







- 可以参考自己以前做过的:PaddleOCR数字仪表识别——3.(New)PaddleOCR迁移学习
- PaddleOCR文字识别的文档:https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/doc_ch/recognition.md
1. 修改textrender生成的数据使之符合PaddleOCR格式
- 参考PaddleOCR文档(和之前第一次试验的时候差距不大):https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_ch/recognition.md#自定义数据集
- 自己之前的博客:PaddleOCR数字仪表识别——2(New). textrenderer使用及修改使之符合PaddleOCR数据标准
如果不确定中间那堆空格是不是\t,建议使用sublime text查看一下,空格是点点和\t(制表符)是一个横线
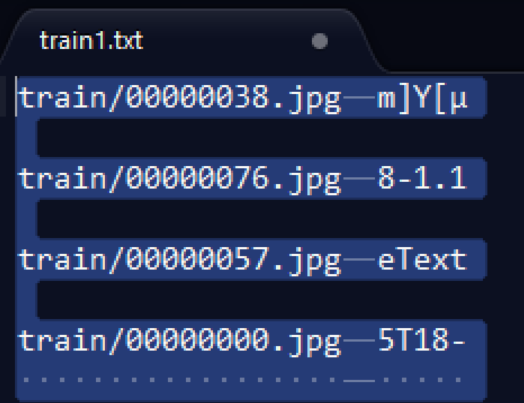
最后,训练集和测试集的数量是24600:4600张,文件结构和之前的保持一致,如下(文件名和标签之间使用\t制表符隔开,制表符的长度可能不那么一致,不影响。)
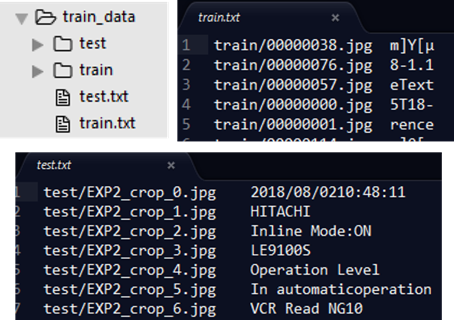
将数据文件进行压缩,上传(不然通过sublime的SFTP文件夹传非常慢),
- 将train_data文件夹进行压缩(就是上面那样的文件结构),zip格式
- 上传至服务器的PaddleOCR文件夹中
- 解压:
# 解压
unzip train_data.zip # 因为最外层其实是一个文件夹,所以直接解压也是一个文件夹(以前遇到过解压完所有的图片都堆在解压目录 所以比较谨慎)
# 层级删除
rm -rf train_data
2. 预训练模型和配置文件
2.1 官方文件
-
OCR模型列表(这里有大量的预训练模型,是百度自研算法的预训练模型):https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/doc_ch/models_list.md#英文识别模型

-
预训练模型列表(是一些常见算法的预训练模型):https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/doc_ch/algorithm_overview.md#2文本识别算法
从这里下载的内容解压后就是三个文件(符合训练模型和预训练模型,注意,这里是PaddleOCR1.0版本的模型!)
-
配置文件列表(没有特别针对配置文件文件作用的说明,自己看看吧):https://github.com/PaddlePaddle/PaddleOCR/tree/develop/configs
-
配置文件参数文档:https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/doc_ch/config.md
2.2 自己的配置过程
我的选择以及选择的理由
- 场景:都是英文、数字、符号,文字长度有限,而且形变不是非常大,从这个角度来说,其实CTC和Attention都可以,但是考虑到Attention存在注意力漂移的问题,还是采用传统的CTC好了。
- 备选项有以下几个:
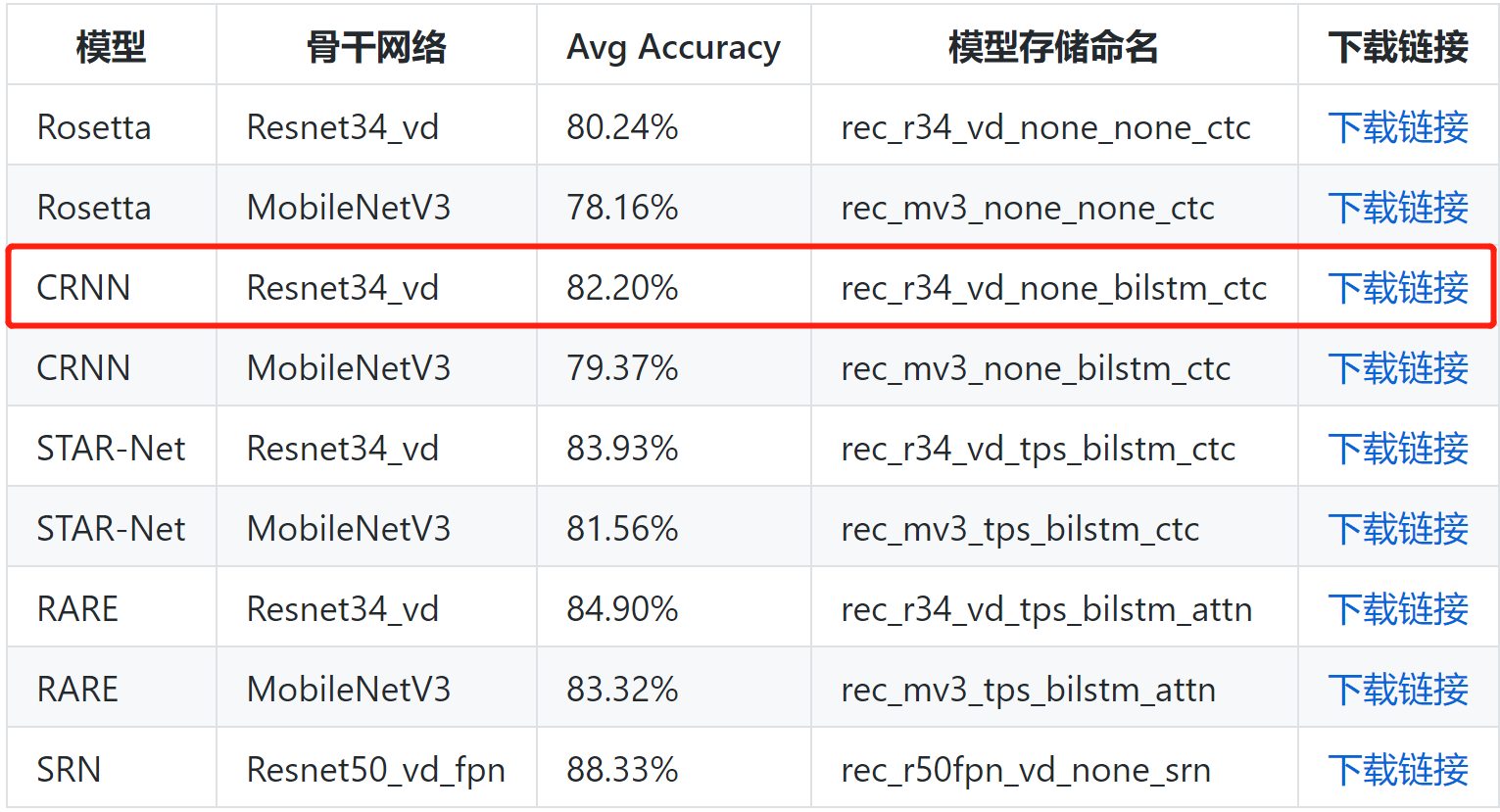
配置文件其实看了两个,内容大致相似,比如:
config/rec/multi_languages/rec_en_lite_train.yml和configs/rec/ch_ppocr_v1.1/rec_chinese_common_train_v1.1.yml- 前者是
en_ppocr_mobile_v1.1_rec 原始超轻量模型,支持英文、数字识别 2M模型的配置文件,后者是ch_ppocr_server_v1.1_rec 通用模型,支持中英文、数字识别 105M的配置文件。 - 反正先搞起来,多试验试验就好了。
2.2.1 下载模型
cd PaddleOCR/
# 下载预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/rec_r34_vd_none_bilstm_ctc.tar
# 以前按照教程用的是这个https://paddleocr.bj.bcebos.com/rec_mv3_none_bilstm_ctc.tar
# CRNN MobileNetV3 79.37% rec_mv3_none_bilstm_ctc
# 解压模型参数
cd pretrain_models
tar -xf rec_r34_vd_none_bilstm_ctc.tar && rm -rf rec_r34_vd_none_bilstm_ctc.tar

可以看到,解压完之后有三个文件,
|- rec_r34_vd_none_bilstm_ctc
|- best_accuracy.pdmodel
|- best_accuracy.pdopt
|- best_accuracy.pdparams
2.2.2 配置文件
github上clone的PaddleOCR本来就有config文件夹,所以不需要再额外进行下载,需要复制一份,改成自己的。
对应于下载的预训练模型的配置文件是:https://github.com/PaddlePaddle/PaddleOCR/blob/develop/configs/rec/rec_r34_vd_none_bilstm_ctc.yml
考虑到以前训练配置文件乱改,效果不太好。这次就不乱改了,既然这个预训练模型对应的就是这个配置文件,那就尽量保持一致,改改字典和数据集位置,预训练模型位置就好了。
解释其中一些配置项目:
# 注意 yml文件每一项的键值是冒号加空格分割开的
save_model_dir: ./output/rec/r34_vd_none_bilstm_ctc/
# 默认paddleOCR没有这个output目录,会新建,同时为了和其他模型训练结果区分,所以给了模型名称作为子文件夹
pretrained_model: ./pretrain_models/rec_r34_vd_none_bilstm_ctc/best_accuracy
# 预训练模型位置
character_dict_path: ./ppocr/utils/eng.txt
# 设置字典路径
character_type: ch
# 设置字符类型 en/ch, en时将使用默认dict,ch时使用自定义dict 所以如果要使用自定义的字典,就需要设置字符类型是ch
- 另外,由于这个预训练模型对应的配置文件采取的读文件方式是IMDBReader,而不是示例中的SimpleReader,参考Windows10制作LMDB详细教程以及What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis,后面这个网站是PaddleOCR下载IMDB类型的dataset的地方,结合以前最开始的imdb格式的mnist数据集,可知这种格式不常用,需要换一个配置文件进行配置。
- 但是通过比较SimpleReader和IMDBReader,这两者的配置其实差不多,就是路径(数据集的文件组织方式不一样),所以直接将配置文件中读取数据的方式由IMDBReader改为SimpleReader。
Train:
dataset:
name: SimpleDataSet
data_dir: ./train_data/ # 数据集路径
label_file_list: ["./train_data/train.txt"] # 训练集标签文件
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 256]
- KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: True
batch_size_per_card: 256
drop_last: True
num_workers: 8
3. 启动训练
先测试一下,能不能正确运行,然后再考虑使用screen这个工具将运行放到后台,防止退出ssh之后进程中断。
2020年12月那会还是这样的运行方式
# 这是以前使用的运行语句
export CUDA_VISIBLE_DEVICES=0
python3.7 tools/train.py -c configs/rec/rec_r34_vd_none_bilstm_ctc.yml 2>&1 | tee train_rec.log
20201年4月已经更新成这个样子了,看架势是多了分布式
# GPU训练 支持单卡,多卡训练,通过--gpus参数指定卡号
# 训练icdar15英文数据 训练日志会自动保存为 "{save_model_dir}" 下的train.log
# 这是第二次跑的时候PaddleOCR更新的内容
python3.7 -m paddle.distributed.launch --gpus '0' tools/train.py -c configs/rec/rec_r34_vd_none_bilstm_ctc.yml
每次都会打印特别多的信息,看着都头疼。。。
3.1 错误信息
使用上述两种运行命令都报错了。都是与cuda相关的错误
Cuda error(100),该提示表示没有这个GPU
首先运行在docker中运行nvidia-smi查看这个docker里有没有cuda,由于我的docker使用的是整个服务器的第三个GPU,所以export CUDA_VISIBLE_DEVICES=3这里的序号是3,但是从下图可以看到,由于在创建容器时只绑定了一个GPU,虽然在服务器的物理序号是3,但是对于docker容器来说,就是0,所以改为export CUDA_VISIBLE_DEVICES=0
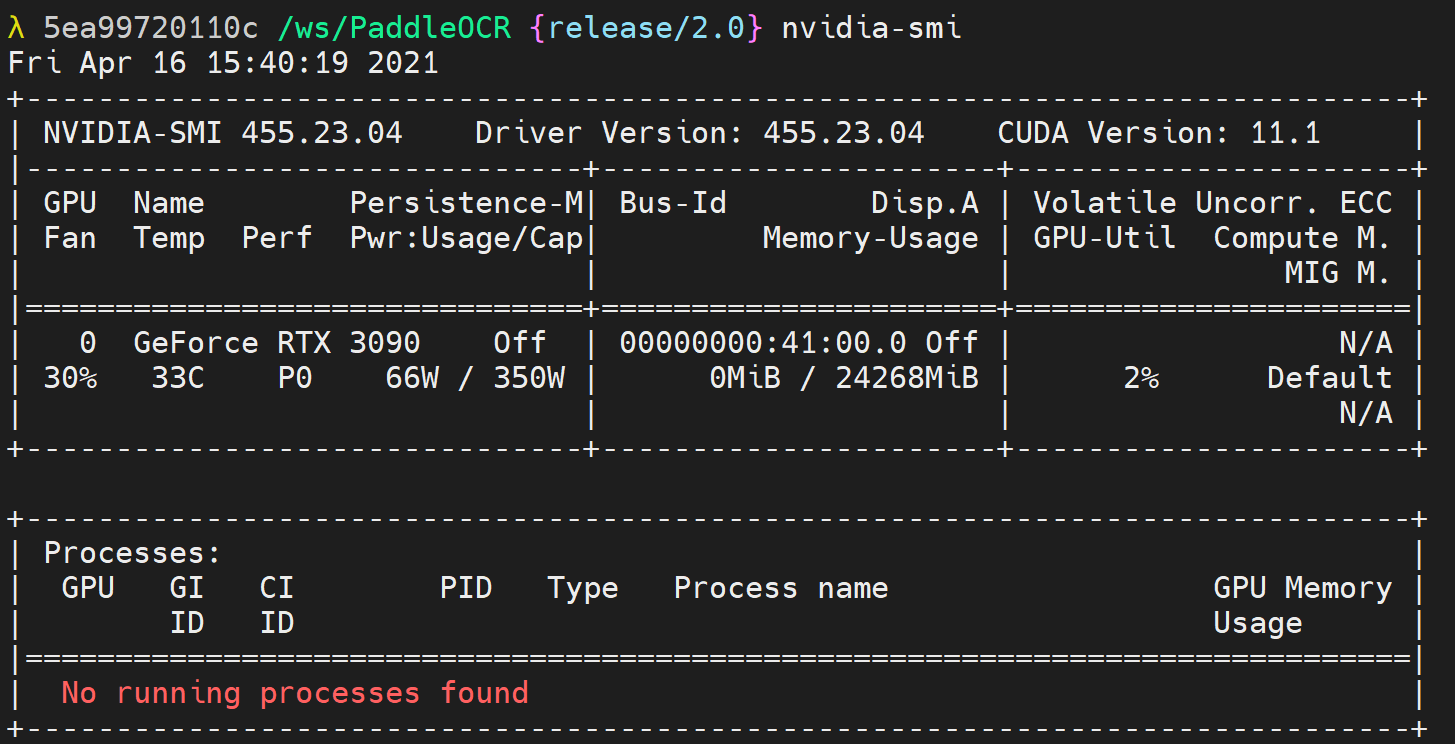
不再报cuda错误,提示
ImportError: No module named 'imgaug',然后突然想起来,这个docker里有很多python版本,应该是使用python3.7去运行
3.2 使用screen将docker中运行的程序放到后台
似乎没有找到很好的解决方案,只看到了docker容器下的screen:

参考: Persistent screen session inside Docker container

3.4 运行结果
GPU确实比CPU快了许多,很快准确率就很高了。。。

看了下配置文件,就72个epoch,也不是很多。。一些训练的基本信息
- 训练时间:2021.4.16 15:47到17:38,一个小时差不多。。。真快
- 准确率变化:最后基本一直在1附近。

最后运行结果可以看下,准确率巨高,也不知道效果咋样,试试吧。
4. 预测结果
使用 PaddleOCR 训练好的模型,可以通过以下脚本进行快速预测。
默认预测图片存储在 infer_img 里,通过 -o Global.checkpoints 指定权重:
# 直接使用预训练模型
python3.7 tools/infer_rec.py -c configs/rec/rec_r34_vd_none_bilstm_ctc.yml -o Global.checkpoints=pretrain_models/rec_r34_vd_none_bilstm_ctc/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
# 迁移训练过的
python3.7 tools/infer_rec.py -c configs/rec/rec_r34_vd_none_bilstm_ctc.yml -o Global.checkpoints=output/rec/r34_vd_none_bilstm_ctc/best_accuracy Global.infer_img=train_data/test/EXP1_crop_55.jpg
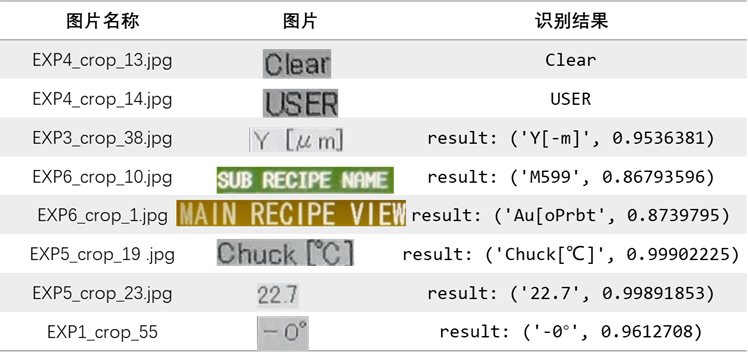
目前看来,感觉还不错,比直接预测的在符号方面要好一些。
4.1 和基线模型比较
直接使用PaddleOCR可以得到一些结果,使用PaddleOCRLabel也可以得到一些标记结果。
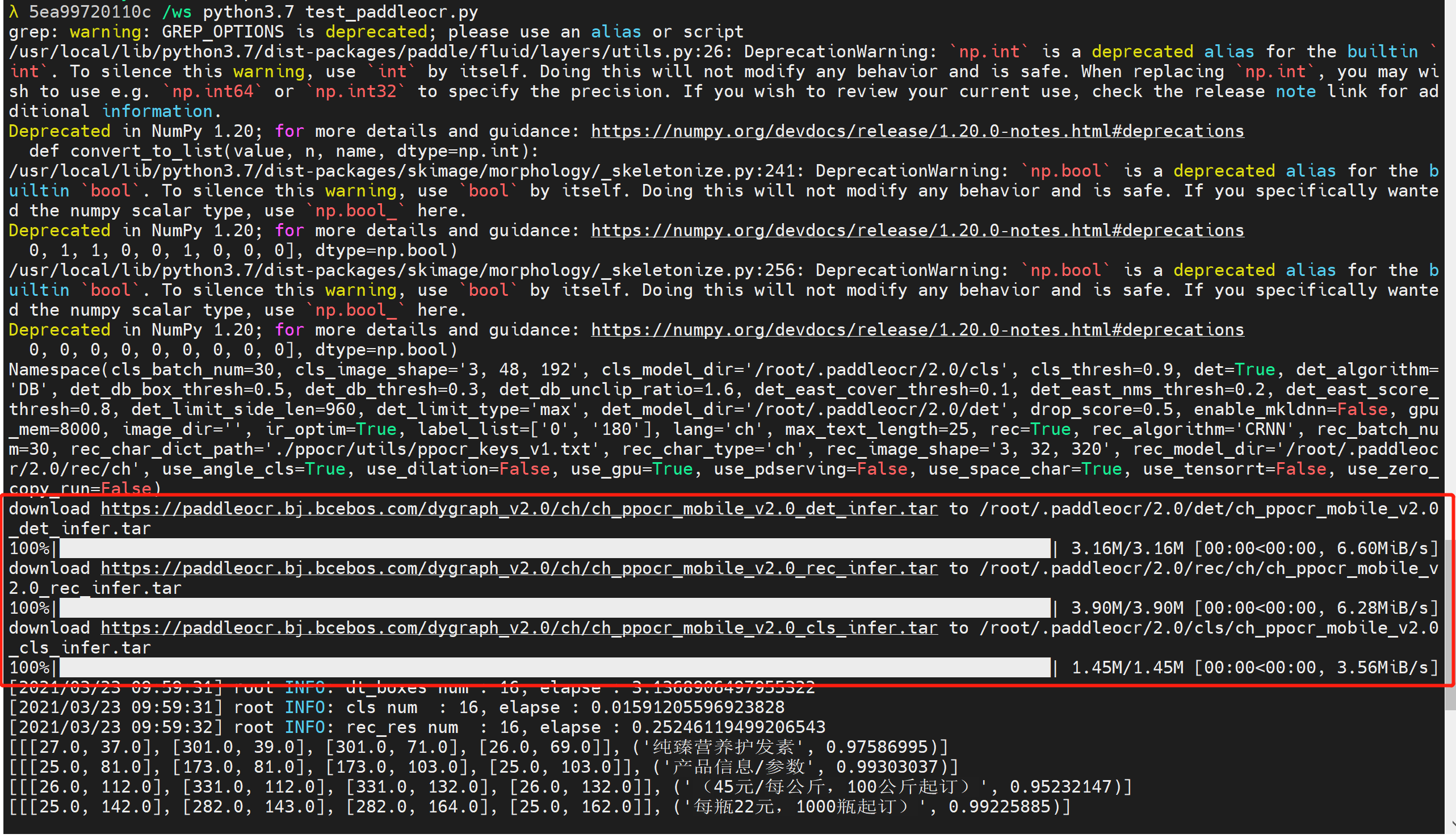
之前直接使用PaddleOCR的wheel来进行预测时,可以看到,其实也是下载了一些模型。在docker中打开这个目录,可以看到

模型文件是这个样子的,比较之前迁移训练/预训练模型的:

4.2.1 训练模型转换为推理模型
考虑进行转换,参考gitee-PaddleOCR-基于Python预测引擎推理或者github-识别模型转inference模型

也就是说,训练后的模型可以转换为推理模型(注意:上面是PaddleOCR2.0的模型)
建议使用的是release2.0,因为PaddleOCR的wheel使用用的就是2.0方式转换后的推理模型,而默认是develop版本。
使用如下代码:
# -c 后面设置训练算法的yml配置文件
# -o 配置可选参数
# Global.pretrained_model 参数设置待转换的训练模型地址,不用添加文件后缀 .pdmodel,.pdopt或.pdparams。
# Global.load_static_weights 参数需要设置为 False。
# Global.save_inference_dir参数设置转换的模型将保存的地址。
python3 tools/export_model.py
# 执行脚本
-c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml
# 配置文件
-o Global.pretrained_model=./ch_lite/ch_ppocr_mobile_v2.0_rec_train/best_accuracy
# 待转换的训练模型地址
Global.load_static_weights=False
# 需要设置为 False
Global.save_inference_dir=./inference/rec_crnn/
# 转换的模型将保存的地址
注意:如果是在自己的数据集上训练的模型,并且调整了中文字符的字典文件,请注意修改配置文件中的character_dict_path是否是所需要的字典文件。(还是要注意配置文件配置对!)
我实际使用的转换命令:
python3.7 tools/export_model.py -c configs/rec/rec_r34_vd_none_bilstm_ctc.yml -o Global.pretrained_model=output/rec/r34_vd_none_bilstm_ctc/best_accuracy Global.load_static_weights=False Global.save_inference_dir=./inference/rec_crnn/
转换成功后,可以看到如下三个文件,和PaddleOCR的wheel用的一样,哈哈。

/inference/cls/
├── inference.pdiparams # 分类inference模型的参数文件
├── inference.pdiparams.info # 分类inference模型的参数信息,可忽略
└── inference.pdmodel # 分类inference模型的program文件
4.2.2 使用推理模型推理
依然是参考:基于Python预测引擎推理

python3 tools/infer/predict_rec.py
--image_dir="./doc/imgs_words_en/word_336.png"
--rec_model_dir="./your inference model"
--rec_image_shape="3, 32, 100"
--rec_char_type="ch"
--rec_char_dict_path="your text dict path"
尤其要注意,对于自定义文本识别字典,需要通过--rec_char_dict_path这个参数指定自定义的文本字典路径。
4.2.3 使用paddleocr package来识别图片
之前在docker中安装好paddleocr的时候使用以下代码测试过
from paddleocr import PaddleOCR, draw_ocr
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
# need to run only once to download and load model into memory
查看PaddleOCR这个类文件(就在PaddleOCR的一级目录下:PaddleOCR\paddleocr.py)的定义,主要看其中的parse_args函数可以知道:
# 改成以下内容,改成自己的模型,另外,要指明字符文件路径(不然会按照默认的中文字符集)
ocr = PaddleOCR(rec_model_dir="PaddleOCR/inference/rec_crnn",
lang="ch",
rec_char_dict_path="PaddleOCR/ppocr/utils/dict/eng.txt",
)
对比一下,直接用paddleocr的package识别结果
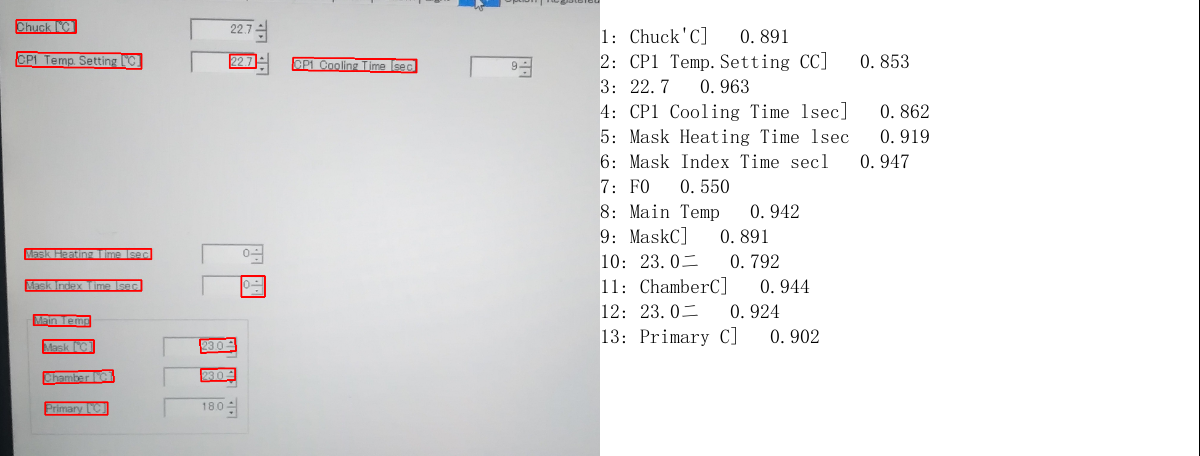
使用迁移训练后的结果,摄氏度符号,括号符号确实有所改善了。
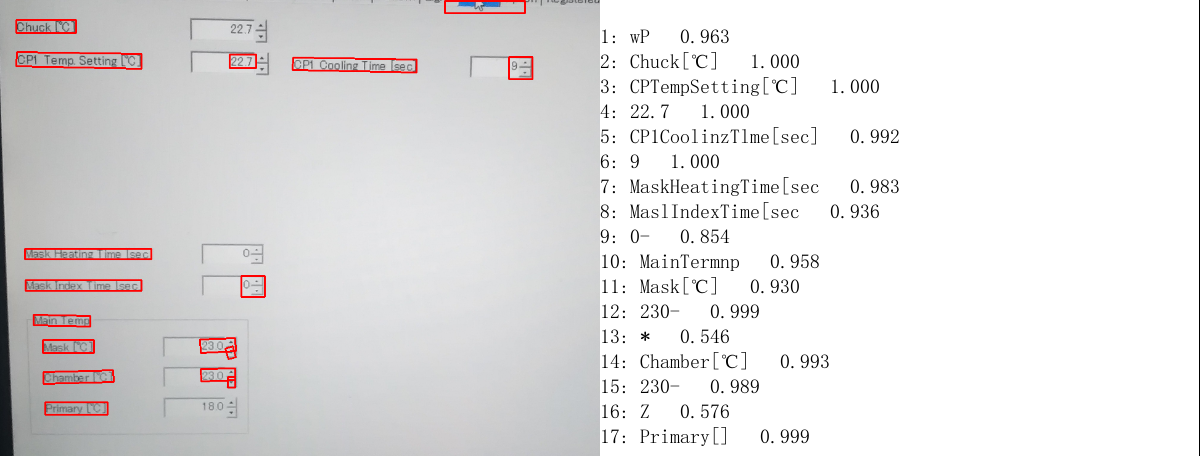
4.2.4 参数优化
进一步修改一些参数,
- 关于
det_db_unclip_ratio参数,参考识别模型框出来的位置太紧凑,会丢失边缘的文字信息,导致识别错误可以在命令中加入 --det_db_unclip_ratio ,参数定义位置,这个参数是检测后处理时控制文本框大小的,默认1.6,可以尝试改成2.5或者更大,反之,如果觉得文本框不够紧凑,也可以把该参数调小。
- 关于配置文件里面检测的阈值设置么?
det_limit_side_len:预测时图像resize的长边尺寸
det_db_thresh: 用于二值化输出图的阈值
det_db_box_thresh:用于过滤文本框的阈值,低于此阈值的文本框不要
det_db_unclip_ratio: 文本框扩张的系数,关系到文本框的大小 - 关于文档场景中,使用DB模型会出现整行漏检的情况应该怎么解决?
可以在预测时调小 det_db_box_thresh 阈值,默认为0.5, 可调小至0.3观察效果。
ocr = PaddleOCR(rec_model_dir="PaddleOCR/inference/rec_crnn",
lang="ch",
rec_char_dict_path="PaddleOCR/ppocr/utils/dict/eng.txt",
rec_image_shape="3, 32, 256",
# 配置文件中图像尺寸是这样,默认是[3,32,300]
det_db_unclip_ratio=2.5,
# 控制文本框紧凑程度的,文字边缘距离文字框的紧凑
det_db_box_thresh=0.7
# 过滤文本框,低于此阈值的文本框不要
)
4.2.5 新的问题
之前运行都可以正常进行,但是后来stop了一次docker,再start之后去运行,出现
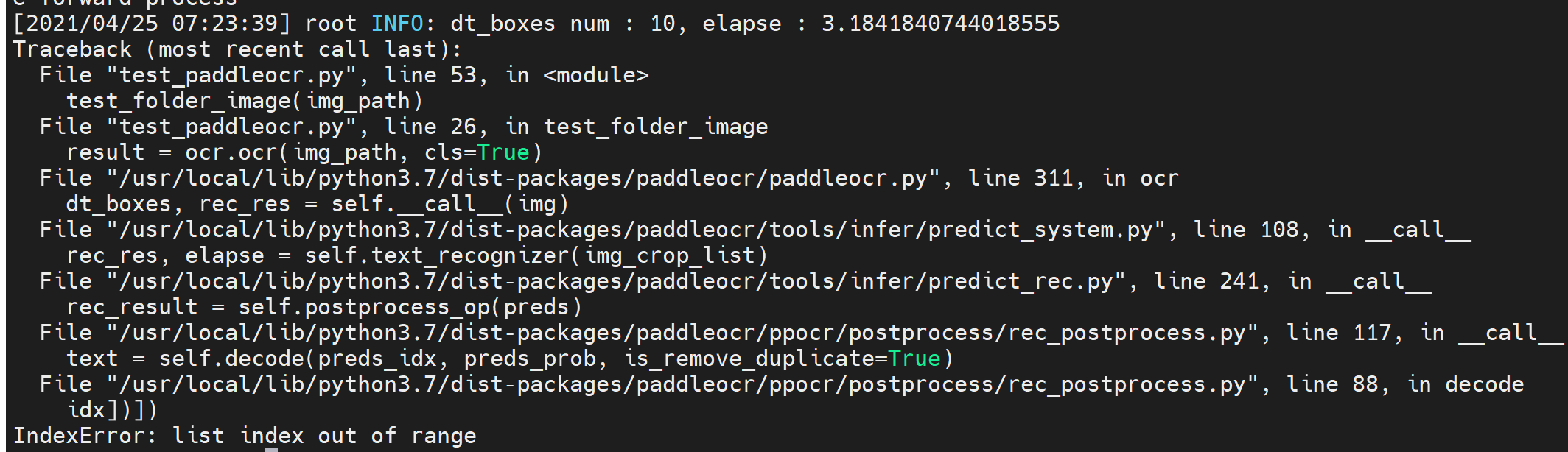
无语,真的是lj,搜到的很多也都无法解决问题,
测试了一下,直接使用以下预测方式还是OK的
python3.7 tools/infer_rec.py -c configs/rec/rec_r34_vd_none_bilstm_ctc.yml -o Global.checkpoints=output/rec/r34_vd_none_bilstm_ctc/best_accuracy Global.infer_img=train_data/test/EXP1_crop_55.jpg
所以问题应该还是出在转换后的模型和词典上,认真看了一下,发现,自己之前的inference生产的地方和paddleOCR目录其实不在一起。

可以通过运行程序时打印的参数,可以看到这个目录其实是相对于根目录,而不是我当前程序运行的目录

所以需要修改正确字符集字典文件的路径以及自己训练的推理模型的路径(我的都是在/ws/PaddleOCR这个文件夹里,而不是和ws同级的这个PaddleOCR文件夹)
4.2 改进方向
之前的数据2.4w张,有很多符号,还是字体不太好,不是特别靠近场景字体,可以考虑使用没有符号的字体,专门针对英语数字进行一次训练。
英语大写+小写52个字母,数字10个字母,62个字母,62*500=3.1w张图片,再和之前的2.46w张一起,重新迁移学习一边。
4.3 每次重新启动的命令
# 如果启动失败,可以先用以下命令查看现有容器的状态
> docker ps -a
# 在这个命令的输出中查看自己那个容器的状态,如果是Exited 就是被暂停了,使用start命令把暂停状态的容器重新运行起来
> docker start OCR
# 然后再进入到容器的命令行中
> docker container exec -it OCR /bin/bash
4.4 训练时使用screen
使用screen来保证退出命令行之后训练不会被终止(就是当前shell不会被杀死)
我的docker中默认没有安装这个包,需要
> apt-get install screen
# 安装完成之后,可以
> screen -v
# 看看版本
基本使用方式(这里只介绍为了保证训练不中断用到的几个命令,其他的什么快捷键都不做多余了解)
# 新建一个会话,大写S
> screen -S train
# 然后可以在这里面启动自己的训练内容了
但是一直报错,所以放弃了,参考另一个文章,由于无法解决使用screen时的错误,所以放弃使用screen,而是使用了更好的tmux工具,docker中使用screen报错 /bin/sh: 1: __git_ps1: not found
参考:


















 1756
1756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











