









/* * Cluster-> WordNode -> Executors -> Threads -> Task * * Job Action操作 * Stage shuffle操作 * * Application -> Jobs -> Stages -> Task */
Spark作业的基本概念
-Application:用户自定义的Spark程序,用户提交后,Spark为App分配资源将程序转换并执行。
-Driver Program:运行Application的main()函数并且创建SparkContext。
-RDD DAG:当RDD遇到Action算子,将之前的所有算子形成一个有向无环图(DAG)。再在Spark中转化为Job,提交到集群进行执行。一个App中可以包含多Job。
-Job:一个RDD Graph触发的作业,往往由Spark Action算子触发,在SparkContext中通过runJob方法向Spark提交Job。
-Stage:每个Job会根据RDD的宽依赖关系被切分很多Stage,每个Stage中包含一组相同的Task,这一组Task也叫TaskSet。
-Task:一个分区对应一个Task,Task执行RDD中对应Stage中所包含的算子。Task被封装好后放入Executor的线程池中执行。Executor会在线程池中取得一个线程,分配给一个任务,之后任务执行完成,线程池回收线程。
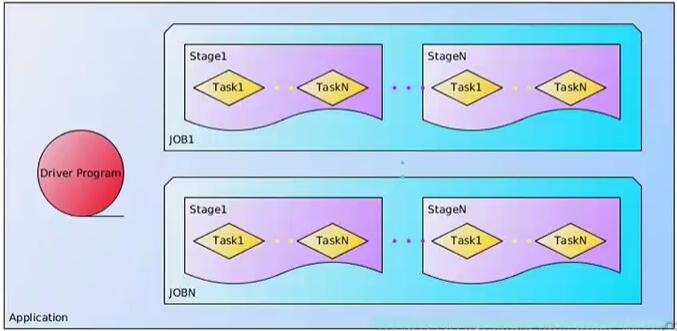
Spark程序与作用概念映射
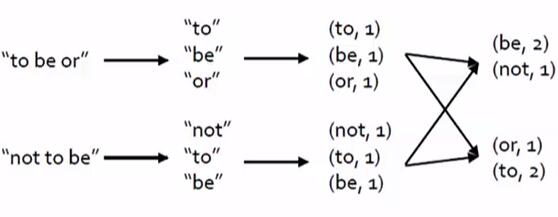
val rawFile = sc.textFile("README.md") //Application:1-6行
(将输入的文本文件转化为RDD)
val words = rawFile.flatMap(line=>line.split(" ")) //Job:1-5行
(将文本文件映射为word单词,将文本文件进行分词,转换为一个单词的RDD)
val wordNumber = words.map(w=>(w,1)) //Stage:1-3或4-5行
(将RDD中的每个单词映射为,单词名称为key,value为1的kye-value对)
val wordCounts = wordNumber.reduceByKey(_+_) //Tasks:1-3或4-5行
(通过reduceBykey操作,将同一个单词的数据进行聚集,进而统计好每一个单词的个数)
wordCounts.foreach(println)
(foreach输出每一个单词的计数)
wordCounts.saveAsTextFile
(saveAsTextFile将结果保存到磁盘)
6行代码对应为一个Application,这个应用程序中有两个Job,1-5行是一个Job,1-4 + 6行是一个Job。
在1-5行这个Job中:
1-3行是一个stage,4-5行是一个stage,因为map和reduceByKey之间要进行shuffle操作。
Spark作业运行流程
-Spark程序转换,将应用程序提交到集群,集群将程序由一个application转换成不同的任务集;
-在集群中输入数据块
-集群会根据调度策略执行各个Stage的Tasks分发到各个节点,在每个数据块上进行执行
-执行完成后,会根据shuffle在集群中将结果进行混洗,再进行下一阶段的Stage,直到所有Stage执行完毕,输出结果返回
Driver
sc
DAGScheduler -> Stage -> Task
TaskScheduler -> 分发Task到Worker
Driver -> 收集Worker的计算结果
Work
执行Task















 1150
1150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









