







用户通过算子能将一个或多个 DataStream 转换成新的 DataStream,在应用程序中可以将多个数据转换算子合并成一个复杂的数据流拓扑。
这部分内容将描述 Flink DataStream API 中基本的数据转换API,数据转换后各种数据分区方式,以及算子的链接策略。
数据流转换 #
Map #
DataStream → DataStream #
Takes one element and produces one element. A map function that doubles the values of the input stream:
DataStream<Integer> dataStream = //...
dataStream.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer value) throws Exception {
return 2 * value;
}
});FlatMap #
DataStream → DataStream #
Takes one element and produces zero, one, or more elements. A flatmap function that splits sentences to words:
dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out)
throws Exception {
for(String word: value.split(" ")){
out.collect(word);
}
}
});Filter #
DataStream → DataStream #
Evaluates a boolean function for each element and retains those for which the function returns true. A filter that filters out zero values:
Java
dataStream.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
return value != 0;
}
});
KeyBy #
DataStream → KeyedStream #
Logically partitions a stream into disjoint partitions. All records with the same key are assigned to the same partition. Internally, keyBy() is implemented with hash partitioning. There are different ways to specify keys.
从逻辑上将流划分为不相交的分区。具有相同密钥的所有记录都被分配给相同的分区。在内部,keyby()是通过哈希分区来实现的。指定键的方法是不同的。
Java
dataStream.keyBy(value -> value.getSomeKey());
dataStream.keyBy(value -> value.f0);A type cannot be a key if:
- it is a POJO type but does not override the
hashCode()method and relies on theObject.hashCode()implementation. - it is an array of any type.
Reduce #
KeyedStream → DataStream #
A “rolling” reduce on a keyed data stream. Combines the current element with the last reduced value and emits the new value.
A reduce function that creates a stream of partial sums:
Java
keyedStream.reduce(new ReduceFunction<Integer>() {
@Override
public Integer reduce(Integer value1, Integer value2)
throws Exception {
return value1 + value2;
}
});Window #
KeyedStream → WindowedStream #
Windows can be defined on already partitioned KeyedStreams. Windows group the data in each key according to some characteristic (e.g., the data that arrived within the last 5 seconds). See windows for a complete description of windows.
Java
dataStream
.keyBy(value -> value.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5))); WindowAll #
DataStreamStream → AllWindowedStream #
Windows can be defined on regular DataStreams. Windows group all the stream events according to some characteristic (e.g., the data that arrived within the last 5 seconds). See windows for a complete description of windows.
This is in many cases a non-parallel transformation. All records will be gathered in one task for the windowAll operator.
Java
dataStream
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));Window Apply #
WindowedStream → DataStream #
AllWindowedStream → DataStream #
Applies a general function to the window as a whole. Below is a function that manually sums the elements of a window.
If you are using a windowAll transformation, you need to use an
AllWindowFunction instead.
Java
windowedStream.apply(new WindowFunction<Tuple2<String,Integer>, Integer, Tuple, Window>() {
public void apply (Tuple tuple,
Window window,
Iterable<Tuple2<String, Integer>> values,
Collector<Integer> out) throws Exception {
int sum = 0;
for (value t: values) {
sum += t.f1;
}
out.collect (new Integer(sum));
}
});
// applying an AllWindowFunction on non-keyed window stream
allWindowedStream.apply (new AllWindowFunction<Tuple2<String,Integer>, Integer, Window>() {
public void apply (Window window,
Iterable<Tuple2<String, Integer>> values,
Collector<Integer> out) throws Exception {
int sum = 0;
for (value t: values) {
sum += t.f1;
}
out.collect (new Integer(sum));
}
});WindowReduce #
WindowedStream → DataStream #
Applies a functional reduce function to the window and returns the reduced value.
Java
windowedStream.reduce (new ReduceFunction<Tuple2<String,Integer>>() {
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<String,Integer>(value1.f0, value1.f1 + value2.f1);
}
});Union #
DataStream* → DataStream #
Union of two or more data streams creating a new stream containing all the elements from all the streams. Note: If you union a data stream with itself you will get each element twice in the resulting stream.
Java
dataStream.union(otherStream1, otherStream2, ...);Window Join #
DataStream,DataStream → DataStream #
Join two data streams on a given key and a common window.
Java
dataStream.join(otherStream)
.where(<key selector>).equalTo(<key selector>)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new JoinFunction () {...});Interval Join #
KeyedStream,KeyedStream → DataStream #
Join two elements e1 and e2 of two keyed streams with a common key over a given time interval, so that e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound.
Java
// this will join the two streams so that
// key1 == key2 && leftTs - 2 < rightTs < leftTs + 2
keyedStream.intervalJoin(otherKeyedStream)
.between(Time.milliseconds(-2), Time.milliseconds(2)) // lower and upper bound
.upperBoundExclusive(true) // optional
.lowerBoundExclusive(true) // optional
.process(new IntervalJoinFunction() {...});Window CoGroup #
DataStream,DataStream → DataStream #
Cogroups two data streams on a given key and a common window.
Java
dataStream.coGroup(otherStream)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new CoGroupFunction () {...});Connect #
DataStream,DataStream → ConnectedStream #
“Connects” two data streams retaining their types. Connect allowing for shared state between the two streams.
Java
DataStream<Integer> someStream = //...
DataStream<String> otherStream = //...
ConnectedStreams<Integer, String> connectedStreams = someStream.connect(otherStream);CoMap, CoFlatMap #
ConnectedStream → DataStream #
Similar to map and flatMap on a connected data stream
Java
connectedStreams.map(new CoMapFunction<Integer, String, Boolean>() {
@Override
public Boolean map1(Integer value) {
return true;
}
@Override
public Boolean map2(String value) {
return false;
}
});
connectedStreams.flatMap(new CoFlatMapFunction<Integer, String, String>() {
@Override
public void flatMap1(Integer value, Collector<String> out) {
out.collect(value.toString());
}
@Override
public void flatMap2(String value, Collector<String> out) {
for (String word: value.split(" ")) {
out.collect(word);
}
}
});Iterate #
DataStream → IterativeStream → ConnectedStream #
Creates a “feedback” loop in the flow, by redirecting the output of one operator to some previous operator. This is especially useful for defining algorithms that continuously update a model. The following code starts with a stream and applies the iteration body continuously. Elements that are greater than 0 are sent back to the feedback channel, and the rest of the elements are forwarded downstream.
Java
IterativeStream<Long> iteration = initialStream.iterate();
DataStream<Long> iterationBody = iteration.map (/*do something*/);
DataStream<Long> feedback = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception {
return value > 0;
}
});
iteration.closeWith(feedback);
DataStream<Long> output = iterationBody.filter(new FilterFunction<Long>(){
@Override
public boolean filter(Long value) throws Exception {
return value <= 0;
}
});物理分区 #
Flink 也提供以下方法让用户根据需要在数据转换完成后对数据分区进行更细粒度的配置。
Custom Partitioning #
DataStream → DataStream #
Uses a user-defined Partitioner to select the target task for each element.
Java
dataStream.partitionCustom(partitioner, "someKey");
dataStream.partitionCustom(partitioner, 0);
ScalaPython
Random Partitioning #
DataStream → DataStream #
Partitions elements randomly according to a uniform distribution.
Java
dataStream.shuffle();Rescaling #
DataStream → DataStream #
Partitions elements, round-robin, to a subset of downstream operations. This is useful if you want to have pipelines where you, for example, fan out from each parallel instance of a source to a subset of several mappers to distribute load but don’t want the full rebalance that rebalance() would incur. This would require only local data transfers instead of transferring data over network, depending on other configuration values such as the number of slots of TaskManagers.
The subset of downstream operations to which the upstream operation sends elements depends on the degree of parallelism of both the upstream and downstream operation. For example, if the upstream operation has parallelism 2 and the downstream operation has parallelism 6, then one upstream operation would distribute elements to three downstream operations while the other upstream operation would distribute to the other three downstream operations. If, on the other hand, the downstream operation has parallelism 2 while the upstream operation has parallelism 6 then three upstream operations would distribute to one downstream operation while the other three upstream operations would distribute to the other downstream operation.
In cases where the different parallelisms are not multiples of each other one or several downstream operations will have a differing number of inputs from upstream operations.
Please see this figure for a visualization of the connection pattern in the above example:
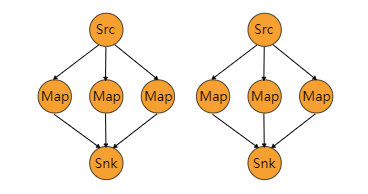
dataStream.rescale();Broadcasting #
DataStream → DataStream #
Broadcasts elements to every partition.
Java
dataStream.broadcast();算子链和资源组 #
将两个算子链接在一起能使得它们在同一个线程中执行,从而提升性能。Flink 默认会将能链接的算子尽可能地进行链接(例如, 两个 map 转换操作)。此外, Flink 还提供了对链接更细粒度控制的 API 以满足更多需求:
如果想对整个作业禁用算子链,可以调用 StreamExecutionEnvironment.disableOperatorChaining()。下列方法还提供了更细粒度的控制。需要注 意的是, 这些方法只能在 DataStream 转换操作后才能被调用,因为它们只对前一次数据转换生效。例如,可以 someStream.map(...).startNewChain() 这样调用,而不能 someStream.startNewChain()这样。
一个资源组对应着 Flink 中的一个 slot 槽,更多细节请看slots 槽。 你可以根据需要手动地将各个算子隔离到不同的 slot 中。
Start New Chain #
Begin a new chain, starting with this operator. The two mappers will be chained, and filter will not be chained to the first mapper.
Java
someStream.filter(...).map(...).startNewChain().map(...);Disable Chaining #
Do not chain the map operator.
Java
someStream.map(...).disableChaining();Set Slot Sharing Group #
Set the slot sharing group of an operation. Flink will put operations with the same slot sharing group into the same slot while keeping operations that don’t have the slot sharing group in other slots. This can be used to isolate slots. The slot sharing group is inherited from input operations if all input operations are in the same slot sharing group. The name of the default slot sharing group is “default”, operations can explicitly be put into this group by calling slotSharingGroup(“default”).
Java
someStream.filter(...).slotSharingGroup("name");















 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









