







1.spark的概念
Apache Spark™ is a fast and general engine for large-scale data processing.
Apache Spark 是处理大规模数据的快速的、通用的引擎。
3.spark的四大特征
(1)Speed(速度)
Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
Apache Spark has an advanced DAG execution engine that supports acyclic data flow and in-memory computing.
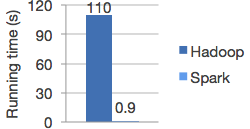
与hadoop的Mapreduce相比,spark基于内存的运算比Mapreduce要快100倍,spark基于磁盘的运算比Mapreduce要快10倍。(实际应用中并没有那么的夸张)
Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。
为什么spark的运行速度会比Mapreduce快??==========》
Mapreduce的map ->磁盘 -> shuffle -> reduce -> 磁盘
上面过程中两次将文件落地到磁盘上面,然后再加载都内存,这样耗费时间;
而spark的函数在运行的时候,绝大多数的函数都是在内存中迭代的,只有少数的函数在运行的时候需要将文件落地到磁盘上面,这样就加快了计算的速度。
总结:Spark是对MapReduce的过程做了优化,
Spark是对MapReduce的架构做了优化
(2)Ease of Use(易用)
Write applications quickly in Java, Scala, Python, R.
Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python and R shells.
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使得用户可以很容易的构建并行应用程序,用户可以交互式的使用Scala、Python、R的shell操作。
语言的选择:
Java
好处:我们做一个大数据的大型项目
Hbase Kafka Flume hadoop -> MySQL SSH 这些都是用Java开发的,因为Java有很成熟的产品和方案存在,所以也会有项目经理。去选Java开发Spark程序。
坏处:代码写出来不好看,运行效率没scala好。
但是好在出来了jdk8 里面有lamda表达式,也支持函数式编程。让代码好看了一点。
Scala:
好处:spark 就是用scala开发,运行效率好。而且是函数式编程。代码很优雅Spark中超过80个算子(map reduce)操作Spark开发起来,会更灵活,而且更简单
Ptyhon去做开发:这也是没问题的
注:一个项目里面可以即用Scala和Java的,因为他们可以无缝的对接,但是维护成本比较高
(3)Generality(通用性)
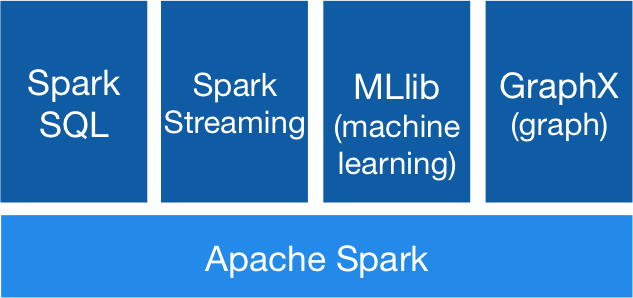
Combine SQL, streaming, and complex analytics.Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
Spark提供了统一的解决方案,Spark可以用于批处理、交互式查询(通过spark SQL)、实时流处理(通过Spark Streaming)、机器学习(通过MLlib)和图计算(GraphX),这些不同类型的处理可以在一个应用中无缝使用,而且spark的性能极好。
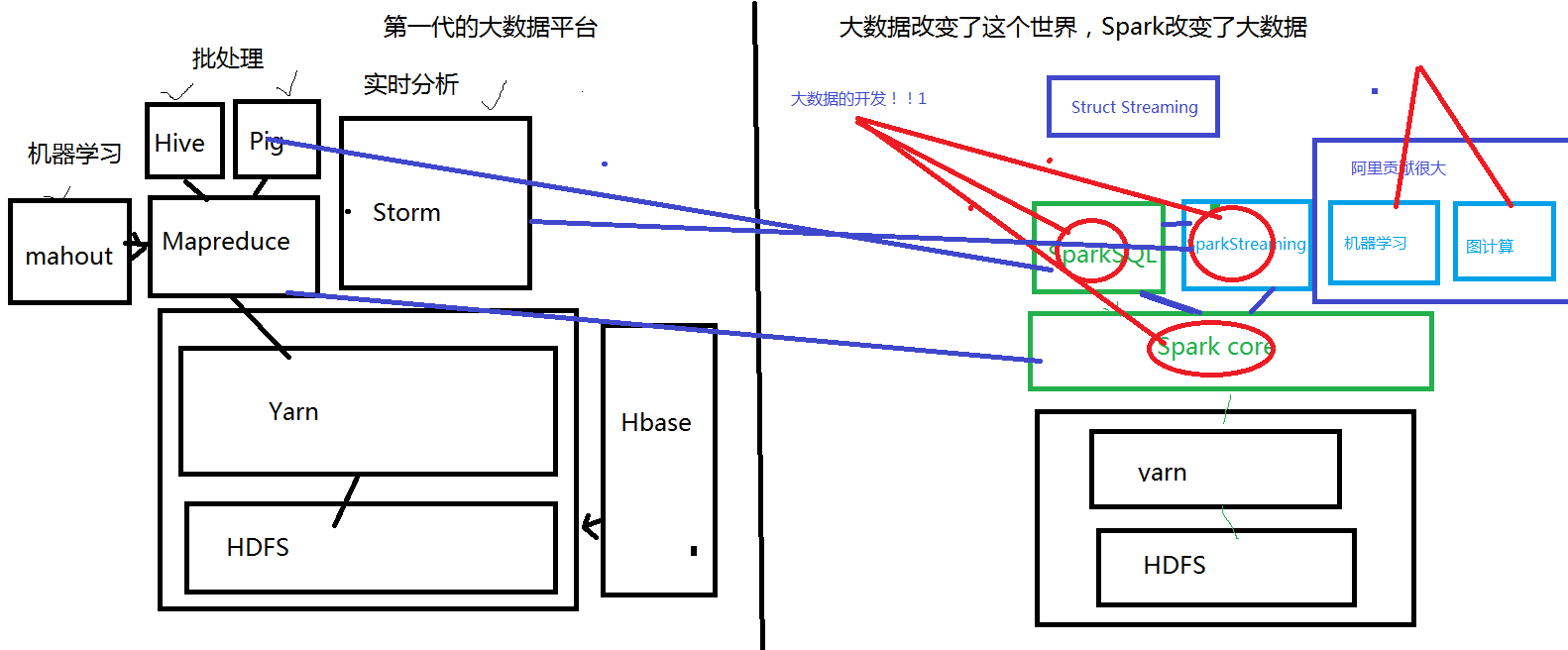
第一代大数据平台
Hadoop上面的分布式的计算系统是MapReduce,但是MapReduce的计算程序要求太高。进而开发出来了基于Hadoop的Hive和Pig,这两个分布式的数据仓库都是将sql语句转化成MapReduce程序提交到Yarn上面运行,计算的数据来源于HDFS。
MapReduce也支持深度学习和机器学习,将Mahout的程序转换成MapReduce程序,提交到Yarn上面进行运行。
对数据实时的交互式查询需要在Hadoop的集群上面安装一个Hbase。
对数据进行实时的计算分析,在Hadoop的集群上面安装一个storm的集群。
第二代大数据平台
SparkCore是类似于Mapreduce的一个计算系统
SparkSQL是类似于Hive和Pig
SparkStreaming类似于Storm
SparkStreaming和SparkSQL可以进行无缝的转换
Spark也支持深度学习和机器学习,还支持图计算(数据结构里面的图结构)
(4)Runs Everywhere(可融合性)
Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, or on Apache Mesos. Access data in HDFS, Cassandra, HBase,Hive, Tachyon, and any Hadoop data source.
Spark的资源管理和调度方面:
在standalone模式下面,spark自己管理和调度自己的资源,此时会开启master和worker,由master来管理和调度资源。
在hadoop yarn的模式下,spark的资源管理和调度器是yarn,由resourcemanager来管理和调度资源。
在 apache mesos的模式下,spark的资源管理和调度器是mesos。Mesos:是一个类似于yarn的资源管理器。
Spark可访问的数据:
HDFS,Cassandra、Hbase、Hive、Tachyon和各种hadoop和访问到的数据资源,比如kafka和flume等。
总结:
在我们国内经常让Spark是运行在yarn上面,原因我们之前的大数据平台就是用hadoop构建的。国外喜欢把Spark运行在Mesos(Spark一出来的时候,就是运行在Mesos)
注:mesos和spark是一个团队写的,最早spark是在masos上面运行的。为了推广所有兼容了其他的资源管理器
Spark自己管理资源,standalone Spark自己管理资源。
Master Worker
Spark –》Mesos (同一个团队写的)
Spark –》 Stanalone的模式















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









