







序言
笔记根据labuladong进行总结,极力推荐labuladong算法进行学习!!
动态规划 链表(环) 图(环) 回溯(子集) 指针(双)
目录
动态规划
动态规划的核心设计思想是数学归纳法。
1、动态规划问题一定会具备「最优子结构」,才能通过子问题的最值得到原问题的最值。
最优子结构:假设一个子问题的最优,是否是他的父问题的其中一部分?!!!!
假设一个子问题已经解决了,那么父问题能否拿子问题的答案解答,假设局部问题很重要!
2、「备忘录」或者「DP table」来优化穷举过程
3、重叠子问题、最优子结构、状态转移方程就是动态规划三要素:要符合「最优子结构」,子问题间必须互相独立。
4、「状态压缩」:根据斐波那契数列的状态转移方程,当前状态只和之前的两个状态有关,不需要那么长的一个 DP table 来存储所有的状态,只要想办法存储之前的两个状态就行了
5、 从左到右 从低到上 递归函数
7、限制条件转化为状态
解决模板
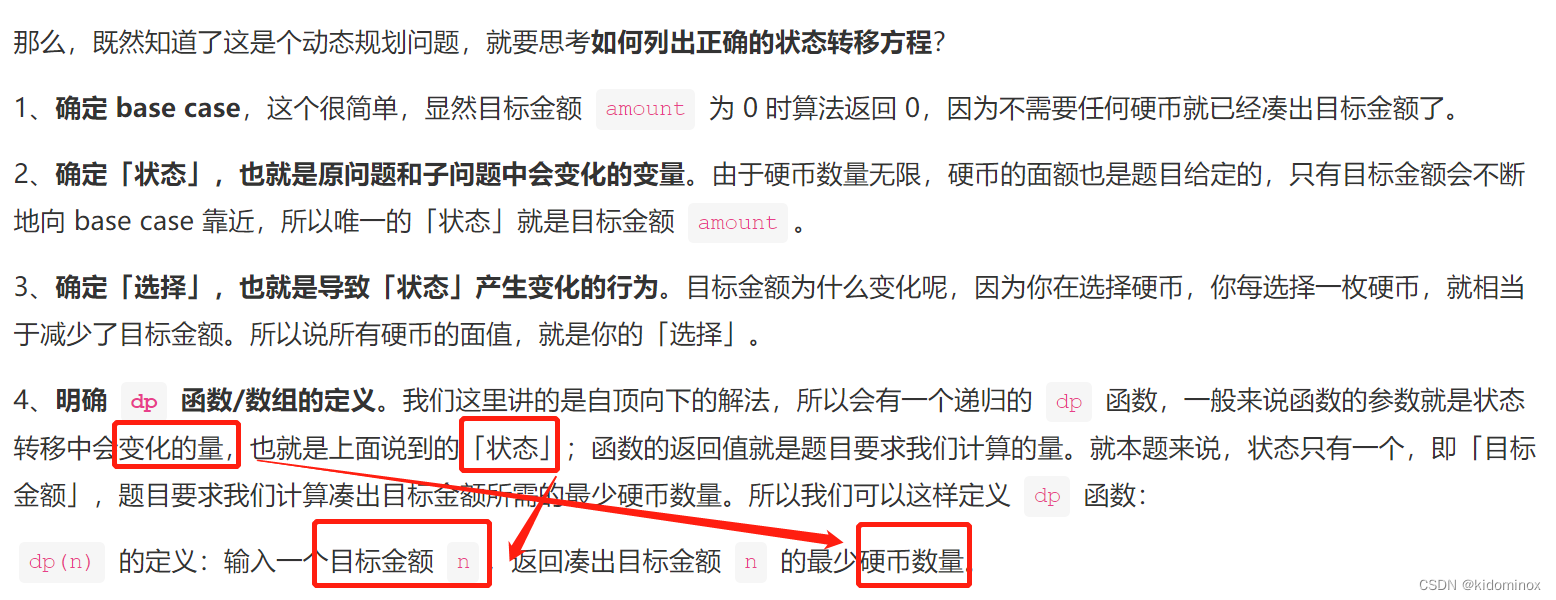
# 初始化 base case
dp[0][0][...] = base
# 进行状态转移
for 状态1 in 状态1的所有取值:
for 状态2 in 状态2的所有取值:
for ...
dp[状态1][状态2][...] = 求最值(选择1,选择2...)
一维:
//cpp
int n = array.size();
vector<int> dp(n,0);
for (int i = 1; i < n; i++) {
for (int j = 0; j < i; j++) {
dp[i] = 最值(dp[i], dp[j] + ...)
}
}
//*max_element(dp.begin(), dp.end())
二维:
//cpp
int n = arr.length;
vector<vector<int>> dp(n+1,vector<int>(w+1,0));
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (arr[i] == arr[j])
dp[i][j] = dp[i][j] + ...
else
dp[i][j] = 最值(...)
}
}
注意问题
1、数组为-1的时候,在for里面if进行初始化
2、写出状态转移方程,看循环是从0-n还是n-0
3、如果一维度不行就用二维设计状态
子序列
不是连续的类型
起码是指数级的吧,这种情况下,不用动态规划技巧
最优子结构:因为序列是从左到右,如果字符串长度到n,最优是dp[n],那么字符串长度是n+1的话,可以从dp[n]中进行数学归纳,得到dp[n+1]。
状态:长度n;
选择:目前还是以往的长度+1;
目标:以n为长度的字符串的最优子序列;
- 增长序列
- 回文子序列(序号头i,尾j)
- 两个公共子序列(序列1 -i,序列2 - j)
- 如果是删除东西,这样字符串被分开,则可以尝试将问题变成添加;
如果**「正向思考」,就只能写出前文的回溯算法;我们需要「反向思考」**,想一想气球 i 和气球 j 之间最后一个被戳破的气球可能是哪一个?变成了函数的动态规划(戳气球) - 打家劫舍
子串-连续的
用dp[i]
代码结构
斜着遍历和倒着遍历

for(int l = 2;l<=n;l++)
{
for(int i = 0;i<=n-l;i++)
{
int j = i+l-1;
int left = piles[i]+dp[i+1][j][1];
int right= piles[j]+dp[i][j-1][1];
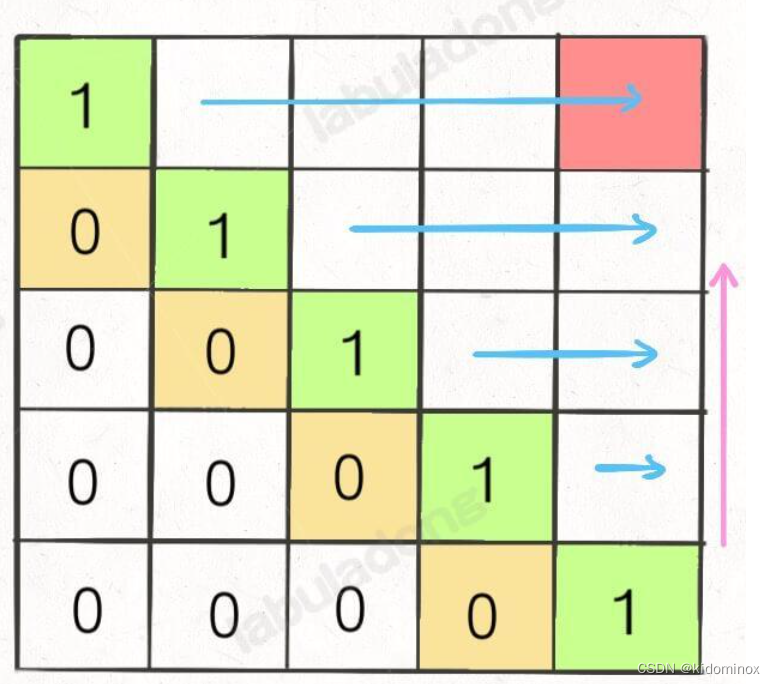
// 反着遍历保证正确的状态转移
for (int i = n - 1; i >= 0; i--) {
for (int j = i + 1; j < n; j++) {
// 状态转移方程
}
}
1、遍历的过程中,所需的状态必须是已经计算出来的。
2、遍历的终点必须是存储结果的那个位置。
sort
static bool cmp(vector<int> a, vector<int> b){
if(a[1] < b[1])
return true;
else
return false;
}
int eraseOverlapIntervals(vector<vector<int>>& intervals) {
sort(intervals.begin(),intervals.end(),cmp);
//上面的代码超时了
//用&,不用重新建立临时空间,不会超时。
sort(intervals.begin(),intervals.end(),[](const vector<int>& u, const vector<int>& v)
{
return u[1] < v[1];
});
股票买卖问题
注意购买次数:
k=1
dp[i][1] = max(dp[i-1][1], - prices[i])
k = +infinity
dp[i][1] = max(dp[i-1][1], dp[i-1][0] - prices[i])
扔鸡蛋
- dp是一个递归函数 如果鸡蛋碎了重新扔,这是一个子问题;
最优子结构并不是动态规划独有的一种性质,能求最值的问题大部分都具有这个性质;但反过来,最优子结构性质作为动态规划问题的必要条件,一定是让你求最值的 - 之前for是遍历状态,这里for 循环来遍历所有选择
- 因为是最坏结果,所以是去取最大,而不同选择中取最小;
- 「状态」很明显,就是当前拥有的鸡蛋数 K 和需要测试的楼层数 N
「选择」其实就是去选择哪层楼扔鸡蛋
//python
def superEggDrop(K: int, N: int):
memo = dict()
def dp(K, N) -> int:
# base case
if K == 1: return N
if N == 0: return 0
# 避免重复计算
if (K, N) in memo:
return memo[(K, N)]
res = float('INF')
# 穷举所有可能的选择
for i in range(1, N + 1):
res = min(res,
max(
dp(K, N - i),
dp(K - 1, i - 1)
) + 1
)
# 记入备忘录
memo[(K, N)] = res
return res
return dp(K, N)
贪心
1、如果能使用动态规划消除重叠子问题,就可以降到多项式级别的时间,如果满足贪心选择性质,那么可以进一步降低时间复杂度,达到线性级别的。
2、贪心算法可以认为是动态规划算法的一个特例。什么是贪心选择性质呢,简单说就是:每一步都做出一个局部最优的选择,最终的结果就是全局最优。
比如你面前放着 100 张人民币,你只能拿十张,怎么才能拿最多的面额?显然每次选择剩下钞票中面值最大的一张,最后你的选择一定是最优的。
而动态规划中则是 把所有的选择遍历一遍选择局部最优。
eg.无重叠区间:
贪心体现在:如果总能最先结束。可以留给更多的时间给后面的活动用。贪心上则是已经做了选择。
博弈问题的套路
其核心思路是在二维 dp 的基础上使用元组分别存储两个人的博弈结果。
dp[i][j].fir = max(piles[i] + dp[i+1][j].sec, piles[j] + dp[i][j-1].sec)
dp[i][j].fir = max( 选择最左边的石头堆 , 选择最右边的石头堆 )
# 解释:我作为先手,面对 piles[i...j] 时,有两种选择:
# 要么我选择最左边的那一堆石头,然后面对 piles[i+1...j]
# 但是此时轮到对方,相当于我变成了后手;
# 要么我选择最右边的那一堆石头,然后面对 piles[i...j-1]
# 但是此时轮到对方,相当于我变成了后手。
if 先手选择左边:
dp[i][j].sec = dp[i+1][j].fir
if 先手选择右边:
dp[i][j].sec = dp[i][j-1].fir
# 解释:我作为后手,要等先手先选择,有两种情况:
# 如果先手选择了最左边那堆,给我剩下了 piles[i+1...j]
# 此时轮到我,我变成了先手;
# 如果先手选择了最右边那堆,给我剩下了 piles[i...j-1]
# 此时轮到我,我变成了先手。
编辑距离
滑动窗口
1、时间复杂度是 O(N)
2、什么时候使用? 子串
更多是匹配,而动态规划的子串更多是求个数和最值
right 指针扩大窗口 [left, right),直到窗口中的字符串符合要求(包含了 T 中的所有字符)。
left 指针缩小窗口 [left, right),直到窗口中的字符串不再符合要求(不包含 T 中的所有字符了)
/* 滑动窗口算法框架 */
void slidingWindow(string s, string t) {
unordered_map<char, int> need, window;
for (char c : t) need[c]++;
int left = 0, right = 0;
int valid = 0;
while (right < s.size()) {
// c 是将移入窗口的字符
char c = s[right];
// 右移窗口
right++;
// 进行窗口内数据的一系列更新
...
/*** debug 输出的位置 ***/
printf("window: [%d, %d)\n", left, right);
/********************/
// 判断左侧窗口是否要收缩 即达到满足条件
while (window needs shrink) {
// d 是将移出窗口的字符
char d = s[left];
// 左移窗口
left++;
// 进行窗口内数据的一系列更新
// 保存result
// 缩小到不满足条件while就break了
...
}
}
}
回溯
1、与动态规划和递归之间的区别
2、什么情况:
自顶而下
时间复杂度都不可能低于 O(N!)
动态规划的三个需要明确的点就是「状态」「选择」和「base case」,是不是就对应着走过的「路径」,当前的「选择列表」和「结束条件」?动态规划的暴力求解阶段就是回溯算法。
是DFS 算法框架;vector 进行push_back 和 pop_back
有固定的个数add,且一开头的add,而不能中间add
“所有组合” 等类似字眼时,我们第一感觉就要想到用回溯
for 选择 in 选择列表:
# 做选择
将该选择从选择列表移除
路径.add(选择)
backtrack(路径, 选择列表)
# 撤销选择
路径.remove(选择)
将该选择再加入选择列表
组合=子集 & 排序
回溯:1、 track进行保存路径 2、 start/used去重
组合/子集问题使用 start 变量保证元素 nums[start] 之后只会出现 nums[start+1…] 中的元素,通过固定元素的相对位置保证不出现重复的子集。即不走回头路。
排序:用used数组标记 或者 数组进行push_back和pop_back
重复性 - 组合/子集
sort(nums.begin(),nums.end());
for (int i = start; i < nums.length; i++) {
// 剪枝逻辑,值相同的相邻树枝,只遍历第一条
if (i > start && nums[i] == nums[i - 1]) {
continue;
}
track.addLast(nums[i]);
backtrack(nums, i + 1);
track.removeLast();
}
所有和为 target 的组合/子集
这是数是不固定的,如果数是固定的,那就是n个数之和的题型
只要额外用一个 trackSum 变量记录回溯路径上的元素和
int trackSum = 0;
void backtrack(int[] nums, int start, int target) {
...
}
排序-重复
保证相同元素在排列中的相对位置保持不变。
//排序
sort(...)
// 新添加的剪枝逻辑,固定相同的元素在排列中的相对位置
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {
// 如果前面的相邻相等元素没有用过,则跳过
continue;
}
当出现重复元素时,比如输入 nums = [1,2,2’,2’‘],2’ 只有在 2 已经被使用的情况下才会被选择,2’’ 只有在 2’ 已经被使用的情况下才会被选择,这就保证了相同元素在排列中的相对位置保证固定。
无重复元素,但每个元素可以被无限次使用。
只要删掉去重逻辑即可
组合
//去重
void backtrack(int[] nums, int start) {
backtrack(nums, i+1);
//不去重
backtrack(nums, i);
排序
used -> 去掉used
BFS
1、BFS 可以找到达到目的的最短距离,但是空间复杂度高
2、选择可以抽象成一幅图(有向或者无向)/决策树。
3、双向 BFS:双向 BFS 则是从起点和终点同时开始扩散,当两边有交集的时候停止。
//JAVA
// 计算从起点 start 到终点 target 的最近距离
int BFS(Node start, Node target) {
Queue<Node> q; // 核心数据结构
Set<Node> visited; // 避免走回头路
q.offer(start); // 将起点加入队列
visited.add(start);
int step = 0; // 记录扩散的步数
while (q not empty) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散 */
for (int i = 0; i < sz; i++) {
Node cur = q.poll();
/* 划重点:这里判断是否到达终点 */
if (cur is target)
return step;
/* 将 cur 的相邻节点加入队列 */
for (Node x : cur.adj())
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
/* 划重点:更新步数在这里 */
step++;
}
}
双向 BFS
1、双向 BFS 还是遵循 BFS 算法框架的,只是不再使用队列,而是使用 HashSet 方便快速判断两个集合是否有交集。
2、双向 BFS 也有局限,因为你必须知道终点在哪里。
3、时间复杂度都是O(n)
回文
寻找回文串是从中间向两端扩展,判断回文串是从两端向中间收缩。
对于单链表,无法直接倒序遍历,可以造一条新的反转链表,可以利用链表的后序遍历,也可以用栈结构倒序处理单链表。
string palindrome(string& s,int l, int r)
{
while(l >= 0 && r < s.size() && s[l] == s[r])
{
l--;
r++;
}
return s.substr(l + 1,r - l + 1);
}
bool isPalindrome(string s)
{
int left = 0,rignt = s.length()-1;
while(left <= right)
{
if(s[left] != s[right])
return false;
left++;
right--;
}
return true;
}
快慢指针
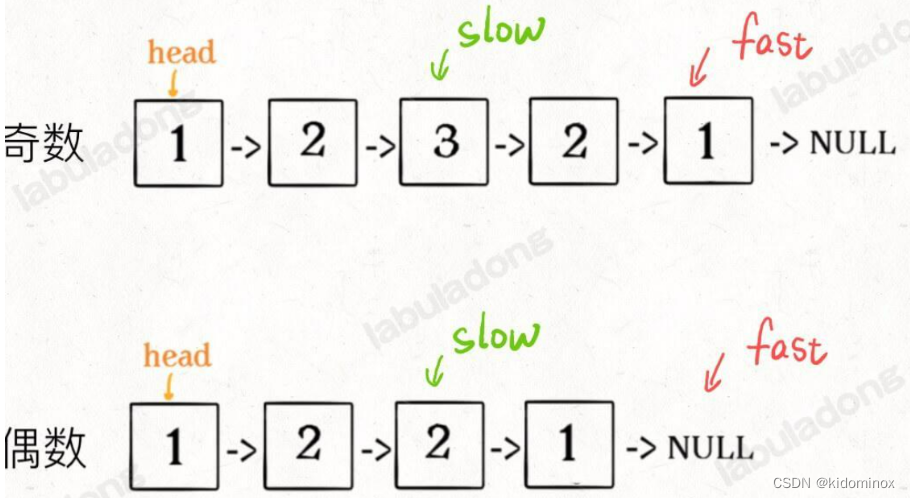
ListNode slow, fast;
slow = fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
// slow 指针现在指向链表中点
待解决:
1、Morris 中序遍历 leetcode 94
2、多种解法最后再做一遍
编辑距离https://www.cnblogs.com/labuladong/p/12320390.html
KMP 算法(Knuth Morris Pratt 算法)
动态规划的实际应用:正则表达式。
四键键盘
union-find
某个连续数据段的和——前缀和技巧
排列
技巧:有序的数组想可否用左右/快慢指针。
“所有组合” 等类似字眼时,我们第一感觉就要想到用回溯
如果至少一个数字的被选数量不同,则两种组合是不同的。 —how to solve
简单总结一下:
排列问题,讲究顺序(即 [2, 2, 3] 与 [2, 3, 2] 视为不同列表时),需要记录哪些数字已经使用过,此时用 used 数组;
组合问题,不讲究顺序(即 [2, 2, 3] 与 [2, 3, 2] 视为相同列表时),需要按照某种顺序搜索,此时使用 begin 变量。
字符串是否在大的字符串中出现:哈希表查询O(1)
因为求解的是个数,不是路径,所以不用树的递归进行求解,而是动态规划!!
题型
两数之和——哈希; n个数之和——1+n-1
去除重复性的数字
在哪里用到?
while(left < right)
{
left++;
while(left < right && nums[left] == temp) left++;
}
# second
for(int ...)
{
while(i < num,size() - 1 && nums[i] == nums[i+1]) i++;
二分查找
链表
1、函数的参数不用改动,而是赋值到新的指针进行检索移动。
2、头指针是一个无用的指针的应用
3、unordered_set存储
4、环->快慢指针
boolean hasCycle(ListNode head) {
ListNode fast, slow;
fast = slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (fast == slow) return true;
}
return false;
}
// 不是链表结构的快慢指针
do{
slow = nums[slow];
fast = nums[nums[fast]];
}while(fast != slow);
栈
stack<int> s;
s.top(); //top 之前记得查看s.empty();
s.pop();
s.push(ch);
单调栈
next greater number
vector<int> nextGreaterElement(vector<int>& nums) {
vector<int> ans(nums.size()); // 存放答案的数组
stack<int> s;
for (int i = nums.size() - 1; i >= 0; i--) { // 倒着往栈里放
while (!s.empty() && s.top() <= nums[i]) { // 判定个子高矮
s.pop(); // 矮个起开,反正也被挡着了。。。
}
ans[i] = s.empty() ? -1 : s.top(); // 这个元素身后的第一个高个
s.push(nums[i]); // 进队,接受之后的身高判定吧!
}
return ans;
}
哈希表
查找某一元素是否出现过就该用哈希 时间复杂度 o(1)
unordered_map<char,char> m;
pairs.count(ch) //是否存在char ch
//
auto it = hashtable.find(target - nums[i]);
if (it != hashtable.end())
图
多叉树
无向图:双向多叉树
邻接表和邻接矩阵:图的存储方式主要有邻接表和邻接矩阵,无论什么花里胡哨的图,都可以用这两种方式存储。
建立图
vector<vector<int>> edges;
edges.resize(numCourses);
for(int i = 0; i < n; i++)
{
edges[prerequisites[i][b]] = prerequisites[i][0];
}
//java
// 邻接矩阵
// graph[x] 存储 x 的所有邻居节点以及对应的权重
List<int[]>[] graph;
// 邻接矩阵
// matrix[x][y] 记录 x 指向 y 的边的权重,0 表示不相邻
int[][] matrix;
图可能包含环:
如果图包含环,利用onPath 判断
这个 onPath 数组的操作很像 回溯算法核心套路 中做「做选择」和「撤销选择」,区别在于位置:回溯算法的「做选择」和「撤销选择」在 for 循环里面,而对 onPath 数组的操作在 for 循环外面。因为在 for 循环里面和外面唯一的区别就是对根节点的处理。
bool dfs(int index)
{
if(onPath[index])
return false;// 发现环
if(visit[index] == true)
return true;//全局visit过,所以过滤掉,减少重复计算。
int n = edges[index].size();
bool res = true;
//根节点处理
onPath[index] = true;
visit[index] = true;
//
//做选择
for(int i = 0; i < n; i++)
{
res = res && dfs(edges[index][i]);
}
// 撤销加入到该路途中
onPath[index] = false;
return res;
}
拓扑排序
概念:
1、广度搜索
2、DFS的后序遍历反转之后的结果,且拓扑排序只能针对有向无环图,进行拓扑排序之前要进行环检测
位运算
1、n&(n-1) 消除最后一个1, — 二进制中1 的个数 ;2的指数
2、res = res ^ num只是出现过一次的数字
3、异或运算时,当前位的两个二进制表示不同则为1相同则为0。
题目是全排列然后给出满足条件的结果
三数之和-这是 和 这个带来的技巧
数组
// 先沿对角线镜像对称二维矩阵
for (int i = 0; i < n; i++) {
for (int j = i; j < n; j++) {
// swap(matrix[i][j], matrix[j][i]);
int temp = matrix[i][j];
matrix[i][j] = matrix[j][i];
matrix[j][i] = temp;
}
}
杂碎
max_num = max_element(map.begin(),map.end(),[](const auto& m1,const auto& m2)
{
return m1.second < m2.second;
})->second;
int max_count = accumulate(map.begin(),map.end(),0,[=](int acc,const auto& u)
{
return acc + u.second == max_num;
});
c++
vector<int>
swap(nums[start],nums[j]);
reverse(nums.begin(), nums.end());
最长连续序列是滑动窗口和dp
并查集?128
,题目一般都会要求算法的时间复杂度,如果你发现 O(NlogN) 这样存在对数的复杂度,一般都要往二分查找的方向上靠,这也算是个小套路。
空间复杂度取决于递归的栈深度
递归算法的时间复杂度怎么计算?就是用子问题个数乘以解决一个子问题需要的时间。
递归和迭代和回溯的区别
回溯是从下到上的指针;
unordered_set
unordered_set<string> vis;
if(!vis.count(newOne))
vis.emplace(newOne);
vis.insert(deadends.begin(), deadends.end());
注意
训练:
1、命名方式
2、输入输出完整
3、return空的vector,return {}
4、pair<int,int> return {c,u}
5、注意覆盖的用法
6、初始情况
if (prices.empty()) {
return 0;
}
















 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









