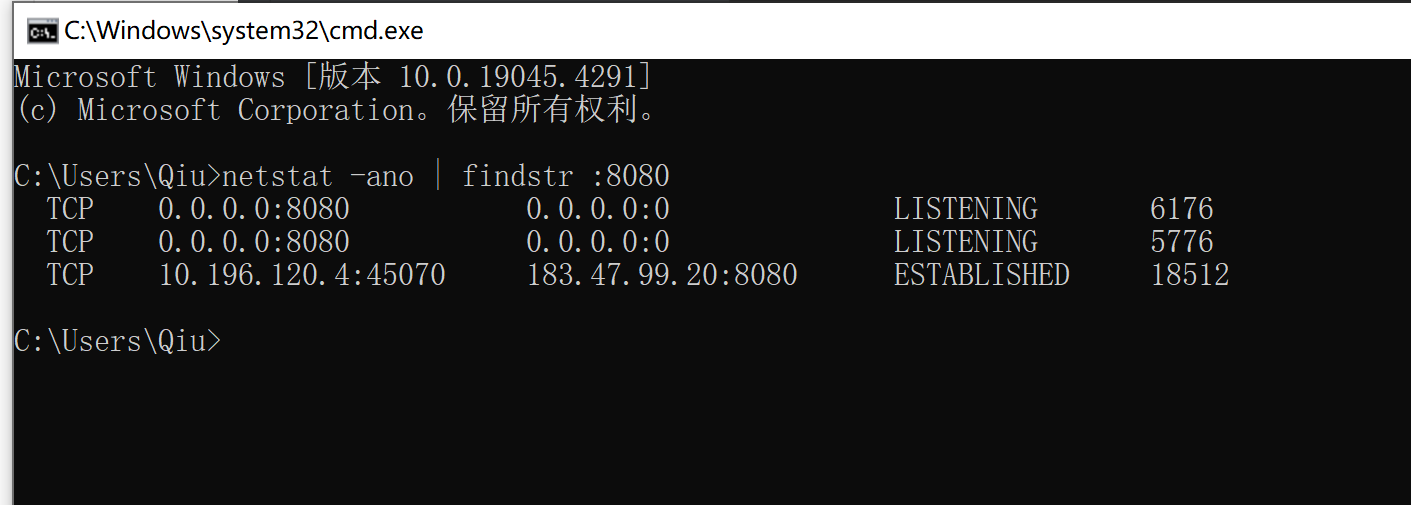
- 这个意思是还有进程和8080通信
taskkill /PID 6176 /F
taskkill /PID 5776 /F
-
如果关掉后在运行关掉8080命令,那是有东西在一直重启通信,应该是你的苍穹外卖、黑马点评什么的没有关闭
-
打开任务管理器
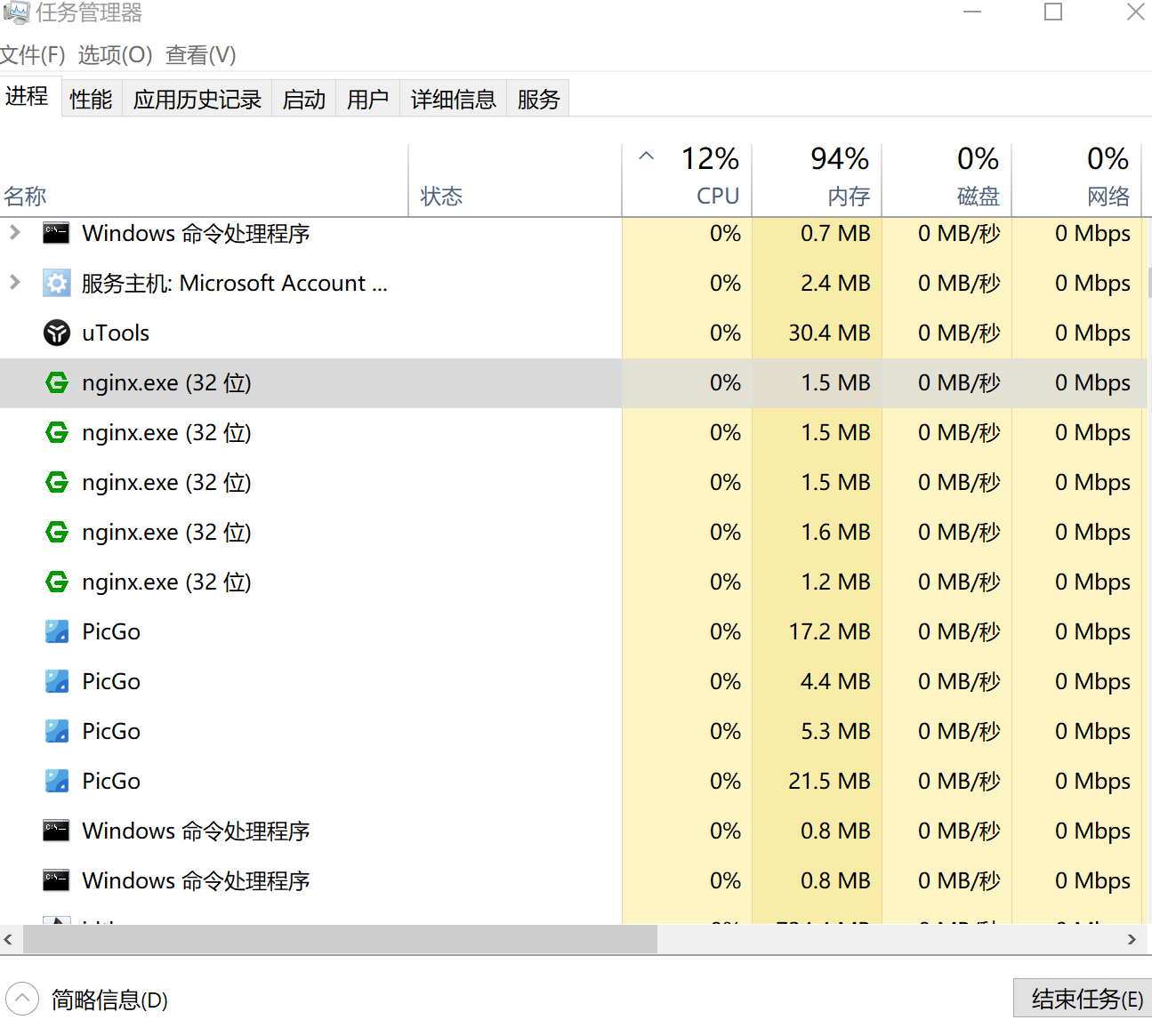
-
诶个突突了
-
还不行就 这个是关闭所有niginx
taskkill /F /IM nginx.exe > nul
用到的请求参数
{
"balance": 2000,
"info": "{\"age\":21}",
"password": "123",
"phone": "13899776876",
"username": "WangWu"
}
Lambda

control
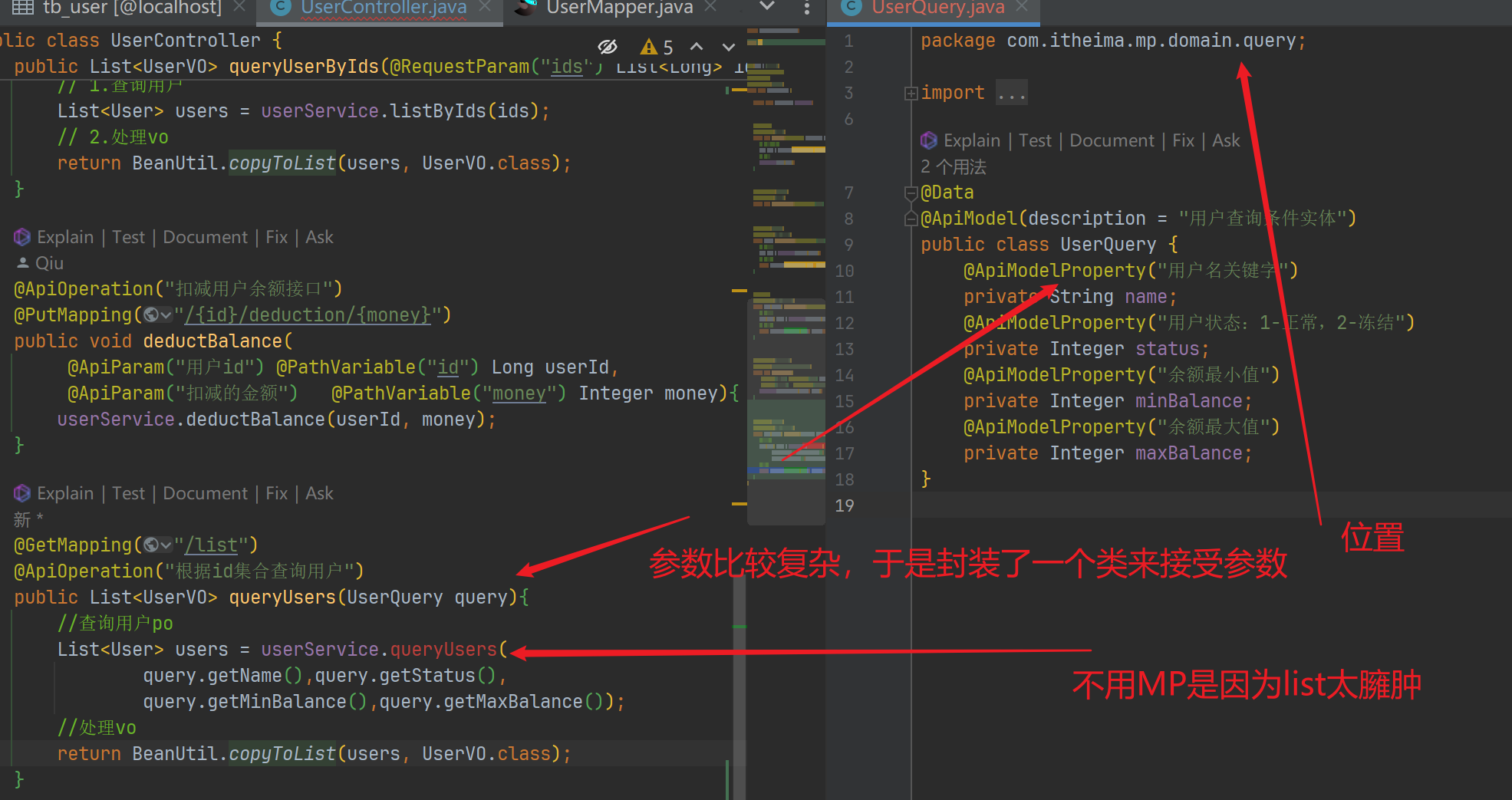
server
@Override
public List<User> queryUsers(String name, Integer status, Integer minBalance, Integer maxBalance) {
return lambdaQuery()
.like(name != null, User::getUsername, name)
.eq(status != null, User::getStatus, status)
.ge(minBalance != null, User::getBalance, minBalance)
.le(maxBalance != null, User::getBalance, maxBalance)
.list();
}
- mp着实强大
批量新增

@Test
void testSaveOneByOne() {
long b = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
userService.save(buildUser(i));
}
long e = System.currentTimeMillis();
System.out.println("耗时:" + (e - b));
}
// 下面这种数据能够提升10倍
@Test
void testSaveBatch() {
// 准备10万条数据
List<User> list = new ArrayList<>(1000);
long b = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
list.add(buildUser(i));
// 每1000条批量插入一次
if (i % 1000 == 0) {
userService.saveBatch(list);
list.clear();
}
}
long e = System.currentTimeMillis();
System.out.println("耗时:" + (e - b));
}
private User buildUser(int i) {
User user = new User();
user.setUsername("user_" + i);
user.setPassword("123");
user.setPhone("" + (18688190000L + i));
user.setBalance(2000);
user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");
user.setCreateTime(LocalDateTime.now());
user.setUpdateTime(user.getCreateTime());
return user;
}
在这两种处理方案中,第一个 testSaveOneByOne 方法是逐个保存每个用户的数据,而第二个 testSaveBatch 方法是批量保存用户数据。
下面是为什么批量保存会更快的一些原因:
- 减少数据库交互次数: 在逐个保存用户数据的方法中,每次保存都需要与数据库进行一次交互,包括建立连接、发送请求、执行操作、关闭连接等,这些操作会产生较大的开销。而批量保存可以将多条数据打包成一次请求发送到数据库,减少了大量的数据库交互次数,从而节省了时间。
- 减少事务开销: 在数据库中,每次保存操作通常都会包含一个事务。在逐个保存的方法中,每次保存都会启动一个新的事务,这会增加事务管理的开销,包括事务的开始、提交和回滚等操作。而批量保存可以将多个保存操作合并到一个事务中,减少了事务管理的开销。
- 优化数据库写入性能: 数据库在处理批量数据插入时通常会有一些优化措施,例如批量插入语句的执行计划优化、预分配内存空间、减少日志记录等,这些优化可以提高数据库写入性能,从而加快批量保存的速度。
批量保存数据可以减少数据库交互次数、减少事务开销,并且可以享受数据库的写入性能优化,因此通常会比逐个保存数据的方式更快。
想要实现真正最快最好的批量插入 的将插入的SQL变成这样
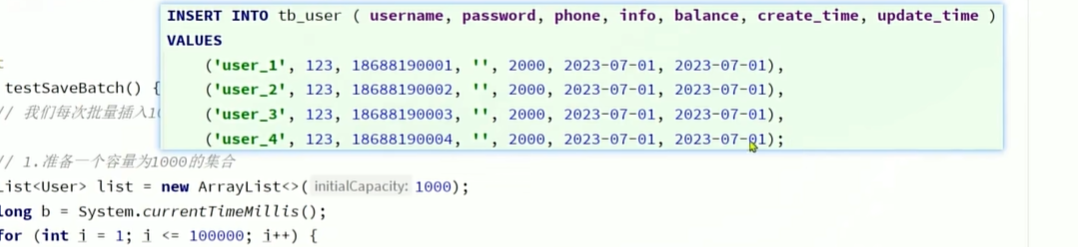
- 这样虽然写了很多数据但对数据库来说只是一个插入操作
MySQL的客户端连接参数中有这样的一个参数:rewriteBatchedStatements。顾名思义,就是重写批处理的statement语句。参考文档:
https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-connp-props-performance-extensions.html#cj-conn-prop_rewriteBatchedStatements
这个参数的默认值是false,我们需要修改连接参数,将其配置为true
修改项目中的application.yml文件,在jdbc的url后面添加参数&rewriteBatchedStatements=true:
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
-
最后加上&rewriteBatchedStatements=true
-
这样就能实现批量插入

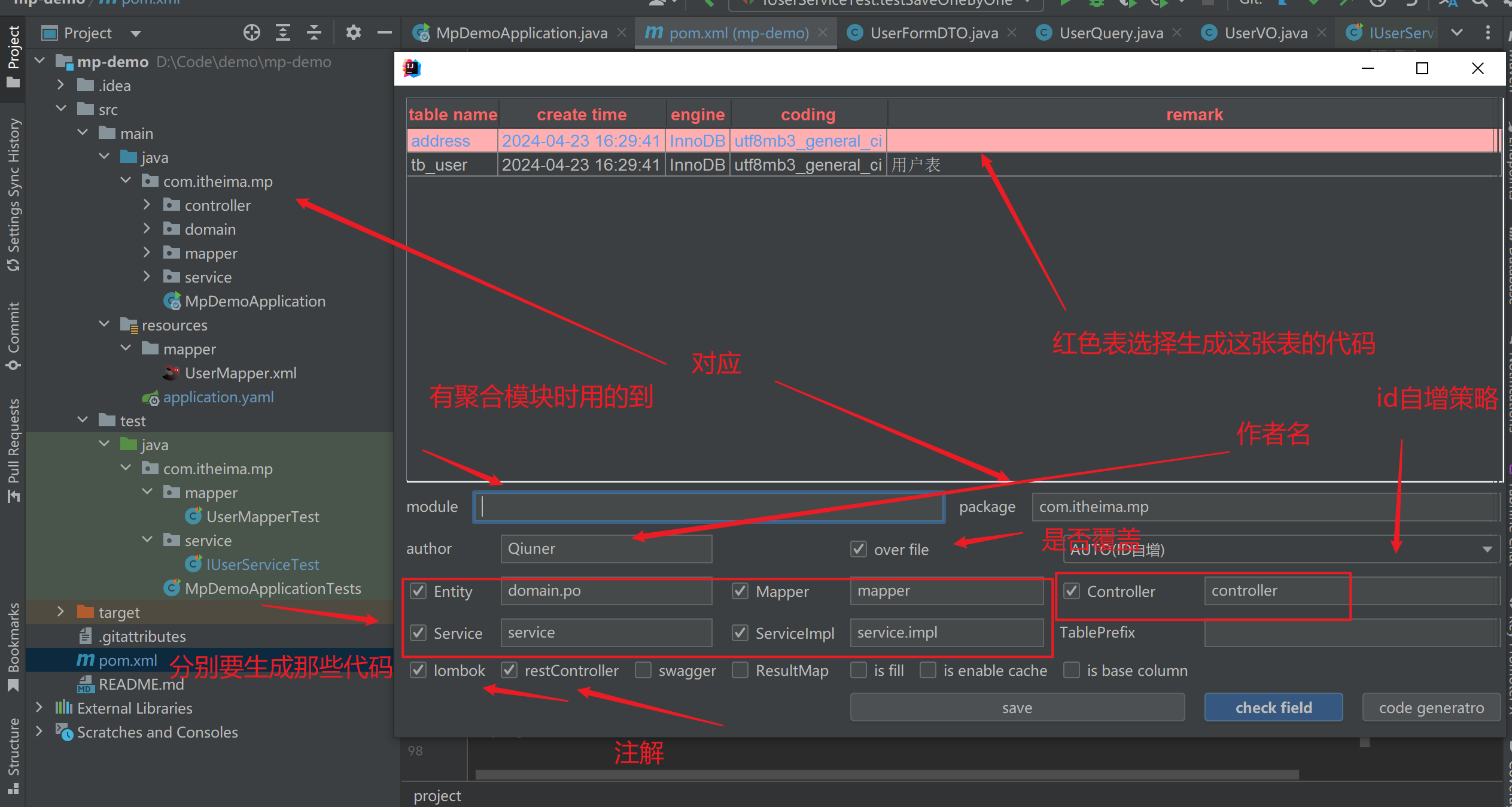
代码生成工具 MybatisPlus

讲师推荐的插件安装后 导航栏没有出现Other
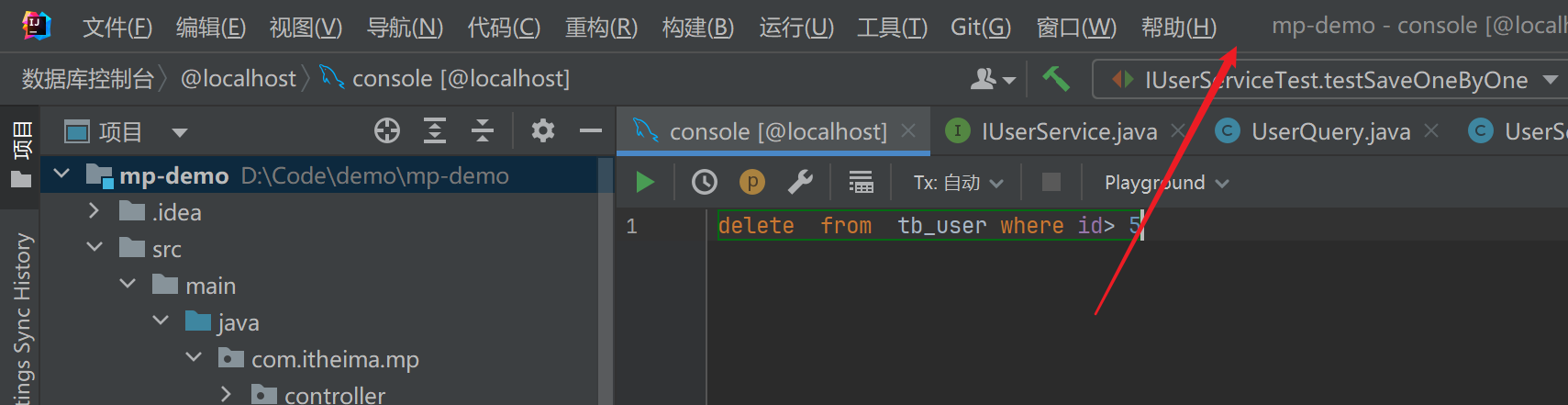

- 这是因为你的idea版本比较新
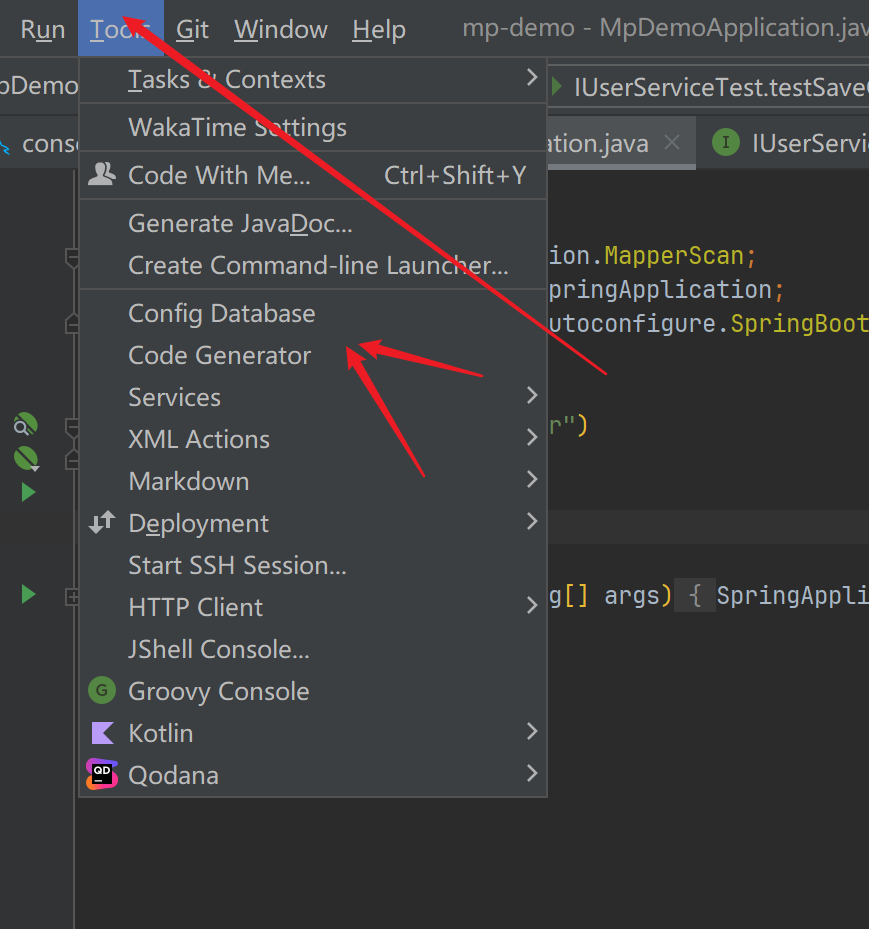
- 新版集成到这里了
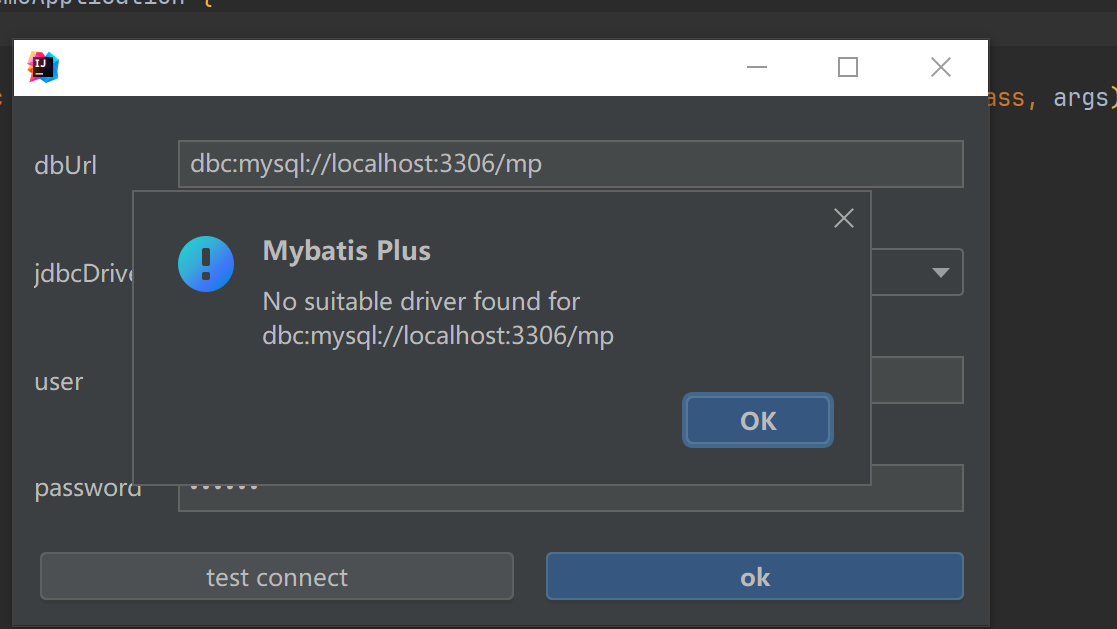
- 这里存在的问题,我也不知道怎么办 给项目加了JDBC的依赖也不行
- 我的解决方法是换成下面这个小蓝鸟
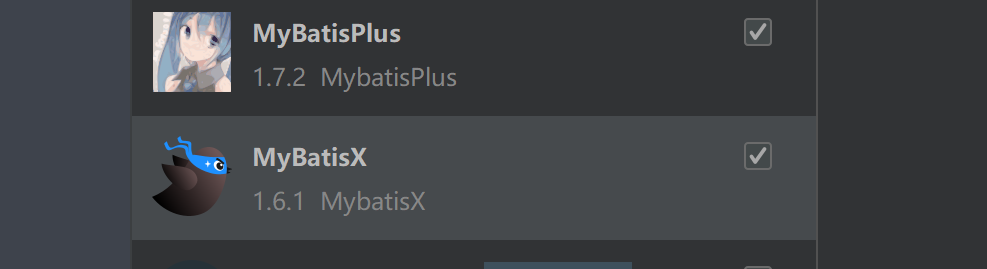
小蓝鸟怎么用 看我的另一篇文章
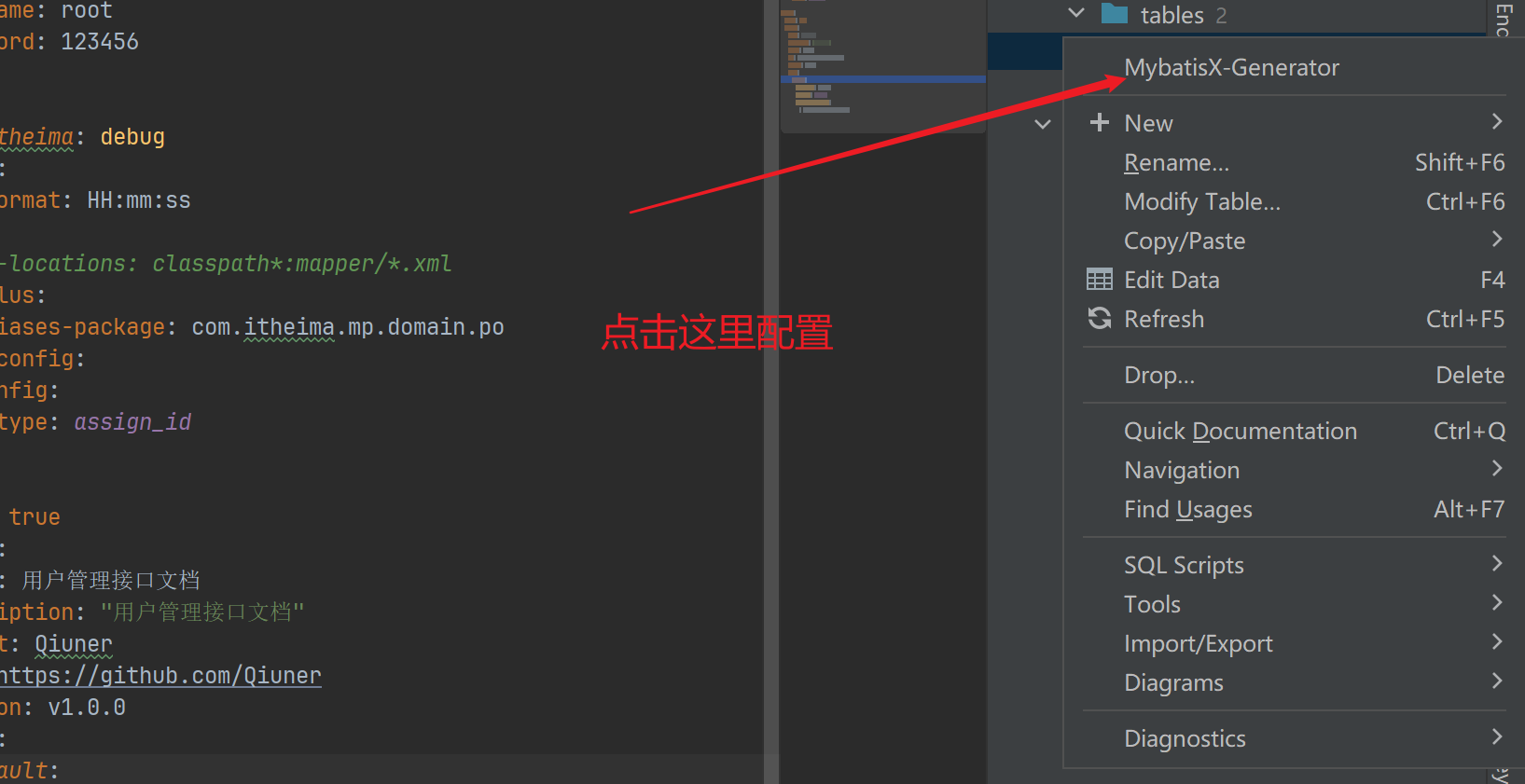
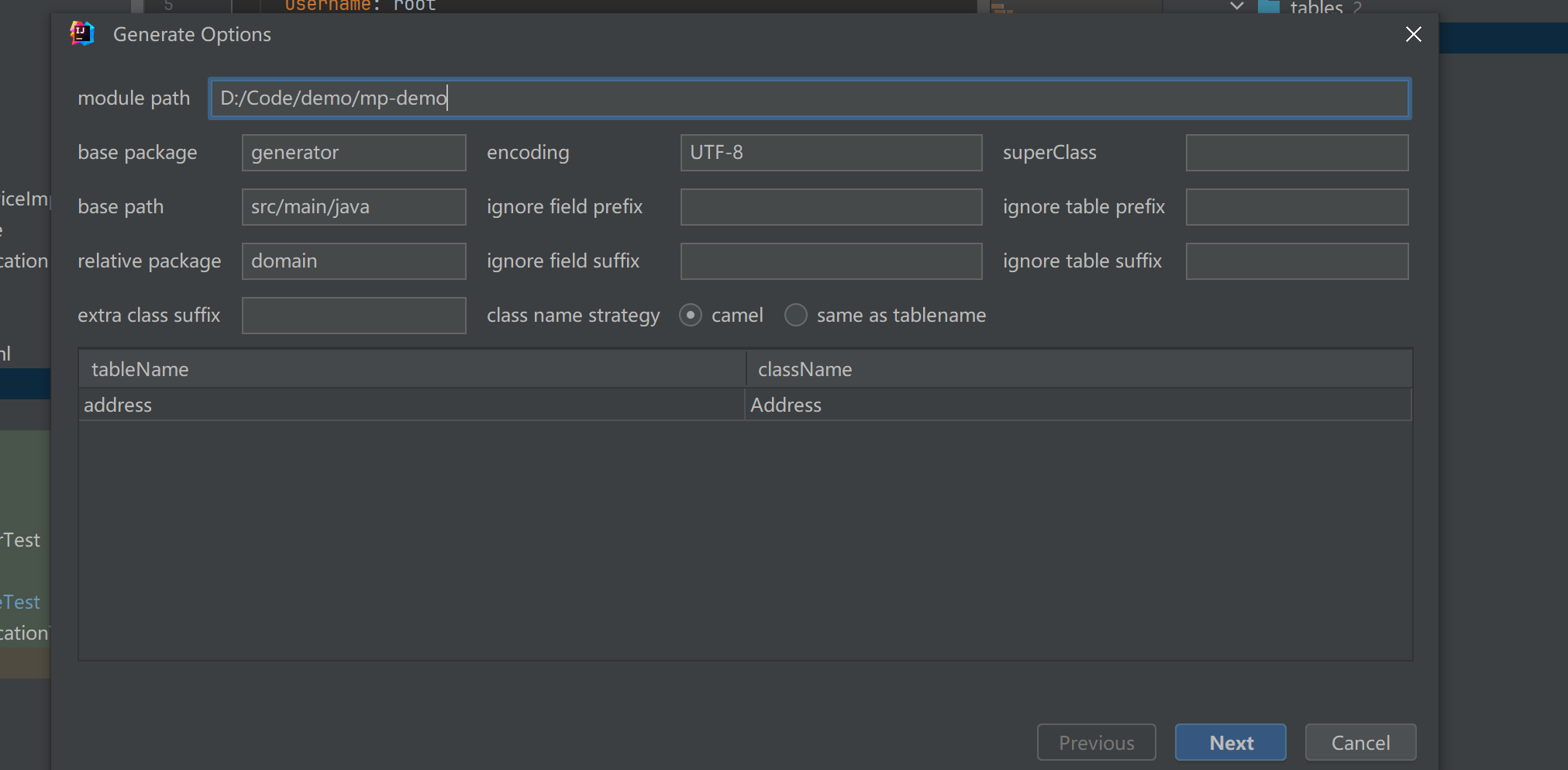
- 选择路径和其他配置项
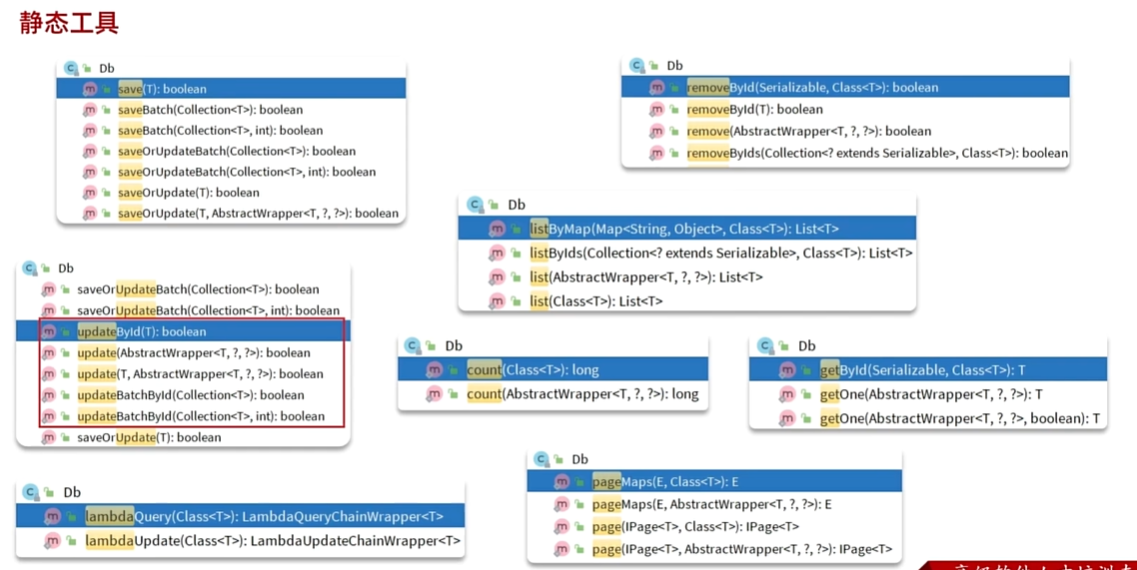
静态工具

静态工具使用报错 The server time zone value ‘�й���ʱ��’ is unrecognized or represents more than one time zone. You must configure either the server or JDBC driver (via the serverTimezone configuration property) to use a more specifc time zone value if you want to utilize time zone support.
问题描述
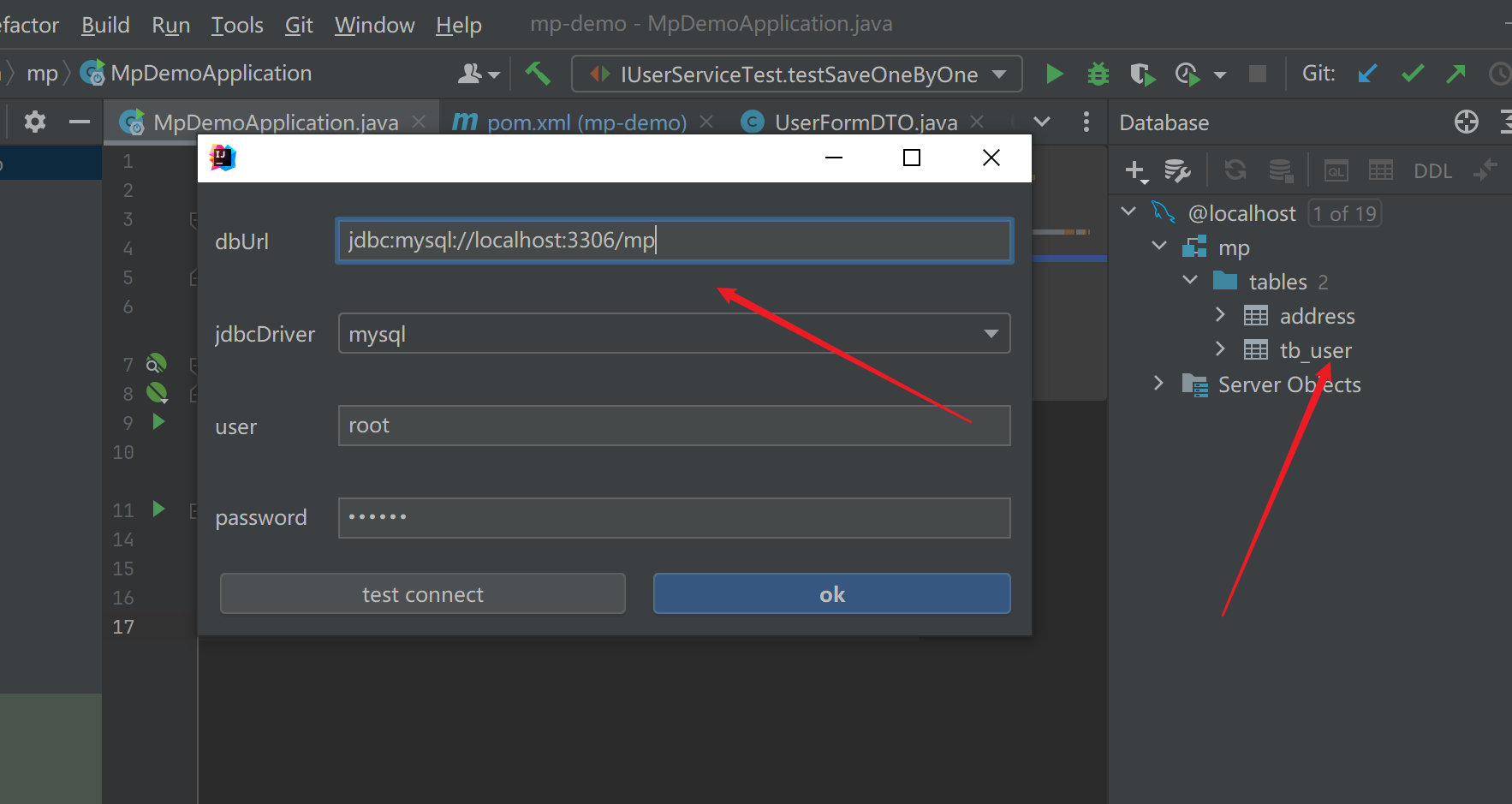
- 数据库连接没有问题,JDBC依赖也导入了
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.28</version> <!-- JDBC依赖 -->
</dependency>
- 但显示
解决办法
- 这是你没有设置时区 下面设置的是中国的时区 这里时区要设置成自己国家的 不然生成不出来
jdbc:mysql://localhost:3306/mp?serverTimezone=Asia/Shanghai
静态Db
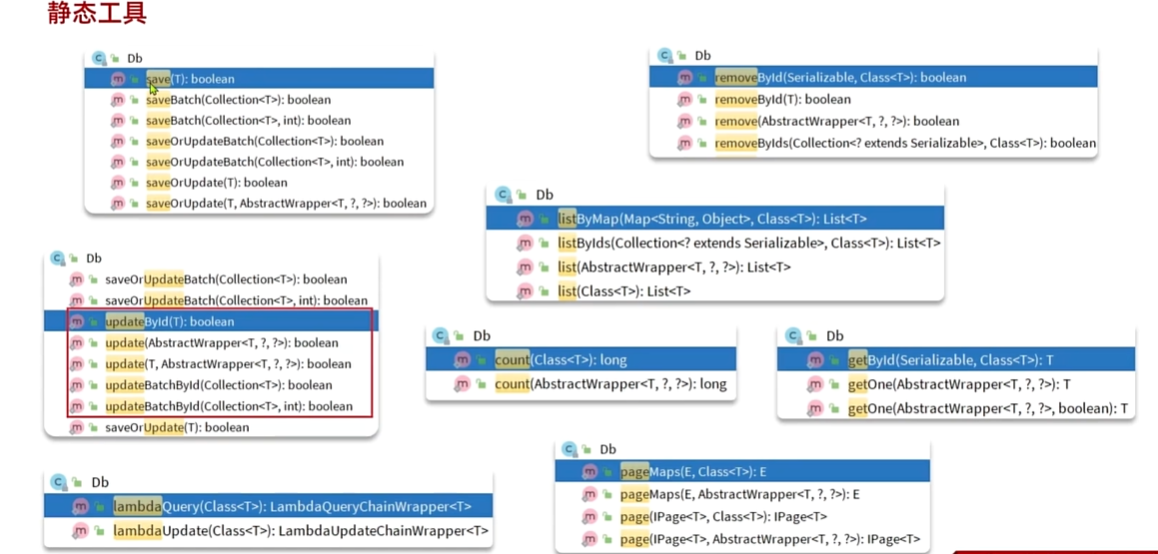
依赖注入的核心思想是将类的依赖关系从类本身解耦,使得类更加灵活、可测试和可维护。
两个类相互注入可能会导致循环依赖的问题。循环依赖指的是两个或多个类之间存在直接或间接的依赖关系,使得它们无法被实例化。例如,类 A 依赖于类 B,而类 B 又依赖于类 A,这样的情况就会导致循环依赖。
循环依赖可能会导致以下问题:
- 编译错误或运行时异常:在解析类之间的依赖关系时,编译器或运行时容器可能会无法确定类的实例化顺序,导致编译错误或运行时异常。
- 性能问题:循环依赖可能导致对象的创建和初始化过程变得复杂,影响程序的性能。
- 可维护性问题:循环依赖会增加代码的复杂性,降低代码的可读性和可维护性。
为了避免循环依赖,可以考虑以下几种方法:
- 重构类设计:尽量避免直接相互依赖,可以考虑通过接口、抽象类或事件总线等方式来解耦类之间的关系。
- 使用延迟初始化:在需要时才初始化对象,避免在类的构造函数中直接注入其他类的实例。
- 使用依赖注入容器:一些依赖注入容器(如Spring)提供了解决循环依赖的机制,可以通过配置或注解来处理循环依赖的情况。
为什么要在DTO中加上VO
- 数据传输的灵活性:通过将地址信息作为 AddressVO 类独立出来,使得在用户表单实体 UserFormDTO 中可以通过引用 AddressVO 类来包含多个收货地址。这样设计使得用户表单实体可以轻松地与收货地址相关联,同时避免了将地址信息直接嵌入到用户表单实体中的复杂性。
- 代码复用性:通过将收货地址信息抽象为 AddressVO 类,可以在系统的其他地方复用这个类,例如在订单模块中也可能需要使用收货地址信息。这样可以避免代码重复,并提高了系统的可维护性。
- 可扩展性:由于地址信息被抽象成了单独的类,如果将来需要添加更多与收货地址相关的字段或功能,可以直接在 AddressVO 类中进行扩展,而不需要修改用户表单实体 UserFormDTO。这样可以减少对现有代码的影响,降低了系统的耦合度。
- 清晰的数据结构:将用户表单实体和收货地址实体分开设计,使得数据结构更加清晰明了,易于理解和维护。同时,使用
根据用户查询id处爆红
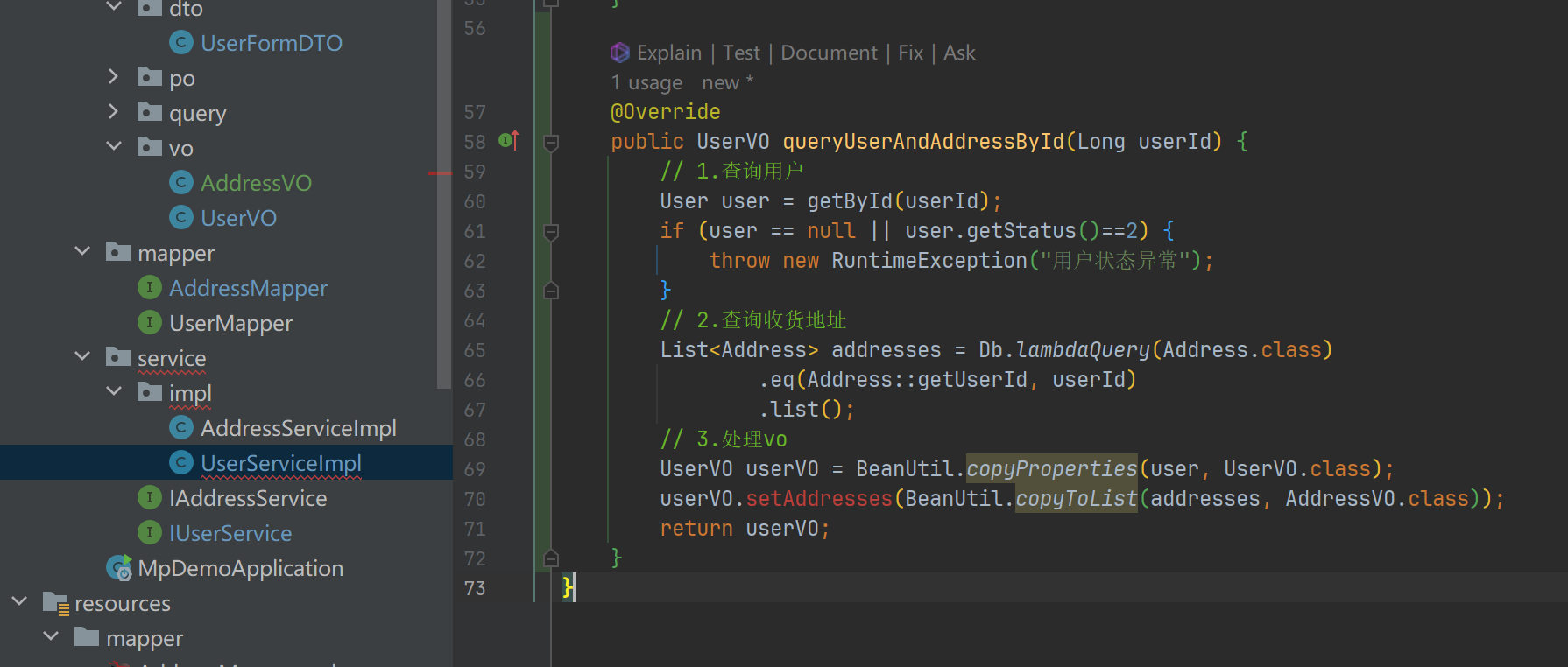
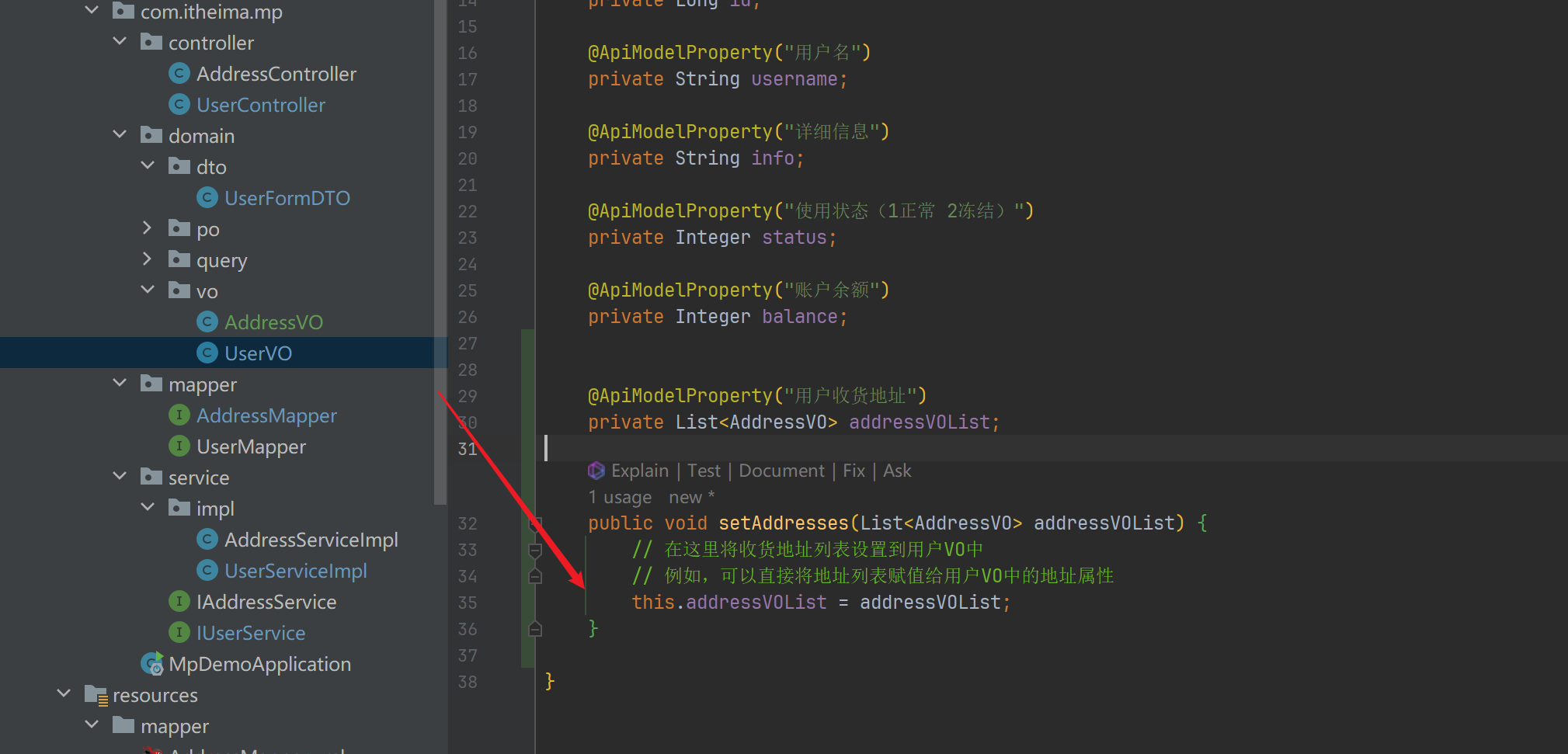
- 加上上面这个即可
public void setAddresses(List<AddressVO> addressVOList) {
// 在这里将收货地址列表设置到用户VO中
// 例如,可以直接将地址列表赋值给用户VO中的地址属性
this.addressVOList = addressVOList;
}
-
这样就避免了相互依赖
-
互相依赖有不少点可以说的 等过些时候我开篇文详细说说
批量查询
@Override
public List<UserVO> queryUserAndAddressByIds(List<Long> ids) {
return List.of();
}
@Override
public List<UserVO> queryUserAndAddressByIds(List<Long> ids) {
// 1 查询用户
List<User> users = listByIds(ids);
if (CollUtil.isEmpty(users)) {
return Collections.emptyList();
}
// 2 查询地址 获取用户集合
List<Long> userIds = users.stream().map(User::getId).collect(Collectors.toList());
// 2.2 根据用户id查询地址
List<Address> addresses = Db.lambdaQuery(Address.class).in(Address::getUserId, userIds).list();
// 3 处理vo
List<UserVO> userVOS = BeanUtil.copyToList(users, UserVO.class);
userVOS.forEach(userVO -> {
List<AddressVO> addressVOS = BeanUtil.copyToList(
addresses.stream()
.filter(address -> address.getUserId().equals(userVO.getId()))
.collect(Collectors.toList()),
AddressVO.class);
userVO.setAddresses(addressVOS);
});
return userVOS;
}
- 这是我写的 和老师有所出入 uu们可以自己看看
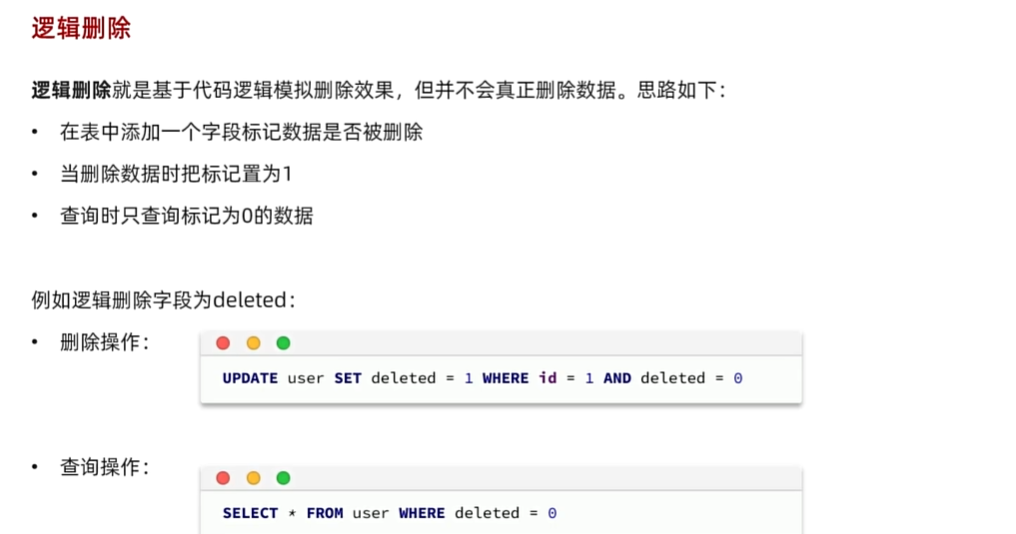
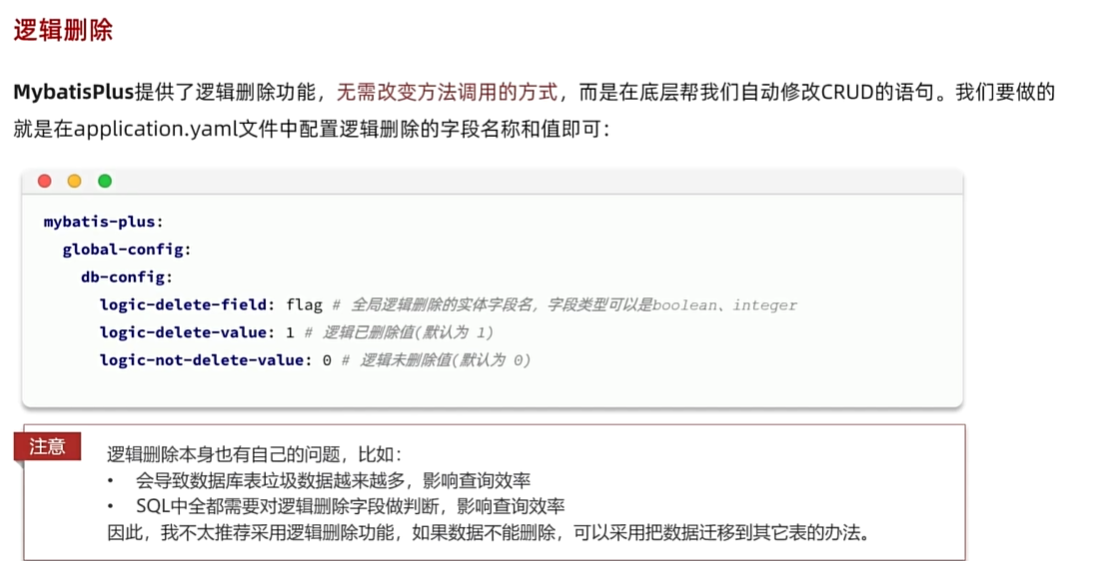
逻辑删除
枚举处理器
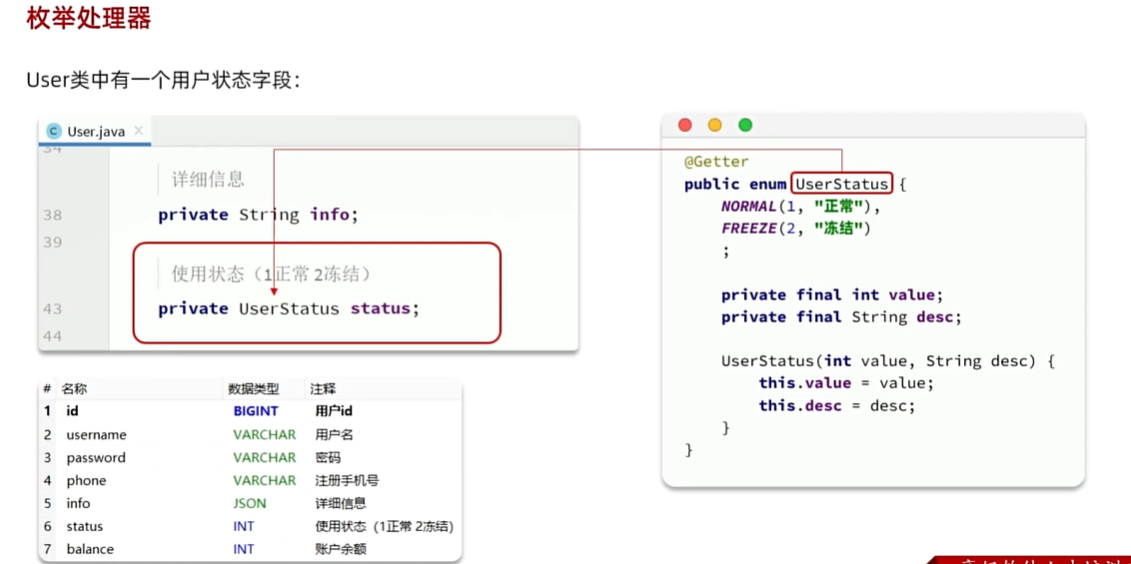
- mybatis实现了类型的int枚举类型转换
- MP的扩展
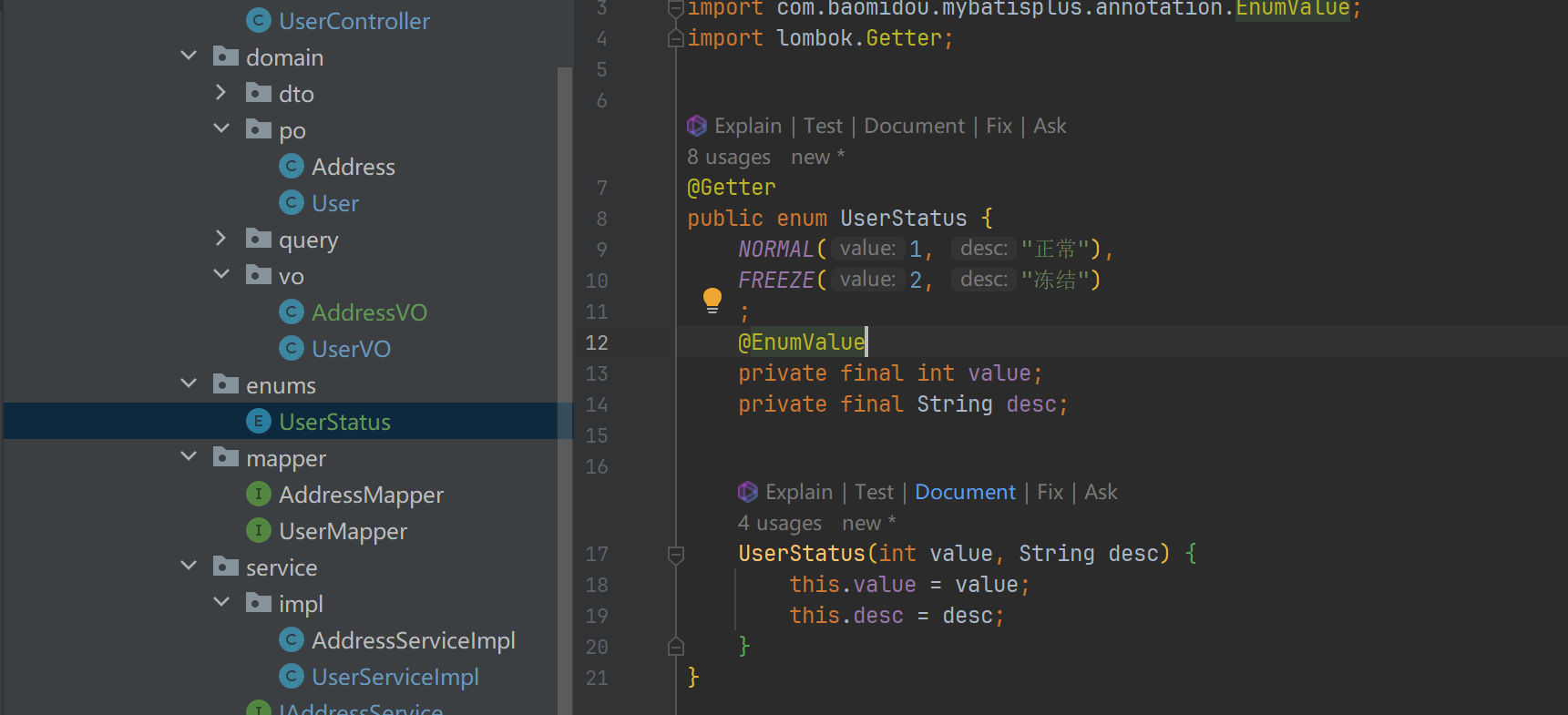
报错ava.lang.IllegalArgumentException: Could not find @EnumValue in Class: com.itheima.mp.enums.UserStatus. at com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler.lambda$new$0(MybatisEnumTypeHandler.java:65) ~[mybatis-plus-core-3.5.3.1.jar:3.5.3.1]
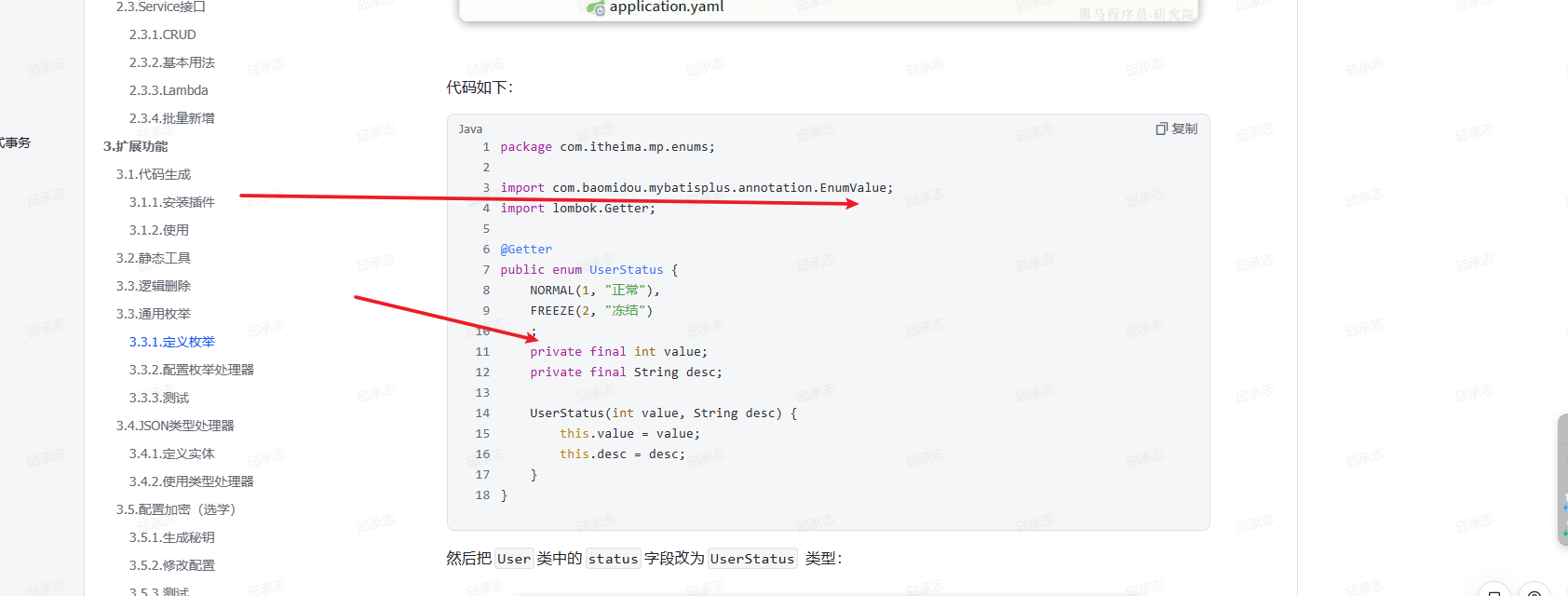
- 这里官方文档给的代码有错
package com.itheima.mp.enums;
import com.baomidou.mybatisplus.annotation.EnumValue;
import lombok.Getter;
@Getter
public enum UserStatus {
NORMAL(1, "正常"),
FREEZE(2, "冻结")
;
@EnumValue
private final int value;
private final String desc;
UserStatus(int value, String desc) {
this.value = value;
this.desc = desc;
}
}

@EnumValue 和 @JsonValue 是两个注解,通常用于在 Java 枚举类中定义枚举值的序列化和反序列化方式。
-
@EnumValue:
- 用于标识枚举类中表示数据库存储值的字段。
- 在 MyBatis Plus 中,当将枚举值持久化到数据库时,会使用被
@EnumValue注解标记的字段的值。这个值应该是枚举类中定义的一个整数字段,通常用来表示数据库中的实际存储值。
-
@JsonValue:
-
用于标识枚举类中表示枚举值描述的字段。
-
在序列化枚举值时,会使用被
@JsonValue注解标记的字段的值作为 JSON 字符串的值。
-
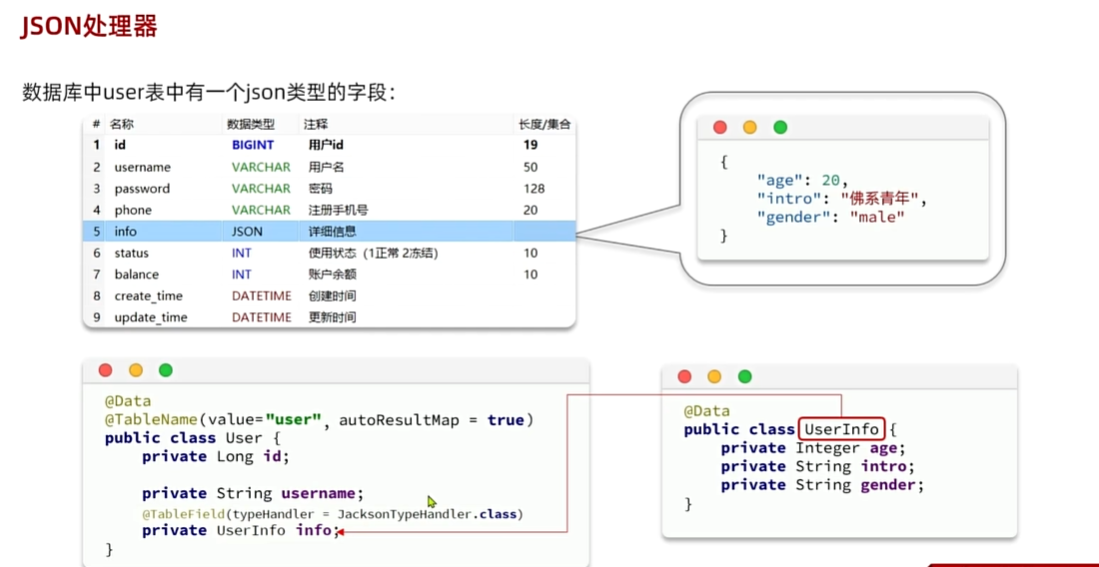
JSON处理器
- 这里在官方文档中记载的很详细
- 因为数据库中的数据是json格式的数据而在实体类中确实String类型 为了解决这件事,所以使用JSON处理器
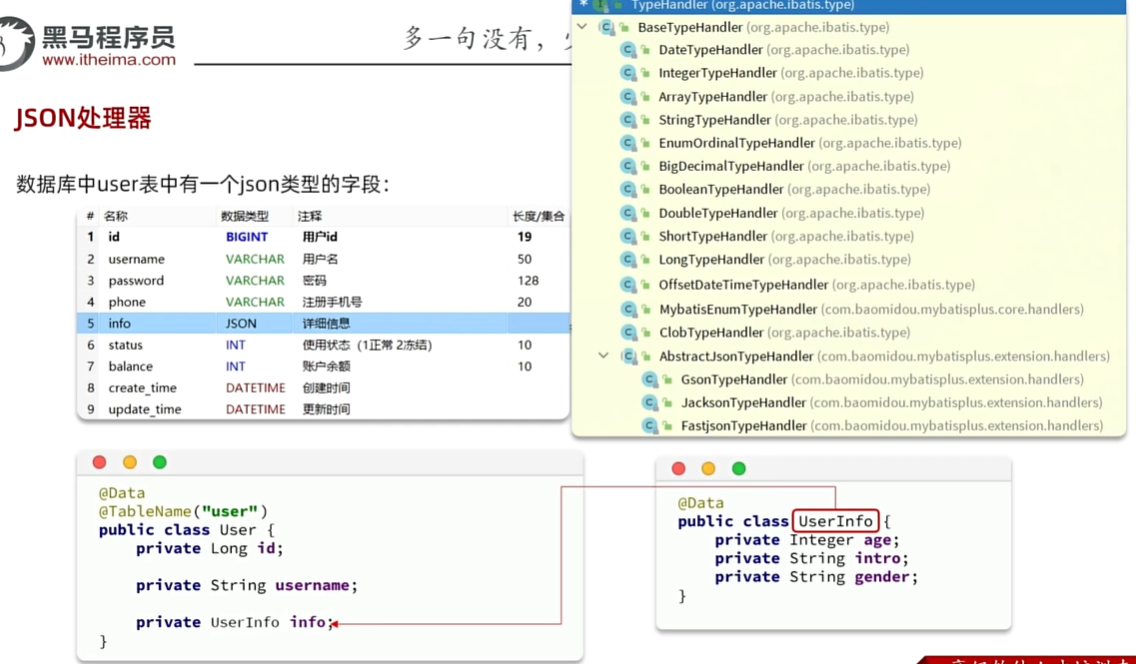
- 使用TableField
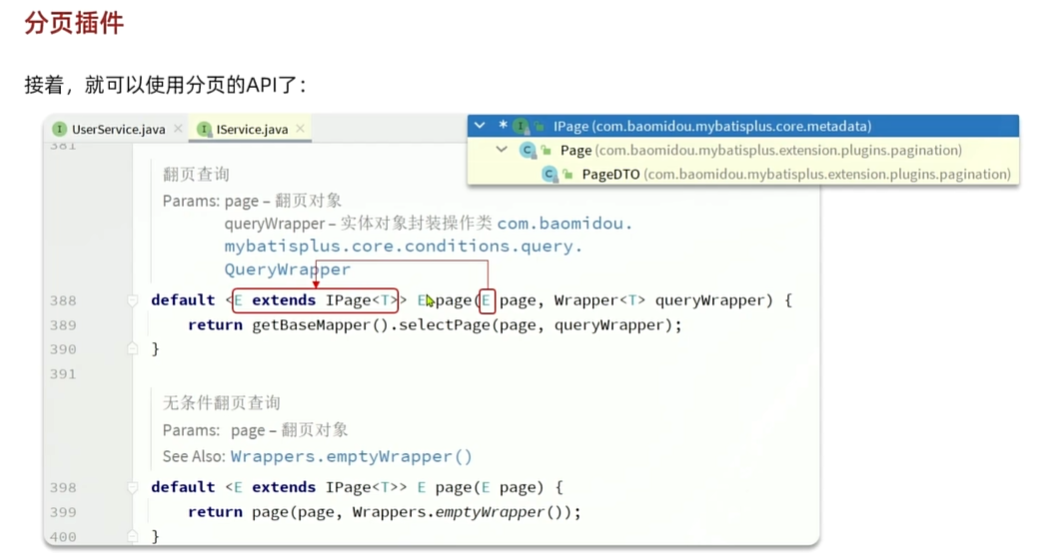
MybatisPlus 内部拦截器

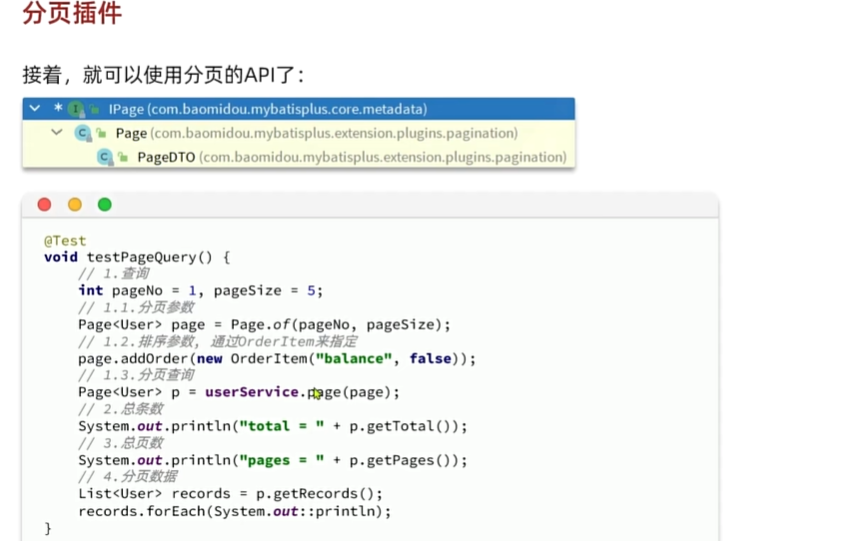
实现分页查询

通用分页实体

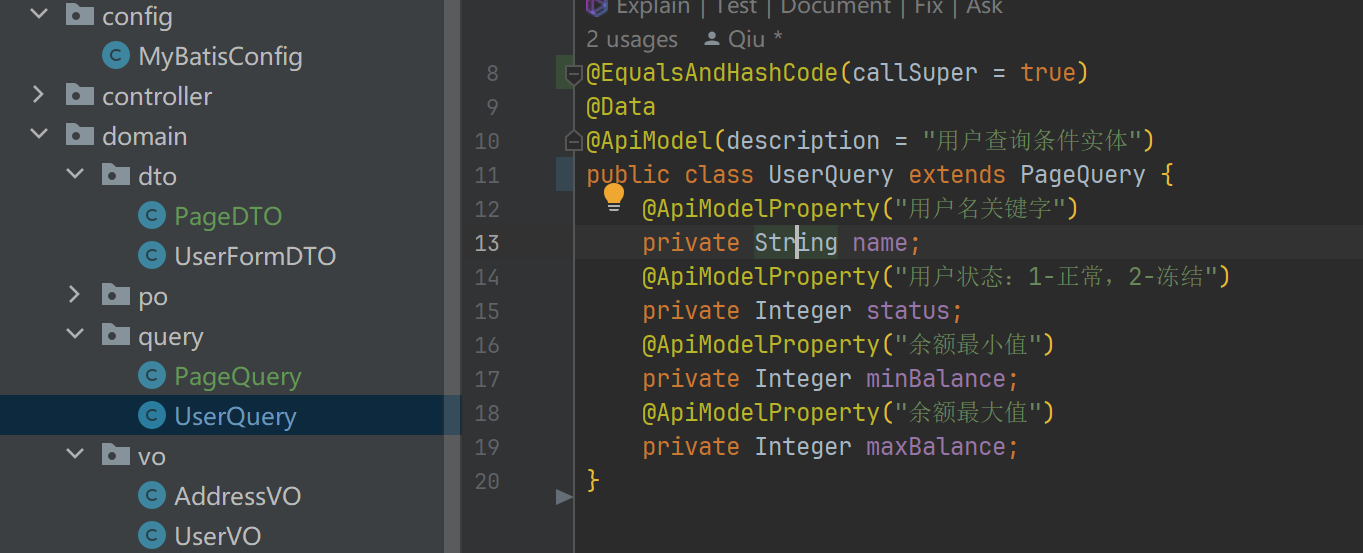
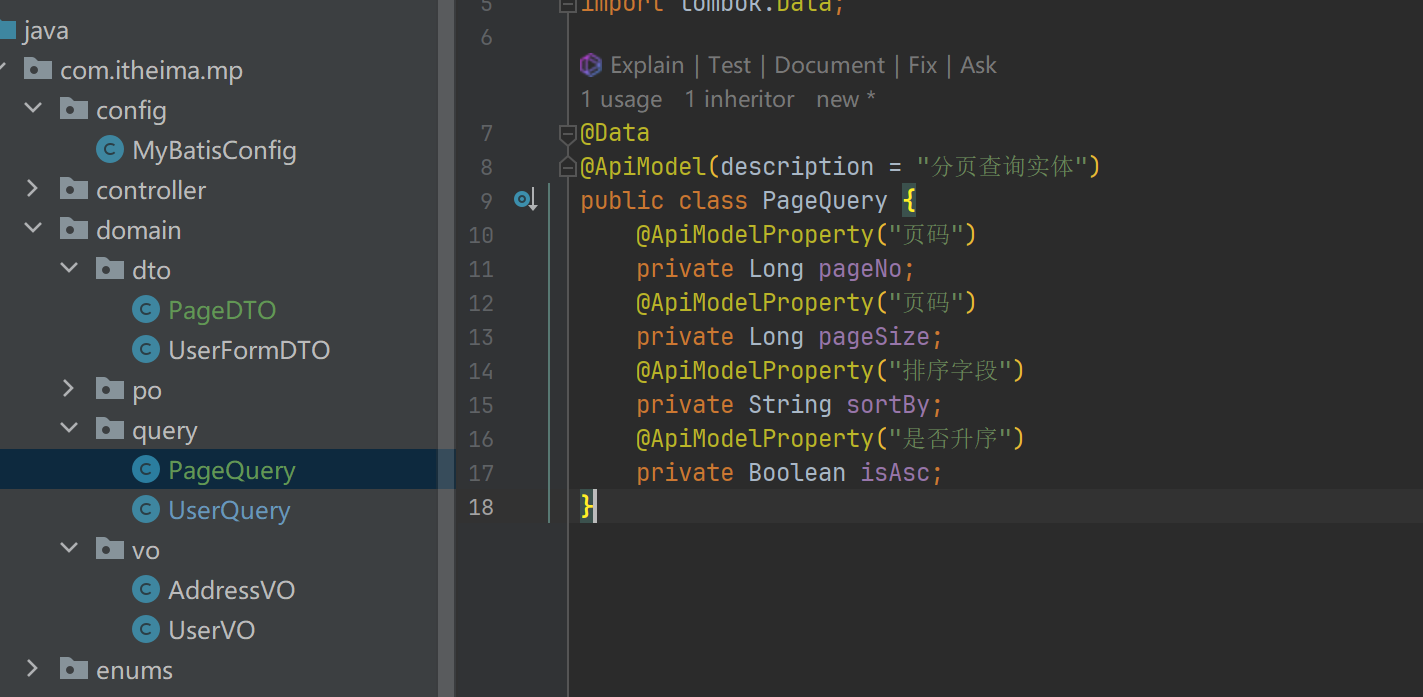
- 这里因为分页查询是通用的 因此封装起来
通用分页实体和MP转换
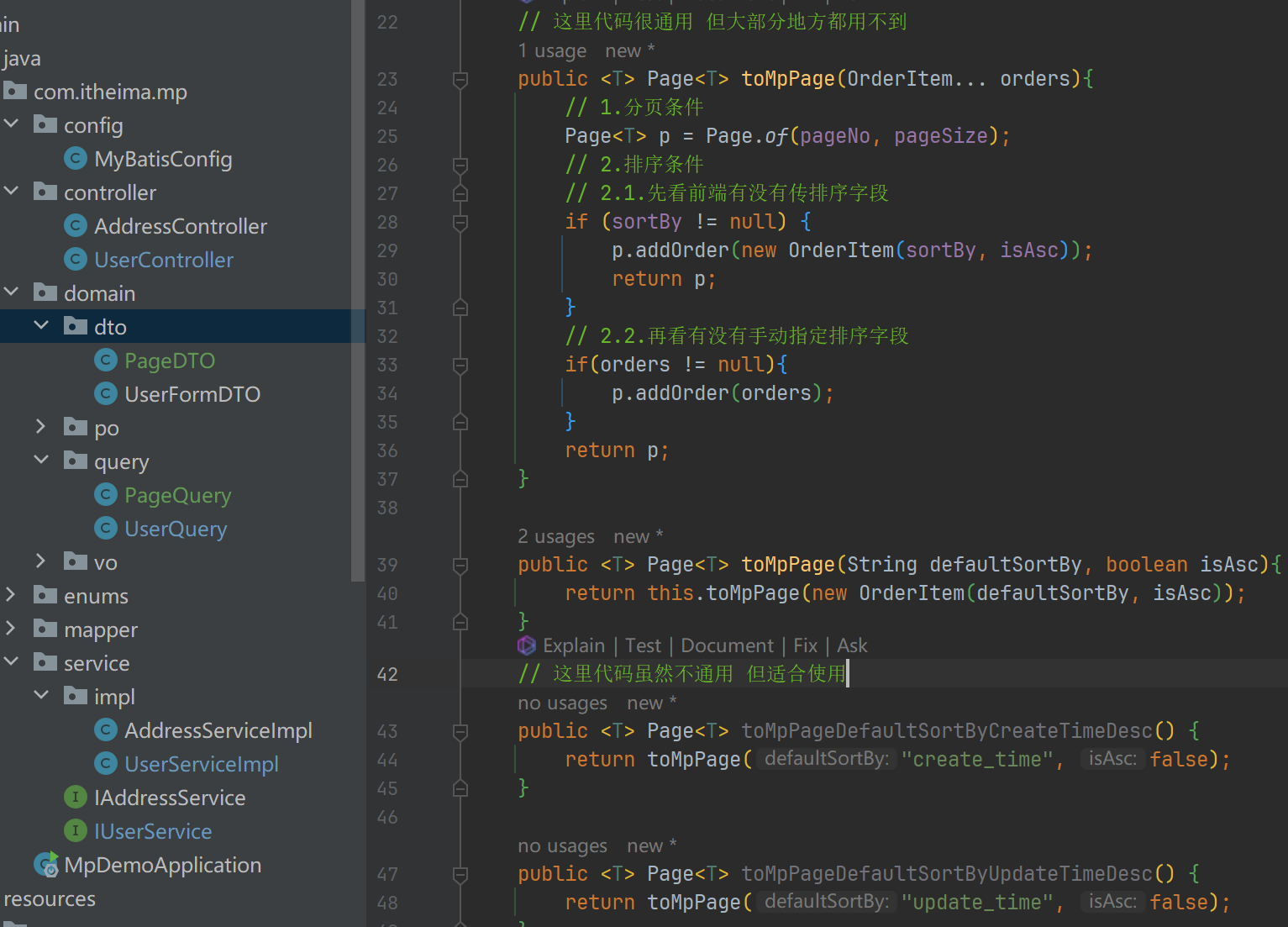
从PageQuery到MybatisPlus的Page之间转换的过程比较麻烦的


















 2439
2439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











