







XXL-JOB
我们可以思考一下下面业务场景的解决方案:
- 某电商平台需要每天上午10点,下午3点,晚上8点发放一批优惠券
- 某银行系统需要在信用卡到期还款日的前三天进行短信提醒
- 某财务系统需要在每天凌晨0:10分结算前一天的财务数据,统计汇总
以上场景就是任务调度所需要解决的问题
任务调度是为了自动完成特定任务,在约定的特定时刻去执行任务的过程
而任务氛围多种:(我的理解)
- 固定周期
- 动态周期
对于固定周期,也就是每个用户固定的时间点,或者系统在固定的时间点会做的任务;
对于动态周期,也就是根据不同用户,会有不同的执行时间点/执行周期的任务;
1. 没有 XXL-JOB 怎么实现?
我能想到的有三种:
- Java 的 Timer 计时器
- Java 的定时线程池
- Spring 的 @Scheduled 任务调度
1.1 本地线程
对于第一第二种,其实是同类的,就是本地线程,去控制定时任务,优点就是,固定周期和动态周期都能实现,但是缺点也很多,时间控制很麻烦,只能在一个应用里,应用停止,任务就会结束,重启需要恢复任务;
1.2 Spring 注解
Spring 的 @Scheduled 进行任务调度
在业务类中方法中贴上这个注解,然后在启动类上贴上@EnableScheduling注解
@Scheduled(cron = "0/20 * * * * ? ")
public void doWork(){
//doSomething
}
优点就是,简单方便,快速实现固定周期,但是缺点也有,无法实现动态周期;
1.3 都无法解决的问题
-
耗资源:开定时线程是需要消耗内存的,任务堆积一多可能就会影响主服务的性能,毕竟任务调度并不是我们的主要业务;
-
高可用:单机版的定式任务调度只能在一台机器上运行,如果程序或者系统出现异常就会导致功能不可用。
-
防止重复执行:在单机模式下,定时任务是没什么问题的。但当我们部署了多台服务,同时又每台服务又有定时任务时,若不进行合理的控制在同一时间,只有一个定时任务启动执行,这时,定时执行的结果就可能存在混乱和错误了
-
单机处理极限:原本1分钟内需要处理1万个订单,但是现在需要1分钟内处理10万个订单;原来一个统计需要1小时,现在业务方需要10分钟就统计出来。你也许会说,你也可以多线程、单机多进程处理。的确,多线程并行处理可以提高单位时间的处理效率,但是单机能力毕竟有限(主要是CPU、内存和磁盘),始终会有单机处理不过来的情况。
-
不好管理,执行失败了无法重试与统计;
-
需要执行一个临时的任务,或者我只是想执行一次某个任务在我想执行的时候,不是很方便;
而 XXL-JOB 很好的解决了上述问题
2. XXL-JOB 介绍
XXL,xvxueli, https://www.xuxueli.com/xxl-job/
XXL-Job:是大众点评的分布式任务调度平台,是一个轻量级分布式任务调度平台, 其核心设计目标是开发迅速、学习简单、轻量级、易扩展
大众点评目前已接入XXL-JOB,该系统在内部已调度约100万次,表现优异。
目前已有多家公司接入xxl-job,包括比较知名的大众点评,京东,优信二手车,360金融 (360),联想集团 (联想),易信 (网易)等等
系统架构图

设计思想
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的 JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;

- 关联起来后,在XXL-JOB就可以针对执行器的某个处理器创建任务,每次触发执行器,执行器都会运行处理器对应的代码;
- 服务端可以根据执行器的任务处理器的名字,动态发布任务,让XXL-JOB去管理调度的时机,这样就不需要本地线程去控制任务执行了,发布完后,服务器就压根就把任务抛之脑后,XXL-JOB通知执行的时候,执行器自然就会执行;
也就是说,服务器只管等着通知执行就好了,其他啥的交给XXL-JOB;
- 你可能现在还有问题,怎么保证执行器执行的业务是我们想要的效果呢?
- 对于固定周期任务,同一段代码处理的业务是一样的,所以本来就可以达到我们的效果
- 对于动态周期任务,执行器执行不同用户的任务的时候确实不同,而 XXL-JOB 的任务调度还引入**“任务参数”**,也就是说我们在业务中,处理器代码通过任务参数面向不同用户即可;
- 因为一个用户一个处理器本来就不可能
3. 快速入门
源码下载地址:
https://github.com/xuxueli/xxl-job
https://gitee.com/xuxueli0323/xxl-job
运行其提供的 sql,然后在 IDEA 打开,修改一下配置文件:
- 路径
- 不做修改,那么XXL-JOB的访问路径就是:
http://127.0.0.1:8080/xxl-job-admin
- 不做修改,那么XXL-JOB的访问路径就是:

- 数据库密码

- 邮箱信息
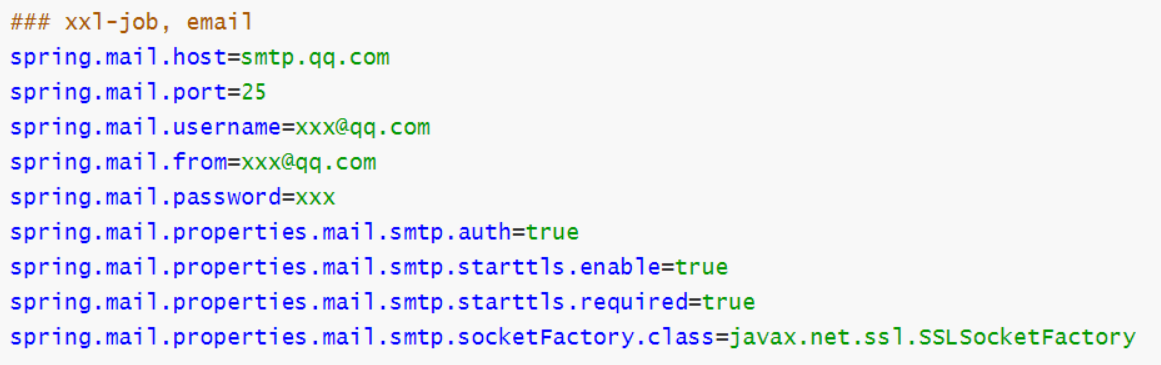
- 其他
- 其他配置顾名思义,或者查阅资料有需要就修改
注意,用户名和密码不是在这里修改的,默认是 admin 123456
IDEA 运行(就跟平时一样)后,可以在访问可视化页面了,任务你需要修改密码,就在用户管理那修改、添加普通用户、添加管理员;
目前我们还不能创建我们自己的项目的任务,因为我们的项目还没对接上 XXL-JOB~
引入XXL-JOB提供的依赖:
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.1</version>
</dependency>
配置:
xxl:
job:
host: http://127.0.0.1
port: # port
admin:
addresses: ${xxl.job.host}:${xxl.job.port}/xxl-job-admin
username: # username
password: # password
accessToken: default_token
executor:
title: Lbcmmszdn
appname: xxl-job-executor-sample
address:
ip: 127.0.0.1
port: 9999
logpath: /data/applogs/xxl-job/jobhandler
logretentiondays: 30
addressType: 1
addressList: http://127.0.0.1:9999
url:
login: /login
groupPageList: /jobgroup/pageList
infoPageList: /jobinfo/pageList
groupSave: /jobgroup/save
infoAdd: /jobinfo/add
infoStart: /jobinfo/start
infoIds: /jobinfo/ids
infoStopIds: /jobinfo/stopids
infoRemove: /jobinfo/remove
@Data public class Admin { private String addresses; private String username; private String password; }@Data public class Executor { private String title; private String appname; private String address; private String ip; private Integer port; private String logpath; private Integer logretentiondays; private String addressType; private String addressList; }@Data public class XxlUrl { private String login; private String groupPageList; private String infoPageList; private String groupSave; private String infoAdd; private String infoStart; private String infoIds; private String infoStopIds; private String infoRemove; }
配置类:
@Setter
@Getter
@Configuration
@ConfigurationProperties(prefix = "xxl.job")
public class XxlJobConfig {
private Admin admin;
private String accessToken;
private Executor executor;
private XxlUrl url;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(admin.getAddresses());
xxlJobSpringExecutor.setAppname(executor.getAppname());
xxlJobSpringExecutor.setAddress(executor.getAddress());
xxlJobSpringExecutor.setIp(executor.getIp());
xxlJobSpringExecutor.setPort(executor.getPort());
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(executor.getLogpath());
xxlJobSpringExecutor.setLogRetentionDays(executor.getLogretentiondays());
return xxlJobSpringExecutor;
}
@Bean
public Admin admin() {
return admin;
}
@Bean
public Executor executor() {
return executor;
}
@Bean
public XxlUrl xxlUrl() {
return url;
}
}
通过以上参数,就相当于声明了针对一个任务调度平台 XXL-JOB 的执行器了~
4. 可视化界面创建一个任务
首先,得在业务代码定义处理器:
- 必须在注入容器的类中定义
- 任务处理器,代表的就是一个“任务模型”,并没有归属必须是哪个执行器才能执行
@Component
public class SimpleXxlJob {
@XxlJob("demoJobHandler")
public void demoJobHandler() throws Exception {
System.out.println("执行定时任务,执行时间:"+new Date());
}
}
还有就是实现 IJobHandler,这个比较麻烦,一般写临时处理器才会用到,平时用注解会方便很多;
创建一个执行器:
- 这里趋向于将任务分组,组名就是这里的title名称,同一个title里的任务被同一个执行器(分组)执行;
- 同一个appname就是同一个执行器(机器),默认的执行器(机器)是由XXL-JOB申请的;

创建一个任务:
- 这里就是通过指定执行器(分组)的名字,处理器的名字,需要保证能够对应上唯一那段代码!
- 任务处理器 JobHandler,代表的就是一个“任务模型”,并没有归属必须是哪个执行器才能执行,但是至少是服务器绑定的执行器(机器),这样才有可能被执行,执行器(分组)不限制

根据情况创建一下就行,CRON 表达式可以查阅资料了解一下
设置报警邮件也很有必要
对任务可以进行操作:

- 对于一些任务,像执行一次就点个按钮就行了,很方便!
可以查看日志:
5. 在业务中定义任务并自动创建执行器,自动创建任务(固定周期任务的发布)
XxlJobGroup 和 XxlJobInfo 框架并没有提供,要从 XXL-JOB 源码哪里 CV 过来:
@Getter
@Setter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class XxlJobGroup {
private int id;
private String appname;
private String title;
private int addressType; // 执行器地址类型:0=自动注册、1=手动录入
private String addressList; // 执行器地址列表,多地址逗号分隔(手动录入)
private Date updateTime;
// registry list
private List<String> registryList; // 执行器地址列表(系统注册)
public List<String> getRegistryList() {
if (addressList!=null && addressList.trim().length()>0) {
registryList = new ArrayList<String>(Arrays.asList(addressList.split(",")));
}
return registryList;
}
}
@Getter
@Setter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class XxlJobInfo {
private int id; // 主键ID
private int jobGroup; // 执行器主键ID
private String jobDesc;
private Date addTime;
private Date updateTime;
private String author; // 负责人
private String alarmEmail; // 报警邮件
private String scheduleType; // 调度类型
private String scheduleConf; // 调度配置,值含义取决于调度类型
private String misfireStrategy; // 调度过期策略
private String executorRouteStrategy; // 执行器路由策略
private String executorHandler; // 执行器,任务Handler名称
private String executorParam; // 执行器,任务参数
private String executorBlockStrategy; // 阻塞处理策略
private int executorTimeout; // 任务执行超时时间,单位秒
private int executorFailRetryCount; // 失败重试次数
private String glueType; // GLUE类型 #com.xxl.job.core.glue.GlueTypeEnum
private String glueSource; // GLUE源代码
private String glueRemark; // GLUE备注
private Date glueUpdatetime; // GLUE更新时间-
private String childJobId; // 子任务ID,多个逗号分隔
private int triggerStatus; // 调度状态:0-停止,1-运行
private long triggerLastTime; // 上次调度时间
private long triggerNextTime; // 下次调度时间
public static XxlJobInfo of(Integer groupId, String jobDesc,
String author, String cron, String value,
String executorRouteStrategy, Integer triggerStatus,
String executorParam) {
return builder()
.scheduleType("CRON")
.glueType("BEAN")
.misfireStrategy("DO_NOTHING")
.executorBlockStrategy("SERIAL_EXECUTION")
.executorTimeout(0)
.executorFailRetryCount(0)
.glueRemark("GLUE代码初始化")
.executorParam(executorParam)
.jobGroup(groupId)
.jobDesc(jobDesc)
.author(author)
.scheduleConf(cron)
.executorHandler(value)
.executorRouteStrategy(executorRouteStrategy)
.triggerStatus(triggerStatus).build();
}
public static XxlJobInfoBuilder builder() {
return new XxlJobInfoBuilder();
}
}
自定义注解:
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface XxlRegister {
String cron();
String jobDesc() default "default jobDesc";
String author() default "default Author";
/*
* 默认为 ROUND 轮询方式
* 可选: FIRST 第一个
* */
String executorRouteStrategy() default "ROUND";
int triggerStatus() default 0;
}
项目启动的初始化任务:
@Component
@Slf4j
public class XxlJobAutoRegister implements ApplicationListener<ApplicationReadyEvent>,
ApplicationContextAware {
private ApplicationContext applicationContext;
@Autowired
private JobGroupService jobGroupService;
@Autowired
private JobInfoService jobInfoService;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
@Override
public void onApplicationEvent(ApplicationReadyEvent event) {
//注册执行器
addJobGroup();
//注册任务
addJobInfo();
}
//自动注册执行器
private void addJobGroup() {
jobGroupService.addJobGroup();
}
private void addJobInfo() {
XxlJobGroup xxlJobGroup = jobGroupService.getJobGroupOne(0);
String[] beanDefinitionNames = applicationContext.getBeanNamesForType(Object.class, Boolean.FALSE, Boolean.TRUE);
for (String beanDefinitionName : beanDefinitionNames) {
Object bean = applicationContext.getBean(beanDefinitionName);
Map<Method, XxlJob> annotatedMethods = MethodIntrospector.selectMethods(bean.getClass(),
(MethodIntrospector.MetadataLookup<XxlJob>) method -> AnnotatedElementUtils.findMergedAnnotation(method, XxlJob.class));
for (Map.Entry<Method, XxlJob> methodXxlJobEntry : annotatedMethods.entrySet()) {
Method executeMethod = methodXxlJobEntry.getKey();
XxlJob xxlJob = methodXxlJobEntry.getValue();
//自动注册
if (executeMethod.isAnnotationPresent(XxlRegister.class)) {
XxlRegister xxlRegister = executeMethod.getAnnotation(XxlRegister.class);
List<XxlJobInfo> jobInfo = jobInfoService.getJobInfo(xxlJobGroup.getId(), xxlJob.value());
if (!jobInfo.isEmpty()) {
//因为是模糊查询,需要再判断一次
Optional<XxlJobInfo> first = jobInfo.stream()
.filter(xxlJobInfo -> xxlJobInfo.getExecutorHandler().equals(xxlJob.value()))
.findFirst();
if (first.isPresent())
continue;
}
XxlJobInfo xxlJobInfo = createXxlJobInfo(xxlJobGroup, xxlJob, xxlRegister);
jobInfoService.addJob(xxlJobInfo);
}
}
}
}
private XxlJobInfo createXxlJobInfo(XxlJobGroup xxlJobGroup, XxlJob xxlJob, XxlRegister xxlRegister) {
return XxlJobInfo.builder()
.jobGroup(xxlJobGroup.getId())
.jobDesc(xxlRegister.jobDesc())
.author(xxlRegister.author())
.scheduleType("CRON")
.scheduleConf(xxlRegister.cron())
.glueType("BEAN")
.executorHandler(xxlJob.value())
.executorRouteStrategy(xxlRegister.executorRouteStrategy())
.misfireStrategy("DO_NOTHING")
.executorBlockStrategy("SERIAL_EXECUTION")
.executorTimeout(0)
.executorFailRetryCount(0)
.glueRemark("GLUE代码初始化")
.triggerStatus(xxlRegister.triggerStatus())
.build();
}
}
注册执行器和任务的实现不在这里演示了,代码链接:OKR-System/xxl-job-service/src/main/java/com/macaku/xxljob at main · CarefreeState/OKR-System (github.com)
GLUE 的意思差不多就是任务模型,差不多就是业务代码那个意思,我们这里的方式是Bean模式,一个处理器代码就是一个具体的GLUE
GLUE的全称是General Language Understanding Evaluation,在2018年,由纽约大学、华盛顿大学以及DeepMind的研究者们共同提出。这个基准由一系列自然语言理解数据集/任务组成,最主要的目标是鼓励开发出能够在任务之间共享通用的语言知识的模型。BERT正是建立在这样一种预训练知识共享的基础之上,在刚推出的时候狂刷11项GLUE任务的纪录,开启了一个新的时代。
例如以下示例,清除缓存的周期任务:
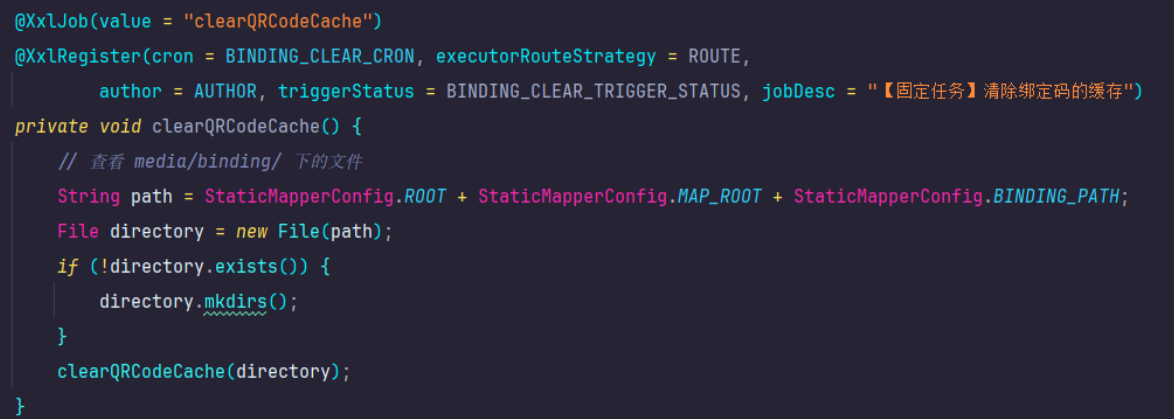
private final static String AUTHOR = "macaku";
private final static String ROUTE = "ROUND";
private final static String BINDING_CLEAR_CRON = "0 0/5 * * * ? *";
private final static int BINDING_CLEAR_TRIGGER_STATUS = 0;
XxlJob注解指定任务处理器
XxlRegister注解指定,任务创建的一些参数,项目启动时将任务进行发布;
6. 动态周期任务的发布

只需要包装一个info,调用这个接口即可,底层实现就是通过访问 XXL-JOB开放的接口;
那问题来了:
- 用户A,需要你每一天的中午12点给我发一条定时消息提醒,持续到 2024年4月的最后一刻结束;
- 而用户B需要我在每一周的星期日的最后一刻发一条定时消息提醒,持续到2024年最后一刻结束;
我们要实现的重点:
- 不同用户不同的触发时间,周期,任务周期结束判断
- 不同用户的任务,对应不同用户的信息(至少不能通知错人)
实现:
-
声明一个任务处理器,
XxlJobHelper.getJobParam()获取参数进行业务处理,判断是否结束周期 -
构造任务,指定Cron
- 指明一个明确的触发时间,那么这个执行器就只会执行一次,要想实现周期就得再发布一个具体触发时间的任务(addJob);判断是否结束周期来决定是否再次发布任务;
- 代表周期的 Cron,我们需要判断是否结束周期,如果要结束周期,就stop这个周期任务
- 我才采用的是前者,后者需要访问XXL-JOB开放的接口,
XxlJobContext.getXxlJobContext().getJobId()可以获取ID去停止任务;
-
在业务中发布任务(调用addJob)
7. 项目重启,任务需要进行更新
项目重启的时候,可能有以下情况:
- 正常情况
- 任务需要增删改
- 如旧的触发时间早就过去了,需要设定新的触发时间…
如果你对每个用户,创建了表去对应他们的定时任务(多对多),那你可以遍历任务去修改,但是我选择,全部删除,再重新发布,简单不易错(在项目启动时初始化,不存在什么用户体验的)
对于删除所有的任务,我修改了XXL-JOB的源码,添加了两个接口:
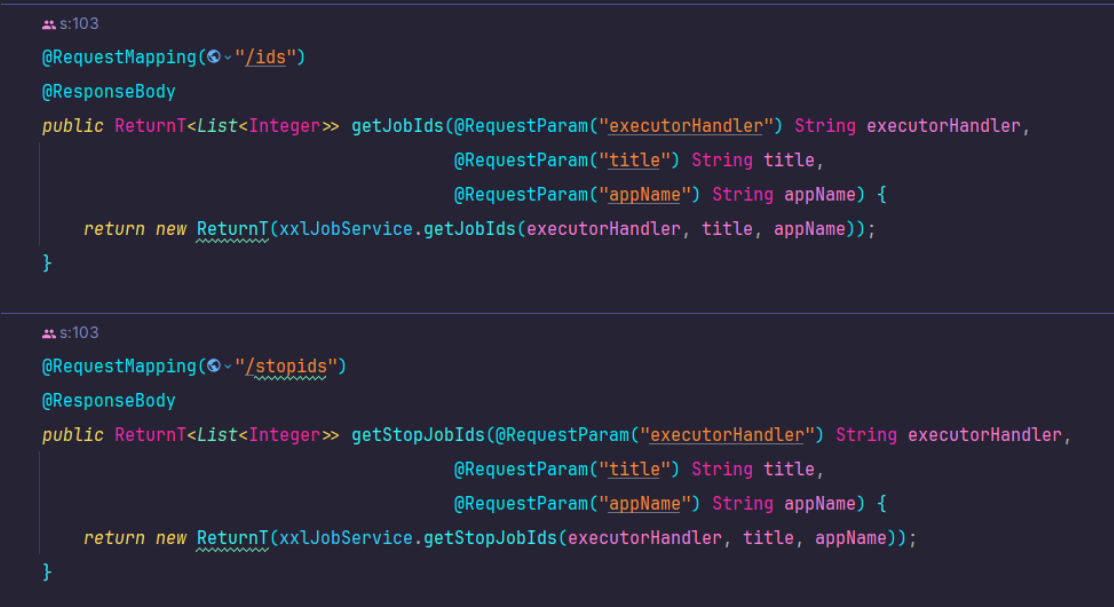
如果任务量比较大,建议采用多线程分批删除
用并行流的foreach去消费Stream,是异步的,所以这个任务可能就结束了,删除的时候就把刚才执行的任务删除了;
8.1 系统时间
在任务处理器内部,尽量不要用System.currentTimeMillis()去获取当前时间,可以用hutool的DateUtil.now(),或者就干脆不要获取了,有时候可以,有时候会出错,我也不知道为啥~、
定时任务可能会有误差,所以这种方式可能会对结果有影响,建议在 Job 参数里面添加时间属性,确定当时的时间是多少,这样有误差,在执行的时候,程序都认为是在该时刻,只不过如果人为的影响,这个时间属性可能会偏离现实,因为程序只通过这个属性了解时间;
这个没啥关系,不要人为就行, 不然问题没完没了了;
8.2 任务的触发
任务触发,Running 状态的界定:任务存在下次执行时间
任务停止,Stop 状态
取决于 job info 这个对象的 trigger status 属性
如果不存在下次执行时间,XXL-JOB 会打印日志:
logback [xxl-job, admin JobFailMonitorHelper] INFO c.x.j.a.c.t.JobFailMonitorHelper - >>>>>>>>>>> xxl-job, job fail monitor thread stop
打印日志 + JOB 直接停止!
没错,XXL-JOB 通知我们的服务器执行任务后,发现不存在下次执行时间,就会直接设置 trigger status 属性为 0,这个 JOB 就直接是 Stop 的状态了,
- 我们也不能说他没触发任务,就是在 触发 – 通知执行 后的那一刻,设置为 0,确确实实触发完了,XXL-JOB 的工作结束,XXL-JOB 可能会监听执行过程是否抛了异常,来记录执行日志
- 不同人有不同的想法吧,可能你觉得确定任务执行结束再设置为 0 好一点,但是 XXL-JOB 就这样;
如果你有删除 Stop 了的任务的业务场景,那么就要注意这个问题,如果一个时间点是个热门时间点,就有可能出现,一个任务把另一个任务给删除了的情况:
- 任务1被触发,trigger status 属性为 0
而现在有任务2被触发,trigger status 属性为 0,但是先一步执行 remove ,任务1未为执行业务就被删除了(还会把自己删除了)
- 写到这里我突然发现刚才的系统时间问题,可能也有可能是这个问题导致的!
解决方法很简单,就是用分布式锁!
9. 发布临时任务(GLUE java 运行模式)
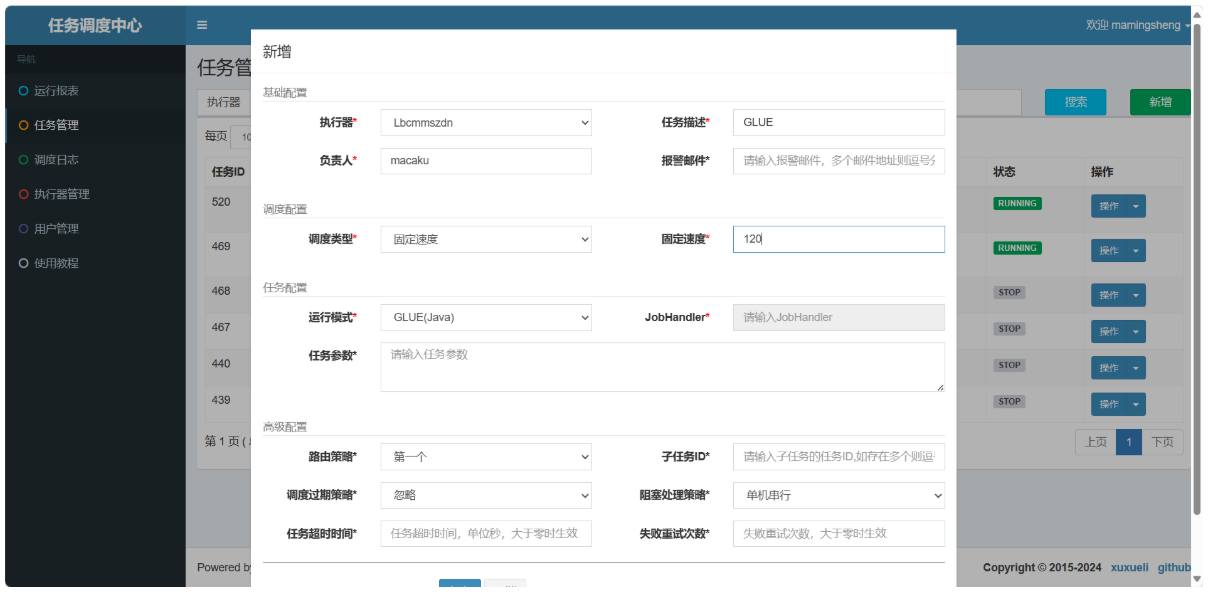
这个时候就不指定任务处理器了,而是实实在在的编写任务处理器:



你可以想象他是在配置类所在的模块,可以获得的Bean,这个处理器也能获取到(通过注入);
不过注意,要导包!!!
如果不少临时的,必然在业务中就应该有处理器的定义,但是如果是临时需要执行的任务,就可以通过这种方式,不需要写进项目源码,也不需要重新上线,就能够执行一个临时任务;
10. 集群与分片(了解)
对于这一部分,知道一些理论知识就差不多了~
10.1 集群
在IDEA中设置SpringBoot项目运行开启多个集群

启动两个SpringBoot程序,需要修改Tomcat端口和执行器端口
-
Tomcat端口8090程序的命令行参数如下:
-Dserver.port=8090 -Dxxl.job.executor.port=9998 -
Tomcat端口8090程序的命令行参数如下:
-Dserver.port=8091 -Dxxl.job.executor.port=9999
在任务管理中,修改路由策略,修改成轮询

重新启动,我们可以看到效果是,定时任务会在这两台机器中进行轮询的执行
-
8090端口的控制台日志如下:

-
8091端口的控制台日志如下:

调度路由算法讲解
当执行器集群部署时,提供丰富的路由策略,包括:
-
FIRST(第一个):固定选择第一个机器 -
LAST(最后一个):固定选择最后一个机器; -
ROUND(轮询):依次的选择在线的机器发起调度 -
RANDOM(随机):随机选择在线的机器; -
CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。 -
LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举; -
LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举; -
FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度; -
BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度; -
SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
10.3 分片
需求:我们现在实现这样的需求,在指定节假日,需要给平台的所有用户去发送祝福的短信.
在数据库中导入xxl_job_demo.sql数据
集成Druid&MyBatis
添加依赖
<!--MyBatis驱动-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.2.0</version>
</dependency>
<!--mysql驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--lombok依赖-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
添加配置
spring.datasource.url=jdbc:mysql://localhost:3306/xxl_job_demo?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=UTF-8
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.username=root
spring.datasource.password=WolfCode_2017
添加实体类
@Setter@Getter
public class UserMobilePlan {
private Long id;//主键
private String username;//用户名
private String nickname;//昵称
private String phone;//手机号码
private String info;//备注
}
添加Mapper处理类
@Mapper
public interface UserMobilePlanMapper {
@Select("select * from t_user_mobile_plan")
List<UserMobilePlan> selectAll();
}
业务功能实现
任务处理方法实现
@XxlJob("sendMsgHandler")
public void sendMsgHandler() throws Exception{
List<UserMobilePlan> userMobilePlans = userMobilePlanMapper.selectAll();
System.out.println("任务开始时间:"+new Date()+",处理任务数量:"+userMobilePlans.size());
Long startTime = System.currentTimeMillis();
userMobilePlans.forEach(item->{
try {
//模拟发送短信动作
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println("任务结束时间:"+new Date());
System.out.println("任务耗时:"+(System.currentTimeMillis()-startTime)+"毫秒");
}
任务配置信息

分片概念讲解
比如我们的案例中有2000+条数据,如果不采取分片形式的话,任务只会在一台机器上执行,这样的话需要20+秒才能执行完任务.
如果采取分片广播的形式的话,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
获取分片参数方式:
// 可参考Sample示例执行器中的示例任务"ShardingJobHandler"了解试用
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
通过这两个参数,我们可以通过求模取余的方式,分别查询,分别执行,这样的话就可以提高处理的速度.
之前2000+条数据只在一台机器上执行需要20+秒才能完成任务,分片后,有两台机器可以共同完成2000+条数据,每台机器处理1000+条数据,这样的话只需要10+秒就能完成任务
案例改造成任务分片
Mapper增加查询方法
@Mapper
public interface UserMobilePlanMapper {
@Select("select * from t_user_mobile_plan where mod(id,#{shardingTotal})=#{shardingIndex}")
List<UserMobilePlan> selectByMod(@Param("shardingIndex") Integer shardingIndex,@Param("shardingTotal")Integer shardingTotal);
@Select("select * from t_user_mobile_plan")
List<UserMobilePlan> selectAll();
}
任务类方法
@XxlJob("sendMsgShardingHandler")
public void sendMsgShardingHandler() throws Exception{
System.out.println("任务开始时间:"+new Date());
int shardTotal = XxlJobHelper.getShardTotal();
int shardIndex = XxlJobHelper.getShardIndex();
List<UserMobilePlan> userMobilePlans = null;
if(shardTotal==1){
//如果没有分片就直接查询所有数据
userMobilePlans = userMobilePlanMapper.selectAll();
}else{
userMobilePlans = userMobilePlanMapper.selectByMod(shardIndex,shardTotal);
}
System.out.println("处理任务数量:"+userMobilePlans.size());
Long startTime = System.currentTimeMillis();
userMobilePlans.forEach(item->{
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println("任务结束时间:"+new Date());
System.out.println("任务耗时:"+(System.currentTimeMillis()-startTime)+"毫秒");
}
任务设置

11. 最后
XXL-JOB 动态发布定时周期任务的功能,我在项目OKR目标与规划管理小程序中重点实践了,后端代码:CarefreeState/OKR-System: 小程序后端项目 (github.com)
小程序码:

欢迎支持!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











